 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Dec 17, 2020
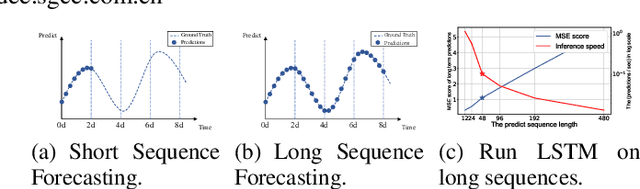
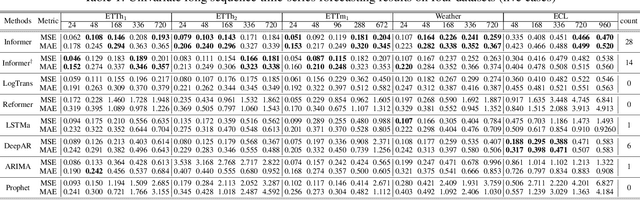
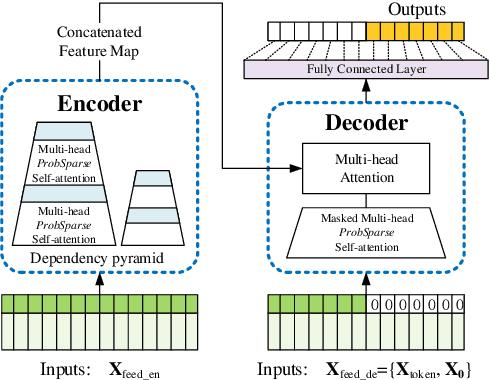
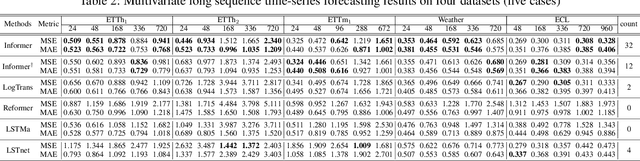
Many real-world applications require the prediction of long sequence time-series, such as electricity consumption planning. Long sequence time-series forecasting (LSTF) demands a high prediction capacity of the model, which is the ability to capture precise long-range dependency coupling between output and input efficiently. Recent studies have shown the potential of Transformer to increase the prediction capacity. However, there are several severe issues with Transformer that prevent it from being directly applicable to LSTF, such as quadratic time complexity, high memory usage, and inherent limitation of the encoder-decoder architecture. To address these issues, we design an efficient transformer-based model for LSTF, named Informer, with three distinctive characteristics: (i) a $ProbSparse$ Self-attention mechanism, which achieves $O(L \log L)$ in time complexity and memory usage, and has comparable performance on sequences' dependency alignment. (ii) the self-attention distilling highlights dominating attention by halving cascading layer input, and efficiently handles extreme long input sequences. (iii) the generative style decoder, while conceptually simple, predicts the long time-series sequences at one forward operation rather than a step-by-step way, which drastically improves the inference speed of long-sequence predictions. Extensive experiments on four large-scale datasets demonstrate that Informer significantly outperforms existing methods and provides a new solution to the LSTF problem.
Turnpike in optimal control of PDEs, ResNets, and beyond
Feb 08, 2022The \emph{turnpike property} in contemporary macroeconomics asserts that if an economic planner seeks to move an economy from one level of capital to another, then the most efficient path, as long as the planner has enough time, is to rapidly move stock to a level close to the optimal stationary or constant path, then allow for capital to develop along that path until the desired term is nearly reached, at which point the stock ought to be moved to the final target. Motivated in part by its nature as a resource allocation strategy, over the past decade, the turnpike property has also been shown to hold for several classes of partial differential equations arising in mechanics. When formalized mathematically, the turnpike theory corroborates the insights from economics: for an optimal control problem set in a finite-time horizon, optimal controls and corresponding states, are close (often exponentially), during most of the time, except near the initial and final time, to the optimal control and corresponding state for the associated stationary optimal control problem. In particular, the former are mostly constant over time. This fact provides a rigorous meaning to the asymptotic simplification that some optimal control problems appear to enjoy over long time intervals, allowing the consideration of the corresponding stationary problem for computing and applications. We review a slice of the theory developed over the past decade --the controllability of the underlying system is an important ingredient, and can even be used to devise simple turnpike-like strategies which are nearly optimal--, and present several novel applications, including, among many others, the characterization of Hamilton-Jacobi-Bellman asymptotics, and stability estimates in deep learning via residual neural networks.
