 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A reproducible experimental survey on biomedical sentence similarity: a string-based method sets the state of the art
May 18, 2022
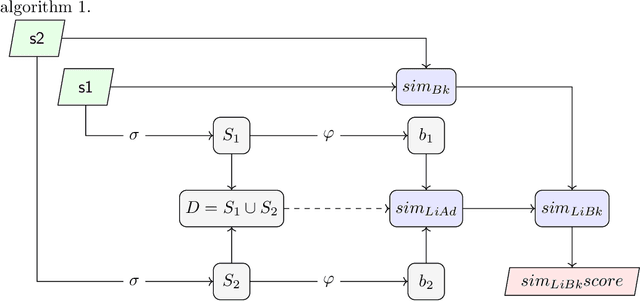



This registered report introduces the largest, and for the first time, reproducible experimental survey on biomedical sentence similarity with the following aims: (1) to elucidate the state of the art of the problem; (2) to solve some reproducibility problems preventing the evaluation of most of current methods; (3) to evaluate several unexplored sentence similarity methods; (4) to evaluate an unexplored benchmark, called Corpus-Transcriptional-Regulation; (5) to carry out a study on the impact of the pre-processing stages and Named Entity Recognition (NER) tools on the performance of the sentence similarity methods; and finally, (6) to bridge the lack of reproducibility resources for methods and experiments in this line of research. Our experimental survey is based on a single software platform that is provided with a detailed reproducibility protocol and dataset as supplementary material to allow the exact replication of all our experiments. In addition, we introduce a new aggregated string-based sentence similarity method, called LiBlock, together with eight variants of current ontology-based methods and a new pre-trained word embedding model trained on the full-text articles in the PMC-BioC corpus. Our experiments show that our novel string-based measure sets the new state of the art on the sentence similarity task in the biomedical domain and significantly outperforms all the methods evaluated herein, except one ontology-based method. Likewise, our experiments confirm that the pre-processing stages, and the choice of the NER tool, have a significant impact on the performance of the sentence similarity methods. We also detail some drawbacks and limitations of current methods, and warn on the need of refining the current benchmarks. Finally, a noticeable finding is that our new string-based method significantly outperforms all state-of-the-art Machine Learning models evaluated herein.
Physical Modeling using Recurrent Neural Networks with Fast Convolutional Layers
Apr 21, 2022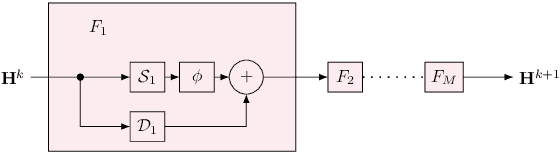

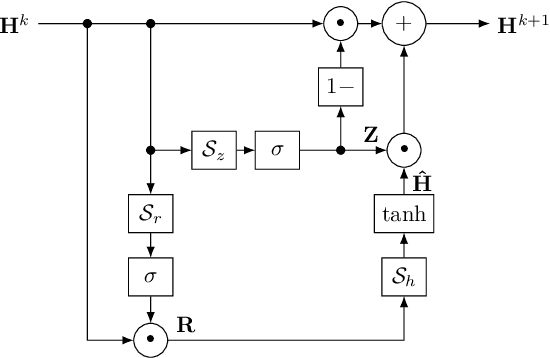
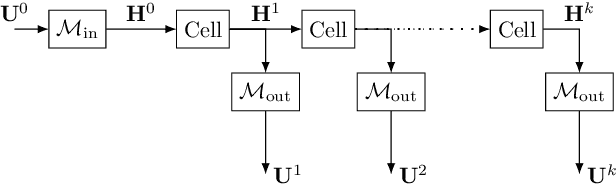
Discrete-time modeling of acoustic, mechanical and electrical systems is a prominent topic in the musical signal processing literature. Such models are mostly derived by discretizing a mathematical model, given in terms of ordinary or partial differential equations, using established techniques. Recent work has applied the techniques of machine-learning to construct such models automatically from data for the case of systems which have lumped states described by scalar values, such as electrical circuits. In this work, we examine how similar techniques are able to construct models of systems which have spatially distributed rather than lumped states. We describe several novel recurrent neural network structures, and show how they can be thought of as an extension of modal techniques. As a proof of concept, we generate synthetic data for three physical systems and show that the proposed network structures can be trained with this data to reproduce the behavior of these systems.
