 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wasserstein Adversarial Learning based Temporal Knowledge Graph Embedding
May 04, 2022
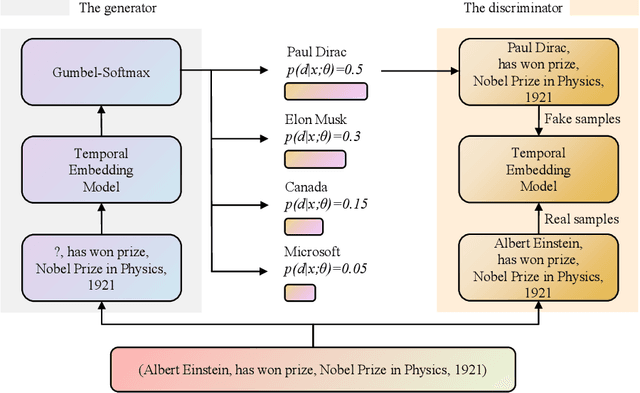
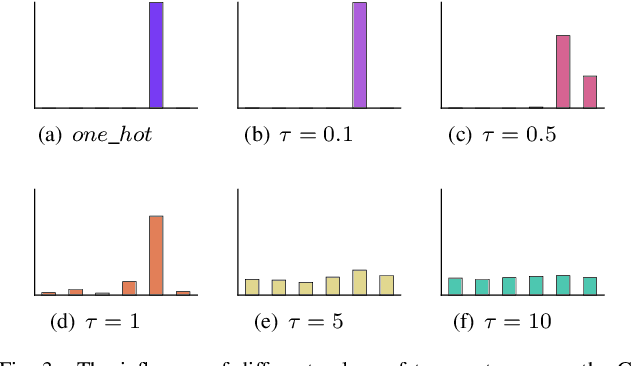

Research on knowledge graph embedding (KGE) has emerged as an active field in which most existing KGE approaches mainly focus on static structural data and ignore the influence of temporal variation involved in time-aware triples. In order to deal with this issue, several temporal knowledge graph embedding (TKGE) approaches have been proposed to integrate temporal and structural information in recent years. However, these methods only employ a uniformly random sampling to construct negative facts. As a consequence, the corrupted samples are often too simplistic for training an effective model. In this paper, we propose a new temporal knowledge graph embedding framework by introducing adversarial learning to further refine the performance of traditional TKGE models. In our framework, a generator is utilized to construct high-quality plausible quadruples and a discriminator learns to obtain the embeddings of entities and relations based on both positive and negative samples. Meanwhile, we also apply a Gumbel-Softmax relaxation and the Wasserstein distance to prevent vanishing gradient problems on discrete data; an inherent flaw in traditional generative adversarial networks. Through comprehensive experimentation on temporal datasets, the results indicate that our proposed framework can attain significant improvements based on benchmark models and also demonstrate the effectiveness and applicability of our framework.
