 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sampling Strategies for Static Powergrid Models
Apr 19, 2022
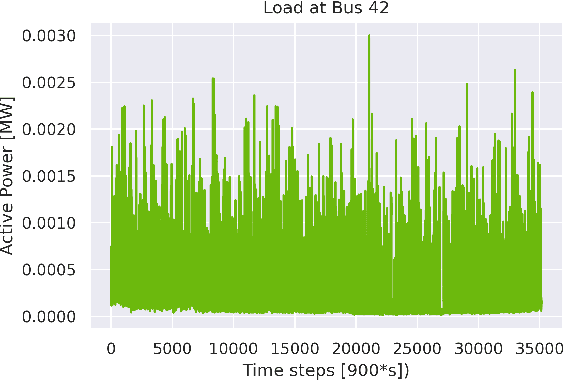
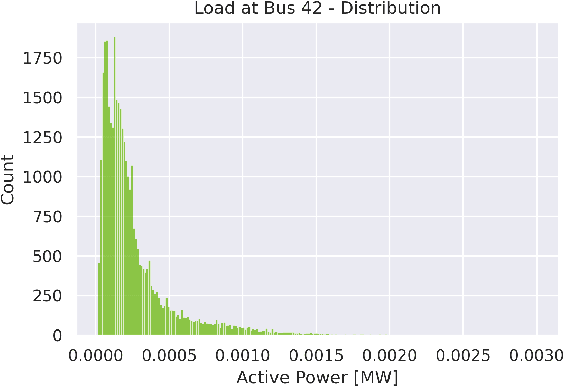
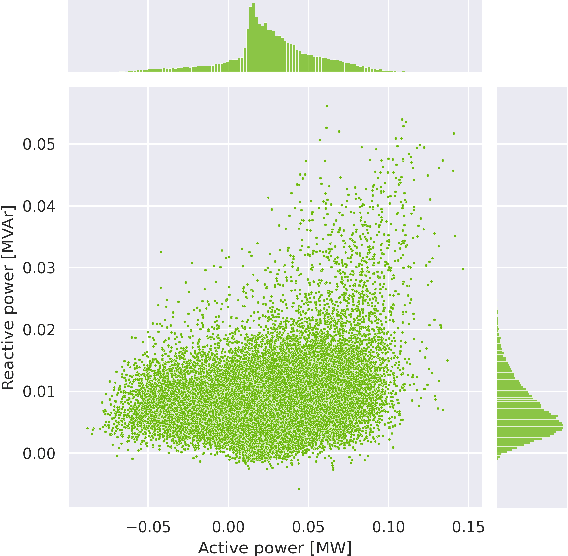
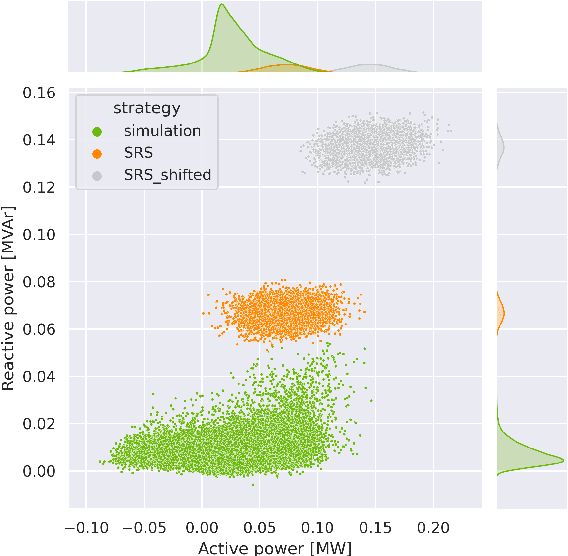
Machine learning and computational intelligence technologies gain more and more popularity as possible solution for issues related to the power grid. One of these issues, the power flow calculation, is an iterative method to compute the voltage magnitudes of the power grid's buses from power values. Machine learning and, especially, artificial neural networks were successfully used as surrogates for the power flow calculation. Artificial neural networks highly rely on the quality and size of the training data, but this aspect of the process is apparently often neglected in the works we found. However, since the availability of high quality historical data for power grids is limited, we propose the Correlation Sampling algorithm. We show that this approach is able to cover a larger area of the sampling space compared to different random sampling algorithms from the literature and a copula-based approach, while at the same time inter-dependencies of the inputs are taken into account, which, from the other algorithms, only the copula-based approach does.
