 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Bayesian Bandits Approach for Anticancer Therapy: Exploration via Functional Prior
May 05, 2022
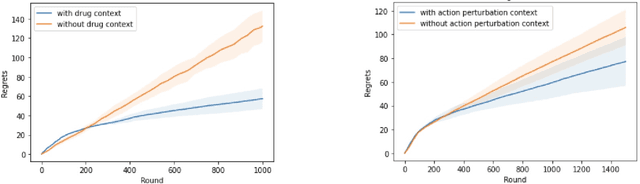
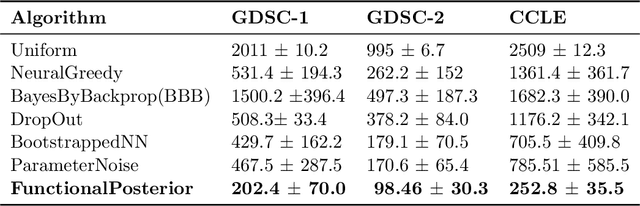
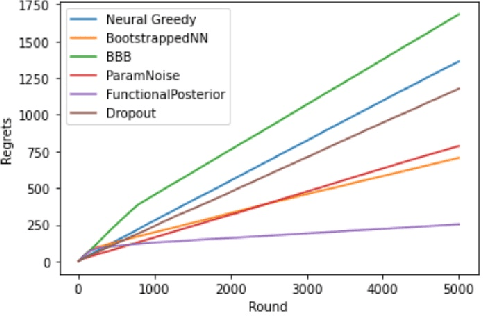
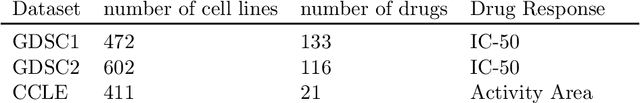
Learning personalized cancer treatment with machine learning holds great promise to improve cancer patients' chance of survival. Despite recent advances in machine learning and precision oncology, this approach remains challenging as collecting data in preclinical/clinical studies for modeling multiple treatment efficacies is often an expensive, time-consuming process. Moreover, the randomization in treatment allocation proves to be suboptimal since some participants/samples are not receiving the most appropriate treatments during the trial. To address this challenge, we formulate drug screening study as a "contextual bandit" problem, in which an algorithm selects anticancer therapeutics based on contextual information about cancer cell lines while adapting its treatment strategy to maximize treatment response in an "online" fashion. We propose using a novel deep Bayesian bandits framework that uses functional prior to approximate posterior for drug response prediction based on multi-modal information consisting of genomic features and drug structure. We empirically evaluate our method on three large-scale in vitro pharmacogenomic datasets and show that our approach outperforms several benchmarks in identifying optimal treatment for a given cell line.
