 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graphical Residual Flows
Apr 23, 2022
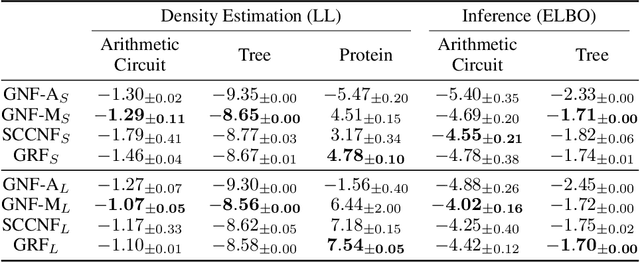
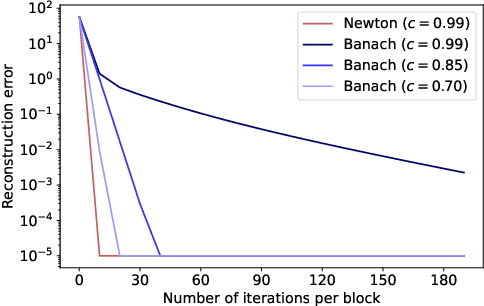
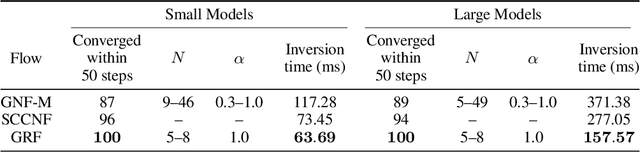
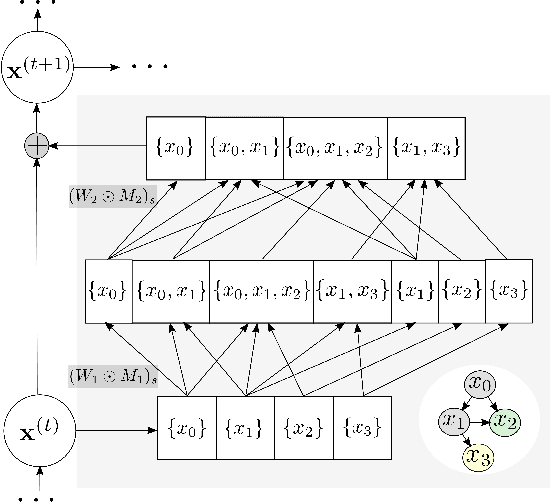
Graphical flows add further structure to normalizing flows by encoding non-trivial variable dependencies. Previous graphical flow models have focused primarily on a single flow direction: the normalizing direction for density estimation, or the generative direction for inference. However, to use a single flow to perform tasks in both directions, the model must exhibit stable and efficient flow inversion. This work introduces graphical residual flows, a graphical flow based on invertible residual networks. Our approach to incorporating dependency information in the flow, means that we are able to calculate the Jacobian determinant of these flows exactly. Our experiments confirm that graphical residual flows provide stable and accurate inversion that is also more time-efficient than alternative flows with similar task performance. Furthermore, our model provides performance competitive with other graphical flows for both density estimation and inference tasks.
HARNet: A Convolutional Neural Network for Realized Volatility Forecasting
May 16, 2022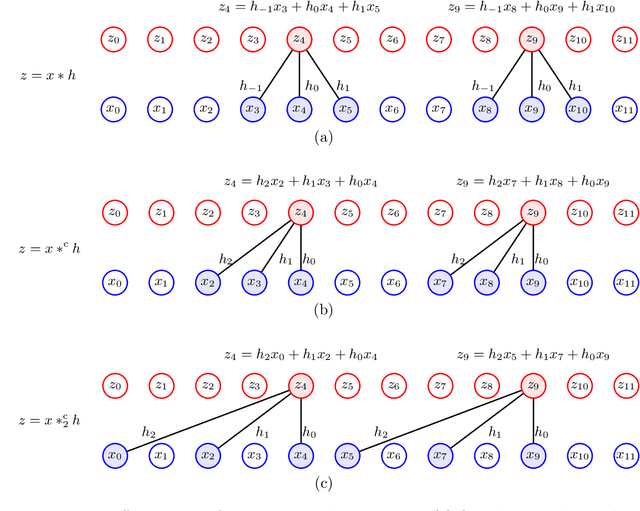

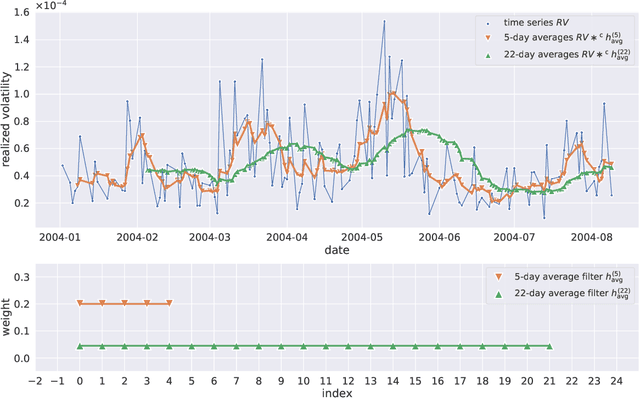
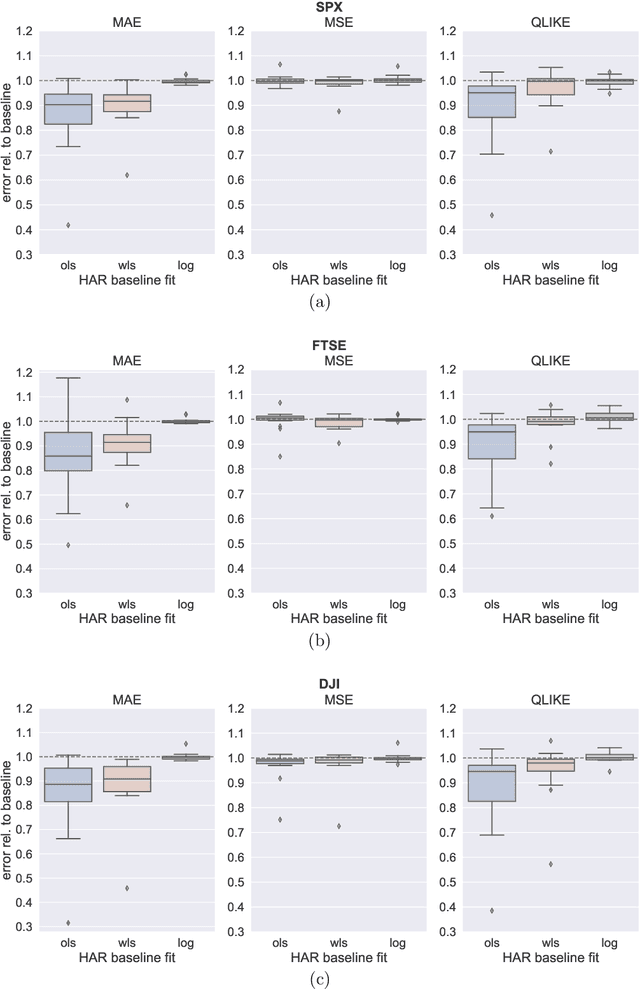
Despite the impressive success of deep neural networks in many application areas, neural network models have so far not been widely adopted in the context of volatility forecasting. In this work, we aim to bridge the conceptual gap between established time series approaches, such as the Heterogeneous Autoregressive (HAR) model, and state-of-the-art deep neural network models. The newly introduced HARNet is based on a hierarchy of dilated convolutional layers, which facilitates an exponential growth of the receptive field of the model in the number of model parameters. HARNets allow for an explicit initialization scheme such that before optimization, a HARNet yields identical predictions as the respective baseline HAR model. Particularly when considering the QLIKE error as a loss function, we find that this approach significantly stabilizes the optimization of HARNets. We evaluate the performance of HARNets with respect to three different stock market indexes. Based on this evaluation, we formulate clear guidelines for the optimization of HARNets and show that HARNets can substantially improve upon the forecasting accuracy of their respective HAR baseline models. In a qualitative analysis of the filter weights learnt by a HARNet, we report clear patterns regarding the predictive power of past information. Among information from the previous week, yesterday and the day before, yesterday's volatility makes by far the most contribution to today's realized volatility forecast. Moroever, within the previous month, the importance of single weeks diminishes almost linearly when moving further into the past.
