 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modelling Evolutionary and Stationary User Preferences for Temporal Sets Prediction
Apr 13, 2022
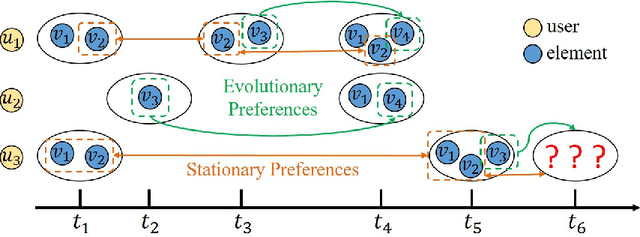

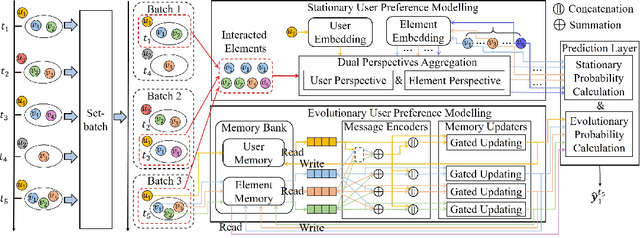

Given a sequence of sets, where each set is associated with a timestamp and contains an arbitrary number of elements, the task of temporal sets prediction aims to predict the elements in the subsequent set. Previous studies for temporal sets prediction mainly capture each user's evolutionary preference by learning from his/her own sequence. Although insightful, we argue that: 1) the collaborative signals latent in different users' sequences are essential but have not been exploited; 2) users also tend to show stationary preferences while existing methods fail to consider. To this end, we propose an integrated learning framework to model both the evolutionary and the stationary preferences of users for temporal sets prediction, which first constructs a universal sequence by chronologically arranging all the user-set interactions, and then learns on each user-set interaction. In particular, for each user-set interaction, we first design an evolutionary user preference modelling component to track the user's time-evolving preference and exploit the latent collaborative signals among different users. This component maintains a memory bank to store memories of the related user and elements, and continuously updates their memories based on the currently encoded messages and the past memories. Then, we devise a stationary user preference modelling module to discover each user's personalized characteristics according to the historical sequence, which adaptively aggregates the previously interacted elements from dual perspectives with the guidance of the user's and elements' embeddings. Finally, we develop a set-batch algorithm to improve the model efficiency, which can create time-consistent batches in advance and achieve 3.5x training speedups on average. Experiments on real-world datasets demonstrate the effectiveness and good interpretability of our approach.
Neural System Level Synthesis: Learning over All Stabilizing Policies for Nonlinear Systems
Mar 22, 2022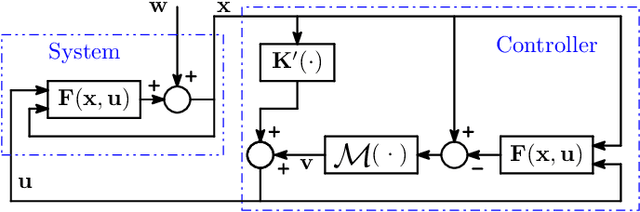

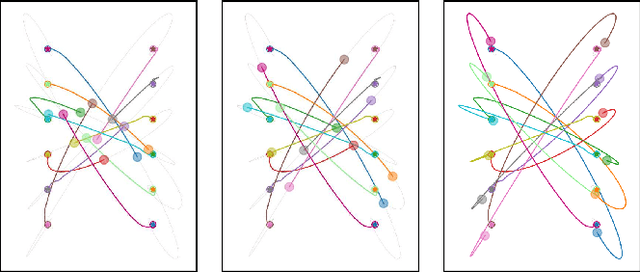
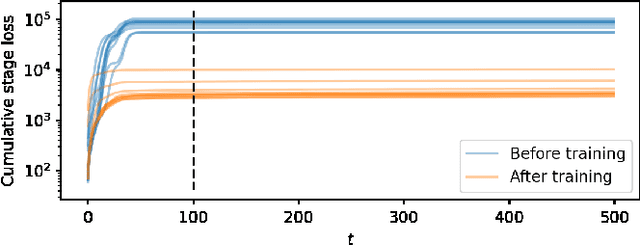
We address the problem of designing stabilizing control policies for nonlinear systems in discrete-time, while minimizing an arbitrary cost function. When the system is linear and the cost is convex, the System Level Synthesis (SLS) approach offers an exact solution based on convex programming. Beyond this case, a globally optimal solution cannot be found in a tractable way, in general. In this paper, we develop a parametrization of all and only the control policies stabilizing a given time-varying nonlinear system in terms of the combined effect of 1) a strongly stabilizing base controller and 2) a stable SLS operator to be freely designed. Based on this result, we propose a Neural SLS (Neur-SLS) approach guaranteeing closed-loop stability during and after parameter optimization, without requiring any constraints to be satisfied. We exploit recent Deep Neural Network (DNN) models based on Recurrent Equilibrium Networks (RENs) to learn over a rich class of nonlinear stable operators, and demonstrate the effectiveness of the proposed approach in numerical examples.