Nearest Neighbor Knowledge Distillation for Neural Machine Translation
May 01, 2022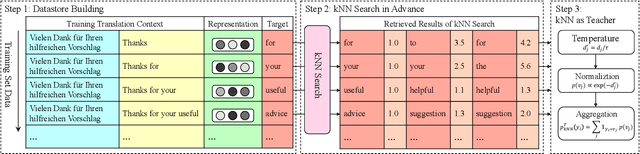
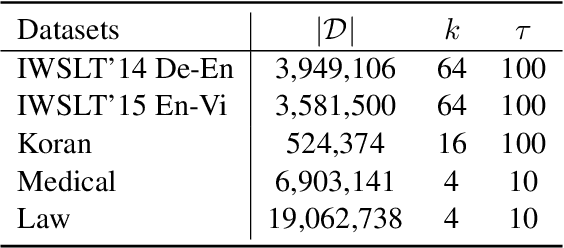
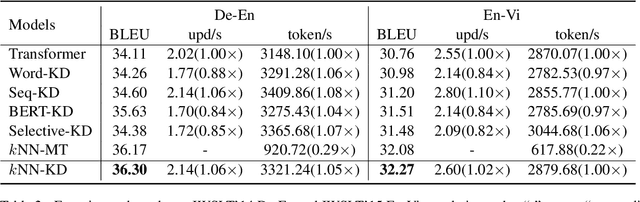
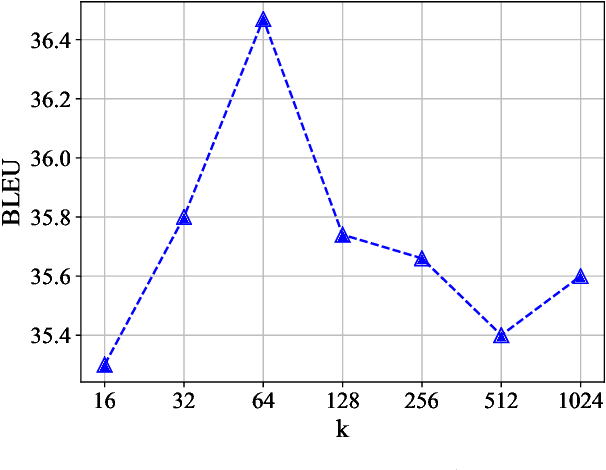
k-nearest-neighbor machine translation (NN-MT), proposed by Khandelwal et al. (2021), has achieved many state-of-the-art results in machine translation tasks. Although effective, NN-MT requires conducting NN searches through the large datastore for each decoding step during inference, prohibitively increasing the decoding cost and thus leading to the difficulty for the deployment in real-world applications. In this paper, we propose to move the time-consuming NN search forward to the preprocessing phase, and then introduce Nearest Neighbor Knowledge Distillation (NN-KD) that trains the base NMT model to directly learn the knowledge of NN. Distilling knowledge retrieved by NN can encourage the NMT model to take more reasonable target tokens into consideration, thus addressing the overcorrection problem. Extensive experimental results show that, the proposed method achieves consistent improvement over the state-of-the-art baselines including NN-MT, while maintaining the same training and decoding speed as the standard NMT model.
Application of multilayer perceptron with data augmentation in nuclear physics
May 16, 2022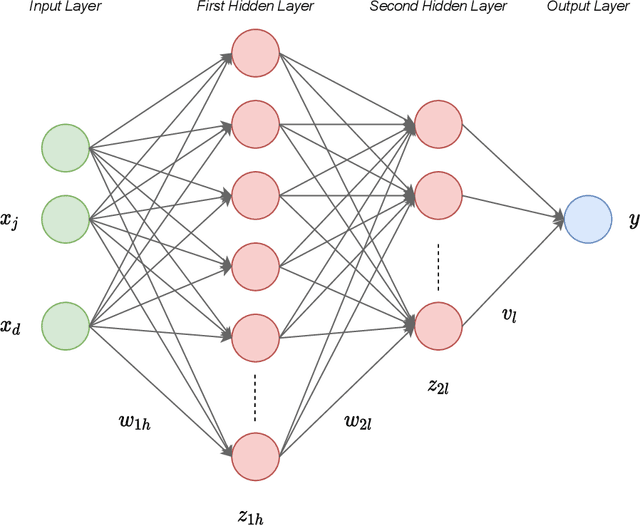
