 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data Augmentation for Manipulation
May 11, 2022


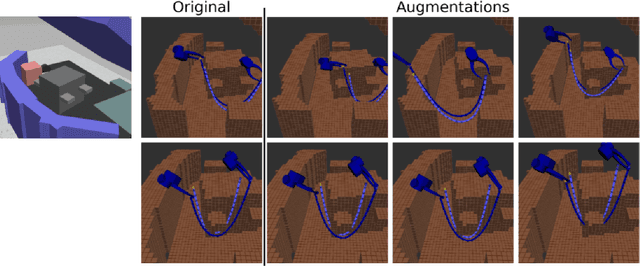
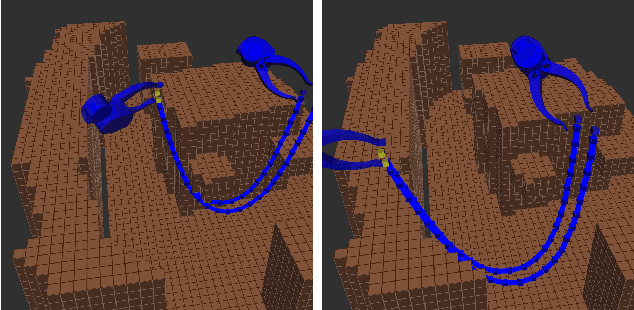
The success of deep learning depends heavily on the availability of large datasets, but in robotic manipulation there are many learning problems for which such datasets do not exist. Collecting these datasets is time-consuming and expensive, and therefore learning from small datasets is an important open problem. Within computer vision, a common approach to a lack of data is data augmentation. Data augmentation is the process of creating additional training examples by modifying existing ones. However, because the types of tasks and data differ, the methods used in computer vision cannot be easily adapted to manipulation. Therefore, we propose a data augmentation method for robotic manipulation. We argue that augmentations should be valid, relevant, and diverse. We use these principles to formalize augmentation as an optimization problem, with the objective function derived from physics and knowledge of the manipulation domain. This method applies rigid body transformations to trajectories of geometric state and action data. We test our method in two scenarios: 1) learning the dynamics of planar pushing of rigid cylinders, and 2) learning a constraint checker for rope manipulation. These two scenarios have different data and label types, yet in both scenarios, training on our augmented data significantly improves performance on downstream tasks. We also show how our augmentation method can be used on real-robot data to enable more data-efficient online learning.
Continual Learning at the Edge: Real-Time Training on Smartphone Devices
May 24, 2021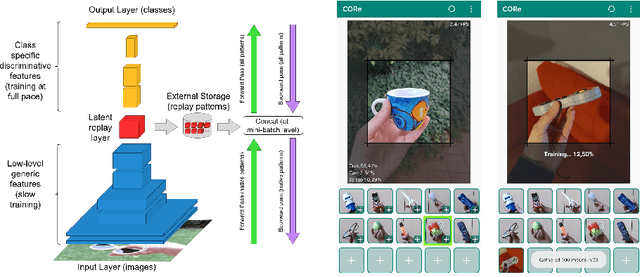
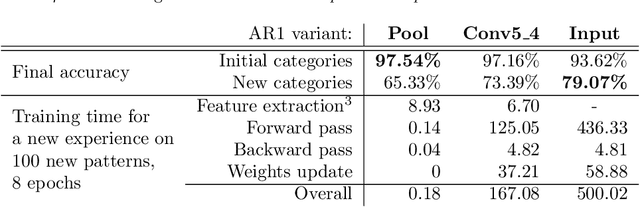
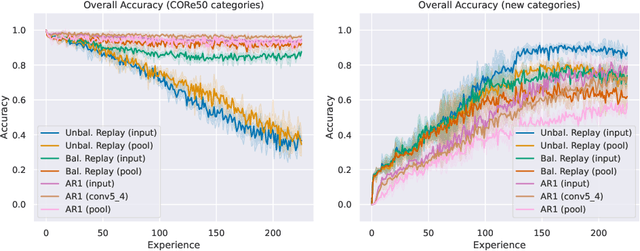
On-device training for personalized learning is a challenging research problem. Being able to quickly adapt deep prediction models at the edge is necessary to better suit personal user needs. However, adaptation on the edge poses some questions on both the efficiency and sustainability of the learning process and on the ability to work under shifting data distributions. Indeed, naively fine-tuning a prediction model only on the newly available data results in catastrophic forgetting, a sudden erasure of previously acquired knowledge. In this paper, we detail the implementation and deployment of a hybrid continual learning strategy (AR1*) on a native Android application for real-time on-device personalization without forgetting. Our benchmark, based on an extension of the CORe50 dataset, shows the efficiency and effectiveness of our solution.
