 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prompt Consistency for Zero-Shot Task Generalization
Apr 29, 2022
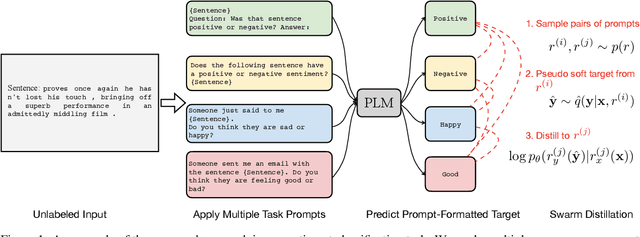
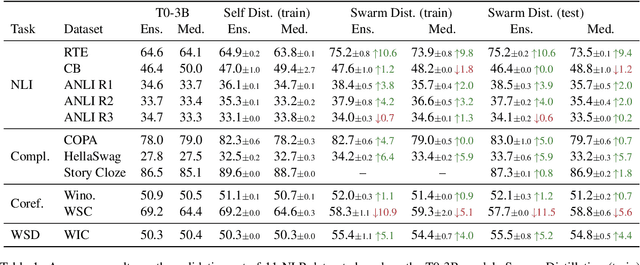
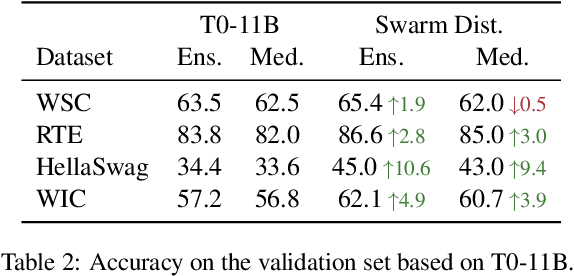
One of the most impressive results of recent NLP history is the ability of pre-trained language models to solve new tasks in a zero-shot setting. To achieve this, NLP tasks are framed as natural language prompts, generating a response indicating the predicted output. Nonetheless, the performance in such settings often lags far behind its supervised counterpart, suggesting a large space for potential improvement. In this paper, we explore methods to utilize unlabeled data to improve zero-shot performance. Specifically, we take advantage of the fact that multiple prompts can be used to specify a single task, and propose to regularize prompt consistency, encouraging consistent predictions over this diverse set of prompts. Our method makes it possible to fine-tune the model either with extra unlabeled training data, or directly on test input at inference time in an unsupervised manner. In experiments, our approach outperforms the state-of-the-art zero-shot learner, T0 (Sanh et al., 2022), on 9 out of 11 datasets across 4 NLP tasks by up to 10.6 absolute points in terms of accuracy. The gains are often attained with a small number of unlabeled examples.
