 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FS-COCO: Towards Understanding of Freehand Sketches of Common Objects in Context
Mar 04, 2022


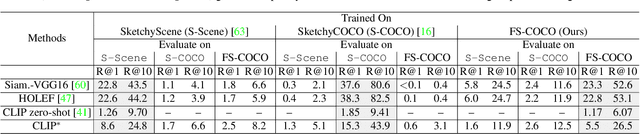
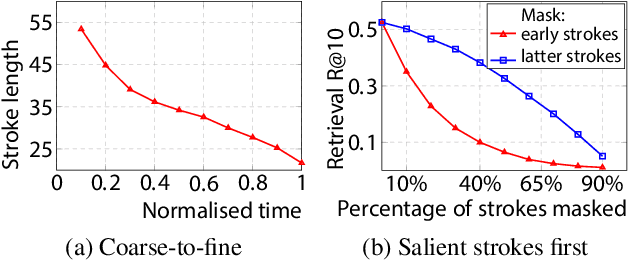
We advance sketch research to scenes with the first dataset of freehand scene sketches, FS-COCO. With practical applications in mind, we collect sketches that convey well scene content but can be sketched within a few minutes by a person with any sketching skills. Our dataset comprises 10,000 freehand scene vector sketches with per point space-time information by 100 non-expert individuals, offering both object- and scene-level abstraction. Each sketch is augmented with its text description. Using our dataset, we study for the first time the problem of the fine-grained image retrieval from freehand scene sketches and sketch captions. We draw insights on (i) Scene salience encoded in sketches with strokes temporal order; (ii) The retrieval performance accuracy from scene sketches against image captions; (iii) Complementarity of information in sketches and image captions, as well as the potential benefit of combining the two modalities. In addition, we propose new solutions enabled by our dataset (i) We adopt meta-learning to show how the retrieval model can be fine-tuned to a new user style given just a small set of sketches, (ii) We extend a popular vector sketch LSTM-based encoder to handle sketches with larger complexity than was supported by previous work. Namely, we propose a hierarchical sketch decoder, which we leverage at a sketch-specific "pretext" task. Our dataset enables for the first time research on freehand scene sketch understanding and its practical applications.