AI Autonomy: Self-Initiation, Adaptation and Continual Learning
Mar 19, 2022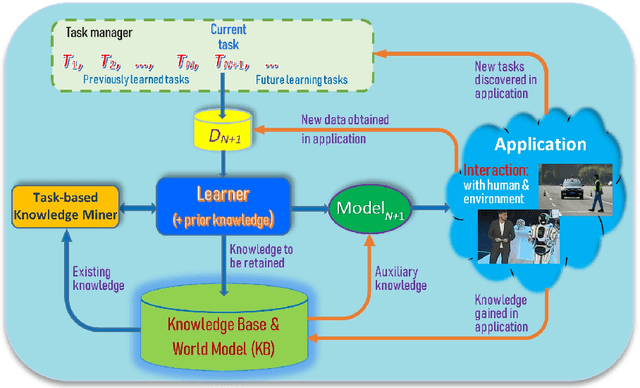
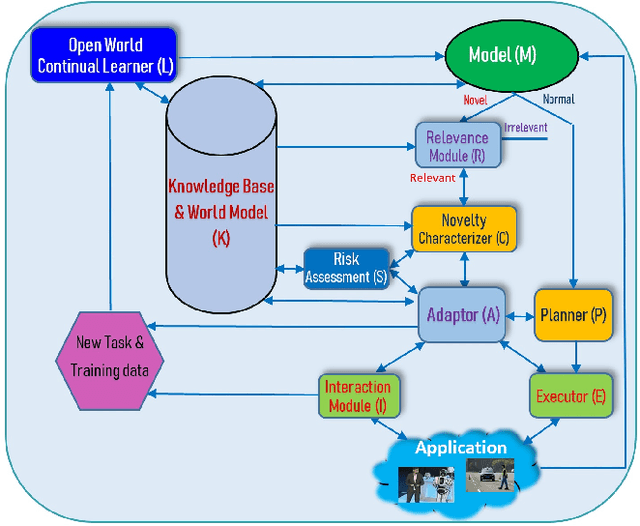
As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can (1) learn by themselves continually in a self-motivated and self-initiated manner rather than being retrained offline periodically on the initiation of human engineers and (2) accommodate or adapt to unexpected or novel circumstances. As the real-world is an open environment that is full of unknowns or novelties, detecting novelties, characterizing them, accommodating or adapting to them, and gathering ground-truth training data and incrementally learning the unknowns/novelties are critical to making the AI agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out continually on the agent's own initiative and through its own interactions with humans, other agents and the environment just like human on-the-job learning. This paper proposes a framework (called SOLA) for this learning paradigm to promote the research of building autonomous and continual learning enabled AI agents. To show feasibility, an implemented agent is also described.
Benchmarking high-fidelity pedestrian tracking systems for research, real-time monitoring and crowd control
Aug 26, 2021
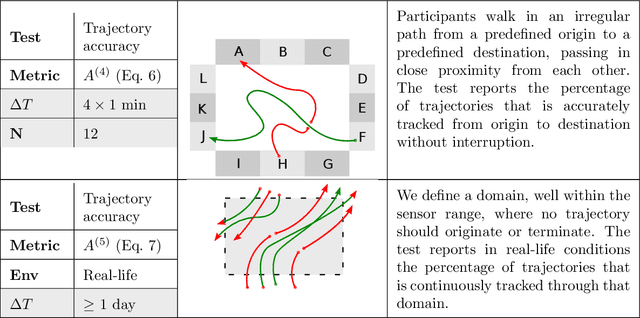
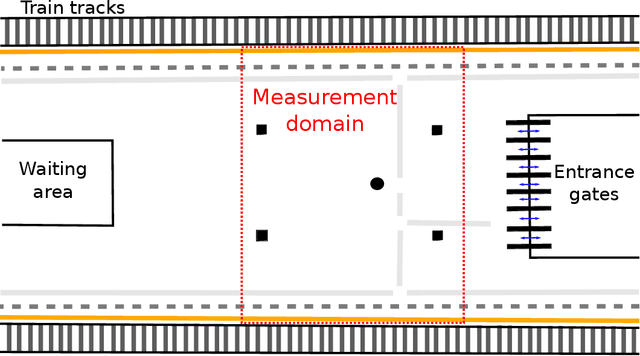
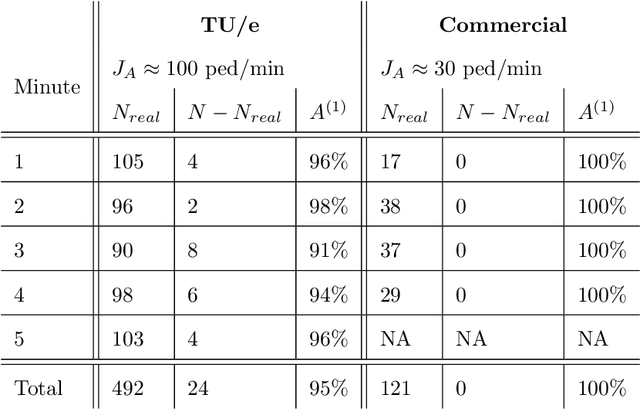
High-fidelity pedestrian tracking in real-life conditions has been an important tool in fundamental crowd dynamics research allowing to quantify statistics of relevant observables including walking velocities, mutual distances and body orientations. As this technology advances, it is becoming increasingly useful also in society. In fact, continued urbanization is overwhelming existing pedestrian infrastructures such as transportation hubs and stations, generating an urgent need for real-time highly-accurate usage data, aiming both at flow monitoring and dynamics understanding. To successfully employ pedestrian tracking techniques in research and technology, it is crucial to validate and benchmark them for accuracy. This is not only necessary to guarantee data quality, but also to identify systematic