Predicting vacant parking space availability zone-wisely: a graph based spatio-temporal prediction approach
May 03, 2022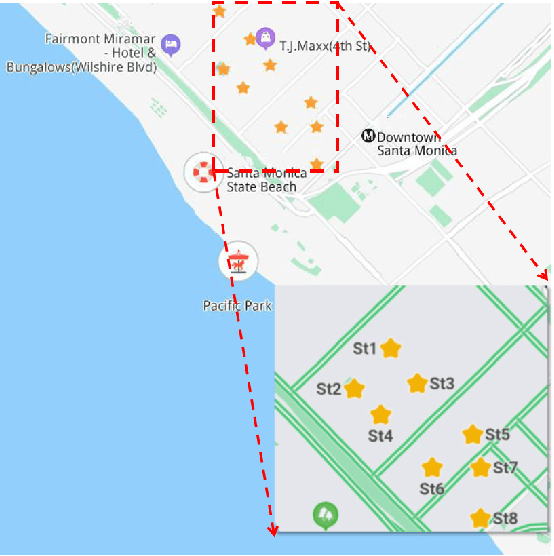
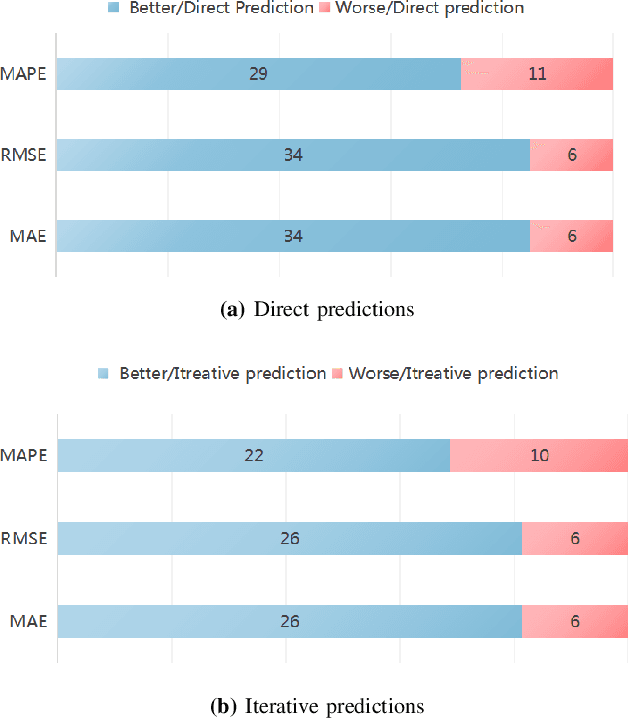
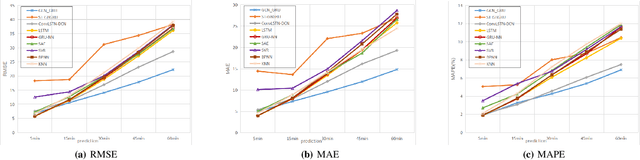
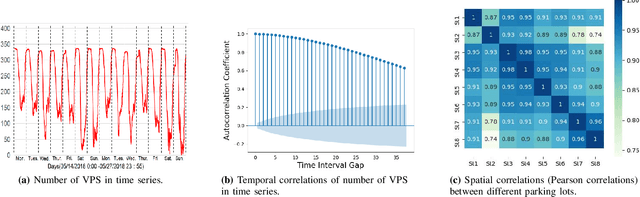
Vacant parking space (VPS) prediction is one of the key issues of intelligent parking guidance systems. Accurately predicting VPS information plays a crucial role in intelligent parking guidance systems, which can help drivers find parking space quickly, reducing unnecessary waste of time and excessive environmental pollution. Through the simple analysis of historical data, we found that there not only exists a obvious temporal correlation in each parking lot, but also a clear spatial correlation between different parking lots. In view of this, this paper proposed a graph data-based model ST-GBGRU (Spatial-Temporal Graph Based Gated Recurrent Unit), the number of VPSs can be predicted both in short-term (i.e., within 30 min) and in long-term (i.e., over 30min). On the one hand, the temporal correlation of historical VPS data is extracted by GRU, on the other hand, the spatial correlation of historical VPS data is extracted by GCN inside GRU. Two prediction methods, namely direct prediction and iterative prediction, are combined with the proposed model. Finally, the prediction model is applied to predict the number VPSs of 8 public parking lots in Santa Monica. The results show that in the short-term and long-term prediction tasks, ST-GBGRU model can achieve high accuracy and have good application prospects.