NPU-BOLT: A Dataset for Bolt Object Detection in Natural Scene Images
May 25, 2022



Bolt joints are very common and important in engineering structures. Due to extreme service environment and load factors, bolts often get loose or even disengaged. To real-time or timely detect the loosed or disengaged bolts is an urgent need in practical engineering, which is critical to keep structural safety and service life. In recent years, many bolt loosening detection methods using deep learning and machine learning techniques have been proposed and are attracting more and more attention. However, most of these studies use bolt images captured in laboratory for deep leaning model training. The images are obtained in a well-controlled light, distance, and view angle conditions. Also, the bolted structures are well designed experimental structures with brand new bolts and the bolts are exposed without any shelter nearby. It is noted that in practical engineering, the above well controlled lab conditions are not easy realized and the real bolt images often have blur edges, oblique perspective, partial occlusion and indistinguishable colors etc., which make the trained models obtained in laboratory conditions loss their accuracy or fails. Therefore, the aim of this study is to develop a dataset named NPU-BOLT for bolt object detection in natural scene images and open it to researchers for public use and further development. In the first version of the dataset, it contains 337 samples of bolt joints images mainly in the natural environment, with image data sizes ranging from 400*400 to 6000*4000, totaling approximately 1275 bolt targets. The bolt targets are annotated into four categories named blur bolt, bolt head, bolt nut and bolt side. The dataset is tested with advanced object detection models including yolov5, Faster-RCNN and CenterNet. The effectiveness of the dataset is validated.
Learning Disentangled Textual Representations via Statistical Measures of Similarity
May 07, 2022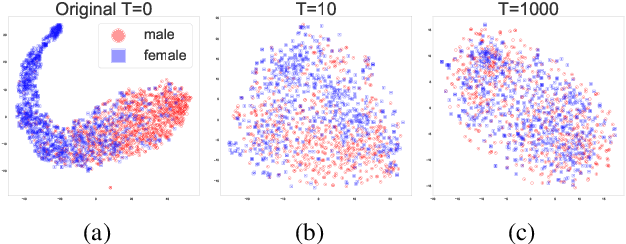
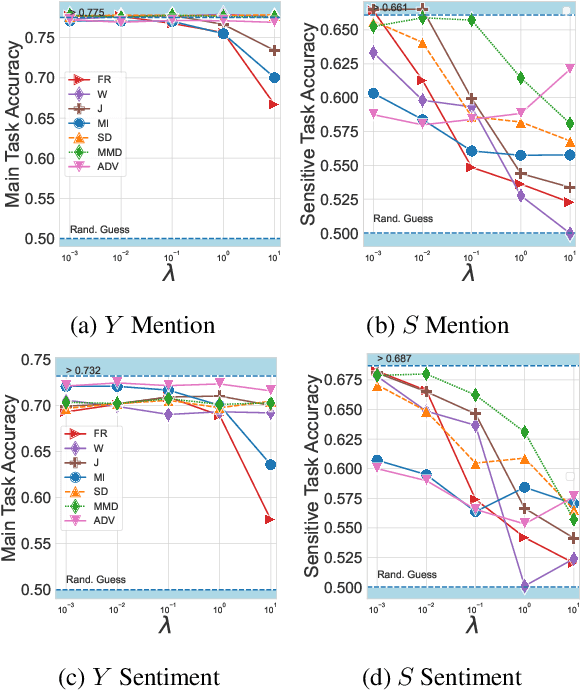
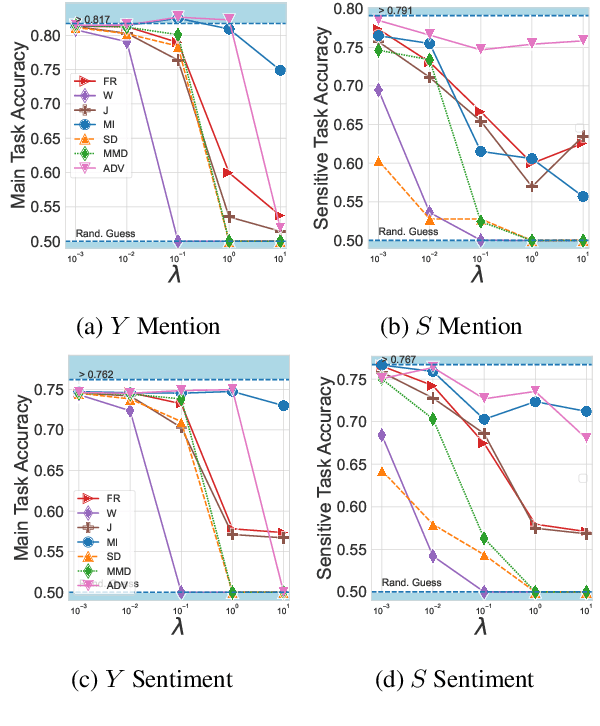