View-labels Are Indispensable: A Multifacet Complementarity Study of Multi-view Clustering
May 05, 2022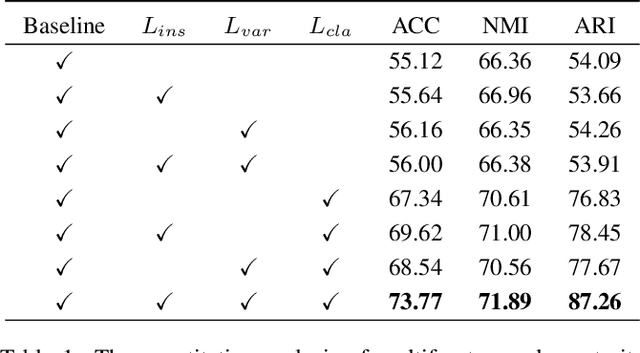
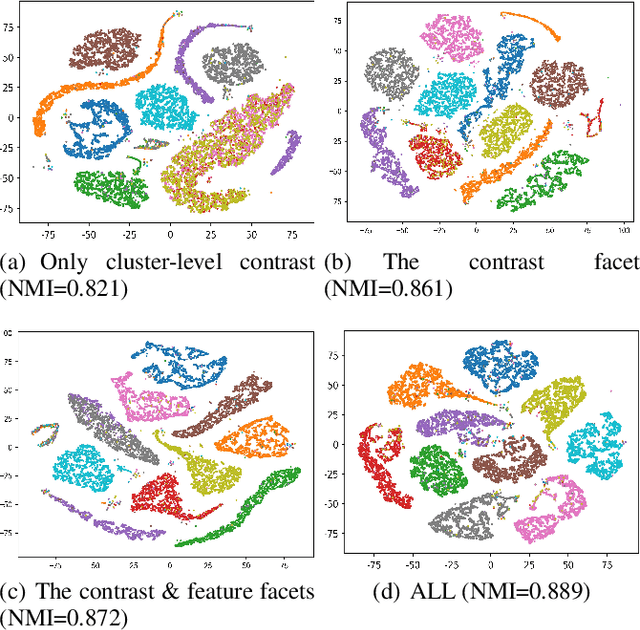
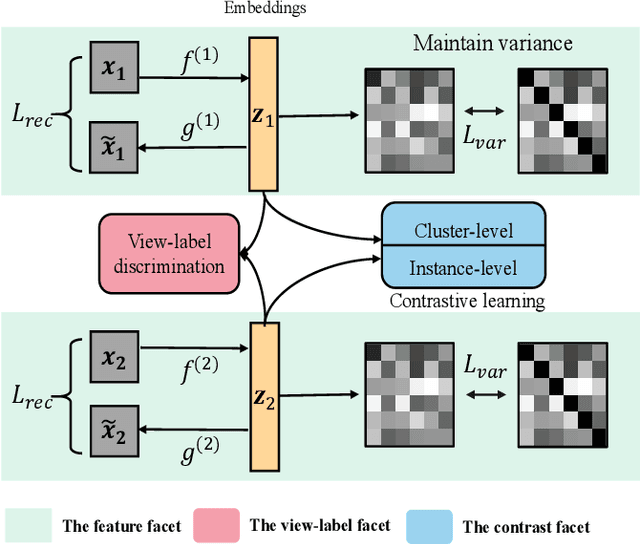
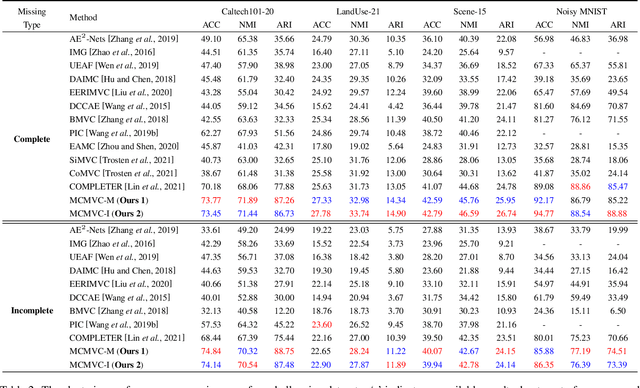
Consistency and complementarity are two key ingredients for boosting multi-view clustering (MVC). Recently with the introduction of popular contrastive learning, the consistency learning of views has been further enhanced in MVC, leading to promising performance. However, by contrast, the complementarity has not received sufficient attention except just in the feature facet, where the Hilbert Schmidt Independence Criterion (HSIC) term or the independent encoder-decoder network is usually adopted to capture view-specific information. This motivates us to reconsider the complementarity learning of views comprehensively from multiple facets including the feature-, view-label- and contrast- facets, while maintaining the view consistency. We empirically find that all the facets contribute to the complementarity learning, especially the view-label facet, which is usually neglected by existing methods. Based on this, we develop a novel \underline{M}ultifacet \underline{C}omplementarity learning framework for \underline{M}ulti-\underline{V}iew \underline{C}lustering (MCMVC), which fuses multifacet complementarity information, especially explicitly embedding the view-label information. To our best knowledge, it is the first time to use view-labels explicitly to guide the complementarity learning of views. Compared with the SOTA baseline, MCMVC achieves remarkable improvements, e.g., by average margins over $5.00\%$ and $7.00\%$ respectively in complete and incomplete MVC settings on Caltech101-20 in terms of three evaluation metrics.