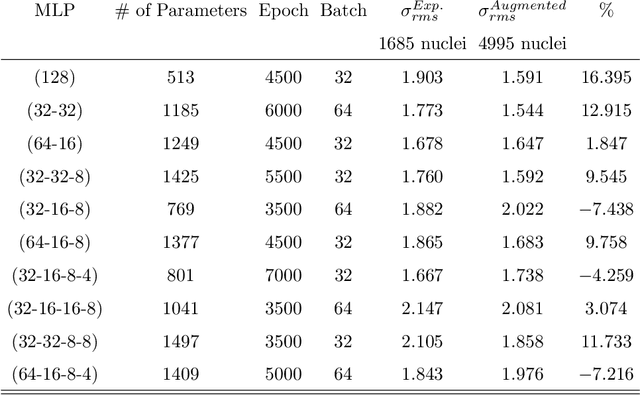
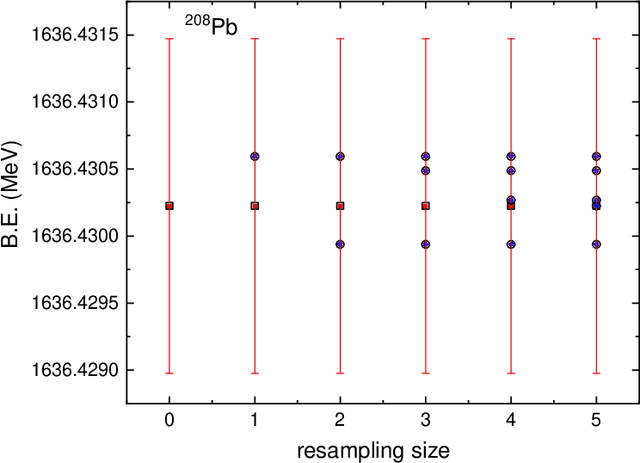
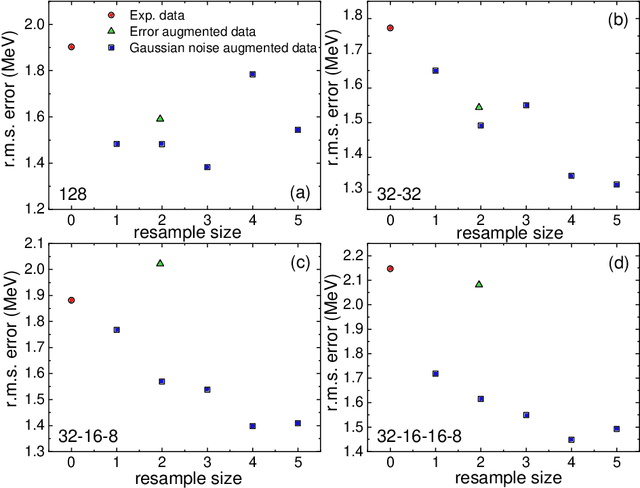
Neural networks have become popular in many fields of science since they serve as reliable and powerful tools. Application of the neural networks to the nuclear physics studies has also become popular in recent years because of their success in the prediction of nuclear properties. In this work, we study the effect of the data augmentation on the predictive power of the neural network models. Even though there are various data augmentation techniques used for classification tasks in the literature, this area is still very limited for regression problems. As predicting the binding energies is statistically defined as a regression problem, in addition to using data augmentation for nuclear physics, this study contributes to this field for regression in general. Using the experimental uncertainties for data augmentation, the size of training data set is artificially boosted and the changes in the root-mean-square error between the model predictions on test set and the experimental data are investigated. As far as we know, this is the first time that data augmentation techniques have been implemented for nuclear physics research. Our results show that the data augmentation decreases the prediction errors, stabilizes the model and prevents overfitting. The extrapolation capabilities of the MLP models with different depths are also tested for newly measured nuclei in AME2020 mass table.
