 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Training Time Without Training
Aug 28, 2020
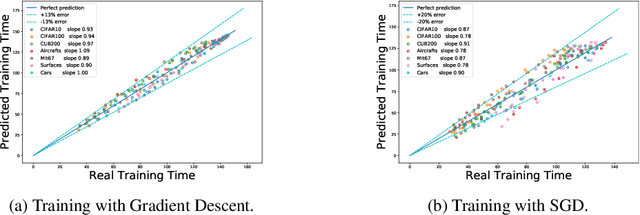
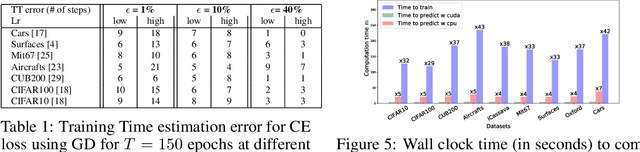
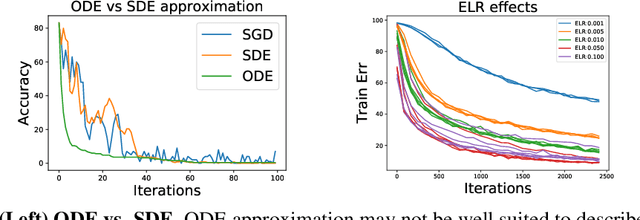
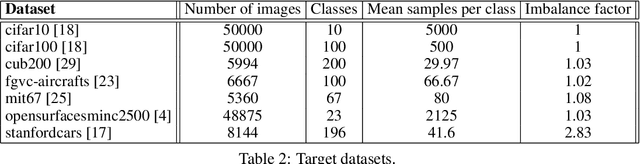
We tackle the problem of predicting the number of optimization steps that a pre-trained deep network needs to converge to a given value of the loss function. To do so, we leverage the fact that the training dynamics of a deep network during fine-tuning are well approximated by those of a linearized model. This allows us to approximate the training loss and accuracy at any point during training by solving a low-dimensional Stochastic Differential Equation (SDE) in function space. Using this result, we are able to predict the time it takes for Stochastic Gradient Descent (SGD) to fine-tune a model to a given loss without having to perform any training. In our experiments, we are able to predict training time of a ResNet within a 20% error margin on a variety of datasets and hyper-parameters, at a 30 to 45-fold reduction in cost compared to actual training. We also discuss how to further reduce the computational and memory cost of our method, and in particular we show that by exploiting the spectral properties of the gradients' matrix it is possible predict training time on a large dataset while processing only a subset of the samples.
Segmentation with Super Images: A New 2D Perspective on 3D Medical Image Analysis
May 05, 2022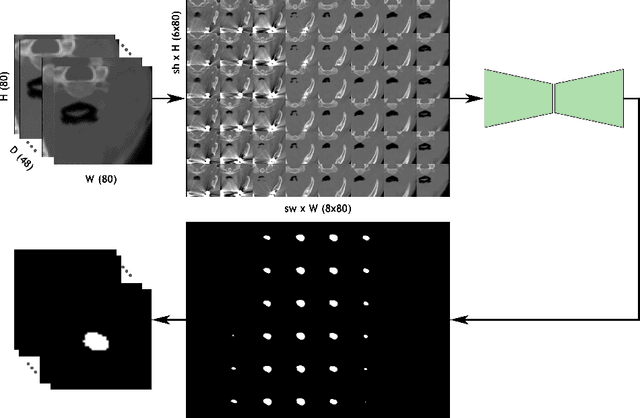
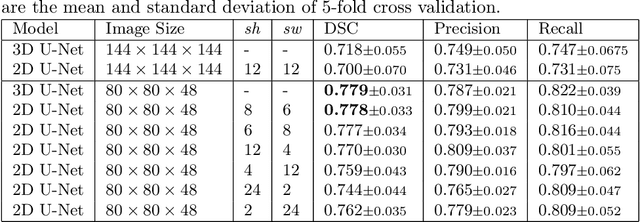

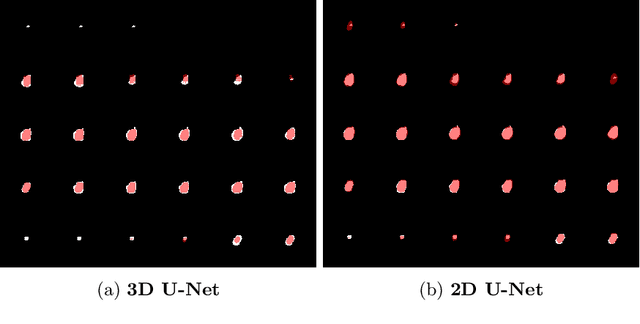
Deep learning is showing an increasing number of audience in medical imaging research. In the segmentation task of medical images, we oftentimes rely on volumetric data, and thus require the use of 3D architectures which are praised for their ability to capture more features from the depth dimension. Yet, these architectures are generally more ineffective in time and compute compared to their 2D counterpart on account of 3D convolutions, max pooling, up-convolutions, and