 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FastGCL: Fast Self-Supervised Learning on Graphs via Contrastive Neighborhood Aggregation
May 02, 2022
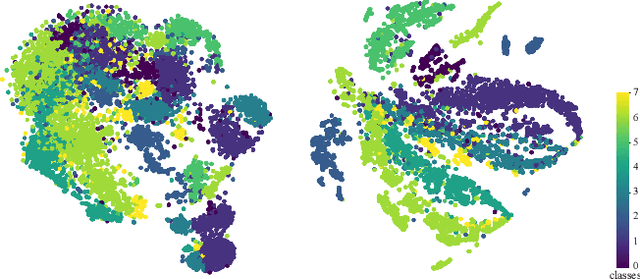
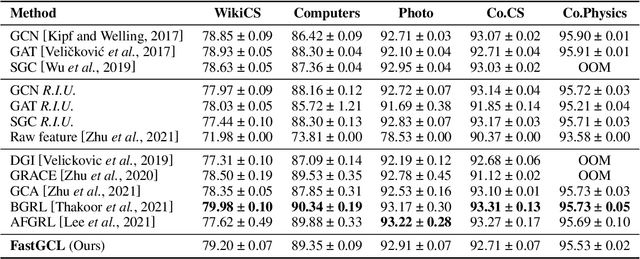
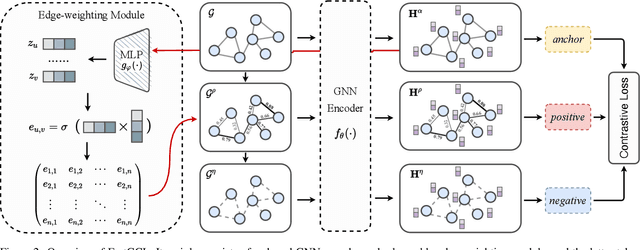
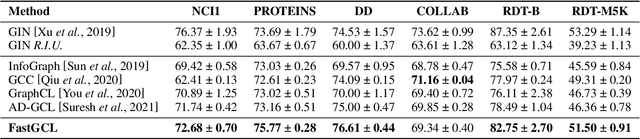
Graph contrastive learning (GCL), as a popular approach to graph self-supervised learning, has recently achieved a non-negligible effect. To achieve superior performance, the majority of existing GCL methods elaborate on graph data augmentation to construct appropriate contrastive pairs. However, existing methods place more emphasis on the complex graph data augmentation which requires extra time overhead, and pay less attention to developing contrastive schemes specific to encoder characteristics. We argue that a better contrastive scheme should be tailored to the characteristics of graph neural networks (e.g., neighborhood aggregation) and propose a simple yet effective method named FastGCL. Specifically, by constructing weighted-aggregated and non-aggregated neighborhood information as positive and negative samples respectively, FastGCL identifies the potential semantic information of data without disturbing the graph topology and node attributes, resulting in faster training and convergence speeds. Extensive experiments have been conducted on node classification and graph classification tasks, showing that FastGCL has competitive classification performance and significant training speedup compared to existing state-of-the-art methods.
db-A*: Discontinuity-bounded Search for Kinodynamic Mobile Robot Motion Planning
Mar 21, 2022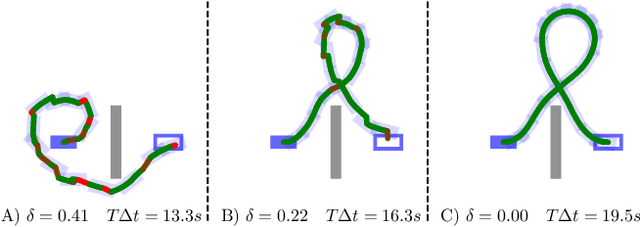
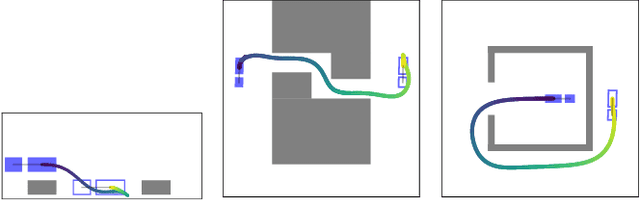
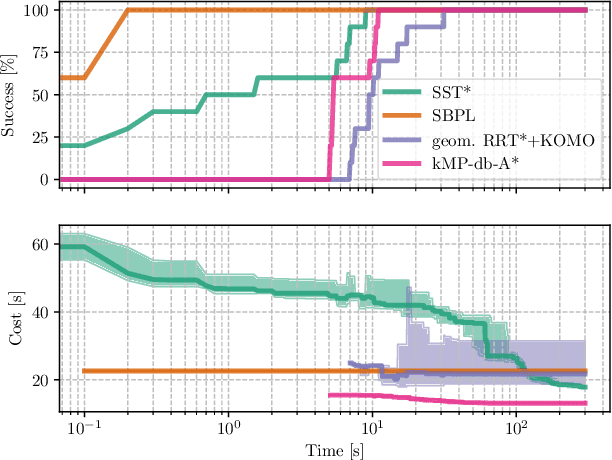
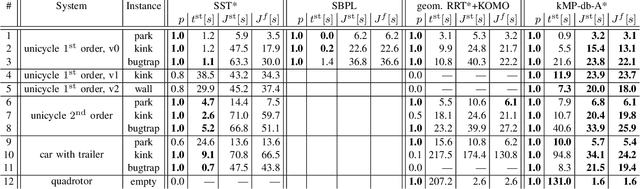
We consider time-optimal motion planning for dynamical systems that are translation-invariant, a property that holds for many mobile robots, such as differential-drives, cars, airplanes, and multirotors. Our key insight is that we can extend graph-search algorithms to the continuous case when used symbiotically with optimization. For the graph search, we introduce discontinuity-bounded A* (db-A*), a generalization of the A* algorithm that uses concepts and data structures from sampling-based planners. Db-A* reuses short