Real-Time Ellipse Detection for Robotics Applications
Feb 25, 2021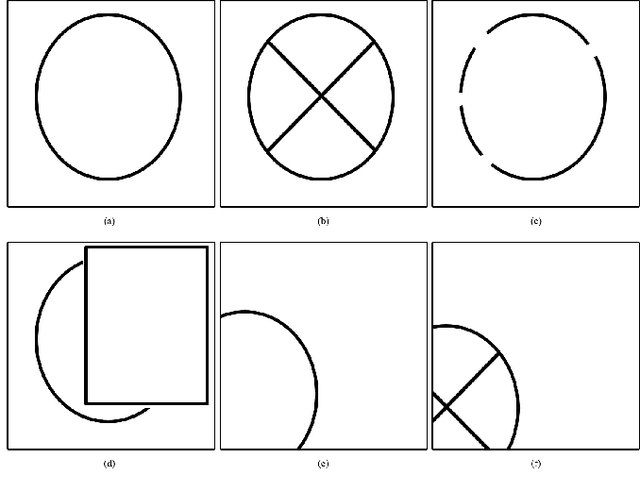
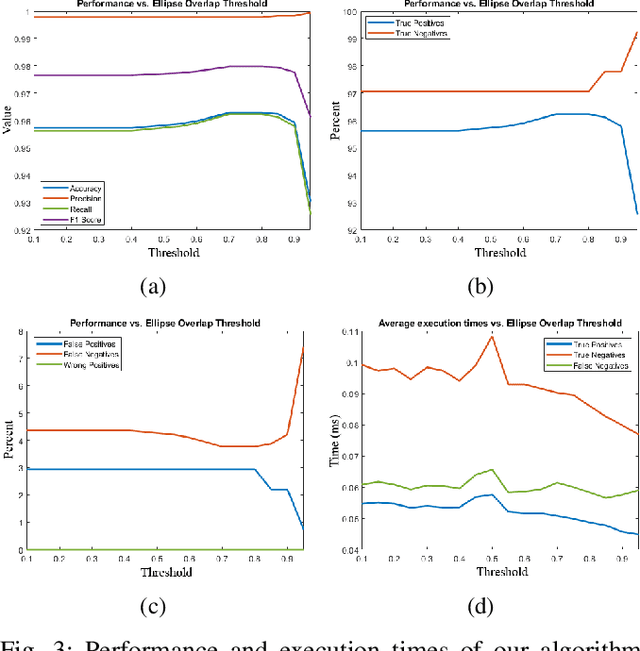
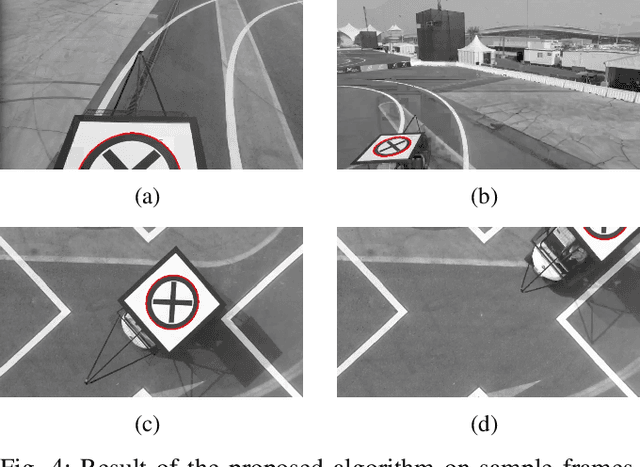

We propose a new algorithm for real-time detection and tracking of elliptic patterns suitable for real-world robotics applications. The method fits ellipses to each contour in the image frame and rejects ellipses that do not yield a good fit. It can detect complete, partial, and imperfect ellipses in extreme weather and lighting conditions and is lightweight enough to be used on robots' resource-limited onboard computers. The method is used on an example application of autonomous UAV landing on a fast-moving vehicle to show its performance indoors, outdoors, and in simulation on a real-world robotics task. The comparison with other well-known ellipse detection methods shows that our proposed algorithm outperforms other methods with the F1 score of 0.981 on a dataset with over 1500 frames. The videos of experiments, the source codes, and the collected dataset are provided with the paper.