OTExtSum: Extractive Text Summarisation with Optimal Transport
Apr 21, 2022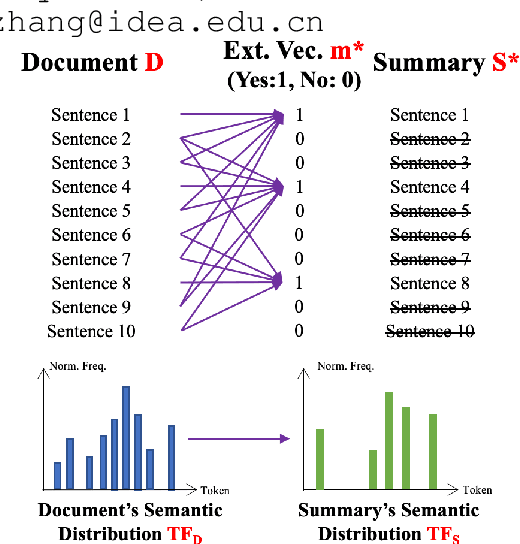
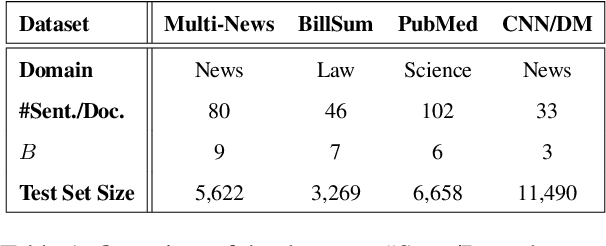
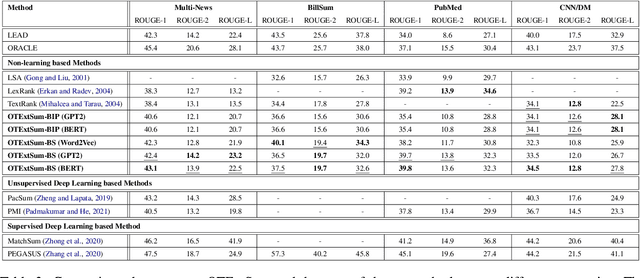

Extractive text summarisation aims to select salient sentences from a document to form a short yet informative summary. While learning-based methods have achieved promising results, they have several limitations, such as dependence on expensive training and lack of interpretability. Therefore, in this paper, we propose a novel non-learning-based method by for the first time formulating text summarisation as an Optimal Transport (OT) problem, namely Optimal Transport Extractive Summariser (OTExtSum). Optimal sentence extraction is conceptualised as obtaining an optimal summary that minimises the transportation cost to a given document regarding their semantic distributions. Such a cost is defined by the Wasserstein distance and used to measure the summary's semantic coverage of the original document. Comprehensive experiments on four challenging and widely used datasets - MultiNews, PubMed, BillSum, and CNN/DM demonstrate that our proposed method outperforms the state-of-the-art non-learning-based methods and several recent learning-based methods in terms of the ROUGE metric.
