 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PreMovNet: Pre-Movement EEG-based Hand Kinematics Estimation for Grasp and Lift task
May 02, 2022
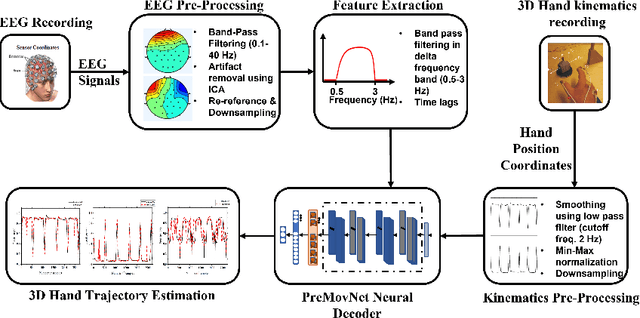
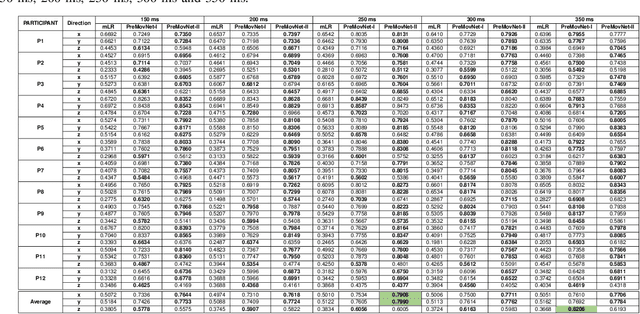
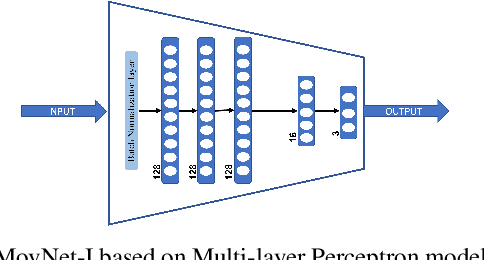

Kinematics decoding from brain activity helps in developing rehabilitation or power-augmenting brain-computer interface devices. Low-frequency signals recorded from non-invasive electroencephalography (EEG) are associated with the neural motor correlation utilised for motor trajectory decoding (MTD). In this communication, the ability to decode motor kinematics trajectory from pre-movement delta-band (0.5-3 Hz) EEG is investigated for the healthy participants. In particular, two deep learning-based neural decoders called PreMovNet-I and PreMovNet-II, are proposed that make use of motor-related neural information existing in the pre-movement EEG data. EEG data segments with various time lags of 150 ms, 200 ms, 250 ms, 300 ms, and 350 ms before the movement onset are utilised for the same. The MTD is presented for grasp-and-lift task (WAY-EEG-GAL dataset) using EEG with the various lags taken as input to the neural decoders. The performance of the proposed decoders are compared with the state-of-the-art multi-variable linear regression (mLR) model. Pearson correlation coefficient and hand trajectory are utilised as performance metric. The results demonstrate the viability of decoding 3D hand kinematics using pre-movement EEG data, enabling better control of BCI-based external devices such as exoskeleton/exosuit.
Disaster Tweets Classification using BERT-Based Language Model
Jan 31, 2022
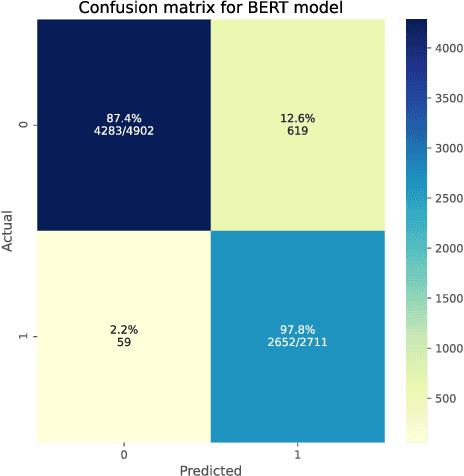
Social networking services have became an important communication channel in time of emergency. The aim of this study is to create a machine learning language model that is able to investigate if a person or area was in danger or not. The ubiquitousness of smartphones enables people to announce an emergency they are observing in real-time. Because of this, more agencies are interested in programmatically monitoring Twitter (i.e. disaster relief organizations and news agencies). Design a language model that is able to understand and acknowledge when a disaster is happening based on the social network posts will become more and more necessary over time.
FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in Context
Mar 04, 2022

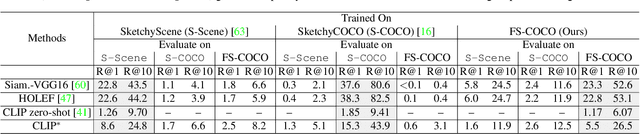
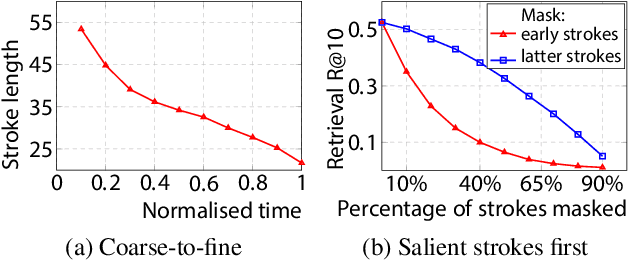
We advance sketch research to scenes with the first dataset of freehand scene sketches, FS-COCO. With practical applications in mind, we collect sketches that convey well scene content but can be sketched within a few minutes by a person with any sketching skills. Our dataset comprises 10,000 freehand scene vector sketches with per point space-time information by 100 non-expert individuals, offering both object- and scene-level abstraction. Each sketch is augmented with its text description. Using our dataset, we study for the first time the problem of the fine-grained image retrieval from freehand scene sketches and sketch captions. We draw insights on (i) Scene salience encoded in sketches with strokes temporal order; (ii) The retrieval performance accuracy from scene sketches against image captions; (iii) Complementarity of information in sketches and image captions, as well as the potential benefit of combining the two modalities. In addition, we propose new solutions enabled by our dataset (i) We adopt meta-learning to show how the retrieval model can be fine-tuned to a new user style given just a small set of sketches, (ii) We extend a popular vector sketch LSTM-based encoder to handle sketches with larger complexity than was supported by previous work. Namely, we propose a hierarchical sketch decoder, which we leverage at a sketch-specific "pretext" task. Our dataset enables for the first time research on freehand scene sketch understanding and its practical applications.
Anomaly Detection of Time Series with Smoothness-Inducing Sequential Variational Auto-Encoder
Feb 02, 2021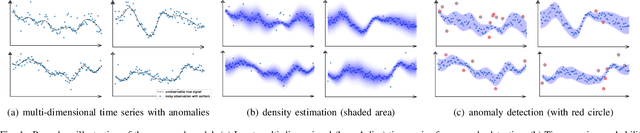
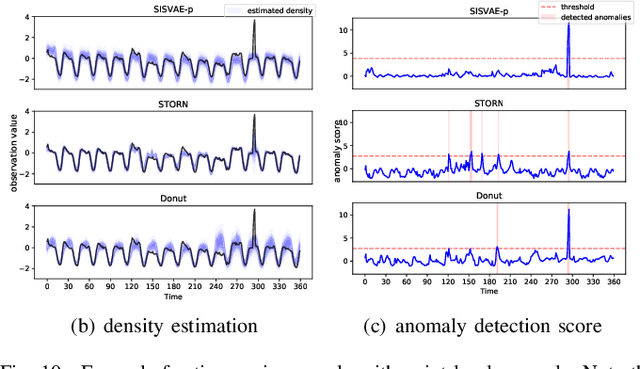
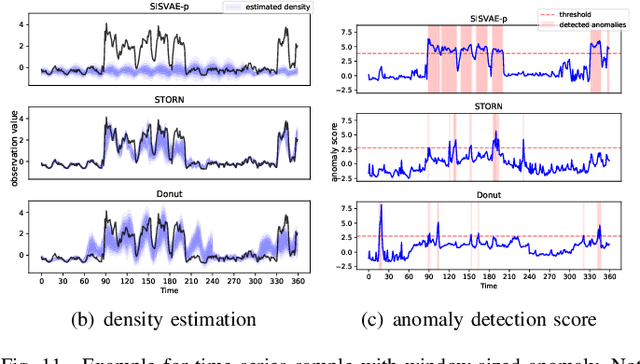
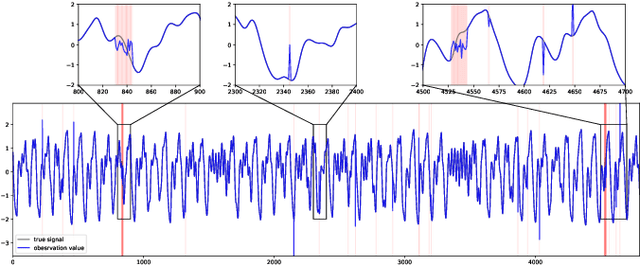
