 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Unsupervised Learning of Accurate Siamese Tracking
Apr 04, 2022
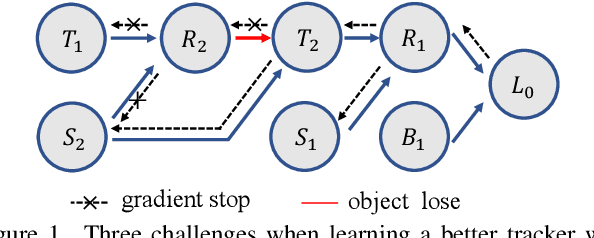
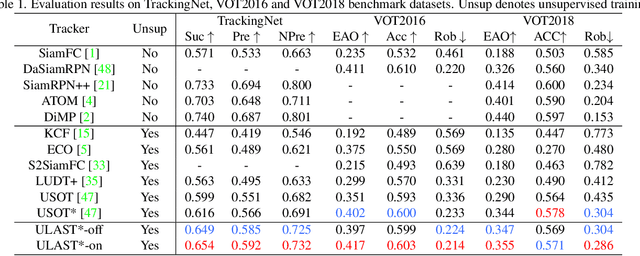
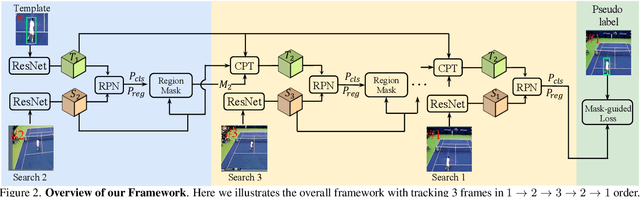
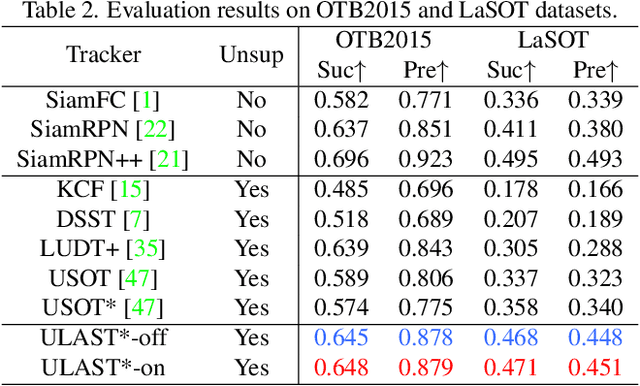
Unsupervised learning has been popular in various computer vision tasks, including visual object tracking. However, prior unsupervised tracking approaches rely heavily on spatial supervision from template-search pairs and are still unable to track objects with strong variation over a long time span. As unlimited self-supervision signals can be obtained by tracking a video along a cycle in time, we investigate evolving a Siamese tracker by tracking videos forward-backward. We present a novel unsupervised tracking framework, in which we can learn temporal correspondence both on the classification branch and regression branch. Specifically, to propagate reliable template feature in the forward propagation process so that the tracker can be trained in the cycle, we first propose a consistency propagation transformation. We then identify an ill-posed penalty problem in conventional cycle training in backward propagation process. Thus, a differentiable region mask is proposed to select features as well as to implicitly penalize tracking errors on intermediate frames. Moreover, since noisy labels may degrade training, we propose a mask-guided loss reweighting strategy to assign dynamic weights based on the quality of pseudo labels. In extensive experiments, our tracker outperforms preceding unsupervised methods by a substantial margin, performing on par with supervised methods on large-scale datasets such as TrackingNet and LaSOT. Code is available at https://github.com/FlorinShum/ULAST.