Classification of Quasars, Galaxies, and Stars in the Mapping of the Universe Multi-modal Deep Learning
May 22, 2022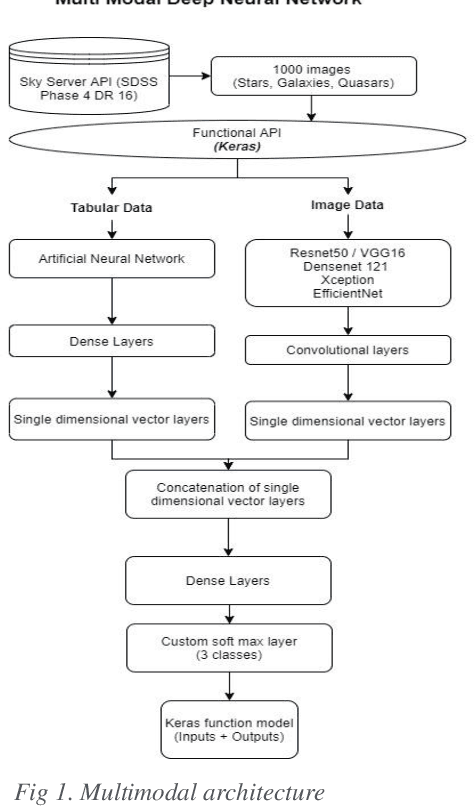
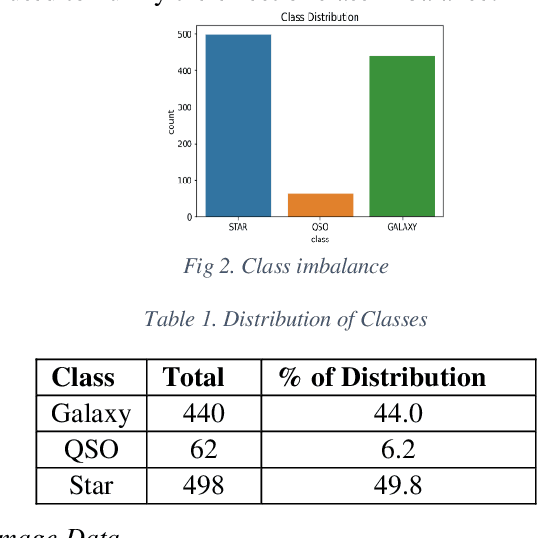
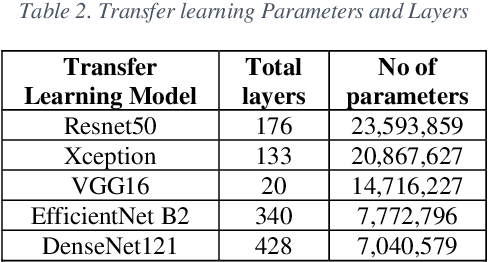

In this paper, the fourth version the Sloan Digital Sky Survey (SDSS-4), Data Release 16 dataset was used to classify the SDSS dataset into galaxies, stars, and quasars using machine learning and deep learning architectures. We efficiently utilize both image and metadata in tabular format to build a novel multi-modal architecture and achieve state-of-the-art results. In addition, our experiments on transfer learning using Imagenet weights on five different architectures (Resnet-50, DenseNet-121 VGG-16, Xception, and EfficientNet) reveal that freezing all layers and adding a final trainable layer may not be an optimal solution for transfer learning. It is hypothesized that higher the number of trainable layers, higher will be the training time and accuracy of predictions. It is also hypothesized that any subsequent increase in the number of training layers towards the base layers will not increase in accuracy as the pre trained lower layers only help in low level feature extraction which would be quite similar in all the datasets. Hence the ideal level of trainable layers needs to be identified for each model in respect to the number of parameters. For the tabular data, we compared classical machine learning algorithms (Logistic Regression, Random Forest, Decision Trees, Adaboost, LightGBM etc.,) with artificial neural networks. Our works shed new light on transfer learning and multi-modal deep learning architectures. The multi-modal architecture not only resulted in higher metrics (accuracy, precision, recall, F1 score) than models using only image data or tabular data. Furthermore, multi-modal architecture achieved the best metrics in lesser training epochs and improved the metrics on all classes.