other operations used in these networks. Moreover, there are limited to no 3D pretrained model weights, and pretraining is generally challenging. To alleviate these issues, we propose to cast volumetric data to 2D super images and use 2D networks for the segmentation task. The method processes the 3D image by stitching slices side-by-side to generate a super resolution image. While the depth information is lost, we expect that deep neural networks can still capture and learn these features. Our goal in this work is to introduce a new perspective when dealing with volumetric data, and test our hypothesis using vanilla networks. We hope that this approach, while achieving close enough results to 3D networks using only 2D counterparts, can attract more related research in the future, especially in medical image analysis since volumetric data is comparably limited.
A Survey and Perspective on Artificial Intelligence for Security-Aware Electronic Design Automation
Apr 21, 2022
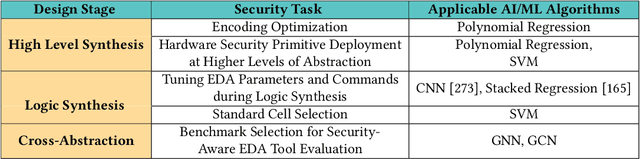
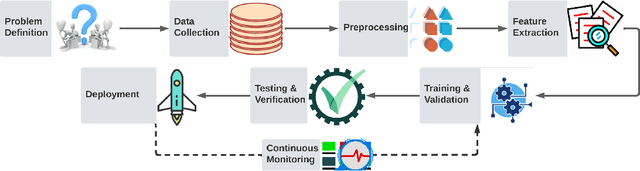
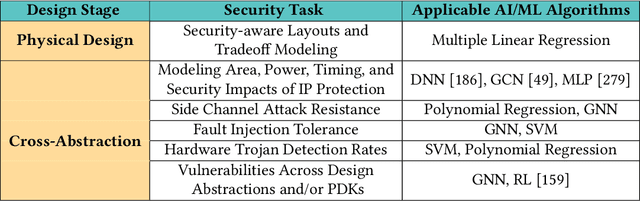
Artificial intelligence (AI) and machine learning (ML) techniques have been increasingly used in several fields to improve performance and the level of automation. In recent years, this use has exponentially increased due to the advancement of high-performance computing and the ever increasing size of data. One of such fields is that of hardware design; specifically the design of digital and analog integrated circuits~(ICs), where AI/ ML techniques have been extensively used to address ever-increasing design complexity, aggressive time-to-market, and the growing number of ubiquitous interconnected devices (IoT). However, the security concerns and issues related to IC design have been highly overlooked. In this paper, we summarize the state-of-the-art in AL/ML for circuit design/optimization, security and engineering challenges, research in security-aware CAD/EDA, and future research directions and needs for using AI/ML for security-aware circuit design.
