 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
L^3U-net: Low-Latency Lightweight U-net Based Image Segmentation Model for Parallel CNN Processors
Mar 30, 2022
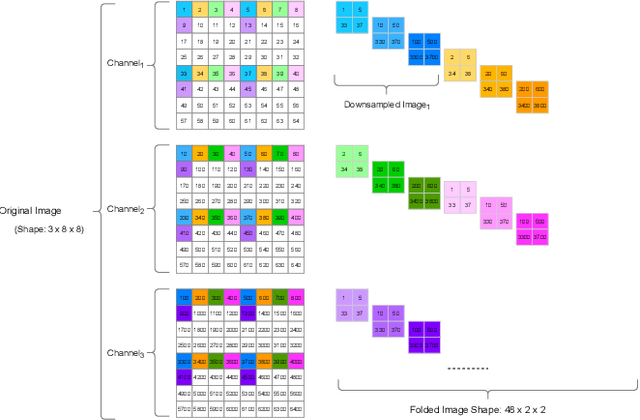
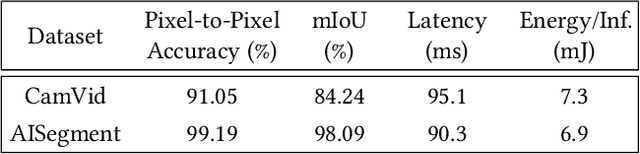
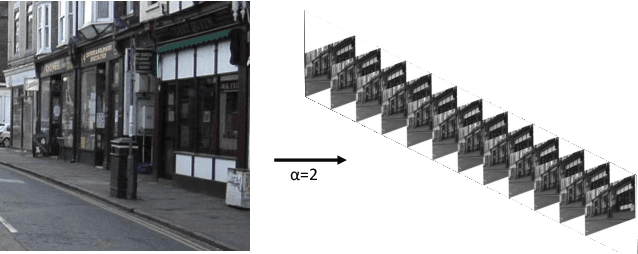
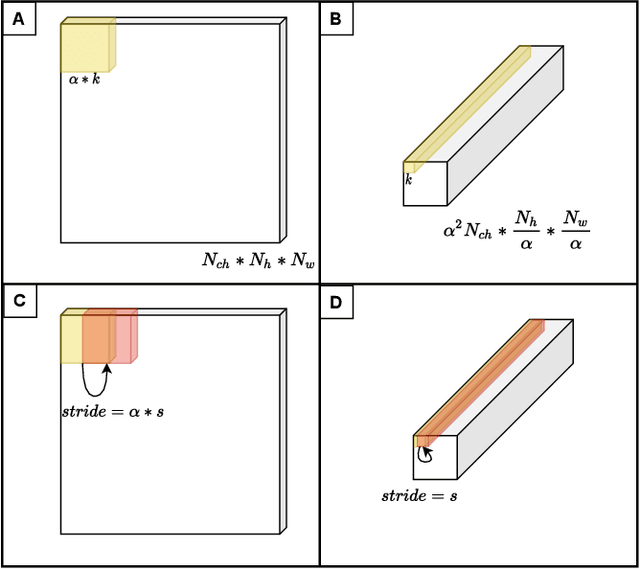
In this research, we propose a tiny image segmentation model, L^3U-net, that works on low-resource edge devices in real-time. We introduce a data folding technique that reduces inference latency by leveraging the parallel convolutional layer processing capability of the CNN accelerators. We also deploy the proposed model to such a device, MAX78000, and the results show that L^3U-net achieves more than 90% accuracy over two different segmentation datasets with 10 fps.
