 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ultra Fast Speech Separation Model with Teacher Student Learning
Apr 27, 2022
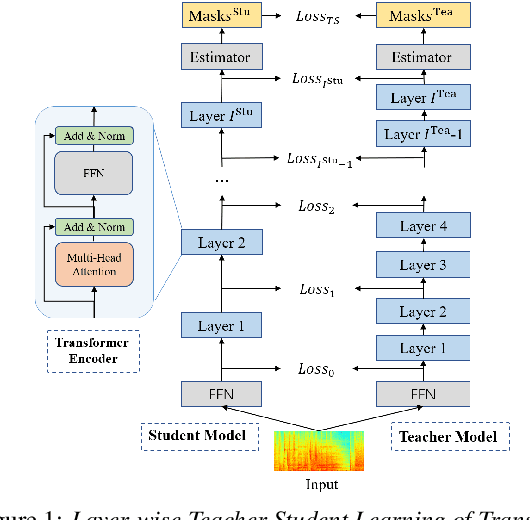
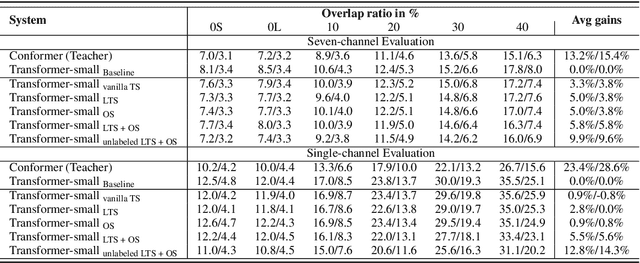
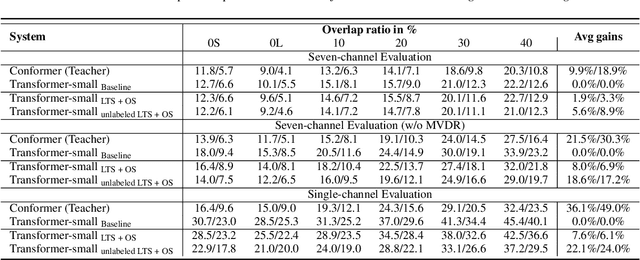
Transformer has been successfully applied to speech separation recently with its strong long-dependency modeling capacity using a self-attention mechanism. However, Transformer tends to have heavy run-time costs due to the deep encoder layers, which hinders its deployment on edge devices. A small Transformer model with fewer encoder layers is preferred for computational efficiency, but it is prone to performance degradation. In this paper, an ultra fast speech separation Transformer model is proposed to achieve both better performance and efficiency with teacher student learning (T-S learning). We introduce layer-wise T-S learning and objective shifting mechanisms to guide the small student model to learn intermediate representations from the large teacher model. Compared with the small Transformer model trained from scratch, the proposed T-S learning method reduces the word error rate (WER) by more than 5% for both multi-channel and single-channel speech separation on LibriCSS dataset. Utilizing more unlabeled speech data, our ultra fast speech separation models achieve more than 10% relative WER reduction.