Pre-trained Language Models as Re-Annotators
May 11, 2022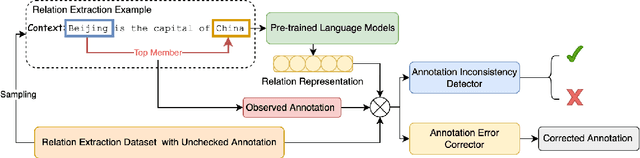

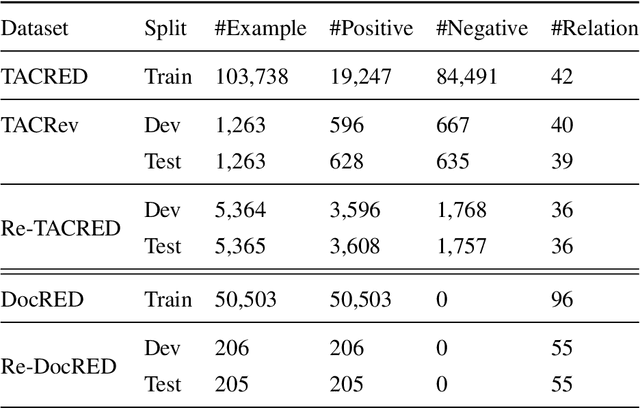
Annotation noise is widespread in datasets, but manually revising a flawed corpus is time-consuming and error-prone. Hence, given the prior knowledge in Pre-trained Language Models and the expected uniformity across all annotations, we attempt to reduce annotation noise in the corpus through two tasks automatically: (1) Annotation Inconsistency Detection that indicates the credibility of annotations, and (2) Annotation Error Correction that rectifies the abnormal annotations. We investigate how to acquire semantic sensitive annotation representations from Pre-trained Language Models, expecting to embed the examples with identical annotations to the mutually adjacent positions even without fine-tuning. We proposed a novel credibility score to reveal the likelihood of annotation inconsistencies based on the neighbouring consistency. Then, we fine-tune the Pre-trained Language Models based classifier with cross-validation for annotation correction. The annotation corrector is further elaborated with two approaches: (1) soft labelling by Kernel Density Estimation and (2) a novel distant-peer contrastive loss. We study the re-annotation in relation extraction and create a new manually revised dataset, Re-DocRED, for evaluating document-level re-annotation. The proposed credibility scores show promising agreement with human revisions, achieving a Binary F1 of 93.4 and 72.5 in detecting inconsistencies on TACRED and DocRED respectively. Moreover, the neighbour-aware classifiers based on distant-peer contrastive learning and uncertain labels achieve Macro F1 up to 66.2 and 57.8 in correcting annotations on TACRED and DocRED respectively. These improvements are not merely theoretical: Rather, automatically denoised training sets demonstrate up to 3.6% performance improvement for state-of-the-art relation extraction models.
Bounding the Effects of Continuous Treatments for Hidden Confounders
Apr 24, 2022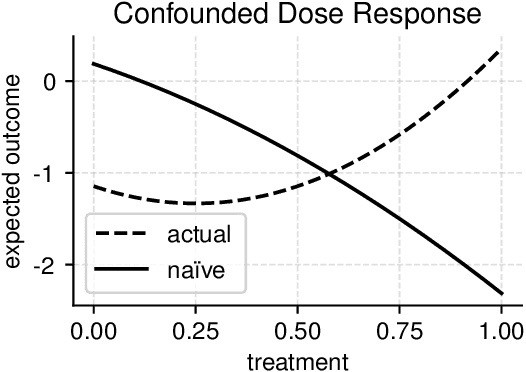
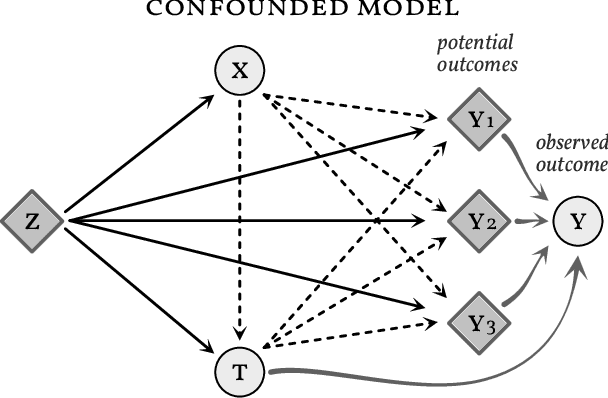
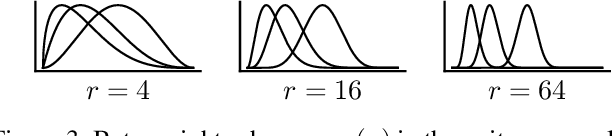
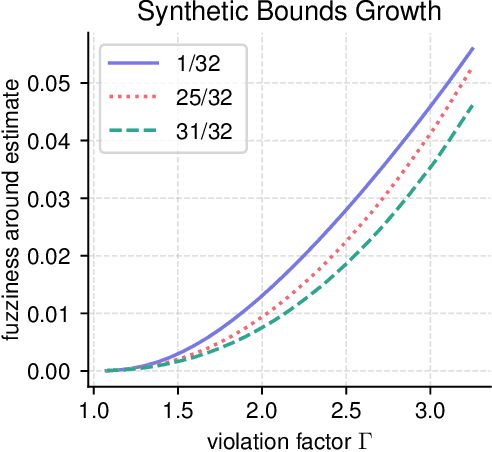
Causal inference involves the disentanglement of effects due to a treatment variable from those of confounders, observed as covariates or not. Since one outcome is ever observed at a time, the problem turns into one of predicting counterfactuals on every individual in the dataset. Observational studies complicate this endeavor by permitting dependencies between the treatment and other variables in the sample. If the covariates influence the propensity of treatment, then one suffers from covariate shift. Should the outcome and the treatment be affected by another variable even after accounting for the covariates, there is also hidden confounding. That is immeasurable by definition. Rather, one must study the worst possible consequences of bounded levels of hidden confounding on downstream decision-making. We explore this problem in the case of continuous treatments. We develop a framework to compute ignorance intervals on the partially identified dose-response curves, which enable us to quantify the susceptibility of our inference to hidden confounders. Our method is supported by simulations as well as empirical tests based on two observational studies.