Physics-Aware Recurrent Convolutional (PARC) Neural Networks to Assimilate Meso-scale Reactive Mechanics of Energetic Materials
Apr 04, 2022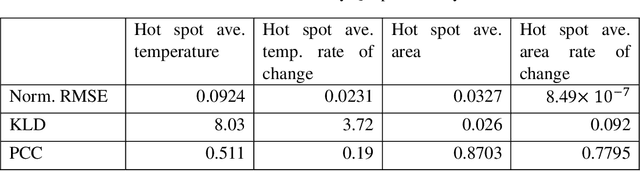
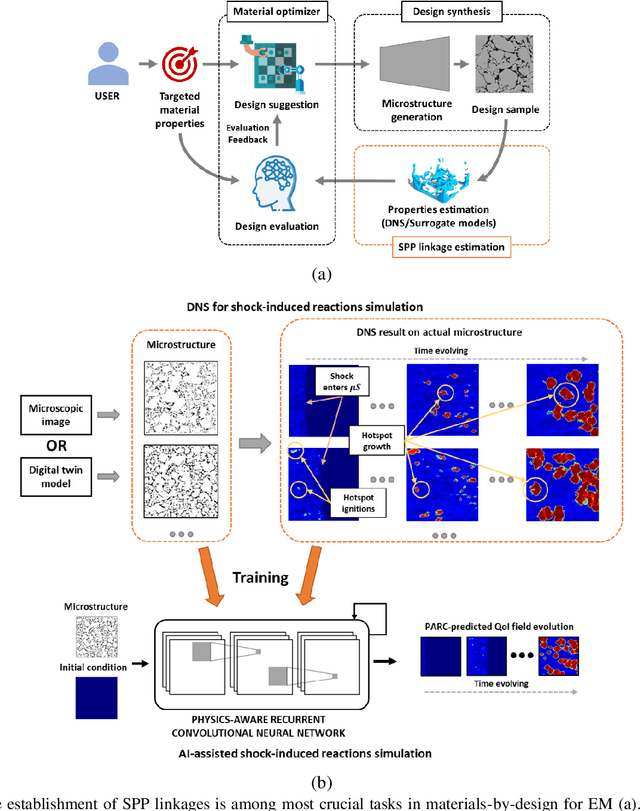

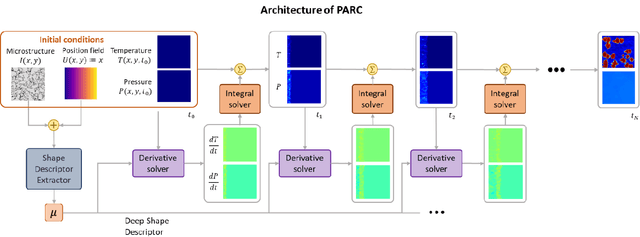
The thermomechanical properties of energetic materials (EM) are known to be a function of their microscopic structures, i.e., morphological configurations of crystals and pores. This microstructural dependency has motivated vigorous research in the EM community, seeking to engineer material microstructures with targeted properties and performance under the materials-by-design paradigm. However, establishing the complex structure-property-performance (SPP) relationships of EMs demands extensive experimental and simulation efforts, and assimilating and encapsulating these relationships in usable models is a challenge. Here, we present a novel deep learning method, Physics-Aware Recurrent Convolutional (PARC) Neural Network, that can "learn" the mesoscale thermo-mechanics of EM microstructures during the shock-to-detonation transition (SDT). We show that this new approach can produce accurate high-fidelity predictions of time-evolving temperature and pressure fields of the same quality as the state-of-the-art direct numerical simulations (DNS), despite the dramatic reduction of computing time, from hours and days on a high-performance computing cluster (HPC) to a little more than a second on a commodity laptop. We also demonstrate that PARC can provide physical insights, i.e., the artificial neurons can illuminate the underlying physics by identifying which microstructural features led to critical hotspots and what are the characteristics of "critical" versus "non-critical" microstructures. This new knowledge generated alongside the capacity to conduct high-throughput experiments will broaden our theoretical understanding of the initiation mechanisms of EM detonation, as a step towards engineering EMs with specific properties.