Towards Process-Oriented, Modular, and Versatile Question Generation that Meets Educational Needs
Apr 30, 2022
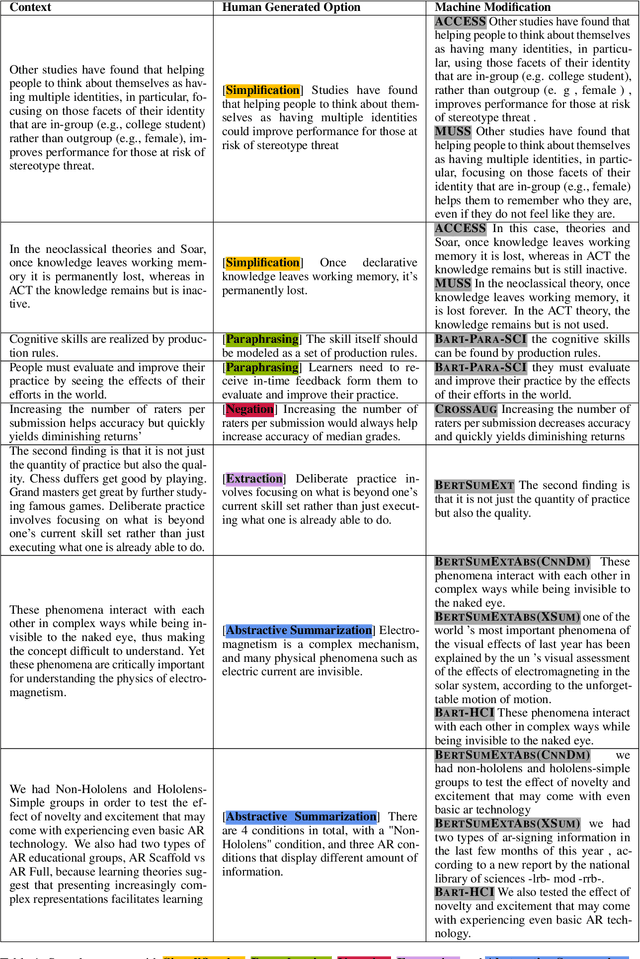
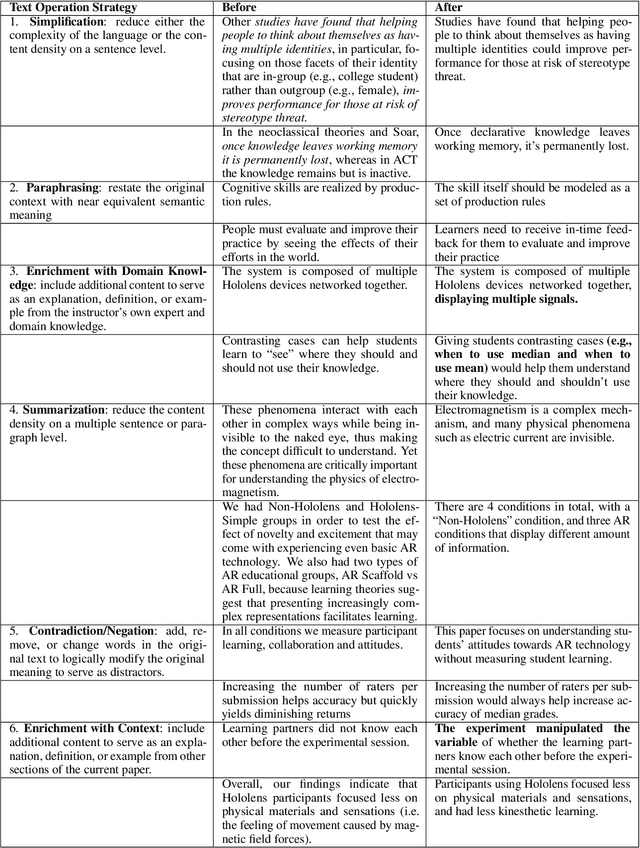
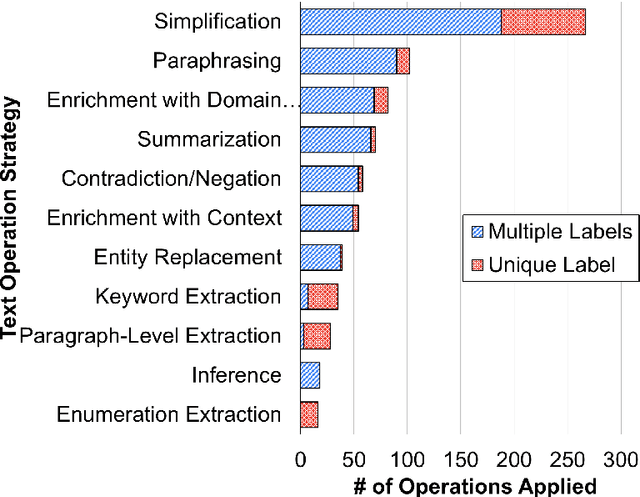
NLP-powered automatic question generation (QG) techniques carry great pedagogical potential of saving educators' time and benefiting student learning. Yet, QG systems have not been widely adopted in classrooms to date. In this work, we aim to pinpoint key impediments and investigate how to improve the usability of automatic QG techniques for educational purposes by understanding how instructors construct questions and identifying touch points to enhance the underlying NLP models. We perform an in-depth need finding study with 11 instructors across 7 different universities, and summarize their thought processes and needs when creating questions. While instructors show great interests in using NLP systems to support question design, none of them has used such tools in practice. They resort to multiple sources of information, ranging from domain knowledge to students' misconceptions, all of which missing from today's QG systems. We argue that building effective human-NLP collaborative QG systems that emphasize instructor control and explainability is imperative for real-world adoption. We call for QG systems to provide process-oriented support, use modular design, and handle diverse sources of input.