An Optical Controlling Environment and Reinforcement Learning Benchmarks
Mar 23, 2022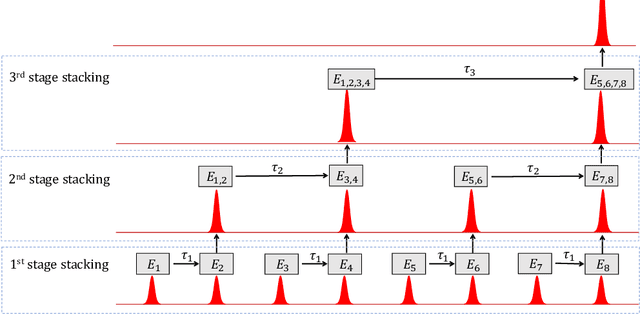
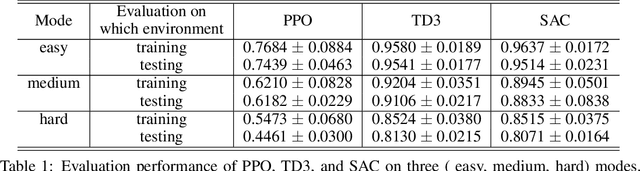
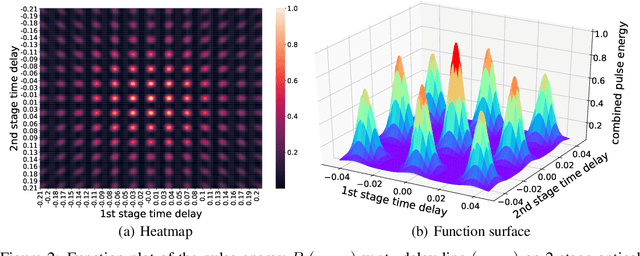
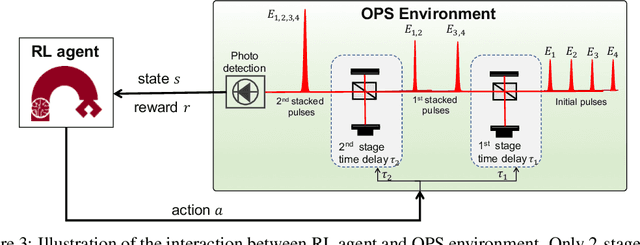
Deep reinforcement learning has the potential to address various scientific problems. In this paper, we implement an optics simulation environment for reinforcement learning based controllers. The environment incorporates nonconvex and nonlinear optical phenomena as well as more realistic time-dependent noise. Then we provide the benchmark results of several state-of-the-art reinforcement learning algorithms on the proposed simulation environment. In the end, we discuss the difficulty of controlling the real-world optical environment with reinforcement learning algorithms.
