 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-based Framework for Automatic Cranial Defect Reconstruction and Implant Modeling
Apr 13, 2022
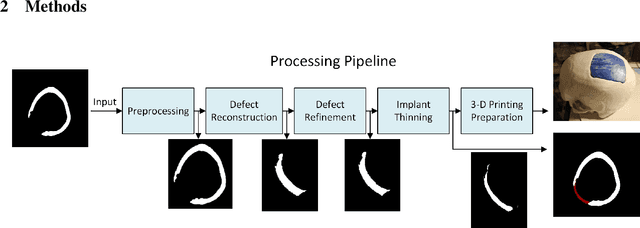
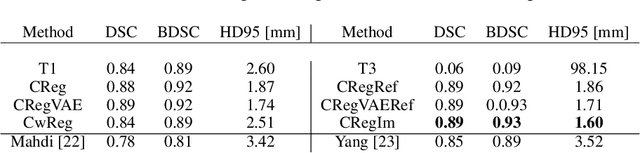
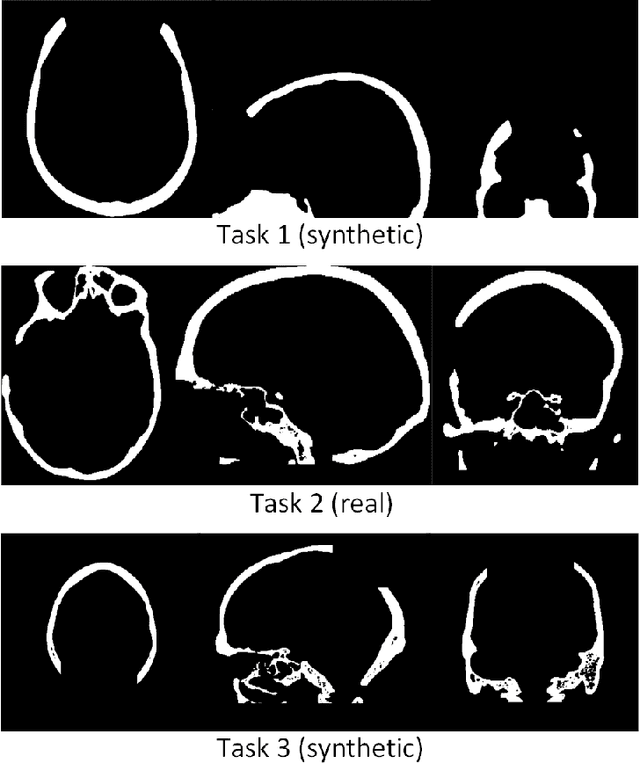

The goal of this work is to propose a robust, fast, and fully automatic method for personalized cranial defect reconstruction and implant modeling. We propose a two-step deep learning-based method using a modified U-Net architecture to perform the defect reconstruction, and a dedicated iterative procedure to improve the implant geometry, followed by automatic generation of models ready for 3-D printing. We propose a cross-case augmentation based on imperfect image registration combining cases from different datasets. We perform ablation studies regarding different augmentation strategies and compare them to other state-of-the-art methods. We evaluate the method on three datasets introduced during the AutoImplant 2021 challenge, organized jointly with the MICCAI conference. We perform the quantitative evaluation using the Dice and boundary Dice coefficients, and the Hausdorff distance. The average Dice coefficient, boundary Dice coefficient, and the 95th percentile of Hausdorff distance are 0.91, 0.94, and 1.53 mm respectively. We perform an additional qualitative evaluation by 3-D printing and visualization in mixed reality to confirm the implant's usefulness. We propose a complete pipeline that enables one to create the cranial implant model ready for 3-D printing. The described method is a greatly extended version of the method that scored 1st place in all AutoImplant 2021 challenge tasks. We freely release the source code, that together with the open datasets, makes the results fully reproducible. The automatic reconstruction of cranial defects may enable manufacturing personalized implants in a significantly shorter time, possibly allowing one to perform the 3-D printing process directly during a given intervention. Moreover, we show the usability of the defect reconstruction in mixed reality that may further reduce the surgery time.