On-demand compute reduction with stochastic wav2vec 2.0
Apr 25, 2022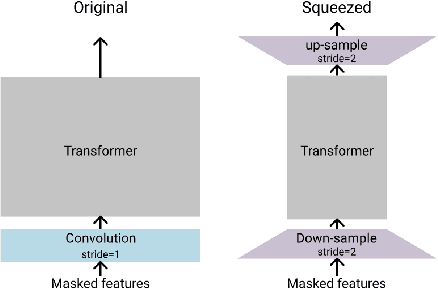
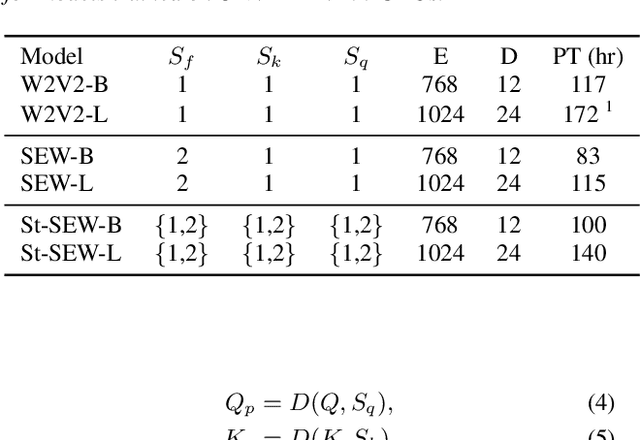
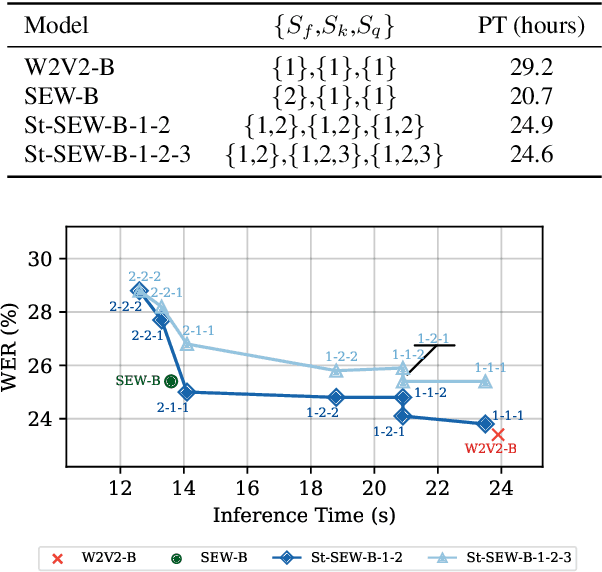
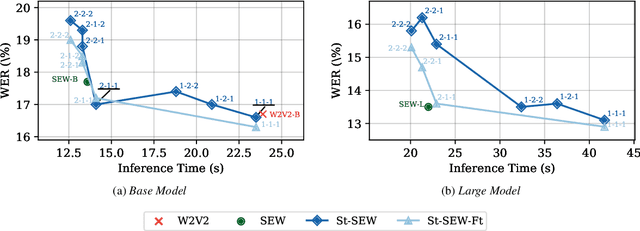
Squeeze and Efficient Wav2vec (SEW) is a recently proposed architecture that squeezes the input to the transformer encoder for compute efficient pre-training and inference with wav2vec 2.0 (W2V2) models. In this work, we propose stochastic compression for on-demand compute reduction for W2V2 models. As opposed to using a fixed squeeze factor, we sample it uniformly during training. We further introduce query and key-value pooling mechanisms that can be applied to each transformer layer for further compression. Our results for models pre-trained on 960h Librispeech dataset and fine-tuned on 10h of transcribed data show that using the same stochastic model, we get a smooth trade-off between word error rate (WER) and inference time with only marginal WER degradation compared to the W2V2 and SEW models trained for a specific setting. We further show that we can fine-tune the same stochastically pre-trained model to a specific configuration to recover the WER difference resulting in significant computational savings on pre-training models from scratch.