`Next Generation' Reservoir Computing: an Empirical Data-Driven Expression of Dynamical Equations in Time-Stepping Form
Jan 13, 2022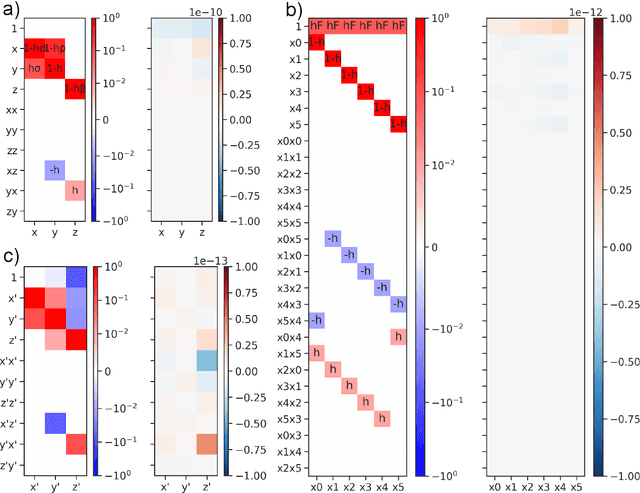

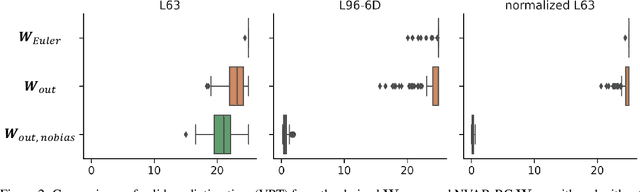
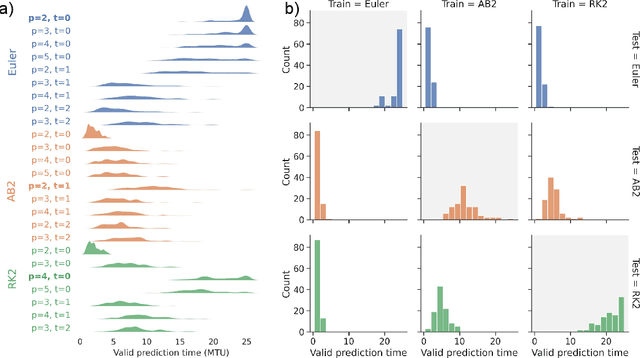
Next generation reservoir computing based on nonlinear vector autoregression (NVAR) is applied to emulate simple dynamical system models and compared to numerical integration schemes such as Euler and the $2^\text{nd}$ order Runge-Kutta. It is shown that the NVAR emulator can be interpreted as a data-driven method used to recover the numerical integration scheme that produced the data. It is also shown that the approach can be extended to produce high-order numerical schemes directly from data. The impacts of the presence of noise and temporal sparsity in the training set is further examined to gauge the potential use of this method for more realistic applications.
Where Was COVID-19 First Discovered? Designing a Question-Answering System for Pandemic Situations
Apr 19, 2022

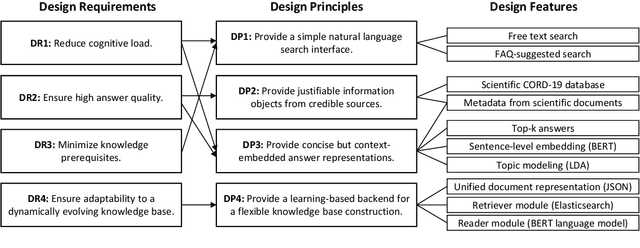

The COVID-19 pandemic is accompanied by a massive "infodemic" that makes it hard to identify concise and credible information for COVID-19-related questions, like incubation time, infection rates, or the effectiveness of vaccines. As a novel solution, our paper is concerned with designing a question-answering system based on modern technologies from natural language processing to overcome information overload and misinformation in pandemic situations. To carry out our research, we followed a design science research approach and applied Ingwersen's cognitive model of information retrieval interaction to inform our design process from a socio-technical lens. On this basis, we derived prescriptive design knowledge in terms of design requirements and design principles, which we translated into the construction of a prototypical instantiation. Our implementation is based on the comprehensive CORD-19 dataset, and we demonstrate our artifact's usefulness by evaluating its answer quality based on a sample of COVID-19 questions labeled by biomedical experts.