Capturing Dynamics of Time-Varying Data via Topology
Oct 07, 2020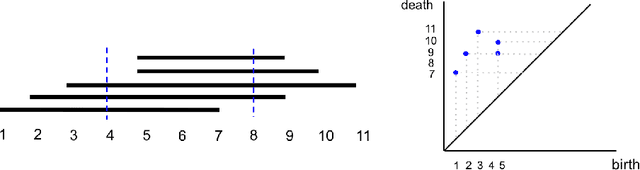
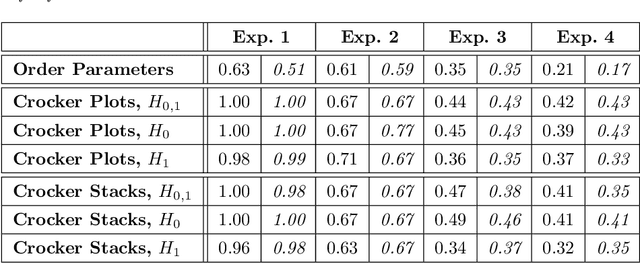
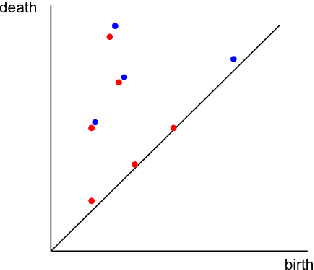
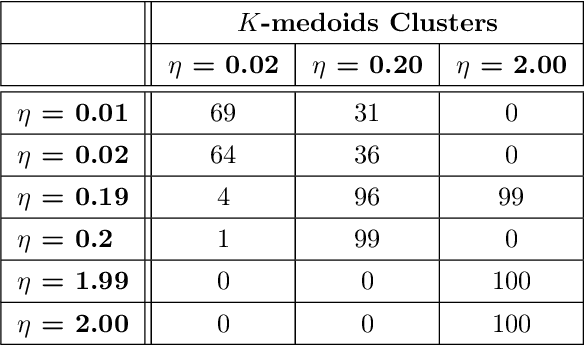
One approach to understanding complex data is to study its shape through the lens of algebraic topology. While the early development of topological data analysis focused primarily on static data, in recent years, theoretical and applied studies have turned to data that varies in time. A time-varying collection of metric spaces as formed, for example, by a moving school of fish or flock of birds, can contain a vast amount of information. There is often a need to simplify or summarize the dynamic behavior. We provide an introduction to topological summaries of time-varying metric spaces including vineyards [17], crocker plots [52], and multiparameter rank functions [34]. We then introduce a new tool to summarize time-varying metric spaces: a crocker stack. Crocker stacks are convenient for visualization, amenable to machine learning, and satisfy a desirable stability property which we prove. We demonstrate the utility of crocker stacks for a parameter identification task involving an influential model of biological aggregations [54]. Altogether, we aim to bring the broader applied mathematics community up-to-date on topological summaries of time-varying metric spaces.
Is Space-Time Attention All You Need for Video Understanding?
Feb 24, 2021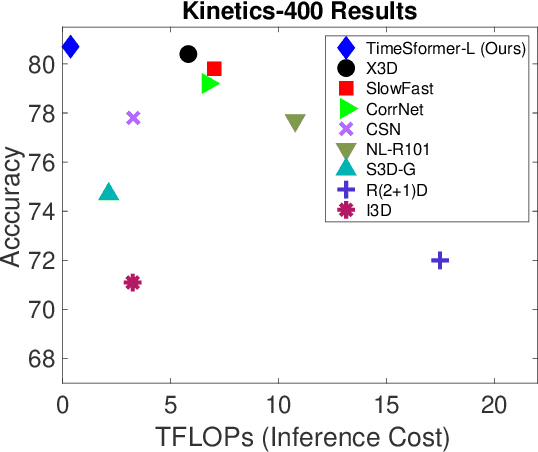
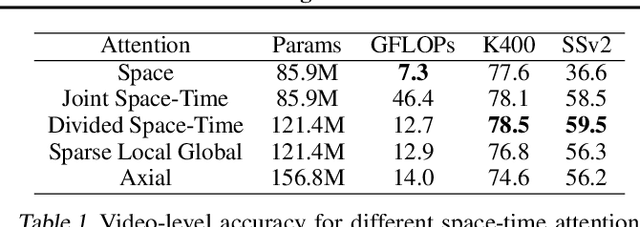
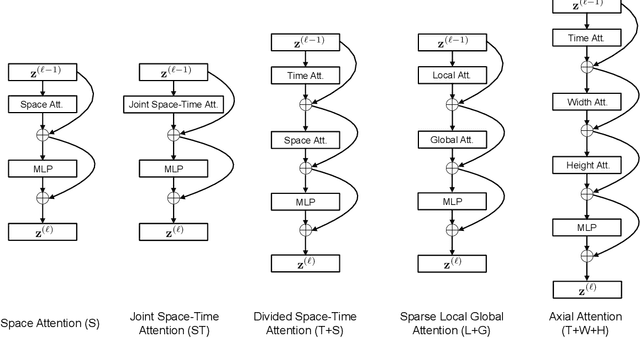
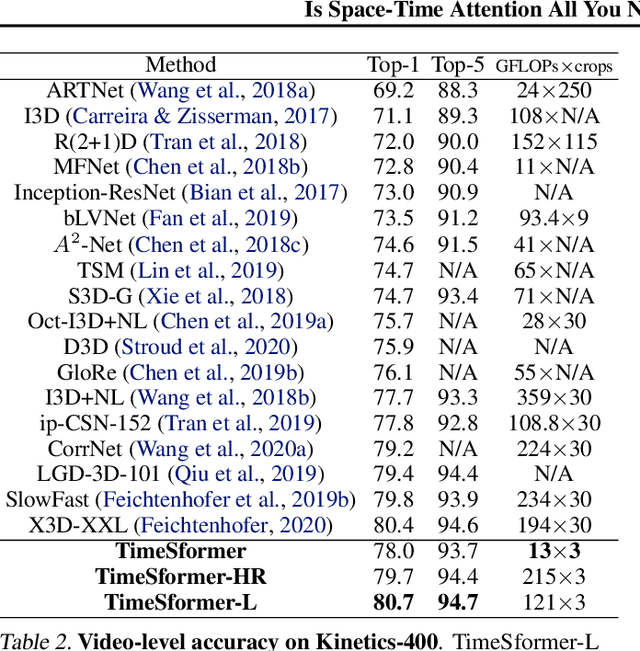
We present a convolution-free approach to video classification built exclusively on self-attention over space and time. Our method, named "TimeSformer," adapts the standard Transformer architecture to video by enabling spatiotemporal feature learning directly from a sequence of frame-level patches. Our experimental study compares different self-attention schemes and suggests that "divided attention," where temporal attention and spatial attention are separately applied within each block, leads to the best video classification accuracy among the design choices considered. Despite the radically different design compared to the prominent paradigm of 3D convolutional architectures for video, TimeSformer achieves state-of-the-art results on several major action recognition benchmarks, including the best reported accuracy on Kinetics-400 and Kinetics-600. Furthermore, our model is faster to train and has higher test-time efficiency compared to competing architectures. Code and pretrained models will be made publicly available.
