 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Heat Source Layout Optimization Using Automatic Deep Learning Surrogate Model and Multimodal Neighborhood Search Algorithm
May 16, 2022
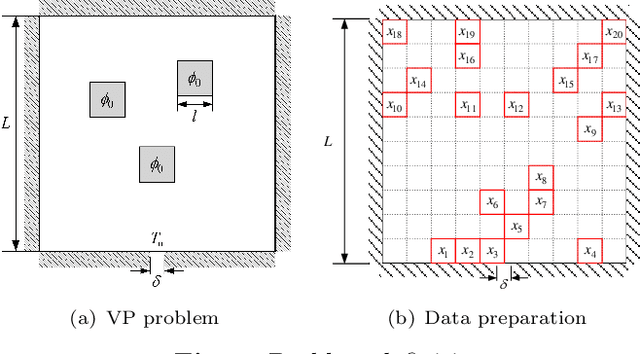

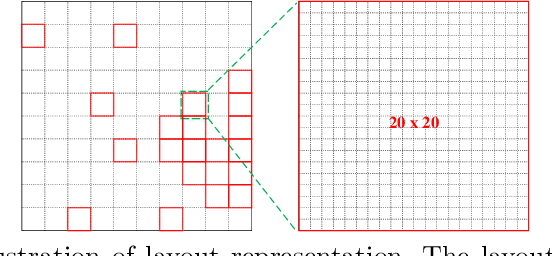
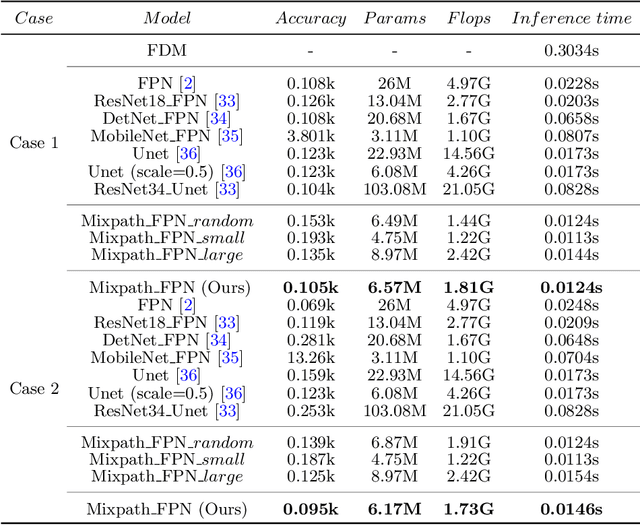
In satellite layout design, heat source layout optimization (HSLO) is an effective technique to decrease the maximum temperature and improve the heat management of the whole system. Recently, deep learning surrogate assisted HSLO has been proposed, which learns the mapping from layout to its corresponding temperature field, so as to substitute the simulation during optimization to decrease the computational cost largely. However, it faces two main challenges: 1) the neural network surrogate for the certain task is often manually designed to be complex and requires rich debugging experience, which is challenging for the designers in the engineering field; 2) existing algorithms for HSLO could only obtain a near optimal solution in single optimization and are easily trapped in local optimum. To address the first challenge, considering reducing the total parameter numbers and ensuring the similar accuracy as well as, a neural architecture search (NAS) method combined with Feature Pyramid Network (FPN) framework is developed to realize the purpose of automatically searching for a small deep learning surrogate model for HSLO. To address the second challenge, a multimodal neighborhood search based layout optimization algorithm (MNSLO) is proposed, which could obtain more and better approximate optimal design schemes simultaneously in single optimization. Finally, two typical two-dimensional heat conduction optimization problems are utilized to demonstrate the effectiveness of the proposed method. With the similar accuracy, NAS finds models with 80% fewer parameters, 64% fewer FLOPs and 36% faster inference time than the original FPN. Besides, with the assistance of deep learning surrogate by automatic search, MNSLO could achieve multiple near optimal design schemes simultaneously to provide more design diversities for designers.