DDOS: A MOS Prediction Framework utilizing Domain Adaptive Pre-training and Distribution of Opinion Scores
Apr 07, 2022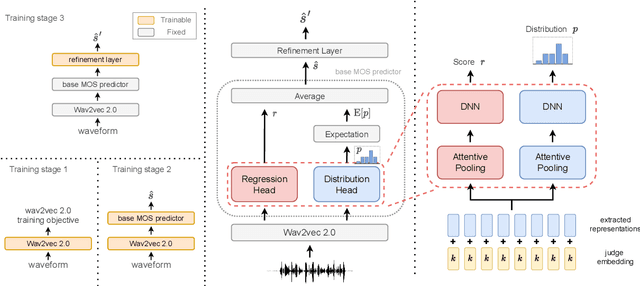
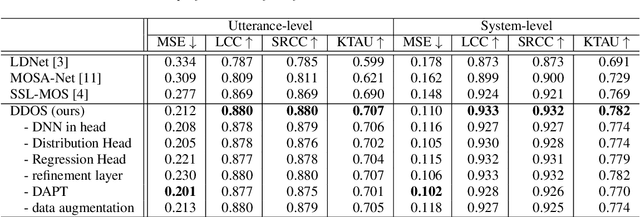
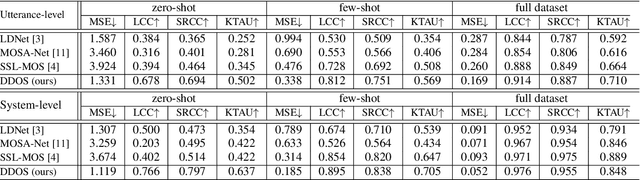
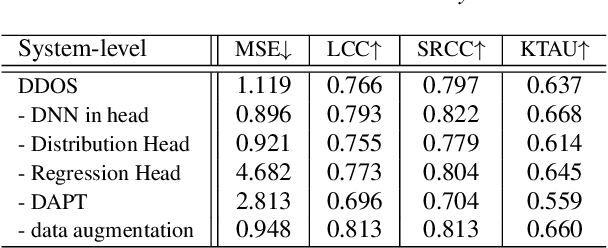
Mean opinion score (MOS) is a typical subjective evaluation metric for speech synthesis systems. Since collecting MOS is time-consuming, it would be desirable if there are accurate MOS prediction models for automatic evaluation. In this work, we propose DDOS, a novel MOS prediction model. DDOS utilizes domain adaptive pre-training to further pre-train self-supervised learning models on synthetic speech. And a proposed module is added to model the opinion score distribution of each utterance. With the proposed components, DDOS outperforms previous works on BVCC dataset. And the zero shot transfer result on BC2019 dataset is significantly improved. DDOS also wins second place in Interspeech 2022 VoiceMOS challenge in terms of system-level score.
One Parameter Defense -- Defending against Data Inference Attacks via Differential Privacy
Mar 13, 2022Machine learning models are vulnerable to data inference attacks, such as membership inference and model inversion attacks. In these types of breaches, an adversary attempts to infer a data record's membership in a dataset or even reconstruct this data record using a confidence score vector predicted by the target model. However, most existing defense methods only protect against membership inference attacks. Methods that can combat both types of attacks require a new model to be trained, which may not be time-efficient. In this paper, we propose a differentially private defense method that handles both types of attacks in a time-efficient manner by tuning only one parameter, the privacy budget. The central idea is to modify and normalize the confidence score vectors with a differential privacy mechanism which preserves privacy and obscures membership and reconstructed data. Moreover, this method can guarantee the order of scores in the vector to avoid any loss in classification accuracy. The experimental results show the method to be an effective and timely defense against both membership inference and model inversion attacks with no reduction in accuracy.
