 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neur2SP: Neural Two-Stage Stochastic Programming
May 20, 2022

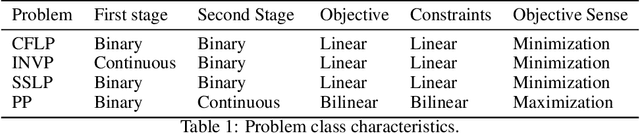
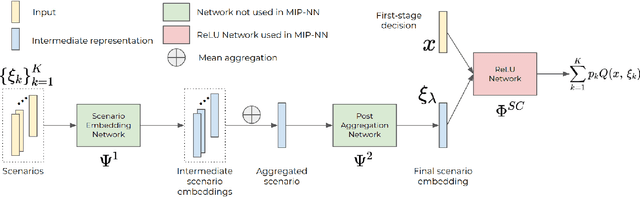
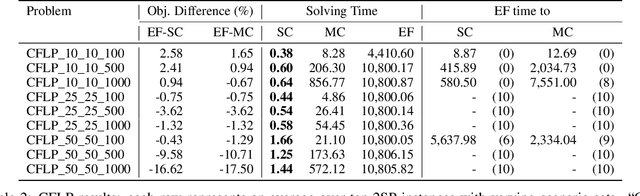
Stochastic programming is a powerful modeling framework for decision-making under uncertainty. In this work, we tackle two-stage stochastic programs (2SPs), the most widely applied and studied class of stochastic programming models. Solving 2SPs exactly requires evaluation of an expected value function that is computationally intractable. Additionally, having a mixed-integer linear program (MIP) or a nonlinear program (NLP) in the second stage further aggravates the problem difficulty. In such cases, solving them can be prohibitively expensive even if specialized algorithms that exploit problem structure are employed. Finding high-quality (first-stage) solutions -- without leveraging problem structure -- can be crucial in such settings. We develop Neur2SP, a new method that approximates the expected value function via a neural network to obtain a surrogate model that can be solved more efficiently than the traditional extensive formulation approach. Moreover, Neur2SP makes no assumptions about the problem structure, in particular about the second-stage problem, and can be implemented using an off-the-shelf solver and open-source libraries. Our extensive computational experiments on benchmark 2SP datasets from four problem classes with different structures (containing MIP and NLP second-stage problems) show the efficiency (time) and efficacy (solution quality) of Neur2SP. Specifically, the proposed method takes less than 1.66 seconds across all problems, achieving high-quality solutions even as the number of scenarios increases, an ideal property that is difficult to have for traditional 2SP solution techniques. Namely, the most generic baseline method typically requires minutes to hours to find solutions of comparable quality.
Similarity measure for sparse time course data based on Gaussian processes
Feb 24, 2021We propose a similarity measure for sparsely sampled time course data in the form of a log-likelihood ratio of Gaussian processes (GP). The proposed GP similarity is similar to a Bayes factor and provides enhanced robustness to noise in sparse time series, such as those found in various biological settings, e.g., gene transcriptomics. We show that the GP measure is equivalent to the Euclidean distance when the noise variance in the GP is negligible compared to the noise variance of the signal. Our numerical experiments on both synthetic and real data show improved performance of the GP similarity when used in conjunction with two distance-based clustering methods.