Towards Deep Industrial Transfer Learning: Clustering for Transfer Case Selection
Apr 04, 2022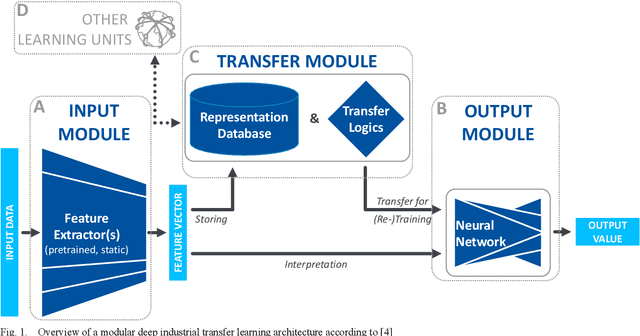
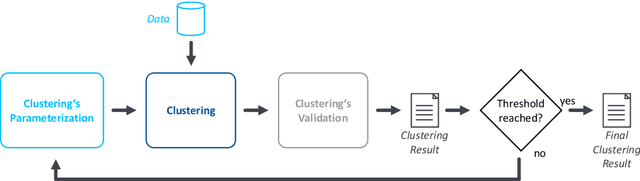
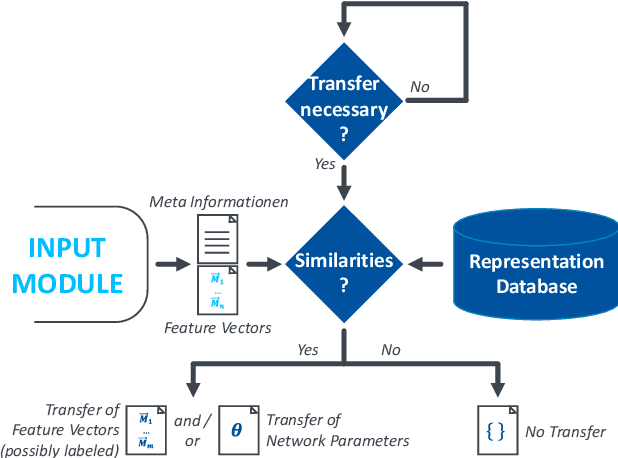
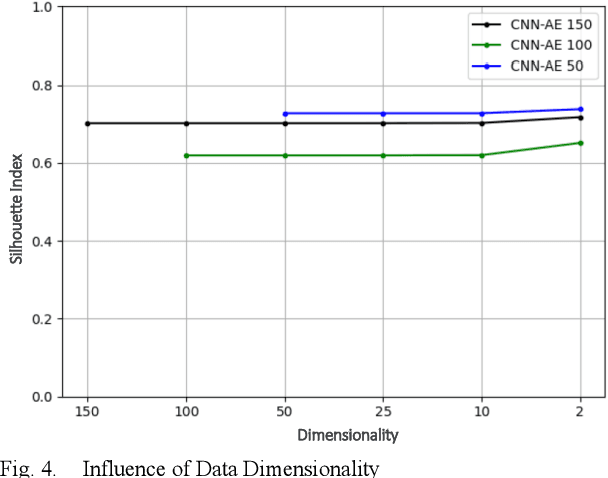
Industrial transfer learning increases the adaptability of deep learning algorithms towards heterogenous and dynamic industrial use cases without high manual efforts. The appropriate selection of what to transfer can vastly improve a transfer's results. In this paper, a transfer case selection based upon clustering is presented. Founded on a survey of clustering algorithms, the BIRCH algorithm is selected for this purpose. It is evaluated on an industrial time series dataset from a discrete manufacturing scenario. Results underline the approaches' applicability caused by its results' reproducibility and practical indifference to sequence, size and dimensionality of (sub-)datasets to be clustered sequentially.
Robust Beamforming Design and Time Allocation for IRS-assisted Wireless Powered Communication Networks
May 13, 2021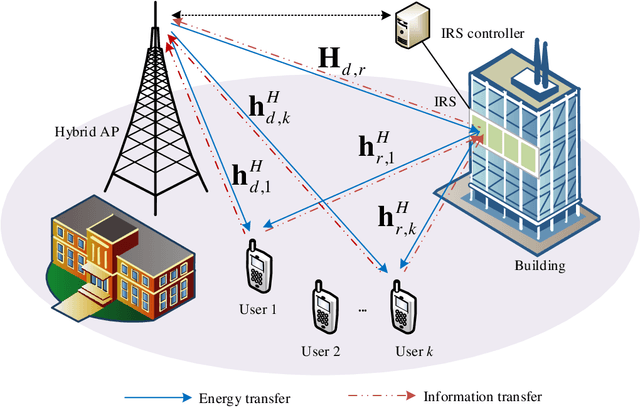
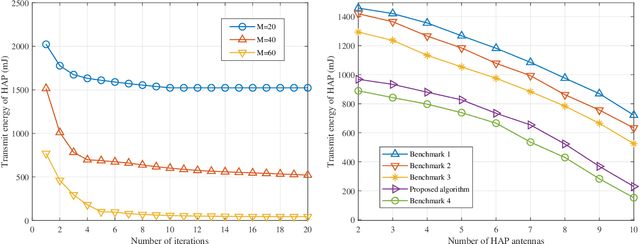
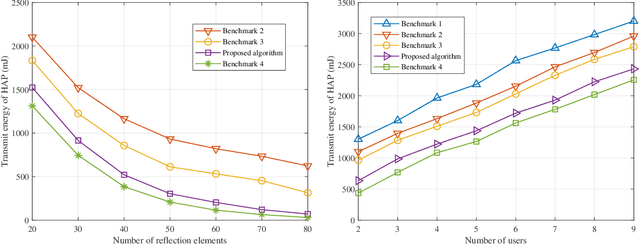
In this paper, a novel intelligent reflecting surface (IRS)-assisted wireless powered communication network (WPCN) architecture is proposed for low-power Internet-of-Things (IoT) devices, where the IRS is exploited to improve the performance of WPCN under imperfect channel state information (CSI). We formulate a hybrid access point (HAP) transmission energy minimization problem by a joint design of time allocation, HAP energy beamforming, receiving beamforming, user transmit power allocation, IRS energy reflection coefficient and information