BARGAIN-MATCH: A Game Theoretical Approach for Resource Allocation and Task Offloading in Vehicular Edge Computing Networks
Mar 26, 2022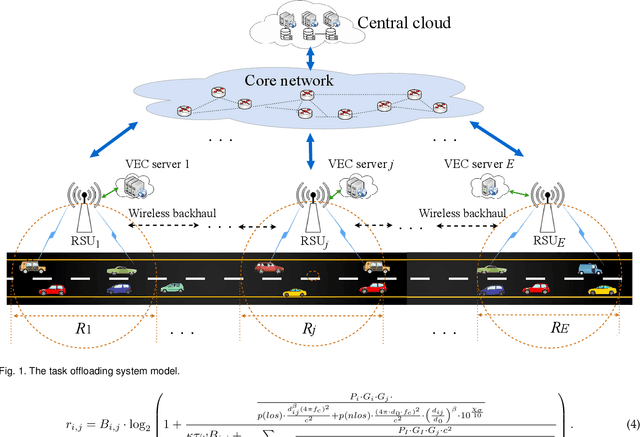
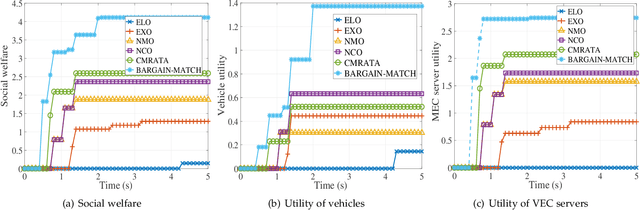
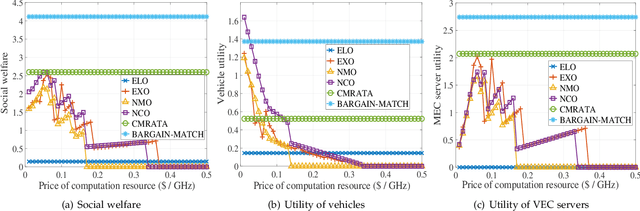
Vehicular edge computing (VEC) is emerging as a promising architecture of vehicular networks (VNs) by deploying the cloud computing resources at the edge of the VNs. This work aims to optimize resource allocation and task offloading in VEC networks. Specifically, we formulate a game theoretical resource allocation and task offloading problem (GTRATOP) that aims to maximize the system performance by jointly considering the incentive for cooperation, competition among vehicles, heterogeneity between VEC servers and vehicles, and inherent dynamic of VNs. Since the formulated GTRATOP is NP-hard, we propose an adaptive approach for resource allocation and task offloading in VEC networks by incorporating bargaining game and matching game, which is called BARGAIN-MATCH. First, for resource allocation, a bargaining game-based incentive is proposed to stimulate the vehicles and VEC servers to negotiate the optimal resource allocation and pricing decisions. Second, for task offloading, a many-to-one matching scheme is proposed to decide the optimal offloading strategies. Third, the dynamic and time-varying features are considered to adapt the strategies of BARGAIN-MATCH to the real-time VEC networks. Moreover, the BARGAIN-MATCH is proved to be stable and weak Pareto optimal. Simulation results demonstrate that the proposed BARGAIN-MATCH achieves superior system performance and efficiency compared to other methods, especially when the system workload is heavy.
Direct LiDAR-Inertial Odometry
Mar 18, 2022
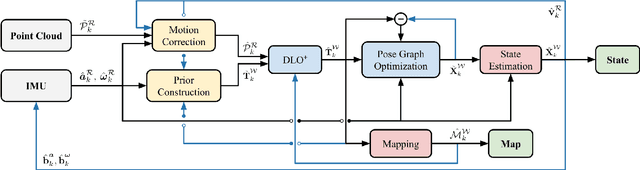
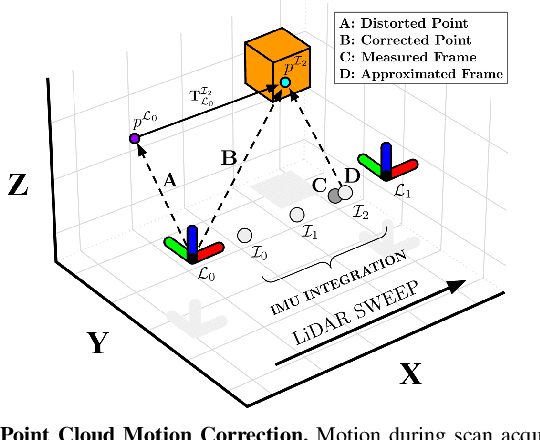
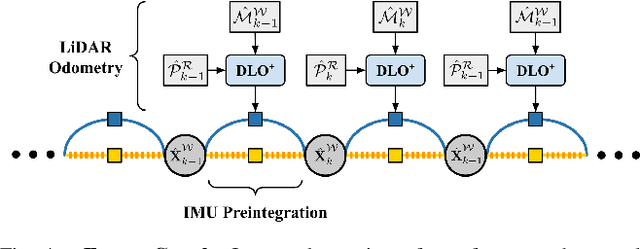
