 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DDoS-UNet: Incorporating temporal information using Dynamic Dual-channel UNet for enhancing super-resolution of dynamic MRI
Feb 10, 2022
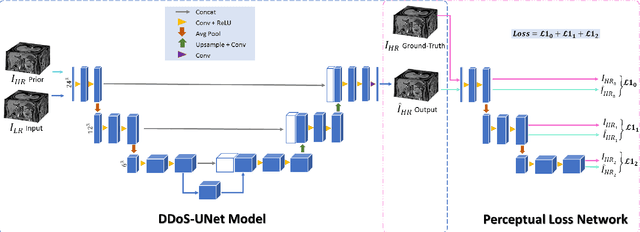
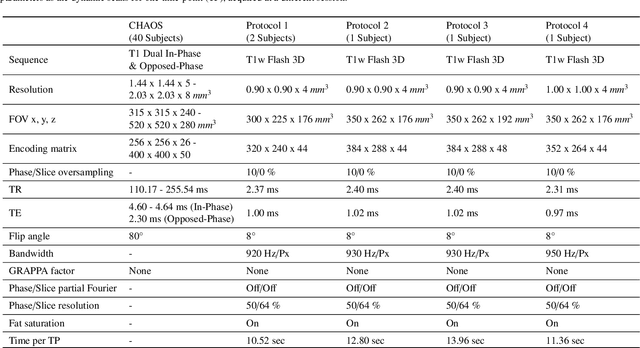

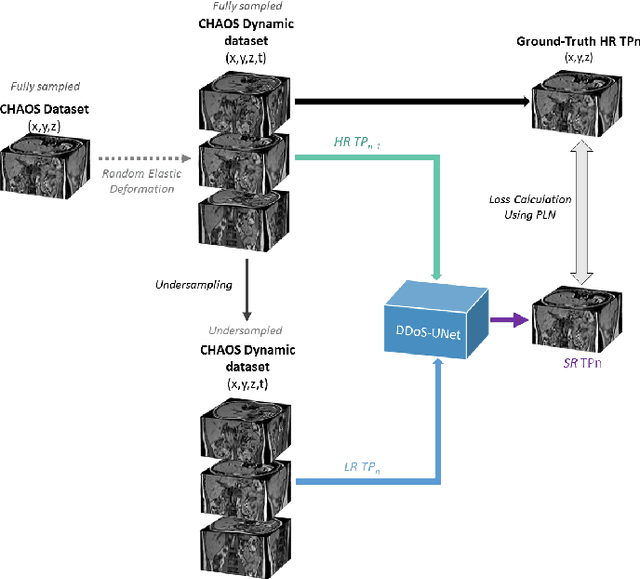
Magnetic resonance imaging (MRI) provides high spatial resolution and excellent soft-tissue contrast without using harmful ionising radiation. Dynamic MRI is an essential tool for interventions to visualise movements or changes of the target organ. However, such MRI acquisition with high temporal resolution suffers from limited spatial resolution - also known as the spatio-temporal trade-off of dynamic MRI. Several approaches, including deep learning based super-resolution approaches, have been proposed to mitigate this trade-off. Nevertheless, such an approach typically aims to super-resolve each time-point separately, treating them as individual volumes. This research addresses the problem by creating a deep learning model which attempts to learn both spatial and temporal relationships. A modified 3D UNet model, DDoS-UNet, is proposed - which takes the low-resolution volume of the current time-point along with a prior image volume. Initially, the network is supplied with a static high-resolution planning scan as the prior image along with the low-resolution input to super-resolve the first time-point. Then it continues step-wise by using the super-resolved time-points as the prior image while super-resolving the subsequent time-points. The model performance was tested with 3D dynamic data that was undersampled to different in-plane levels. The proposed network achieved an average SSIM value of 0.951$\pm$0.017 while reconstructing the lowest resolution data (i.e. only 4\% of the k-space acquired) - which could result in a theoretical acceleration factor of 25. The proposed approach can be used to reduce the required scan-time while achieving high spatial resolution.
