 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection
Mar 31, 2022
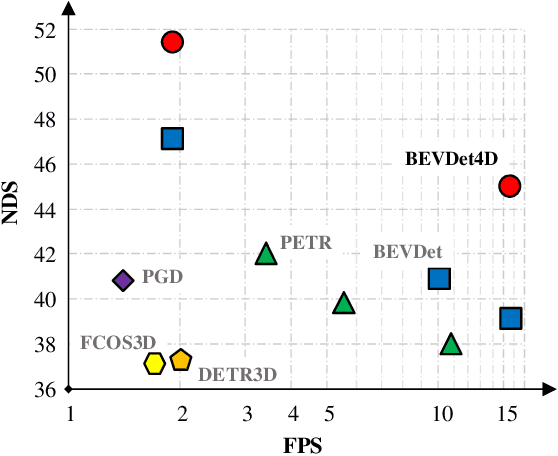
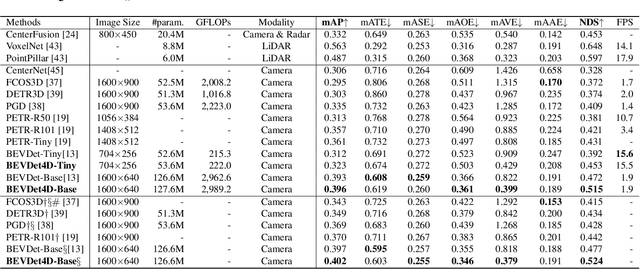
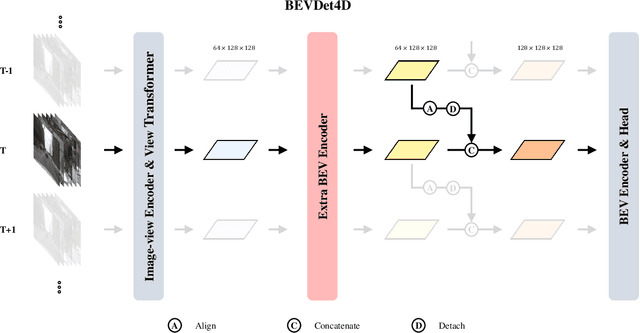
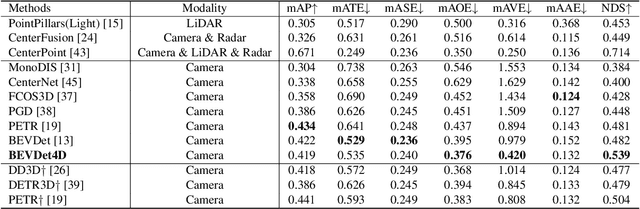
Single frame data contains finite information which limits the performance of the existing vision-based multi-camera 3D object detection paradigms. For fundamentally pushing the performance boundary in this area, BEVDet4D is proposed to lift the scalable BEVDet paradigm from the spatial-only 3D space to the spatial-temporal 4D space. We upgrade the framework with a few modifications just for fusing the feature from the previous frame with the corresponding one in the current frame. In this way, with negligible extra computing budget, we enable the algorithm to access the temporal cues by querying and comparing the two candidate features. Beyond this, we also simplify the velocity learning task by removing the factors of ego-motion and time, which equips BEVDet4D with robust generalization performance and reduces the velocity error by 52.8%. This makes vision-based methods, for the first time, become comparable with those relied on LiDAR or radar in this aspect. On challenge benchmark nuScenes, we report a new record of 51.5% NDS with the high-performance configuration dubbed BEVDet4D-Base, which surpasses the previous leading method BEVDet by +4.3% NDS.
Physical Layer Security for 6G Systems why it is needed and how to make it happen
May 03, 2022Sixth generations (6G) systems will be required to meet diverse constraints in an integrated ground-air-space global network. In particular, meeting overly aggressive latency constraints, operating in massive connectivity regimes, with low energy footprint and low computational effort, while providing explicit security guarantees, can be challenging. In this setting, quality of security (QoSec) is envisioned as a flexible security framework for future networks with highly diverse non-functional requirements. Mirroring the differentiated services (DiffServ) networking paradigm, different security levels could be conceptualized, moving away from static security controls, captured currently in zero-trust security architectures. In parallel, the integration of communications and sensing, along with embedded (on-device) AI, can provide the foundations for building autonomous and adaptive security controls, orchestrated by a vertical security plane in coordination with a vertical semantic plane. It is in this framework, that we envision the incorporation of physical layer security (PLS) schemes in 6G security protocols, introducing security controls at all layers, for the first time.