errors. In this contribution, we present and discuss a benchmark suite, towards an open standard in the community, for privacy-respectful pedestrian tracking techniques. The suite is technology-independent and is applicable to academic and commercial pedestrian tracking systems, operating both in lab environments and real-life conditions. The benchmark suite consists of 5 tests addressing specific aspects of pedestrian tracking quality, including accurate crowd flux estimation, density estimation, position detection and trajectory accuracy. The output of the tests are quality factors expressed as single numbers. We provide the benchmark results for two tracking systems, both operating in real-life, one commercial, and the other based on overhead depth-maps developed at TU Eindhoven. We discuss the results on the basis of the quality factors and report on the typical sensor and algorithmic performance. This enables us to highlight the current state-of-the-art, its limitations and provide installation recommendations, with specific attention to multi-sensor setups and data stitching.
Synthetic Distracted Driving (SynDD1) dataset for analyzing distracted behaviors and various gaze zones of a driver
Apr 19, 2022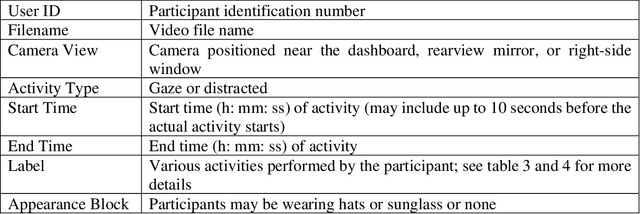



This article presents a synthetic distracted driving (SynDD1) dataset for machine learning models to detect and analyze drivers' various distracted behavior and different gaze zones. We collected the data in a stationary vehicle using three in-vehicle cameras positioned at locations: on the dashboard, near the rearview mirror, and on the top right-side window corner. The dataset contains two activity types: distracted activities, and gaze zones for each participant and each activity type has two sets: without appearance blocks and with appearance blocks such as wearing a hat or sunglasses. The order and duration of each activity for each participant are random. In addition, the dataset contains manual annotations for each activity, having its start and end time annotated. Researchers could use this dataset to evaluate the performance of machine learning algorithms for the classification of various distracting activities and gaze zones of drivers.