Style-Guided Domain Adaptation for Face Presentation Attack Detection
Mar 28, 2022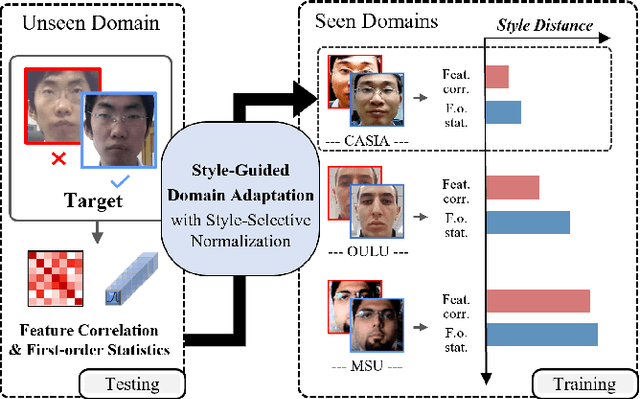
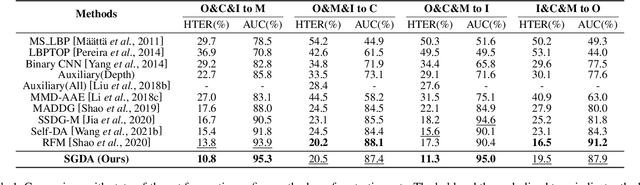
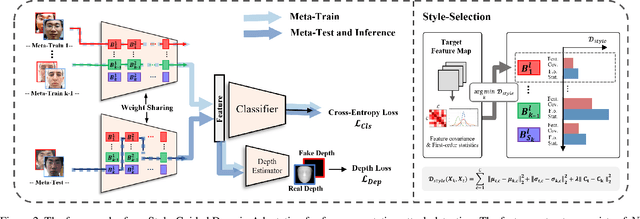

Domain adaptation (DA) or domain generalization (DG) for face presentation attack detection (PAD) has attracted attention recently with its robustness against unseen attack scenarios. Existing DA/DG-based PAD methods, however, have not yet fully explored the domain-specific style information that can provide knowledge regarding attack styles (e.g., materials, background, illumination and resolution). In this paper, we introduce a novel Style-Guided Domain Adaptation (SGDA) framework for inference-time adaptive PAD. Specifically, Style-Selective Normalization (SSN) is proposed to explore the domain-specific style information within the high-order feature statistics. The proposed SSN enables the adaptation of the model to the target domain by reducing the style difference between the target and the source domains. Moreover, we carefully design Style-Aware Meta-Learning (SAML) to boost the adaptation ability, which simulates the inference-time adaptation with style selection process on virtual test domain. In contrast to previous domain adaptation approaches, our method does not require either additional auxiliary models (e.g., domain adaptors) or the unlabeled target domain during training, which makes our method more practical to PAD task. To verify our experiments, we utilize the public datasets: MSU-MFSD, CASIA-FASD, OULU-NPU and Idiap REPLAYATTACK. In most assessments, the result demonstrates a notable gap of performance compared to the conventional DA/DG-based PAD methods.
Worst-Case Dynamic Power Distribution Network Noise Prediction Using Convolutional Neural Network
Apr 27, 2022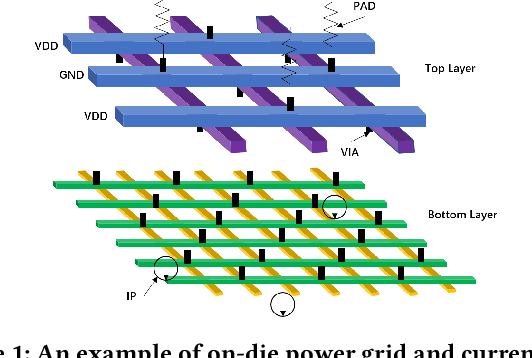
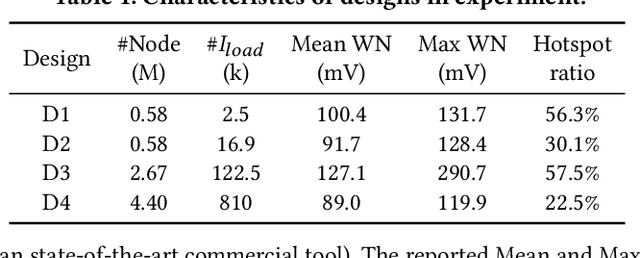
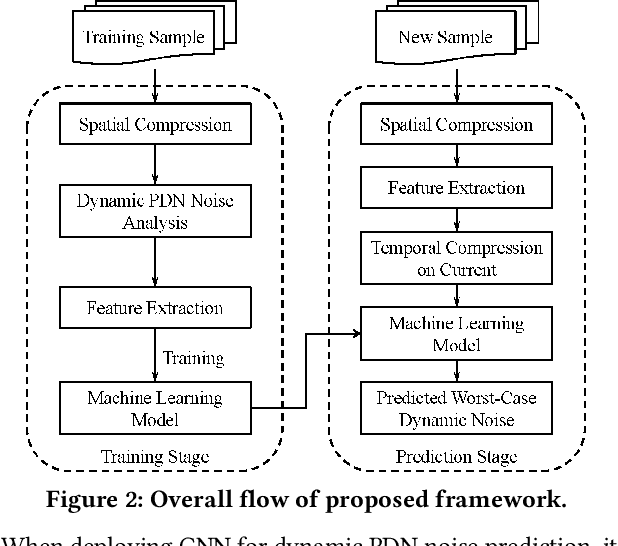

Worst-case dynamic PDN noise analysis is an essential step in PDN sign-off to ensure the performance and reliability of chips. However, with the growing PDN size and increasing scenarios to be validated, it becomes very time- and resource-consuming to conduct full-stack PDN simulation to check the worst-case noise for different test vectors. Recently, various works have proposed machine learning based methods for supply noise prediction, many of which still suffer from large training overhead, inefficiency, or non-scalability. Thus, this paper proposed an efficient and scalable framework for the worst-case dynamic PDN noise prediction. The framework first reduces the spatial and temporal redundancy in the PDN and input current vector, and then employs efficient feature extraction as well as a novel convolutional neural network architecture to predict the worst-case dynamic PDN noise. Experimental results show that the proposed framework consistently outperforms the commercial tool and the state-of-the-art machine learning method with only 0.63-1.02% mean relative error and 25-69$\times$ speedup.