Soft Threshold Ternary Networks
Apr 04, 2022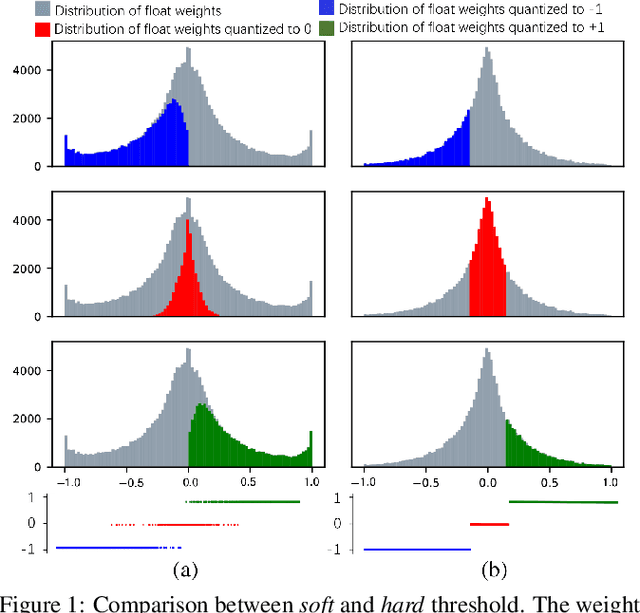

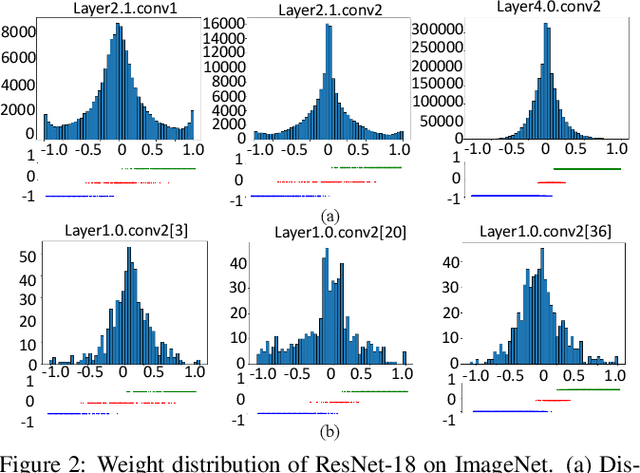

Large neural networks are difficult to deploy on mobile devices because of intensive computation and storage. To alleviate it, we study ternarization, a balance between efficiency and accuracy that quantizes both weights and activations into ternary values. In previous ternarized neural networks, a hard threshold {\Delta} is introduced to determine quantization intervals. Although the selection of {\Delta} greatly affects the training results, previous works estimate {\Delta} via an approximation or treat it as a hyper-parameter, which is suboptimal. In this paper, we present the Soft Threshold Ternary Networks (STTN), which enables the model to automatically determine quantization intervals instead of depending on a hard threshold. Concretely, we replace the original ternary kernel with the addition of two binary kernels at training time, where ternary values are determined by the combination of two corresponding binary values. At inference time, we add up the two binary kernels to obtain a single ternary kernel. Our method dramatically outperforms current state-of-the-arts, lowering the performance gap between full-precision networks and extreme low bit networks. Experiments on ImageNet with ResNet-18 (Top-1 66.2%) achieves new state-of-the-art. Update: In this version, we further fine-tune the experimental hyperparameters and training procedure. The latest STTN shows that ResNet-18 with ternary weights and ternary activations achieves up to 68.2% Top-1 accuracy on ImageNet. Code is available at: github.com/WeixiangXu/STTN.