trajectories, so-called motion primitives, as edges and allows a maximum user-specified discontinuity at the vertices. These trajectories are locally repaired with trajectory optimization, which also provides new improved motion primitives. Our novel kinodynamic motion planner, kMP-db-A*, has almost surely asymptotic optimal behavior and computes near-optimal solutions quickly. For our empirical validation, we provide the first benchmark that compares search-, sampling-, and optimization-based time-optimal motion planning on multiple dynamical systems in different settings. Compared to the baselines, kMP-db-A* consistently solves more problem instances, finds lower-cost initial solutions, and converges more quickly.
Time Series Anomaly Detection for Cyber-physical Systems via Neural System Identification and Bayesian Filtering
Jun 15, 2021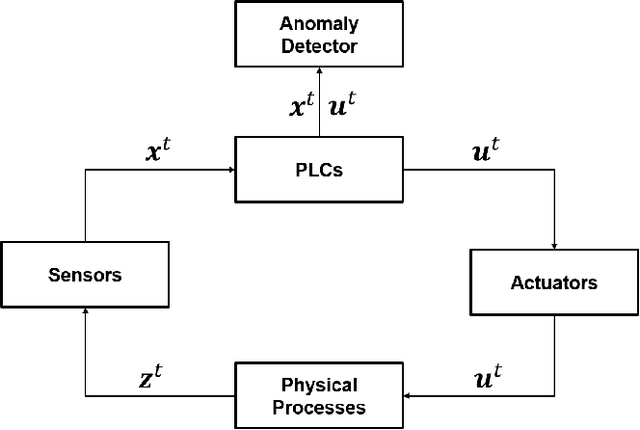

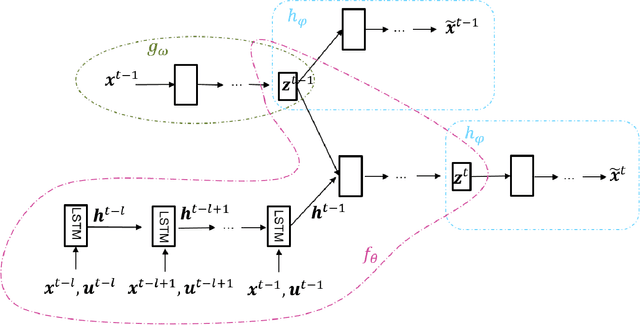
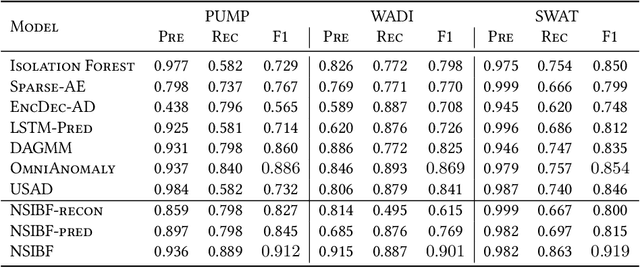
Recent advances in AIoT technologies have led to an increasing popularity of utilizing machine learning algorithms to detect operational failures for cyber-physical systems (CPS). In its basic form, an anomaly detection module monitors the sensor measurements and actuator states from the physical plant, and detects anomalies in these measurements to identify abnormal operation status. Nevertheless, building effective anomaly detection models for CPS is rather challenging as the model has to accurately detect anomalies in presence of highly complicated system dynamics and unknown amount of sensor noise. In this work, we propose a novel time series anomaly detection method called Neural System Identification and Bayesian Filtering (NSIBF) in which a specially crafted neural network architecture is posed for system identification, i.e., capturing the dynamics of CPS in a dynamical state-space model; then a Bayesian filtering algorithm is naturally applied on top of the "identified" state-space model for robust anomaly detection by tracking the uncertainty of the hidden state of the system recursively over time. We provide qualitative as well as quantitative experiments with the proposed method on a synthetic and three real-world CPS datasets, showing that NSIBF compares favorably to the state-of-the-art methods with considerable improvements on anomaly detection in CPS.