ARCADE: Adversarially Regularized Convolutional Autoencoder for Network Anomaly Detection
May 13, 2022
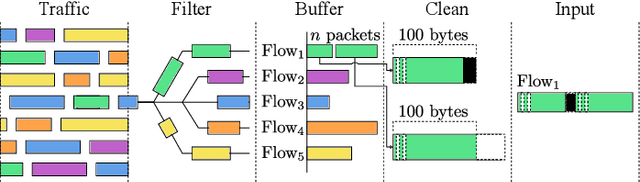
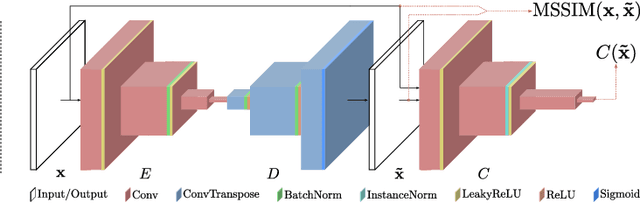

As the number of heterogenous IP-connected devices and traffic volume increase, so does the potential for security breaches. The undetected exploitation of these breaches can bring severe cybersecurity and privacy risks. In this paper, we present a practical unsupervised anomaly-based deep learning detection system called ARCADE (Adversarially Regularized Convolutional Autoencoder for unsupervised network anomaly DEtection). ARCADE exploits the property of 1D Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GAN) to automatically build a profile of the normal traffic based on a subset of raw bytes of a few initial packets of network flows so that potential network anomalies and intrusions can be effectively detected before they could cause any more damage to the network. A convolutional Autoencoder (AE) is proposed that suits online detection in resource-constrained environments, and can be easily improved for environments with higher computational capabilities. An adversarial training strategy is proposed to regularize and decrease the AE's capabilities to reconstruct network flows that are out of the normal distribution, and thereby improve its anomaly detection capabilities. The proposed approach is more effective than existing state-of-the-art deep learning approaches for network anomaly detection and significantly reduces detection time. The evaluation results show that the proposed approach is suitable for anomaly detection on resource-constrained hardware platforms such as Raspberry Pi.