reflection coefficient under the imperfect CSI and non-linear energy harvesting model. Due to the high coupling of optimization variables, this problem is a non-convex optimization problem, which is difficult to solve directly. In order to solve the above-mentioned challenging problems, the alternating optimization (AO) is applied to decouple the optimization variables to solve the problem. Specifically, through AO, time allocation, HAP energy beamforming, receiving beamforming, user transmit power allocation, IRS energy reflection coefficient and information reflection coefficient are divided into three sub-problems to be solved alternately. The difference-of-convex (DC) programming is applied to solve the non-convex rank-one constraint in solving the IRS energy reflection coefficient and information reflection coefficient. Numerical simulations verify the effectiveness of our proposed algorithm in reducing HAP transmission energy compared to other benchmarks.
Learning Graph Neural Networks for Multivariate Time Series Anomaly Detection
Nov 15, 2021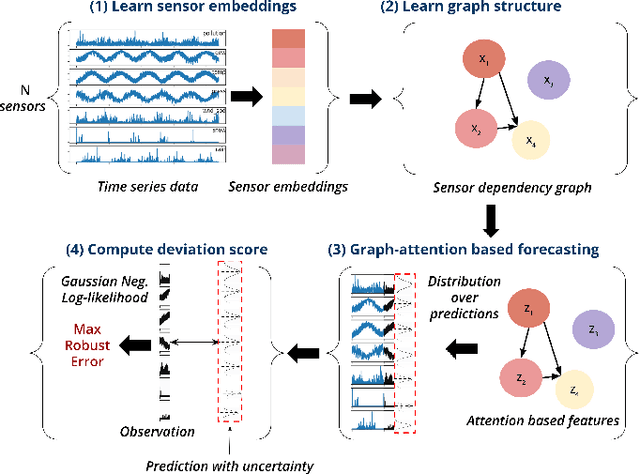
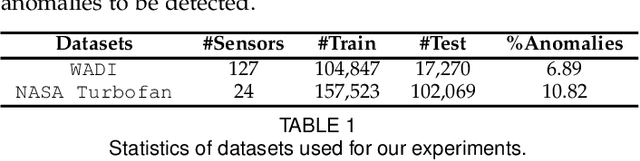
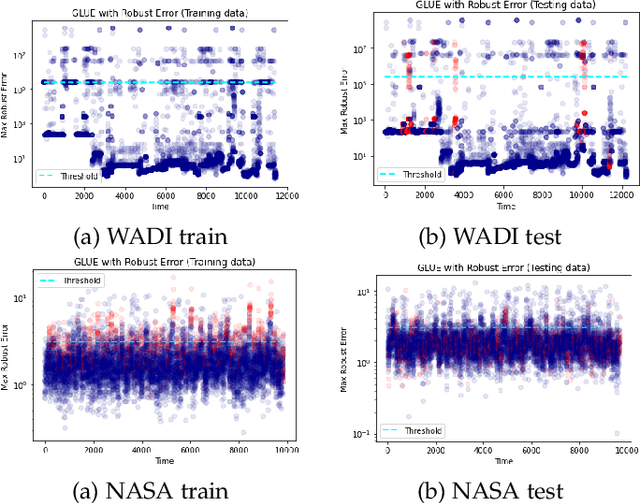
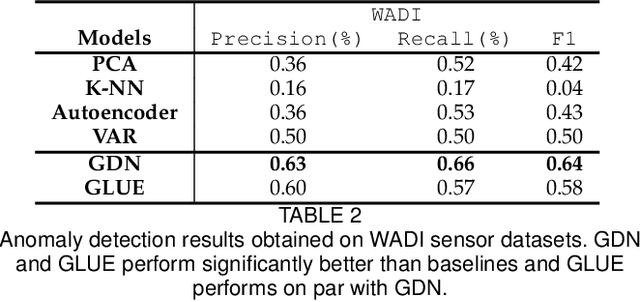
In this work, we propose GLUE (Graph Deviation Network with Local Uncertainty Estimation), building on the recently proposed Graph Deviation Network (GDN). GLUE not only automatically learns complex dependencies between variables and uses them to better identify anomalous behavior, but also quantifies its predictive uncertainty, allowing us to account for the variation in the data as well to have more interpretable anomaly detection thresholds. Results on two real world datasets tell us that optimizing the negative Gaussian