Model selection in reconciling hierarchical time series
Oct 29, 2020
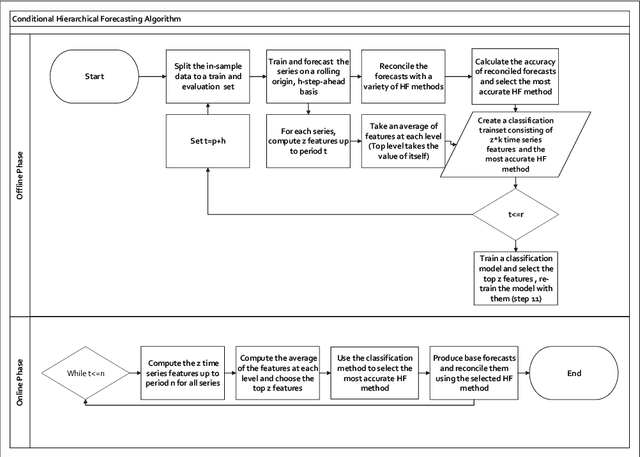
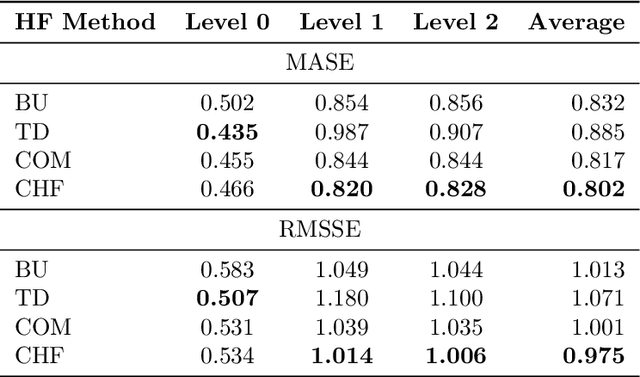
Model selection has been proven an effective strategy for improving accuracy in time series forecasting applications. However, when dealing with hierarchical time series, apart from selecting the most appropriate forecasting model, forecasters have also to select a suitable method for reconciling the base forecasts produced for each series to make sure they are coherent. Although some hierarchical forecasting methods like minimum trace are strongly supported both theoretically and empirically for reconciling the base forecasts, there are still circumstances under which they might not produce the most accurate results, being outperformed by other methods. In this paper we propose an approach for dynamically selecting the most appropriate hierarchical forecasting method and succeeding better forecasting accuracy along with coherence. The approach, to be called conditional hierarchical forecasting, is based on Machine Learning classification methods and uses time series features as leading indicators for performing the selection for each hierarchy examined considering a variety of alternatives. Our results suggest that conditional hierarchical forecasting leads to significantly more accurate forecasts than standard approaches, especially at lower hierarchical levels.
