 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ULF: Unsupervised Labeling Function Correction using Cross-Validation for Weak Supervision
Apr 14, 2022
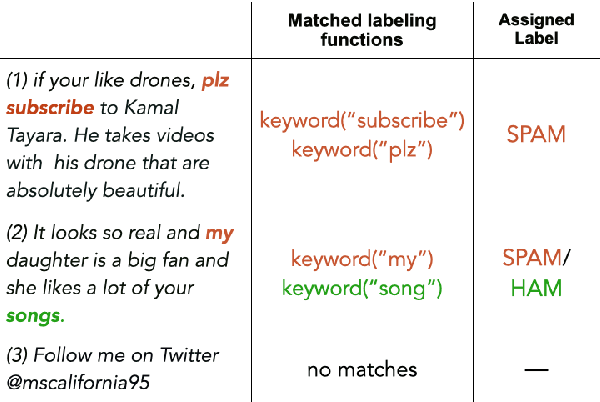
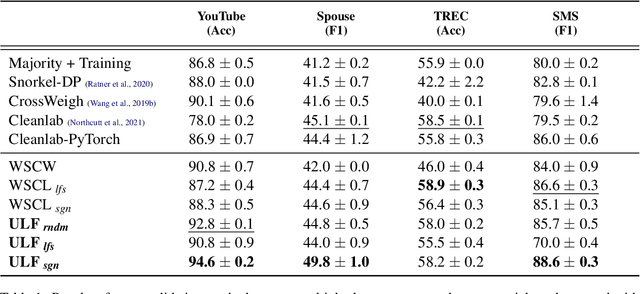
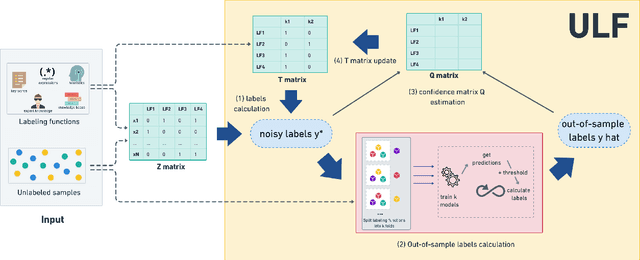

A way to overcome expensive and time-consuming manual data labeling is weak supervision - automatic annotation of data samples via a predefined set of labeling functions (LFs), rule-based mechanisms that generate potentially erroneous labels. In this work, we investigate noise reduction techniques for weak supervision based on the principle of k-fold cross-validation. In particular, we extend two frameworks for detecting the erroneous samples in manually annotated data to the weakly supervised setting. Our methods profit from leveraging the information about matching LFs and detect noisy samples more accurately. We also introduce a new algorithm for denoising the weakly annotated data called ULF, that refines the allocation of LFs to classes by estimating the reliable LFs-to-classes joint matrix. Evaluation on several datasets shows that ULF successfully improves weakly supervised learning without using any manually labeled data.
ActionFormer: Localizing Moments of Actions with Transformers
Feb 16, 2022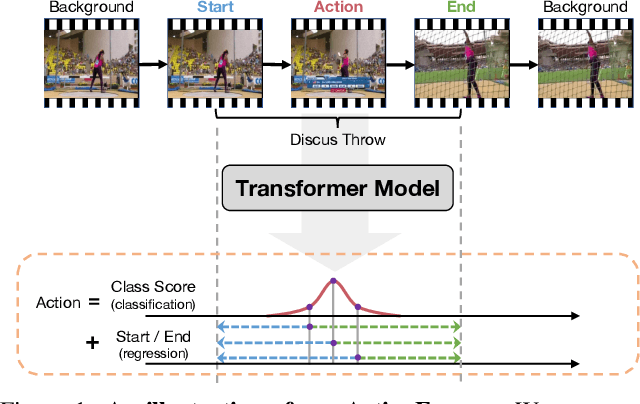
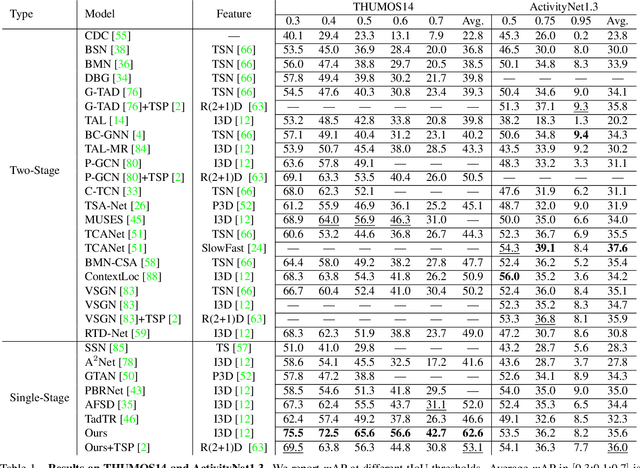
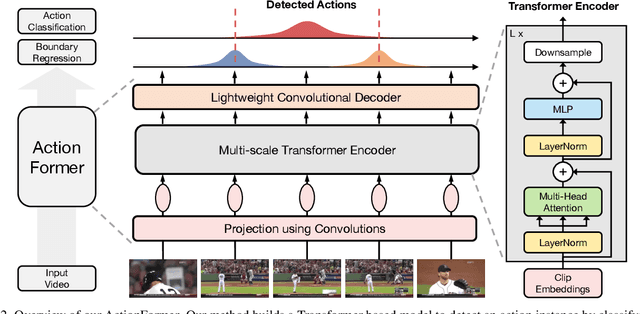
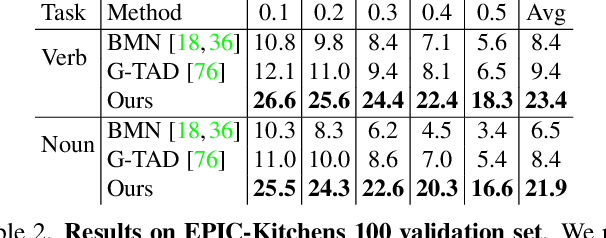
Self-attention based Transformer models have demonstrated impressive results for image classification and object detection, and more recently for video understanding. Inspired by this success, we investigate the application of Transformer networks for temporal action localization in videos. To this end, we present ActionFormer -- a simple yet powerful model to identify actions in time and recognize their categories in a single shot, without using action proposals or relying on pre-defined anchor windows. ActionFormer combines a multiscale feature representation with local self-attention, and uses a light-weighted decoder to classify every moment in time and estimate the corresponding action boundaries. We show that this