Diffuse Map Guiding Unsupervised Generative Adversarial Network for SVBRDF Estimation
May 25, 2022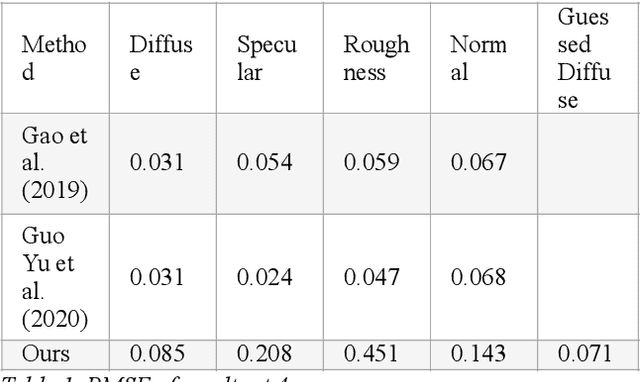
Reconstructing materials in the real world has always been a difficult problem in computer graphics. Accurately reconstructing the material in the real world is critical in the field of realistic rendering. Traditionally, materials in computer graphics are mapped by an artist, then mapped onto a geometric model by coordinate transformation, and finally rendered with a rendering engine to get realistic materials. For opaque objects, the industry commonly uses physical-based bidirectional reflectance distribution function (BRDF) rendering models for material modeling. The commonly used physical-based rendering models are Cook-Torrance BRDF, Disney BRDF. In this paper, we use the Cook-Torrance model to reconstruct the materials. The SVBRDF material parameters include Normal, Diffuse, Specular and Roughness. This paper presents a Diffuse map guiding material estimation method based on the Generative Adversarial Network(GAN). This method can predict plausible SVBRDF maps with global features using only a few pictures taken by the mobile phone. The main contributions of this paper are: 1) We preprocess a small number of input pictures to produce a large number of non-repeating pictures for training to reduce over-fitting. 2) We use a novel method to directly obtain the guessed diffuse map with global characteristics, which provides more prior information for the training process. 3) We improve the network architecture of the generator so that it can generate fine details of normal maps and reduce the possibility to generate over-flat normal maps. The method used in this paper can obtain prior knowledge without using dataset training, which greatly reduces the difficulty of material reconstruction and saves a lot of time to generate and calibrate datasets.
Decentralized Stochastic Proximal Gradient Descent with Variance Reduction over Time-varying Networks
Dec 20, 2021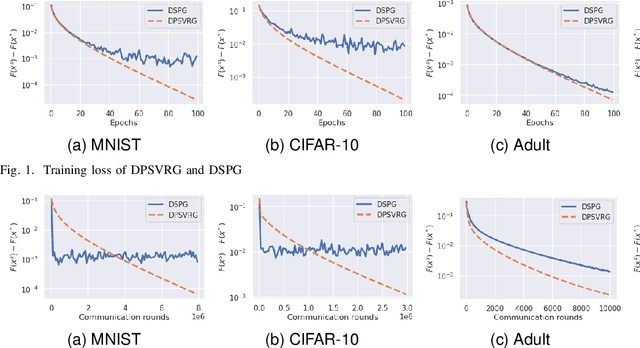
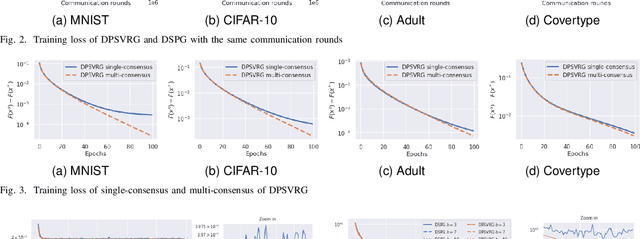
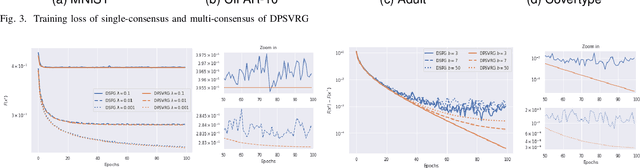
In decentralized learning, a network of nodes cooperate to minimize an overall objective function that is usually the finite-sum of their local objectives, and incorporates a non-smooth regularization term for the better generalization ability. Decentralized stochastic proximal gradient (DSPG) method is commonly used to train this type of learning models, while the convergence rate is retarded by the variance of stochastic gradients. In this paper, we propose a novel algorithm, namely DPSVRG, to accelerate the decentralized training by leveraging the variance reduction technique. The basic idea is to introduce an estimator in each node, which tracks the local full gradient periodically, to correct the stochastic gradient at each iteration. By transforming our decentralized algorithm into a centralized inexact proximal gradient algorithm with variance reduction, and controlling the bounds of error sequences, we prove that DPSVRG converges at the rate of $O(1/T)$ for general convex objectives plus a non-smooth term with $T$ as the number of iterations, while DSPG converges at the rate $O(\frac{1}{\sqrt{T}})$. Our experiments on different applications, network topologies and learning models demonstrate that DPSVRG converges much faster than DSPG, and the loss function of DPSVRG decreases smoothly along with the training epochs.