Understanding A Class of Decentralized and Federated Optimization Algorithms: A Multi-Rate Feedback Control Perspective
Apr 27, 2022
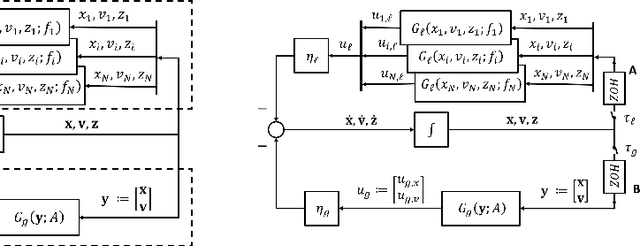
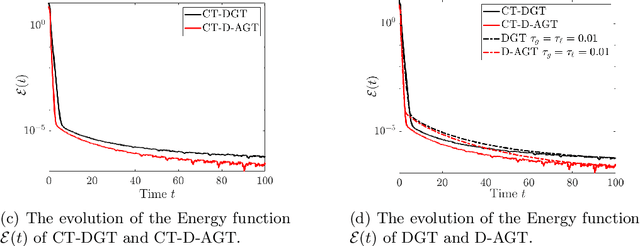
Distributed algorithms have been playing an increasingly important role in many applications such as machine learning, signal processing, and control. Significant research efforts have been devoted to developing and analyzing new algorithms for various applications. In this work, we provide a fresh perspective to understand, analyze, and design distributed optimization algorithms. Through the lens of multi-rate feedback control, we show that a wide class of distributed algorithms, including popular decentralized/federated schemes, can be viewed as discretizing a certain continuous-time feedback control system, possibly with multiple sampling rates, such as decentralized gradient descent, gradient tracking, and federated averaging. This key observation not only allows us to develop a generic framework to analyze the convergence of the entire algorithm class. More importantly, it also leads to an interesting way of designing new distributed algorithms. We develop the theory behind our framework and provide examples to highlight how the framework can be used in practice.
Myoelectric Pattern Recognition Performance Enhancement Using Nonlinear Features
Mar 28, 2022
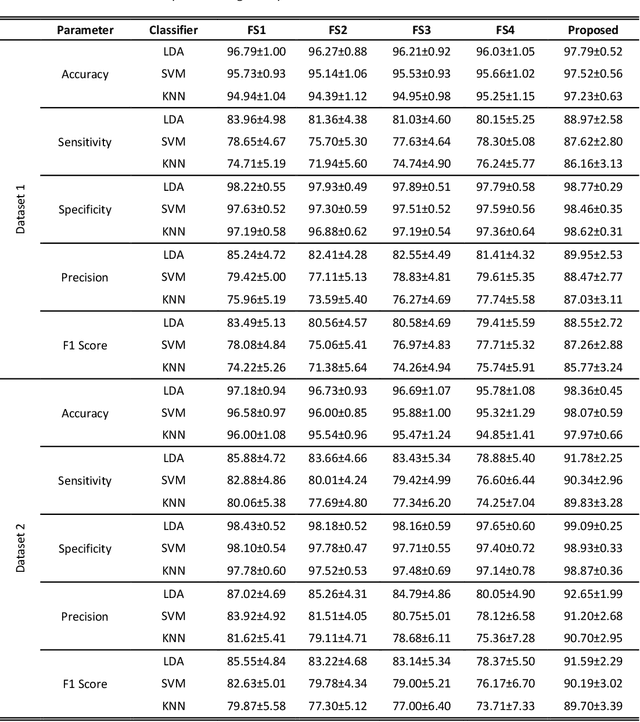