Learning a Better Control Barrier Function
May 11, 2022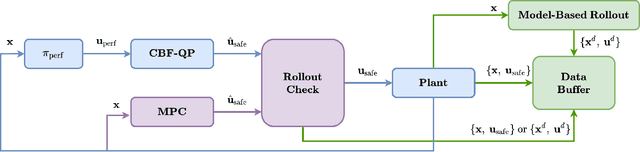
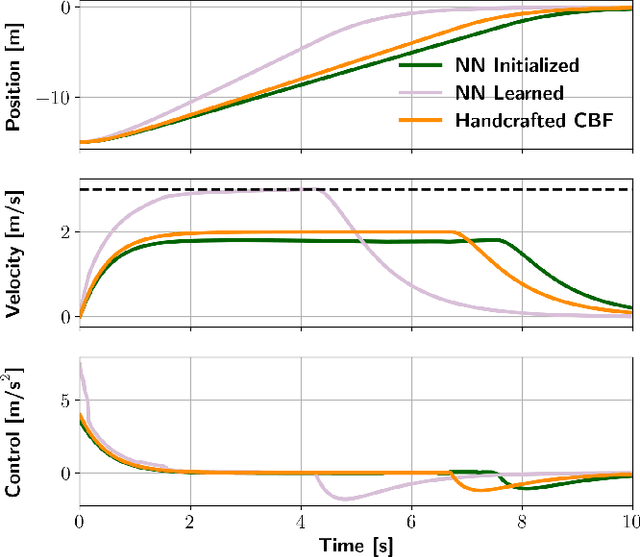
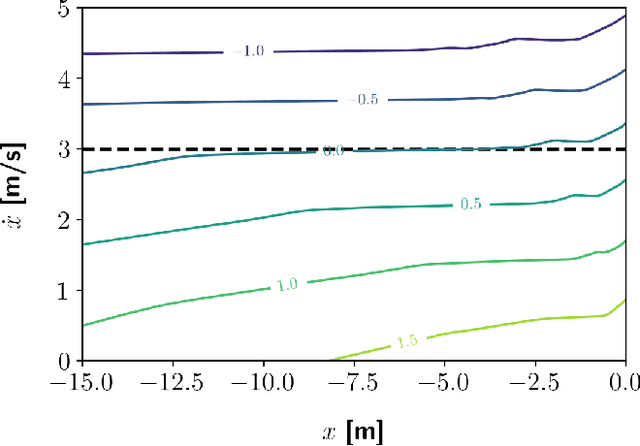
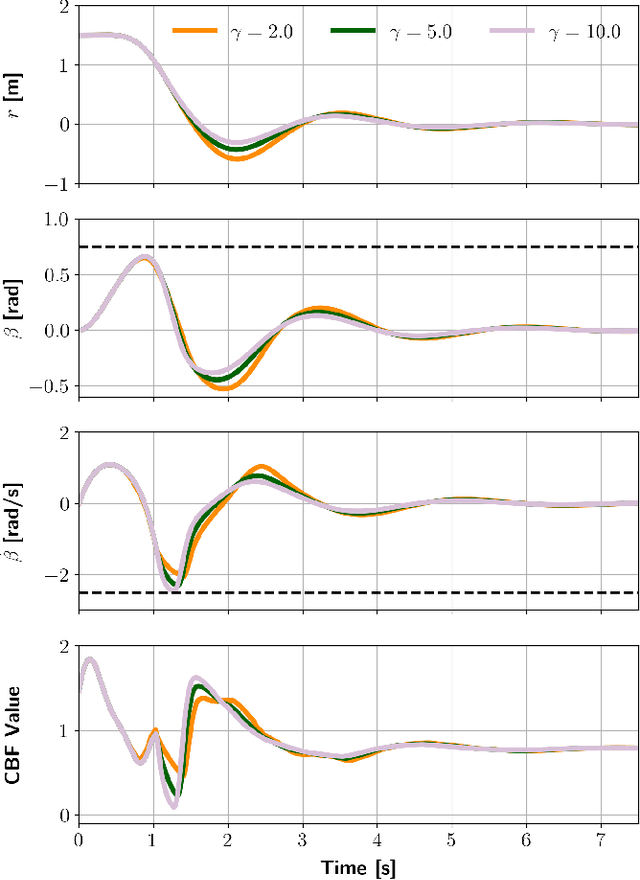
Control barrier functions (CBF) are widely used in safety-critical controllers. However, the construction of valid CBFs is well known to be challenging, especially for nonlinear or non-convex constraints and high relative degree systems. On the other hand, finding a conservative CBF that only recovers a portion of the true safe set is usually possible. In this work, starting from a "conservative" handcrafted control barrier function (HCBF), we develop a method to find a control barrier function that recovers a reasonably larger portion of the safe set. Using a different approach, by incorporating the hard constraints into an optimal control problem, e.g., MPC, we can safely generate solutions within the true safe set. Nevertheless, such an approach is usually computationally expensive and may not lend itself to real-time implementations. We propose to combine the two methods. During training, we utilize MPC to collect safe trajectory data. Thereafter, we train a neural network to estimate the difference between the HCBF and the CBF that recovers a closer solution to the true safe set. Using the proposed approach, we can generate a safe controller that is less conservative and computationally efficient. We validate our approach on three systems: a second-order integrator, ball-on-beam, and unicycle.