orchestrated design results in major improvements upon prior works. Without bells and whistles, ActionFormer achieves 65.6% mAP at tIoU=0.5 on THUMOS14, outperforming the best prior model by 8.7 absolute percentage points and crossing the 60% mAP for the first time. Further, ActionFormer demonstrates strong results on ActivityNet 1.3 (36.0% average mAP) and the more recent EPIC-Kitchens 100 (+13.5% average mAP over prior works). Our code is available at http://github.com/happyharrycn/actionformer_release
PCP Theorems, SETH and More: Towards Proving Sub-linear Time Inapproximability
Nov 04, 2020In this paper we propose the PCP-like theorem for sub-linear time inapproximability. Abboud et. have devised the distributed PCP framework for sub-quadratic time inapproximability. We show that the distributed PCP theorem can be generalized for proving arbitrary polynomial time inapproximability, but fails in the linear case. We borrow similar proof techniques from \cite{Abboud2017} for proving the sub-linear time PCP, and show how to use it to prove both existing and new inapproximability results. These results exhibits the power of the sub-linear PCP theorem proposed in this paper. Considering the emerging research works on sub-linear time algorithms, the sub-linear PCP theorem is important in guiding the research in sub-linear time approximation algorithms.
Adversarial Training for High-Stakes Reliability
May 04, 2022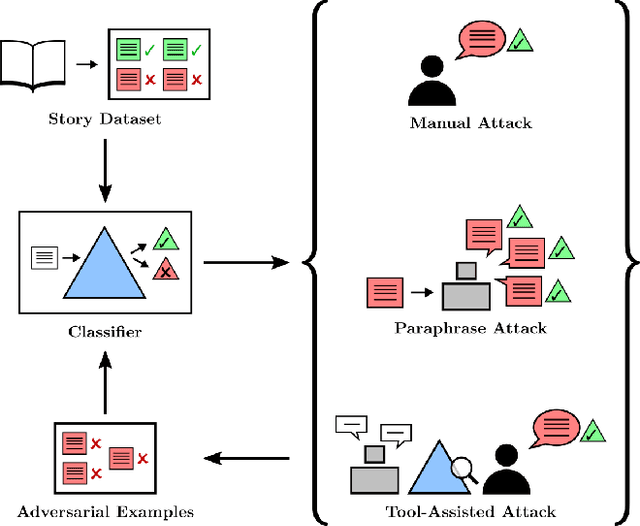


In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a language generation task as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques -- including a tool that assists human adversaries -- to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our simple "avoid injuries" task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. With our chosen thresholds, filtering with our baseline classifier decreases the rate of unsafe completions from about 2.4% to 0.003% on in-distribution data, which is near the limit of our ability to measure. We found that adversarial training significantly increased robustness to the adversarial attacks that we trained on, without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.