Deep generative models have demonstrated their effectiveness in learning latent representation and modeling complex dependencies of time series. In this paper, we present a Smoothness-Inducing Sequential Variational Auto-Encoder (SISVAE) model for robust estimation and anomaly detection of multi-dimensional time series. Our model is based on Variational Auto-Encoder (VAE), and its backbone is fulfilled by a Recurrent Neural Network to capture latent temporal structures of time series for both generative model and inference model. Specifically, our model parameterizes mean and variance for each time-stamp with flexible neural networks, resulting in a non-stationary model that can work without the assumption of constant noise as commonly made by existing Markov models. However, such a flexibility may cause the model fragile to anomalies. To achieve robust density estimation which can also benefit detection tasks, we propose a smoothness-inducing prior over possible estimations. The proposed prior works as a regularizer that places penalty at non-smooth reconstructions. Our model is learned efficiently with a novel stochastic gradient variational Bayes estimator. In particular, we study two decision criteria for anomaly detection: reconstruction probability and reconstruction error. We show the effectiveness of our model on both synthetic datasets and public real-world benchmarks.
General Hannan and Quinn Criterion for Common Time Series
Jan 11, 2021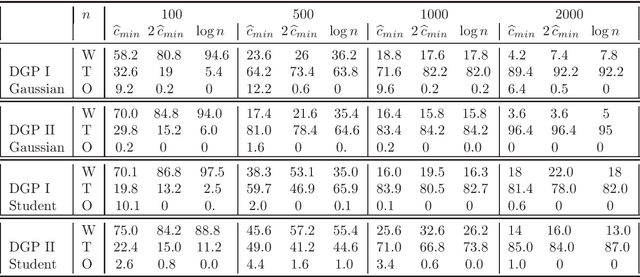

This paper aims to study data driven model selection criteria for a large class of time series, which includes ARMA or AR($\infty$) processes, as well as GARCH or ARCH($\infty$), APARCH and many others processes. We tackled the challenging issue of designing adaptive criteria which enjoys the strong consistency property. When the observations are generated from one of the aforementioned models, the new criteria, select the true model almost surely asymptotically. The proposed criteria are based on the minimization of a penalized contrast akin to the Hannan and Quinn's criterion and then involved a term which is known for most classical time series models and for more complex models, this term can be data driven calibrated. Monte-Carlo experiments and an illustrative example on the CAC 40 index are performed to highlight the obtained results.