UBERT: A Novel Language Model for Synonymy Prediction at Scale in the UMLS Metathesaurus
Apr 27, 2022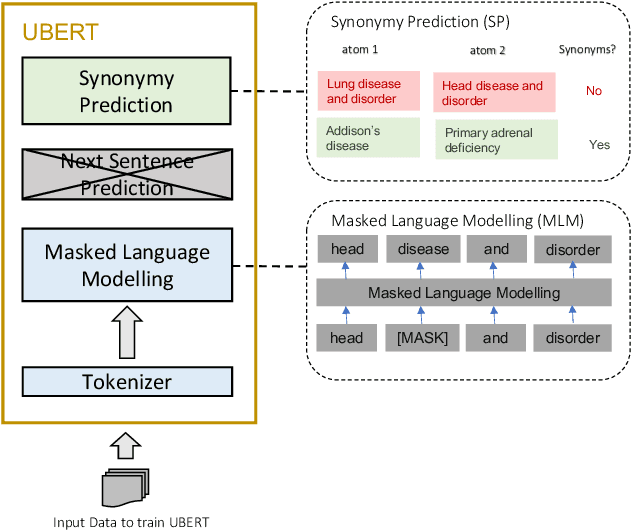
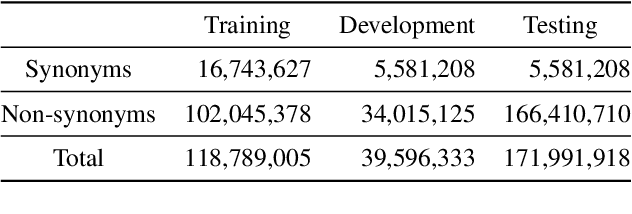
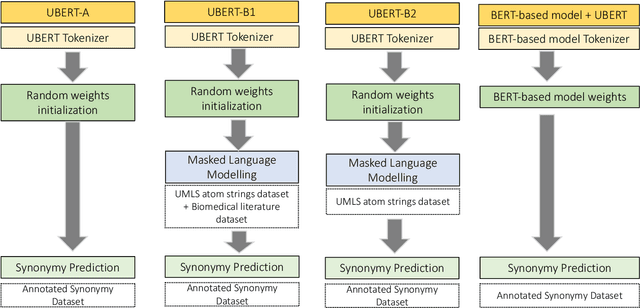

The UMLS Metathesaurus integrates more than 200 biomedical source vocabularies. During the Metathesaurus construction process, synonymous terms are clustered into concepts by human editors, assisted by lexical similarity algorithms. This process is error-prone and time-consuming. Recently, a deep learning model (LexLM) has been developed for the UMLS Vocabulary Alignment (UVA) task. This work introduces UBERT, a BERT-based language model, pretrained on UMLS terms via a supervised Synonymy Prediction (SP) task replacing the original Next Sentence Prediction (NSP) task. The effectiveness of UBERT for UMLS Metathesaurus construction process is evaluated using the UMLS Vocabulary Alignment (UVA) task. We show that UBERT outperforms the LexLM, as well as biomedical BERT-based models. Key to the performance of UBERT are the synonymy prediction task specifically developed for UBERT, the tight alignment of training data to the UVA task, and the similarity of the models used for pretrained UBERT.