Decision-Time Postponing Motion Planning for Combinatorial Uncertain Maneuvering
Dec 13, 2020
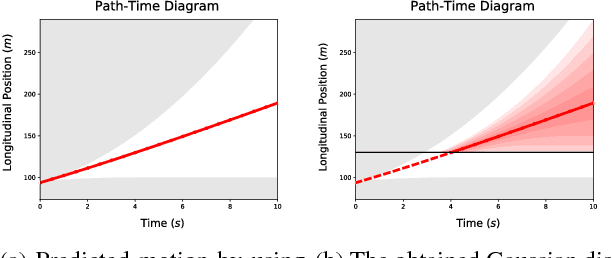
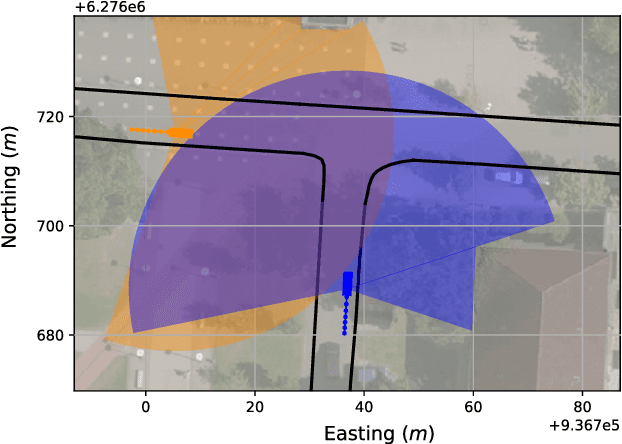
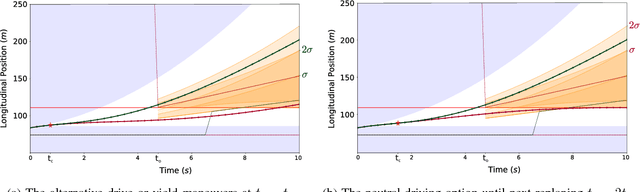
Motion planning involves decision making among combinatorial maneuver variants in urban driving. A planner must consider uncertainties and associated risks of the maneuver variants, and subsequently select a maneuver alternative. In this paper we present a planning approach that considers the uncertainties in the prediction and, in case of high uncertainty, postpones the combinatorial decision making to a later time within the planning horizon. With our proposed approach, safe but at the same time not overconservative motion is planned.
* 7 pages, 5 figures
A Study on Prompt-based Few-Shot Learning Methods for Belief State Tracking in Task-oriented Dialog Systems
Apr 18, 2022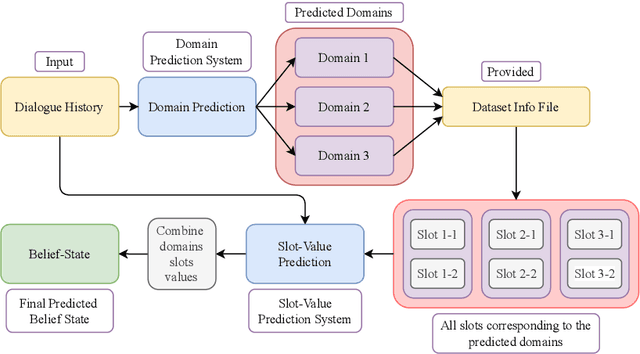
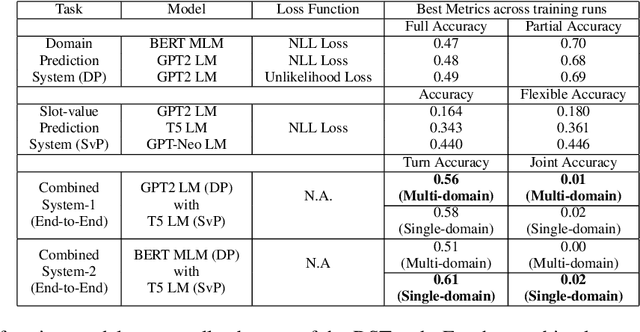
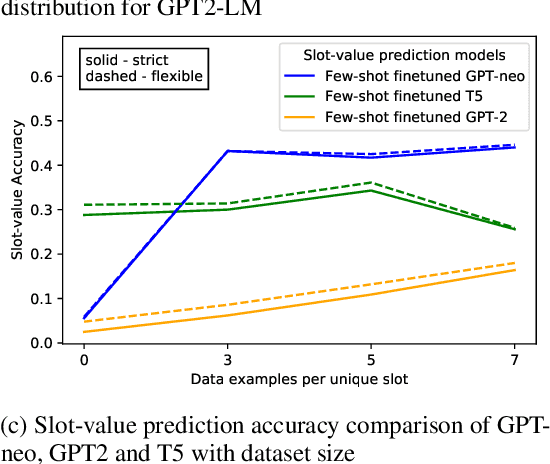
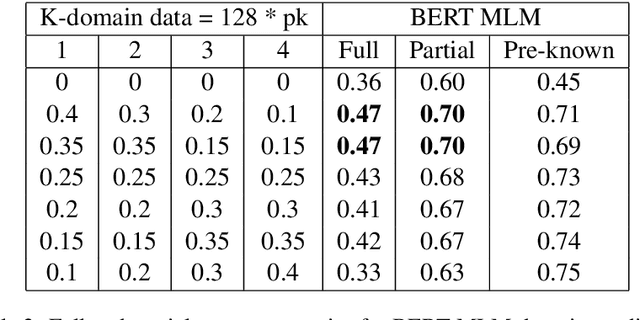
We tackle the Dialogue Belief State Tracking(DST) problem of task-oriented conversational systems. Recent approaches to this problem leveraging Transformer-based models have yielded great results. However, training these models is expensive, both in terms of computational resources and time. Additionally, collecting high quality annotated dialogue datasets remains a challenge for researchers because of the extensive annotation required for training these models. Driven