Learning neural audio features without supervision
Mar 29, 2022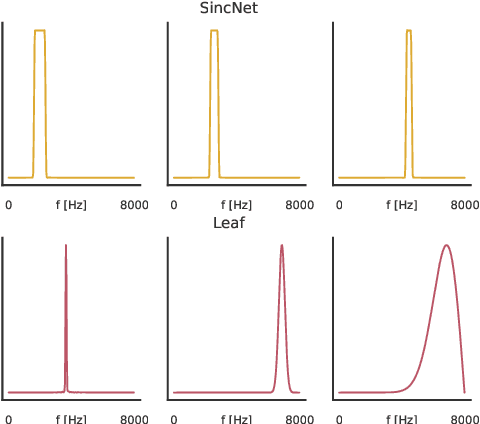
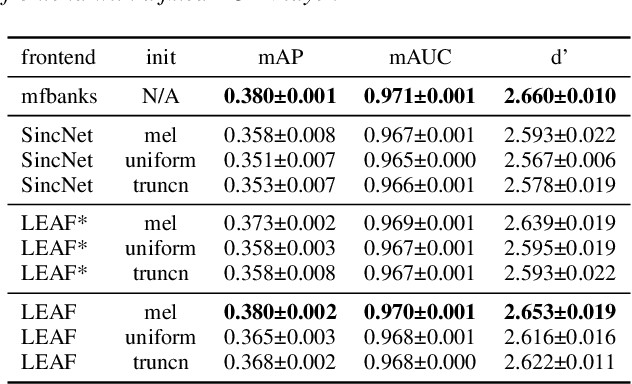
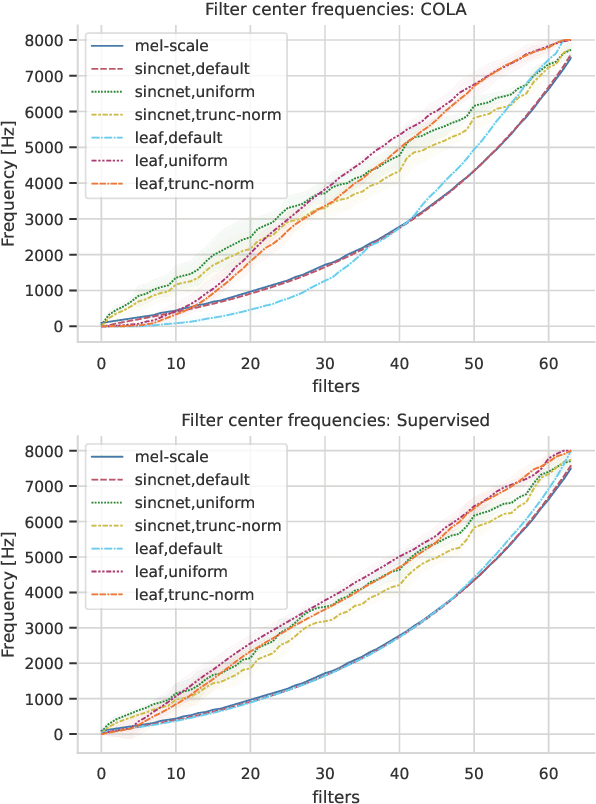
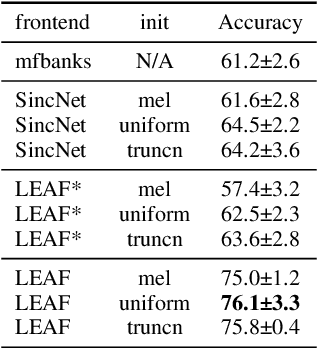
Deep audio classification, traditionally cast as training a deep neural network on top of mel-filterbanks in a supervised fashion, has recently benefited from two independent lines of work. The first one explores "learnable frontends", i.e., neural modules that produce a learnable time-frequency representation, to overcome limitations of fixed features. The second one uses self-supervised learning to leverage unprecedented scales of pre-training data. In this work, we study the feasibility of combining both approaches, i.e., pre-training learnable frontend jointly with the main architecture for downstream classification. First, we show that pretraining two previously proposed frontends (SincNet and LEAF) on Audioset drastically improves linear-probe performance over fixed mel-filterbanks, suggesting that learnable time-frequency representations can benefit self-supervised pre-training even more than supervised training. Surprisingly, randomly initialized learnable filterbanks outperform mel-scaled initialization in the self-supervised setting, a counter-intuitive result that questions the appropriateness of strong priors when designing learnable filters. Through exploratory analysis of the learned frontend components, we uncover crucial differences in properties of these frontends when used in a supervised and self-supervised setting, especially the affinity of self-supervised filters to diverge significantly from the mel-scale to model a broader range of frequencies.