When working with textual data, a natural application of disentangled representations is fair classification where the goal is to make predictions without being biased (or influenced) by sensitive attributes that may be present in the data (e.g., age, gender or race). Dominant approaches to disentangle a sensitive attribute from textual representations rely on learning simultaneously a penalization term that involves either an adversarial loss (e.g., a discriminator) or an information measure (e.g., mutual information). However, these methods require the training of a deep neural network with several parameter updates for each update of the representation model. As a matter of fact, the resulting nested optimization loop is both time consuming, adding complexity to the optimization dynamic, and requires a fine hyperparameter selection (e.g., learning rates, architecture). In this work, we introduce a family of regularizers for learning disentangled representations that do not require training. These regularizers are based on statistical measures of similarity between the conditional probability distributions with respect to the sensitive attributes. Our novel regularizers do not require additional training, are faster and do not involve additional tuning while achieving better results both when combined with pretrained and randomly initialized text encoders.
Generating Reliable Process Event Streams and Time Series Data based on Neural Networks
Mar 09, 2021
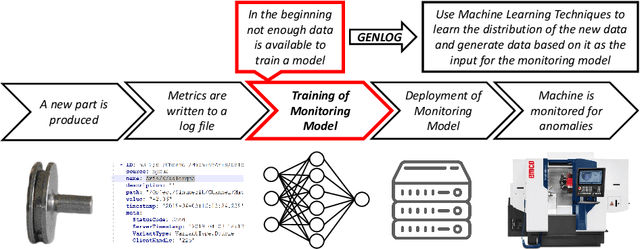

Domains such as manufacturing and medicine crave for continuous monitoring and analysis of their processes, especially in combination with time series as produced by sensors. Time series data can be exploited to, for example, explain and predict concept drifts during runtime. Generally, a certain data volume is required in order to produce meaningful analysis results. However, reliable data sets are often missing, for example, if event streams and times series data are collected separately, in case of a new process, or if it is too expensive to obtain a sufficient data volume. Additional challenges arise with preparing time series data from multiple event sources, variations in data collection frequency, and concept drift. This paper proposes the GENLOG approach to generate reliable event and time series data that follows the distribution of the underlying input data set. GENLOG employs data resampling and enables the user to select different parts of the log data to orchestrate the training of a recurrent neural network for stream generation. The generated data is sampled back to its original sample rate and is embedded into a template representing the log data format it originated from. Overall, GENLOG can boost small data sets and consequently the application of online process mining.