Weakly-supervised Temporal Path Representation Learning with Contrastive Curriculum Learning -- Extended Version
Apr 15, 2022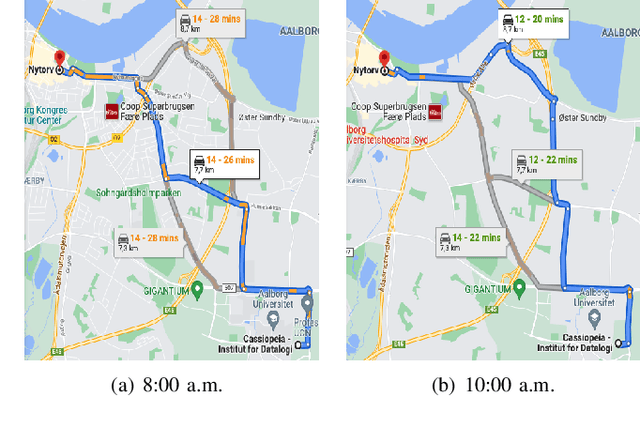
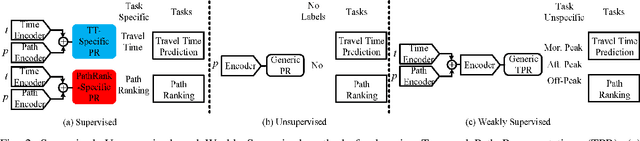
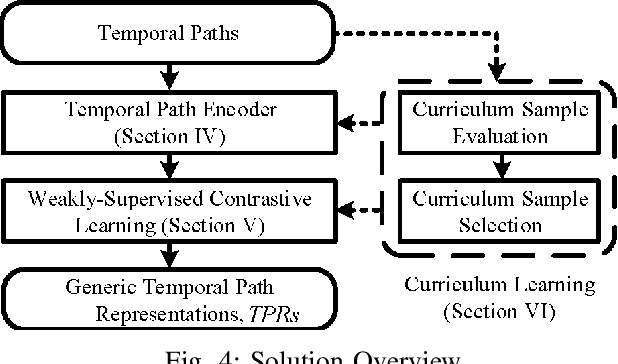
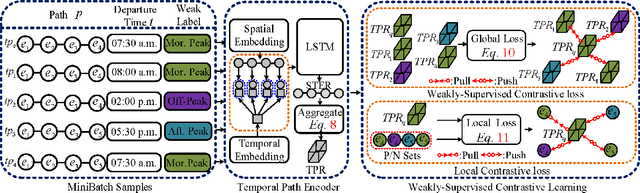
In step with the digitalization of transportation, we are witnessing a growing range of path-based smart-city applications, e.g., travel-time estimation and travel path ranking. A temporal path(TP) that includes temporal information, e.g., departure time, into the path is fundamental to enable such applications. In this setting, it is essential to learn generic temporal path representations(TPRs) that consider spatial and temporal correlations simultaneously and that can be used in different applications, i.e., downstream tasks. Existing methods fail to achieve the goal since (i) supervised methods require large amounts of task-specific labels when training and thus fail to generalize the obtained TPRs to other tasks; (ii) through unsupervised methods can learn generic representations, they disregard the temporal aspect, leading to sub-optimal results. To contend with the limitations of existing solutions, we propose a Weakly-Supervised Contrastive (WSC) learning model. We first propose a temporal path encoder that encodes both the spatial and temporal information of a temporal path into a TPR. To train the encoder, we introduce weak labels that are easy and inexpensive to obtain and are relevant to different tasks, e.g., temporal labels indicating peak vs. off-peak hours from departure times. Based on the weak labels, we construct meaningful positive and negative temporal path samples by considering both spatial and temporal information, which facilities training the encoder using contrastive learning by pulling closer to the positive samples' representations while pushing away the negative samples' representations. To better guide contrastive learning, we propose a learning strategy based on Curriculum Learning such that the learning performs from easy to hard training instances. Experiments studies verify the effectiveness of the proposed method.