RENs: Relevance Encoding Networks
May 25, 2022
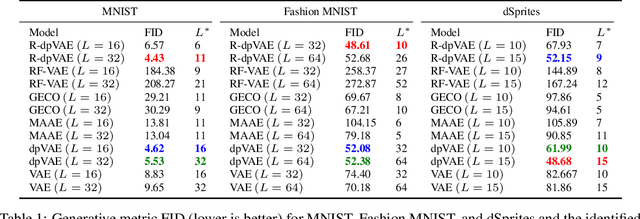

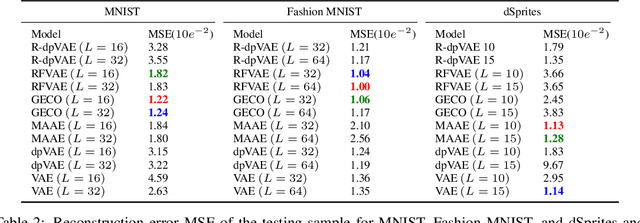
The manifold assumption for high-dimensional data assumes that the data is generated by varying a set of parameters obtained from a low-dimensional latent space. Deep generative models (DGMs) are widely used to learn data representations in an unsupervised way. DGMs parameterize the underlying low-dimensional manifold in the data space using bottleneck architectures such as variational autoencoders (VAEs). The bottleneck dimension for VAEs is treated as a hyperparameter that depends on the dataset and is fixed at design time after extensive tuning. As the intrinsic dimensionality of most real-world datasets is unknown, often, there is a mismatch between the intrinsic dimensionality and the latent dimensionality chosen as a hyperparameter. This mismatch can negatively contribute to the model performance for representation learning and sample generation tasks. This paper proposes relevance encoding networks (RENs): a novel probabilistic VAE-based framework that uses the automatic relevance determination (ARD) prior in the latent space to learn the data-specific bottleneck dimensionality. The relevance of each latent dimension is directly learned from the data along with the other model parameters using stochastic gradient descent and a reparameterization trick adapted to non-Gaussian priors. We leverage the concept of DeepSets to capture permutation invariant statistical properties in both data and latent spaces for relevance determination. The proposed framework is general and flexible and can be used