Shape-Aware Monocular 3D Object Detection
Apr 19, 2022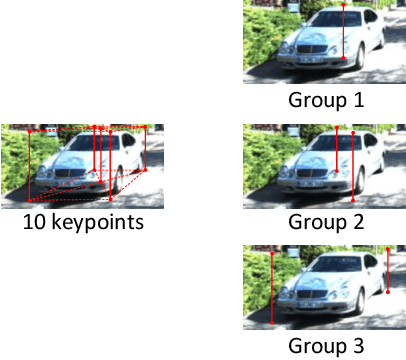

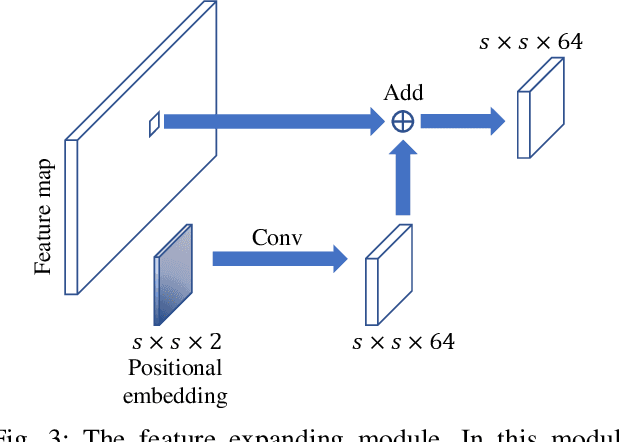
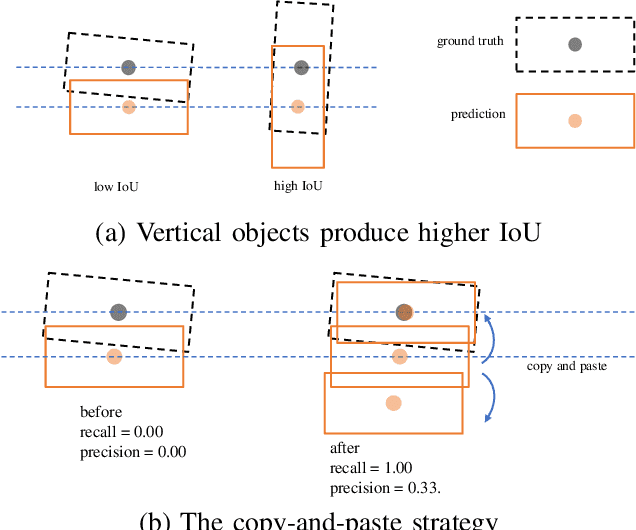
The detection of 3D objects through a single perspective camera is a challenging issue. The anchor-free and keypoint-based models receive increasing attention recently due to their effectiveness and simplicity. However, most of these methods are vulnerable to occluded and truncated objects. In this paper, a single-stage monocular 3D object detection model is proposed. An instance-segmentation head is integrated into the model training, which allows the model to be aware of the visible shape of a target object. The detection largely avoids interference from irrelevant regions surrounding the target objects. In addition, we also reveal that the popular IoU-based evaluation metrics, which were originally designed for evaluating stereo or LiDAR-based detection methods, are insensitive to the improvement of monocular 3D object detection algorithms. A novel evaluation metric, namely average depth similarity (ADS) is proposed for the monocular 3D object detection models. Our method outperforms the baseline on both the popular and the proposed evaluation metrics while maintaining real-time efficiency.
Adversarial Training for High-Stakes Reliability
May 04, 2022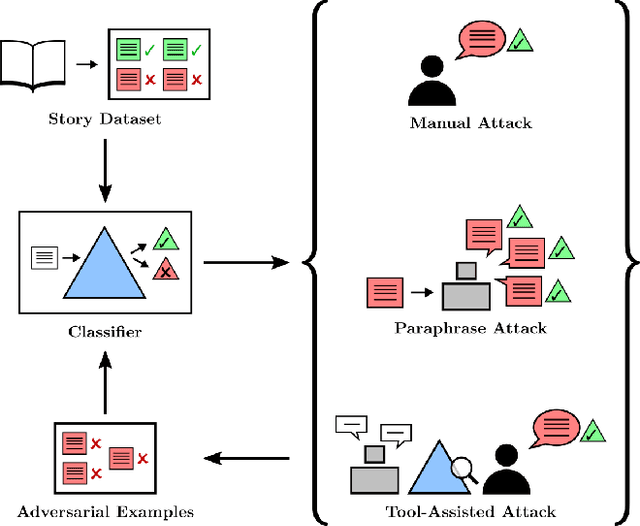
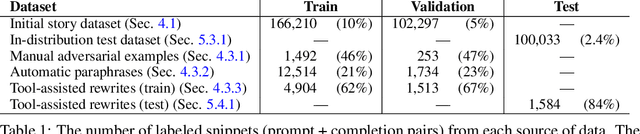


In the future, powerful AI systems may be deployed in high-stakes settings, where a single failure could be catastrophic. One technique for improving AI safety in high-stakes settings is adversarial training, which uses an adversary to generate examples to train on in order to achieve better worst-case performance. In this work, we used a language generation task as a testbed for achieving high reliability through adversarial training. We created a series of adversarial training techniques -- including a tool that assists human adversaries -- to find and eliminate failures in a classifier that filters text completions suggested by a generator. In our simple "avoid injuries" task, we determined that we can set very conservative classifier thresholds without significantly impacting the quality of the filtered outputs. With our chosen thresholds, filtering with our baseline classifier decreases the rate of unsafe completions from about 2.4% to 0.003% on in-distribution data, which is near the limit of our ability to measure. We found that adversarial training significantly increased robustness to the adversarial attacks that we trained on, without affecting in-distribution performance. We hope to see further work in the high-stakes reliability setting, including more powerful tools for enhancing human adversaries and better ways to measure high levels of reliability, until we can confidently rule out the possibility of catastrophic deployment-time failures of powerful models.