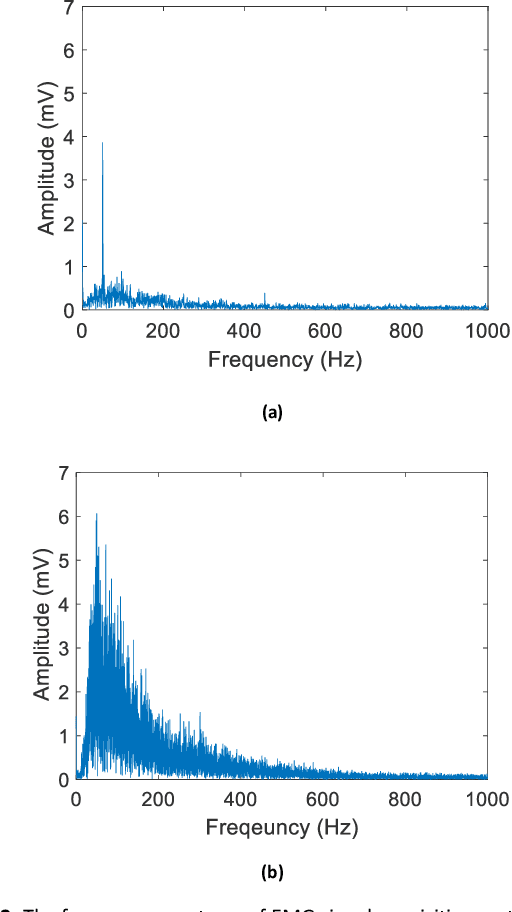
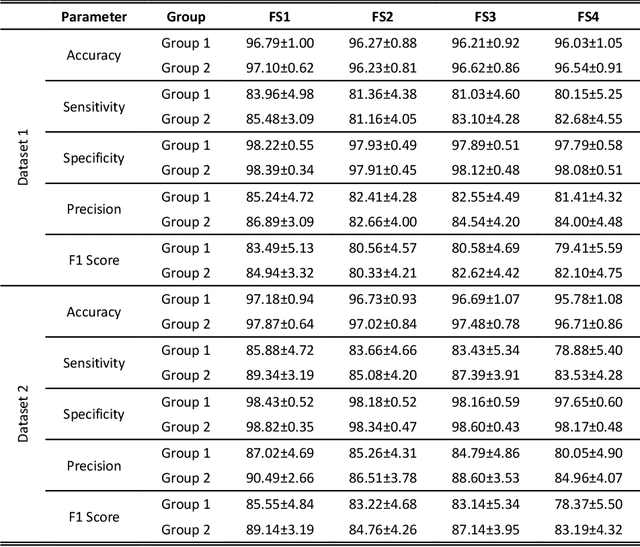
The multichannel electrode array used for electromyogram (EMG) pattern recognition provides good performance, but it has a high cost, is computationally expensive, and is inconvenient to wear. Therefore, researchers try to use as few channels as possible while maintaining improved pattern recognition performance. However, minimizing the number of channels affects the performance due to the least separable margin among the movements possessing weak signal strengths. To meet these challenges, two time-domain features based on nonlinear scaling, the log of the mean absolute value (LMAV) and the nonlinear scaled value (NSV), are proposed. In this study, we validate the proposed features on two datasets, existing four feature extraction methods, variable window size and various signal to noise ratios (SNR). In addition, we also propose a feature extraction method where the LMAV and NSV are grouped with the existing 11 time-domain features. The proposed feature extraction method enhances accuracy, sensitivity, specificity, precision, and F1 score by 1.00%, 5.01%, 0.55%, 4.71%, and 5.06% for dataset 1, and 1.18%, 5.90%, 0.66%, 5.63%, and 6.04% for dataset 2, respectively. Therefore, the experimental results strongly suggest the proposed feature extraction method, for taking a step forward with regard to improved myoelectric pattern recognition performance.