Digital Twins for Dynamic Management of Blockchain Systems
Apr 26, 2022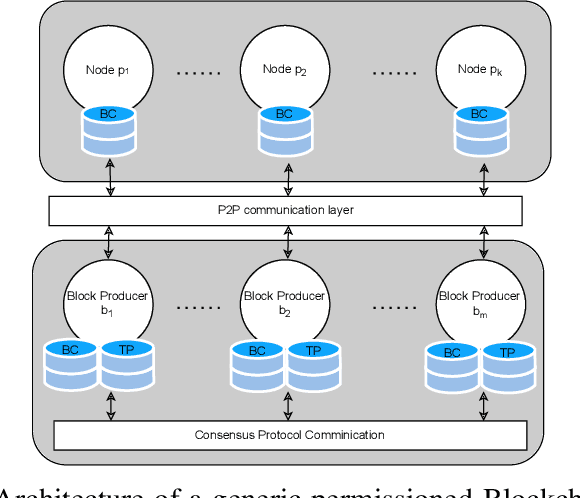
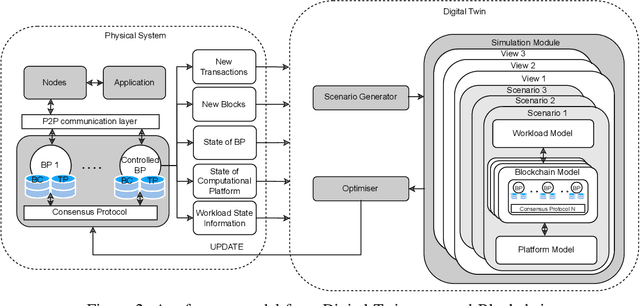
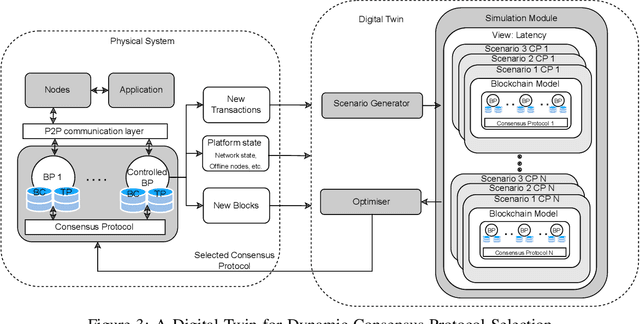
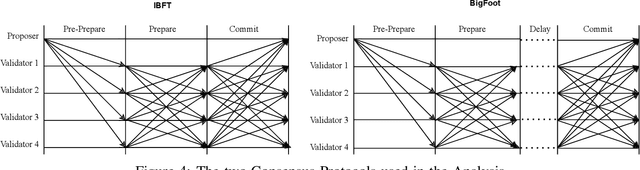
Blockchain systems are challenged by the so-called Trilemma tradeoff: decentralization, scalability and security. Infrastructure and node configuration, choice of the Consensus Protocol and complexity of the application transactions are cited amongst the factors that affect the tradeoffs balance. Given that Blockchains are complex, dynamic dynamic systems, a dynamic approach to their management and reconfiguration at runtime is deemed necessary to reflect the changes in the state of the infrastructure and application. This paper introduces the utilisation of Digital Twins for this purpose. The novel contribution of the paper is design of a framework and conceptual architecture of a Digital Twin that can assist in maintaining the Trilemma tradeoffs of time critical systems. The proposed Digital Twin is illustrated via an innovative approach to dynamic selection of Consensus Protocols. Simulations results show that the proposed framework can effectively support the dynamic adaptation and management of the Blockchain
A hybrid multi-object segmentation framework with model-based B-splines for microbial single cell analysis
May 03, 2022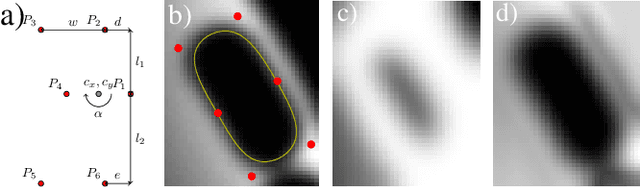
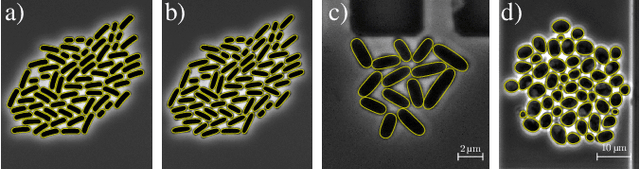
In this paper, we propose a hybrid approach for multi-object microbial cell segmentation. The approach combines an ML-based detection with a geometry-aware variational-based segmentation using B-splines that are parametrized based on a geometric model of the cell shape. The detection is done first using YOLOv5. In a second step, each detected cell is segmented individually. Thus, the segmentation only needs to be done on a per-cell basis, which makes it amenable to a variational approach that incorporates prior knowledge on the geometry. Here, the contour of the segmentation is modelled as closed uniform cubic B-spline, whose control points are parametrized using the known cell geometry. Compared to purely ML-based segmentation approaches, which need accurate segmentation maps as training data that are very laborious to produce, our method just needs bounding boxes as training data. Still, the proposed method performs on par with ML-based segmentation approaches usually used in this context. We study the performance of the proposed method on time-lapse microscopy data of Corynebacterium glutamicum.