Gated Res2Net for Multivariate Time Series Analysis
Sep 19, 2020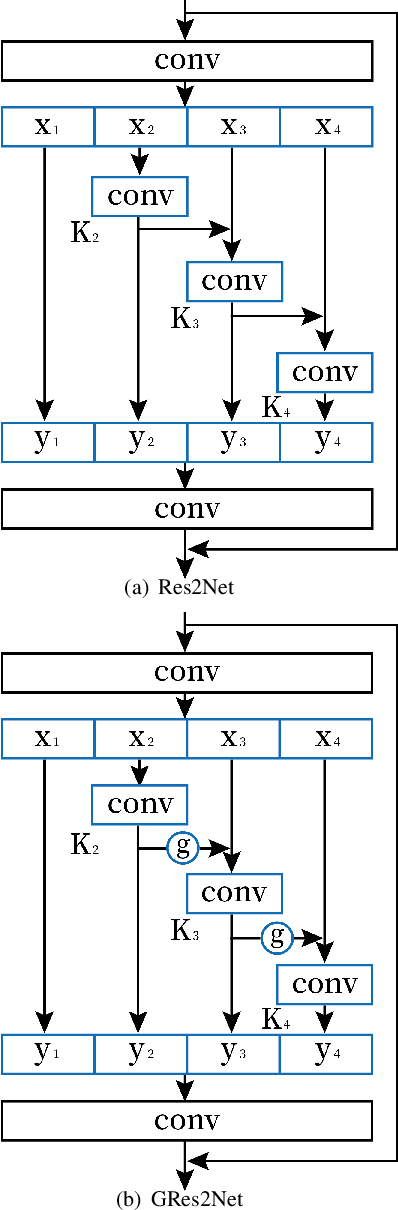
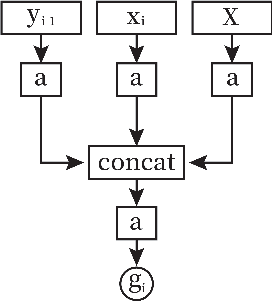
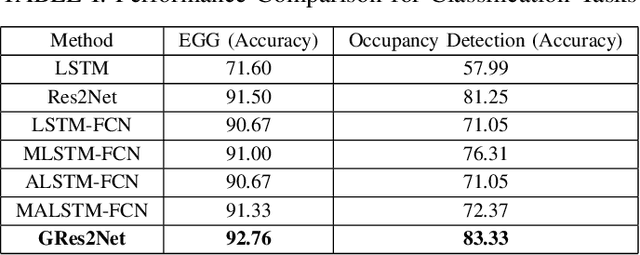
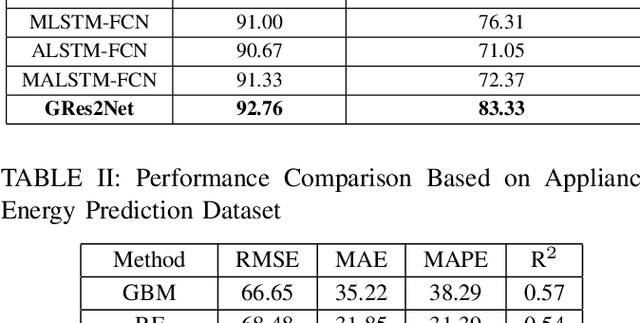
Multivariate time series analysis is an important problem in data mining because of its widespread applications. With the increase of time series data available for training, implementing deep neural networks in the field of time series analysis is becoming common. Res2Net, a recently proposed backbone, can further improve the state-of-the-art networks as it improves the multi-scale representation ability through connecting different groups of filters. However, Res2Net ignores the correlations of the feature maps and lacks the control on the information interaction process. To address that problem, in this paper, we propose a backbone convolutional neural network based on the thought of gated mechanism and Res2Net, namely Gated Res2Net (GRes2Net), for multivariate time series analysis. The hierarchical residual-like connections are influenced by gates whose values are calculated based on the original feature maps, the previous output feature maps and the next input feature maps thus considering the correlations between the feature maps more effectively. Through the utilization of gated mechanism, the network can control the process of information sending hence can better capture and utilize the both the temporal information and the correlations between the feature maps. We evaluate the GRes2Net on four multivariate time series datasets including two classification datasets and two forecasting datasets. The results demonstrate that GRes2Net have better performances over the state-of-the-art methods thus indicating the superiority