Predicting Training Time Without Training
Aug 28, 2020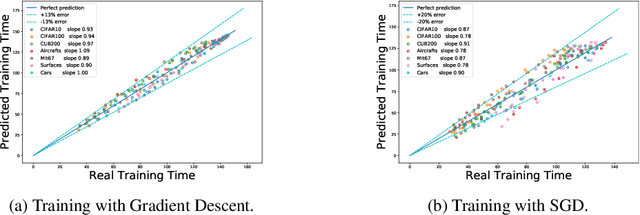
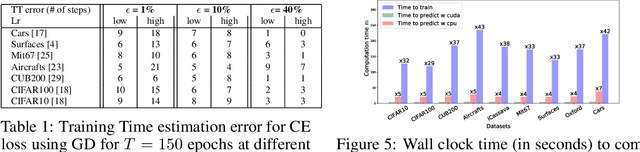
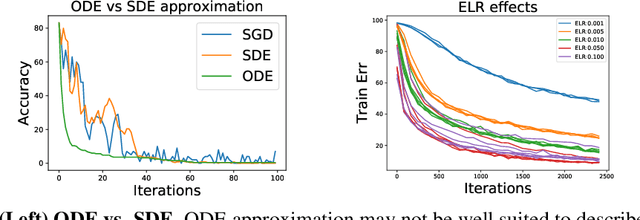
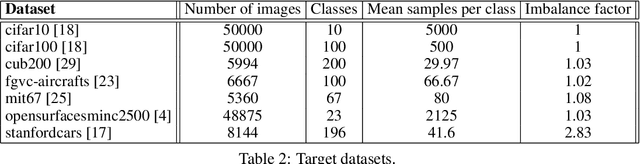
We tackle the problem of predicting the number of optimization steps that a pre-trained deep network needs to converge to a given value of the loss function. To do so, we leverage the fact that the training dynamics of a deep network during fine-tuning are well approximated by those of a linearized model. This allows us to approximate the training loss and accuracy at any point during training by solving a low-dimensional Stochastic Differential Equation (SDE) in function space. Using this result, we are able to predict the time it takes for Stochastic Gradient Descent (SGD) to fine-tune a model to a given loss without having to perform any training. In our experiments, we are able to predict training time of a ResNet within a 20% error margin on a variety of datasets and hyper-parameters, at a 30 to 45-fold reduction in cost compared to actual training. We also discuss how to further reduce the computational and memory cost of our method, and in particular we show that by exploiting the spectral properties of the gradients' matrix it is possible predict training time on a large dataset while processing only a subset of the samples.
Leveraging Smooth Attention Prior for Multi-Agent Trajectory Prediction
