 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Norm-Agnostic Linear Bandits
May 03, 2022

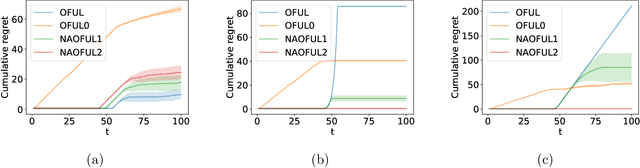

Linear bandits have a wide variety of applications including recommendation systems yet they make one strong assumption: the algorithms must know an upper bound $S$ on the norm of the unknown parameter $\theta^*$ that governs the reward generation. Such an assumption forces the practitioner to guess $S$ involved in the confidence bound, leaving no choice but to wish that $\|\theta^*\|\le S$ is true to guarantee that the regret will be low. In this paper, we propose novel algorithms that do not require such knowledge for the first time. Specifically, we propose two algorithms and analyze their regret bounds: one for the changing arm set setting and the other for the fixed arm set setting. Our regret bound for the former shows that the price of not knowing $S$ does not affect the leading term in the regret bound and inflates only the lower order term. For the latter, we do not pay any price in the regret for now knowing $S$. Our numerical experiments show standard algorithms assuming knowledge of $S$ can fail catastrophically when $\|\theta^*\|\le S$ is not true whereas our algorithms enjoy low regret.
An Extensive Data Processing Pipeline for MIMIC-IV
Apr 29, 2022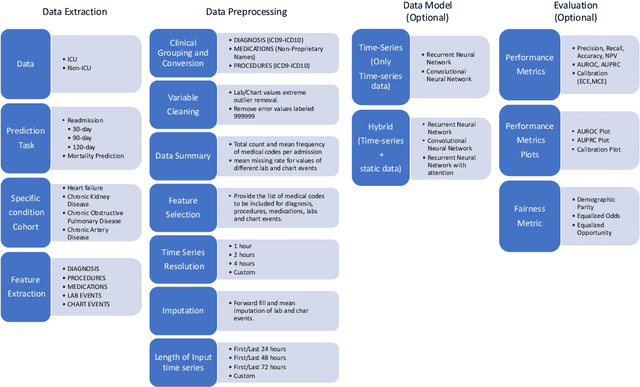

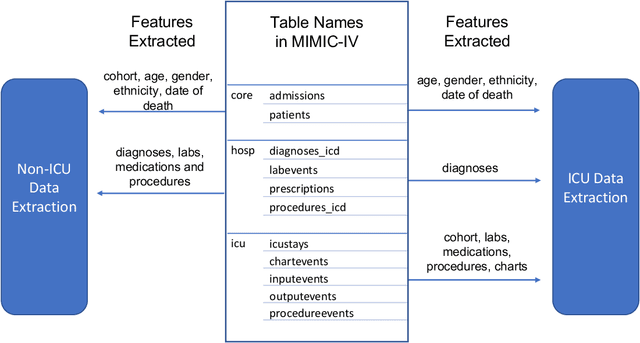
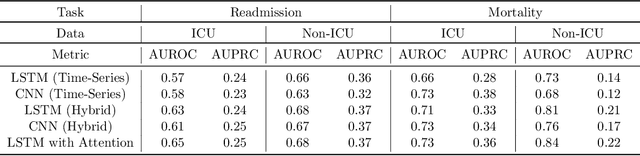
An increasing amount of research is being devoted to applying machine learning methods to electronic health record (EHR) data for various clinical tasks. This growing area of research has exposed the limitation of accessibility of EHR datasets for all, as well as the reproducibility of different modeling frameworks. One reason for these limitations is the lack of standardized pre-processing pipelines. MIMIC is a freely available EHR dataset in a raw format that has been used in numerous studies. The absence of standardized pre-processing steps serves as a major barrier to the wider adoption of the dataset. It also leads to different cohorts being used in downstream tasks, limiting the ability to compare the results among similar studies. Contrasting studies also use various distinct performance metrics, which can greatly reduce the ability to compare model results. In this work, we provide an end-to-end fully customizable pipeline to extract, clean, and pre-process data; and to predict and evaluate the fourth version of the MIMIC dataset (MIMIC-IV) for ICU and non-ICU-related clinical time-series prediction tasks.