Towards Process-Oriented, Modular, and Versatile Question Generation that Meets Educational Needs
Apr 30, 2022
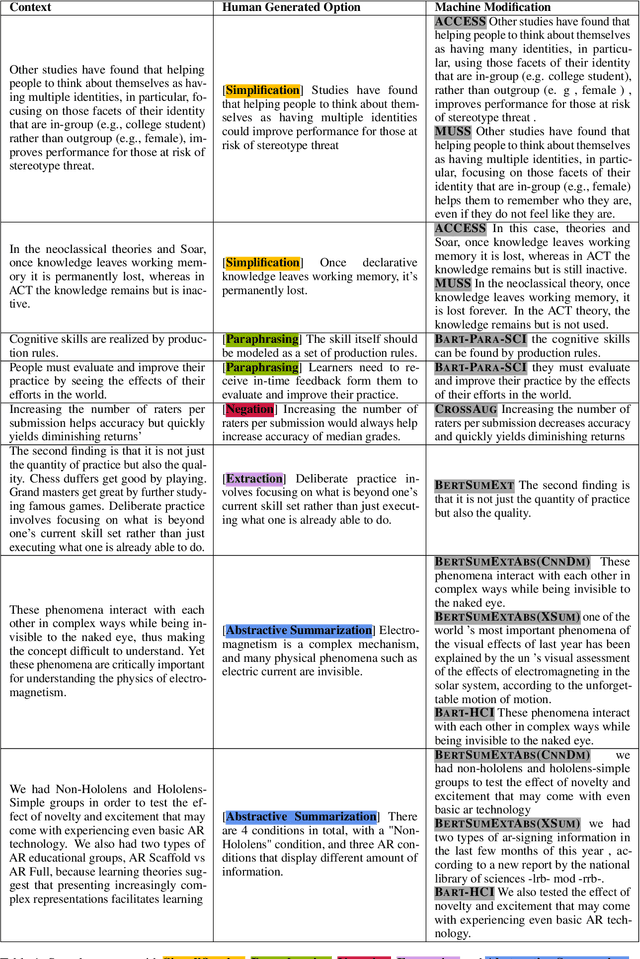
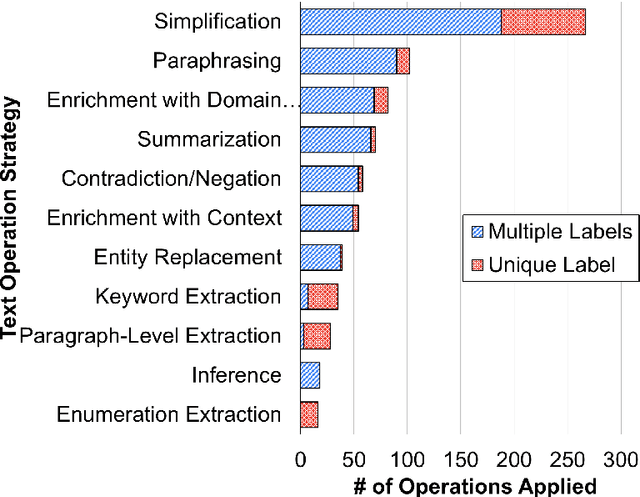
NLP-powered automatic question generation (QG) techniques carry great pedagogical potential of saving educators' time and benefiting student learning. Yet, QG systems have not been widely adopted in classrooms to date. In this work, we aim to pinpoint key impediments and investigate how to improve the usability of automatic QG techniques for educational purposes by understanding how instructors construct questions and identifying touch points to enhance the underlying NLP models. We perform an in-depth need finding study with 11 instructors across 7 different universities, and summarize their thought processes and needs when creating questions. While instructors show great interests in using NLP systems to support question design, none of them has used such tools in practice. They resort to multiple sources of information, ranging from domain knowledge to students' misconceptions, all of which missing from today's QG systems. We argue that building effective human-NLP collaborative QG systems that emphasize instructor control and explainability is imperative for real-world adoption. We call for QG systems to provide process-oriented support, use modular design, and handle diverse sources of input.