Single-grasp deformable object discrimination: the effect of gripper morphology, sensing modalities, and action parameters
Apr 13, 2022

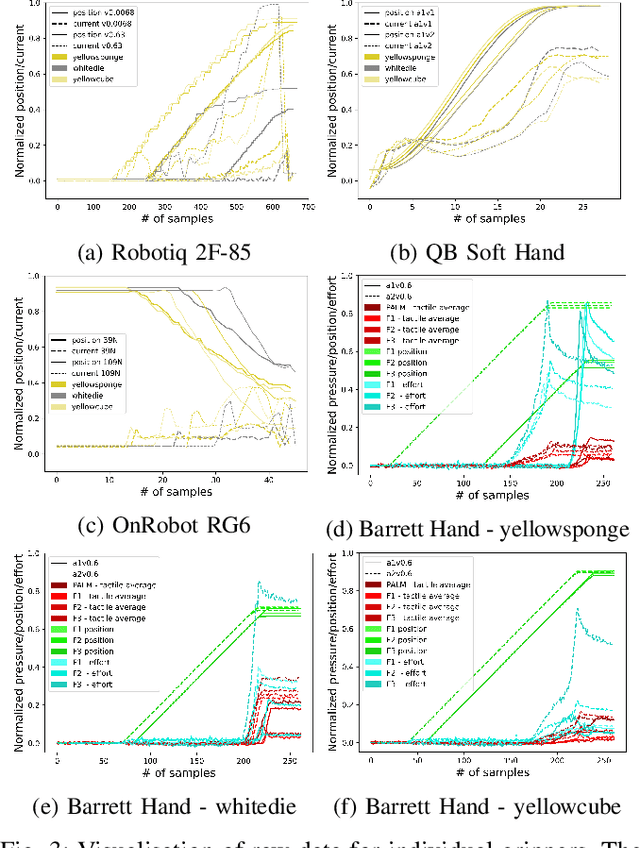
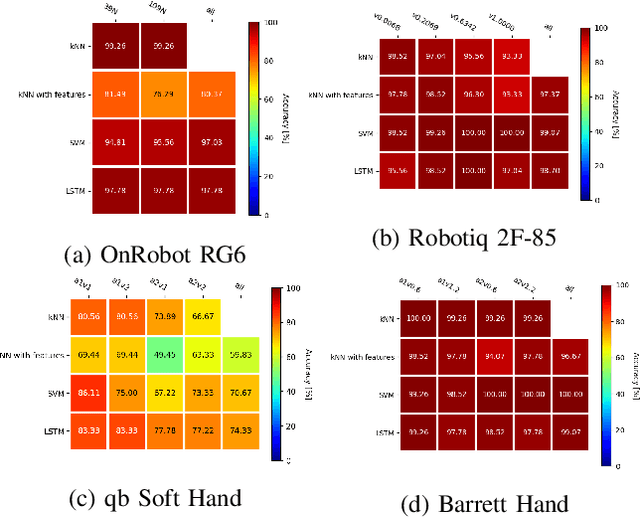
We studied the discrimination of deformable objects by grasping them using 4 different robot hands / grippers: Barrett hand (3 fingers with adjustable configuration, 96 tactile, 8 position, 3 torque sensors), qb SoftHand (5 fingers, 1 motor, position and current feedback), and two industrial type parallel jaw grippers with position and effort feedback (Robotiq 2F-85 and OnRobot RG6). A set of 9 ordinary objects differing in size and stiffness and another highly challenging set of 20 polyurethane foams differing in material properties only was used. We systematically compare the grippers' performance, together with the effects of: (1) type of classifier (k-NN, SVM, LSTM) operating on raw time series or on features, (2) action parameters (grasping configuration and speed of squeezing), (3) contribution of sensory modalities. Classification results are complemented by visualization of the data using PCA. We found: (i) all the grippers but the qb SoftHand could reliably distinguish the ordinary objects set; (ii) Barrett Hand reached around 95% accuracy on the foams; OnRobot RG6 around 75% and Robotiq 2F-85 around 70%; (iii) across all grippers, SVM over features and LSTM on raw time series performed best; (iv) faster compression speeds degrade classification performance; (v) transfer learning between compression speeds worked well for the Barrett Hand only; transfer between grasping configurations is limited; (vi) ablation experiments provided intriguing insights -- sometimes a single sensory channel suffices for discrimination. Overall, the Barrett Hand as a complex and expensive device with rich sensory feedback provided best results, but uncalibrated parallel jaw grippers without tactile sensors can have sufficient performance for single-grasp object discrimination based on position and effort data only. Transfer learning between the different robot hands remains a challenge.