Efficient Training of Neural Transducer for Speech Recognition
Apr 22, 2022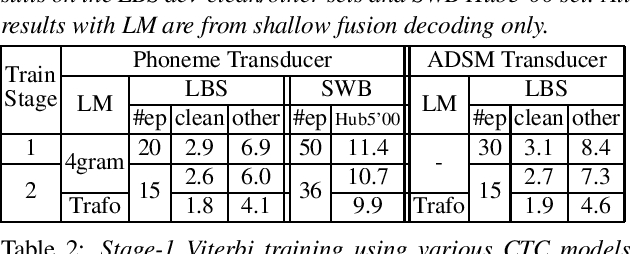
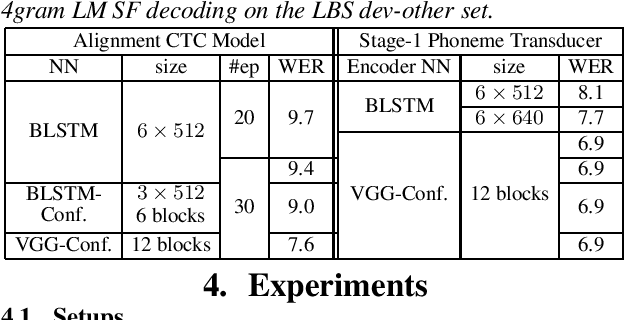
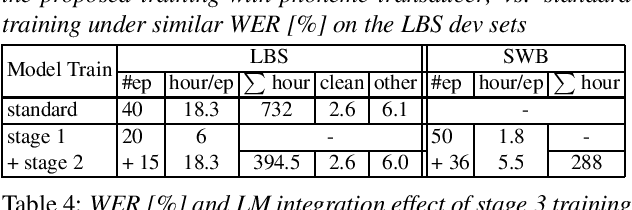
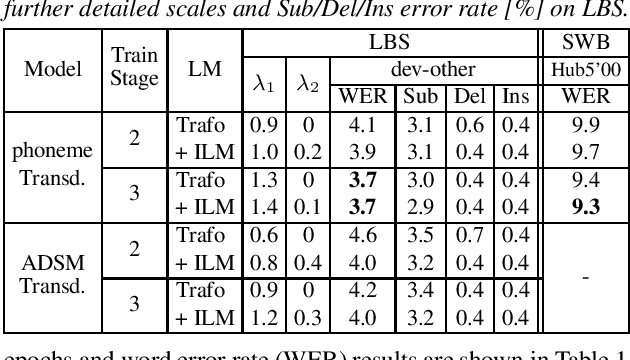
As one of the most popular sequence-to-sequence modeling approaches for speech recognition, the RNN-Transducer has achieved evolving performance with more and more sophisticated neural network models of growing size and increasing training epochs. While strong computation resources seem to be the prerequisite of training superior models, we try to overcome it by carefully designing a more efficient training pipeline. In this work, we propose an efficient 3-stage progressive training pipeline to build highly-performing neural transducer models from scratch with very limited computation resources in a reasonable short time period. The effectiveness of each stage is experimentally verified on both Librispeech and Switchboard corpora. The proposed pipeline is able to train transducer models approaching state-of-the-art performance with a single GPU in just 2-3 weeks. Our best conformer transducer achieves 4.1% WER on Librispeech test-other with only 35 epochs of training.
Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach
May 10, 2022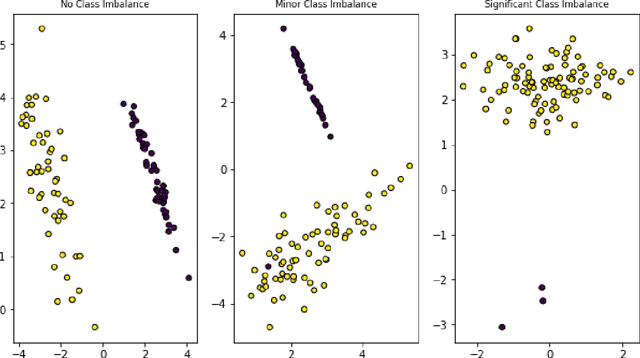
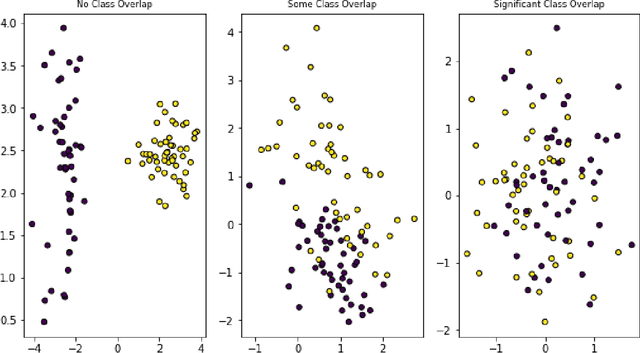
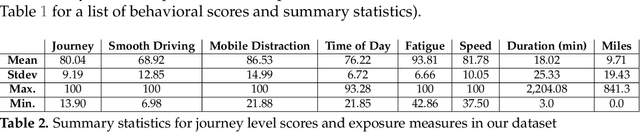
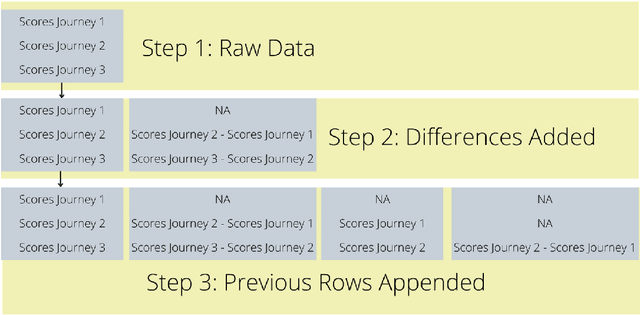
In recent years it has become possible to collect GPS data from drivers and to incorporate this data into automobile insurance pricing for the driver. This data is continuously collected and processed nightly into metadata consisting of mileage and time summaries of each discrete trip taken, and a set of behavioral scores describing attributes of the trip (e.g, driver fatigue or driver distraction) so we examine whether it can be used to identify periods of increased risk by successfully classifying trips that occur immediately before a trip in which there was an incident leading to a claim for that driver. Identification of periods of increased risk for a driver is valuable because it creates an opportunity for intervention and, potentially, avoidance of a claim. We examine metadata for each trip a driver takes and train a classifier to predict whether \textit{the following trip} is one in which a claim occurs for that driver. By achieving a area under the receiver-operator characteristic above 0.6, we show that it is possible to predict claims in advance. Additionally, we compare the predictive power, as measured by the area under the receiver-operator characteristic of XGBoost classifiers trained to predict whether a driver will have a claim using exposure features such as driven miles, and those trained using behavioral features such as a computed speed score.
Dynamic super-resolution in particle tracking problems
Apr 08, 2022Particle tracking in biological imaging is concerned with reconstructing the trajectories, locations, or velocities of the targeting particles. The standard approach of particle tracking consists of two steps: first reconstructing statically the source locations in each time step, and second applying tracking techniques to obtain the trajectories and velocities. In contrast, the dynamic reconstruction seeks to simultaneously recover the source locations and velocities from all frames, which enjoys certain advantages. In this paper, we provide a rigorous mathematical analysis for the resolution limit of reconstructing source number, locations, and velocities by general dynamical reconstruction in particle tracking problems, by which we demonstrate the possibility of achieving super-resolution for the dynamic reconstruction. We show that when the location-velocity pairs of the particles are separated beyond certain distances (the resolution limits), the number of particles and the location-velocity pair can be stably recovered. The resolution limits are related to the cut-off frequency of the imaging system, signal-to-noise ratio, and the sparsity of the source. By these estimates, we also derive a stability result for a sparsity-promoting dynamic reconstruction. In addition, we further show that the reconstruction of velocities has a better resolution limit which improves constantly as the particles moving. This result is derived by an observation that the inherent cut-off frequency for the velocity recovery can be viewed as the total observation time multiplies the cut-off frequency of the imaging system, which may lead to a better resolution limit as compared to the one for each diffraction-limited frame. It is anticipated that this observation can inspire new reconstruction algorithms that improve the resolution of particle tracking in practice.