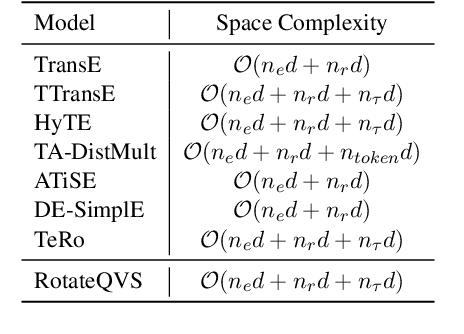
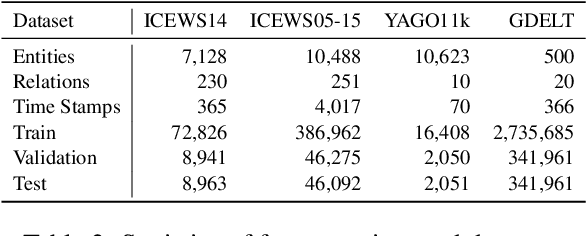
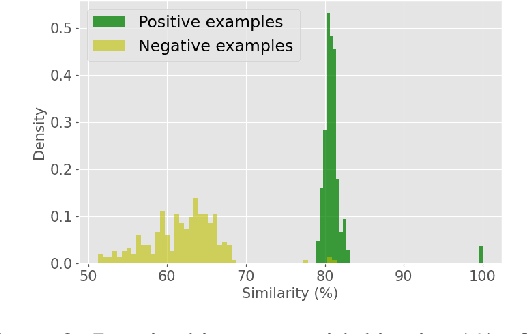
RotateQVS: Representing Temporal Information as Rotations in Quaternion Vector Space for Temporal Knowledge Graph Completion
Mar 17, 2022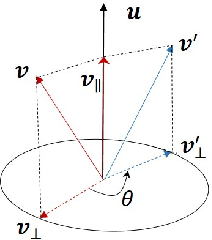
Temporal factors are tied to the growth of facts in realistic applications, such as the progress of diseases and the development of political situation, therefore, research on Temporal Knowledge Graph (TKG) attracks much attention. In TKG, relation patterns inherent with temporality are required to be studied for representation learning and reasoning across temporal facts. However, existing methods can hardly model temporal relation patterns, nor can capture the intrinsic connections between relations when evolving over time, lacking of interpretability. In this paper, we propose a novel temporal modeling method which represents temporal entities as Rotations in Quaternion Vector Space (RotateQVS) and relations as complex vectors in Hamilton's quaternion space. We demonstrate our method can model key patterns of relations in TKG, such as symmetry, asymmetry, inverse, and can further capture time-evolved relations by theory. Empirically, we show that our method can boost the performance of link prediction tasks over four temporal knowledge graph benchmarks.
Learning Model Predictive Control for Quadrotors
Feb 15, 2022
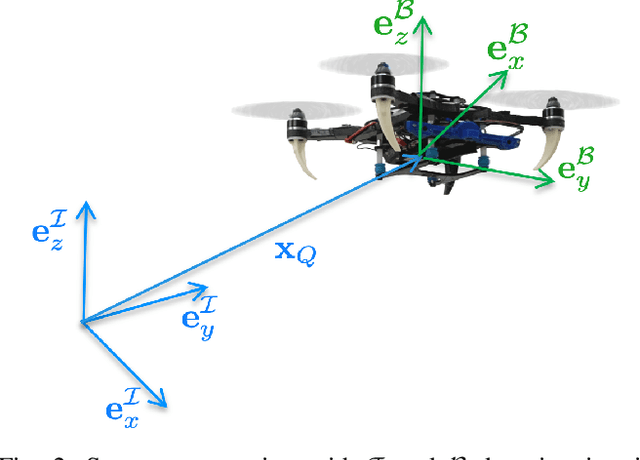
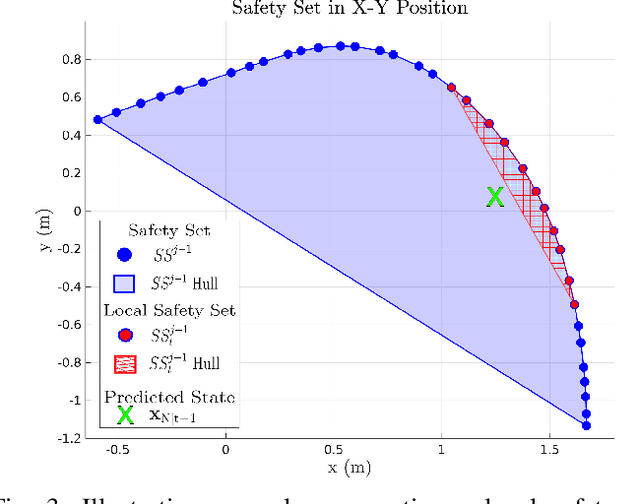
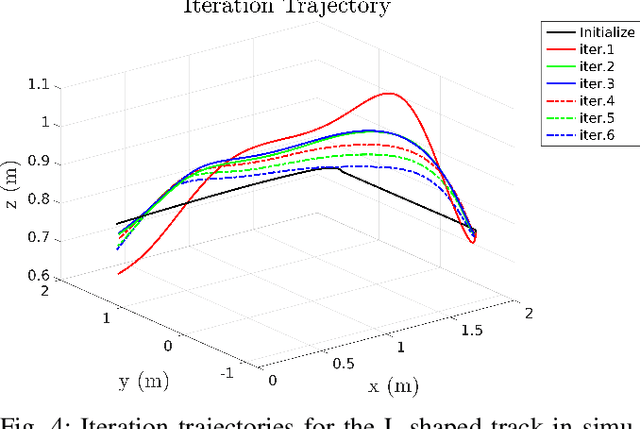
Aerial robots can enhance their safe and agile navigation in complex and cluttered environments by efficiently exploiting the information collected during a given task. In this paper, we address the learning model predictive control problem for quadrotors. We design a learning receding--horizon nonlinear control strategy directly formulated on the system nonlinear manifold configuration space SO(3)xR^3. The proposed approach exploits past successful task iterations to improve the system performance over time while respecting system dynamics and actuator constraints. We further relax its computational complexity making it compatible with real-time quadrotor control requirements. We show the effectiveness of the proposed approach in learning a minimum time control task, respecting dynamics, actuators, and environment constraints. Several experiments in simulation and real-world set-up validate the proposed approach.