Distributed Learning and its Application for Time-Series Prediction
Jun 10, 2021
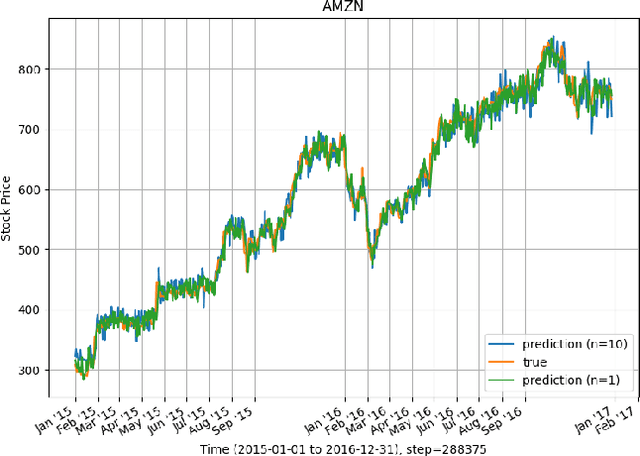


Extreme events are occurrences whose magnitude and potential cause extensive damage on people, infrastructure, and the environment. Motivated by the extreme nature of the current global health landscape, which is plagued by the coronavirus pandemic, we seek to better understand and model extreme events. Modeling extreme events is common in practice and plays an important role in time-series prediction applications. Our goal is to (i) compare and investigate the effect of some common extreme events modeling methods to explore which method can be practical in reality and (ii) accelerate the deep learning training process, which commonly uses deep recurrent neural network (RNN), by implementing the asynchronous local Stochastic Gradient Descent (SGD) framework among multiple compute nodes. In order to verify our distributed extreme events modeling, we evaluate our proposed framework on a stock data set S\&P500, with a standard recurrent neural network. Our intuition is to explore the (best) extreme events modeling method which could work well under the distributed deep learning setting. Moreover, by using asynchronous distributed learning, we aim to significantly reduce the communication cost among the compute nodes and central server, which is the main bottleneck of almost all distributed learning frameworks. We implement our proposed work and evaluate its performance on representative data sets, such as S&P500 stock in $5$-year period. The experimental results validate the correctness of the design principle and show a significant training duration reduction upto $8$x, compared to the baseline single compute node. Our results also show that our proposed work can achieve the same level of test accuracy, compared to the baseline setting.
PU-EVA: An Edge Vector based Approximation Solution for Flexible-scale Point Cloud Upsampling
Apr 22, 2022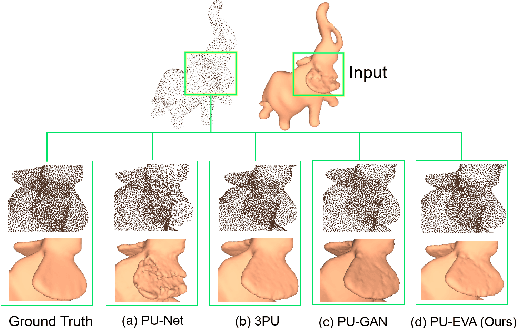
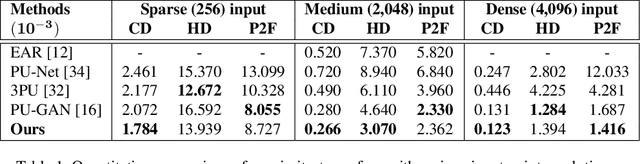
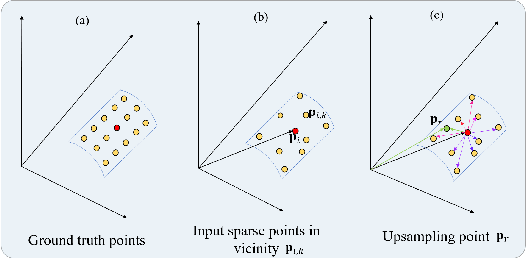
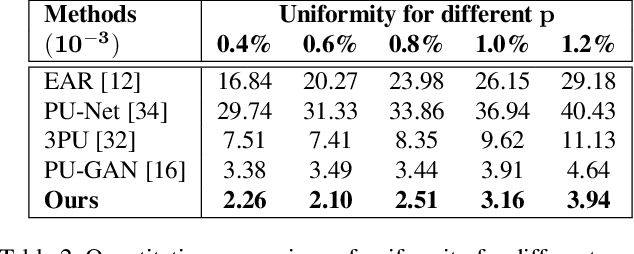
High-quality point clouds have practical significance for point-based rendering, semantic understanding, and surface reconstruction. Upsampling sparse, noisy and nonuniform point clouds for a denser and more regular approximation of target objects is a desirable but challenging task. Most existing methods duplicate point features for upsampling, constraining the upsampling scales at a fixed rate. In this work, the flexible upsampling rates are achieved via edge vector based affine combinations, and a novel design of Edge Vector based Approximation for Flexible-scale Point clouds Upsampling (PU-EVA) is proposed. The edge vector based approximation encodes the neighboring connectivity via affine combinations based on edge vectors, and restricts the approximation error within the second-order term of Taylor's Expansion. The EVA upsampling decouples the upsampling scales with network architecture, achieving the flexible upsampling rates in one-time training. Qualitative and quantitative evaluations demonstrate that the proposed PU-EVA outperforms the state-of-the-art in terms of proximity-to-surface, distribution uniformity, and geometric details preservation.