Towards Real-Time Monocular Depth Estimation for Robotics: A Survey
Nov 16, 2021
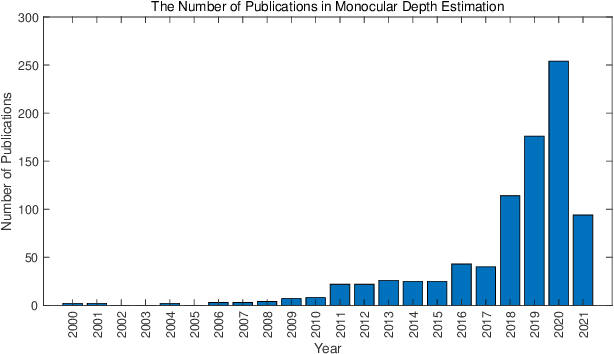
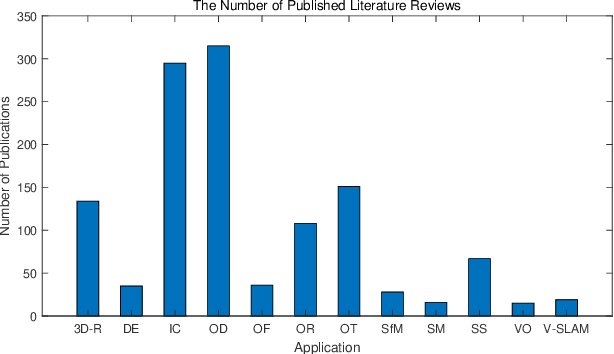
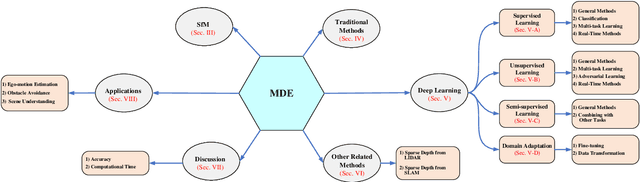
As an essential component for many autonomous driving and robotic activities such as ego-motion estimation, obstacle avoidance and scene understanding, monocular depth estimation (MDE) has attracted great attention from the computer vision and robotics communities. Over the past decades, a large number of methods have been developed. To the best of our knowledge, however, there is not a comprehensive survey of MDE. This paper aims to bridge this gap by reviewing 197 relevant articles published between 1970 and 2021. In particular, we provide a comprehensive survey of MDE covering various methods, introduce the popular performance evaluation metrics and summarize publically available datasets. We also summarize available open-source implementations of some representative methods and compare their performances. Furthermore, we review the application of MDE in some important robotic tasks. Finally, we conclude this paper by presenting some promising directions for future research. This survey is expected to assist readers to navigate this research field.