Mar 19, 2022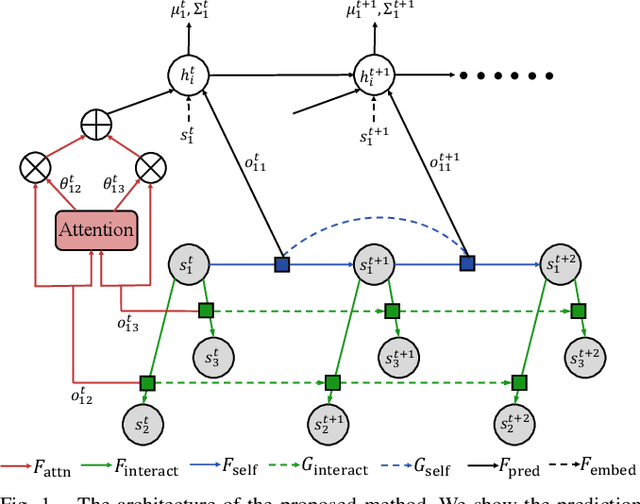
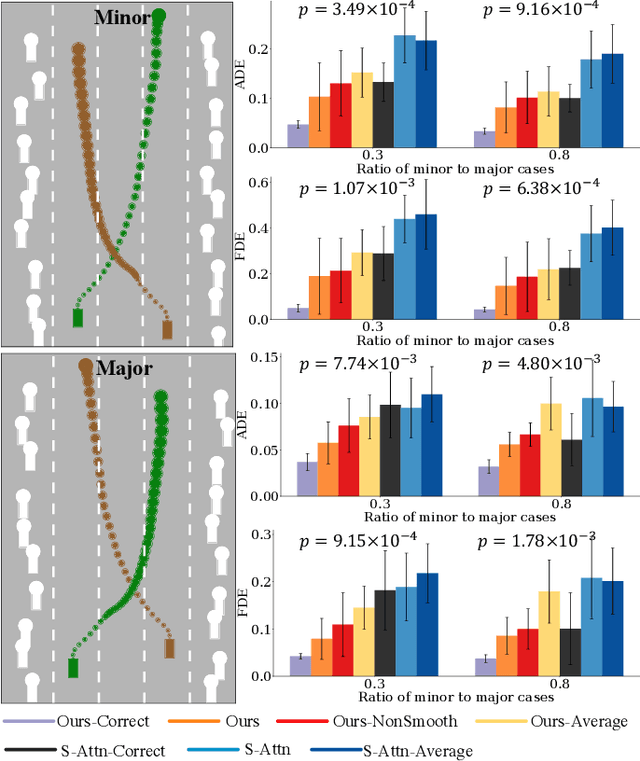
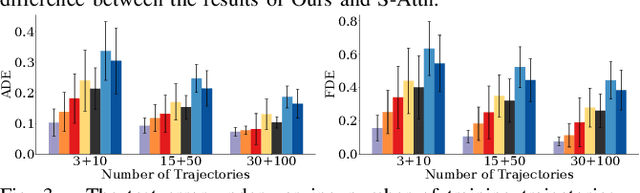
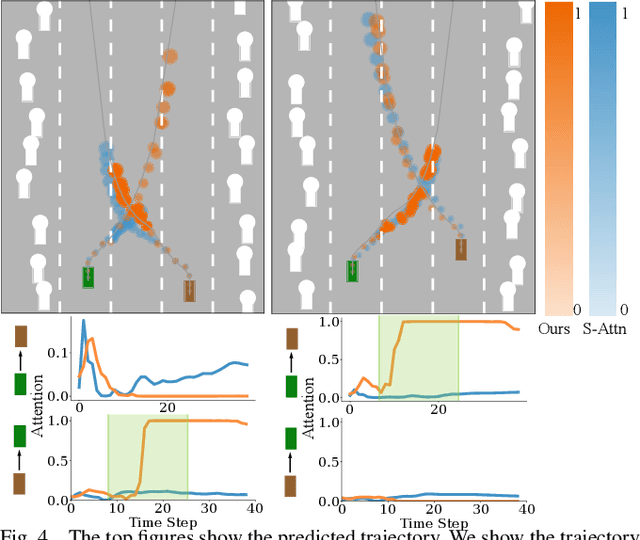
Multi-agent interactions are important to model for forecasting other agents' behaviors and trajectories. At a certain time, to forecast a reasonable future trajectory, each agent needs to pay attention to the interactions with only a small group of most relevant agents instead of unnecessarily paying attention to all the other agents. However, existing attention modeling works ignore that human attention in driving does not change rapidly, and may introduce fluctuating attention across time steps. In this paper, we formulate an attention model for multi-agent interactions based on a total variation temporal smoothness prior and propose a trajectory prediction architecture that leverages the knowledge of these attended interactions. We demonstrate how the total variation attention prior along with the new sequence prediction loss terms leads to smoother attention and more sample-efficient learning of multi-agent trajectory prediction, and show its advantages in terms of prediction accuracy by comparing it with the state-of-the-art approaches on both synthetic and naturalistic driving data. We demonstrate the performance of our algorithm for trajectory prediction on the INTERACTION dataset on our website.