Deep Transformer Networks for Time Series Classification: The NPP Safety Case
Apr 09, 2021

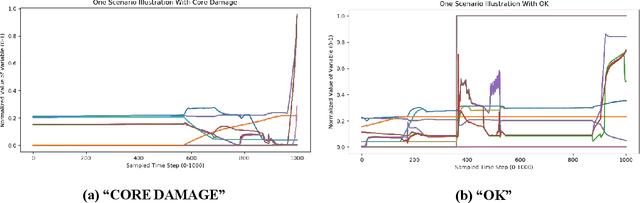
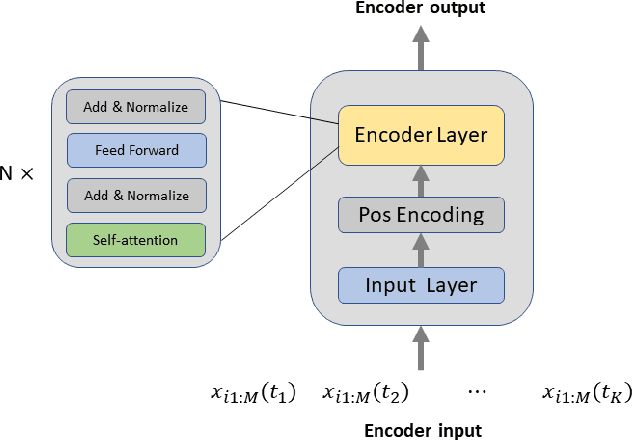
A challenging part of dynamic probabilistic risk assessment for nuclear power plants is the need for large amounts of temporal simulations given various initiating events and branching conditions from which representative feature extraction becomes complicated for subsequent applications. Artificial Intelligence techniques have been shown to be powerful tools in time-dependent sequential data processing to automatically extract and yield complex features from large data. An advanced temporal neural network referred to as the Transformer is used within a supervised learning fashion to model the time-dependent NPP simulation data and to infer whether a given sequence of events leads to core damage or not. The training and testing datasets for the Transformer are obtained by running 10,000 RELAP5-3D NPP blackout simulations with the list of variables obtained from the RAVEN software. Each simulation is classified as "OK" or "CORE DAMAGE" based on the consequence. The results show that the Transformer can learn the characteristics of the sequential data and yield promising performance with approximately 99% classification accuracy on the testing dataset.
BILP-Q: Quantum Coalition Structure Generation
Apr 28, 2022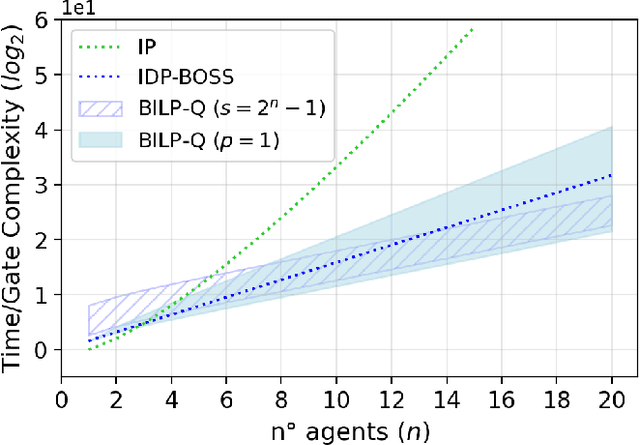
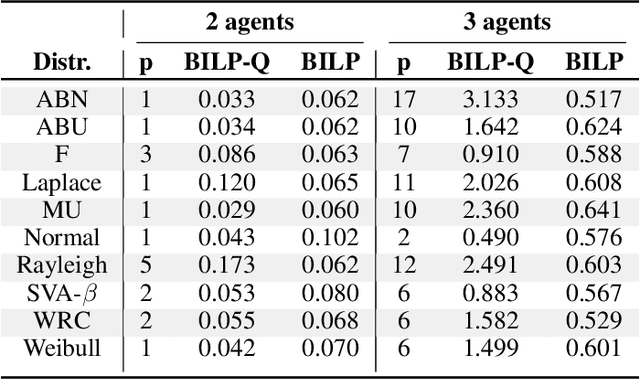
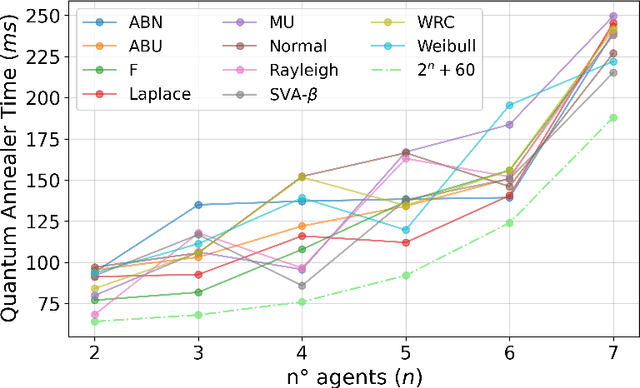