This paper proposes a new LiDAR-inertial odometry framework that generates accurate state estimates and detailed maps in real-time on resource-constrained mobile robots. Our Direct LiDAR-Inertial Odometry (DLIO) algorithm utilizes a hybrid architecture that combines the benefits of loosely-coupled and tightly-coupled IMU integration to enhance reliability and real-time performance while improving accuracy. The proposed architecture has two key elements. The first is a fast keyframe-based LiDAR scan-matcher that builds an internal map by registering dense point clouds to a local submap with a translational and rotational prior generated by a nonlinear motion model. The second is a factor graph and high-rate propagator that fuses the output of the scan-matcher with preintegrated IMU measurements for up-to-date pose, velocity, and bias estimates. These estimates enable us to accurately deskew the next point cloud using a nonlinear kinematic model for precise motion correction, in addition to initializing the next scan-to-map optimization prior. We demonstrate DLIO's superior localization accuracy, map quality, and lower computational overhead by comparing it to the state-of-the-art using multiple benchmark, public, and self-collected datasets on both consumer and hobby-grade hardware.
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Apr 14, 2022
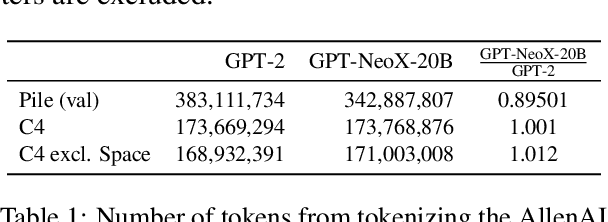
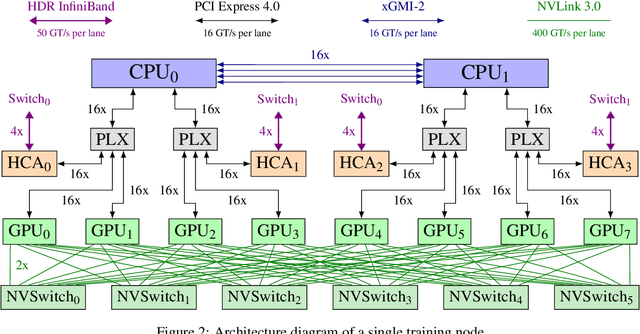

We introduce GPT-NeoX-20B, a 20 billion parameter autoregressive language model trained on the Pile, whose weights will be made freely and openly available to the public through a permissive license. It is, to the best of our knowledge, the largest dense autoregressive model that has publicly available weights at the time of submission. In this work, we describe \model{}'s architecture and training and evaluate its performance on a range of language-understanding, mathematics, and knowledge-based tasks. We find that GPT-NeoX-20B is a particularly powerful few-shot reasoner and gains far more in performance when evaluated five-shot than similarly sized GPT-3 and FairSeq models. We open-source the training and evaluation code, as well as the model weights, at https://github.com/EleutherAI/gpt-neox.