* 8 pages
Planning to Practice: Efficient Online Fine-Tuning by Composing Goals in Latent Space
May 17, 2022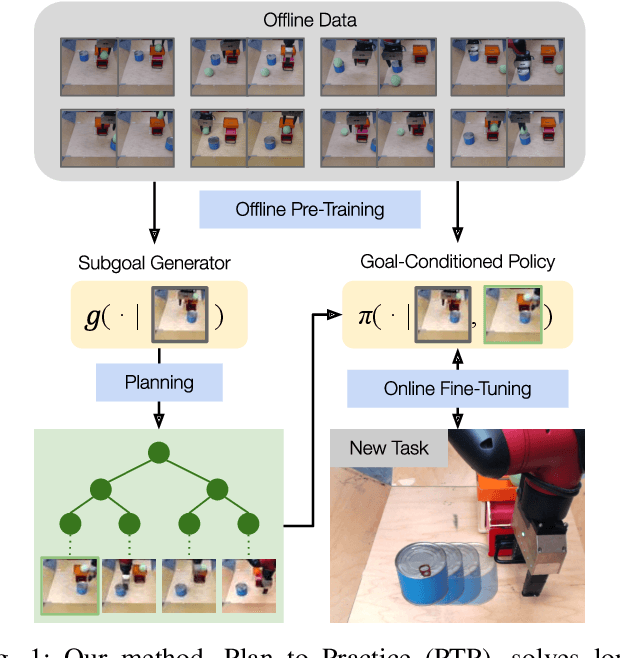
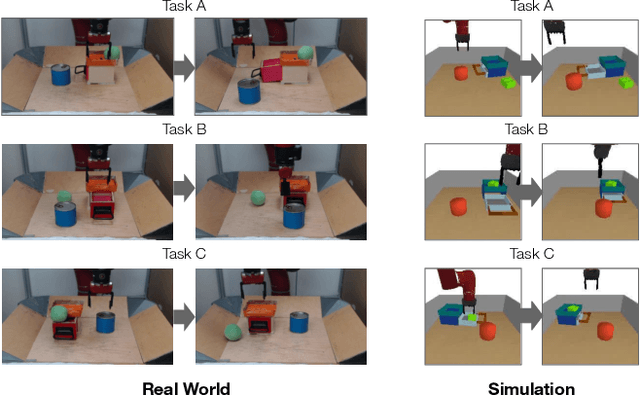
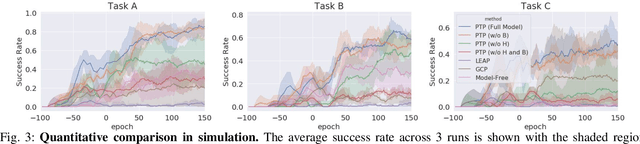

General-purpose robots require diverse repertoires of behaviors to complete challenging tasks in real-world unstructured environments. To address this issue, goal-conditioned reinforcement learning aims to acquire policies that can reach configurable goals for a wide range of tasks on command. However, such goal-conditioned policies are notoriously difficult and time-consuming to train from scratch. In this paper, we propose Planning to Practice (PTP), a method that makes it practical to train goal-conditioned policies for long-horizon tasks that require multiple distinct types of interactions to solve. Our approach is based on two key ideas. First, we decompose the goal-reaching problem hierarchically, with a high-level planner that sets intermediate subgoals using conditional subgoal generators in the latent space for a low-level model-free policy. Second, we propose a hybrid approach which first pre-trains both the conditional subgoal generator and the policy on previously collected data through offline reinforcement learning, and then fine-tunes the policy via online exploration. This fine-tuning process is itself facilitated by the planned subgoals, which breaks down the original target task into short-horizon goal-reaching tasks that are significantly easier to learn. We conduct experiments in both the simulation and real world, in which the policy is pre-trained on demonstrations of short primitive behaviors and fine-tuned for temporally extended tasks that are unseen in the offline data. Our experimental results show that PTP can generate feasible sequences of subgoals that enable the policy to efficiently solve the target tasks.