for the state-of-the-art VAE models that leverage regularizers to impose specific characteristics in the latent space (e.g., disentanglement). With extensive experimentation on synthetic and public image datasets, we show that the proposed model learns the relevant latent bottleneck dimensionality without compromising the representation and generation quality of the samples.
DACSR: Dual-Aggregation End-to-End Calibrated Sequential Recommendation
Apr 29, 2022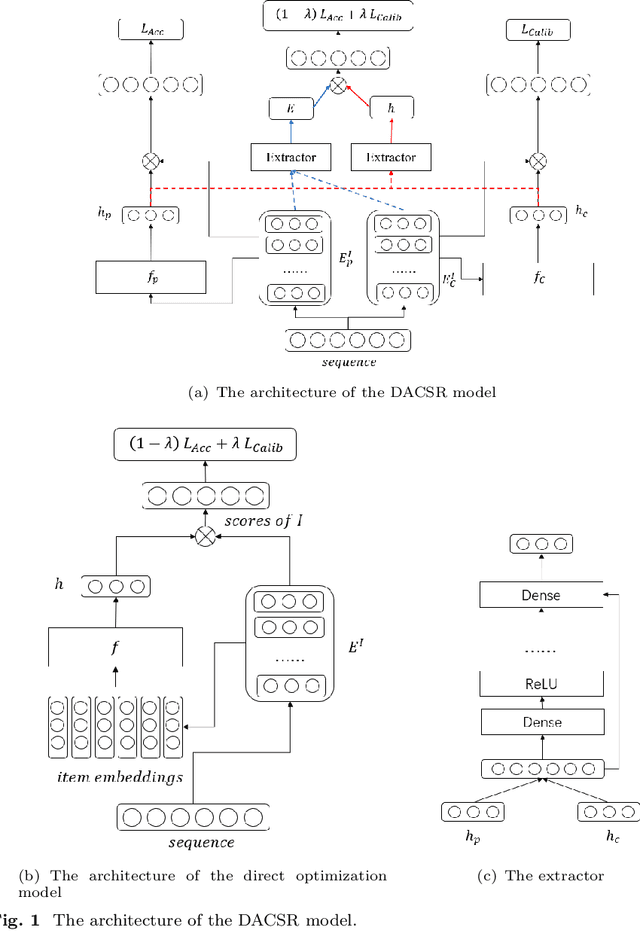
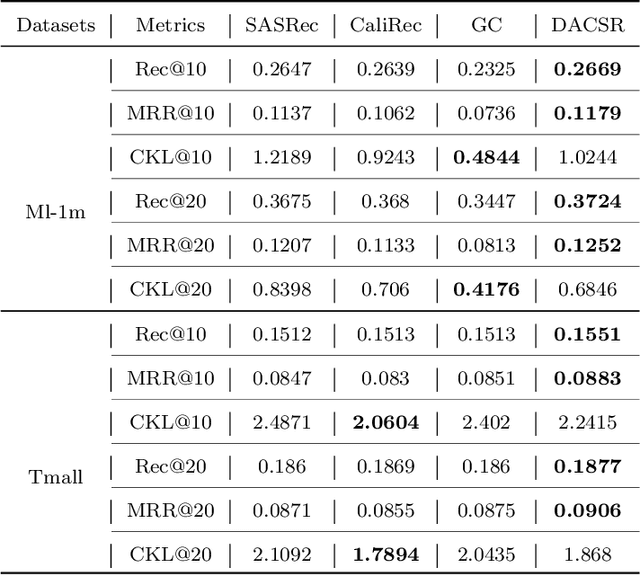
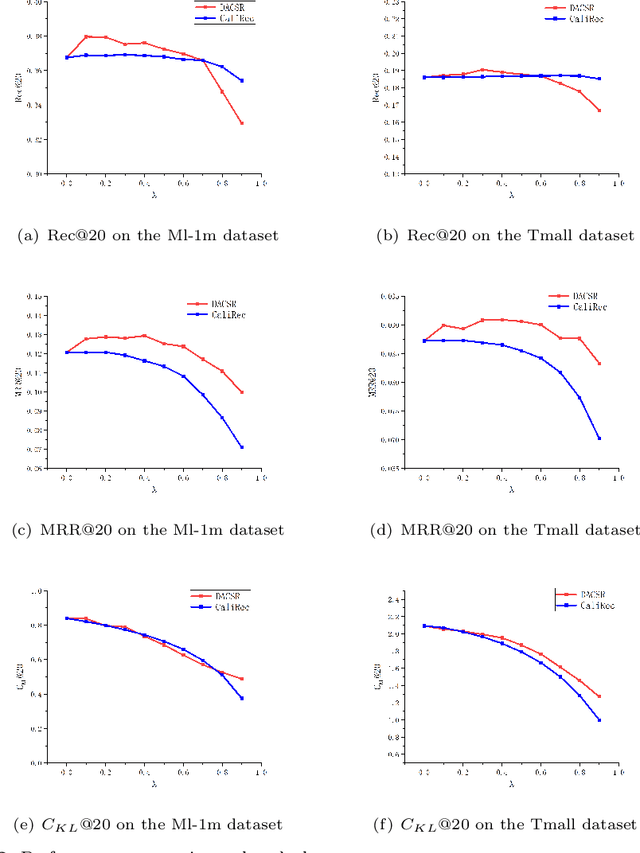
Recent years have witnessed the progress of sequential recommendation in accurately predicting users' future behaviors. However, only persuading accuracy leads to the risk of filter bubbles where recommenders only focus on users' main interest areas. Different from other studies which improve diversity or coverage, we investigate the calibration in sequential recommendation. However, existing calibrated methods followed a post-processing paradigm, which costs more computation time and sacrifices the recommendation accuracy. To this end, we propose an end-to-end framework to provide both accurate and calibrated recommendations. We propose a loss function to measure the divergence of distributions between recommendation lists and historical behaviors for sequential recommendation framework. In addition, we design a dual-aggregation model which extracts information from two individual sequence encoders with different objectives to further improve the recommendation. Experiments on two benchmark datasets demonstrate the effectiveness and efficiency of our model.