Toward More Effective Human Evaluation for Machine Translation
Apr 11, 2022
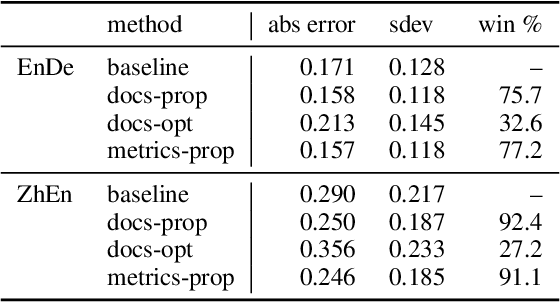
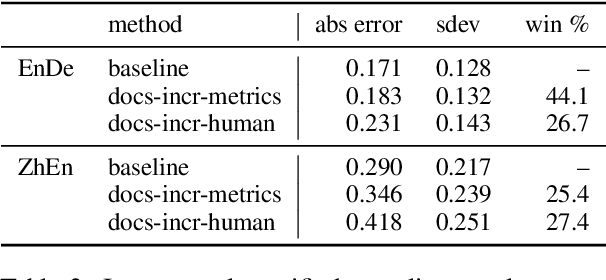
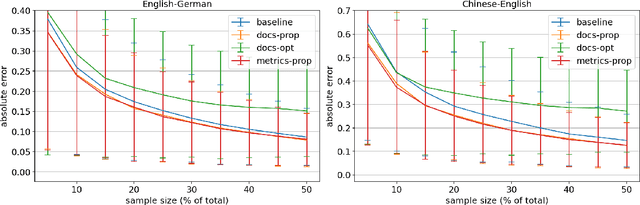
Improvements in text generation technologies such as machine translation have necessitated more costly and time-consuming human evaluation procedures to ensure an accurate signal. We investigate a simple way to reduce cost by reducing the number of text segments that must be annotated in order to accurately predict a score for a complete test set. Using a sampling approach, we demonstrate that information from document membership and automatic metrics can help improve estimates compared to a pure random sampling baseline. We achieve gains of up to 20% in average absolute error by leveraging stratified sampling and control variates. Our techniques can improve estimates made from a fixed annotation budget, are easy to implement, and can be applied to any problem with structure similar to the one we study.
Real-time anomaly detection with superexperts