Image2Gif: Generating Continuous Realistic Animations with Warping NODEs
May 09, 2022
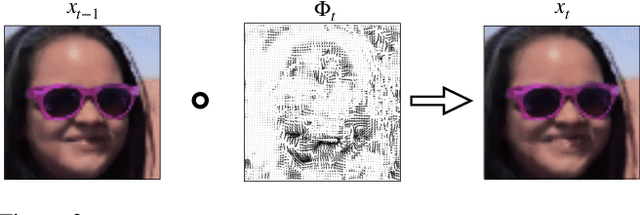
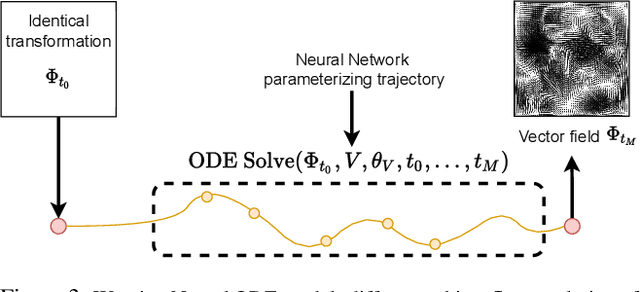
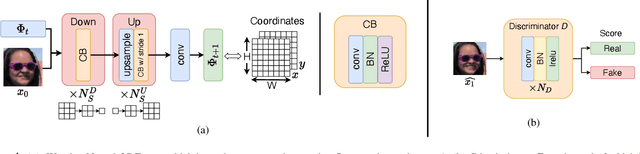
Generating smooth animations from a limited number of sequential observations has a number of applications in vision. For example, it can be used to increase number of frames per second, or generating a new trajectory only based on first and last frames, e.g. a motion of face emotions. Despite the discrete observed data (frames), the problem of generating a new trajectory is a continues problem. In addition, to be perceptually realistic, the domain of an image should not alter drastically through the trajectory of changes. In this paper, we propose a new framework, Warping Neural ODE, for generating a smooth animation (video frame interpolation) in a continuous manner, given two ("farther apart") frames, denoting the start and the end of the animation. The key feature of our framework is utilizing the continuous spatial transformation of the image based on the vector field, derived from a system of differential equations. This allows us to achieve the smoothness and the realism of an animation with infinitely small time steps between the frames. We show the application of our work in generating an animation given two frames, in different training settings, including Generative Adversarial Network (GAN) and with $L_2$ loss.
Online multi-resolution fusion of space-borne multispectral images
Apr 26, 2022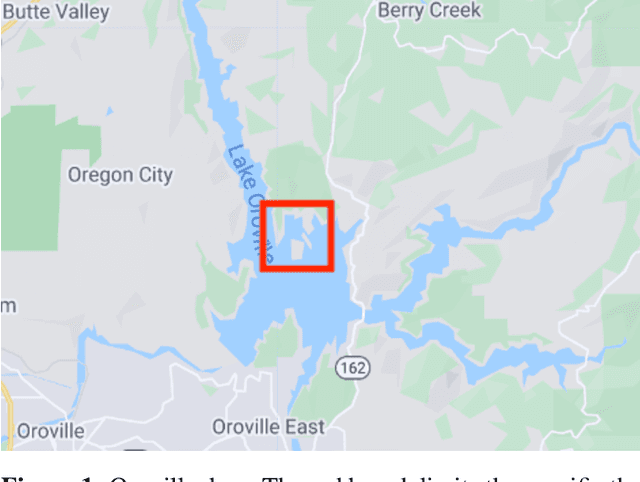
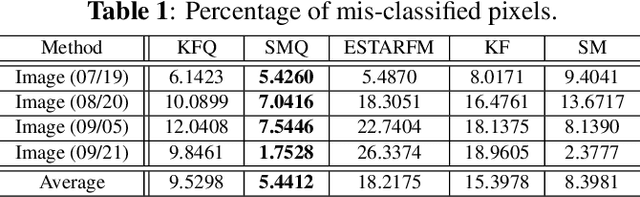
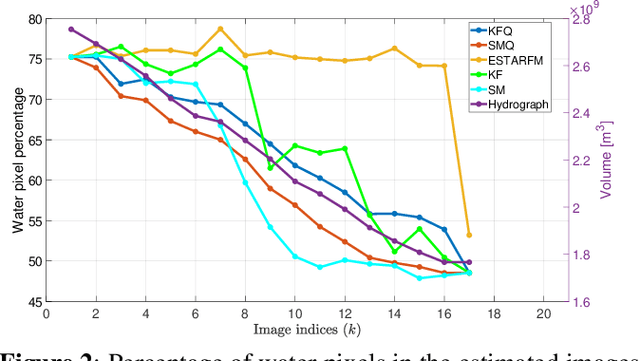
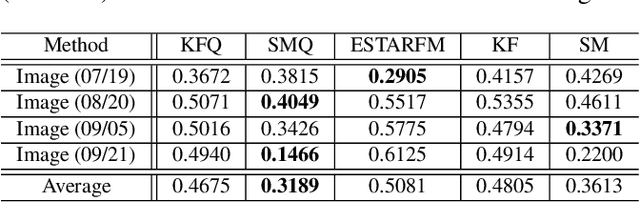