Exploiting Multi-modal Contextual Sensing for City-bus's Stay Location Characterization: Towards Sub-60 Seconds Accurate Arrival Time Prediction
May 24, 2021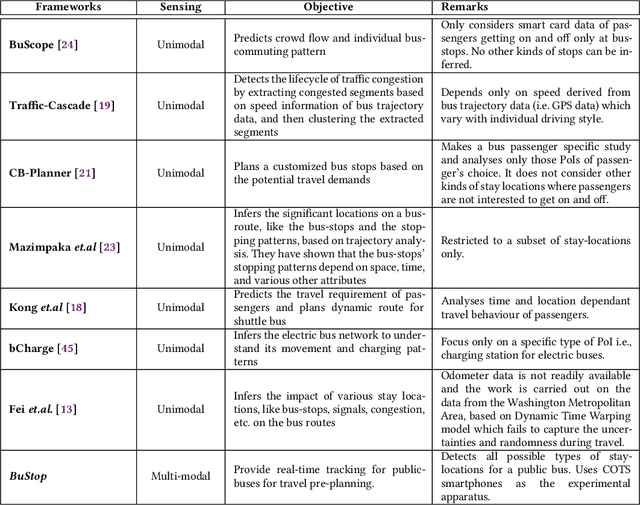
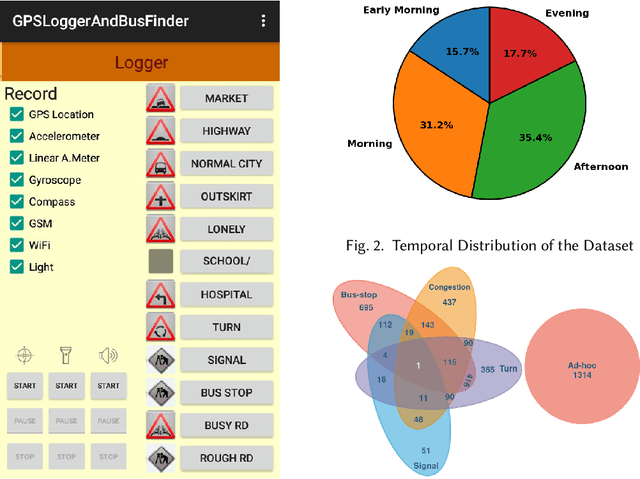


Intelligent city transportation systems are one of the core infrastructures of a smart city. The true ingenuity of such an infrastructure lies in providing the commuters with real-time information about citywide transports like public buses, allowing her to pre-plan the travel. However, providing prior information for transportation systems like public buses in real-time is inherently challenging because of the diverse nature of different stay-locations that a public bus stops. Although straightforward factors stay duration, extracted from unimodal sources like GPS, at these locations look erratic, a thorough analysis of public bus GPS trails for 720km of bus travels at the city of Durgapur, a semi-urban city in India, reveals that several other fine-grained contextual features can characterize these locations accurately. Accordingly, we develop BuStop, a system for extracting and characterizing the stay locations from multi-modal sensing using commuters' smartphones. Using this multi-modal information BuStop extracts a set of granular contextual features that allow the system to differentiate among the different stay-location types. A thorough analysis of BuStop using the collected dataset indicates that the system works with high accuracy in identifying different stay locations like regular bus stops, random ad-hoc stops, stops due to traffic congestion stops at traffic signals, and stops at sharp turns. Additionally, we also develop a proof-of-concept setup on top of BuStop to analyze the potential of the framework in predicting expected arrival time, a critical piece of information required to pre-plan travel, at any given bus stop. Subsequent analysis of the PoC framework, through simulation over the test dataset, shows that characterizing the stay-locations indeed helps make more accurate arrival time predictions with deviations less than 60s from the ground-truth arrival time.