LeRaC: Learning Rate Curriculum
May 18, 2022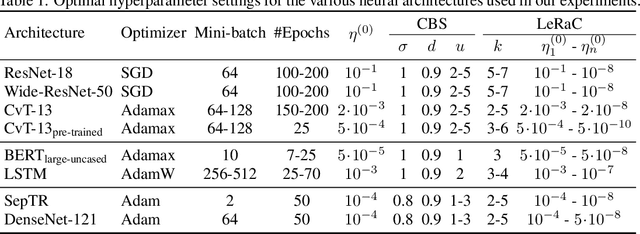
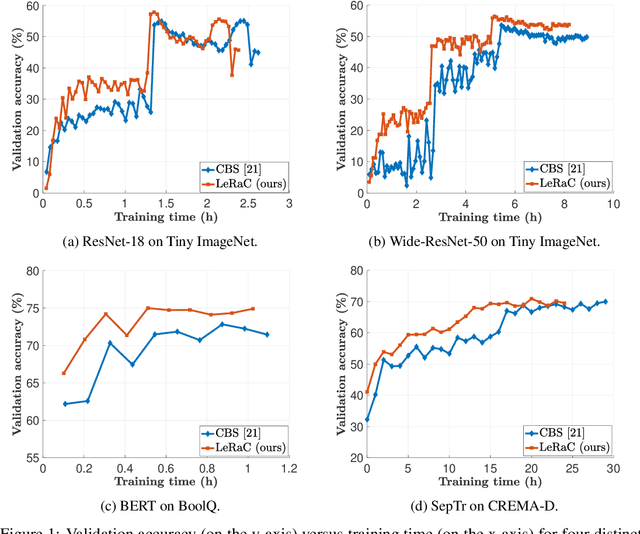
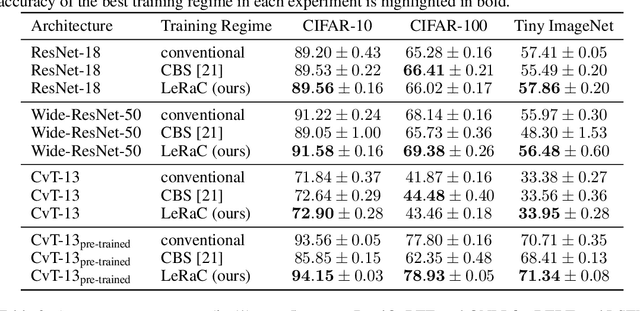
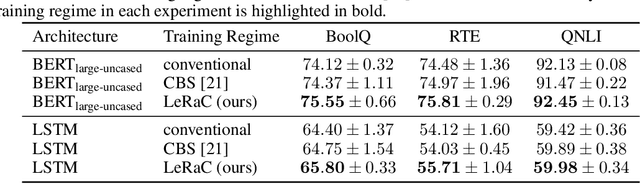
Most curriculum learning methods require an approach to sort the data samples by difficulty, which is often cumbersome to perform. In this work, we propose a novel curriculum learning approach termed Learning Rate Curriculum (LeRaC), which leverages the use of a different learning rate for each layer of a neural network to create a data-free curriculum during the initial training epochs. More specifically, LeRaC assigns higher learning rates to neural layers closer to the input, gradually decreasing the learning rates as the layers are placed farther away from the input. The learning rates increase at various paces during the first training iterations, until they all reach the same value. From this point on, the neural model is trained as usual. This creates a model-level curriculum learning strategy that does not require sorting the examples by difficulty and is compatible with any neural network, generating higher performance levels regardless of the architecture. We conduct comprehensive experiments on eight datasets from the computer vision (CIFAR-10, CIFAR-100, Tiny ImageNet), language (BoolQ, QNLI, RTE) and audio (ESC-50, CREMA-D) domains, considering various convolutional (ResNet-18, Wide-ResNet-50, DenseNet-121), recurrent (LSTM) and transformer (CvT, BERT, SepTr) architectures, comparing our approach with the conventional training regime. Moreover, we also compare with Curriculum by Smoothing (CBS), a state-of-the-art data-free curriculum learning approach. Unlike CBS, our performance improvements over the standard training regime are consistent across all datasets and models. Furthermore, we significantly surpass CBS in terms of training time (there is no additional cost over the standard training regime for LeRaC).