Knowledge Distillation of Russian Language Models with Reduction of Vocabulary
May 04, 2022
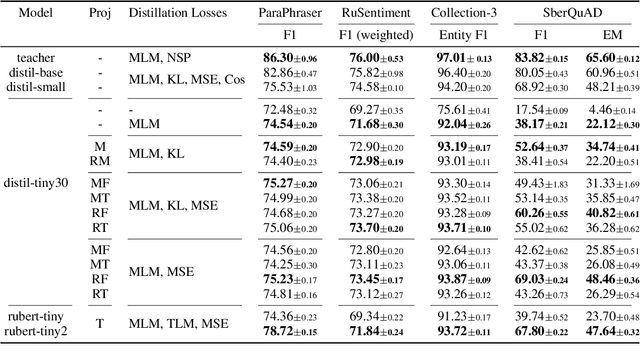

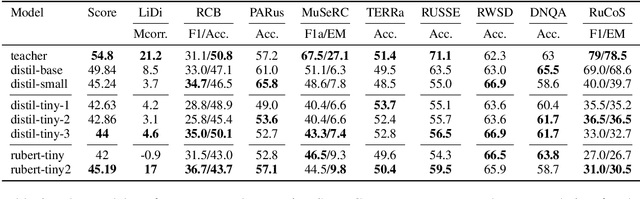
Today, transformer language models serve as a core component for majority of natural language processing tasks. Industrial application of such models requires minimization of computation time and memory footprint. Knowledge distillation is one of approaches to address this goal. Existing methods in this field are mainly focused on reducing the number of layers or dimension of embeddings/hidden representations. Alternative option is to reduce the number of tokens in vocabulary and therefore the embeddings matrix of the student model. The main problem with vocabulary minimization is mismatch between input sequences and output class distributions of a teacher and a student models. As a result, it is impossible to directly apply KL-based knowledge distillation. We propose two simple yet effective alignment techniques to make knowledge distillation to the students with reduced vocabulary. Evaluation of distilled models on a number of common benchmarks for Russian such as Russian SuperGLUE, SberQuAD, RuSentiment, ParaPhaser, Collection-3 demonstrated that our techniques allow to achieve compression from $17\times$ to $49\times$, while maintaining quality of $1.7\times$ compressed student with the full-sized vocabulary, but reduced number of Transformer layers only. We make our code and distilled models available.
Data Augmentation for Manipulation
May 11, 2022

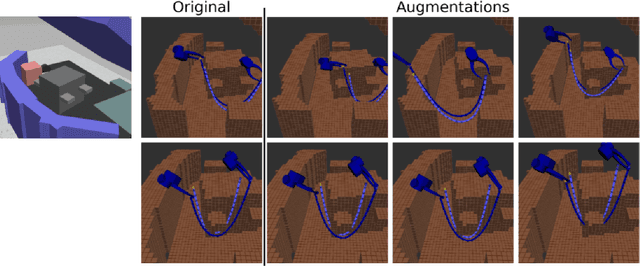
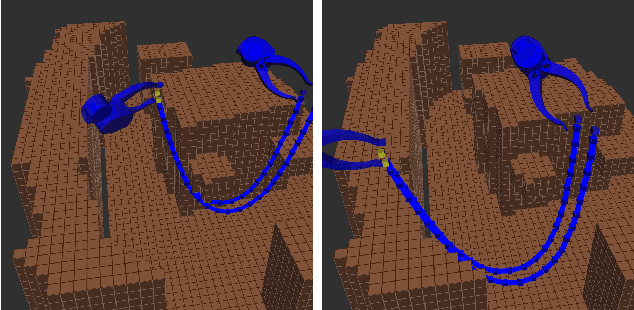
The success of deep learning depends heavily on the availability of large datasets, but in robotic manipulation there are many learning problems for which such datasets do not exist. Collecting these datasets is time-consuming and expensive, and therefore learning from small datasets is an important open problem. Within computer vision, a common approach to a lack of data is data augmentation. Data augmentation is the process of creating additional training examples by modifying existing ones. However, because the types of tasks and data differ, the methods used in computer vision cannot be easily adapted to manipulation. Therefore, we propose a data augmentation method for robotic manipulation. We argue that augmentations should be valid, relevant, and diverse. We use these principles to formalize augmentation as an optimization problem, with the objective function derived from physics and knowledge of the manipulation domain. This method applies rigid body transformations to trajectories of geometric state and action data. We test our method in two scenarios: 1) learning the dynamics of planar pushing of rigid cylinders, and 2) learning a constraint checker for rope manipulation. These two scenarios have different data and label types, yet in both scenarios, training on our augmented data significantly improves performance on downstream tasks. We also show how our augmentation method can be used on real-robot data to enable more data-efficient online learning.