Conformal prediction interval for dynamic time-series
Nov 09, 2020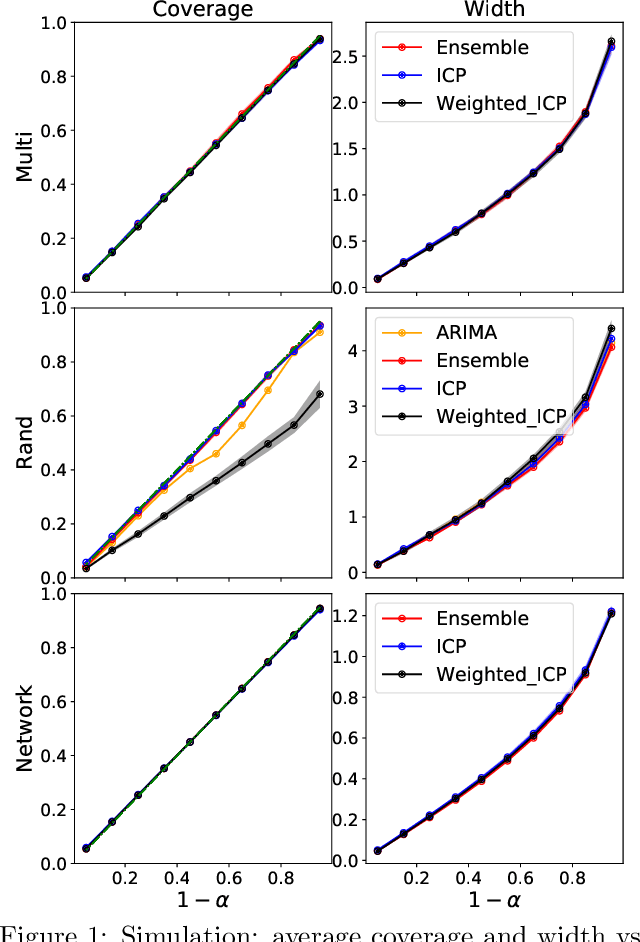
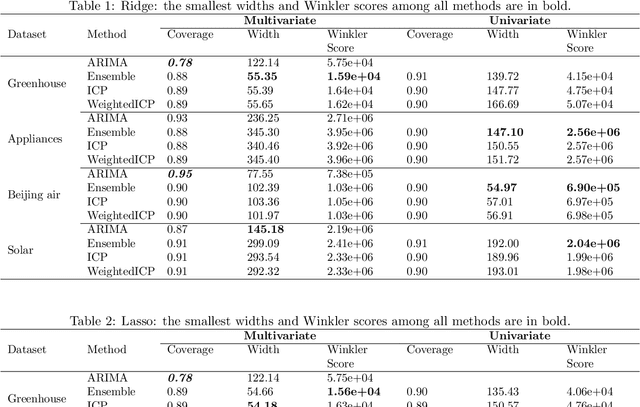
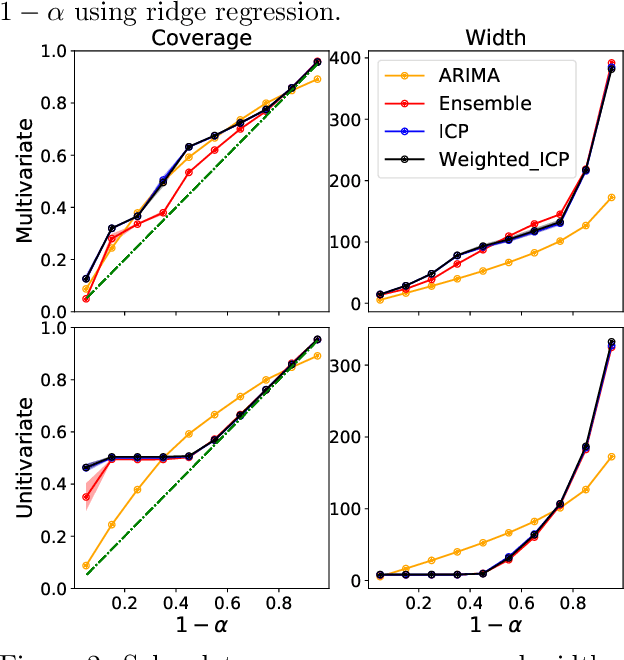
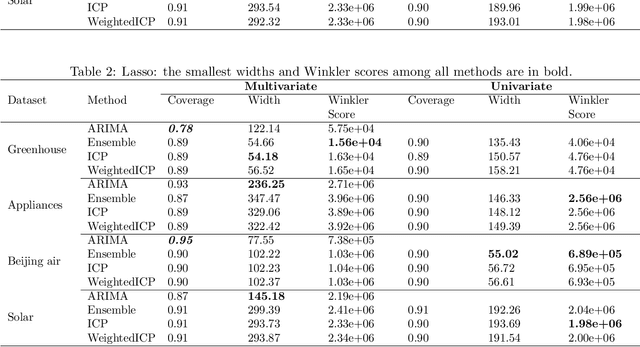
We develop a method to build distribution-free prediction intervals in batches for time-series based on conformal inference, called \Verb|EnbPI| that wraps around any ensemble estimator to construct sequential prediction intervals. \Verb|EnbPI| is closely related to the conformal prediction (CP) framework but does not require data exchangeability. Theoretically, these intervals attain finite-sample, approximately valid average coverage for broad classes of regression functions and time-series with strongly mixing stochastic errors. Computationally, \Verb|EnbPI| requires no training of multiple ensemble estimators; it efficiently operates around an already trained ensemble estimator. In general, \Verb|EnbPI| is easy to implement, scalable to producing arbitrarily many prediction intervals sequentially, and well-suited to a wide range of regression functions. We perform extensive simulations and real-data analyses to demonstrate its effectiveness.