Viko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
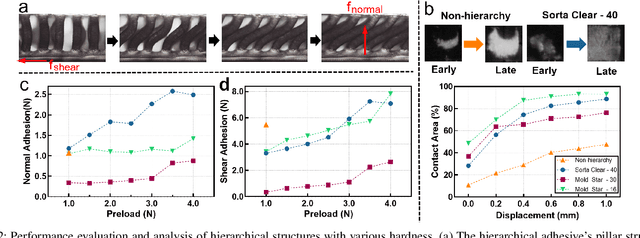
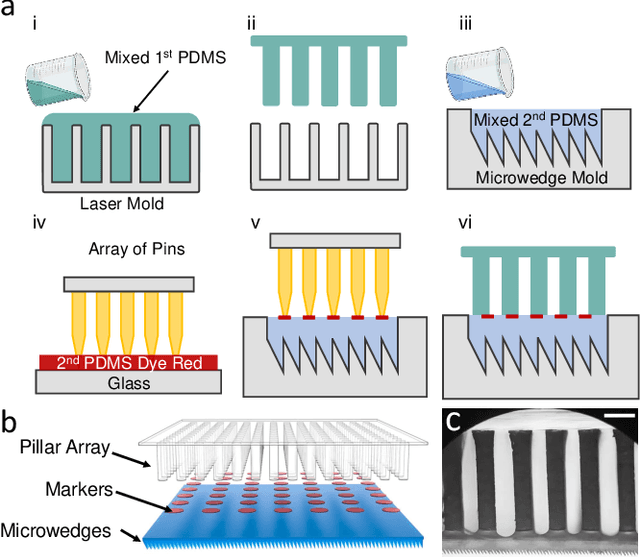
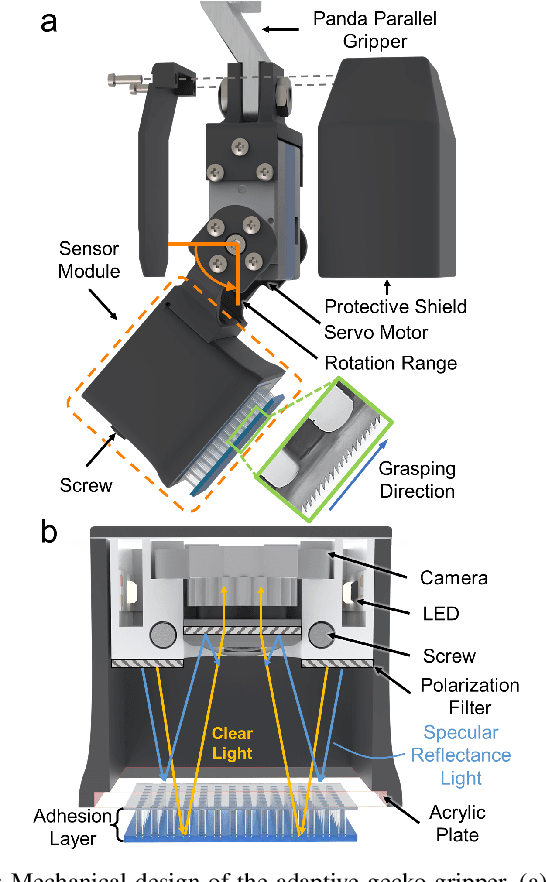
Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.
Identifying and Characterizing Active Citizens who Refute Misinformation in Social Media
Apr 21, 2022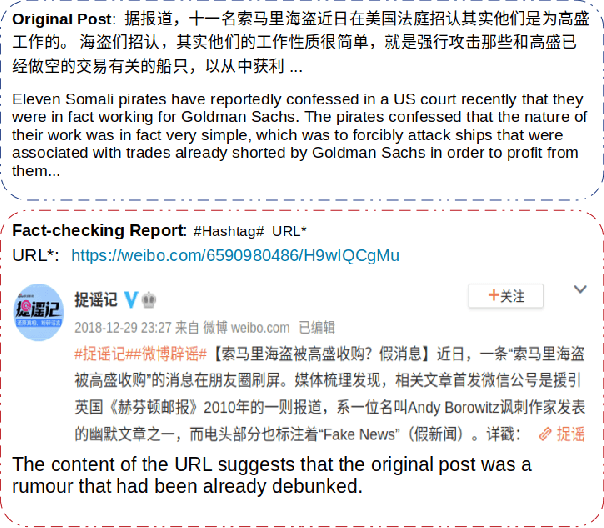
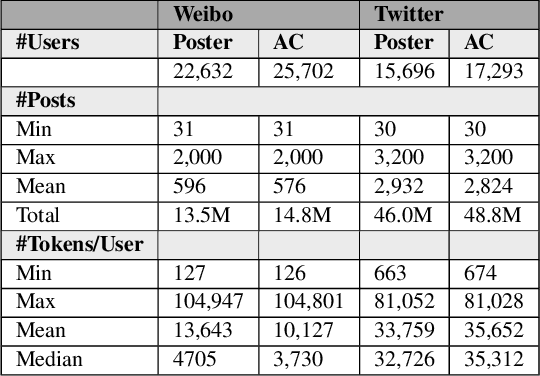
The phenomenon of misinformation spreading in social media has developed a new form of active citizens who focus on tackling the problem by refuting posts that might contain misinformation. Automatically identifying and characterizing the behavior of such active citizens in social media is an important task in computational social science for complementing studies in misinformation analysis. In this paper, we study this task across different social media platforms (i.e., Twitter and Weibo) and languages (i.e., English and Chinese) for the first time. To this end, (1) we develop and make publicly available a new dataset of Weibo users mapped into one of the two categories (i.e., misinformation posters or active citizens); (2) we evaluate a battery of supervised models on our new Weibo dataset and an existing Twitter dataset which we repurpose for the task; and (3) we present an extensive analysis of the differences in language use between the two user categories.