HRTF measurement for accurate sound localization cues
Apr 06, 2022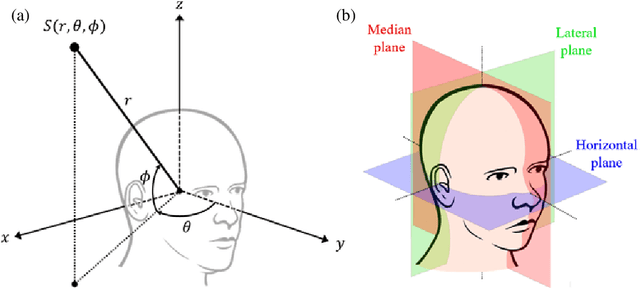
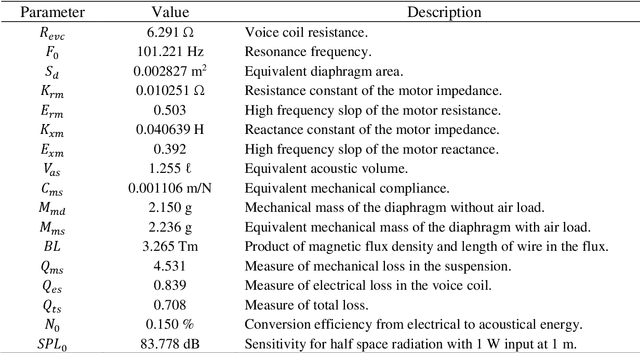
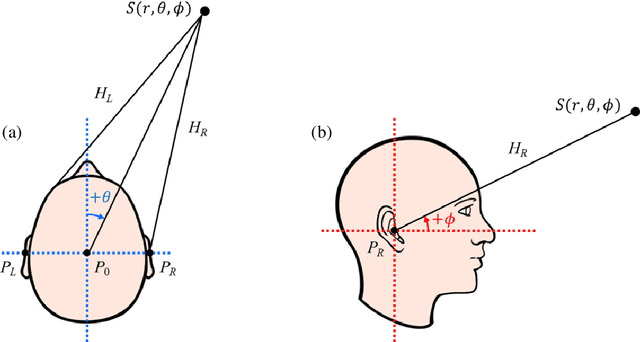
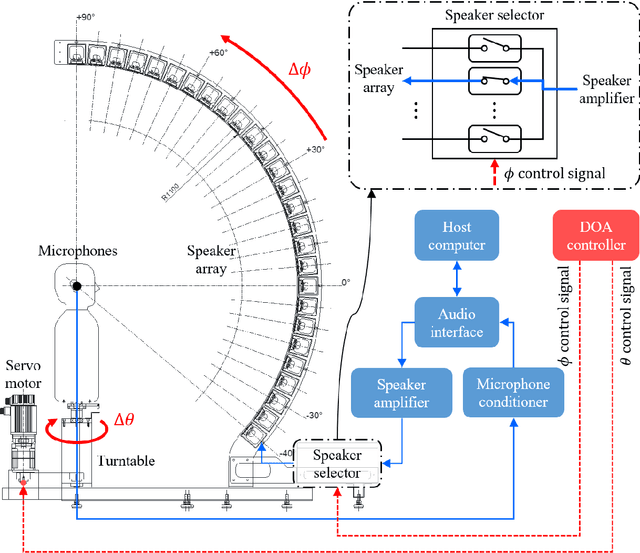
A new database of head-related transfer functions (HRTFs) for accurate sound source localization is presented through precise measurement and post-processing in terms of improved frequency bandwidth and causality of head-related impulse responses (HRIRs) for accurate spectral cue (SC) and interaural time difference (ITD), respectively. The improvement effects of the proposed methods on binaural sound localization cues were investigated. To achieve sufficient frequency bandwidth with a single source, a one-way sealed speaker module was designed to obtain wide band frequency response based on electro-acoustics, whereas most existing HRTF databases rely on a two-way vented loudspeaker that has multiple sources. The origin transfer function at the head center was obtained by the proposed measurement scheme using a 0 degree on-axis microphone to ensure accurate spectral cue pattern of HRTFs, whereas in the previous measurements with a 90 degree off-axis microphone, the magnitude response of the origin transfer function fluctuated and decreased with increasing frequency, causing erroneous SCs of HRTFs. To prevent discontinuity of ITD due to non-causality of ipsilateral HRTFs, obtained HRIRs were circularly shifted by time delay considering the head radius of the measurement subject. Finally, various sound localization cues such as ITD, interaural level difference (ILD), SC, and horizontal plane directivity (HPD) were derived from the presented HRTFs, and improvements on binaural sound localization cues were examined. As a result, accurate