Estimation of Non-Functional Properties for Embedded Hardware with Application to Image Processing
Mar 03, 2022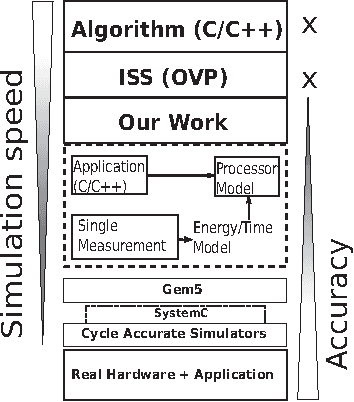
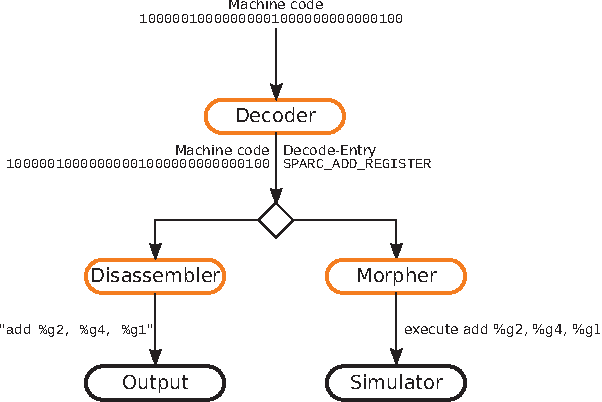
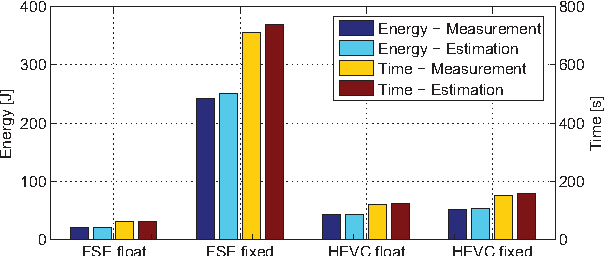
In recent years, due to a higher demand for portable devices, which provide restricted amounts of processing capacity and battery power, the need for energy and time efficient hard- and software solutions has increased. Preliminary estimations of time and energy consumption can thus be valuable to improve implementations and design decisions. To this end, this paper presents a method to estimate the time and energy consumption of a given software solution, without having to rely on the use of a traditional Cycle Accurate Simulator (CAS). Instead, we propose to utilize a combination of high-level functional simulation with a mechanistic extension to include non-functional properties: Instruction counts from virtual execution are multiplied with corresponding specific energies and times. By evaluating two common image processing algorithms on an FPGA-based CPU, where a mean relative estimation error of 3% is achieved for cacheless systems, we show that this estimation tool can be a valuable aid in the development of embedded processor architectures. The tool allows the developer to reach well-suited design decisions regarding the optimal processor hardware configuration for a given algorithm at an early stage in the design process.
A Machine Learning Approach for Prosumer Management in Intraday Electricity Markets
Mar 11, 2022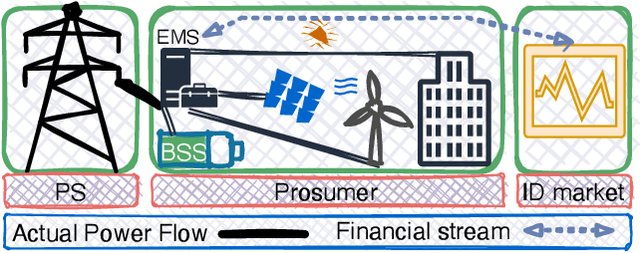
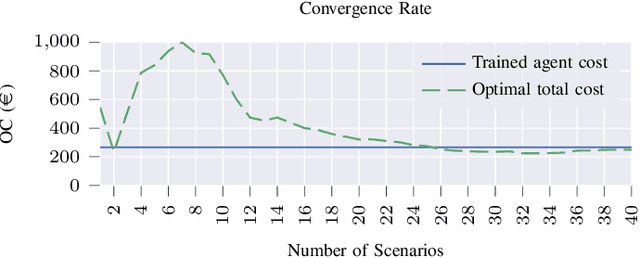
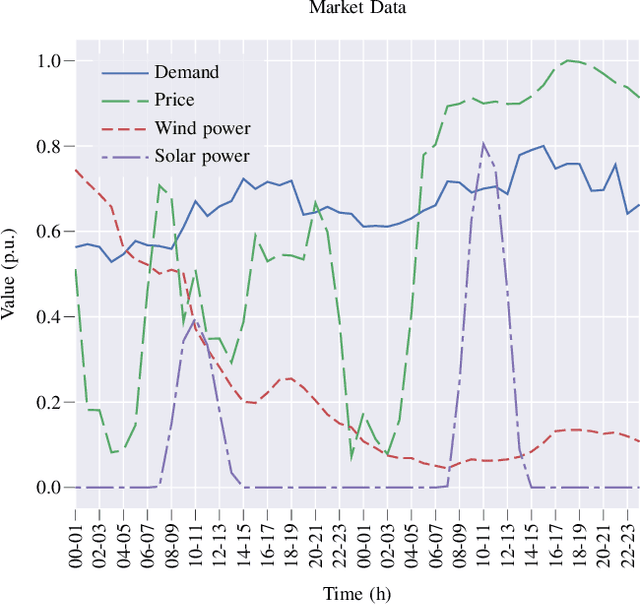
Prosumer operators are dealing with extensive challenges to participate in short-term electricity markets while taking uncertainties into account. Challenges such as variation in demand, solar energy, wind power, and electricity prices as well as faster response time in intraday electricity markets. Machine learning approaches could resolve these challenges due to their ability to continuous learning of complex relations and providing a real-time response. Such approaches are applicable with presence of the high performance computing and big data. To tackle these challenges, a Markov decision process is proposed and solved with a reinforcement learning algorithm with proper observations and actions employing tabular Q-learning. Trained agent converges to a policy which is similar to the global optimal solution. It increases the prosumer's profit by 13.39% compared to the well-known stochastic optimization approach.