Learning the Effect of Registration Hyperparameters with HyperMorph
Mar 30, 2022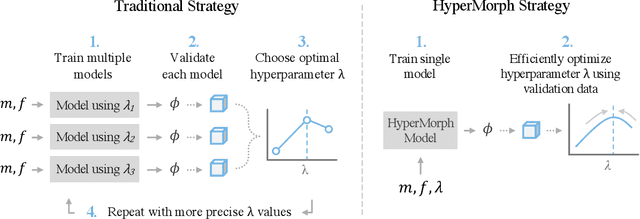
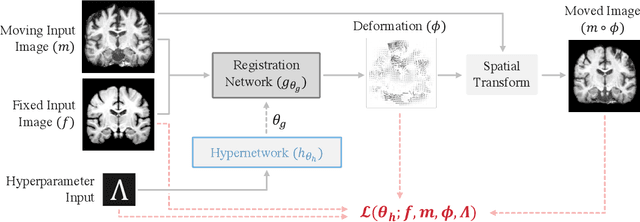

We introduce HyperMorph, a framework that facilitates efficient hyperparameter tuning in learning-based deformable image registration. Classical registration algorithms perform an iterative pair-wise optimization to compute a deformation field that aligns two images. Recent learning-based approaches leverage large image datasets to learn a function that rapidly estimates a deformation for a given image pair. In both strategies, the accuracy of the resulting spatial correspondences is strongly influenced by the choice of certain hyperparameter values. However, an effective hyperparameter search consumes substantial time and human effort as it often involves training multiple models for different fixed hyperparameter values and may lead to suboptimal registration. We propose an amortized hyperparameter learning strategy to alleviate this burden by learning the impact of hyperparameters on deformation fields. We design a meta network, or hypernetwork, that predicts the parameters of a registration network for input hyperparameters, thereby comprising a single model that generates the optimal deformation field corresponding to given hyperparameter values. This strategy enables fast, high-resolution hyperparameter search at test-time, reducing the inefficiency of traditional approaches while increasing flexibility. We also demonstrate additional benefits of HyperMorph, including enhanced robustness to model initialization and the ability to rapidly identify optimal hyperparameter values specific to a dataset, image contrast, task, or even anatomical region, all without the need to retrain models. We make our code publicly available at http://hypermorph.voxelmorph.net.
Using the Projected Belief Network at High Dimensions
Apr 25, 2022
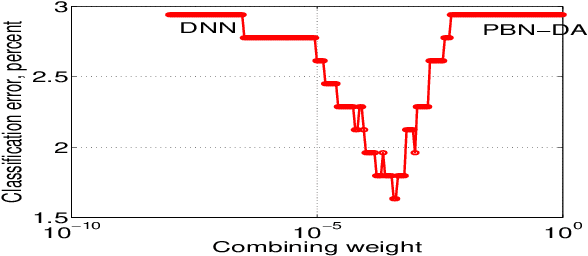
The projected belief network (PBN) is a layered generative network (LGN) with tractable likelihood function, and is based on a feed-forward neural network (FFNN). There are two versions of the PBN: stochastic and deterministic (D-PBN), and each has theoretical advantages over other LGNs. However, implementation of the PBN requires an iterative algorithm that includes the inversion of a symmetric matrix of size M X M in each layer, where M is the layer output dimension. This, and the fact that the network must be always dimension-reducing in each layer, can limit the types of problems where the PBN can be applied. In this paper, we describe techniques to avoid or mitigate these restrictions and use the PBN effectively at high dimension. We apply the discriminatively aligned PBN (PBN-DA) to classifying and auto-encoding high-dimensional spectrograms of acoustic events. We also present the discriminatively aligned D-PBN for the first time.