MR-iNet Gym: Framework for Edge Deployment of Deep Reinforcement Learning on Embedded Software Defined Radio
Apr 09, 2022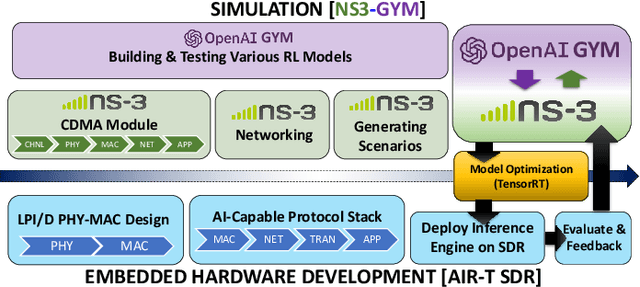
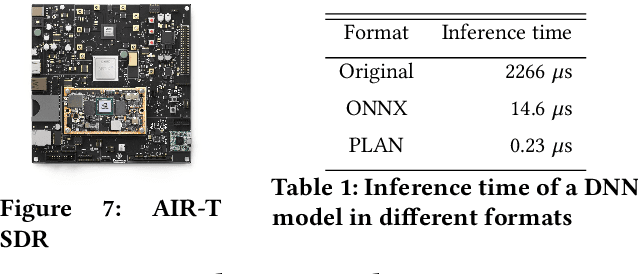
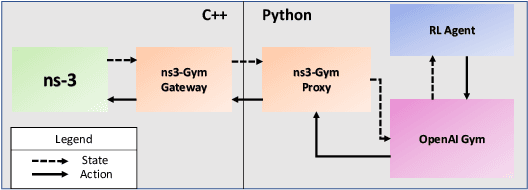
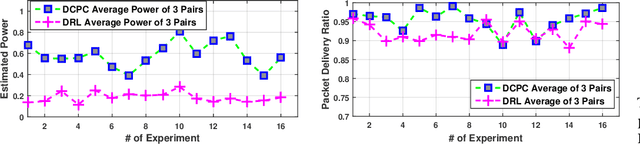
Dynamic resource allocation plays a critical role in the next generation of intelligent wireless communication systems. Machine learning has been leveraged as a powerful tool to make strides in this domain. In most cases, the progress has been limited to simulations due to the challenging nature of hardware deployment of these solutions. In this paper, for the first time, we design and deploy deep reinforcement learning (DRL)-based power control agents on the GPU embedded software defined radios (SDRs). To this end, we propose an end-to-end framework (MR-iNet Gym) where the simulation suite and the embedded SDR development work cohesively to overcome real-world implementation hurdles. To prove feasibility, we consider the problem of distributed power control for code-division multiple access (DS-CDMA)-based LPI/D transceivers. We first build a DS-CDMA ns3 module that interacts with the OpenAI Gym environment. Next, we train the power control DRL agents in this ns3-gym simulation environment in a scenario that replicates our hardware testbed. Next, for edge (embedded on-device) deployment, the trained models are optimized for real-time operation without loss of performance. Hardware-based evaluation verifies the efficiency of DRL agents over traditional distributed constrained power control (DCPC) algorithm. More significantly, as the primary goal, this is the first work that has established the feasibility of deploying DRL to provide optimized distributed resource allocation for next-generation of GPU-embedded radios.
Near-Optimal Goal-Oriented Reinforcement Learning in Non-Stationary Environments
May 25, 2022We initiate the study of dynamic regret minimization for goal-oriented reinforcement learning modeled by a non-stationary stochastic shortest path problem with changing cost and transition functions. We start by establishing a lower bound $\Omega((B_{\star} SAT_{\star}(\Delta_c + B_{\star}^2\Delta_P))^{1/3}K^{2/3})$, where $B_{\star}$ is the maximum expected cost of the optimal policy of any episode starting from any state, $T_{\star}$ is the maximum hitting time of the optimal policy of any episode starting from the initial state, $SA$ is the number of state-action pairs, $\Delta_c$ and $\Delta_P$ are the amount of changes of the cost and transition functions respectively, and $K$ is the number of episodes. The different roles of $\Delta_c$ and $\Delta_P$ in this lower bound inspire us to design algorithms that estimate costs and transitions separately. Specifically, assuming the knowledge of $\Delta_c$ and $\Delta_P$, we develop a simple but sub-optimal algorithm and another more involved minimax optimal algorithm (up to logarithmic terms). These algorithms combine the ideas of finite-horizon approximation [Chen et al., 2022a], special Bernstein-style bonuses of the MVP algorithm [Zhang et al., 2020], adaptive confidence widening [Wei and Luo, 2021], as well as some new techniques such as properly penalizing long-horizon policies. Finally, when $\Delta_c$ and $\Delta_P$ are unknown, we develop a variant of the MASTER algorithm [Wei and Luo, 2021] and integrate the aforementioned ideas into it to achieve $\widetilde{O}(\min\{B_{\star} S\sqrt{ALK}, (B_{\star}^2S^2AT_{\star}(\Delta_c+B_{\star}\Delta_P))^{1/3}K^{2/3}\})$ regret, where $L$ is the unknown number of changes of the environment.