SC patterns of HRTFs were confirmed through the proposed measurement scheme using the 0 degree on-axis microphone, and continuous ITD patterns were obtained due to the non-causality compensation. Source codes and presented HRTF database are available to relevant research groups at GitHub (https://github.com/han-saram/HRTF-HATS-KAIST).
POMDPs in Continuous Time and Discrete Spaces
Oct 26, 2020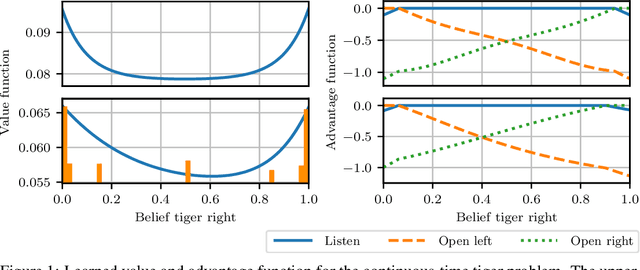
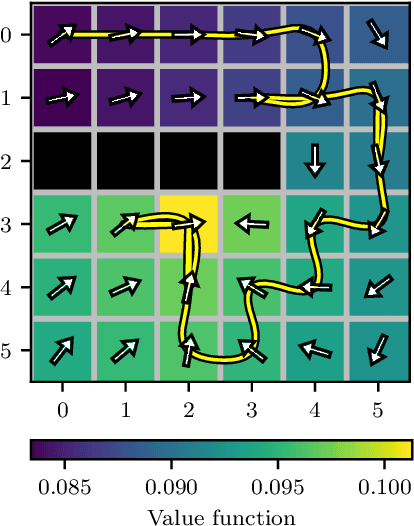
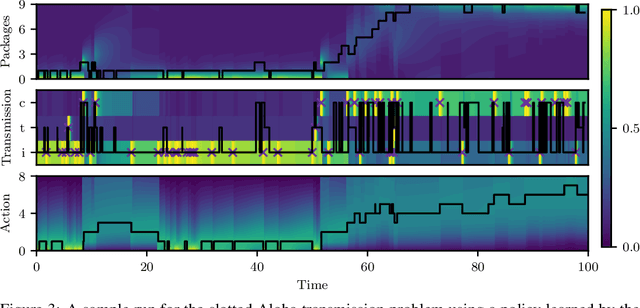
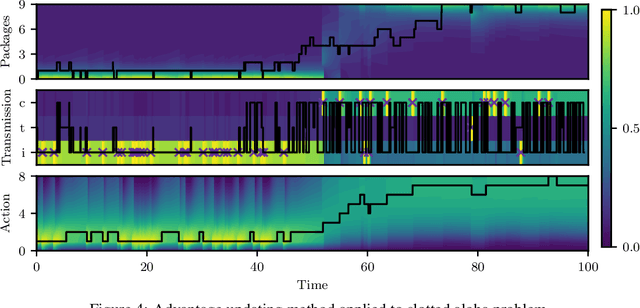
Many processes, such as discrete event systems in engineering or population dynamics in biology, evolve in discrete space and continuous time. We consider the problem of optimal decision making in such discrete state and action space systems under partial observability. This places our work at the intersection of optimal filtering and optimal control. At the current state of research, a mathematical description for simultaneous decision making and filtering in continuous time with finite state and action spaces is still missing. In this paper, we give a mathematical description of a continuous-time partial observable Markov decision process (POMDP). By leveraging optimal filtering theory we derive a Hamilton-Jacobi-Bellman (HJB) type equation that characterizes the optimal solution. Using techniques from deep learning we approximately solve the resulting partial integro-differential equation. We present (i) an approach solving the decision problem offline by learning an approximation of the value function and (ii) an online algorithm which provides a solution in belief space using deep reinforcement learning. We show the applicability on a set of toy examples which pave the way for future methods providing solutions for high dimensional problems.