Class Balanced PixelNet for Neurological Image Segmentation
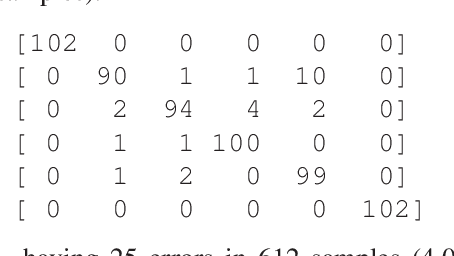
Apr 23, 2022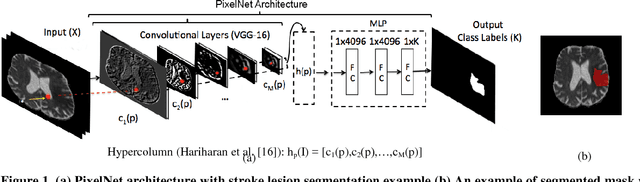
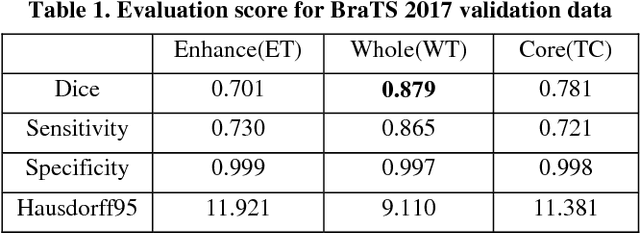
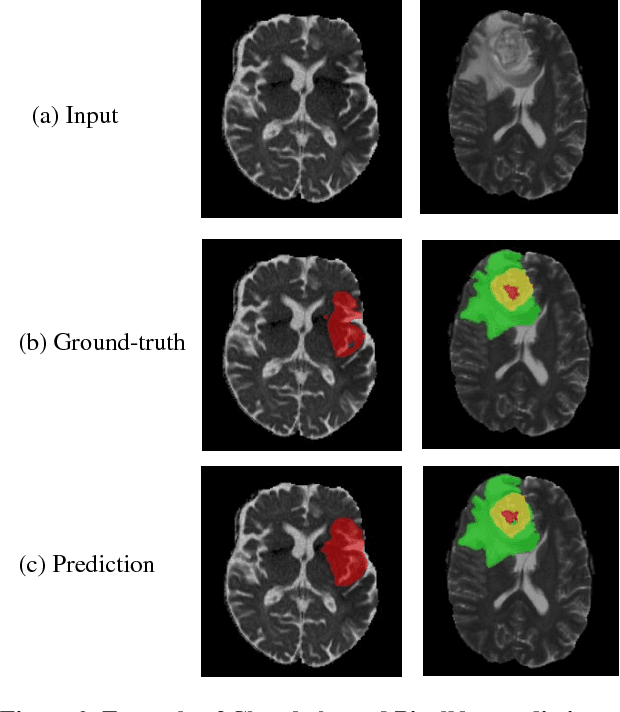
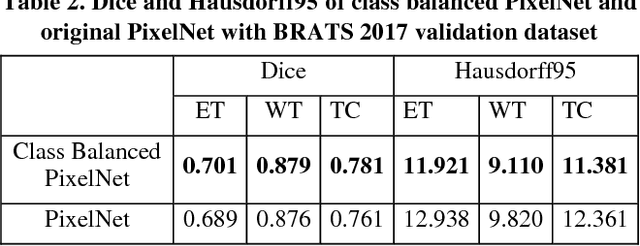
In this paper, we propose an automatic brain tumor segmentation approach (e.g., PixelNet) using a pixel-level convolutional neural network (CNN). The model extracts feature from multiple convolutional layers and concatenate them to form a hyper-column where samples a modest number of pixels for optimization. Hyper-column ensures both local and global contextual information for pixel-wise predictors. The model confirms the statistical efficiency by sampling a few pixels in the training phase where spatial redundancy limits the information learning among the neighboring pixels in conventional pixel-level semantic segmentation approaches. Besides, label skewness in training data leads the convolutional model often converge to certain classes which is a common problem in the medical dataset. We deal with this problem by selecting an equal number of pixels for all the classes in sampling time. The proposed model has achieved promising results in brain tumor and ischemic stroke lesion segmentation datasets.
Learning Dynamic Bipedal Walking Across Stepping Stones
May 03, 2022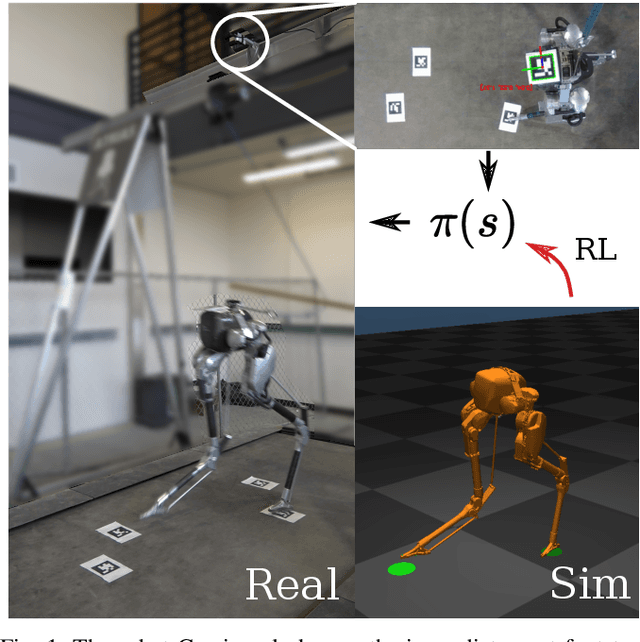
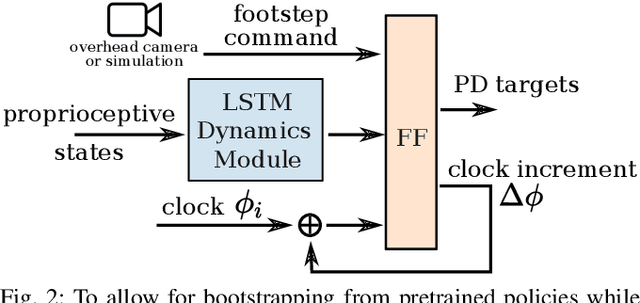
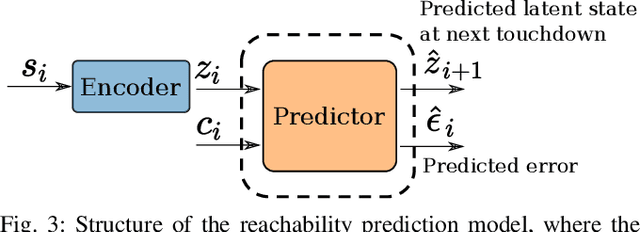
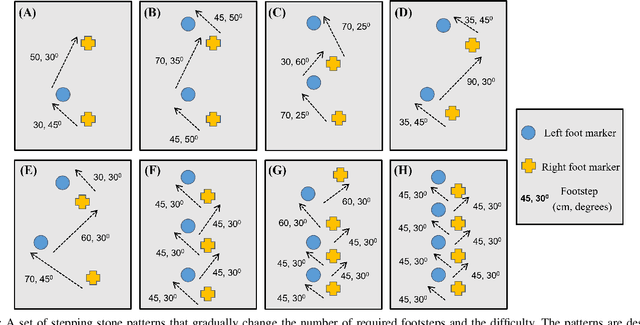
In this work, we propose a learning approach for 3D dynamic bipedal walking when footsteps are constrained to stepping stones. While recent work has shown progress on this problem, real-world demonstrations have been limited to relatively simple open-loop, perception-free scenarios. Our main contribution is a more advanced learning approach that enables real-world demonstrations, using the Cassie robot, of closed-loop dynamic walking over moderately difficult stepping-stone patterns. Our approach first uses reinforcement learning (RL) in simulation to train a controller that maps footstep commands onto joint actions without any reference motion information. We then learn a model of that controller's capabilities, which enables prediction of feasible footsteps