Path-specific Underwater Acoustic Channel Tracking and its Application in Passive Time Reversal Mirror
Mar 01, 2021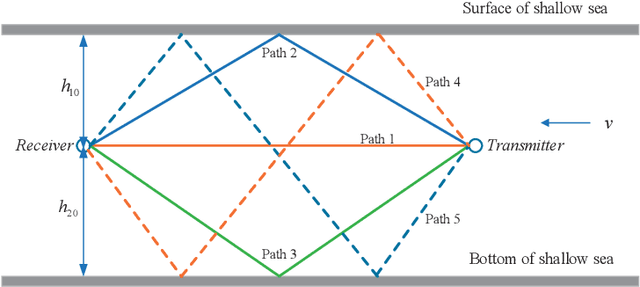
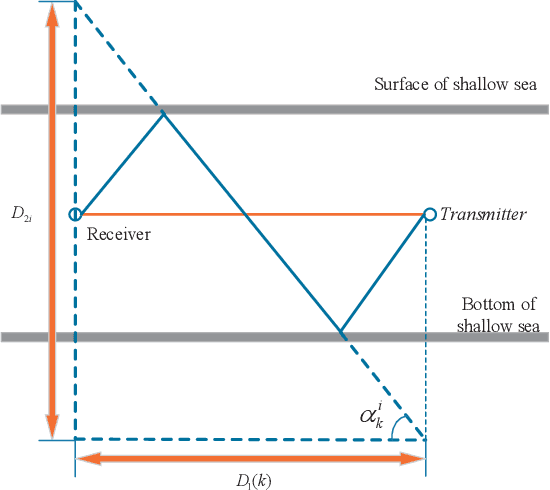
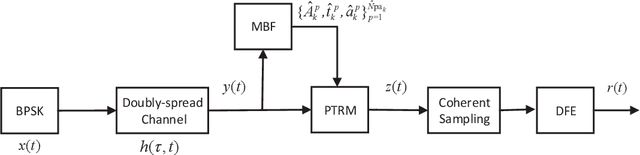

We consider the underwater acoustic channel which is time-variant and doubly-spread in this work. Since conventional channel estimation and decision feedback equalizer (DFE) can not work well for this type of channel, a path-specific underwater acoustic channel tracking is proposed. It is based on the framework of Kalman filter. We provide a simplified sound propagation model as the state transition model. A multipath tracker is proposed which is tolerant of the model-mismatch. Then we can obtain the time-variant path number and path-specific parameters such as delay and Doppler scaling factor. We also consider the application of the proposed path-specific underwater acoustic channel tracking. We propose two types of passive time reversal mirror (PTRM) with our path-specific parameters for time-variant and doubly-spread underwater acoustic channel. With the path-specific parameters obtained by the proposed channel tracking, the proposed PTRM can not only match the time dispersion as conventional PTRM, but also the doubly-spread channel, since the path-specific delay and Doppler scaler factor can help to match the channel in both time and frequency domain. For extensive doubly-spread channel, we can further apply the path-specific compensation to the PTRM. Both simulations and experimental results by data from 2016 Qiandao Lake experiment show the efficiency of proposed path-specific channel tracking and proposed PTRMs with path-specific parameters.