Oct 08, 2020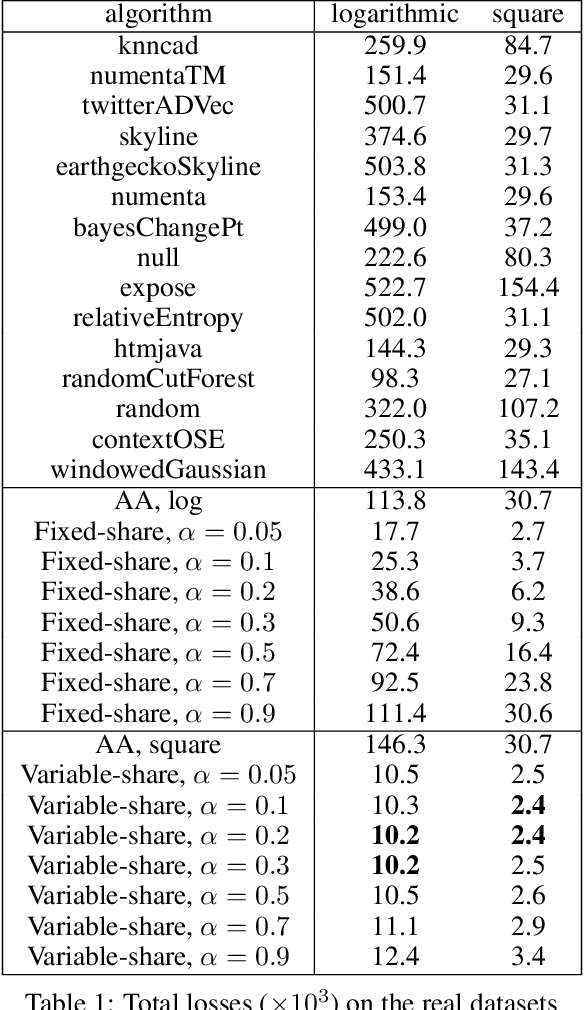
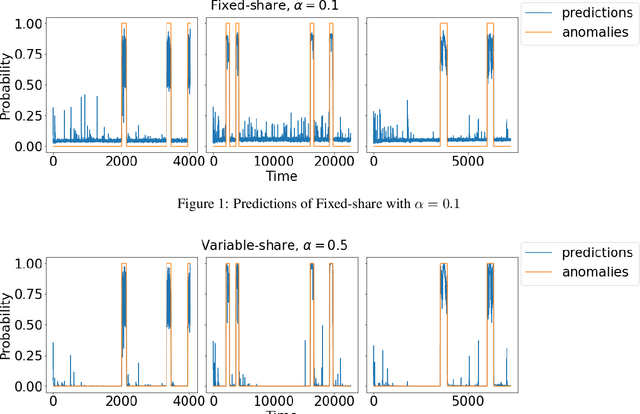
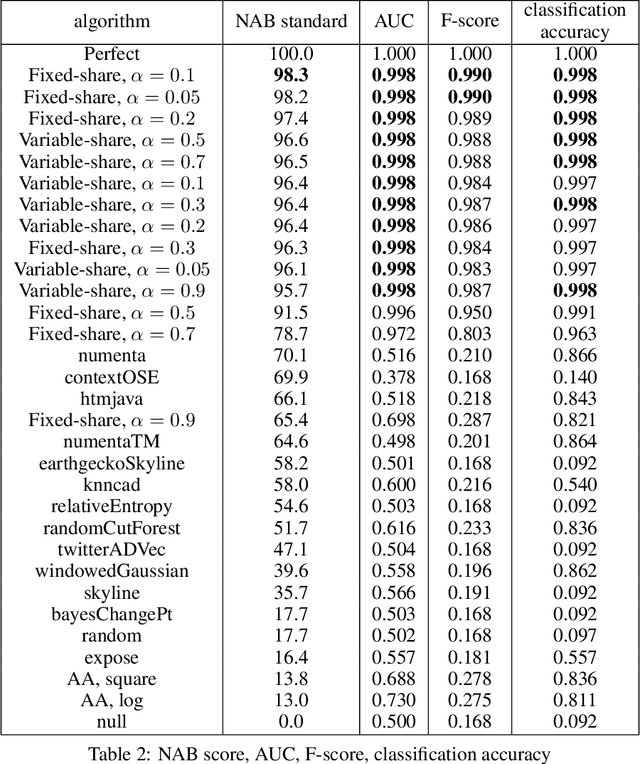
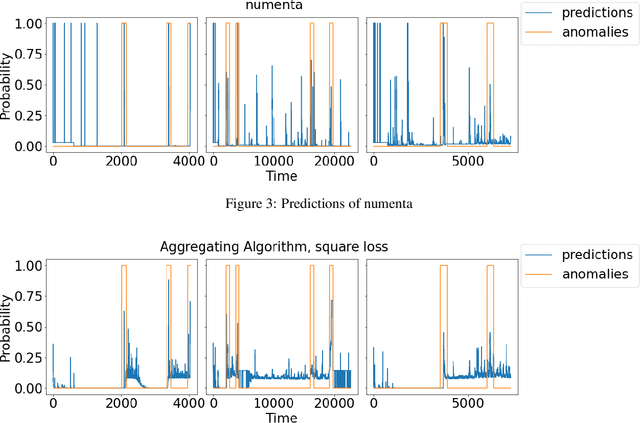
The increasing connectivity of data and cyber-physical systems has resulted in a growing number of cyber attacks. Real-time detection of such attacks, through identification of anomalous activity, is required so that mitigation and contingent actions can be effectively and rapidly deployed. We propose to apply the prediction with expert advice (PEA) framework to a real-time anomaly detection problem. We apply PEA on open-source real datasets and show that the combination of models, which we call experts, provides significantly better results than any single model. An important property of the proposed approaches is their theoretical guarantees that they perform close to the best expert or even the superexpert, which can switch between the best performing experts. In addition, the approaches are also straightforward to implement and require little memory to run on streaming data.