Real-time Whole-body Obstacle Avoidance for 7-DOF Redundant Manipulators
Dec 29, 2020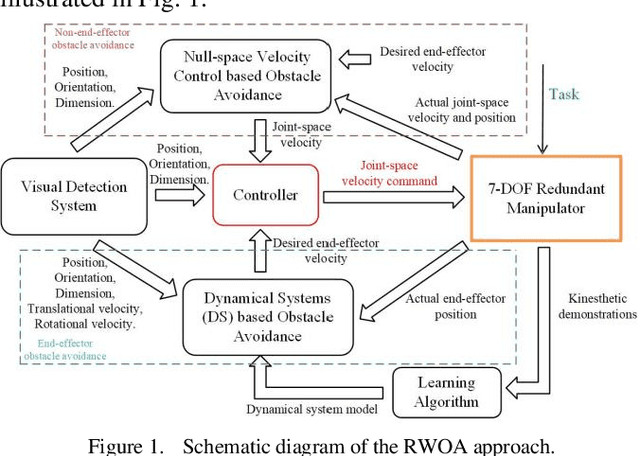
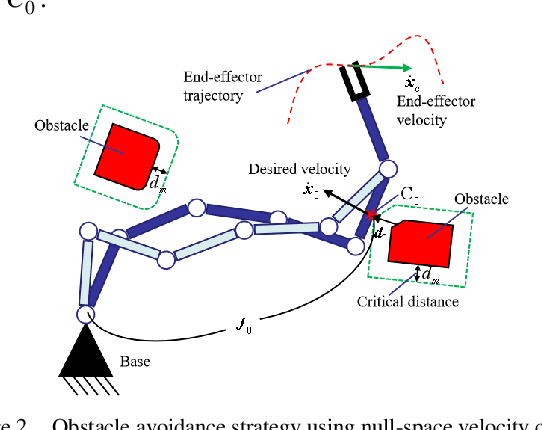
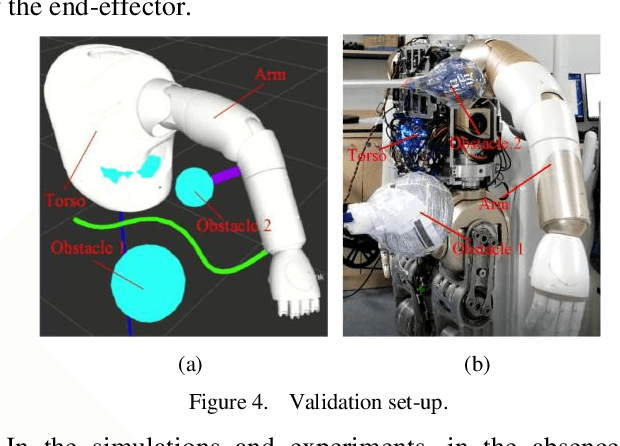
Mainly because of the heavy computational costs, the real-time whole-body obstacle avoidance for the redundant manipulators has not been well implemented. This paper presents an approach that can ensure that the whole-body of a redundant manipulator can avoid moving obstacles in real-time during the execution of a task. The manipulator is divided into end-effector and non-end-effector portion. Based on dynamical systems (DS), the real-time end-effector obstacle avoidance is obtained. Besides, the end-effector can reach the given target. By using null-space velocity control, the real-time non-endeffector obstacle avoidance is achieved. Finally, a controller is designed to ensure the whole-body obstacle avoidance. We validate the effectiveness of the method in the simulations and experiments on the 7-DOF arm of the UBTECH humanoid robot.