Enhancing Feasibility and Safety of Nonlinear Model Predictive Control with Discrete-Time Control Barrier Functions
May 21, 2021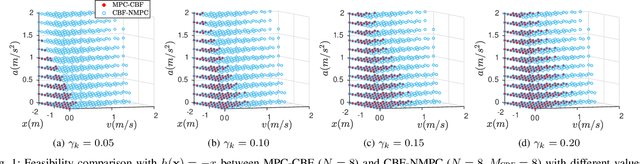
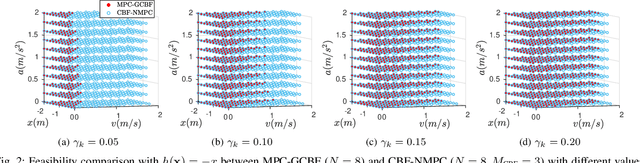
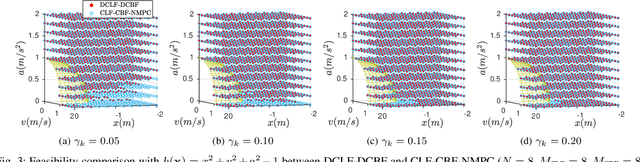
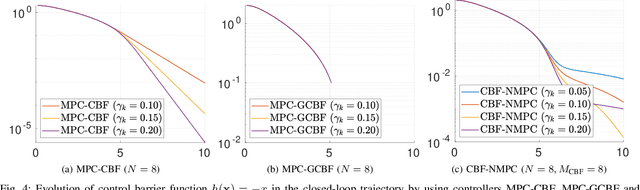
Safety is one of the fundamental problems in robotics. Recently, one-step or multi-step optimal control problems for discrete-time nonlinear dynamical system are formulated to offer tracking stability using control Lyapunov functions (CLFs) while subject to input constraints as well as safety-critical constraints using control barrier functions (CBFs). The limitations of these existing approaches are mainly about feasibility and safety. In the existing approaches, the optimization feasibility and the system safety cannot be enhanced at the same time theoretically. In this paper, we propose two formulations that unifies CLFs and CBFs under the framework of nonlinear model predictive control (NMPC). In the proposed formulations, safety criteria is commonly formulated as CBF constraints and stability performance is ensured with either a terminal cost function or CLF constraints. Relaxing variables are introduced on the CBF constraints to resolve the tradeoff between feasibility and safety so that they can be enhanced at the same. The advantages about feasibility and safety of proposed formulations compared with existing methods are analyzed theoretically and validated with numerical results.
Deep vs. Shallow Learning: A Benchmark Study in Low Magnitude Earthquake Detection
May 01, 2022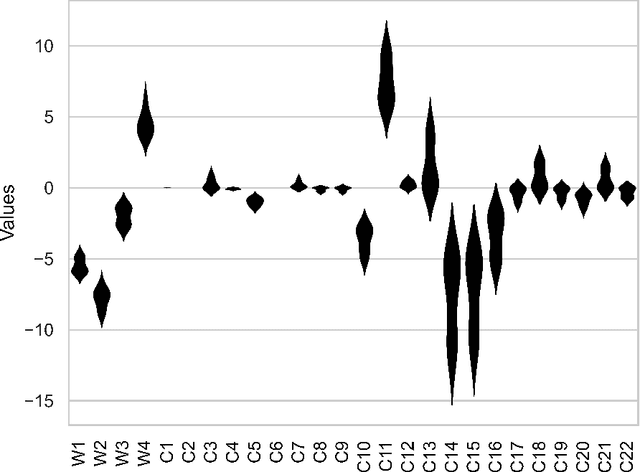

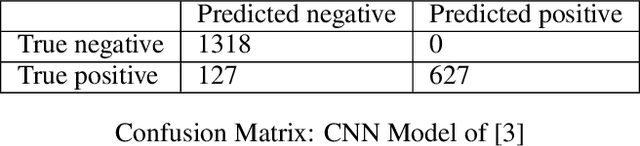

While deep learning models have seen recent high uptake in the geosciences, and are appealing in their ability to learn from minimally processed input data, as black box models they do not provide an easy means to understand how a decision is reached, which in safety-critical tasks especially can be problematical. An alternative route is to use simpler, more transparent white box models, in which task-specific feature construction replaces the more opaque feature discovery process performed automatically within deep learning models. Using data from the Groningen Gas Field in the Netherlands, we build on an existing logistic regression model by the addition of four further features discovered using elastic net driven data mining within the catch22 time series analysis package. We then evaluate the performance of the augmented logistic regression model relative to a deep (CNN) model, pre-trained on the Groningen data, on progressively increasing noise-to-signal ratios. We discover that, for each ratio, our logistic regression model correctly detects every earthquake, while the deep model fails to detect nearly 20 % of seismic events, thus justifying at least a degree of caution in the application of deep models, especially to data with higher noise-to-signal ratios.