Learning Graph Structures with Transformer for Multivariate Time Series Anomaly Detection in IoT
Apr 08, 2021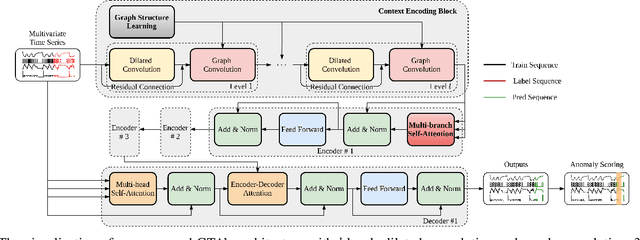
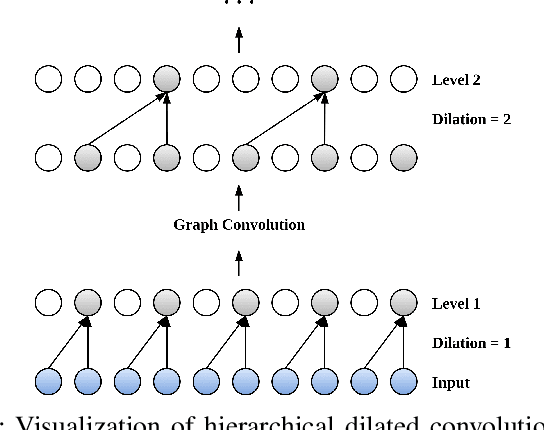
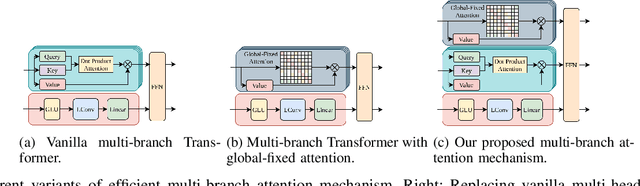
Many real-world IoT systems comprising various internet-connected sensory devices generate substantial amounts of multivariate time series data. Meanwhile, those critical IoT infrastructures, such as smart power grids and water distribution networks, are often targets of cyber-attacks, making anomaly detection of high research value. However, considering the complex topological and nonlinear dependencies that are initially unknown among sensors, modeling such relatedness is inevitable for any efficient and accurate anomaly detection system. Additionally, due to multivariate time series' temporal dependency and stochasticity, their anomaly detection remains a big challenge. This work proposed a novel framework, namely GTA, for multivariate time series anomaly detection by automatically learning a graph structure followed by the graph convolution and modeling the temporal dependency through a Transformer-based architecture. The core idea of learning graph structure is called the connection learning policy based on the Gumbel-softmax sampling strategy to learn bi-directed associations among sensors directly. We also devised a novel graph convolution named Influence Propagation convolution to model the anomaly information flow between graph nodes. Moreover, we proposed a multi-branch attention mechanism to substitute for original multi-head self-attention to overcome the quadratic complexity challenge. The extensive experiments on four public anomaly detection benchmarks further demonstrate our approach's superiority over other state-of-the-arts.