Predicting Training Time Without Training
Aug 28, 2020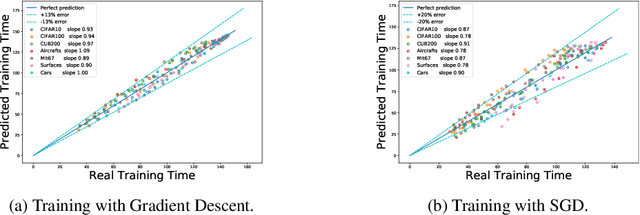
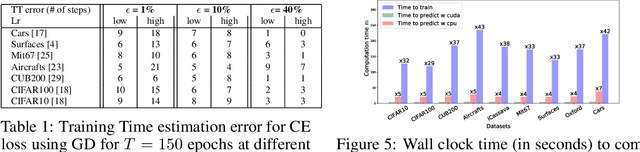
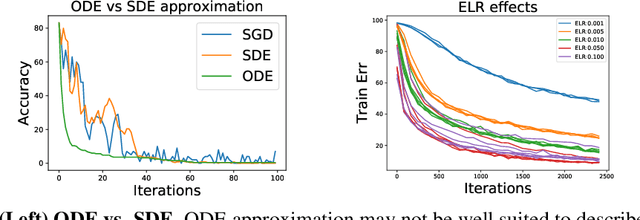
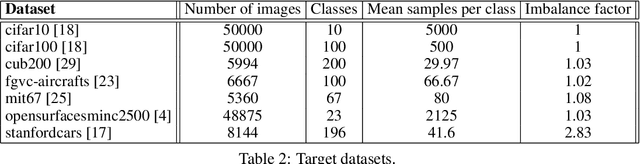
We tackle the problem of predicting the number of optimization steps that a pre-trained deep network needs to converge to a given value of the loss function. To do so, we leverage the fact that the training dynamics of a deep network during fine-tuning are well approximated by those of a linearized model. This allows us to approximate the training loss and accuracy at any point during training by solving a low-dimensional Stochastic Differential Equation (SDE) in function space. Using this result, we are able to predict the time it takes for Stochastic Gradient Descent (SGD) to fine-tune a model to a given loss without having to perform any training. In our experiments, we are able to predict training time of a ResNet within a 20% error margin on a variety of datasets and hyper-parameters, at a 30 to 45-fold reduction in cost compared to actual training. We also discuss how to further reduce the computational and memory cost of our method, and in particular we show that by exploiting the spectral properties of the gradients' matrix it is possible predict training time on a large dataset while processing only a subset of the samples.
Per-clip adaptive Lagrangian multiplier optimisation with low-resolution proxies
Apr 19, 2022This work focuses on reducing the computational cost of repeated video encodes by using a lower resolution clip as a proxy. Features extracted from the low resolution clip are used to learn an optimal lagrange multiplier for rate control on the original resolution clip. In addition to reducing the computational cost and encode time by using lower resolution clips, we also investigate the use of older, but faster codecs such as H.264 to create proxies. This work shows that the computational load is reduced by 22 times using 144p proxies. Our tests are based on the YouTube UGC dataset, hence our results are based on a practical instance of the adaptive bitrate encoding problem. Further improvements are possible, by optimising the placement and sparsity of operating points required for the rate distortion curves.