Indoor Localization for Quadrotors using Invisible Projected Tags
Mar 13, 2022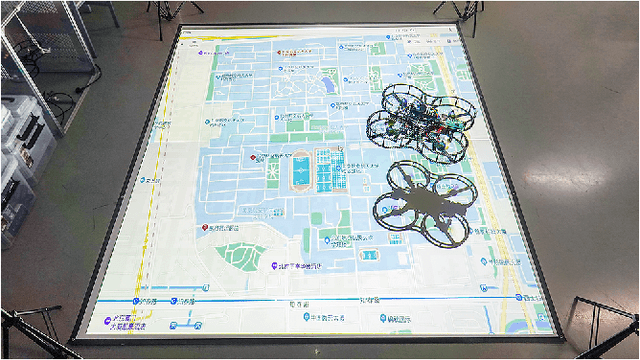
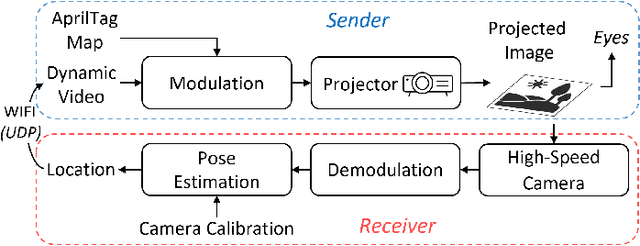
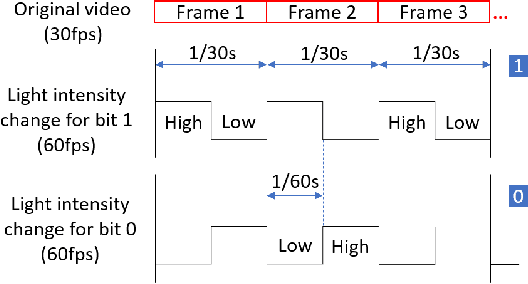
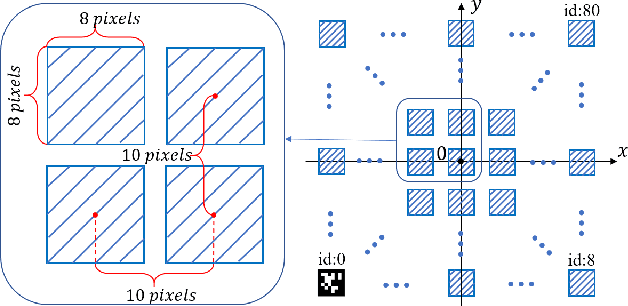
Augmented reality (AR) technology has been introduced into the robotics field to narrow the visual gap between indoor and outdoor environments. However, without signals from satellite navigation systems, flight experiments in these indoor AR scenarios need other accurate localization approaches. This work proposes a real-time centimeter-level indoor localization method based on psycho-visually invisible projected tags (IPT), requiring a projector as the sender and quadrotors with high-speed cameras as the receiver. The method includes a modulation process for the sender, as well as demodulation and pose estimation steps for the receiver, where screen-camera communication technology is applied to hide fiducial tags using human vision property. Experiments have demonstrated that IPT can achieve accuracy within ten centimeters and a speed of about ten FPS. Compared with other localization methods for AR robotics platforms, IPT is affordable by using only a projector and high-speed cameras as hardware consumption and convenient by omitting a coordinate alignment step. To the authors' best knowledge, this is the first time screen-camera communication is utilized for AR robot localization.