Predicting Training Time Without Training
Aug 28, 2020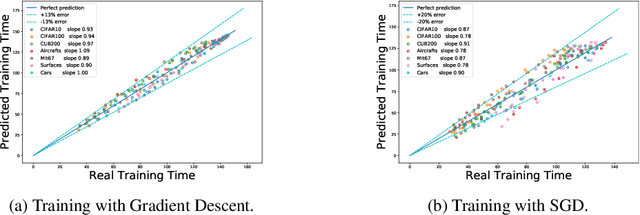
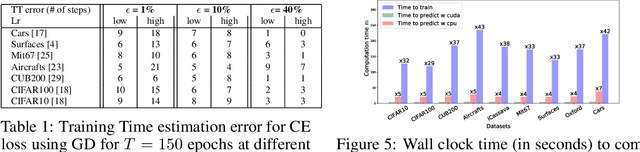
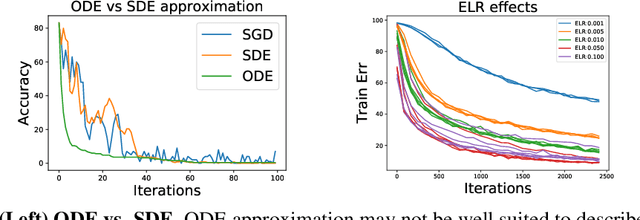
We tackle the problem of predicting the number of optimization steps that a pre-trained deep network needs to converge to a given value of the loss function. To do so, we leverage the fact that the training dynamics of a deep network during fine-tuning are well approximated by those of a linearized model. This allows us to approximate the training loss and accuracy at any point during training by solving a low-dimensional Stochastic Differential Equation (SDE) in function space. Using this result, we are able to predict the time it takes for Stochastic Gradient Descent (SGD) to fine-tune a model to a given loss without having to perform any training. In our experiments, we are able to predict training time of a ResNet within a 20% error margin on a variety of datasets and hyper-parameters, at a 30 to 45-fold reduction in cost compared to actual training. We also discuss how to further reduce the computational and memory cost of our method, and in particular we show that by exploiting the spectral properties of the gradients' matrix it is possible predict training time on a large dataset while processing only a subset of the samples.
Scaling up Ranking under Constraints for Live Recommendations by Replacing Optimization with Prediction
Feb 14, 2022

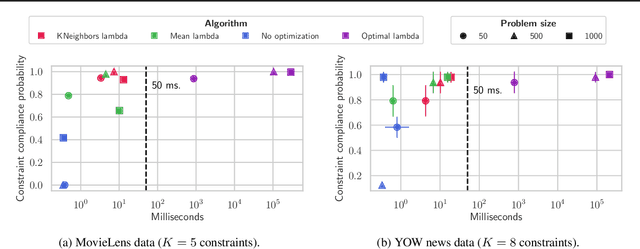
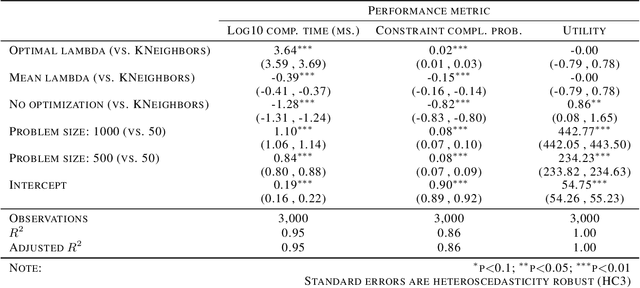
Many important multiple-objective decision problems can be cast within the framework of ranking under constraints and solved via a weighted bipartite matching linear program. Some of these optimization problems, such as personalized content recommendations, may need to be solved in real time and thus must comply with strict time requirements to prevent the perception of latency by consumers. Classical linear programming is too computationally inefficient for such settings. We propose a novel approach to scale up ranking under constraints by replacing the weighted bipartite matching optimization with a prediction problem in the algorithm deployment stage. We show empirically that the proposed approximate solution to the ranking problem leads to a major reduction in required computing resources without much sacrifice in constraint compliance and achieved utility, allowing us to solve larger constrained ranking problems real-time, within the required 50 milliseconds, than previously reported.