Federated learning for LEO constellations via inter-HAP links
May 17, 2022
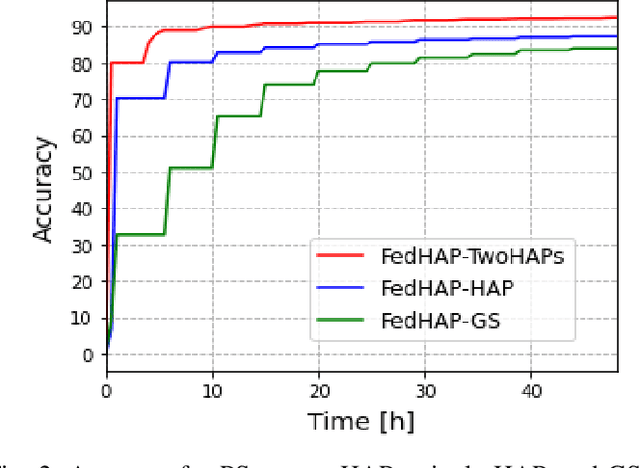
Low Earth Obit (LEO) satellite constellations have seen a sharp increase of deployment in recent years, due to their distinctive capabilities of providing broadband Internet access and enabling global data acquisition as well as large-scale AI applications. To apply machine learning (ML) in such applications, the traditional way of downloading satellite data such as imagery to a ground station (GS) and then training a model in a centralized manner, is not desirable because of the limited bandwidth, intermittent connectivity between satellites and the GS, and privacy concerns on transmitting raw data. Federated Learning (FL) as an emerging communication and computing paradigm provides a potentially supreme solution to this problem. However, we show that existing FL solutions do not fit well in such LEO constellation scenarios because of significant challenges such as excessive convergence delay and unreliable wireless channels. To this end, we propose to introduce high-altitude platforms (HAPs) as distributed parameter servers (PSs) and propose a synchronous FL algorithm, FedHAP, to accomplish model training in an efficient manner via inter-satellite collaboration. To accelerate convergence, we also propose a layered communication scheme between satellites and HAPs that FedHAP leverages. Our simulations demonstrate that FedHAP attains model convergence in much fewer communication rounds than benchmarks, cutting the training time substantially from several days down to a few hours with the same level of resulting accuracy.
Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
Mar 29, 2022
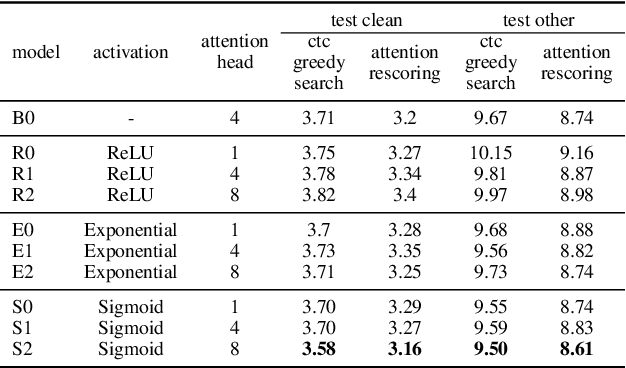
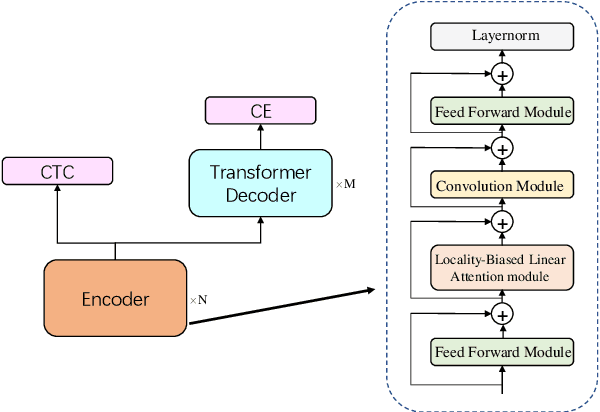
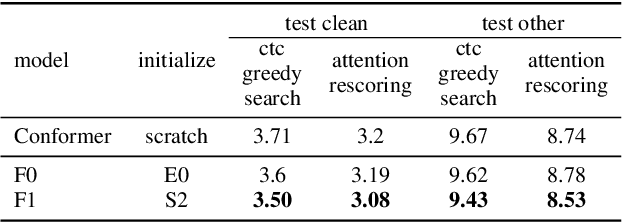
Conformer has shown a great success in automatic speech recognition (ASR) on many public benchmarks. One of its crucial drawbacks is the quadratic time-space complexity with respect to the input sequence length, which prohibits the model to scale-up as well as process longer input audio sequences. To solve this issue, numerous linear attention methods have been proposed. However, these methods often have limited performance on ASR as they treat tokens equally in modeling, neglecting the fact that the neighbouring tokens are often more connected than the distanced tokens. In this paper, we take this fact into account and propose a new locality-biased linear attention for Conformer. It not only achieves higher accuracy than the vanilla Conformer, but also enjoys linear space-time computational complexity. To be specific, we replace the softmax attention with a locality-biased linear attention (LBLA) mechanism in Conformer blocks. The LBLA contains a kernel function to ensure the linear complexities and a cosine reweighing matrix to impose more weights on neighbouring tokens. Extensive experiments on the LibriSpeech corpus show that by introducing this locality bias to the Conformer, our method achieves a lower word error rate with more than 22% inference speed.