Improving RNN-T ASR Performance with Date-Time and Location Awareness
Jun 11, 2021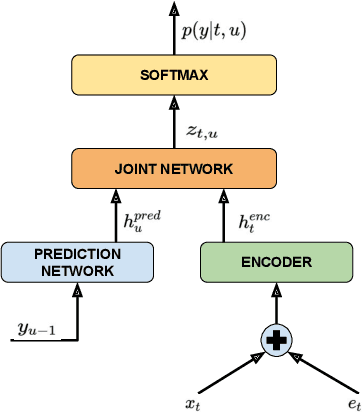
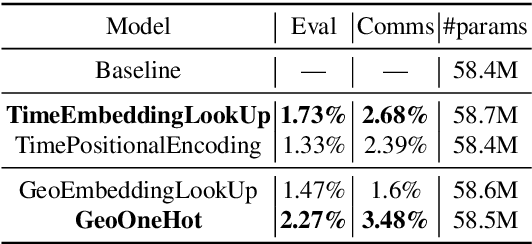
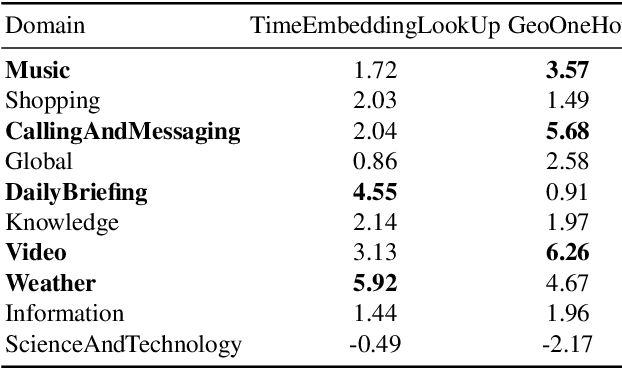

In this paper, we explore the benefits of incorporating context into a Recurrent Neural Network (RNN-T) based Automatic Speech Recognition (ASR) model to improve the speech recognition for virtual assistants. Specifically, we use meta information extracted from the time at which the utterance is spoken and the approximate location information to make ASR context aware. We show that these contextual information, when used individually, improves overall performance by as much as 3.48% relative to the baseline and when the contexts are combined, the model learns complementary features and the recognition improves by 4.62%. On specific domains, these contextual signals show improvements as high as 11.5%, without any significant degradation on others. We ran experiments with models trained on data of sizes 30K hours and 10K hours. We show that the scale of improvement with the 10K hours dataset is much higher than the one obtained with 30K hours dataset. Our results indicate that with limited data to train the ASR model, contextual signals can improve the performance significantly.
A Deep Adversarial Model for Suffix and Remaining Time Prediction of Event Sequences
Feb 15, 2021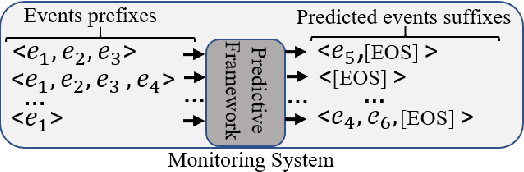



Event suffix and remaining time prediction are sequence to sequence learning tasks. They have wide applications in different areas such as economics, digital health, business process management and IT infrastructure monitoring. Timestamped event sequences contain ordered events which carry at least two attributes: the event's label and its timestamp. Suffix and remaining time prediction are about obtaining the most likely continuation of event labels and the remaining time until the sequence finishes, respectively. Recent deep learning-based works for such predictions are prone to potentially large prediction errors because of closed-loop training (i.e., the next event is conditioned on the ground truth of previous events) and open-loop inference (i.e., the next event is conditioned on previously predicted events). In this work, we propose an encoder-decoder architecture for open-loop training to advance the suffix and remaining time prediction of event sequences. To capture the joint temporal dynamics of events, we harness the power of adversarial learning techniques to boost prediction performance. We consider four real-life datasets and three baselines in our experiments. The results show improvements up to four times compared to the state of the art in suffix and remaining time prediction of event sequences, specifically in the realm of business process executions. We also show that the obtained improvements of adversarial training are superior compared to standard training under the same experimental setup.