A SSIM Guided cGAN Architecture For Clinically Driven Generative Image Synthesis of Multiplexed Spatial Proteomics Channels
May 20, 2022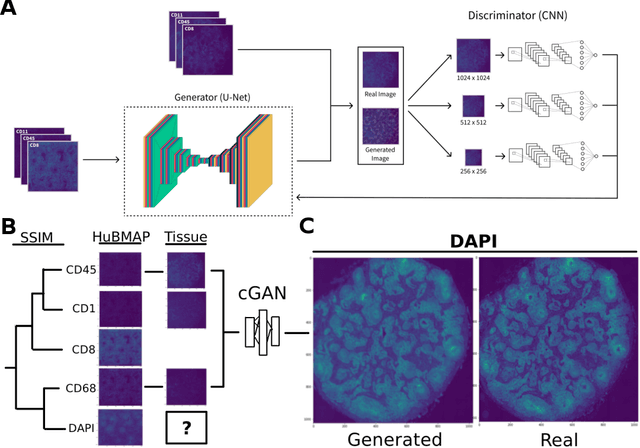


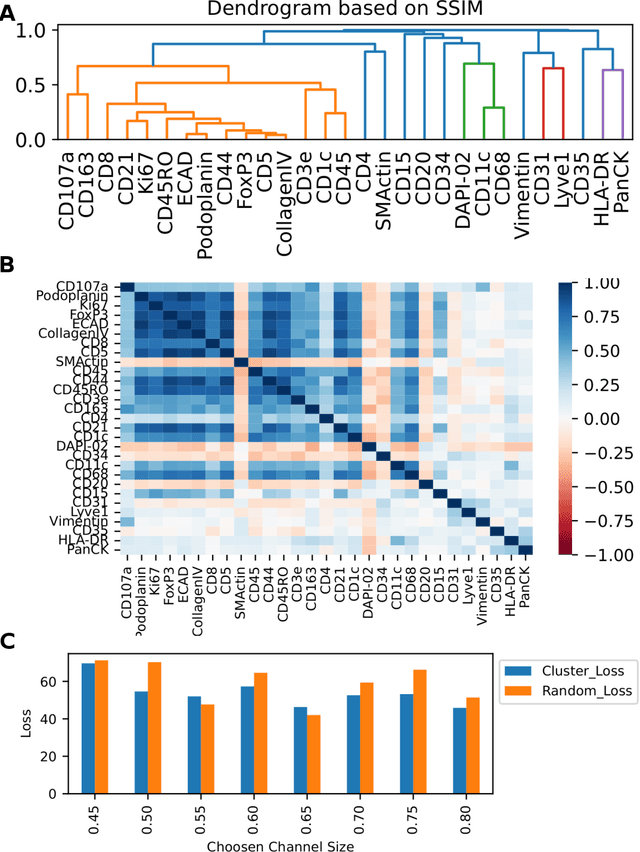
Here we present a structural similarity index measure (SSIM) guided conditional Generative Adversarial Network (cGAN) that generatively performs image-to-image (i2i) synthesis to generate photo-accurate protein channels in multiplexed spatial proteomics images. This approach can be utilized to accurately generate missing spatial proteomics channels that were not included during experimental data collection either at the bench or the clinic. Experimental spatial proteomic data from the Human BioMolecular Atlas Program (HuBMAP) was used to generate spatial representations of missing proteins through a U-Net based image synthesis pipeline. HuBMAP channels were hierarchically clustered by the (SSIM) as a heuristic to obtain the minimal set needed to recapitulate the underlying biology represented by the spatial landscape of proteins. We subsequently prove that our SSIM based architecture allows for scaling of generative image synthesis to slides with up to 100 channels, which is better than current state of the art algorithms which are limited to data with 11 channels. We validate these claims by generating a new experimental spatial proteomics data set from human lung adenocarcinoma tissue sections and show that a model trained on HuBMAP can accurately synthesize channels from our new data set. The ability to recapitulate experimental data from sparsely stained multiplexed histological slides containing spatial proteomic will have tremendous impact on medical diagnostics and drug development, and also raises important questions on the medical ethics of utilizing data produced by generative image synthesis in the clinical setting. The algorithm that we present in this paper will allow researchers and clinicians to save time and costs in proteomics based histological staining while also increasing the amount of data that they can generate through their experiments.