WikiOmnia: generative QA corpus on the whole Russian Wikipedia
Apr 29, 2022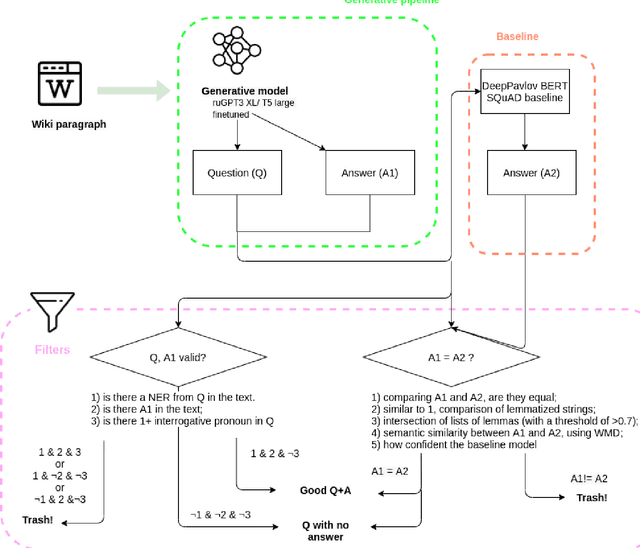
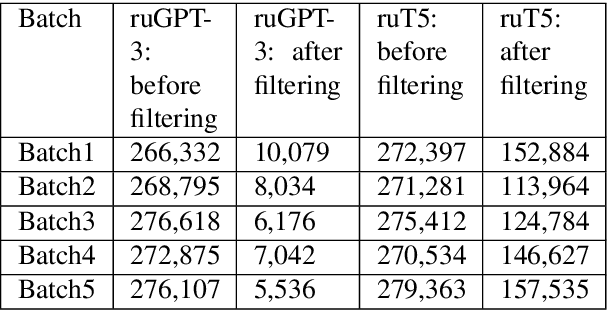
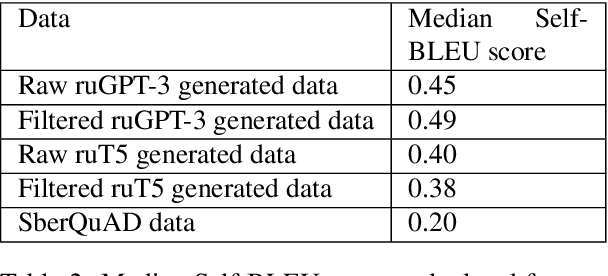
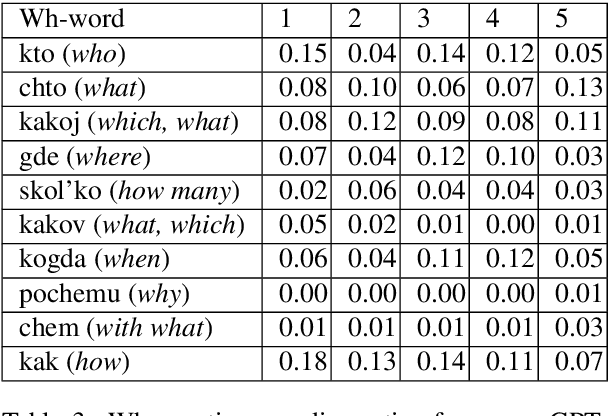
The General QA field has been developing the methodology referencing the Stanford Question answering dataset (SQuAD) as the significant benchmark. However, compiling factual questions is accompanied by time- and labour-consuming annotation, limiting the training data's potential size. We present the WikiOmnia dataset, a new publicly available set of QA-pairs and corresponding Russian Wikipedia article summary sections, composed with a fully automated generative pipeline. The dataset includes every available article from Wikipedia for the Russian language. The WikiOmnia pipeline is available open-source and is also tested for creating SQuAD-formatted QA on other domains, like news texts, fiction, and social media. The resulting dataset includes two parts: raw data on the whole Russian Wikipedia (7,930,873 QA pairs with paragraphs for ruGPT-3 XL and 7,991,040 QA pairs with paragraphs for ruT5-large) and cleaned data with strict automatic verification (over 160,000 QA pairs with paragraphs for ruGPT-3 XL and over 3,400,000 QA pairs with paragraphs for ruT5-large).