Active Audio-Visual Separation of Dynamic Sound Sources
Feb 02, 2022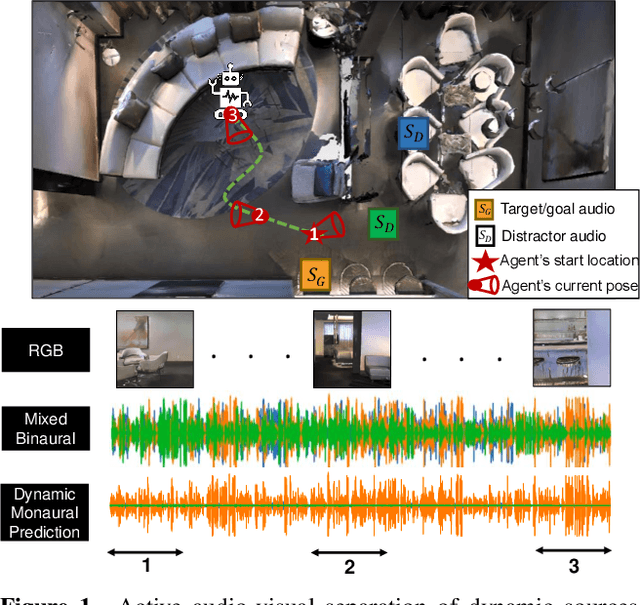
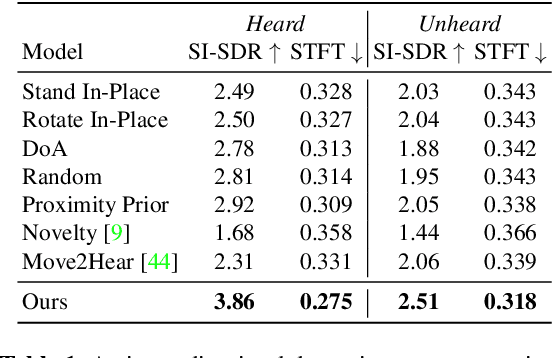
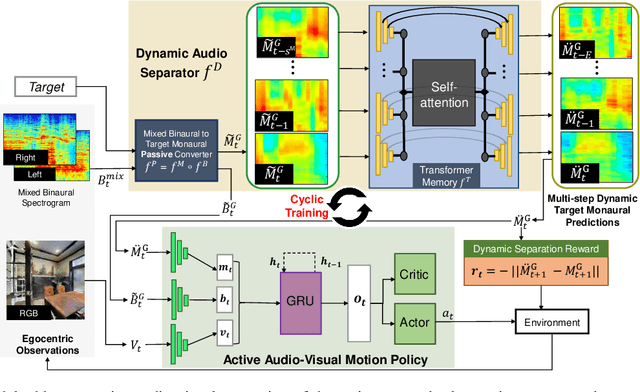
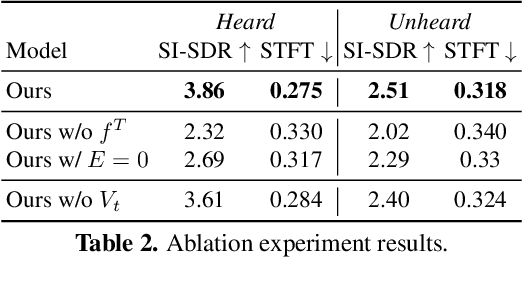
We explore active audio-visual separation for dynamic sound sources, where an embodied agent moves intelligently in a 3D environment to continuously isolate the time-varying audio stream being emitted by an object of interest. The agent hears a mixed stream of multiple time-varying audio sources (e.g., multiple people conversing and a band playing music at a noisy party). Given a limited time budget, it needs to extract the target sound using egocentric audio-visual observations. We propose a reinforcement learning agent equipped with a novel transformer memory that learns motion policies to control its camera and microphone to recover the dynamic target audio, improving its own estimates for past timesteps via self-attention. Using highly realistic acoustic SoundSpaces simulations in real-world scanned Matterport3D environments, we show that our model is able to learn efficient behavior to carry out continuous separation of a time-varying audio target. Project: https://vision.cs.utexas.edu/projects/active-av-dynamic-separation/.