Attention-based Multimodal Feature Representation Model for Micro-video Recommendation
May 18, 2022
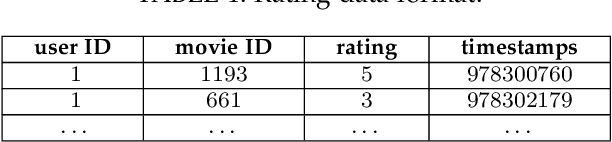
In recommender systems, models mostly use a combination of embedding layers and multilayer feedforward neural networks. The high-dimensional sparse original features are downscaled in the embedding layer and then fed into the fully connected network to obtain prediction results. However, the above methods have a rather obvious problem, that is, the features directly input are treated as independent individuals, and in fact there are internal correlations between features and features, and even different features have different importance in the recommendation. In this regard, this paper adopts a self-attentive mechanism to mine the internal correlations between features as well as their relative importance. In recent years, as a special form of attention mechanism, self-attention mechanism is favored by many researchers. The self-attentive mechanism captures the internal correlation of data or features by learning itself, thus reducing the dependence on external sources. Therefore, this paper adopts a multi-headed self-attentive mechanism to mine the internal correlations between features and thus learn the internal representation of features. At the same time, considering the rich information often hidden between features, the new feature representation obtained by crossover between the two is likely to imply the new description of the user likes the item. However, not all crossover features are meaningful, i.e., there is a problem of limited expression of feature combinations. Therefore, this paper adopts an attention-based approach to learn the external cross-representation of features.
YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
Apr 14, 2022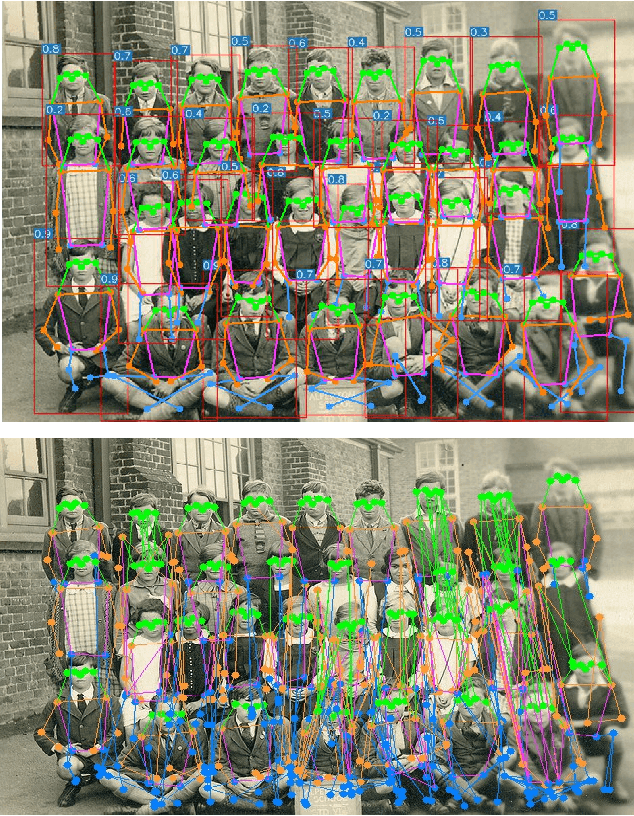
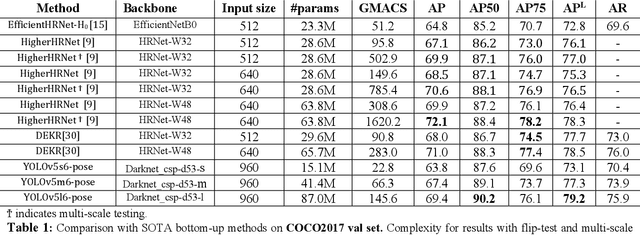
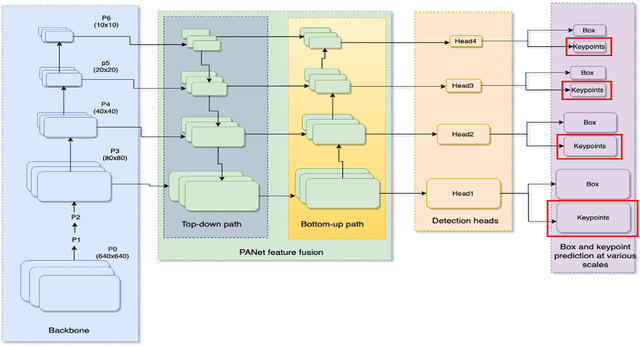
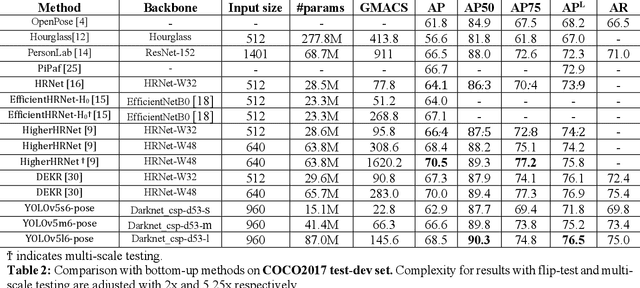
We introduce YOLO-pose, a novel heatmap-free approach for joint detection, and 2D multi-person pose estimation in an image based on the popular YOLO object detection framework. Existing heatmap based two-stage approaches are sub-optimal as they are not end-to-end trainable and training relies on a surrogate L1 loss that is not equivalent to maximizing the evaluation metric, i.e. Object Keypoint Similarity (OKS). Our framework allows us to train the model end-to-end and optimize the OKS metric itself. The proposed model learns to jointly detect bounding boxes for multiple persons and their corresponding 2D poses in a single forward pass and