Personalized incentives as feedback design in generalized Nash equilibrium problems
Mar 24, 2022
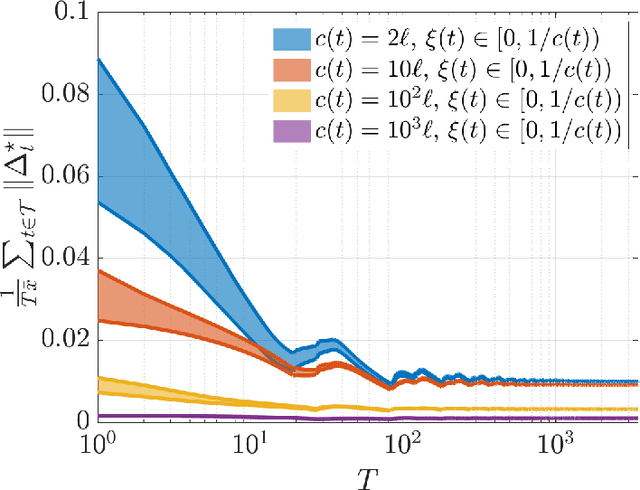
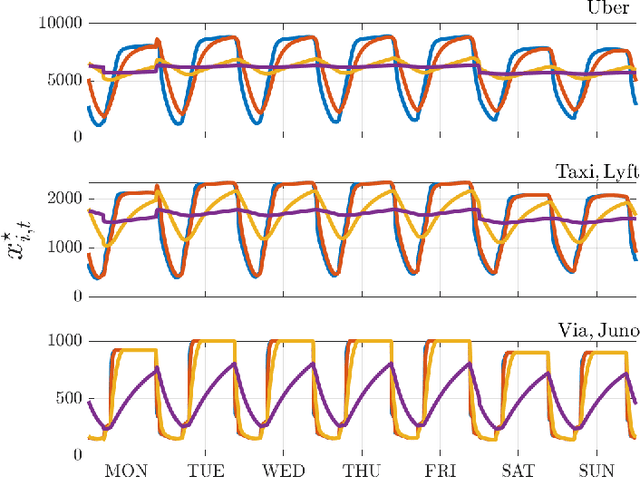
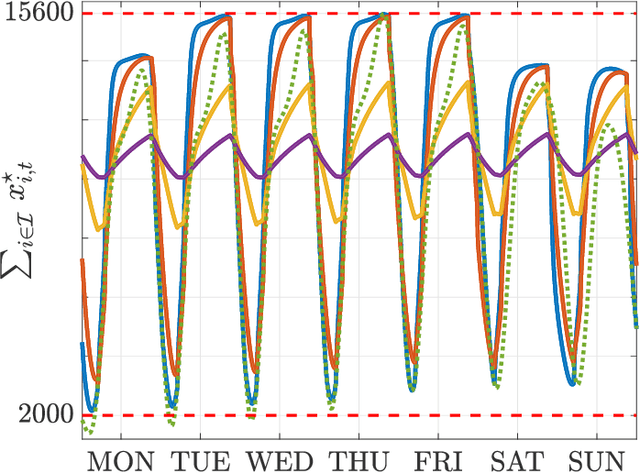
We investigate both stationary and time-varying, nonmonotone generalized Nash equilibrium problems that exhibit symmetric interactions among the agents, which are known to be potential. As may happen in practical cases, however, we envision a scenario in which the formal expression of the underlying potential function is not available, and we design a semi-decentralized Nash equilibrium seeking algorithm. In the proposed two-layer scheme, a coordinator iteratively integrates the (possibly noisy and sporadic) agents' feedback to learn the pseudo-gradients of the agents, and then design personalized incentives for them. On their side, the agents receive those personalized incentives, compute a solution to an extended game, and then return feedback measurements to the coordinator. In the stationary setting, our algorithm returns a Nash equilibrium in case the coordinator is endowed with standard learning policies, while it returns a Nash equilibrium up to a constant, yet adjustable, error in the time-varying case. As a motivating application, we consider the ridehailing service provided by several companies with mobility as a service orchestration, necessary to both handle competition among firms and avoid traffic congestion, which is also adopted to run numerical experiments verifying our results.
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Dec 17, 2020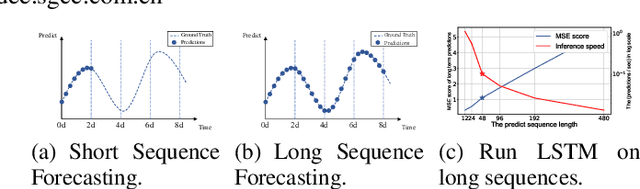
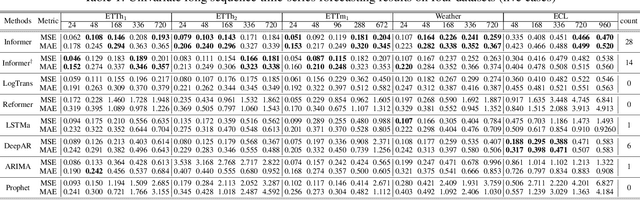
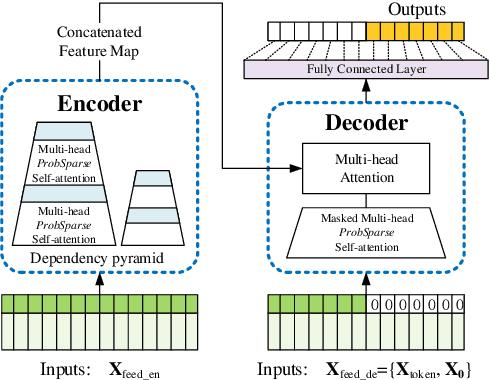
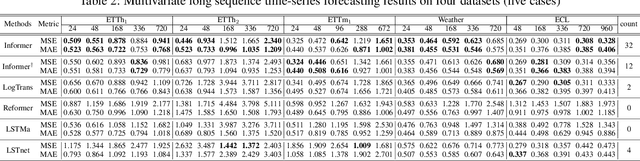
Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, such as quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a $ProbSparse$ Self-attention mechanism, which achieves $O(L \log L)$ in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.