Self-Supervised Test-Time Learning for Reading Comprehension
Mar 20, 2021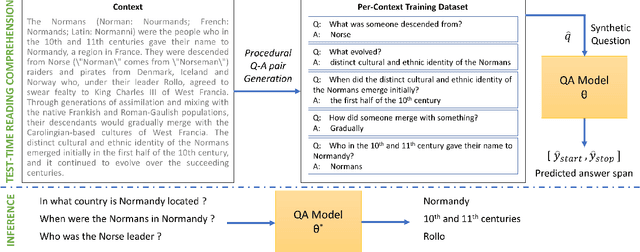
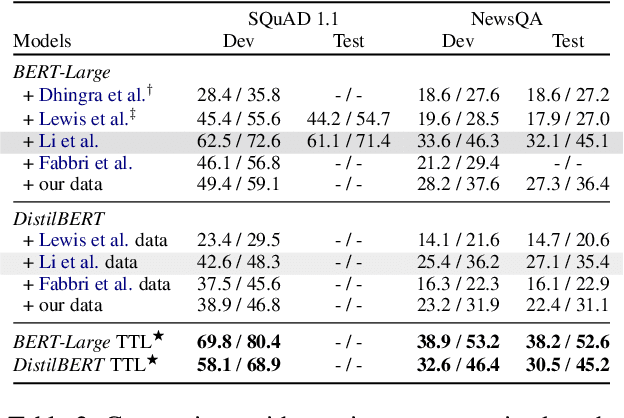
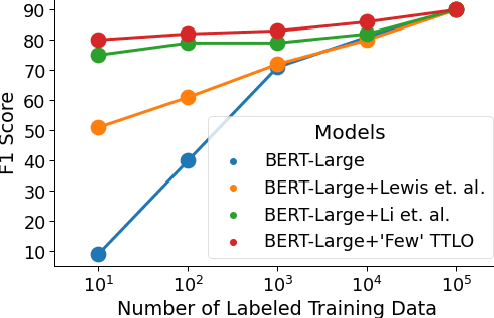
Recent work on unsupervised question answering has shown that models can be trained with procedurally generated question-answer pairs and can achieve performance competitive with supervised methods. In this work, we consider the task of unsupervised reading comprehension and present a method that performs "test-time learning" (TTL) on a given context (text passage), without requiring training on large-scale human-authored datasets containing \textit{context-question-answer} triplets. This method operates directly on a single test context, uses self-supervision to train models on synthetically generated question-answer pairs, and then infers answers to unseen human-authored questions for this context. Our method achieves accuracies competitive with fully supervised methods and significantly outperforms current unsupervised methods. TTL methods with a smaller model are also competitive with the current state-of-the-art in unsupervised reading comprehension.