Satellite imaging has a central role in monitoring, detecting and estimating the intensity of key natural phenomena. One important feature of satellite images is the trade-off between spatial/spectral resolution and their revisiting time, a consequence of design and physical constraints imposed by satellite orbit among other technical limitations. In this paper, we focus on fusing multi-temporal, multi-spectral images where data acquired from different instruments with different spatial resolutions is used. We leverage the spatial relationship between images at multiple modalities to generate high-resolution image sequences at higher revisiting rates. To achieve this goal, we formulate the fusion method as a recursive state estimation problem and study its performance in filtering and smoothing contexts. The proposed strategy clearly outperforms competing methodologies, which is shown in the paper for real data acquired by the Landsat and MODIS instruments.
INSTA-YOLO: Real-Time Instance Segmentation
Feb 12, 2021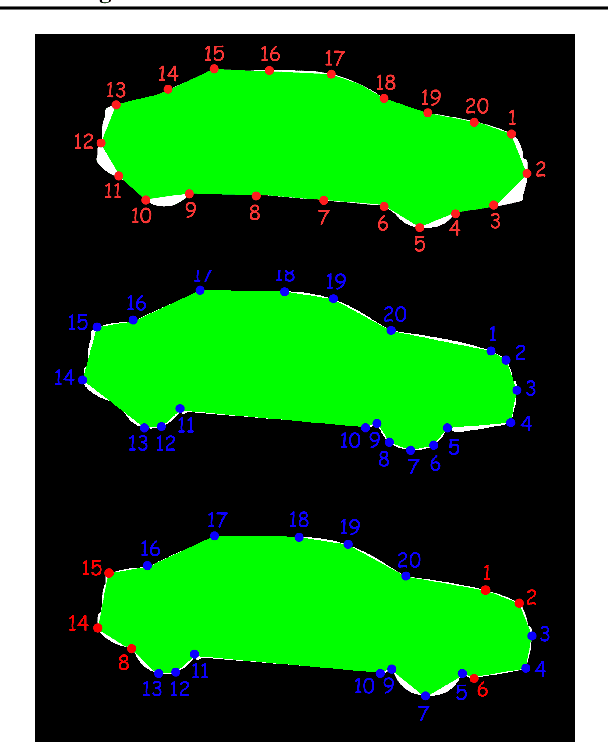
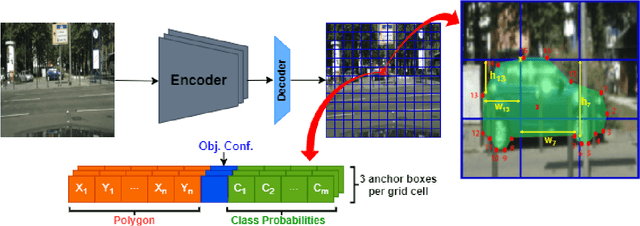
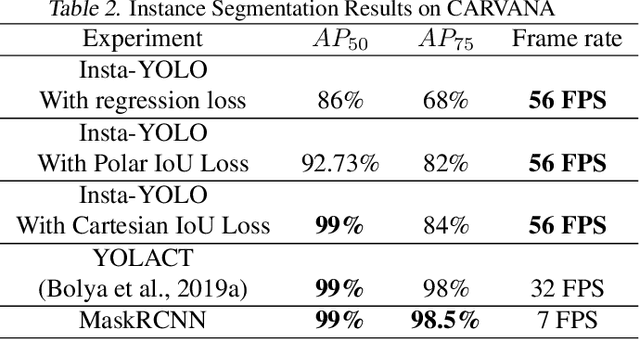

Instance segmentation has gained recently huge attention in various computer vision applications. It aims at providing different IDs to different objects of the scene, even if they belong to the same class. Instance segmentation is usually performed as a two-stage pipeline. First, an object is detected, then semantic segmentation within the detected box area is performed which involves costly up-sampling. In this paper, we propose Insta-YOLO, a novel one-stage end-to-end deep learning model for real-time instance segmentation. Instead of pixel-wise prediction, our model predicts instances as object contours represented by 2D points in Cartesian space. We evaluate our model on three datasets, namely, Carvana,Cityscapes and Airbus. We compare our results to the state-of-the-art models for instance segmentation. The results show our model achieves competitive accuracy in terms of mAP at twice the speed on GTX-1080 GPU.