Robust Active Visual Perching with Quadrotors on Inclined Surfaces
Apr 05, 2022
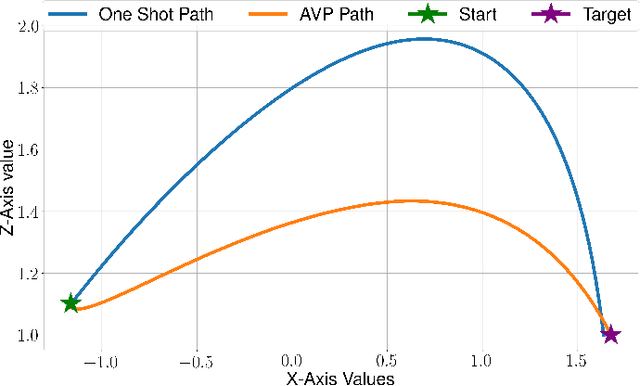
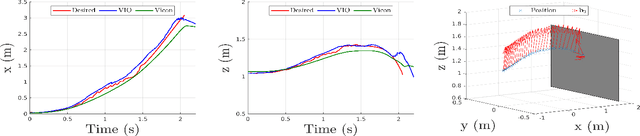
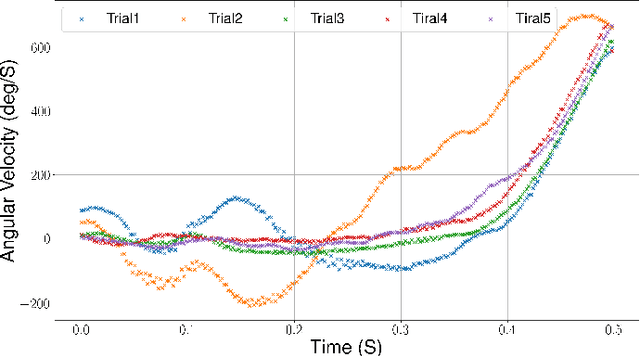
Autonomous Micro Aerial Vehicles are deployed for a variety tasks including surveillance and monitoring. Perching and staring allow the vehicle to monitor targets without flying, saving battery power and increasing the overall mission time without the need to frequently replace batteries. This paper addresses the Active Visual Perching (AVP) control problem to autonomously perch on inclined surfaces up to $90^\circ$. Our approach generates dynamically feasible trajectories to navigate and perch on a desired target location, while taking into account actuator and Field of View (FoV) constraints. By replanning in mid-flight, we take advantage of more accurate target localization increasing the perching maneuver's robustness to target localization or control errors. We leverage the Karush-Kuhn-Tucker (KKT) conditions to identify the compatibility between planning objectives and the visual sensing constraint during the planned maneuver. Furthermore, we experimentally identify the corresponding boundary conditions that maximizes the spatio-temporal target visibility during the perching maneuver. The proposed approach works on-board in real-time with significant computational constraints relying exclusively on cameras and an Inertial Measurement Unit (IMU). Experimental results validate the proposed approach and shows the higher success rate as well as increased target interception precision and accuracy with respect to a one-shot planning approach, while still retaining aggressive capabilities with flight envelopes that include large excursions from the hover position on inclined surfaces up to 90$^\circ$, angular speeds up to 750~deg/s, and accelerations up to 10~m/s$^2$.