Fast matrix multiplication for binary and ternary CNNs on ARM CPU
May 18, 2022
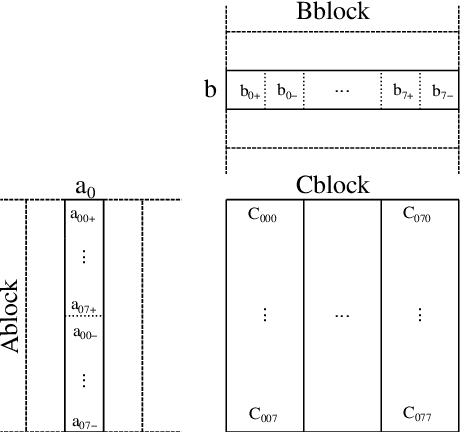
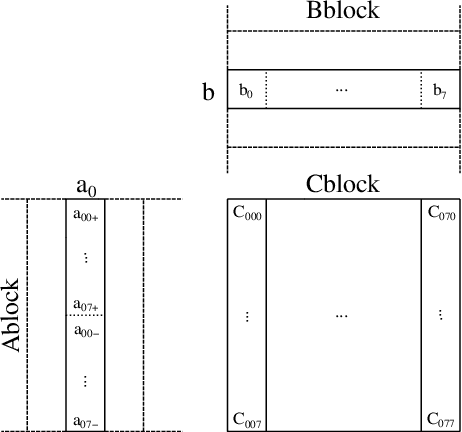
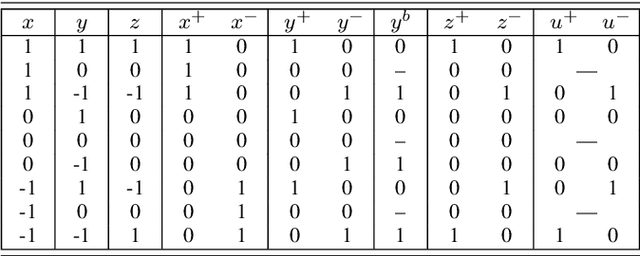
Low-bit quantized neural networks are of great interest in practical applications because they significantly reduce the consumption of both memory and computational resources. Binary neural networks are memory and computationally efficient as they require only one bit per weight and activation and can be computed using Boolean logic and bit count operations. QNNs with ternary weights and activations and binary weights and ternary activations aim to improve recognition quality compared to BNNs while preserving low bit-width. However, their efficient implementation is usually considered on ASICs and FPGAs, limiting their applicability in real-life tasks. At the same time, one of the areas where efficient recognition is most in demand is recognition on mobile devices using their CPUs. However, there are no known fast implementations of TBNs and TNN, only the daBNN library for BNNs inference. In this paper, we propose novel fast algorithms of ternary, ternary-binary, and binary matrix multiplication for mobile devices with ARM architecture. In our algorithms, ternary weights are represented using 2-bit encoding and binary - using one bit. It allows us to replace matrix multiplication with Boolean logic operations that can be computed on 128-bits simultaneously, using ARM NEON SIMD extension. The matrix multiplication results are accumulated in 16-bit integer registers. We also use special reordering of values in left and right matrices. All that allows us to efficiently compute a matrix product while minimizing the number of loads and stores compared to the algorithm from daBNN. Our algorithms can be used to implement inference of convolutional and fully connected layers of TNNs, TBNs, and BNNs. We evaluate them experimentally on ARM Cortex-A73 CPU and compare their inference speed to efficient implementations of full-precision, 8-bit, and 4-bit quantized matrix multiplications.