Neural-MPC: Deep Learning Model Predictive Control for Quadrotors and Agile Robotic Platforms
Mar 15, 2022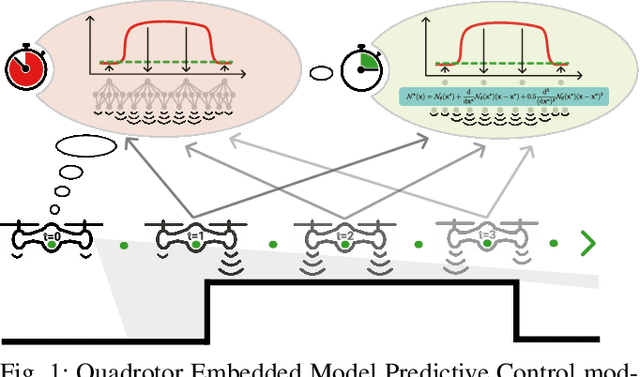
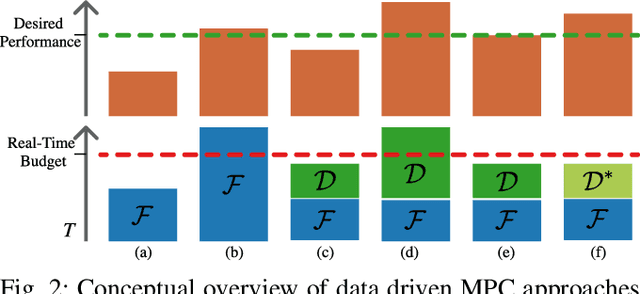
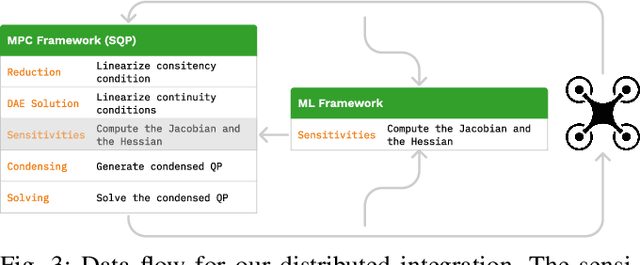
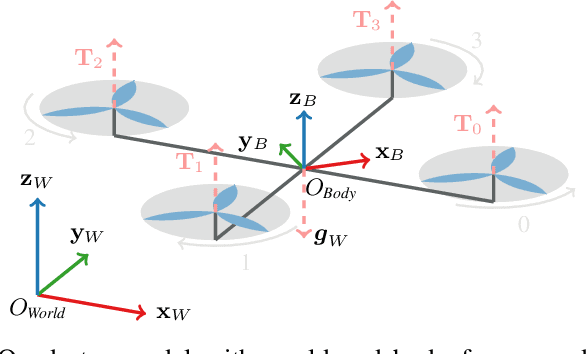
Model Predictive Control (MPC) has become a popular framework in embedded control for high-performance autonomous systems. However, to achieve good control performance using MPC, an accurate dynamics model is key. To maintain real-time operation, the dynamics models used on embedded systems have been limited to simple first-principle models, which substantially limits their representative power. In contrast, neural networks can model complex effects purely from data. In contrast to such simple models, machine learning approaches such as neural networks have been shown to accurately model even complex dynamic effects, but their large computational complexity hindered combination with fast real-time iteration loops. With this work, we present Neural-MPC, a framework to efficiently integrate large, complex neural network architectures as dynamics models within a model-predictive control pipeline. Our experiments, performed in simulation and the real world on a highly agile quadrotor platform, demonstrate up to 83% reduction in positional tracking error when compared to state-of-the-art MPC approaches without neural network dynamics.