by the recent success of pre-trained language models and prompt-based learning, we explore prompt-based few-shot learning for Dialogue Belief State Tracking. We formulate the DST problem as a 2-stage prompt-based language modelling task and train language models for both tasks and present a comprehensive empirical analysis of their separate and joint performance. We demonstrate the potential of prompt-based methods in few-shot learning for DST and provide directions for future improvement.
CryoRL: Reinforcement Learning Enables Efficient Cryo-EM Data Collection
Apr 15, 2022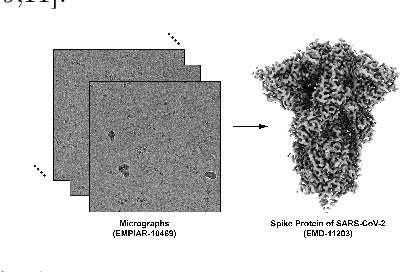

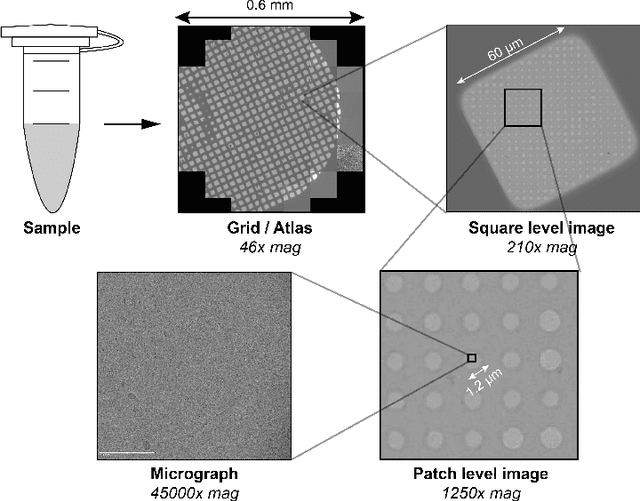

Single-particle cryo-electron microscopy (cryo-EM) has become one of the mainstream structural biology techniques because of its ability to determine high-resolution structures of dynamic bio-molecules. However, cryo-EM data acquisition remains expensive and labor-intensive, requiring substantial expertise. Structural biologists need a more efficient and objective method to collect the best data in a limited time frame. We formulate the cryo-EM data collection task as an optimization problem in this work. The goal is to maximize the total number of good images taken within a specified period. We show that reinforcement learning offers an effective way to plan cryo-EM data collection, successfully navigating heterogenous cryo-EM grids. The approach we developed, cryoRL, demonstrates better performance than average users for data collection under similar settings.