Prompt Consistency for Zero-Shot Task Generalization
Apr 29, 2022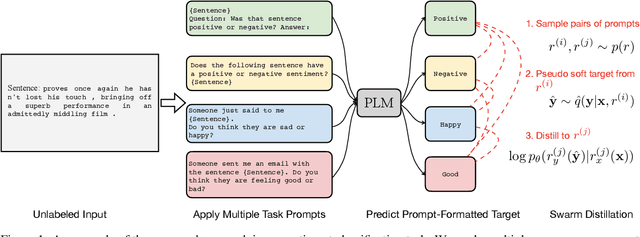
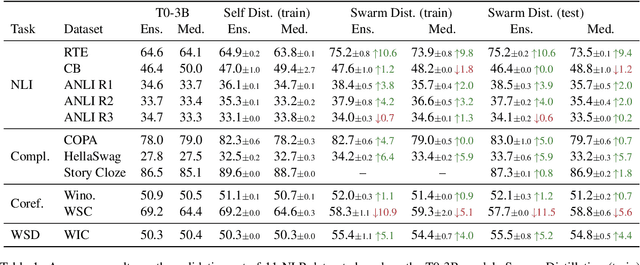
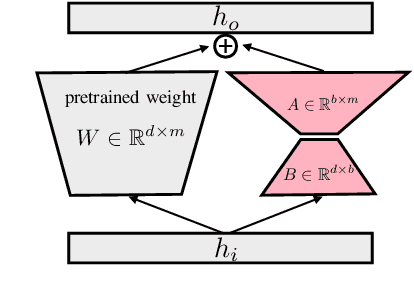
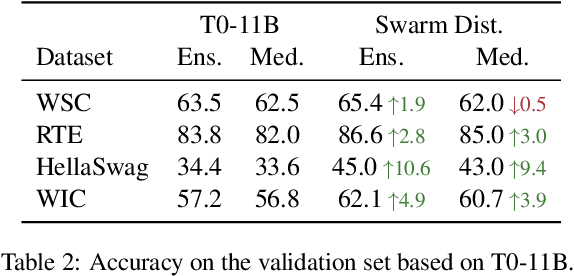
One of the most impressive results of recent NLP history is the ability of pre-trained language models to solve new tasks in a zero-shot setting. To achieve this, NLP tasks are framed as natural language prompts, generating a response indicating the predicted output. Nonetheless, the performance in such settings often lags far behind its supervised counterpart, suggesting a large space for potential improvement. In this paper, we explore methods to utilize unlabeled data to improve zero-shot performance. Specifically, we take advantage of the fact that multiple prompts can be used to specify a single task, and propose to regularize prompt consistency, encouraging consistent predictions over this diverse set of prompts. Our method makes it possible to fine-tune the model either with extra unlabeled training data, or directly on test input at inference time in an unsupervised manner. In experiments, our approach outperforms the state-of-the-art zero-shot learner, T0 (Sanh et al., 2022), on 9 out of 11 datasets across 4 NLP tasks by up to 10.6 absolute points in terms of accuracy. The gains are often attained with a small number of unlabeled examples.
On-demand compute reduction with stochastic wav2vec 2.0
Apr 25, 2022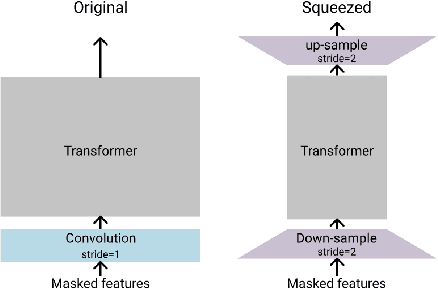
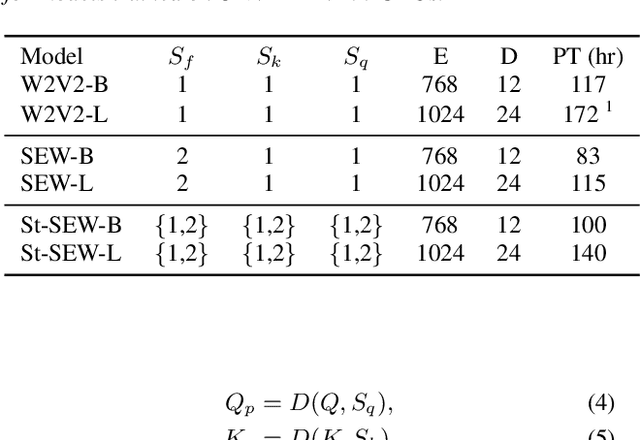
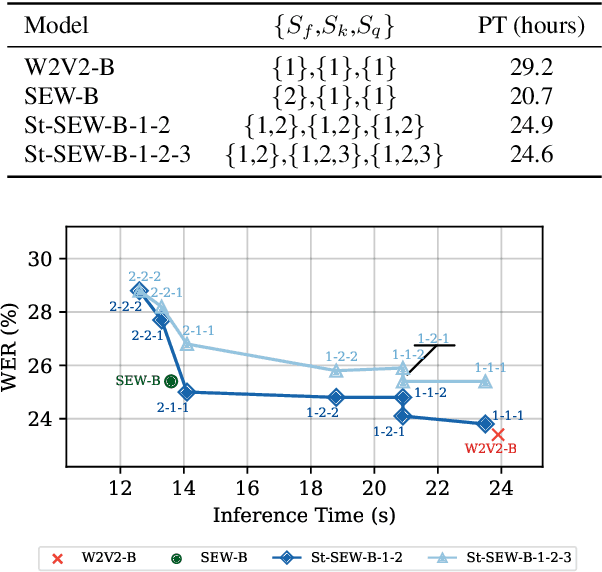
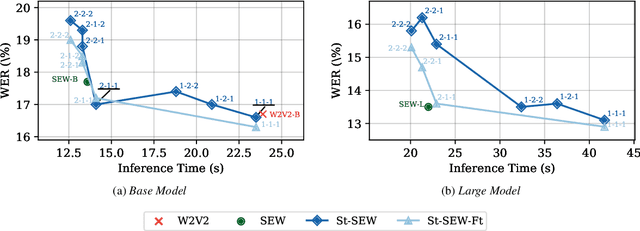
Squeeze and Efficient Wav2vec (SEW) is a recently proposed architecture that squeezes the input to the transformer encoder for compute efficient pre-training and inference with wav2vec 2.0 (W2V2) models. In this work, we propose stochastic compression for on-demand compute reduction for W2V2 models. As opposed to using a fixed squeeze