Formalizing PQRST Complex in Accelerometer-based Gait Cycle for Authentication
May 14, 2022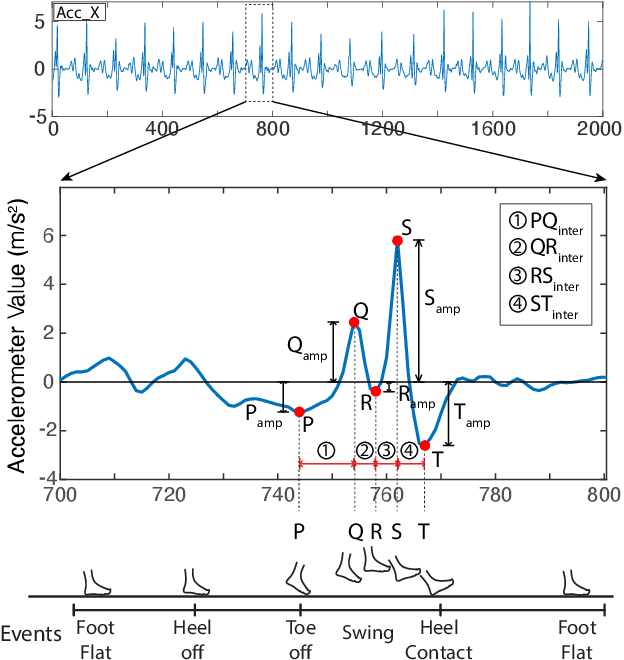

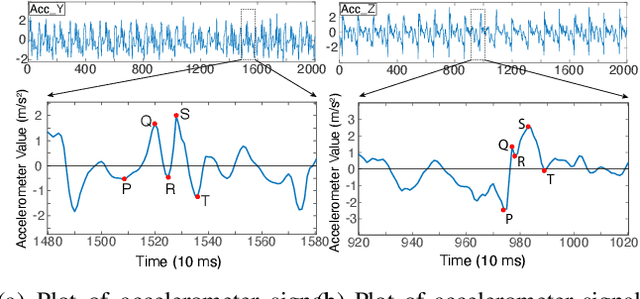
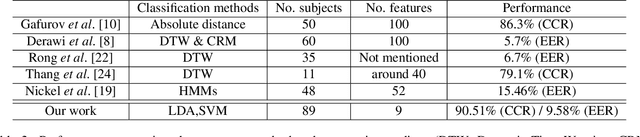
Accelerometer signals generated through gait present a new frontier of human interface with mobile devices. Gait cycle detection based on these signals has applications in various areas, including authentication, health monitoring, and activity detection. Template-based studies focus on how the entire gait cycle represents walking patterns, but these are compute-intensive. Aggregate feature-based studies extract features in the time domain and frequency domain from the entire gait cycle to reduce the number of features. However, these methods may miss critical structural information needed to appropriately represent the intricacies of walking patterns. To the best of our knowledge, no study has formally proposed a structure to capture variations within gait cycles or phases from accelerometer readings. We propose a new structure named the PQRST Complex, which corresponds to the swing phase in a gait cycle and matches the foot movements during this phase, thus capturing the changes in foot position. In our experiments, based on the nine features derived from this structure, the accelerometer-based gait authentication system outperforms many state-of-the-art gait cycle-based authentication systems. Our work opens up a new paradigm of capturing the structure of gait and opens multiple areas of research and practice using gait analogous to the "QRS complex" structure of ECG signals related to the heart.