Slow-varying Dynamics Assisted Temporal Capsule Network for Machinery Remaining Useful Life Estimation
Mar 30, 2022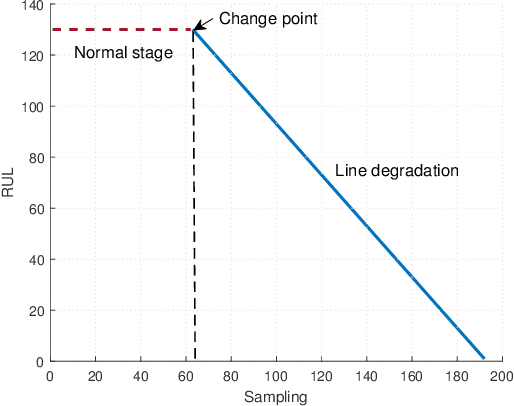
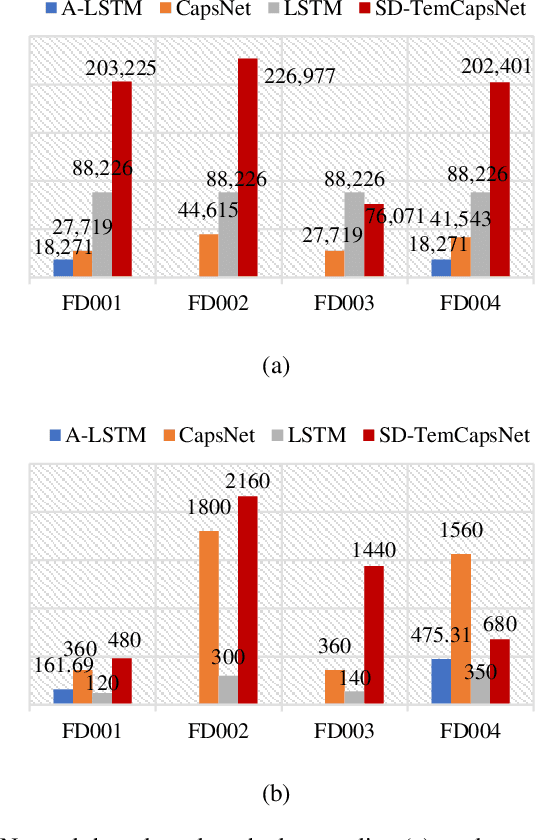
Capsule network (CapsNet) acts as a promising alternative to the typical convolutional neural network, which is the dominant network to develop the remaining useful life (RUL) estimation models for mechanical equipment. Although CapsNet comes with an impressive ability to represent the entities' hierarchical relationships through a high-dimensional vector embedding, it fails to capture the long-term temporal correlation of run-to-failure time series measured from degraded mechanical equipment. On the other hand, the slow-varying dynamics, which reveals the low-frequency information hidden in mechanical dynamical behaviour, is overlooked in the existing RUL estimation models, limiting the utmost ability of advanced networks. To address the aforementioned concerns, we propose a Slow-varying Dynamics assisted Temporal CapsNet (SD-TemCapsNet) to simultaneously learn the slow-varying dynamics and temporal dynamics from measurements for accurate RUL estimation. First, in light of the sensitivity of fault evolution, slow-varying features are decomposed from normal raw data to convey the low-frequency components corresponding to the system dynamics. Next, the long short-term memory (LSTM) mechanism is introduced into CapsNet to capture the temporal correlation of time series. To this end, experiments conducted on an aircraft engine and a milling machine verify that the proposed SD-TemCapsNet outperforms the mainstream methods. In comparison with CapsNet, the estimation accuracy of the aircraft engine with four different scenarios has been improved by 10.17%, 24.97%, 3.25%, and 13.03% concerning the index root mean squared error, respectively. Similarly, the estimation accuracy of the milling machine has been improved by 23.57% compared to LSTM and 19.54% compared to CapsNet.