Dynamic ConvNets on Tiny Devices via Nested Sparsity
Mar 07, 2022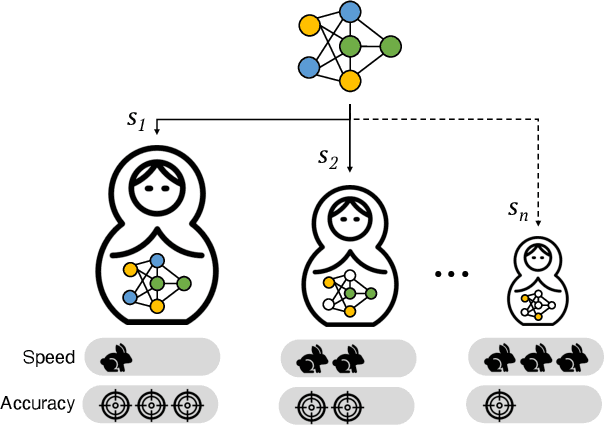
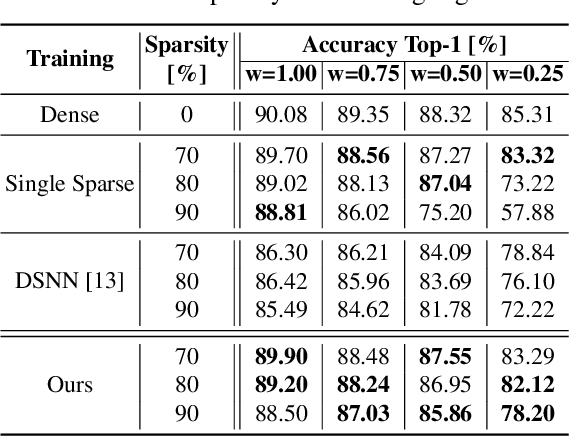
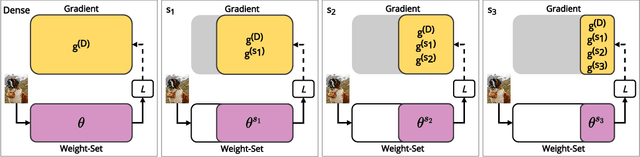
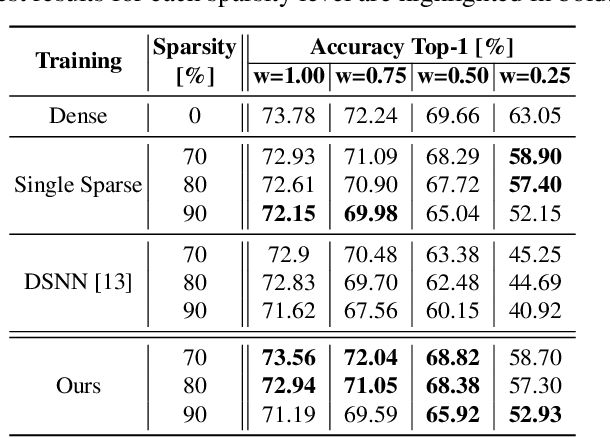
This work introduces a new training and compression pipeline to build Nested Sparse ConvNets, a class of dynamic Convolutional Neural Networks (ConvNets) suited for inference tasks deployed on resource-constrained devices at the edge of the Internet-of-Things. A Nested Sparse ConvNet consists of a single ConvNet architecture containing N sparse sub-networks with nested weights subsets, like a Matryoshka doll, and can trade accuracy for latency at run time, using the model sparsity as a dynamic knob. To attain high accuracy at training time, we propose a gradient masking technique that optimally routes the learning signals across the nested weights subsets. To minimize the storage footprint and efficiently process the obtained models at inference time, we introduce a new sparse matrix compression format with dedicated compute kernels that fruitfully exploit the characteristic of the nested weights subsets. Tested on image classification and object detection tasks on an off-the-shelf ARM-M7 Micro Controller Unit (MCU), Nested Sparse ConvNets outperform variable-latency solutions naively built assembling single sparse models trained as stand-alone instances, achieving (i) comparable accuracy, (ii) remarkable storage savings, and (iii) high performance. Moreover, when compared to state-of-the-art dynamic strategies, like dynamic pruning and layer width scaling, Nested Sparse ConvNets turn out to be Pareto optimal in the accuracy vs. latency space.