NeuVV: Neural Volumetric Videos with Immersive Rendering and Editing
Feb 12, 2022
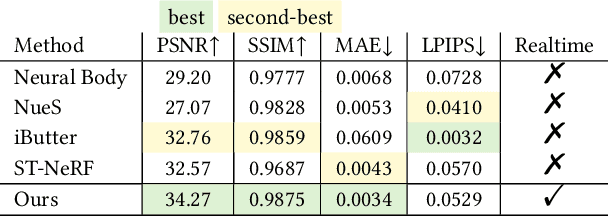
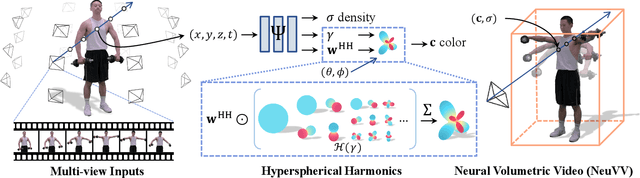
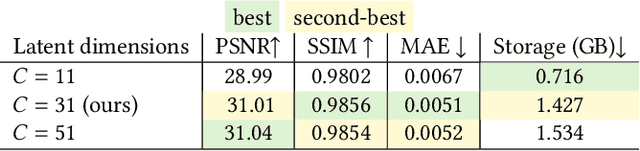
Some of the most exciting experiences that Metaverse promises to offer, for instance, live interactions with virtual characters in virtual environments, require real-time photo-realistic rendering. 3D reconstruction approaches to rendering, active or passive, still require extensive cleanup work to fix the meshes or point clouds. In this paper, we present a neural volumography technique called neural volumetric video or NeuVV to support immersive, interactive, and spatial-temporal rendering of volumetric video contents with photo-realism and in real-time. The core of NeuVV is to efficiently encode a dynamic neural radiance field (NeRF) into renderable and editable primitives. We introduce two types of factorization schemes: a hyper-spherical harmonics (HH) decomposition for modeling smooth color variations over space and time and a learnable basis representation for modeling abrupt density and color changes caused by motion. NeuVV factorization can be integrated into a Video Octree (VOctree) analogous to PlenOctree to significantly accelerate training while reducing memory overhead. Real-time NeuVV rendering further enables a class of immersive content editing tools. Specifically, NeuVV treats each VOctree as a primitive and implements volume-based depth ordering and alpha blending to realize spatial-temporal compositions for content re-purposing. For example, we demonstrate positioning varied manifestations of the same performance at different 3D locations with different timing, adjusting color/texture of the performer's clothing, casting spotlight shadows and synthesizing distance falloff lighting, etc, all at an interactive speed. We further develop a hybrid neural-rasterization rendering framework to support consumer-level VR headsets so that the aforementioned volumetric video viewing and editing, for the first time, can be conducted immersively in virtual 3D space.