Differentiable Zooming for Multiple Instance Learning on Whole-Slide Images
Apr 26, 2022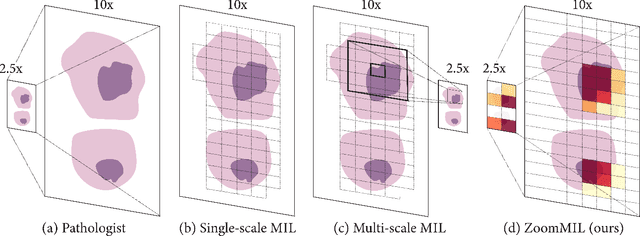
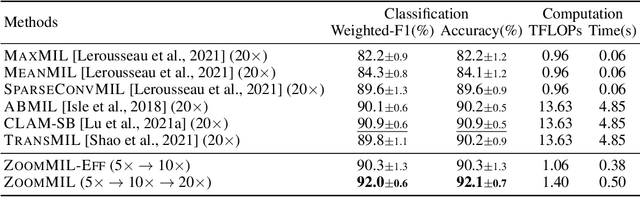
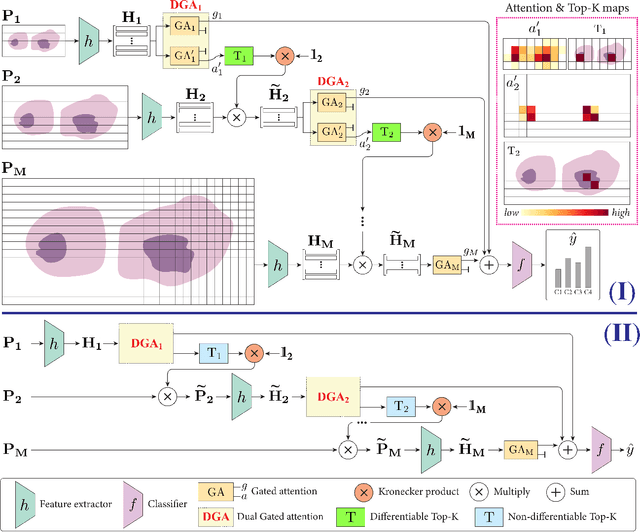
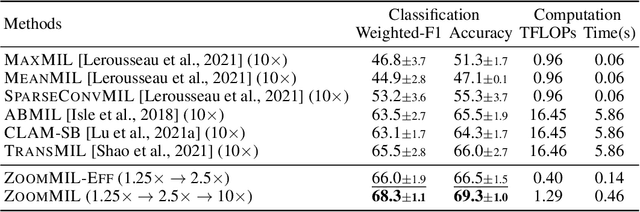
Multiple Instance Learning (MIL) methods have become increasingly popular for classifying giga-pixel sized Whole-Slide Images (WSIs) in digital pathology. Most MIL methods operate at a single WSI magnification, by processing all the tissue patches. Such a formulation induces high computational requirements, and constrains the contextualization of the WSI-level representation to a single scale. A few MIL methods extend to multiple scales, but are computationally more demanding. In this paper, inspired by the pathological diagnostic process, we propose ZoomMIL, a method that learns to perform multi-level zooming in an end-to-end manner. ZoomMIL builds WSI representations by aggregating tissue-context information from multiple magnifications. The proposed method outperforms the state-of-the-art MIL methods in WSI classification on two large datasets, while significantly reducing the computational demands with regard to Floating-Point Operations (FLOPs) and processing time by up to 40x.