thus bringing in the best of both top-down and bottom-up approaches. Proposed approach doesn't require the postprocessing of bottom-up approaches to group detected keypoints into a skeleton as each bounding box has an associated pose, resulting in an inherent grouping of the keypoints. Unlike top-down approaches, multiple forward passes are done away with since all persons are localized along with their pose in a single inference. YOLO-pose achieves new state-of-the-art results on COCO validation (90.2% AP50) and test-dev set (90.3% AP50), surpassing all existing bottom-up approaches in a single forward pass without flip test, multi-scale testing, or any other test time augmentation. All experiments and results reported in this paper are without any test time augmentation, unlike traditional approaches that use flip-test and multi-scale testing to boost performance. Our training codes will be made publicly available at https://github.com/TexasInstruments/edgeai-yolov5 and https://github.com/TexasInstruments/edgeai-yolox
Learning to Help Emergency Vehicles Arrive Faster: A Cooperative Vehicle-Road Scheduling Approach
Feb 20, 2022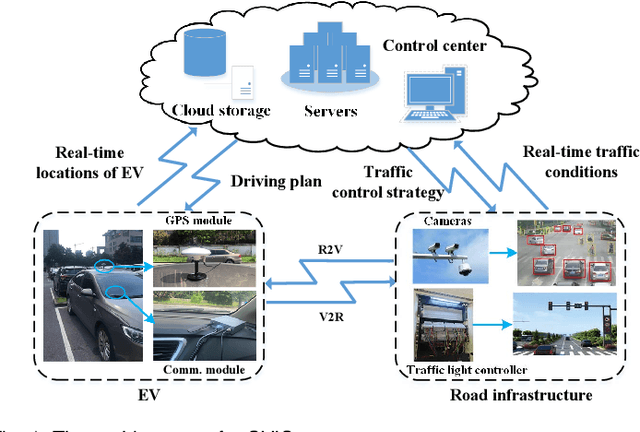

The ever-increasing heavy traffic congestion potentially impedes the accessibility of emergency vehicles (EVs), resulting in detrimental impacts on critical services and even safety of people's lives. Hence, it is significant to propose an efficient scheduling approach to help EVs arrive faster. Existing vehicle-centric scheduling approaches aim to recommend the optimal paths for EVs based on the current traffic status while the road-centric scheduling approaches aim to improve the traffic condition and assign a higher priority for EVs to pass an intersection. With the intuition that real-time vehicle-road information interaction and strategy coordination can bring more benefits, we propose LEVID, a LEarning-based cooperative VehIcle-roaD scheduling approach including a real-time route planning module and a collaborative traffic signal control module, which interact with each other and make decisions iteratively. The real-time route planning module adapts the artificial potential field method to address the real-time changes of traffic signals and avoid falling into a local optimum. The collaborative traffic signal control module leverages a graph attention reinforcement learning framework to extract the latent features of different intersections and abstract their interplay to learn cooperative policies. Extensive experiments based on multiple real-world datasets show that our approach outperforms the state-of-the-art baselines.