ALAP-AE: As-Lite-as-Possible Auto-Encoder
Mar 19, 2022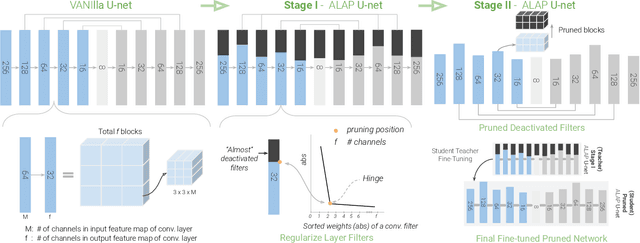
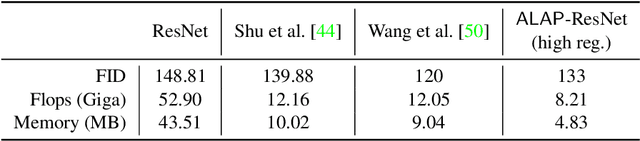
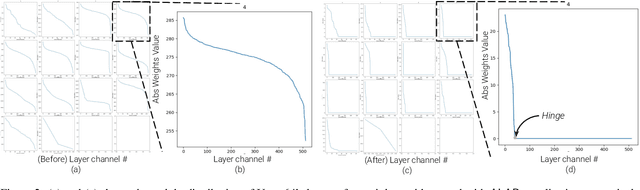
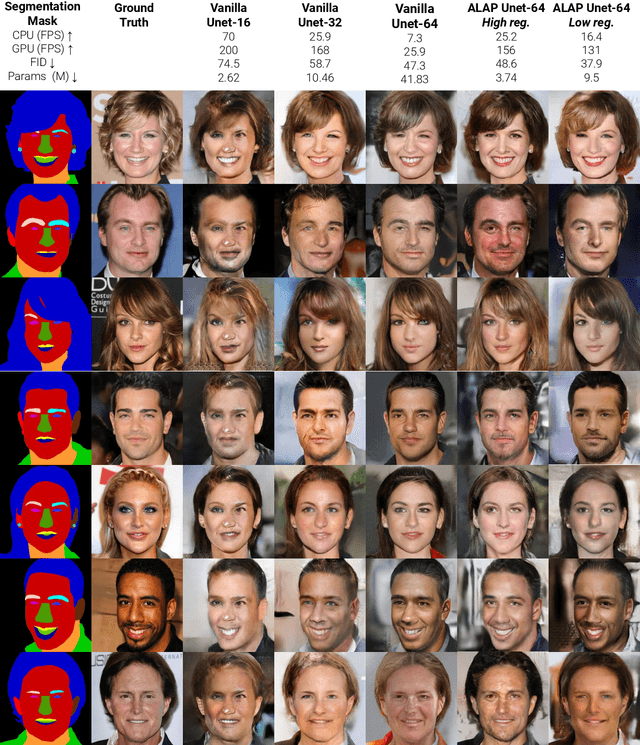
We present a novel algorithm to reduce tensor compute required by a conditional image generation autoencoder and make it as-lite-as-possible, without sacrificing quality of photo-realistic image generation. Our method is device agnostic, and can optimize an autoencoder for a given CPU-only, GPU compute device(s) in about normal time it takes to train an autoencoder on a generic workstation. We achieve this via a two-stage novel strategy where, first, we condense the channel weights, such that, as few as possible channels are used. Then, we prune the nearly zeroed out weight activations, and fine-tune this lite autoencoder. To maintain image quality, fine-tuning is done via student-teacher training, where we reuse the condensed autoencoder as the teacher. We show performance gains for various conditional image generation tasks: segmentation mask to face images, face images to cartoonization, and finally CycleGAN-based model on horse to zebra dataset over multiple compute devices. We perform various ablation studies to justify the claims and design choices, and achieve real-time versions of various autoencoders on CPU-only devices while maintaining image quality, thus enabling at-scale deployment of such autoencoders.
A Deep Adversarial Model for Suffix and Remaining Time Prediction of Event Sequences
Feb 15, 2021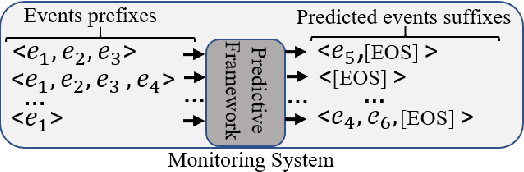



Event suffix and remaining time prediction are sequence to sequence learning tasks. They have wide applications in different areas such as economics, digital health, business process management and IT infrastructure monitoring. Timestamped event sequences contain ordered events which carry at least two attributes: the event's label and its timestamp. Suffix and remaining time prediction are about obtaining the most likely continuation of event labels and the remaining time until the sequence finishes, respectively. Recent deep learning-based works for such predictions are prone to potentially large prediction errors because of closed-loop training (i.e., the next event is conditioned on the ground truth of previous events) and open-loop inference (i.e., the next event is conditioned on previously predicted events). In this work, we propose an encoder-decoder architecture for open-loop training to advance the suffix and remaining time prediction of event sequences. To capture the joint temporal dynamics of events, we harness the power of adversarial learning techniques to boost prediction performance. We consider four real-life datasets and three baselines in our experiments. The results show improvements up to four times compared to the state of the art in suffix and remaining time prediction of event sequences, specifically in the realm of business process executions. We also show that the obtained improvements of adversarial training are superior compared to standard training under the same experimental setup.