Evaluation of Multi-Scale Multiple Instance Learning to Improve Thyroid Cancer Classification
Apr 22, 2022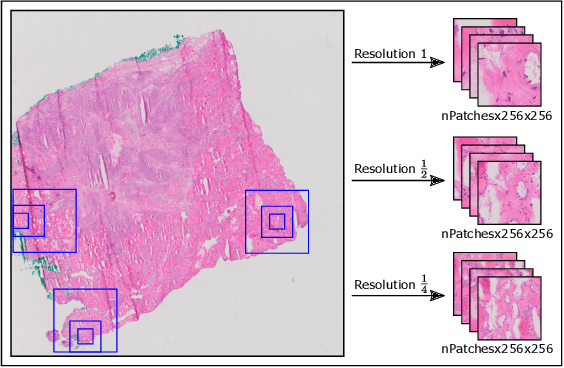
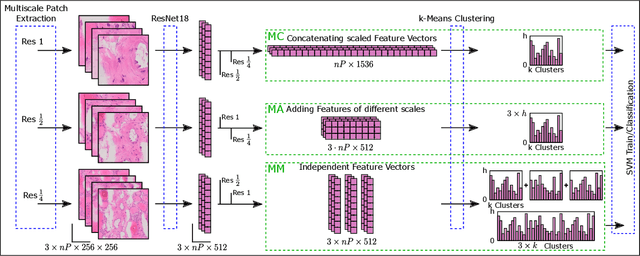
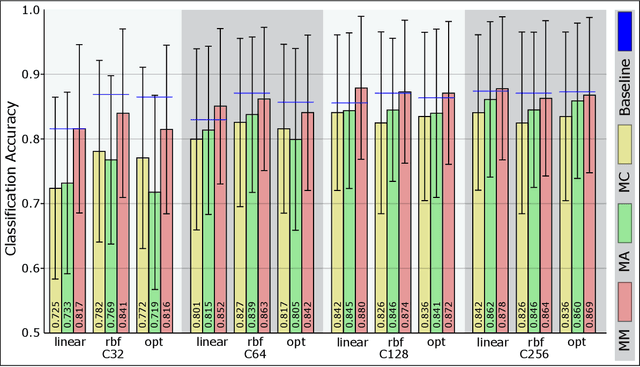
Thyroid cancer is currently the fifth most common malignancy diagnosed in women. Since differentiation of cancer sub-types is important for treatment and current, manual methods are time consuming and subjective, automatic computer-aided differentiation of cancer types is crucial. Manual differentiation of thyroid cancer is based on tissue sections, analysed by pathologists using histological features. Due to the enormous size of gigapixel whole slide images, holistic classification using deep learning methods is not feasible. Patch based multiple instance learning approaches, combined with aggregations such as bag-of-words, is a common approach. This work's contribution is to extend a patch based state-of-the-art method by generating and combining feature vectors of three different patch resolutions and analysing three distinct ways of combining them. The results showed improvements in one of the three multi-scale approaches, while the others led to decreased scores. This provides motivation for analysis and discussion of the individual approaches.