Cello: Efficient Computer Systems Optimization with Predictive Early Termination and Censored Regression
Apr 11, 2022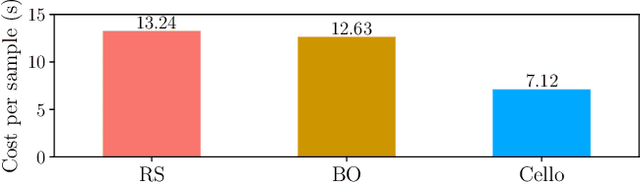
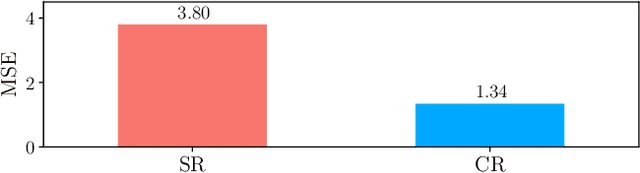
Sample-efficient machine learning (SEML) has been widely applied to find optimal latency and power tradeoffs for configurable computer systems. Instead of randomly sampling from the configuration space, SEML reduces the search cost by dramatically reducing the number of configurations that must be sampled to optimize system goals (e.g., low latency or energy). Nevertheless, SEML only reduces one component of cost -- the total number of samples collected -- but does not decrease the cost of collecting each sample. Critically, not all samples are equal; some take much longer to collect because they correspond to slow system configurations. This paper present Cello, a computer systems optimization framework that reduces sample collection costs -- especially those that come from the slowest configurations. The key insight is to predict ahead of time whether samples will have poor system behavior (e.g., long latency or high energy) and terminate these samples early before their measured system behavior surpasses the termination threshold, which we call it predictive early termination. To predict the future system behavior accurately before it manifests as high runtime or energy, Cello uses censored regression to produces accurate predictions for running samples. We evaluate Cello by optimizing latency and energy for Apache Spark workloads. We give Cello a fixed amount of time to search a combined space of hardware and software configuration parameters. Our evaluation shows that compared to the state-of-the-art SEML approach in computer systems optimization, Cello improves latency by 1.19X for minimizing latency under a power constraint, and improves energy by 1.18X for minimizing energy under a latency constraint.
FedHAP: Fast Federated Learning for LEO Constellations using Collaborative HAPs
May 15, 2022
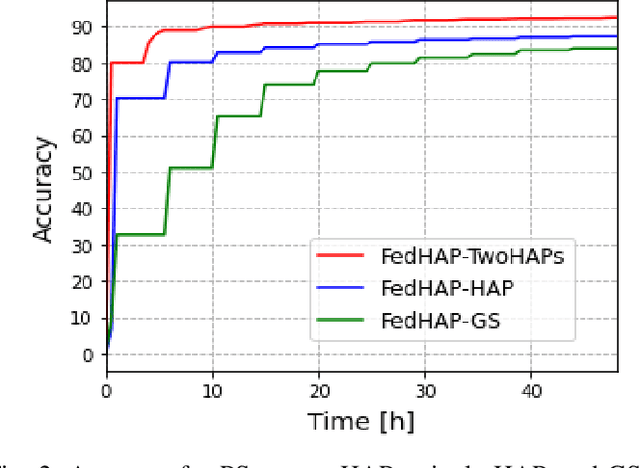
Low Earth Obit (LEO) satellite constellations have seen a sharp increase of deployment in recent years, due to their distinctive capabilities of providing broadband Internet access and enabling global data acquisition as well as large-scale AI applications. To apply machine learning (ML) in such applications, the traditional way of downloading satellite data such as imagery to a ground station (GS) and then training a model in a centralized manner, is not desirable because of the limited bandwidth, intermittent connectivity between satellites and the GS, and privacy concerns on transmitting raw data. Federated Learning (FL) as an emerging communication and computing paradigm provides a potentially supreme solution to this problem. However, we show that existing FL solutions do not fit well in such LEO constellation scenarios because of significant challenges such as excessive convergence delay and unreliable wireless channels. To this end, we propose to introduce high-altitude platforms (HAPs) as distributed parameter servers (PSs) and propose a synchronous FL algorithm, FedHAP, to accomplish model training in an efficient manner via inter-satellite collaboration. To accelerate convergence, we also propose a layered communication scheme between satellites and HAPs that FedHAP leverages. Our simulations demonstrate that FedHAP attains model convergence in much fewer communication rounds than benchmarks, cutting the training time substantially from several days down to a few hours with the same level of resulting accuracy.