Global Extreme Heat Forecasting Using Neural Weather Models
May 23, 2022
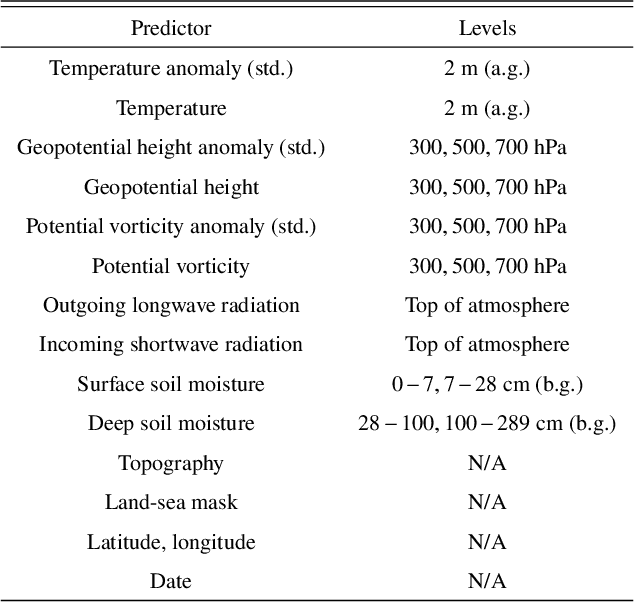
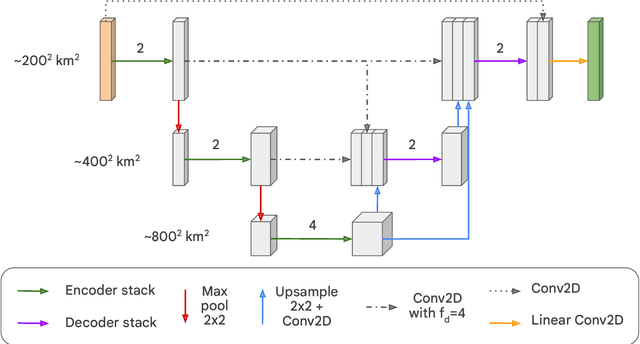
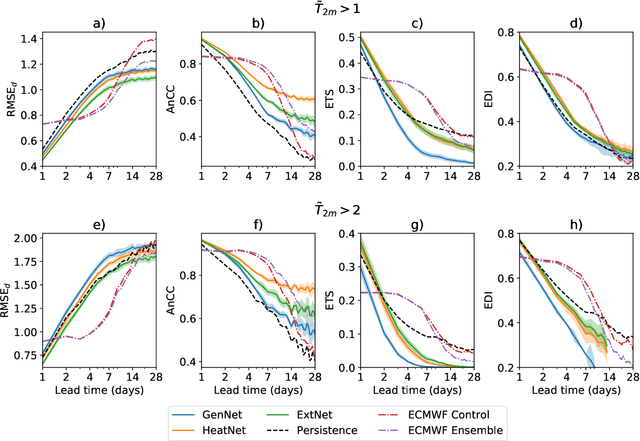
Heat waves are projected to increase in frequency and severity with global warming. Improved warning systems would help reduce the associated loss of lives, wildfires, power disruptions, and reduction in crop yields. In this work, we explore the potential for deep learning systems trained on historical data to forecast extreme heat on short, medium and subseasonal timescales. To this purpose, we train a set of neural weather models (NWMs) with convolutional architectures to forecast surface temperature anomalies globally, 1 to 28 days ahead, at $\sim200~\mathrm{km}$ resolution and on the cubed sphere. The NWMs are trained using the ERA5 reanalysis product and a set of candidate loss functions, including the mean squared error and exponential losses targeting extremes. We find that training models to minimize custom losses tailored to emphasize extremes leads to significant skill improvements in the heat wave prediction task, compared to NWMs trained on the mean squared error loss. This improvement is accomplished with almost no skill reduction in the general temperature prediction task, and it can be efficiently realized through transfer learning, by re-training NWMs with the custom losses for a few epochs. In addition, we find that the use of a symmetric exponential loss reduces the smoothing of NWM forecasts with lead time. Our best NWM is able to outperform persistence in a regressive sense for all lead times and temperature anomaly thresholds considered, and shows positive regressive skill compared to the ECMWF subseasonal-to-seasonal control forecast within the first two forecast days and after two weeks.