Efficient Localness Transformer for Smart Sensor-Based Energy Disaggregation
Mar 29, 2022


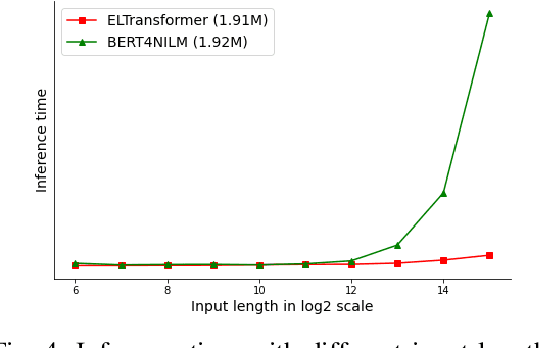
Modern smart sensor-based energy management systems leverage non-intrusive load monitoring (NILM) to predict and optimize appliance load distribution in real-time. NILM, or energy disaggregation, refers to the decomposition of electricity usage conditioned on the aggregated power signals (i.e., smart sensor on the main channel). Based on real-time appliance power prediction using sensory technology, energy disaggregation has great potential to increase electricity efficiency and reduce energy expenditure. With the introduction of transformer models, NILM has achieved significant improvements in predicting device power readings. Nevertheless, transformers are less efficient due to O(l^2) complexity w.r.t. sequence length l. Moreover, transformers can fail to capture local signal patterns in sequence-to-point settings due to the lack of inductive bias in local context. In this work, we propose an efficient localness transformer for non-intrusive load monitoring (ELTransformer). Specifically, we leverage normalization functions and switch the order of matrix multiplication to approximate self-attention and reduce computational complexity. Additionally, we introduce localness modeling with sparse local attention heads and relative position encodings to enhance the model capacity in extracting short-term local patterns. To the best of our knowledge, ELTransformer is the first NILM model that addresses computational complexity and localness modeling in NILM. With extensive experiments and quantitative analyses, we demonstrate the efficiency and effectiveness of the the proposed ELTransformer with considerable improvements compared to state-of-the-art baselines.
Blind Equalization and Channel Estimation in Coherent Optical Communications Using Variational Autoencoders
Apr 25, 2022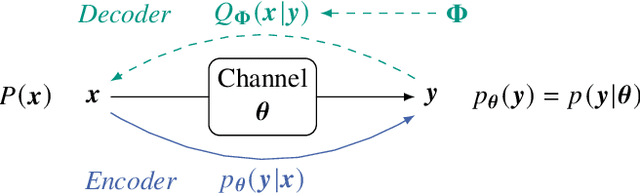
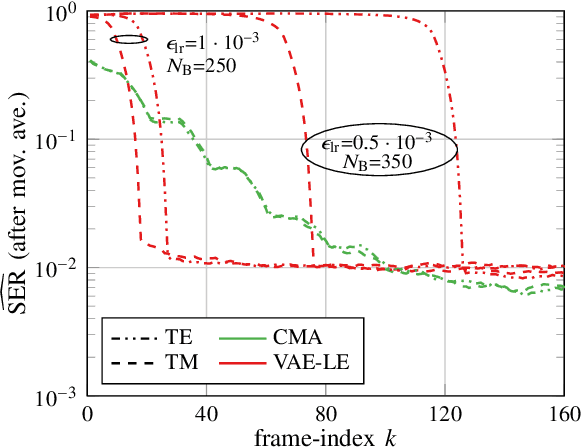
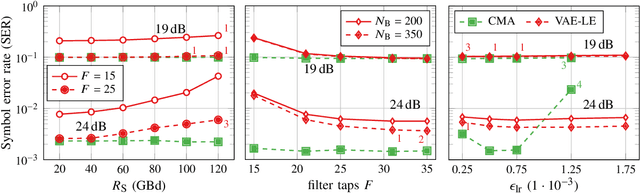
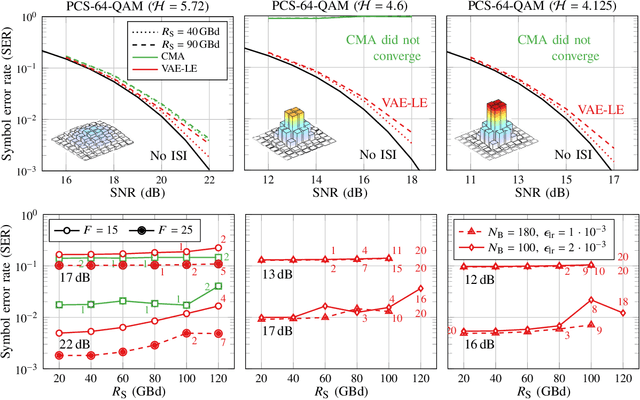
We investigate the potential of adaptive blind equalizers based on variational inference for carrier recovery in optical communications. These equalizers are based on a low-complexity approximation of maximum likelihood channel estimation. We generalize the concept of variational autoencoder (VAE) equalizers to higher order modulation formats encompassing probabilistic constellation shaping (PCS), ubiquitous in optical communications, oversampling at the receiver, and dual-polarization transmission. Besides black-box equalizers based on convolutional neural networks, we propose a model-based equalizer based on a linear butterfly filter and train the filter coefficients using the variational inference paradigm. As a byproduct, the VAE also provides a reliable channel estimation. We analyze the VAE in terms of performance and flexibility over a classical additive white Gaussian noise (AWGN) channel with inter-symbol interference (ISI) and over a dispersive linear optical dual-polarization channel. We show that it can extend the application range of blind adaptive equalizers by outperforming the state-of-the-art constant-modulus algorithm (CMA) for PCS for both fixed but also time-varying channels. The evaluation is accompanied with a hyperparameter analysis.