Time-Invariance Coefficients Tests with the Adaptive Multi-Factor Model
Nov 09, 2020
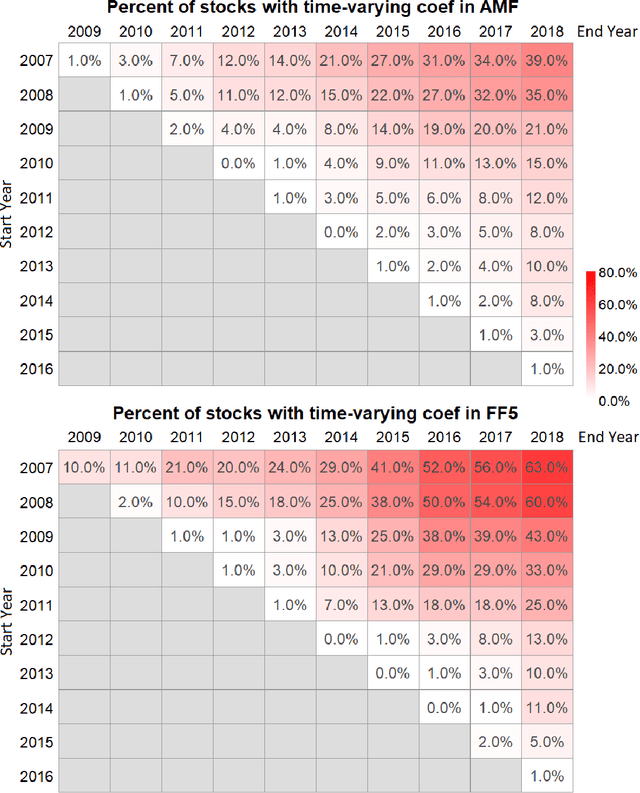
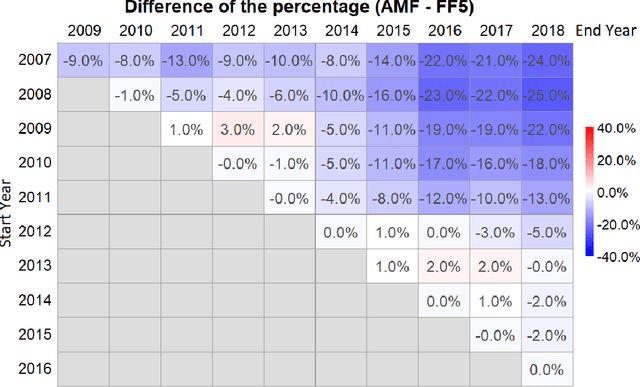
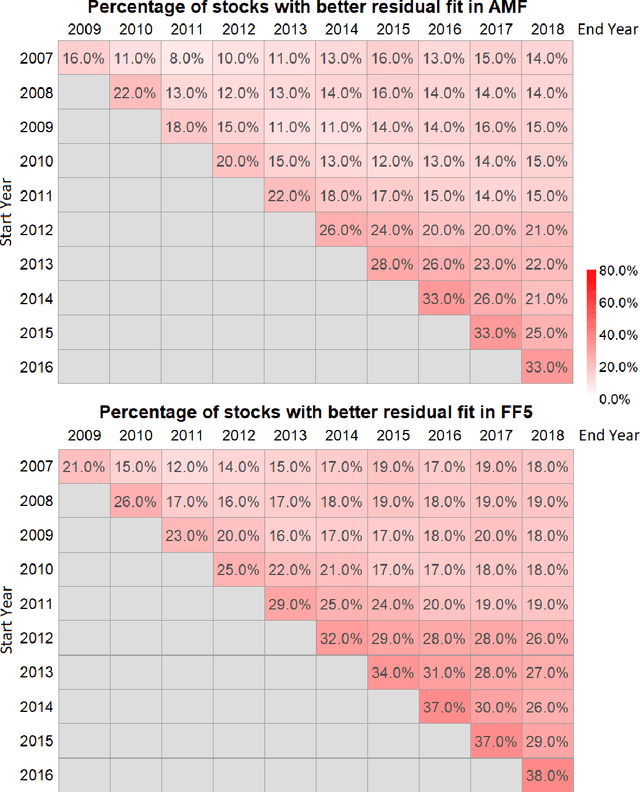
The purpose of this paper is to test the multi-factor beta model implied by the generalized arbitrage pricing theory (APT) and the Adaptive Multi-Factor (AMF) model with the Groupwise Interpretable Basis Selection (GIBS) algorithm, without imposing the exogenous assumption of constant betas. The intercept (arbitrage) tests validate both the AMF and the Fama-French 5-factor (FF5) model. We do the time-invariance tests for the betas for both the AMF model and the FF5 in various time periods. We show that for nearly all time periods with length less than 6 years, the beta coefficients are time-invariant for the AMF model, but not the FF5 model. The beta coefficients are time-varying for both AMF and FF5 models for longer time periods. Therefore, using the dynamic AMF model with a decent rolling window (such as 5 years) is more powerful and stable than the FF5 model.