Microwave Breast Imaging via Neural Networks for Almost Real-time Applications
Mar 21, 2021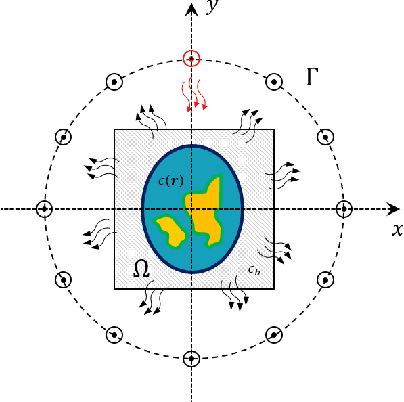
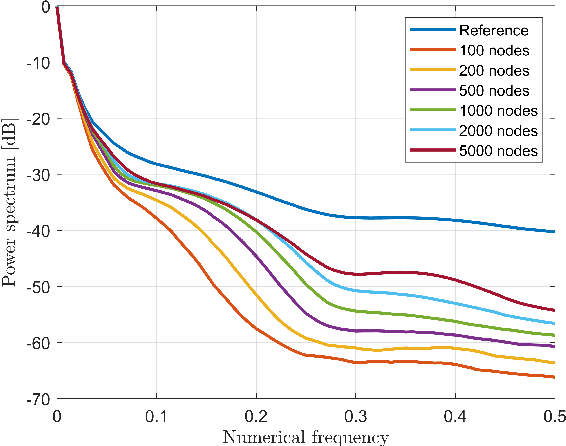
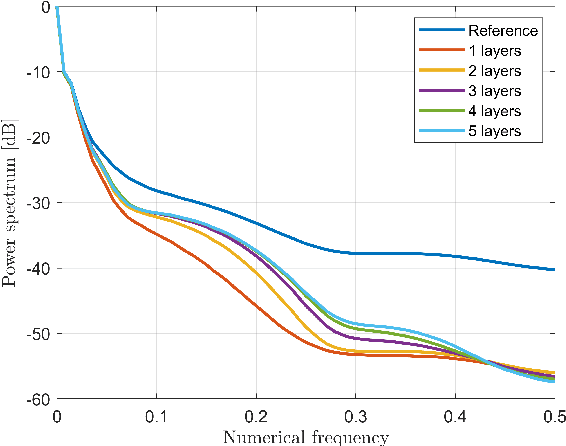
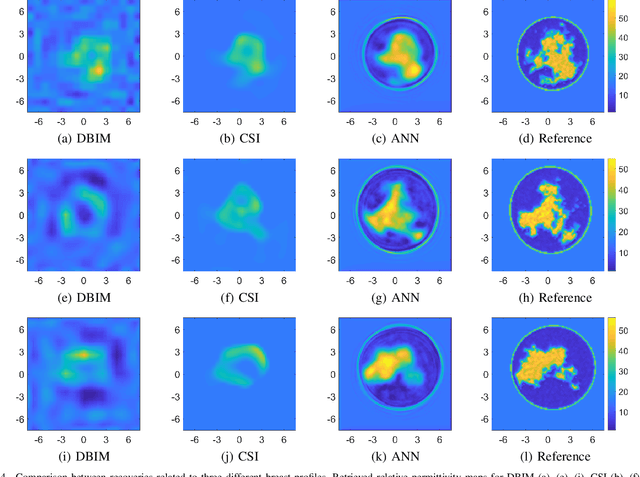
Conventional breast cancer imaging techniques are nowadays based on the use of ionising radiations or ultrasound waves for the inspection of breast areas. Nevertheless, these conventional techniques present some drawbacks related to patient safety, processing time and resolution issues. In this framework, microwave imaging can represent a valid alternative or a complementary technique compared to other conventional medical imaging modalities since it is safe (using non-ionising radiations), relatively cheap and more comfortable from patient point of view. Unfortunately, it is slow and computationally expensive, which strongly limit its use in clinical scenarios. In this paper, an artificial neural network for effective and almost real-time breast imaging is proposed. First, a realistic breast-like phantom generator was developed for training the network. Subsequently, numerical analyses have been conducted for the optimisation and the performance evaluation of the approach. The results seem very promising in terms of recovery performance as well as for the computation burden.