TomoSAR-ALISTA: Efficient TomoSAR Imaging via Deep Unfolded Network
May 05, 2022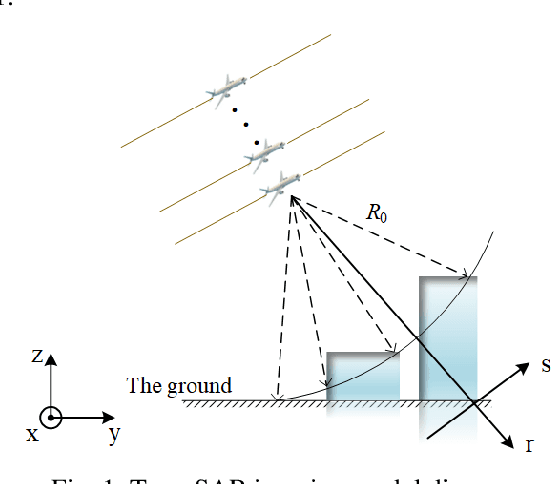

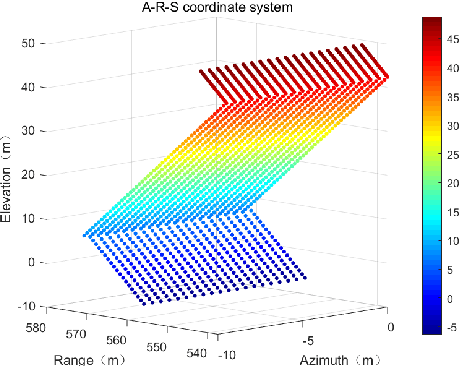
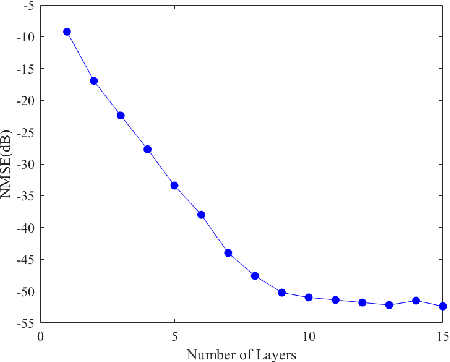
Synthetic aperture radar (SAR) tomography (TomoSAR) has attracted remarkable interest for its ability in achieving three-dimensional reconstruction along the elevation direction from multiple observations. In recent years, compressed sensing (CS) technique has been introduced into TomoSAR considering for its super-resolution ability with limited samples. Whereas, the CS-based methods suffer from several drawbacks, including weak noise resistance, high computational complexity and complex parameter fine-tuning. Among the different CS algorithms, iterative soft-thresholding algorithm (ISTA) is widely used as a robust reconstruction approach, however, the parameters in the ISTA algorithm are manually chosen, which usually requires a time-consuming fine-tuning process to achieve the best performance. Aiming at efficient TomoSAR imaging, a novel sparse unfolding network named analytic learned ISTA (ALISTA) is proposed towards the TomoSAR imaging problem in this paper, and the key parameters of ISTA are learned from training data via deep learning to avoid complex parameter fine-tuning and significantly relieves the training burden. In addition, experiments verify that it is feasible to use traditional CS algorithms as training labels, which provides a tangible supervised training method to achieve better 3D reconstruction performance even in the absence of labeled data in real applications.