HARNet: A Convolutional Neural Network for Realized Volatility Forecasting
May 16, 2022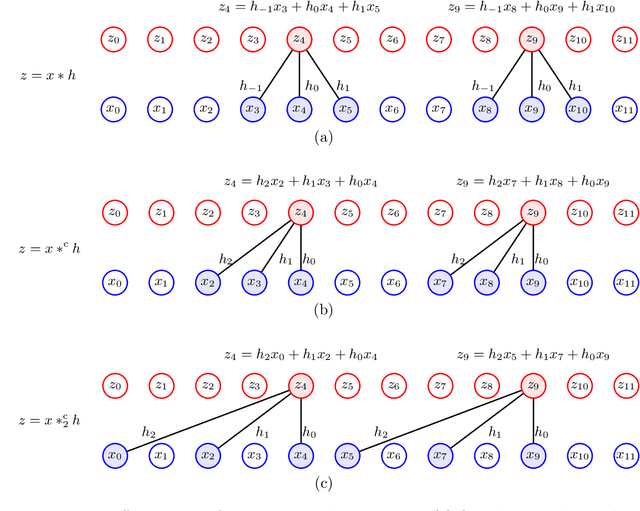

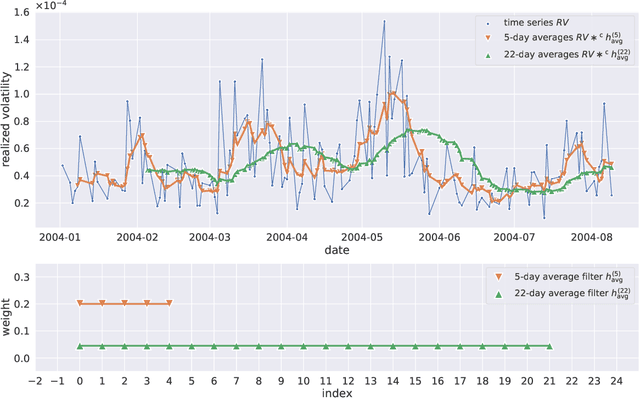
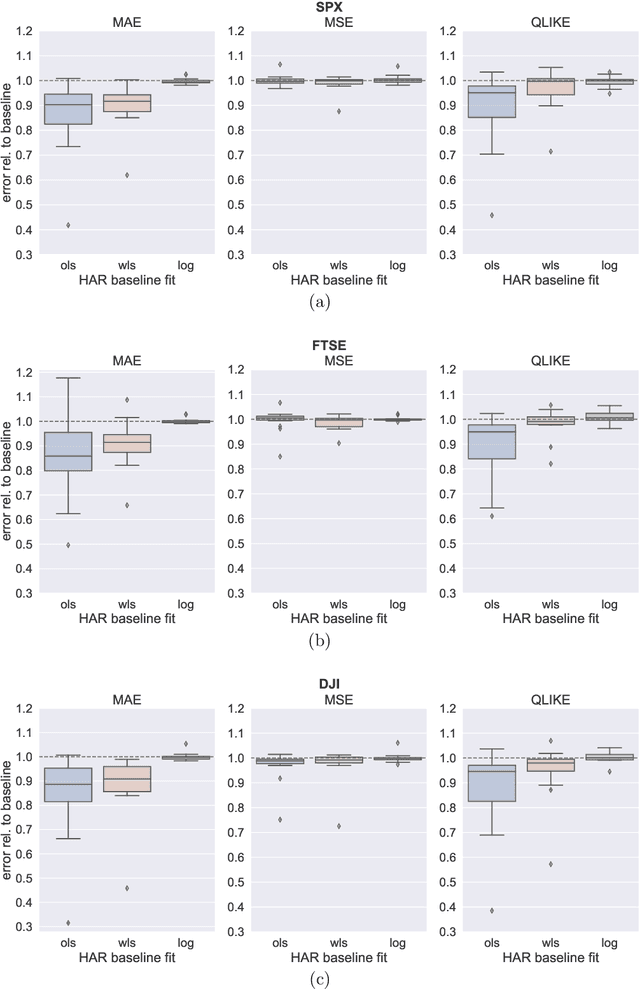
Despite the impressive success of deep neural networks in many application areas, neural network models have so far not been widely adopted in the context of volatility forecasting. In this work, we aim to bridge the conceptual gap between established time series approaches, such as the Heterogeneous Autoregressive (HAR) model, and state-of-the-art deep neural network models. The newly introduced HARNet is based on a hierarchy of dilated convolutional layers, which facilitates an exponential growth of the receptive field of the model in the number of model parameters. HARNets allow for an explicit initialization scheme such that before optimization, a HARNet yields identical predictions as the respective baseline HAR model. Particularly when considering the QLIKE error as a loss function, we find that this approach significantly stabilizes the optimization of HARNets. We evaluate the performance of HARNets with respect to three different stock market indexes. Based on this evaluation, we formulate clear guidelines for the optimization of HARNets and show that HARNets can substantially improve upon the forecasting accuracy of their respective HAR baseline models. In a qualitative analysis of the filter weights learnt by a HARNet, we report clear patterns regarding the predictive power of past information. Among information from the previous week, yesterday and the day before, yesterday's volatility makes by far the most contribution to today's realized volatility forecast. Moroever, within the previous month, the importance of single weeks diminishes almost linearly when moving further into the past.