Meta-path Analysis on Spatio-Temporal Graphs for Pedestrian Trajectory Prediction
Feb 27, 2022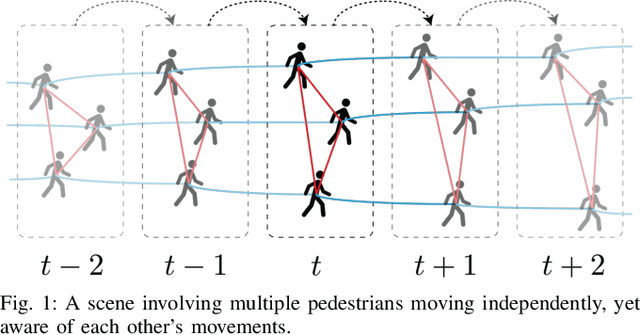
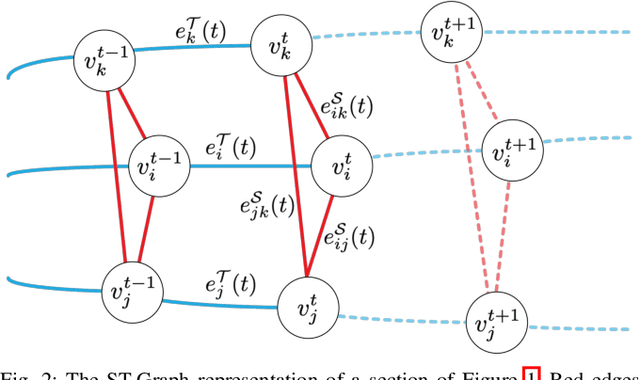
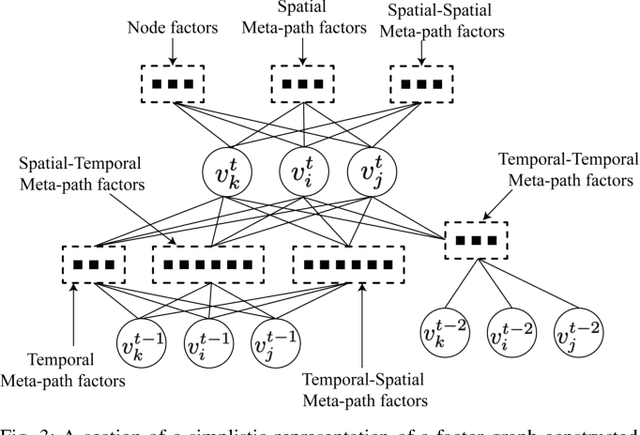
Spatio-temporal graphs (ST-graphs) have been used to model time series tasks such as traffic forecasting, human motion modeling, and action recognition. The high-level structure and corresponding features from ST-graphs have led to improved performance over traditional architectures. However, current methods tend to be limited by simple features, despite the rich information provided by the full graph structure, which leads to inefficiencies and suboptimal performance in downstream tasks. We propose the use of features derived from meta-paths, walks across different types of edges, in ST-graphs to improve the performance of Structural Recurrent Neural Network. In this paper, we present the Meta-path Enhanced Structural Recurrent Neural Network (MESRNN), a generic framework that can be applied to any spatio-temporal task in a simple and scalable manner. We employ MESRNN for pedestrian trajectory prediction, utilizing these meta-path based features to capture the relationships between the trajectories of pedestrians at different points in time and space. We compare our MESRNN against state-of-the-art ST-graph methods on standard datasets to show the performance boost provided by meta-path information. The proposed model consistently outperforms the baselines in trajectory prediction over long time horizons by over 32\%, and produces more socially compliant trajectories in dense crowds. For more information please refer to the project website at https://sites.google.com/illinois.edu/mesrnn/home.