factor, we sample it uniformly during training. We further introduce query and key-value pooling mechanisms that can be applied to each transformer layer for further compression. Our results for models pre-trained on 960h Librispeech dataset and fine-tuned on 10h of transcribed data show that using the same stochastic model, we get a smooth trade-off between word error rate (WER) and inference time with only marginal WER degradation compared to the W2V2 and SEW models trained for a specific setting. We further show that we can fine-tune the same stochastically pre-trained model to a specific configuration to recover the WER difference resulting in significant computational savings on pre-training models from scratch.
Finite-Sample Analysis for Two Time-scale Non-linear TDC with General Smooth Function Approximation
Apr 07, 2021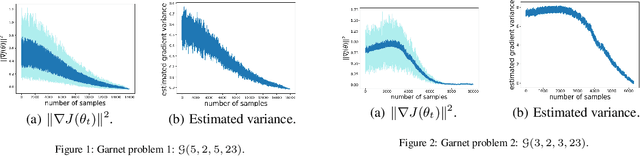
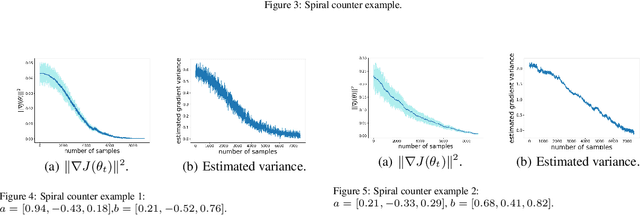
Temporal-difference learning with gradient correction (TDC) is a two time-scale algorithm for policy evaluation in reinforcement learning. This algorithm was initially proposed with linear function approximation, and was later extended to the one with general smooth function approximation. The asymptotic convergence for the on-policy setting with general smooth function approximation was established in [bhatnagar2009convergent], however, the finite-sample analysis remains unsolved due to challenges in the non-linear and two-time-scale update structure, non-convex objective function and the time-varying projection onto a tangent plane. In this paper, we develop novel techniques to explicitly characterize the finite-sample error bound for the general off-policy setting with i.i.d.\ or Markovian samples, and show that it converges as fast as $\mathcal O(1/\sqrt T)$ (up to a factor of $\mathcal O(\log T)$). Our approach can be applied to a wide range of value-based reinforcement learning algorithms with general smooth function approximation.