TC-Driver: Trajectory Conditioned Driving for Robust Autonomous Racing -- A Reinforcement Learning Approach
May 19, 2022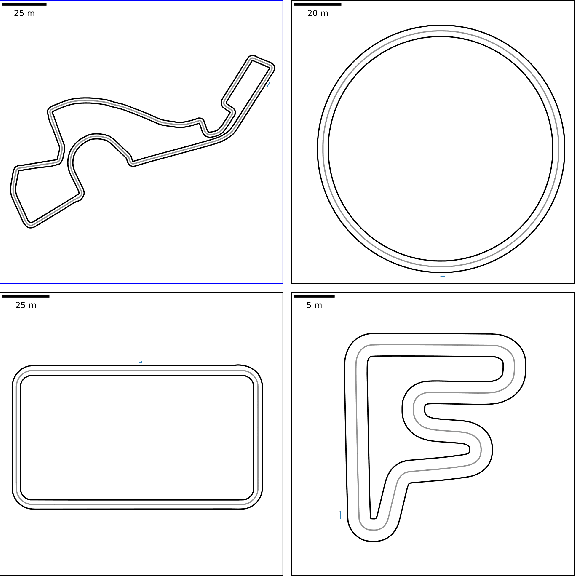
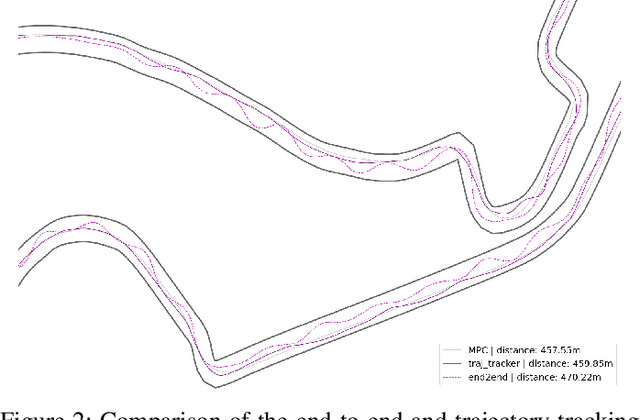
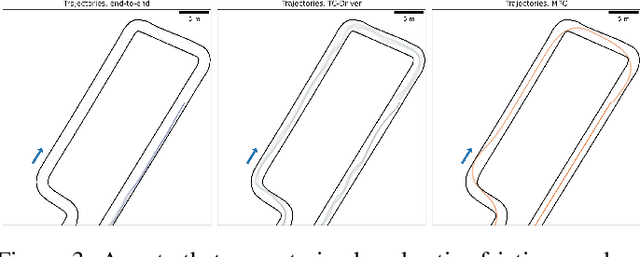
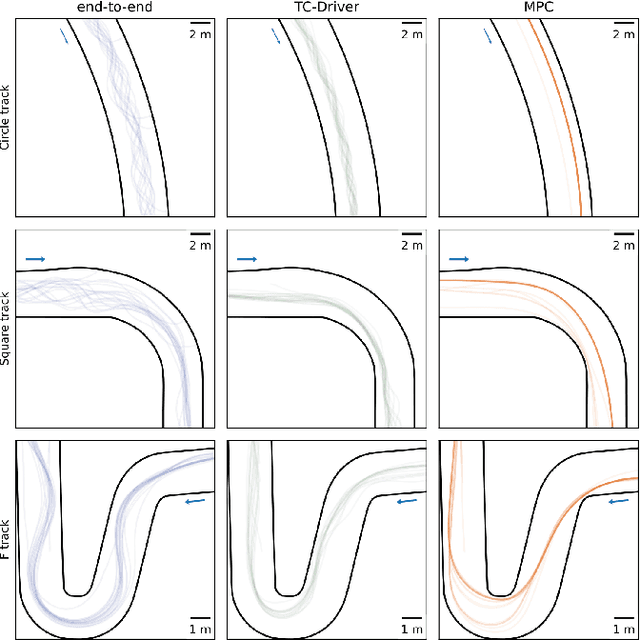
Autonomous racing is becoming popular for academic and industry researchers as a test for general autonomous driving by pushing perception, planning, and control algorithms to their limits. While traditional control methods such as MPC are capable of generating an optimal control sequence at the edge of the vehicles physical controllability, these methods are sensitive to the accuracy of the modeling parameters. This paper presents TC-Driver, a RL approach for robust control in autonomous racing. In particular, the TC-Driver agent is conditioned by a trajectory generated by any arbitrary traditional high-level planner. The proposed TC-Driver addresses the tire parameter modeling inaccuracies by exploiting the heuristic nature of RL while leveraging the reliability of traditional planning methods in a hierarchical control structure. We train the agent under varying tire conditions, allowing it to generalize to different model parameters, aiming to increase the racing capabilities of the system in practice. The proposed RL method outperforms a non-learning-based MPC with a 2.7 lower crash ratio in a model mismatch setting, underlining robustness to parameter discrepancies. In addition, the average RL inference duration is 0.25 ms compared to the average MPC solving time of 11.5 ms, yielding a nearly 40-fold speedup, allowing for complex control deployment in computationally constrained devices. Lastly, we show that the frequently utilized end-to-end RL architecture, as a control policy directly learned from sensory input, is not well suited to model mismatch robustness nor track generalization. Our realistic simulations show that TC-Driver achieves a 6.7 and 3-fold lower crash ratio under model mismatch and track generalization settings, while simultaneously achieving lower lap times than an end-to-end approach, demonstrating the viability of TC-driver to robust autonomous racing.