Classification of Quasars, Galaxies, and Stars in the Mapping of the Universe Multi-modal Deep Learning
May 22, 2022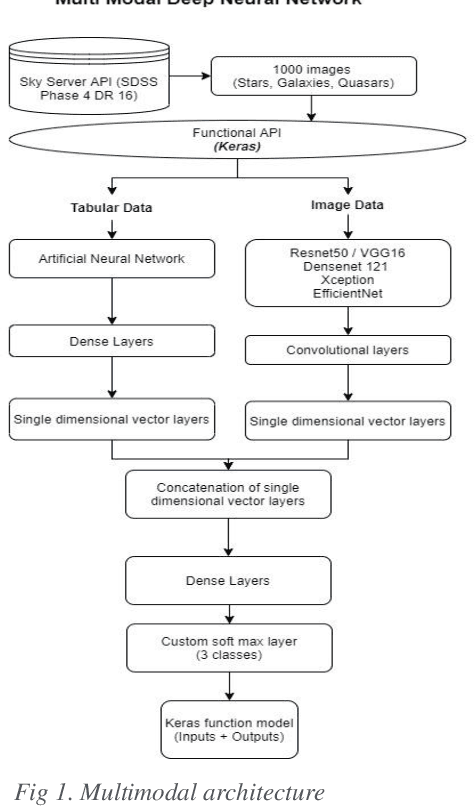
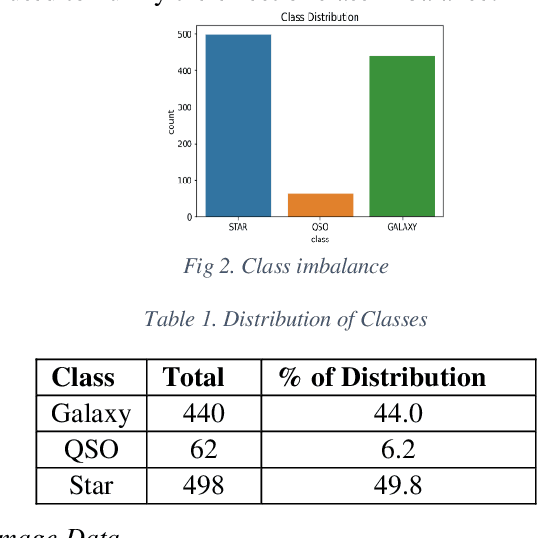
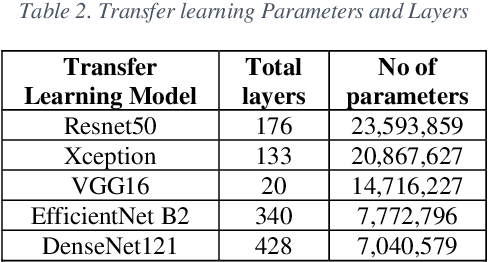

In this paper, the fourth version the Sloan Digital Sky Survey (SDSS-4), Data Release 16 dataset was used to classify the SDSS dataset into galaxies, stars, and quasars using machine learning and deep learning architectures. We efficiently utilize both image and metadata in tabular format to build a novel multi-modal architecture and achieve state-of-the-art results. In addition, our experiments on transfer learning using Imagenet weights on five different architectures (Resnet-50, DenseNet-121 VGG-16, Xception, and EfficientNet) reveal that freezing all layers and adding a final trainable layer may not be an optimal solution for transfer learning. It is hypothesized that higher the number of trainable layers, higher will be the training time and accuracy of predictions. It is also hypothesized that any subsequent increase in the number of training layers towards the base layers will not increase in accuracy as the pre trained lower layers only help in low level feature extraction which would be quite similar in all the datasets. Hence the ideal level of trainable layers needs to be identified for each model in respect to the number of parameters. For the tabular data, we compared classical machine learning algorithms (Logistic Regression, Random Forest, Decision Trees, Adaboost, LightGBM etc.,) with artificial neural networks. Our works shed new light on transfer learning and multi-modal deep learning architectures. The multi-modal architecture not only resulted in higher metrics (accuracy, precision, recall, F1 score) than models using only image data or tabular data. Furthermore, multi-modal architecture achieved the best metrics in lesser training epochs and improved the metrics on all classes.