X-Fields: Implicit Neural View-, Light- and Time-Image Interpolation
Oct 01, 2020
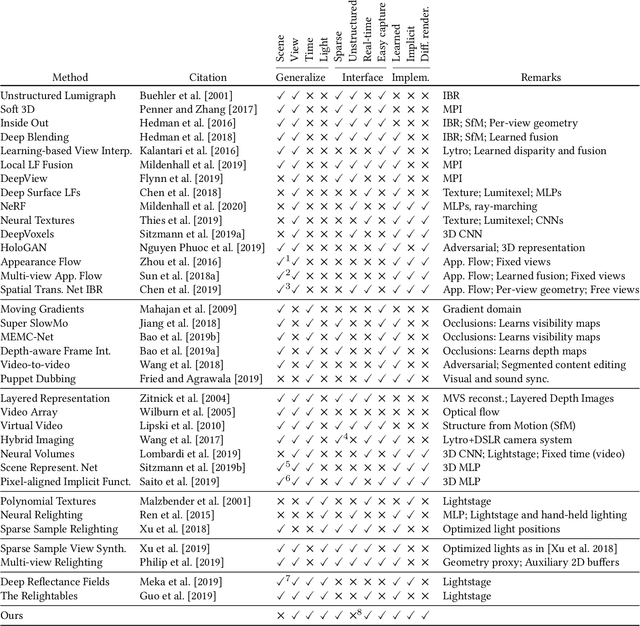
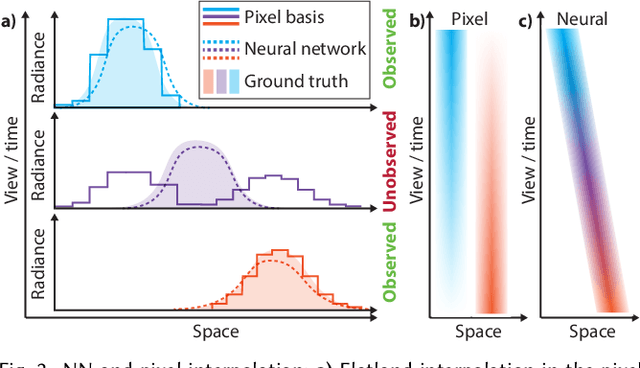
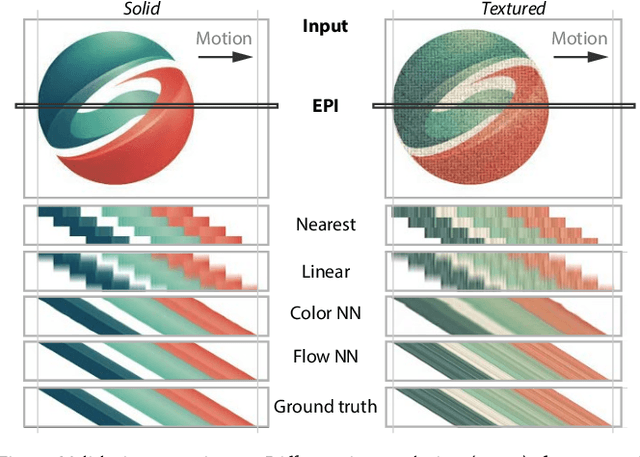
We suggest to represent an X-Field -a set of 2D images taken across different view, time or illumination conditions, i.e., video, light field, reflectance fields or combinations thereof-by learning a neural network (NN) to map their view, time or light coordinates to 2D images. Executing this NN at new coordinates results in joint view, time or light interpolation. The key idea to make this workable is a NN that already knows the "basic tricks" of graphics (lighting, 3D projection, occlusion) in a hard-coded and differentiable form. The NN represents the input to that rendering as an implicit map, that for any view, time, or light coordinate and for any pixel can quantify how it will move if view, time or light coordinates change (Jacobian of pixel position with respect to view, time, illumination, etc.). Our X-Field representation is trained for one scene within minutes, leading to a compact set of trainable parameters and hence real-time navigation in view, time and illumination.