RLSS: Real-time Multi-Robot Trajectory Replanning using Linear Spatial Separations
Mar 13, 2021
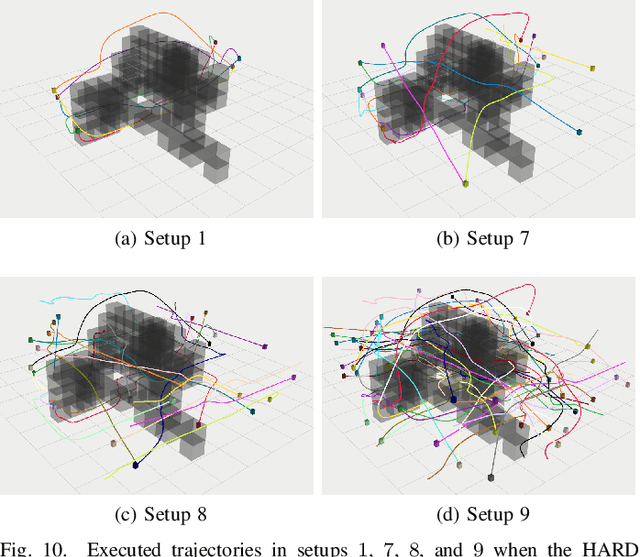
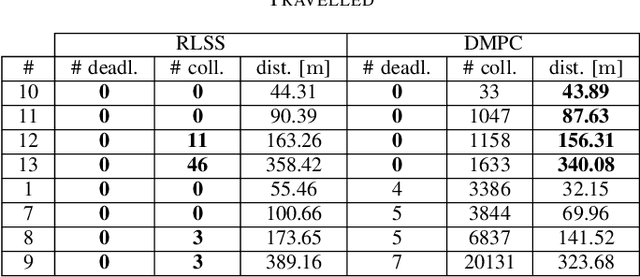
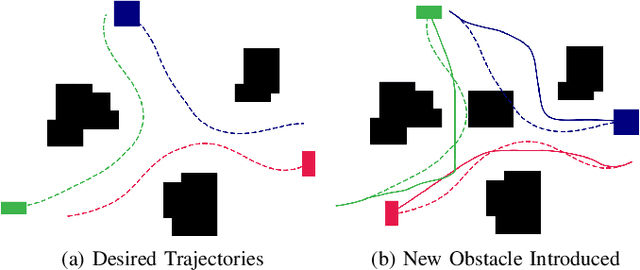
Trajectory replanning is a critical problem for multi-robot teams navigating dynamic environments. We present RLSS (Replanning using Linear Spatial Separations): a real-time trajectory replanning algorithm for cooperative multi-robot teams that uses linear spatial separations to enforce safety. Our algorithm handles the dynamic limits of the robots explicitly, is completely distributed, and is robust to environment changes, robot failures, and trajectory tracking errors. It requires no communication between robots and relies instead on local relative measurements only. We demonstrate that the algorithm works in real-time both in simulations and in experiments using physical robots. We compare our algorithm to a state-of-the-art online trajectory generation algorithm based on model predictive control, and show that our algorithm results in significantly fewer collisions in highly constrained environments, and effectively avoids deadlocks.