Neural Geometric Level of Detail: Real-time Rendering with Implicit 3D Shapes
Jan 26, 2021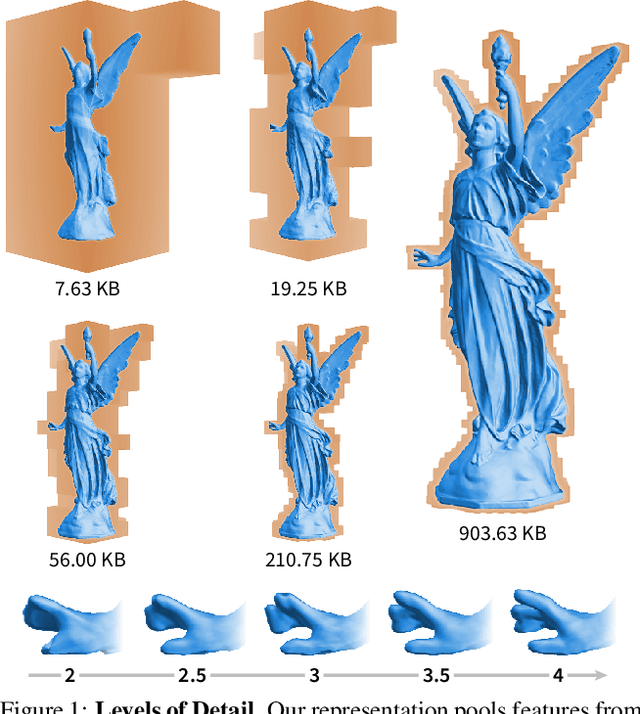
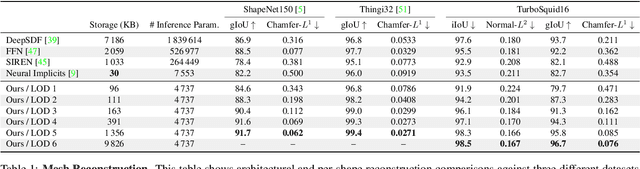

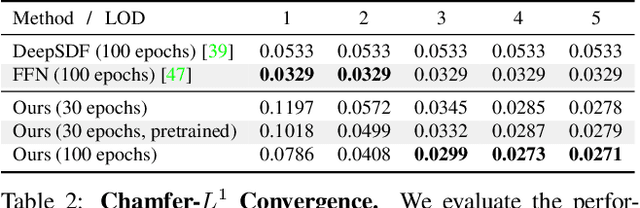
Neural signed distance functions (SDFs) are emerging as an effective representation for 3D shapes. State-of-the-art methods typically encode the SDF with a large, fixed-size neural network to approximate complex shapes with implicit surfaces. Rendering with these large networks is, however, computationally expensive since it requires many forward passes through the network for every pixel, making these representations impractical for real-time graphics. We introduce an efficient neural representation that, for the first time, enables real-time rendering of high-fidelity neural SDFs, while achieving state-of-the-art geometry reconstruction quality. We represent implicit surfaces using an octree-based feature volume which adaptively fits shapes with multiple discrete levels of detail (LODs), and enables continuous LOD with SDF interpolation. We further develop an efficient algorithm to directly render our novel neural SDF representation in real-time by querying only the necessary LODs with sparse octree traversal. We show that our representation is 2-3 orders of magnitude more efficient in terms of rendering speed compared to previous works. Furthermore, it produces state-of-the-art reconstruction quality for complex shapes under both 3D geometric and 2D image-space metrics.