Channel Estimation and Projection for RIS-assisted MIMO Using Zadoff-Chu Sequences
Feb 21, 2022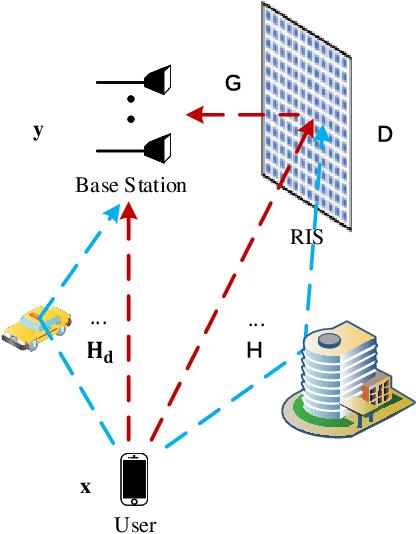

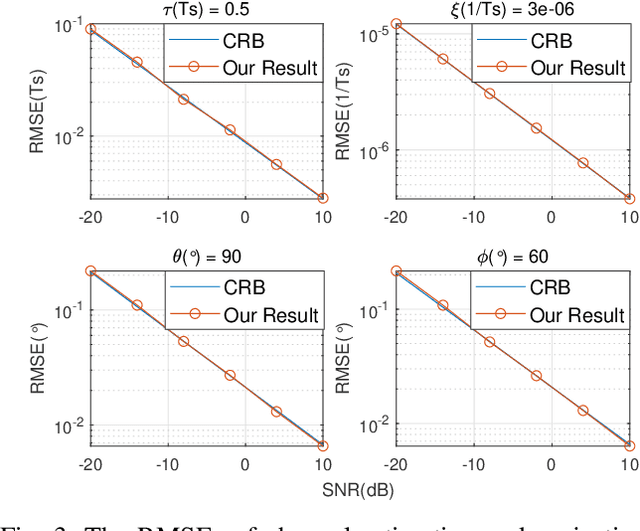
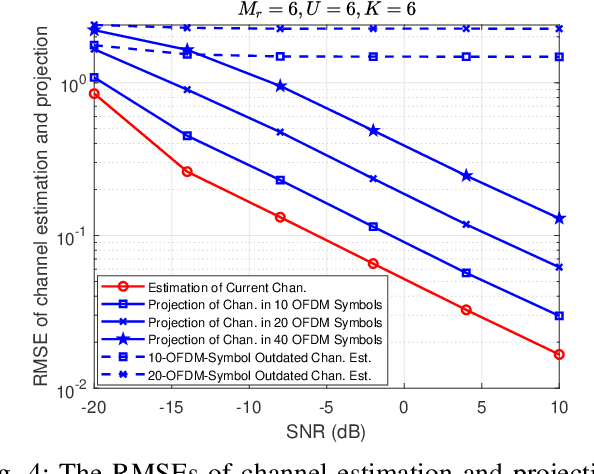
The reconfigurable intelligent surface (RIS) technology is a promising enabler for millimeter wave (mmWave) wireless communications, as it can potentially provide spectral efficiency comparable to the conventional massive multiple-input multiple-output (MIMO) but with significantly lower hardware complexity. In this paper, we focus on the estimation and projection of the uplink RIS-aided massive MIMO channel, which can be time-varying. We propose to let the user equipments (UE) transmit Zadoff-Chu (ZC) sequences and let the base station (BS) conduct maximum likelihood (ML) estimation of the uplink channel. The proposed scheme is computationally efficient: it uses ZC sequences to decouple the estimation of the frequency and time offsets; it uses the space-alternating generalized expectation-maximization (SAGE) method to reduce the high-dimensional problem due to the multipaths to multiple lower-dimensional ones per path. Owing to the estimation of the Doppler frequency offsets, the time-varying channel state can be projected, which can significantly lower the overhead of the pilots for channel estimation. The numerical simulations verify the effectiveness of the proposed scheme.