Dual Branch Neural Network for Sea Fog Detection in Geostationary Ocean Color Imager
May 04, 2022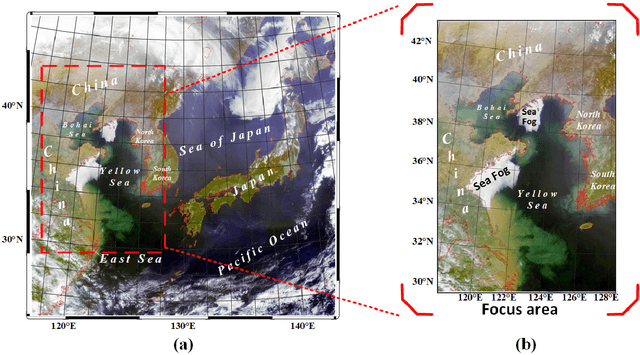
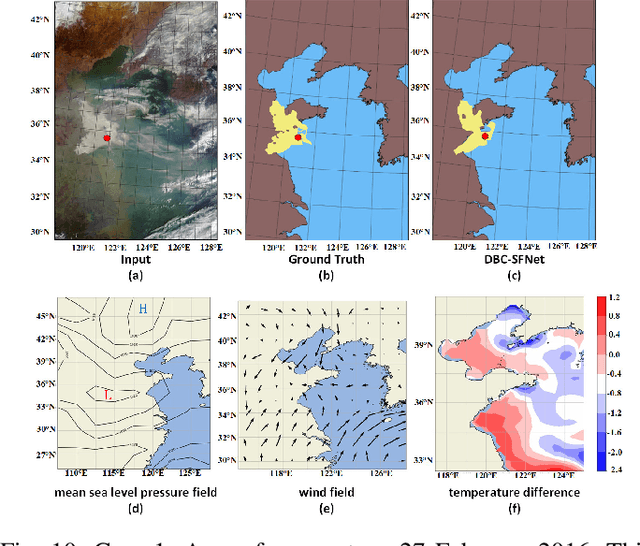
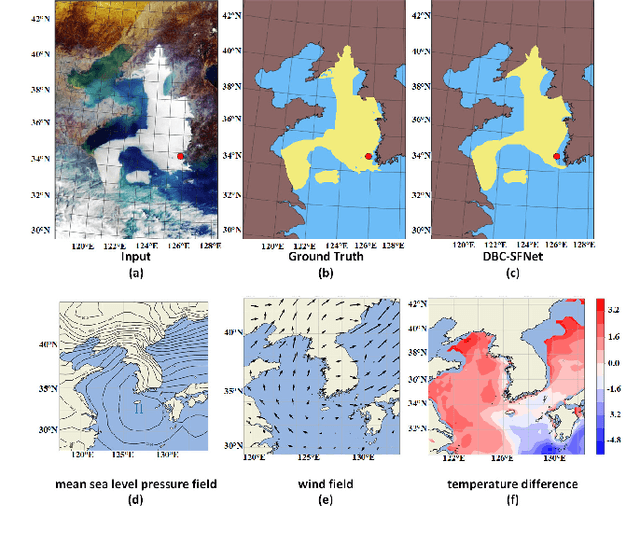
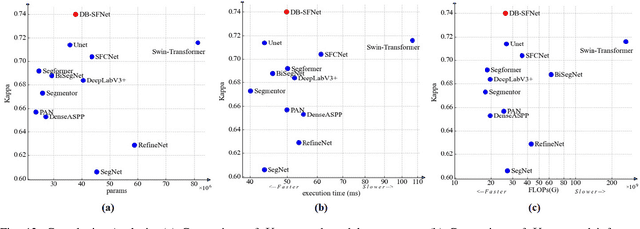
Sea fog significantly threatens the safety of maritime activities. This paper develops a sea fog dataset (SFDD) and a dual branch sea fog detection network (DB-SFNet). We investigate all the observed sea fog events in the Yellow Sea and the Bohai Sea (118.1{\deg}E-128.1{\deg}E, 29.5{\deg}N-43.8{\deg}N) from 2010 to 2020, and collect the sea fog images for each event from the Geostationary Ocean Color Imager (GOCI) to comprise the dataset SFDD. The location of the sea fog in each image in SFDD is accurately marked. The proposed dataset is characterized by a long-time span, large number of samples, and accurate labeling, that can substantially improve the robustness of various sea fog detection models. Furthermore, this paper proposes a dual branch sea fog detection network to achieve accurate and holistic sea fog detection. The poporsed DB-SFNet is composed of a knowledge extraction module and a dual branch optional encoding decoding module. The two modules jointly extracts discriminative features from both visual and statistical domain. Experiments show promising sea fog detection results with an F1-score of 0.77 and a critical success index of 0.63. Compared with existing advanced deep learning networks, DB-SFNet is superior in detection performance and stability, particularly in the mixed cloud and fog areas.