A Simulation Benchmark for Vision-based Autonomous Navigation
Apr 01, 2022

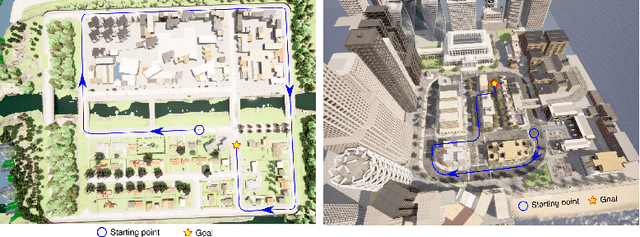
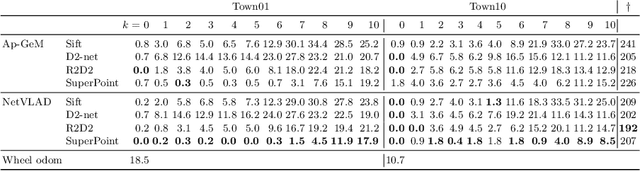
This work introduces a simulator benchmark for vision-based autonomous navigation. The simulator offers control over real world variables such as the environment, time of day, weather and traffic. The benchmark includes a modular integration of different components of a full autonomous visual navigation stack. In the experimental part of the paper, state-of-the-art visual localization methods are evaluated as a part of the stack in realistic navigation tasks. To the authors' best knowledge, the proposed benchmark is the first to study modern visual localization methods as part of a full autonomous visual navigation stack.
The Connection between Discrete- and Continuous-Time Descriptions of Gaussian Continuous Processes
Jan 20, 2021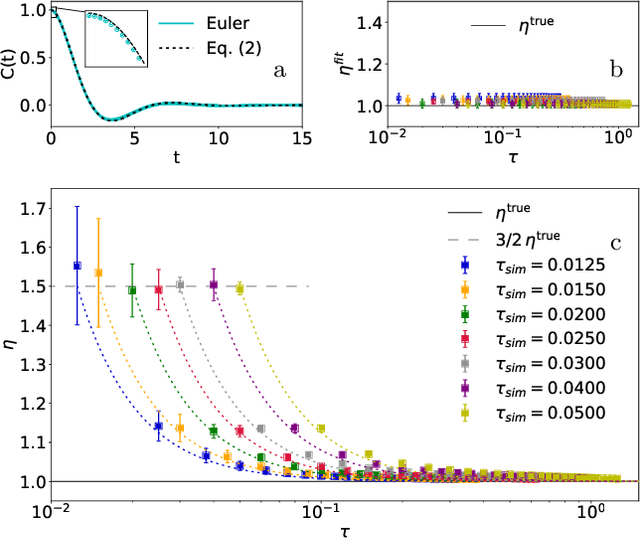

Learning the continuous equations of motion from discrete observations is a common task in all areas of physics. However, not any discretization of a Gaussian continuous-time stochastic process can be adopted in parametric inference. We show that discretizations yielding consistent estimators have the property of `invariance under coarse-graining', and correspond to fixed points of a renormalization group map on the space of autoregressive moving average (ARMA) models (for linear processes). This result explains why combining differencing schemes for derivatives reconstruction and local-in-time inference approaches does not work for time series analysis of second or higher order stochastic differential equations, even if the corresponding integration schemes may be acceptably good for numerical simulations.