ULF: Unsupervised Labeling Function Correction using Cross-Validation for Weak Supervision
Apr 14, 2022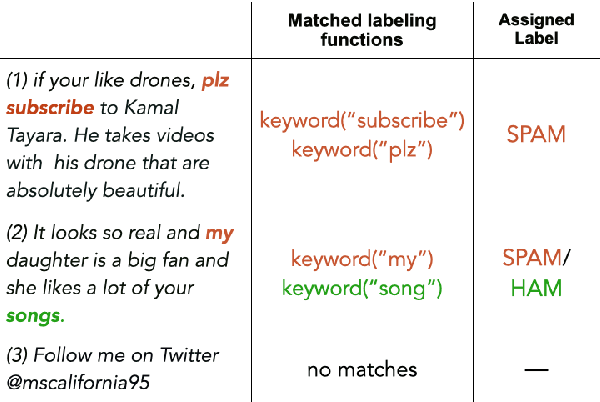
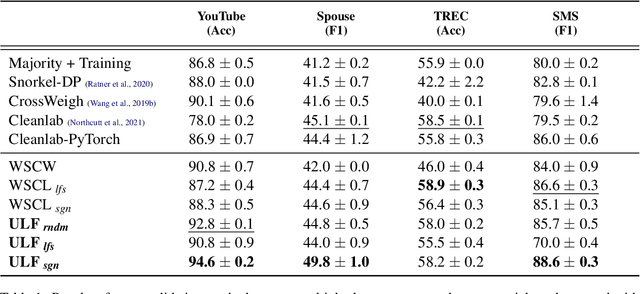
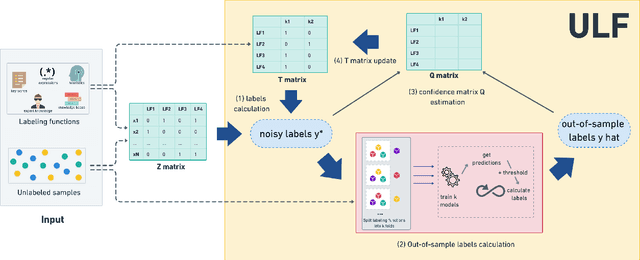

A way to overcome expensive and time-consuming manual data labeling is weak supervision - automatic annotation of data samples via a predefined set of labeling functions (LFs), rule-based mechanisms that generate potentially erroneous labels. In this work, we investigate noise reduction techniques for weak supervision based on the principle of k-fold cross-validation. In particular, we extend two frameworks for detecting the erroneous samples in manually annotated data to the weakly supervised setting. Our methods profit from leveraging the information about matching LFs and detect noisy samples more accurately. We also introduce a new algorithm for denoising the weakly annotated data called ULF, that refines the allocation of LFs to classes by estimating the reliable LFs-to-classes joint matrix. Evaluation on several datasets shows that ULF successfully improves weakly supervised learning without using any manually labeled data.