Explaining the Effectiveness of Multi-Task Learning for Efficient Knowledge Extraction from Spine MRI Reports
May 06, 2022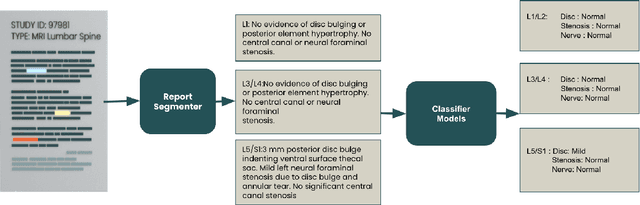
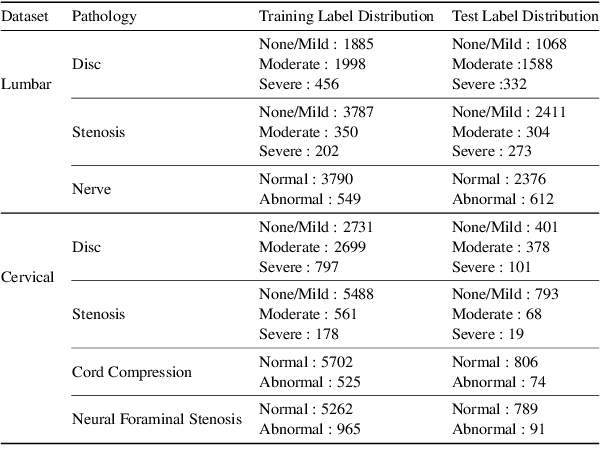
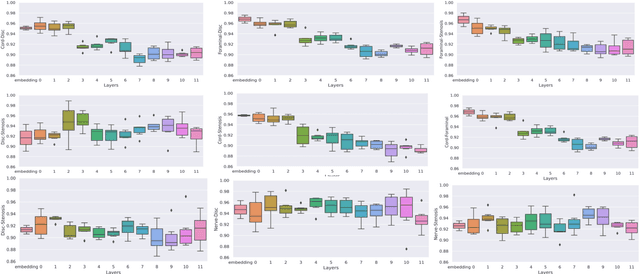
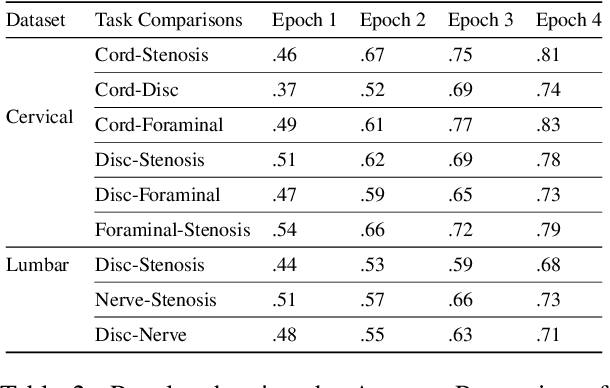
Pretrained Transformer based models finetuned on domain specific corpora have changed the landscape of NLP. However, training or fine-tuning these models for individual tasks can be time consuming and resource intensive. Thus, a lot of current research is focused on using transformers for multi-task learning (Raffel et al.,2020) and how to group the tasks to help a multi-task model to learn effective representations that can be shared across tasks (Standley et al., 2020; Fifty et al., 2021). In this work, we show that a single multi-tasking model can match the performance of task specific models when the task specific models show similar representations across all of their hidden layers and their gradients are aligned, i.e. their gradients follow the same direction. We hypothesize that the above observations explain the effectiveness of multi-task learning. We validate our observations on our internal radiologist-annotated datasets on the cervical and lumbar spine. Our method is simple and intuitive, and can be used in a wide range of NLP problems.