DynamicEarthNet: Daily Multi-Spectral Satellite Dataset for Semantic Change Segmentation
Mar 23, 2022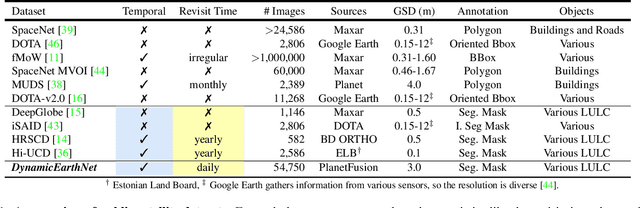
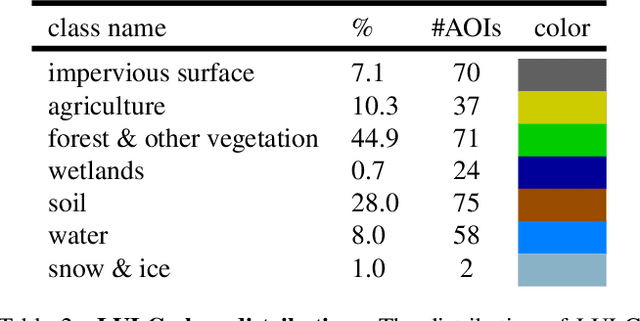

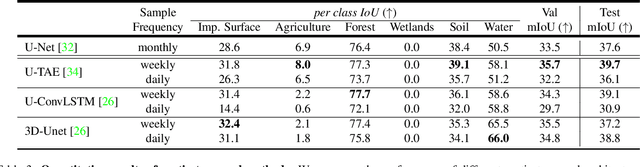
Earth observation is a fundamental tool for monitoring the evolution of land use in specific areas of interest. Observing and precisely defining change, in this context, requires both time-series data and pixel-wise segmentations. To that end, we propose the DynamicEarthNet dataset that consists of daily, multi-spectral satellite observations of 75 selected areas of interest distributed over the globe with imagery from Planet Labs. These observations are paired with pixel-wise monthly semantic segmentation labels of 7 land use and land cover (LULC) classes. DynamicEarthNet is the first dataset that provides this unique combination of daily measurements and high-quality labels. In our experiments, we compare several established baselines that either utilize the daily observations as additional training data (semi-supervised learning) or multiple observations at once (spatio-temporal learning) as a point of reference for future research. Finally, we propose a new evaluation metric SCS that addresses the specific challenges associated with time-series semantic change segmentation. The data is available at: https://mediatum.ub.tum.de/1650201.
Reflective Fiber Faults Detection and Characterization Using Long-Short-Term Memory
Mar 19, 2022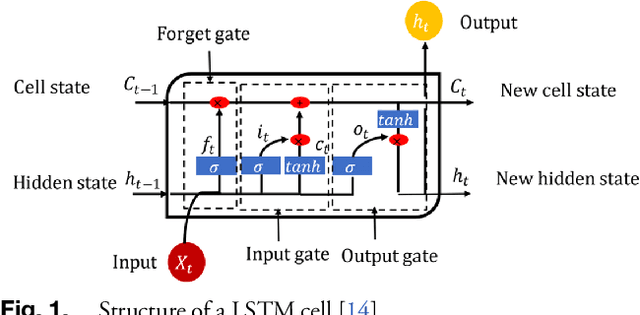
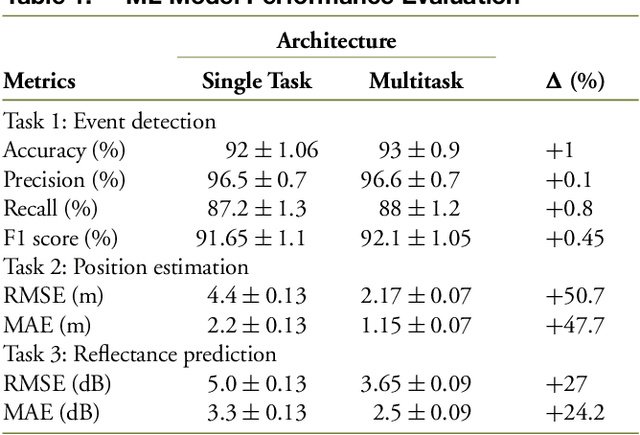
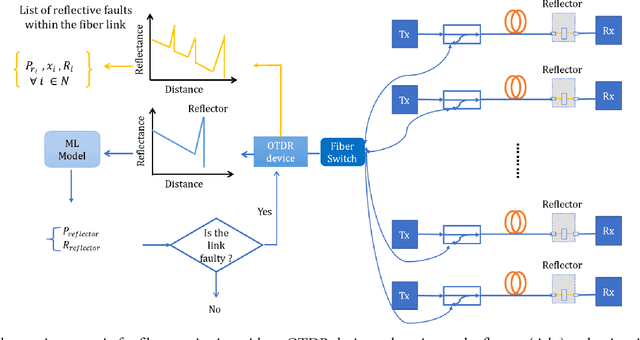
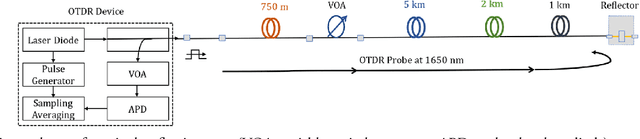
To reduce operation-and-maintenance expenses (OPEX) and to ensure optical network survivability, optical network operators need to detect and diagnose faults in a timely manner and with high accuracy. With the rapid advancement of telemetry technology and data analysis techniques, data-driven approaches leveraging telemetry data to tackle the fault diagnosis problem have been gaining popularity due to their quick implementation and deployment. In this paper, we propose a novel multi-task learning model based on long short-term memory (LSTM) to detect, locate, and estimate the reflectance of fiber reflective faults (events) including the connectors and the mechanical splices by extracting insights from monitored data obtained by the optical time domain reflectometry (OTDR) principle commonly used for troubleshooting of fiber optic cables or links. The experimental results prove that the proposed method: (i) achieves a good detection capability and high localization accuracy within short measurement time even for low SNR values; and (ii) outperforms conventionally employed techniques.