Research on Parallel SVM Algorithm Based on Cascade SVM
Mar 11, 2022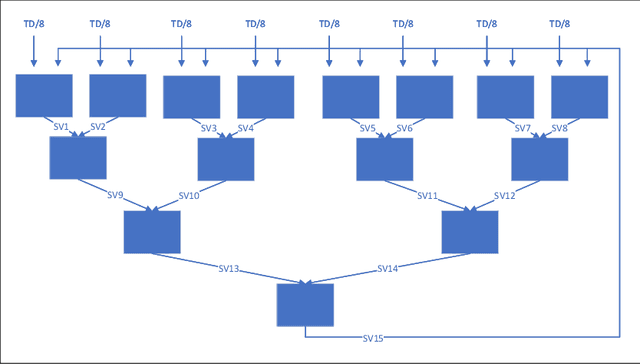

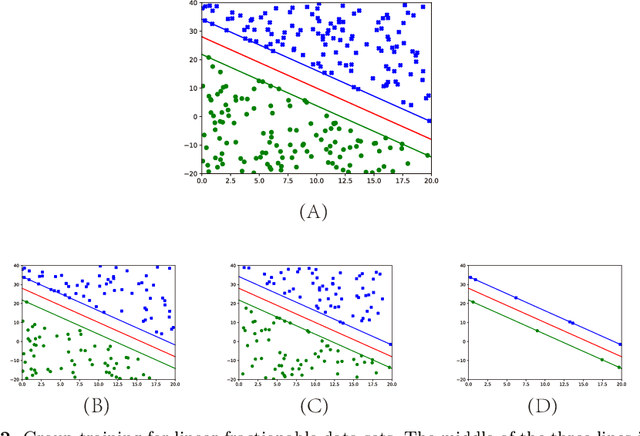
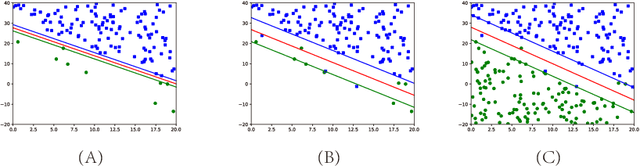
Cascade SVM (CSVM) can group datasets and train subsets in parallel, which greatly reduces the training time and memory consumption. However, the model accuracy obtained by using this method has some errors compared with direct training. In order to reduce the error, we analyze the causes of error in grouping training, and summarize the grouping without error under ideal conditions. A Balanced Cascade SVM (BCSVM) algorithm is proposed, which balances the sample proportion in the subset after grouping to ensure that the sample proportion in the subset is the same as the original dataset. At the same time, it proves that the accuracy of the model obtained by BCSVM algorithm is higher than that of CSVM. Finally, two common datasets are used for experimental verification, and the results show that the accuracy error obtained by using BCSVM algorithm is reduced from 1% of CSVM to 0.1%, which is reduced by an order of magnitude.