given the robot's current dynamic state. The resulting controller and model are then integrated with a real-time overhead camera system for detecting stepping stone locations. For evaluation, we develop a benchmark set of stepping stone patterns, which are used to test performance in both simulation and the real world. Overall, we demonstrate that sim-to-real learning is extremely promising for enabling dynamic locomotion over stepping stones. We also identify challenges remaining that motivate important future research directions.
Empirical Analysis of Lifelog Data using Optimal Feature Selection based Unsupervised Logistic Regression (OFS-ULR) Model with Spark Streaming
Apr 12, 2022



Recent advancement in the field of pervasive healthcare monitoring systems causes the generation of a huge amount of lifelog data in real-time. Chronic diseases are one of the most serious health challenges in developing and developed countries. According to WHO, this accounts for 73% of all deaths and 60% of the global burden of diseases. Chronic disease classification models are now harnessing the potential of lifelog data to explore better healthcare practices. This paper is to construct an optimal feature selection-based unsupervised logistic regression model (OFS-ULR) to classify chronic diseases. Since lifelog data analysis is crucial due to its sensitive nature; thus the conventional classification models show limited performance. Therefore, designing new classifiers for the classification of chronic diseases using lifelog data is the need of the age. The vital part of building a good model depends on pre-processing of the dataset, identifying important features, and then training a learning algorithm with suitable hyper parameters for better performance. The proposed approach improves the performance of existing methods using a series of steps such as (i) removing redundant or invalid instances, (ii) making the data labelled using clustering and partitioning the data into classes, (iii) identifying the suitable subset of features by applying either some domain knowledge or selection algorithm, (iv) hyper parameter tuning for models to get best results, and (v) performance evaluation using Spark streaming environment. For this purpose, two-time series datasets are used in the experiment to compute the accuracy, recall, precision, and f1-score. The experimental analysis proves the suitability of the proposed approach as compared to the conventional classifiers and our newly constructed model achieved highest accuracy and reduced training complexity among all among all.