Univariate and Multivariate LSTM Model for Short-Term Stock Market Prediction
May 08, 2022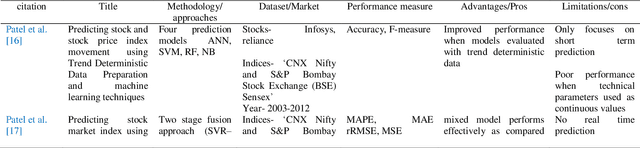
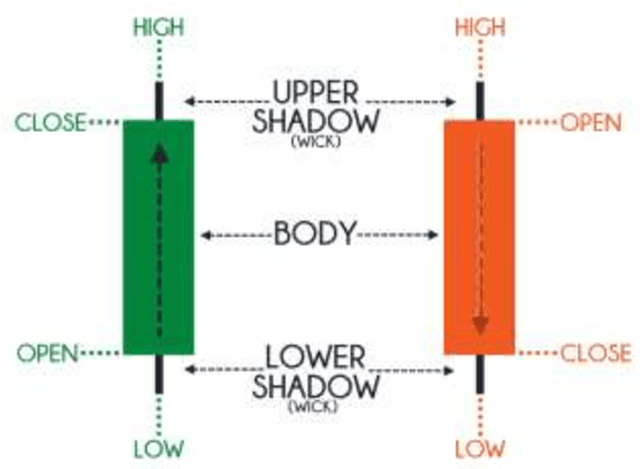
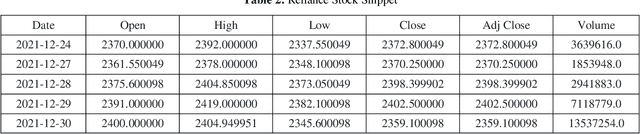
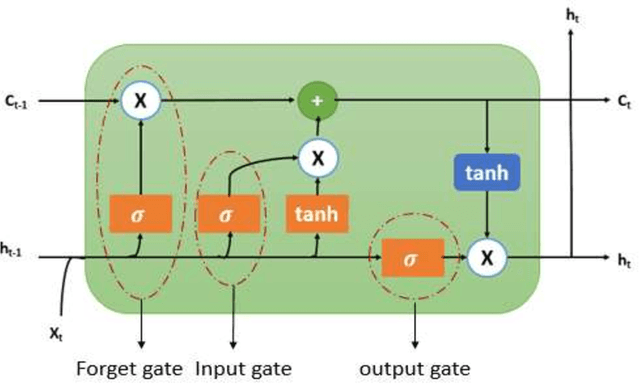
Designing robust and accurate prediction models has been a viable research area since a long time. While proponents of a well-functioning market predictors believe that it is difficult to accurately predict market prices but many scholars disagree. Robust and accurate prediction systems will not only be helpful to the businesses but also to the individuals in making their financial investments. This paper presents an LSTM model with two different input approaches for predicting the short-term stock prices of two Indian companies, Reliance Industries and Infosys Ltd. Ten years of historic data (2012-2021) is taken from the yahoo finance website to carry out analysis of proposed approaches. In the first approach, closing prices of two selected companies are directly applied on univariate LSTM model. For the approach second, technical indicators values are calculated from the closing prices and then collectively applied on Multivariate LSTM model. Short term market behaviour for upcoming days is evaluated. Experimental outcomes revel that approach one is useful to determine the future trend but multivariate LSTM model with technical indicators found to be useful in accurately predicting the future price behaviours.