log likelihood is reasonable because GLUE's forecasting results are at par with GDN and in fact better than the vector autoregressor baseline, which is significant given that GDN directly optimizes the MSE loss. In summary, our experiments demonstrate that GLUE is competitive with GDN at anomaly detection, with the added benefit of uncertainty estimations. We also show that GLUE learns meaningful sensor embeddings which clusters similar sensors together.
Improving RNN-T ASR Performance with Date-Time and Location Awareness
Jun 11, 2021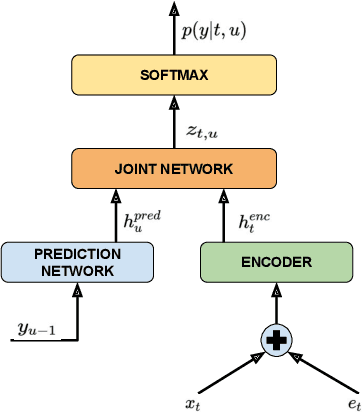
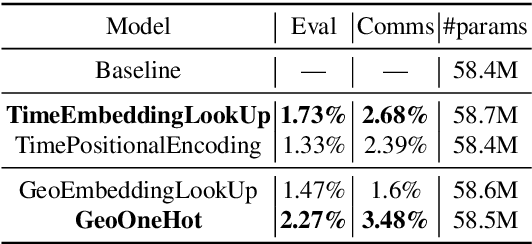
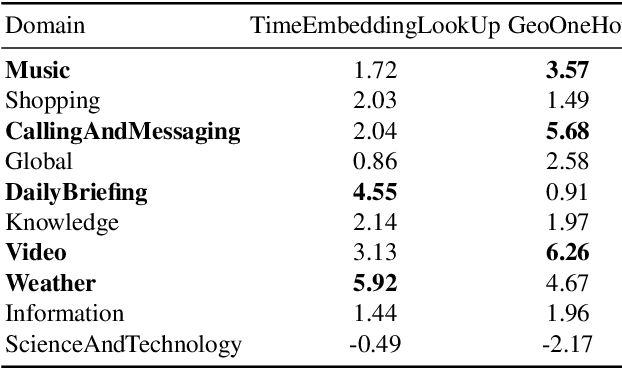

In this paper, we explore the benefits of incorporating context into a Recurrent Neural Network (RNN-T) based Automatic Speech Recognition (ASR) model to improve the speech recognition for virtual assistants. Specifically, we use meta information extracted from the time at which the utterance is spoken and the approximate location information to make ASR context aware. We show that these contextual information, when used individually, improves overall performance by as much as 3.48% relative to the baseline and when the contexts are combined, the model learns complementary features and the recognition improves by 4.62%. On specific domains, these contextual signals show improvements as high as 11.5%, without any significant degradation on others. We ran experiments with models trained on data of sizes 30K hours and 10K hours. We show that the scale of improvement with the 10K hours dataset is much higher than the one obtained with 30K hours dataset. Our results indicate that with limited data to train the ASR model, contextual signals can improve the performance significantly.