Unbiased Estimation of the Gradient of the Log-Likelihood for a Class of Continuous-Time State-Space Models
May 28, 2021
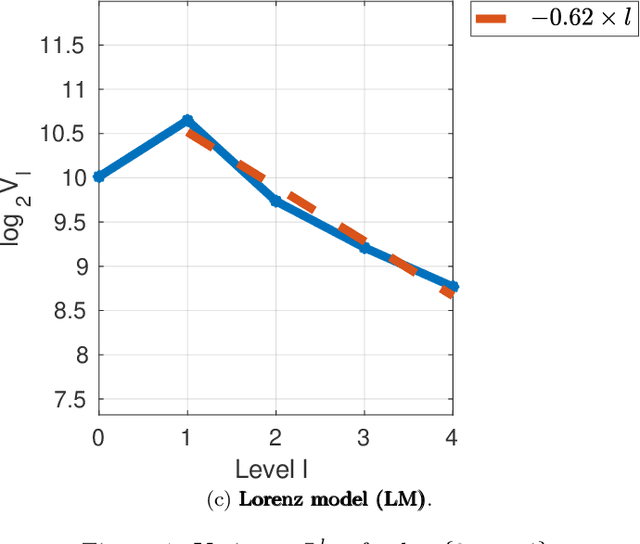
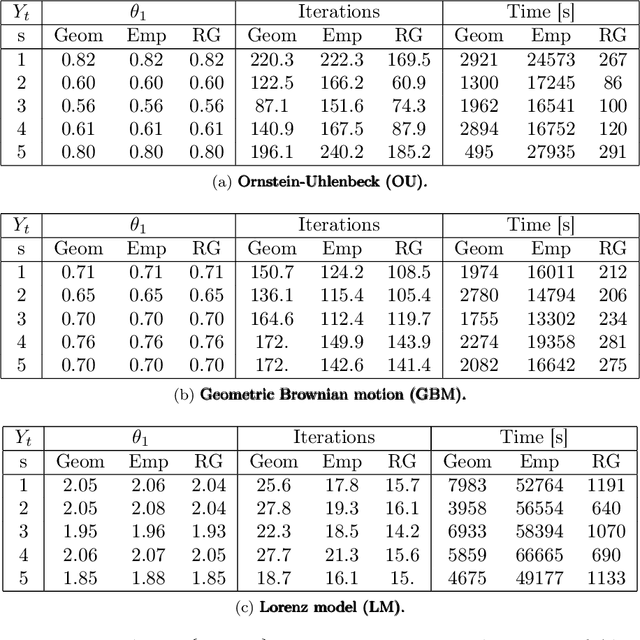
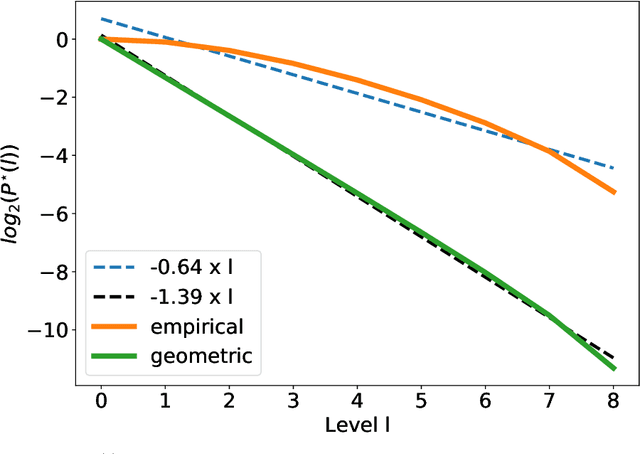
In this paper, we consider static parameter estimation for a class of continuous-time state-space models. Our goal is to obtain an unbiased estimate of the gradient of the log-likelihood (score function), which is an estimate that is unbiased even if the stochastic processes involved in the model must be discretized in time. To achieve this goal, we apply a doubly randomized scheme, that involves a novel coupled conditional particle filter (CCPF) on the second level of randomization. Our novel estimate helps facilitate the application of gradient-based estimation algorithms, such as stochastic-gradient Langevin descent. We illustrate our methodology in the context of stochastic gradient descent (SGD) in several numerical examples and compare with the Rhee & Glynn estimator.