Latency Overhead of ROS2 for Modular Time-Critical Systems
Jan 06, 2021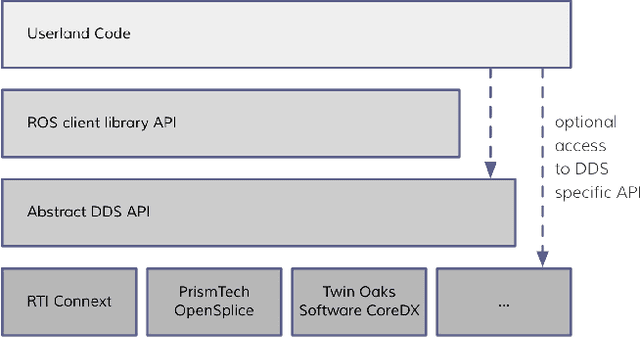
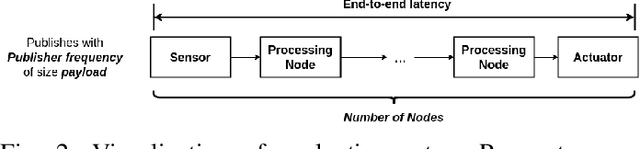
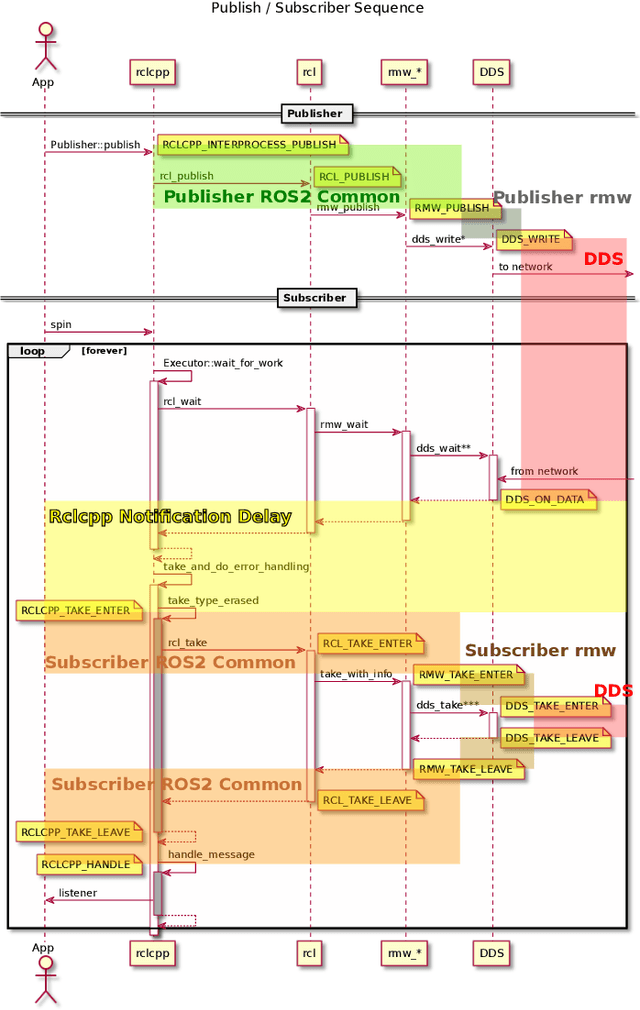
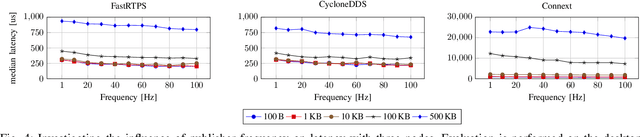
Robot Operating System 2 (ROS2) targets distributed real-time systems. Especially in tight real-time control loops, latency in data processing and communication can lead to instabilities. As ROS2 encourages splitting of the data-processing pipelines into several modules, it is important to understand the latency implications of such modularization. In this paper, we investigate the end-to-end latency of ROS2 data-processing pipeline with different Data Distribution Service (DDS) middlewares. In addition, we profile the ROS2 stack and point out latency bottlenecks. Our findings indicate that end-to-end latency strongly depends on the used DDS middleware. Moreover, we show that ROS2 can lead to 50 % latency overhead compared to using low-level DDS communications. Our results imply guidelines for designing modular ROS2 architectures and indicate possibilities for reducing the ROS2 overhead.