Pessimism meets VCG: Learning Dynamic Mechanism Design via Offline Reinforcement Learning
May 05, 2022Dynamic mechanism design has garnered significant attention from both computer scientists and economists in recent years. By allowing agents to interact with the seller over multiple rounds, where agents' reward functions may change with time and are state dependent, the framework is able to model a rich class of real world problems. In these works, the interaction between agents and sellers are often assumed to follow a Markov Decision Process (MDP). We focus on the setting where the reward and transition functions of such an MDP are not known a priori, and we are attempting to recover the optimal mechanism using an a priori collected data set. In the setting where the function approximation is employed to handle large state spaces, with only mild assumptions on the expressiveness of the function class, we are able to design a dynamic mechanism using offline reinforcement learning algorithms. Moreover, learned mechanisms approximately have three key desiderata: efficiency, individual rationality, and truthfulness. Our algorithm is based on the pessimism principle and only requires a mild assumption on the coverage of the offline data set. To the best of our knowledge, our work provides the first offline RL algorithm for dynamic mechanism design without assuming uniform coverage.
RepSR: Training Efficient VGG-style Super-Resolution Networks with Structural Re-Parameterization and Batch Normalization
May 11, 2022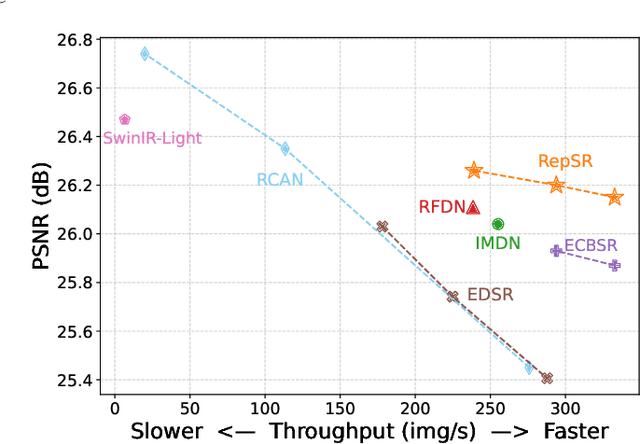
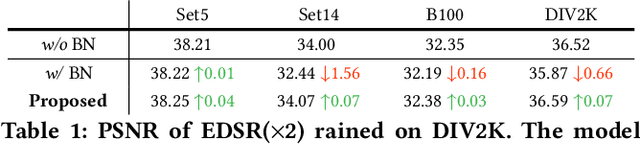
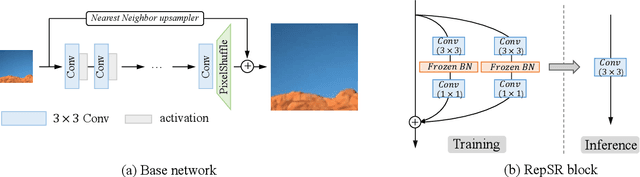
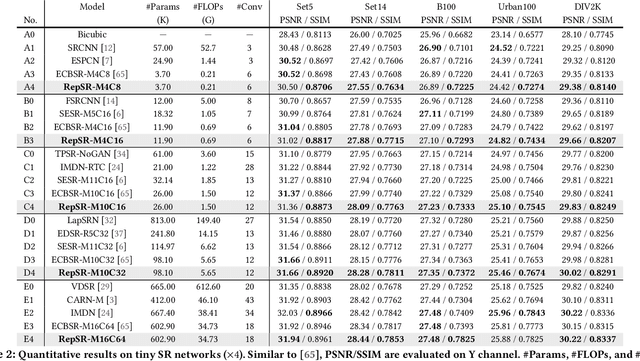
This paper explores training efficient VGG-style super-resolution (SR) networks with the structural re-parameterization technique. The general pipeline of re-parameterization is to train networks with multi-branch topology first, and then merge them into standard 3x3 convolutions for efficient inference. In this work, we revisit those primary designs and investigate essential components for re-parameterizing SR networks. First of all, we find that batch normalization (BN) is important to bring training non-linearity and improve the final performance. However, BN is typically ignored in SR, as it usually degrades the performance and introduces unpleasant artifacts. We carefully analyze the cause of BN issue and then propose a straightforward yet effective solution. In particular, we first train SR networks with mini-batch statistics as usual, and then switch to using population statistics at the later training period. While we have successfully re-introduced BN into SR, we further design a new re-parameterizable block tailored for SR, namely RepSR. It consists of a clean residual path and two expand-and-squeeze convolution paths with the modified BN. Extensive experiments demonstrate that our simple RepSR is capable of achieving superior performance to previous SR re-parameterization methods among different model sizes. In addition, our RepSR can achieve a better trade-off between performance and actual running time (throughput) than previous SR methods. Codes will be available at https://github.com/TencentARC/RepSR.