A Framework for Interactive Knowledge-Aided Machine Teaching
Apr 21, 2022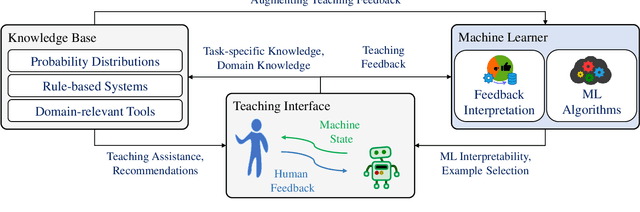
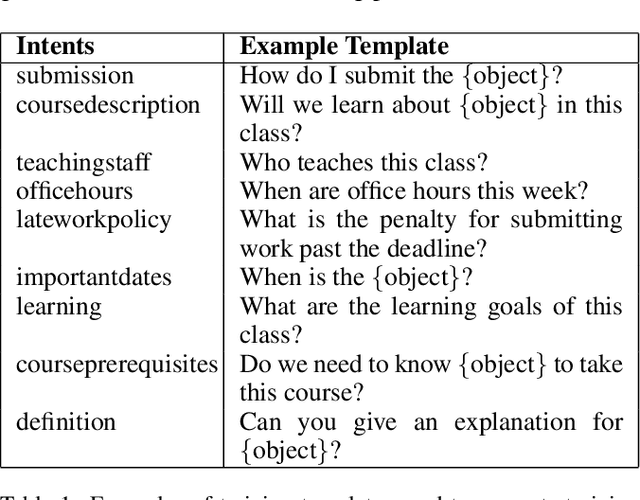
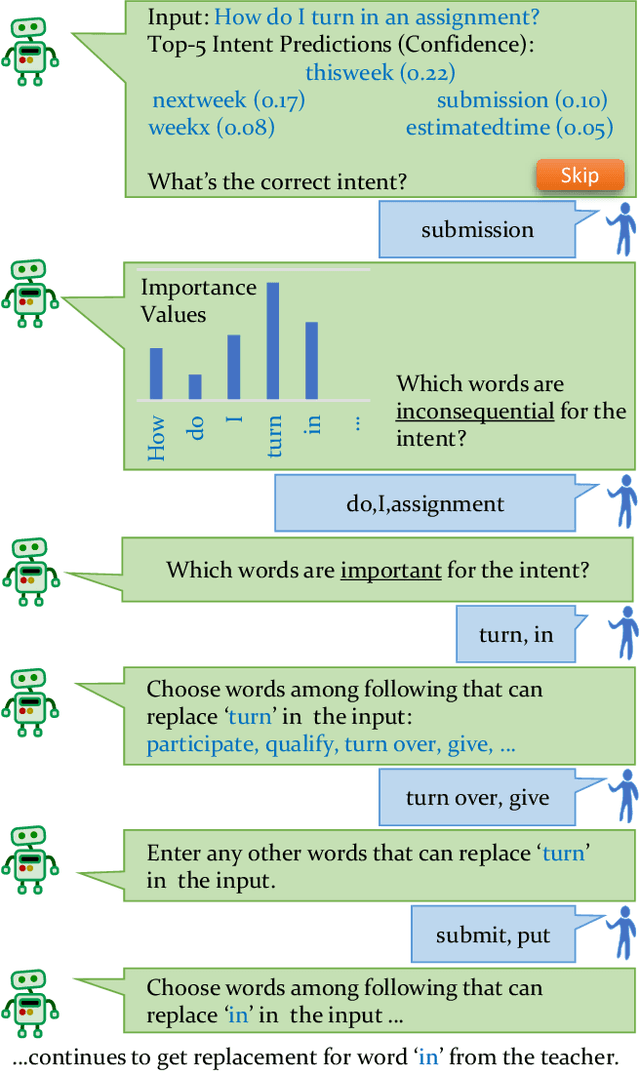
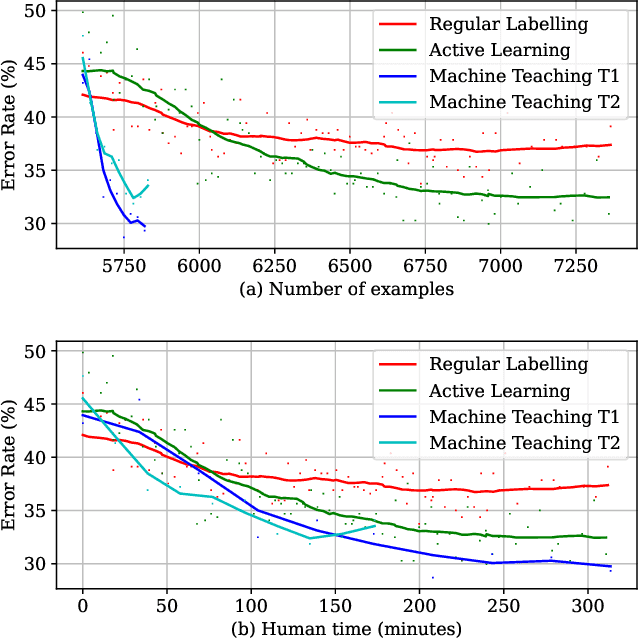
Machine Teaching (MT) is an interactive process where humans train a machine learning model by playing the role of a teacher. The process of designing an MT system involves decisions that can impact both efficiency of human teachers and performance of machine learners. Previous research has proposed and evaluated specific MT systems but there is limited discussion on a general framework for designing them. We propose a framework for designing MT systems and also detail a system for the text classification problem as a specific instance. Our framework focuses on three components i.e. teaching interface, machine learner, and knowledge base; and their relations describe how each component can benefit the others. Our preliminary experiments show how MT systems can reduce both human teaching time and machine learner error rate.
Impartial Games: A Challenge for Reinforcement Learning
May 25, 2022

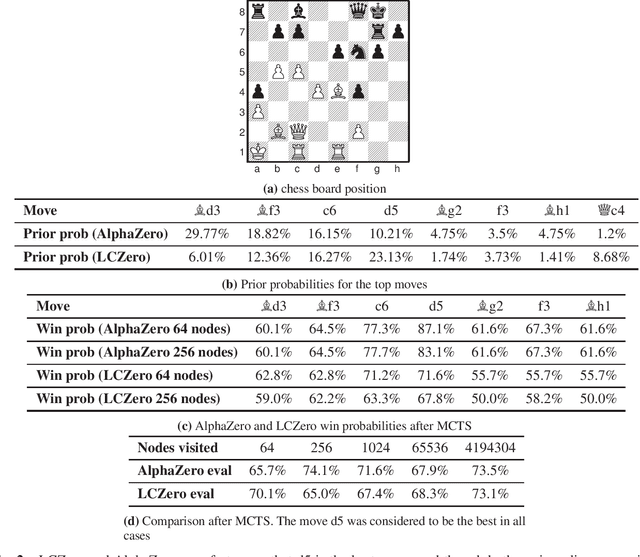

The AlphaZero algorithm and its successor MuZero have revolutionised several competitive strategy games, including chess, Go, and shogi and video games like Atari, by learning to play these games better than any human and any specialised computer program. Aside from knowing the rules, AlphaZero had no prior knowledge of each game. This dramatically advanced progress on a long-standing AI challenge to create programs that can learn for themselves from first principles. Theoretically, there are well-known limits to the power of deep learning for strategy games like chess, Go, and shogi, as they are known to be NEXPTIME hard. Some papers have argued that the AlphaZero methodology has limitations and is unsuitable for general AI. However, none of these works has suggested any specific limits for any particular game. In this paper, we provide more powerful bottlenecks than previously suggested. We present the first concrete example of a game - namely the (children) game of nim - and other impartial games that seem to be a stumbling block for AlphaZero and similar reinforcement learning algorithms. We show experimentally that the bottlenecks apply to both the policy and value networks. Since solving nim can be done in linear time using logarithmic space i.e. has very low-complexity, our experimental results supersede known theoretical limits based on many games' PSPACE (and NEXPTIME) completeness. We show that nim can be learned on small boards, but when the board size increases, AlphaZero style algorithms rapidly fail to improve. We quantify the difficulties for various setups, parameter settings and computational resources. Our results might help expand the AlphaZero self-play paradigm by allowing it to use meta-actions during training and/or actual game play like applying abstract transformations, or reading and writing to an external memory.