Deep Learning-based Channel Estimation for Wideband Hybrid MmWave Massive MIMO
May 10, 2022
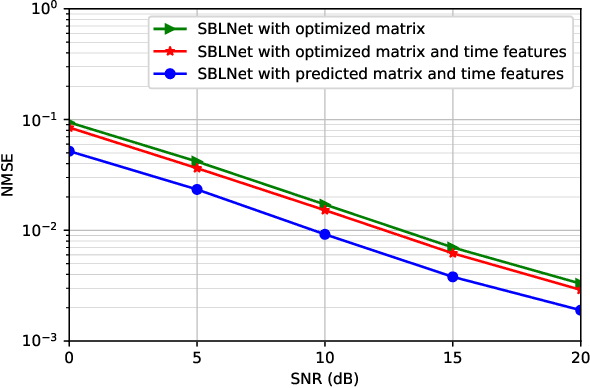
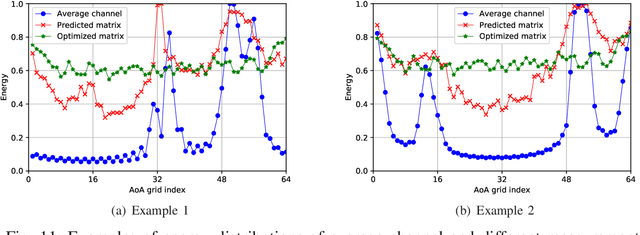
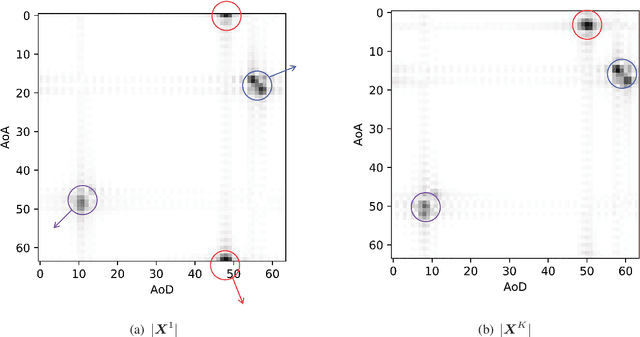
Hybrid analog-digital (HAD) architecture is widely adopted in practical millimeter wave (mmWave) massive multiple-input multiple-output (MIMO) systems to reduce hardware cost and energy consumption. However, channel estimation in the context of HAD is challenging due to only limited radio frequency (RF) chains at transceivers. Although various compressive sensing (CS) algorithms have been developed to solve this problem by exploiting inherent channel sparsity and sparsity structures, practical effects, such as power leakage and beam squint, can still make the real channel features deviate from the assumed models and result in performance degradation. Also, the high complexity of CS algorithms caused by a large number of iterations hinders their applications in practice. To tackle these issues, we develop a deep learning (DL)-based channel estimation approach where the sparse Bayesian learning (SBL) algorithm is unfolded into a deep neural network (DNN). In each SBL layer, Gaussian variance parameters of the sparse angular domain channel are updated by a tailored DNN, which is able to effectively capture complicated channel sparsity structures in various domains. Besides, the measurement matrix is jointly optimized for performance improvement. Then, the proposed approach is extended to the multi-block case where channel correlation in time is further exploited to adaptively predict the measurement matrix and facilitate the update of Gaussian variance parameters. Based on simulation results, the proposed approaches significantly outperform existing approaches but with reduced complexity.
A quantum Fourier transform (QFT) based note detection algorithm
Apr 30, 2022
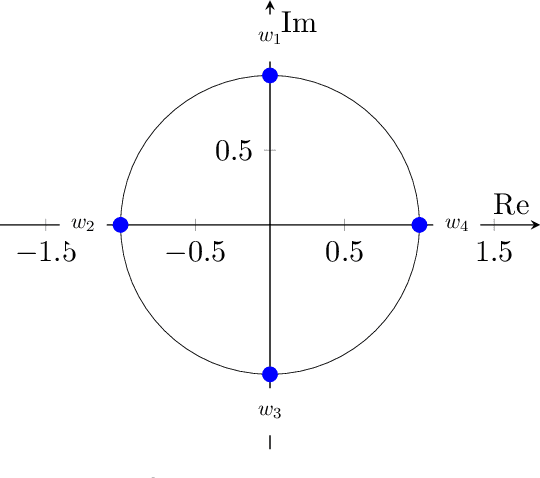

In quantum information processing (QIP), the quantum Fourier transform (QFT) has a plethora of applications [1] [2] [3]: Shor's algorithm and phase estimation are just a few well-known examples. Shor's quantum factorization algorithm, one of the most widely quoted quantum algorithms [4] [5] [6] relies heavily on the QFT and efficiently finds integer prime factors of large numbers on quantum computers [4]. This seminal ground-breaking design for quantum algorithms has triggered a cascade of viable alternatives to previously unsolvable problems on a classical computer that are potentially superior and can run in polynomial time. In this work we examine the QFT's structure and implementation for the creation of a quantum music note detection algorithm both on a simulated and a real quantum computer. Though formal approaches [7] [1] [8] [9] exist for the verification of quantum algorithms, in this study we limit ourselves to a simpler, symbolic representation which we validate using the symbolic SymPy [10] [11] package which symbolically replicates quantum computing processes. The algorithm is then implemented as a quantum circuit, using IBM's qiskit [12] library and finally period detection is exemplified on an actual single musical tone using a varying number of qubits.