Graphical Residual Flows
Apr 23, 2022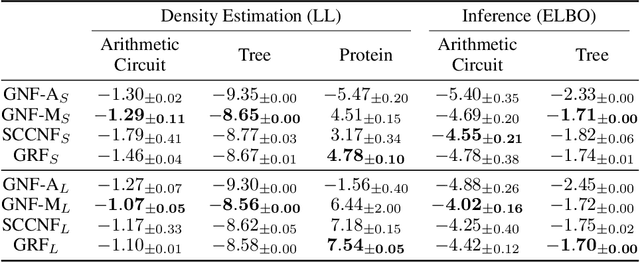
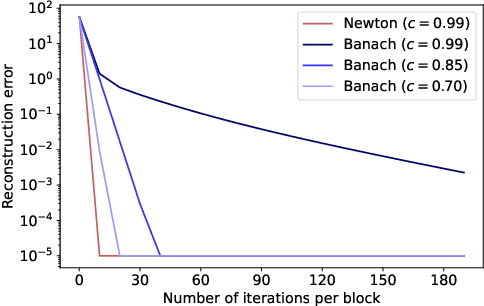
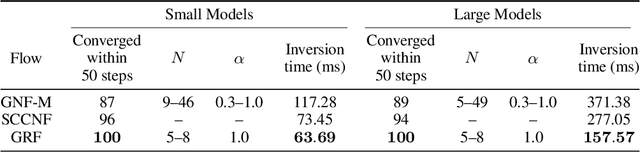
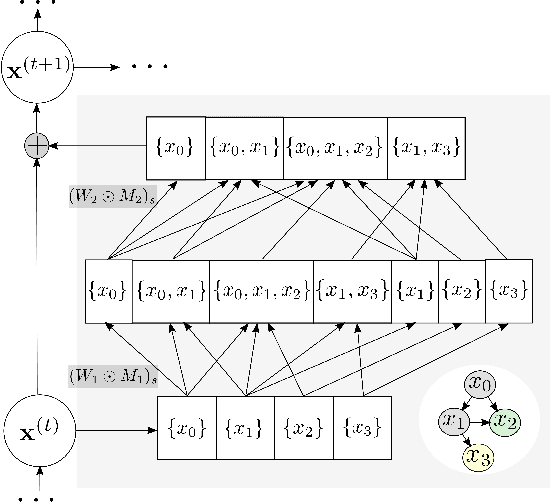
Graphical flows add further structure to normalizing flows by encoding non-trivial variable dependencies. Previous graphical flow models have focused primarily on a single flow direction: the normalizing direction for density estimation, or the generative direction for inference. However, to use a single flow to perform tasks in both directions, the model must exhibit stable and efficient flow inversion. This work introduces graphical residual flows, a graphical flow based on invertible residual networks. Our approach to incorporating dependency information in the flow, means that we are able to calculate the Jacobian determinant of these flows exactly. Our experiments confirm that graphical residual flows provide stable and accurate inversion that is also more time-efficient than alternative flows with similar task performance. Furthermore, our model provides performance competitive with other graphical flows for both density estimation and inference tasks.