Modeling Dynamic User Preference via Dictionary Learning for Sequential Recommendation
Apr 02, 2022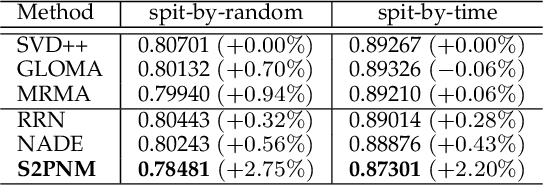
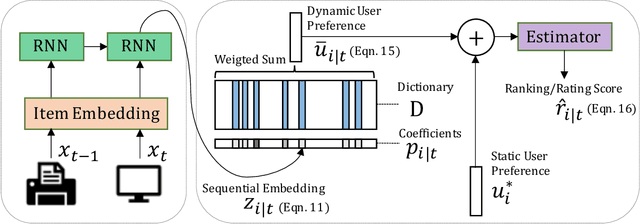

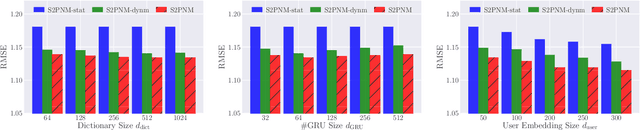
Capturing the dynamics in user preference is crucial to better predict user future behaviors because user preferences often drift over time. Many existing recommendation algorithms -- including both shallow and deep ones -- often model such dynamics independently, i.e., user static and dynamic preferences are not modeled under the same latent space, which makes it difficult to fuse them for recommendation. This paper considers the problem of embedding a user's sequential behavior into the latent space of user preferences, namely translating sequence to preference. To this end, we formulate the sequential recommendation task as a dictionary learning problem, which learns: 1) a shared dictionary matrix, each row of which represents a partial signal of user dynamic preferences shared across users; and 2) a posterior distribution estimator using a deep autoregressive model integrated with Gated Recurrent Unit (GRU), which can select related rows of the dictionary to represent a user's dynamic preferences conditioned on his/her past behaviors. Qualitative studies on the Netflix dataset demonstrate that the proposed method can capture the user preference drifts over time and quantitative studies on multiple real-world datasets demonstrate that the proposed method can achieve higher accuracy compared with state-of-the-art factorization and neural sequential recommendation methods. The code is available at https://github.com/cchao0116/S2PNM-TKDE2021.