Real-Time Topology Optimization in 3D via Deep Transfer Learning
Feb 11, 2021
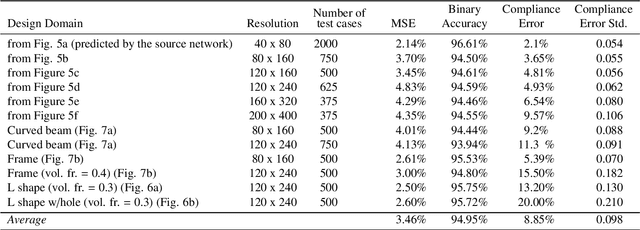
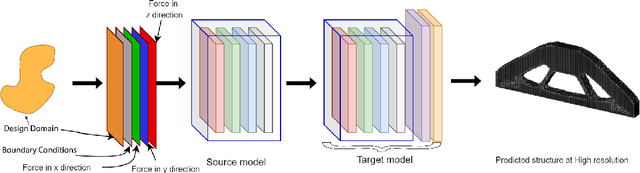
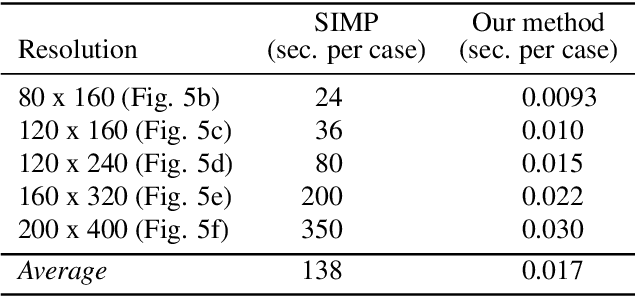
The published literature on topology optimization has exploded over the last two decades to include methods that use shape and topological derivatives or evolutionary algorithms formulated on various geometric representations and parametrizations. One of the key challenges of all these methods is the massive computational cost associated with 3D topology optimization problems. We introduce a transfer learning method based on a convolutional neural network that (1) can handle high-resolution 3D design domains of various shapes and topologies; (2) supports real-time design space explorations as the domain and boundary conditions change; (3) requires a much smaller set of high-resolution examples for the improvement of learning in a new task compared to traditional deep learning networks; (4) is multiple orders of magnitude more efficient than the established gradient-based methods, such as SIMP. We provide numerous 2D and 3D examples to showcase the effectiveness and accuracy of our proposed approach, including for design domains that are unseen to our source network, as well as the generalization capabilities of the transfer learning-based approach. Our experiments achieved an average binary accuracy of around 95% at real-time prediction rates. These properties, in turn, suggest that the proposed transfer-learning method may serve as the first practical underlying framework for real-time 3D design exploration based on topology optimization
Need is All You Need: Homeostatic Neural Networks Adapt to Concept Shift
May 17, 2022
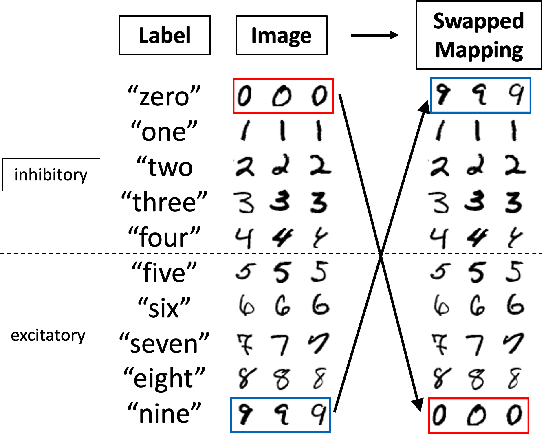

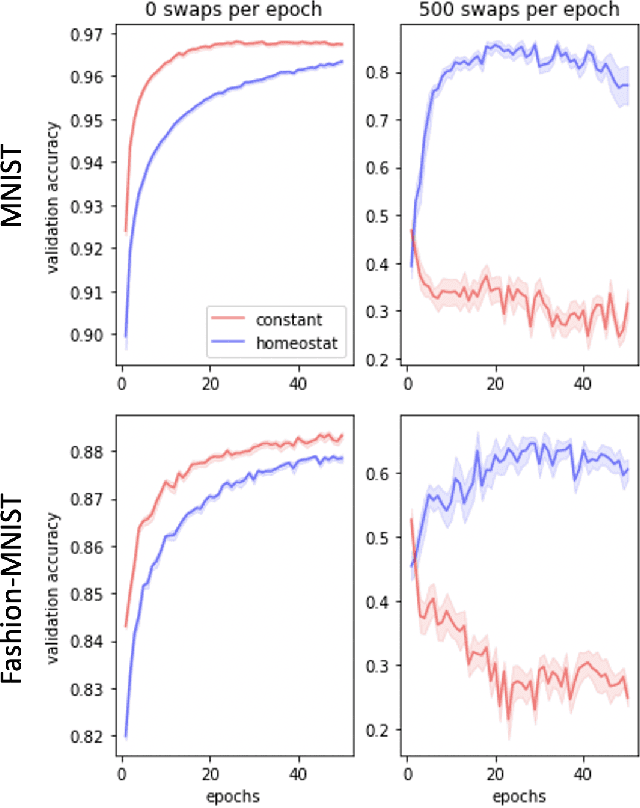
In living organisms, homeostasis is the natural regulation of internal states aimed at maintaining conditions compatible with life. Typical artificial systems are not equipped with comparable regulatory features. Here, we introduce an artificial neural network that incorporates homeostatic features. Its own computing substrate is placed in a needful and vulnerable relation to the very objects over which it computes. For example, artificial neurons performing classification of MNIST digits or Fashion-MNIST articles of clothing may receive excitatory or inhibitory effects, which alter their own learning rate as a direct result of perceiving and classifying the digits. In this scenario, accurate recognition is desirable to the agent itself because it guides decisions to regulate its vulnerable internal states and functionality. Counterintuitively, the addition of vulnerability to a learner does not necessarily impair its performance. On the contrary, self-regulation in response to vulnerability confers benefits under certain conditions. We show that homeostatic design confers increased adaptability under concept shift, in which the relationships between labels and data change over time, and that the greatest advantages are obtained under the highest rates of shift. This necessitates the rapid un-learning of past associations and the re-learning of new ones. We also demonstrate the superior abilities of homeostatic learners in environments with dynamically changing rates of concept shift. Our homeostatic design exposes the artificial neural network's thinking machinery to the consequences of its own "thoughts", illustrating the advantage of putting one's own "skin in the game" to improve fluid intelligence.