Predicting Multi-Antenna Frequency-Selective Channels via Meta-Learned Linear Filters based on Long-Short Term Channel Decomposition
Mar 23, 2022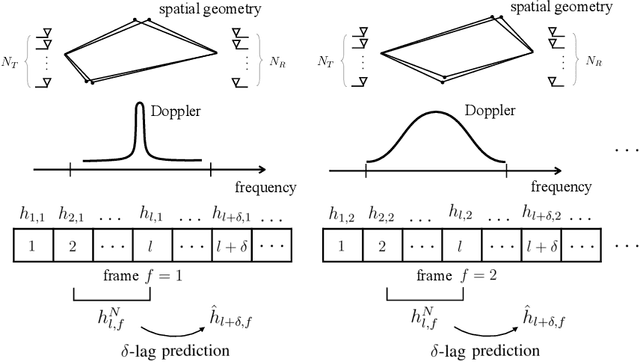
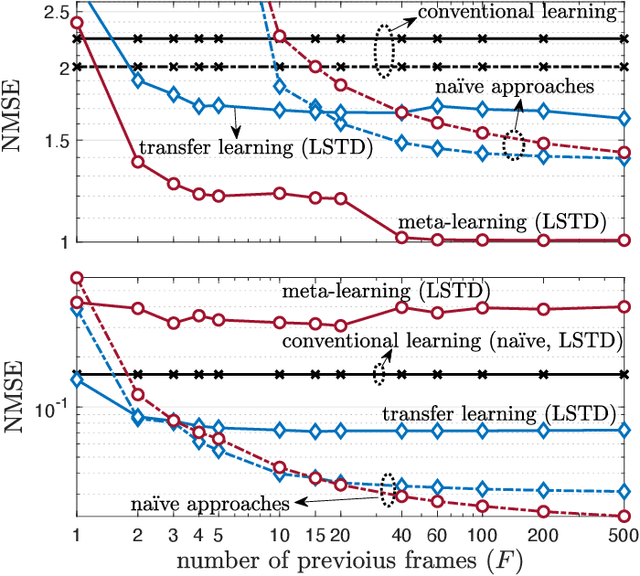
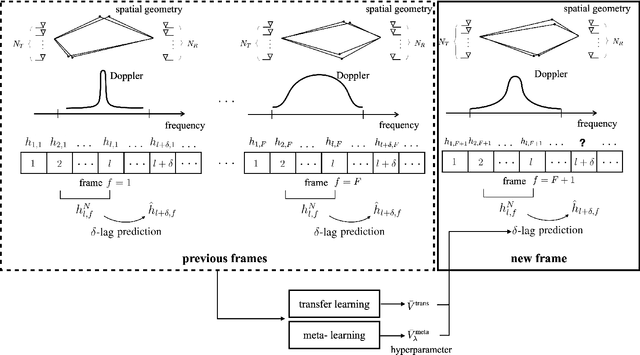
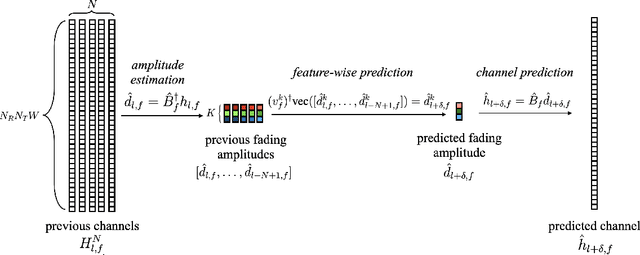
An efficient data-driven prediction strategy for multi-antenna frequency-selective channels must operate based on a small number of pilot symbols. This paper proposes novel channel prediction algorithms that address this goal by integrating transfer and meta-learning with a reduced-rank parametrization of the channel. The proposed methods optimize linear predictors by utilizing data from previous frames, which are generally characterized by distinct propagation characteristics, in order to enable fast training on the time slots of the current frame. The proposed predictors rely on a novel long-short-term decomposition (LSTD) of the linear prediction model that leverages the disaggregation of the channel into long-term space-time signatures and fading amplitudes. We first develop predictors for single-antenna frequency-flat channels based on transfer/meta-learned quadratic regularization. Then, we introduce transfer and meta-learning algorithms for LSTD-based prediction models that build on equilibrium propagation (EP) and alternating least squares (ALS). Numerical results under the 3GPP 5G standard channel model demonstrate the impact of transfer and meta-learning on reducing the number of pilots for channel prediction, as well as the merits of the proposed LSTD parametrization.