Learning Eco-Driving Strategies at Signalized Intersections
Apr 26, 2022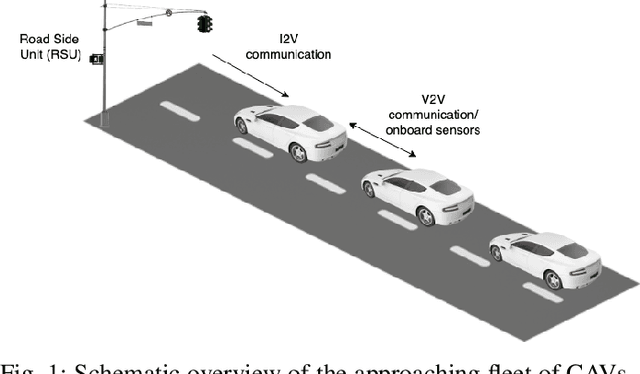
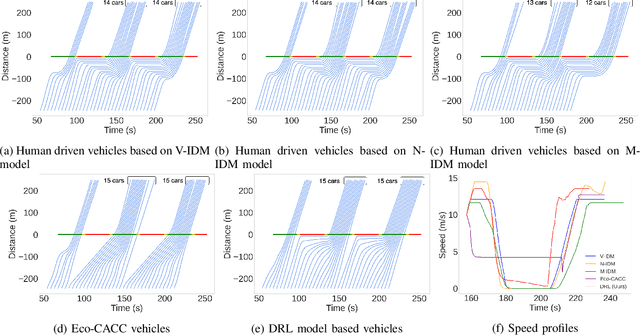
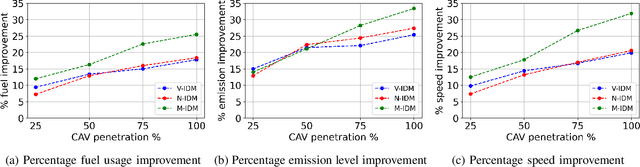
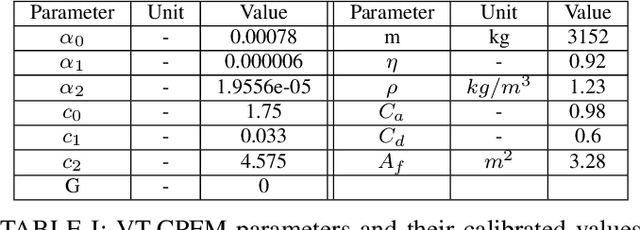
Signalized intersections in arterial roads result in persistent vehicle idling and excess accelerations, contributing to fuel consumption and CO2 emissions. There has thus been a line of work studying eco-driving control strategies to reduce fuel consumption and emission levels at intersections. However, methods to devise effective control strategies across a variety of traffic settings remain elusive. In this paper, we propose a reinforcement learning (RL) approach to learn effective eco-driving control strategies. We analyze the potential impact of a learned strategy on fuel consumption, CO2 emission, and travel time and compare with naturalistic driving and model-based baselines. We further demonstrate the generalizability of the learned policies under mixed traffic scenarios. Simulation results indicate that scenarios with 100% penetration of connected autonomous vehicles (CAV) may yield as high as 18% reduction in fuel consumption and 25% reduction in CO2 emission levels while even improving travel speed by 20%. Furthermore, results indicate that even 25% CAV penetration can bring at least 50% of the total fuel and emission reduction benefits.