Deep Learning-based Framework for Automatic Cranial Defect Reconstruction and Implant Modeling
Apr 13, 2022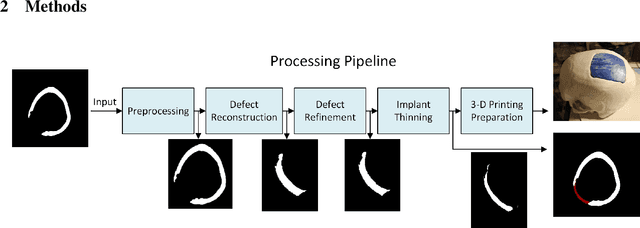
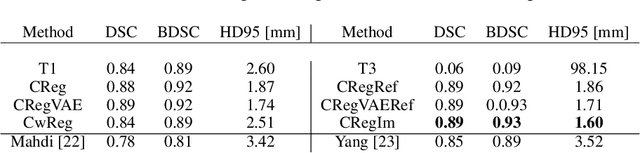
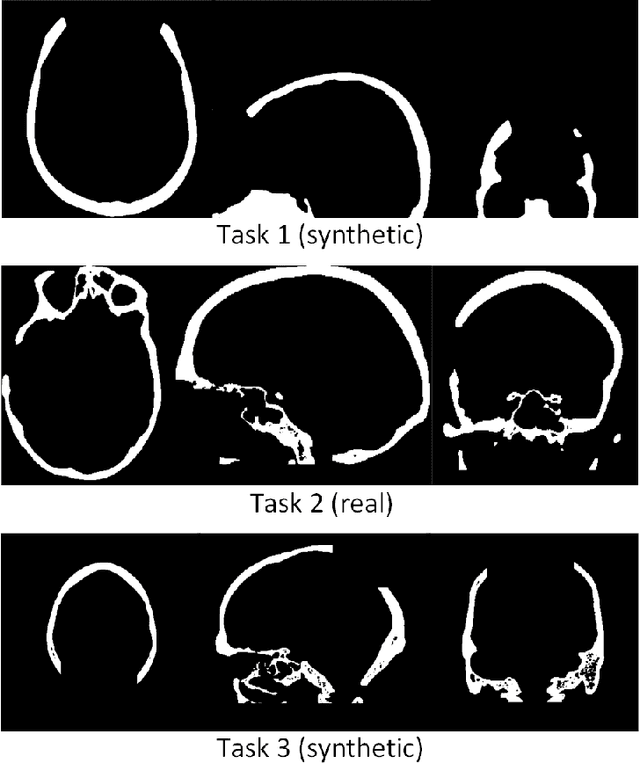

The goal of this work is to propose a robust, fast, and fully automatic method for personalized cranial defect reconstruction and implant modeling. We propose a two-step deep learning-based method using a modified U-Net architecture to perform the defect reconstruction, and a dedicated iterative procedure to improve the implant geometry, followed by automatic generation of models ready for 3-D printing. We propose a cross-case augmentation based on imperfect image registration combining cases from different datasets. We perform ablation studies regarding different augmentation strategies and compare them to other state-of-the-art methods. We evaluate the method on three datasets introduced during the AutoImplant 2021 challenge, organized jointly with the MICCAI conference. We perform the quantitative evaluation using the Dice and boundary Dice coefficients, and the Hausdorff distance. The average Dice coefficient, boundary Dice coefficient, and the 95th percentile of Hausdorff distance are 0.91, 0.94, and 1.53 mm respectively. We perform an additional qualitative evaluation by 3-D printing and visualization in mixed reality to confirm the implant's usefulness. We propose a complete pipeline that enables one to create the cranial implant model ready for 3-D printing. The described method is a greatly extended version of the method that scored 1st place in all AutoImplant 2021 challenge tasks. We freely release the source code, that together with the open datasets, makes the results fully reproducible. The automatic reconstruction of cranial defects may enable manufacturing personalized implants in a significantly shorter time, possibly allowing one to perform the 3-D printing process directly during a given intervention. Moreover, we show the usability of the defect reconstruction in mixed reality that may further reduce the surgery time.