ExKaldi-RT: A Real-Time Automatic Speech Recognition Extension Toolkit of Kaldi
Apr 03, 2021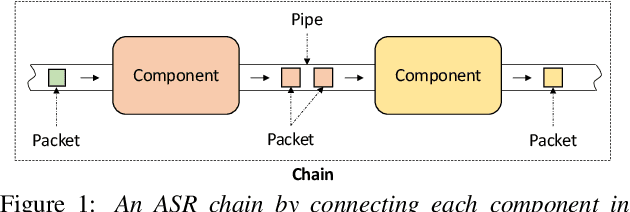

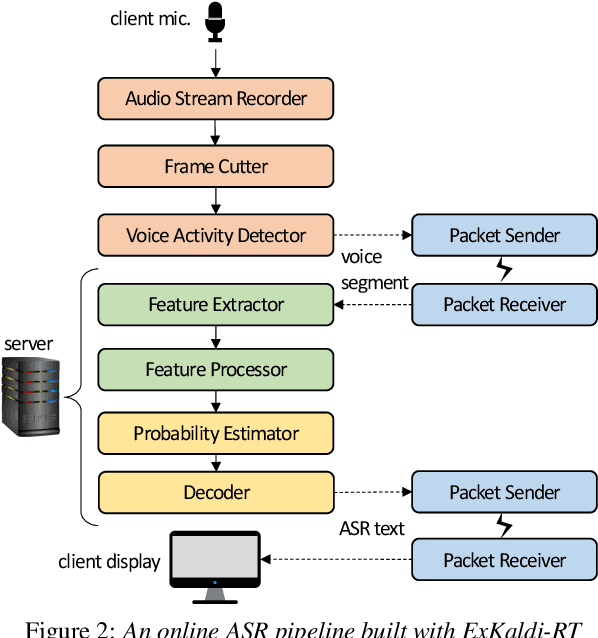
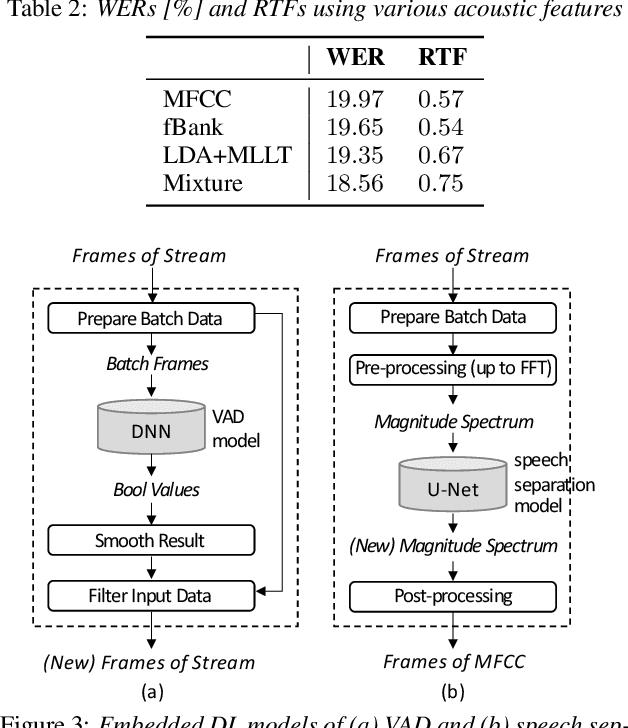
The availability of open-source software is playing a remarkable role in automatic speech recognition (ASR). Kaldi, for instance, is widely used to develop state-of-the-art offline and online ASR systems. This paper describes the "ExKaldi-RT," online ASR toolkit implemented based on Kaldi and Python language. ExKaldi-RT provides tools for providing a real-time audio stream pipeline, extracting acoustic features, transmitting packets with a remote connection, estimating acoustic probabilities with a neural network, and online decoding. While similar functions are available built on Kaldi, a key feature of ExKaldi-RT is completely working on Python language, which has an easy-to-use interface for online ASR system developers to exploit original research, for example, by applying neural network-based signal processing and acoustic model trained with deep learning frameworks. We performed benchmark experiments on the minimum LibriSpeech corpus, and showed that ExKaldi-RT could achieve competitive ASR performance in real-time.