SepTr: Separable Transformer for Audio Spectrogram Processing
Mar 17, 2022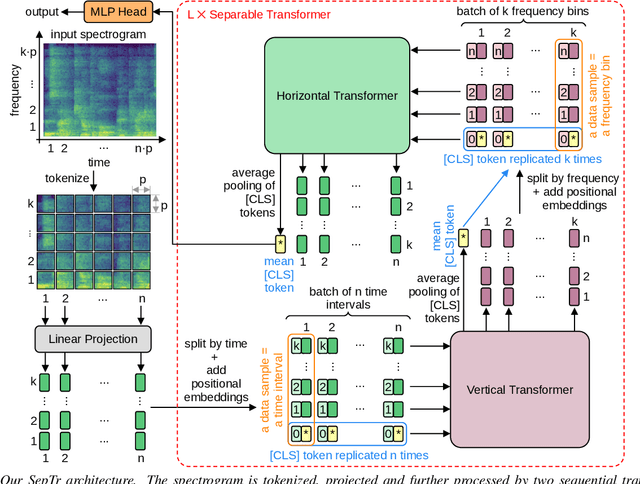
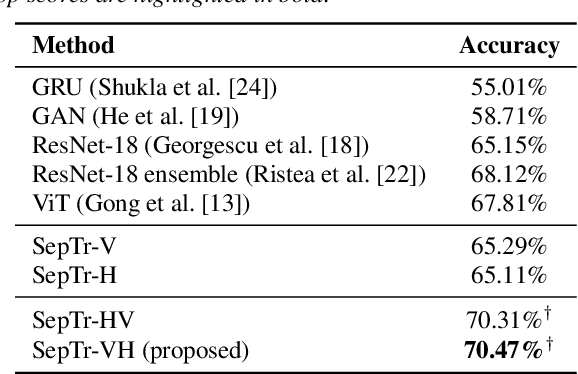
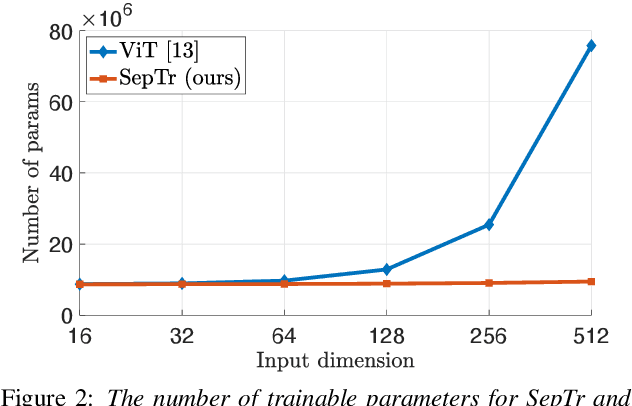
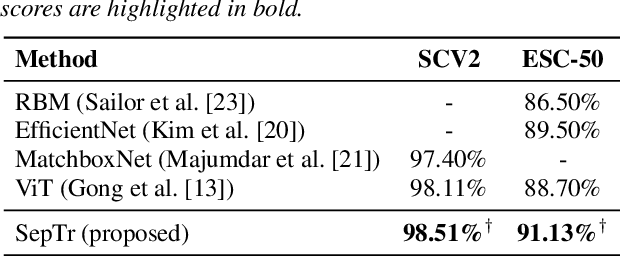
Following the successful application of vision transformers in multiple computer vision tasks, these models have drawn the attention of the signal processing community. This is because signals are often represented as spectrograms (e.g. through Discrete Fourier Transform) which can be directly provided as input to vision transformers. However, naively applying transformers to spectrograms is suboptimal. Since the axes represent distinct dimensions, i.e. frequency and time, we argue that a better approach is to separate the attention dedicated to each axis. To this end, we propose the Separable Transformer (SepTr), an architecture that employs two transformer blocks in a sequential manner, the first attending to tokens within the same frequency bin, and the second attending to tokens within the same time interval. We conduct experiments on three benchmark data sets, showing that our separable architecture outperforms conventional vision transformers and other state-of-the-art methods. Unlike standard transformers, SepTr linearly scales the number of trainable parameters with the input size, thus having a lower memory footprint. Our code is available as open source at https://github.com/ristea/septr.