A SSIM Guided cGAN Architecture For Clinically Driven Generative Image Synthesis of Multiplexed Spatial Proteomics Channels
May 20, 2022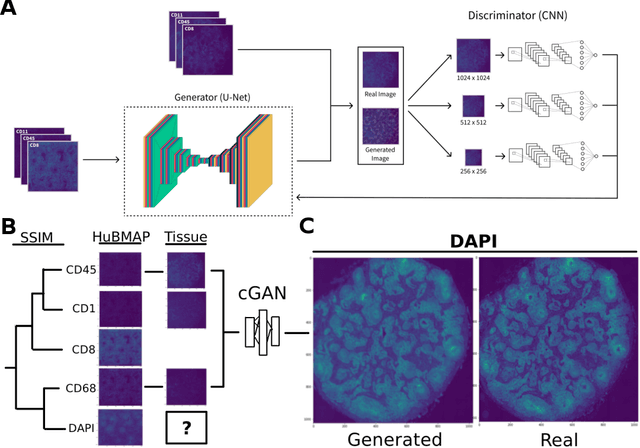


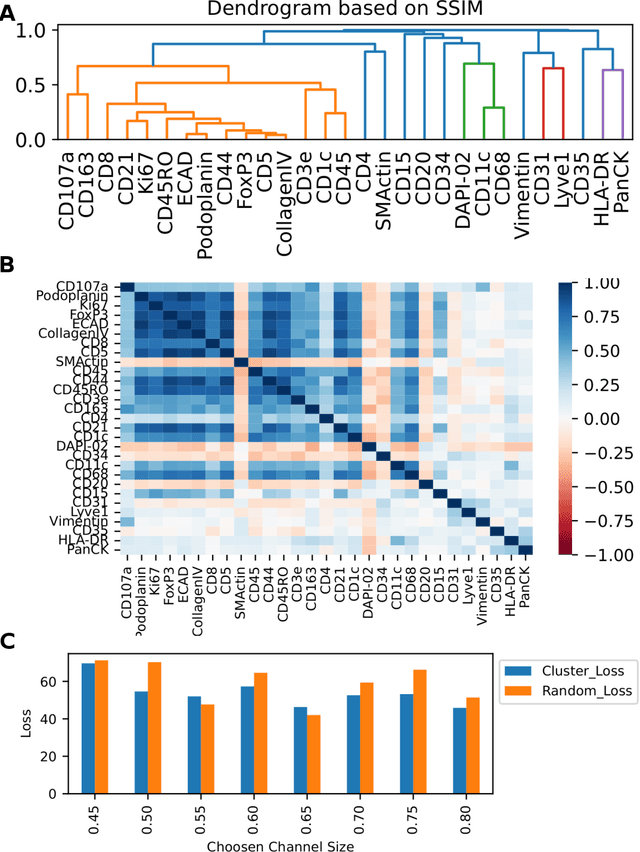
Here we present a structural similarity index measure (SSIM) guided conditional Generative Adversarial Network (cGAN) that generatively performs image-to-image (i2i) synthesis to generate photo-accurate protein channels in multiplexed spatial proteomics images. This approach can be utilized to accurately generate missing spatial proteomics channels that were not included during experimental data collection either at the bench or the clinic. Experimental spatial proteomic data from the Human BioMolecular Atlas Program (HuBMAP) was used to generate spatial representations of missing proteins through a U-Net based image synthesis pipeline. HuBMAP channels were hierarchically clustered by the (SSIM) as a heuristic to obtain the minimal set needed to recapitulate the underlying biology represented by the spatial landscape of proteins. We subsequently prove that our SSIM based architecture allows for scaling of generative image synthesis to slides with up to 100 channels, which is better than current state of the art algorithms which are limited to data with 11 channels. We validate these claims by generating a new experimental spatial proteomics data set from human lung adenocarcinoma tissue sections and show that a model trained on HuBMAP can accurately synthesize channels from our new data set. The ability to recapitulate experimental data from sparsely stained multiplexed histological slides containing spatial proteomic will have tremendous impact on medical diagnostics and drug development, and also raises important questions on the medical ethics of utilizing data produced by generative image synthesis in the clinical setting. The algorithm that we present in this paper will allow researchers and clinicians to save time and costs in proteomics based histological staining while also increasing the amount of data that they can generate through their experiments.
Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking
Mar 27, 2022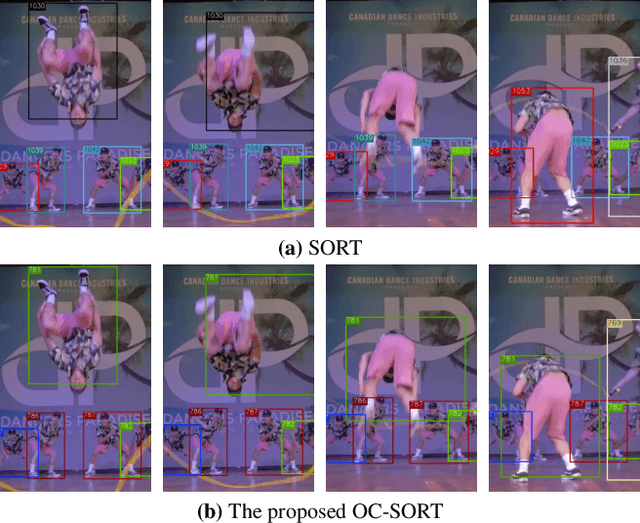



Multi-Object Tracking (MOT) has rapidly progressed with the development of object detection and re-identification. However, motion modeling, which facilitates object association by forecasting short-term trajectories with past observations, has been relatively under-explored in recent years. Current motion models in MOT typically assume that the object motion is linear in a small time window and needs continuous observations, so these methods are sensitive to occlusions and non-linear motion and require high frame-rate videos. In this work, we show that a simple motion model can obtain state-of-the-art tracking performance without other cues like appearance. We emphasize the role of "observation" when recovering tracks from being lost and reducing the error accumulated by linear motion models during the lost period. We thus name the proposed method as Observation-Centric SORT, OC-SORT for short. It remains simple, online, and real-time but improves robustness over occlusion and non-linear motion. It achieves 63.2 and 62.1 HOTA on MOT17 and MOT20, respectively, surpassing all published methods. It also sets new states of the art on KITTI Pedestrian Tracking and DanceTrack where the object motion is highly non-linear. The code and model are available at https://github.com/noahcao/OC_SORT.
WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
Mar 31, 2022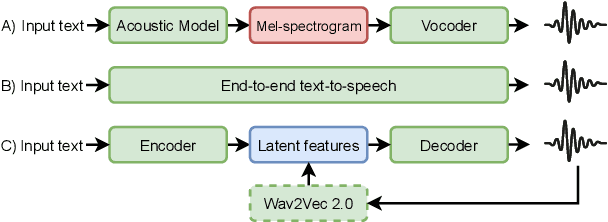

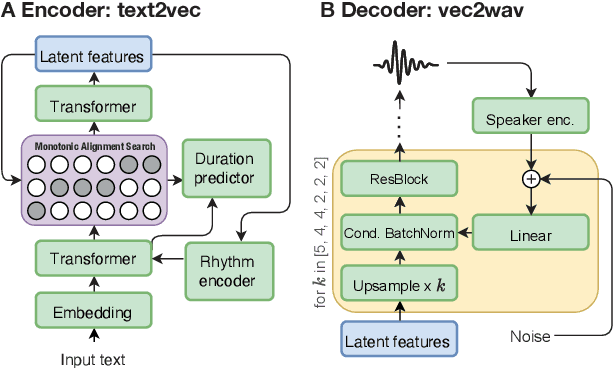
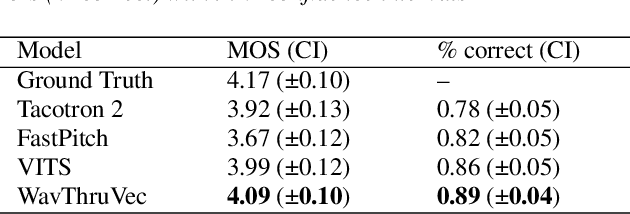
Recent advances in neural text-to-speech research have been dominated by two-stage pipelines utilizing low-level intermediate speech representation such as mel-spectrograms. However, such predetermined features are fundamentally limited, because they do not allow to exploit the full potential of a data-driven approach through learning hidden representations. For this reason, several end-to-end methods have been proposed. However, such models are harder to train and require a large number of high-quality recordings with transcriptions. Here, we propose WavThruVec - a two-stage architecture that resolves the bottleneck by using high-dimensional Wav2Vec 2.0 embeddings as intermediate speech representation. Since these hidden activations provide high-level linguistic features, they are more robust to noise. That allows us to utilize annotated speech datasets of a lower quality to train the first-stage module. At the same time, the second-stage component can be trained on large-scale untranscribed audio corpora, as Wav2Vec 2.0 embeddings are time-aligned and speaker-independent. This results in an increased generalization capability to out-of-vocabulary words, as well as to a better generalization to unseen speakers. We show that the proposed model not only matches the quality of state-of-the-art neural models, but also presents useful properties enabling tasks like voice conversion or zero-shot synthesis.