Channel Estimation and Projection for RIS-assisted MIMO Using Zadoff-Chu Sequences
Feb 21, 2022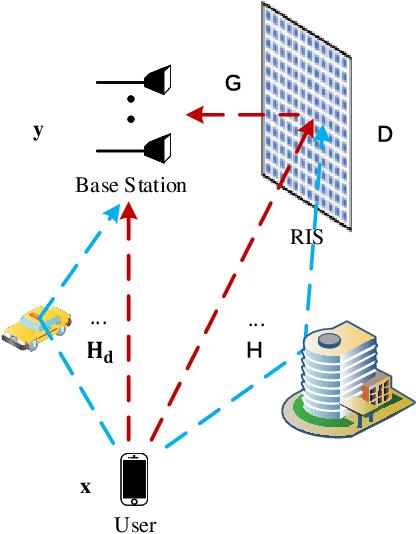

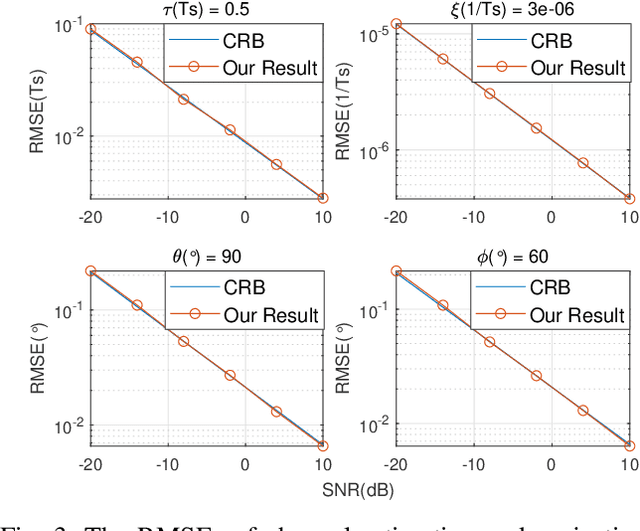
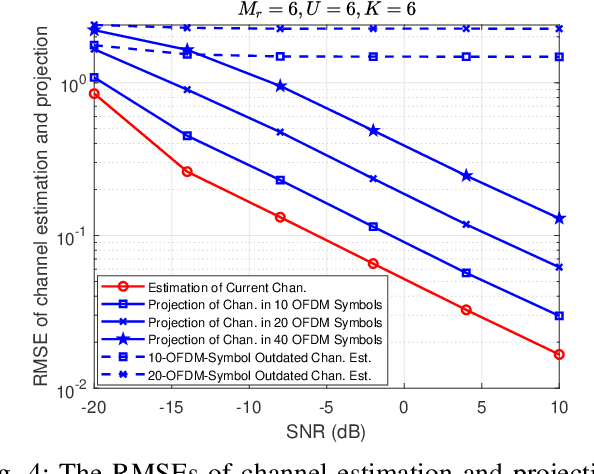
The reconfigurable intelligent surface (RIS) technology is a promising enabler for millimeter wave (mmWave) wireless communications, as it can potentially provide spectral efficiency comparable to the conventional massive multiple-input multiple-output (MIMO) but with significantly lower hardware complexity. In this paper, we focus on the estimation and projection of the uplink RIS-aided massive MIMO channel, which can be time-varying. We propose to let the user equipments (UE) transmit Zadoff-Chu (ZC) sequences and let the base station (BS) conduct maximum likelihood (ML) estimation of the uplink channel. The proposed scheme is computationally efficient: it uses ZC sequences to decouple the estimation of the frequency and time offsets; it uses the space-alternating generalized expectation-maximization (SAGE) method to reduce the high-dimensional problem due to the multipaths to multiple lower-dimensional ones per path. Owing to the estimation of the Doppler frequency offsets, the time-varying channel state can be projected, which can significantly lower the overhead of the pilots for channel estimation. The numerical simulations verify the effectiveness of the proposed scheme.