A General Measure of Collision Hazard in Traffic
May 17, 2022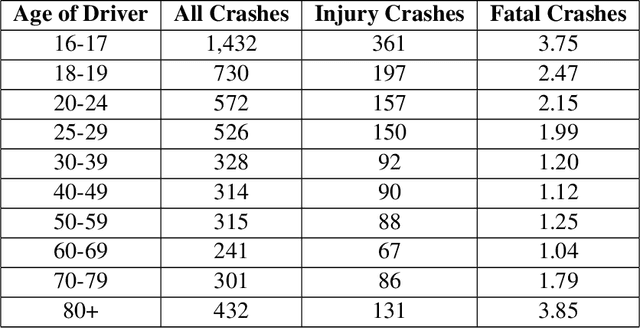
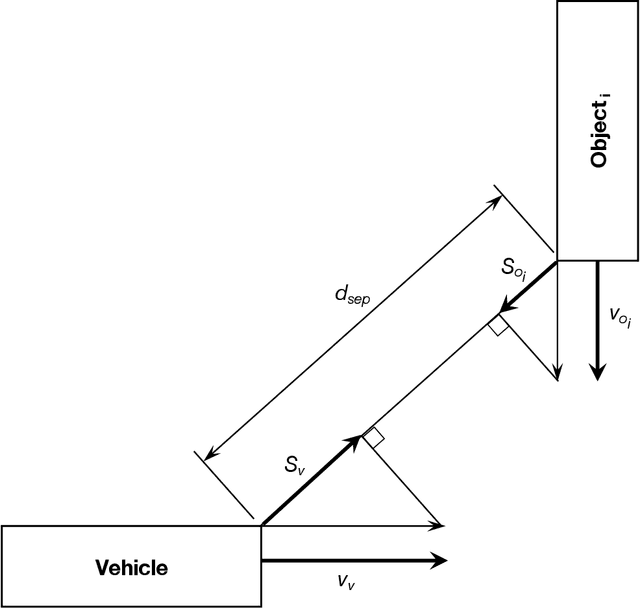
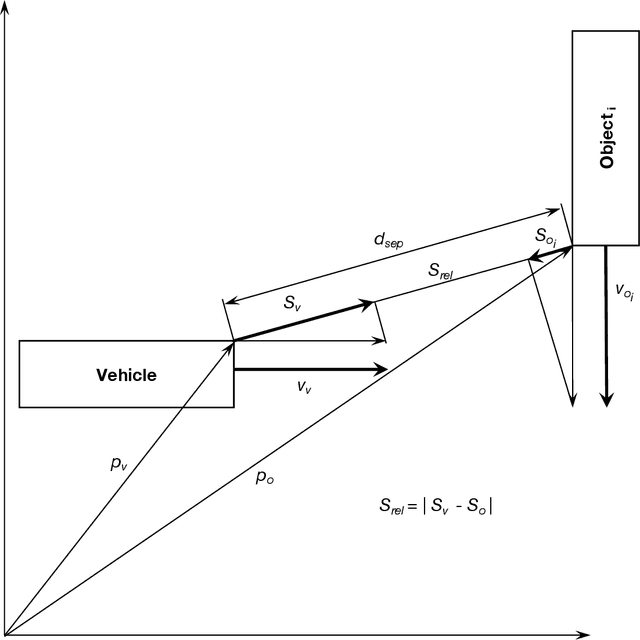
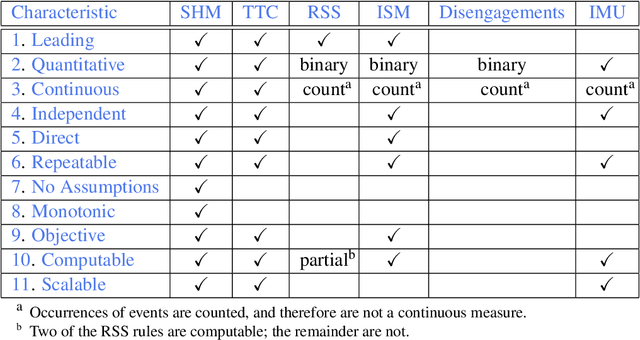
A collision hazard measure that has the essential characteristics to provide a measurement of safety that will be useful to AV developers, traffic infrastructure developers and managers, regulators and the public is introduced here. The Streetscope Collision Hazard Measure (SHM) overcomes the limitations of existing measures, and provides an independent leading indication of safety. * Trailing indicators, such as collision statistics, incur pain and loss on society, and are not an ethically acceptable approach. * Near-misses have been shown to be effective predictors of incidents. * Time-to-Collision (TTC) provides ambiguous indication of collision hazards, and requires assumptions about vehicle behavior. * Responsibility-Sensitive Safety (RSS), because of its reliance on rules for individual circumstances, will not scale up to handle the complexities of traffic. * Instantaneous Safety Metric (ISM) relies on probabilistic predictions of behaviors to categorize events (possible, imminent, critical), and does not provide a quantitative measure of the severity of the hazard. * Inertial Measurement Unit (IMU) acceleration data is not correlated with hazard or risk. * A new measure, based on the concept of near-misses, that incorporates both proximity (separation distance) and motion (relative speed) is introduced. * Near-miss data has been shown to be predictive of the likelihood and severity of incidents. The new measure presented here gathers movement data about vehicles continuously and a quantitative score reflecting the hazard encountered or created (from which the riskiness or safeness of the behavior of vehicles can be estimated) is computed nearly continuously.