Time-varying Gaussian Process Bandit Optimization with Non-constant Evaluation Time
Mar 11, 2020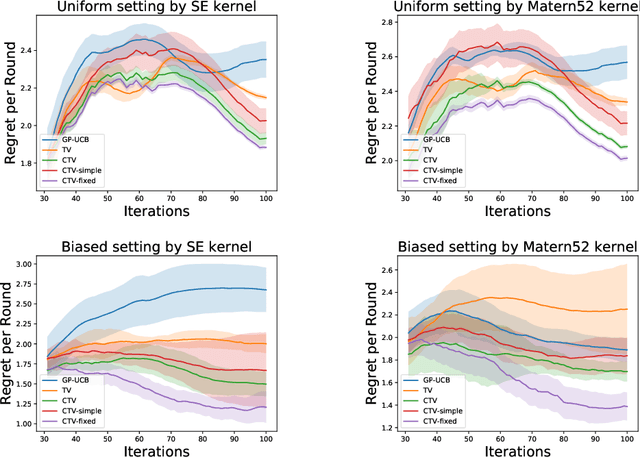
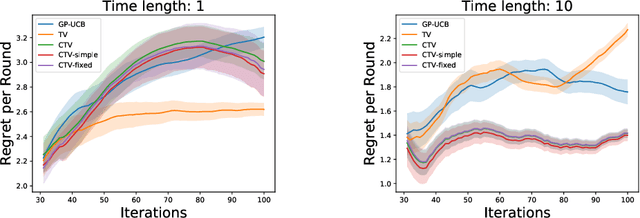
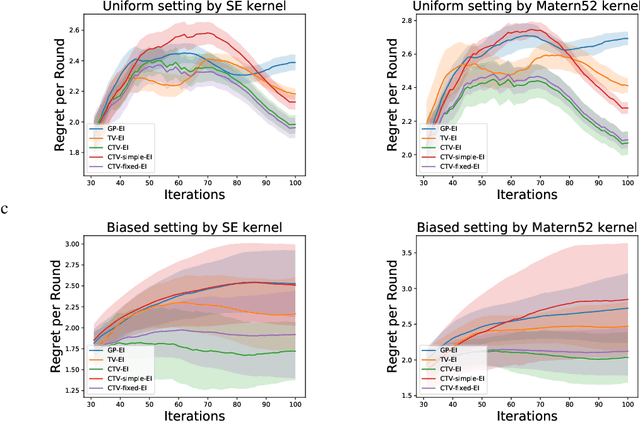
The Gaussian process bandit is a problem in which we want to find a maximizer of a black-box function with the minimum number of function evaluations. If the black-box function varies with time, then time-varying Bayesian optimization is a promising framework. However, a drawback with current methods is in the assumption that the evaluation time for every observation is constant, which can be unrealistic for many practical applications, e.g., recommender systems and environmental monitoring. As a result, the performance of current methods can be degraded when this assumption is violated. To cope with this problem, we propose a novel time-varying Bayesian optimization algorithm that can effectively handle the non-constant evaluation time. Furthermore, we theoretically establish a regret bound of our algorithm. Our bound elucidates that a pattern of the evaluation time sequence can hugely affect the difficulty of the problem. We also provide experimental results to validate the practical effectiveness of the proposed method.
ARCADE: Adversarially Regularized Convolutional Autoencoder for Network Anomaly Detection
May 13, 2022
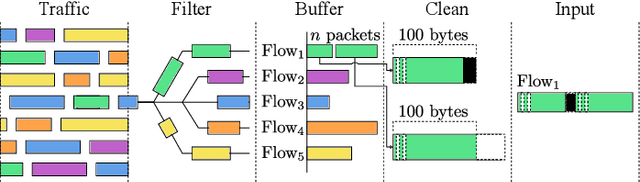
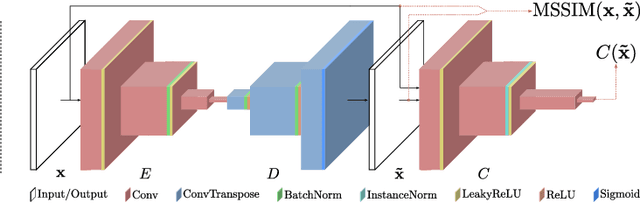

As the number of heterogenous IP-connected devices and traffic volume increase, so does the potential for security breaches. The undetected exploitation of these breaches can bring severe cybersecurity and privacy risks. In this paper, we present a practical unsupervised anomaly-based deep learning detection system called ARCADE (Adversarially Regularized Convolutional Autoencoder for unsupervised network anomaly DEtection). ARCADE exploits the property of 1D Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GAN) to automatically build a profile of the normal traffic based on a subset of raw bytes of a few initial packets of network flows so that potential network anomalies and intrusions can be effectively detected before they could cause any more damage to the network. A convolutional Autoencoder (AE) is proposed that suits online detection in resource-constrained environments, and can be easily improved for environments with higher computational capabilities. An adversarial training strategy is proposed to regularize and decrease the AE's capabilities to reconstruct network flows that are out of the normal distribution, and thereby improve its anomaly detection capabilities. The proposed approach is more effective than existing state-of-the-art deep learning approaches for network anomaly detection and significantly reduces detection time. The evaluation results show that the proposed approach is suitable for anomaly detection on resource-constrained hardware platforms such as Raspberry Pi.