Information Retrieval in Friction Stir Welding of Aluminum Alloys by using Natural Language Processing based Algorithms
Apr 25, 2022

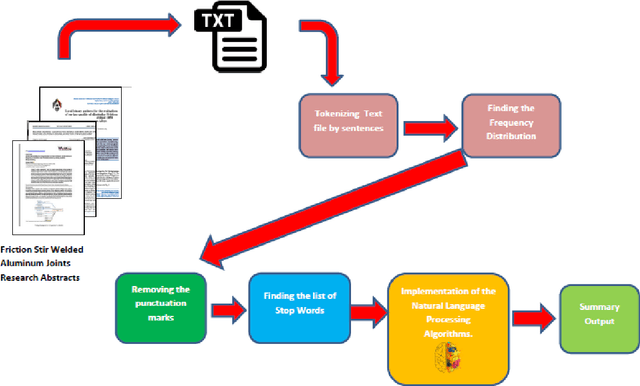
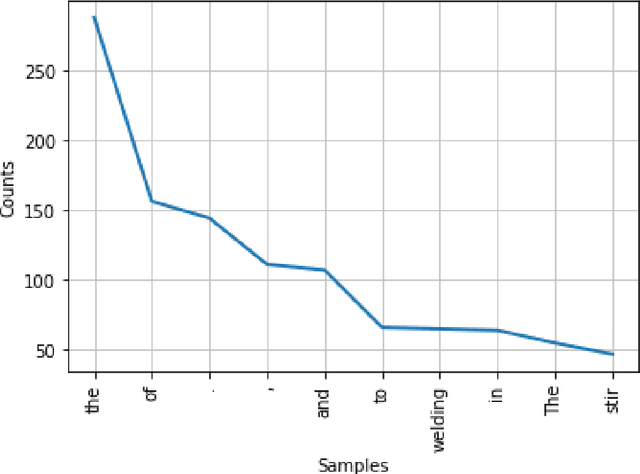
Text summarization is a technique for condensing a big piece of text into a few key elements that give a general impression of the content. When someone requires a quick and precise summary of a large amount of information, it becomes vital. If done manually, summarizing text can be costly and time-consuming. Natural Language Processing (NLP) is the sub-division of Artificial Intelligence that narrows down the gap between technology and human cognition by extracting the relevant information from the pile of data. In the present work, scientific information regarding the Friction Stir Welding of Aluminum alloys was collected from the abstract of scholarly research papers. For extracting the relevant information from these research abstracts four Natural Language Processing based algorithms i.e. Latent Semantic Analysis (LSA), Luhn Algorithm, Lex Rank Algorithm, and KL-Algorithm were used. In order to evaluate the accuracy score of these algorithms, Recall-Oriented Understudy for Gisting Evaluation (ROUGE) was used. The results showed that the Luhn Algorithm resulted in the highest f1-Score of 0.413 in comparison to other algorithms.
Message Flow Analysis with Complex Causal Links for Distributed ROS 2 Systems
Apr 25, 2022
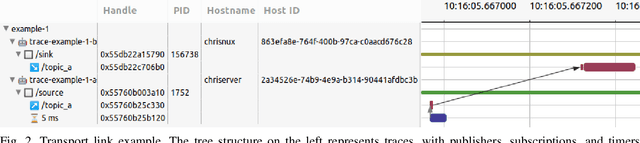

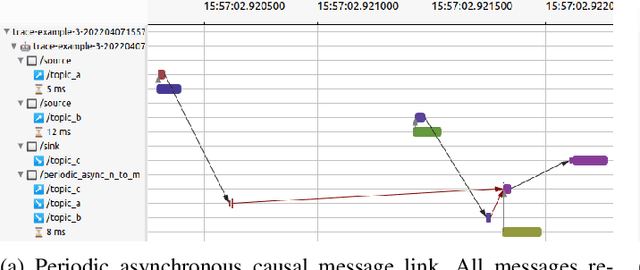
Distributed robotic systems rely heavily on publish-subscribe frameworks, such as ROS, to efficiently implement modular computation graphs. The ROS 2 executor, a high-level task scheduler which handles messages internally, is a performance bottleneck. In previous work, we presented ros2_tracing, a framework with instrumentation and tools for real-time tracing of ROS 2. We now extend on that instrumentation and leverage the tracing tools to propose an analysis and visualization of the flow of messages across distributed ROS 2 systems. Our proposed method detects one-to-many and many-to-many causal links between input and output messages, including indirect causal links through simple user-level annotations. We validate our method on both synthetic and real robotic systems, and demonstrate its low runtime overhead. Moreover, the underlying intermediate execution representation database can be further leveraged to extract additional metrics and high-level results. This can provide valuable timing and scheduling information to further study and improve the ROS 2 executor as well as optimize any ROS 2 system. The source code is available at: https://github.com/christophebedard/ros2-message-flow-analysis.
Topologically-Aware Deformation Fields for Single-View 3D Reconstruction
May 12, 2022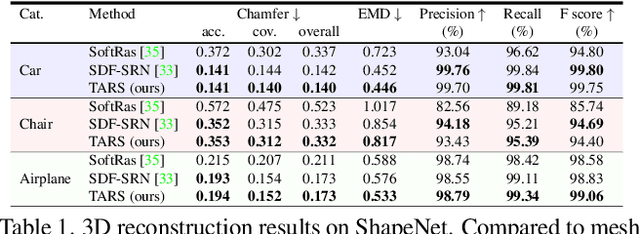
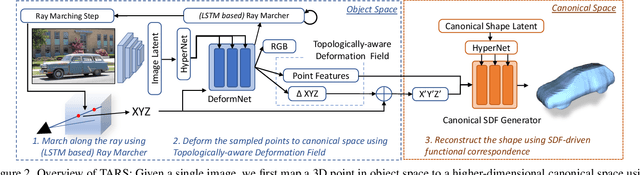

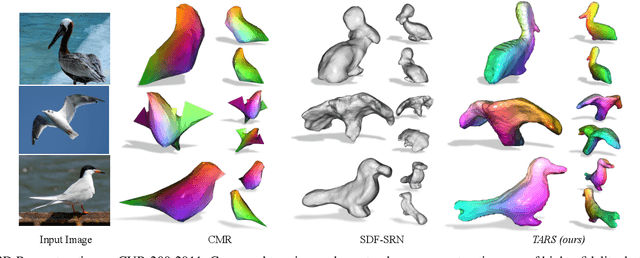
We present a new framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs. Result videos and code at https://shivamduggal4.github.io/tars-3D/