Quantum AI is an emerging field that uses quantum computing to solve typical complex problems in AI. In this work, we propose BILP-Q, the first-ever general quantum approach for solving the Coalition Structure Generation problem (CSGP), which is notably NP-hard. In particular, we reformulate the CSGP in terms of a Quadratic Binary Combinatorial Optimization (QUBO) problem to leverage existing quantum algorithms (e.g., QAOA) to obtain the best coalition structure. Thus, we perform a comparative analysis in terms of time complexity between the proposed quantum approach and the most popular classical baselines. Furthermore, we consider standard benchmark distributions for coalition values to test the BILP-Q on small-scale experiments using the IBM Qiskit environment. Finally, since QUBO problems can be solved operating with quantum annealing, we run BILP-Q on medium-size problems using a real quantum annealer (D-Wave).
Exploring the Role of Task Transferability in Large-Scale Multi-Task Learning
Apr 23, 2022
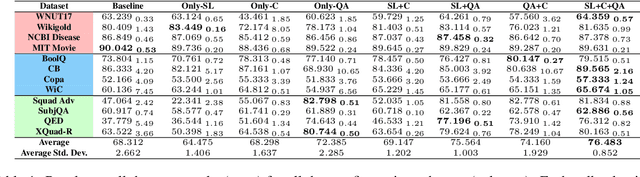

Recent work has found that multi-task training with a large number of diverse tasks can uniformly improve downstream performance on unseen target tasks. In contrast, literature on task transferability has established that the choice of intermediate tasks can heavily affect downstream task performance. In this work, we aim to disentangle the effect of scale and relatedness of tasks in multi-task representation learning. We find that, on average, increasing the scale of multi-task learning, in terms of the number of tasks, indeed results in better learned representations than smaller multi-task setups. However, if the target tasks are known ahead of time, then training on a smaller set of related tasks is competitive to the large-scale multi-task training at a reduced computational cost.
Evidential Temporal-aware Graph-based Social Event Detection via Dempster-Shafer Theory
May 24, 2022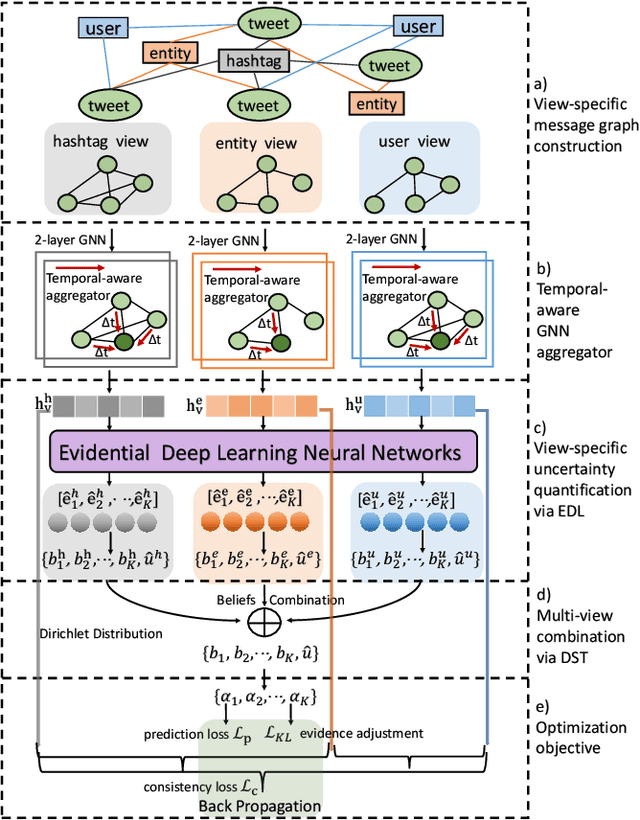
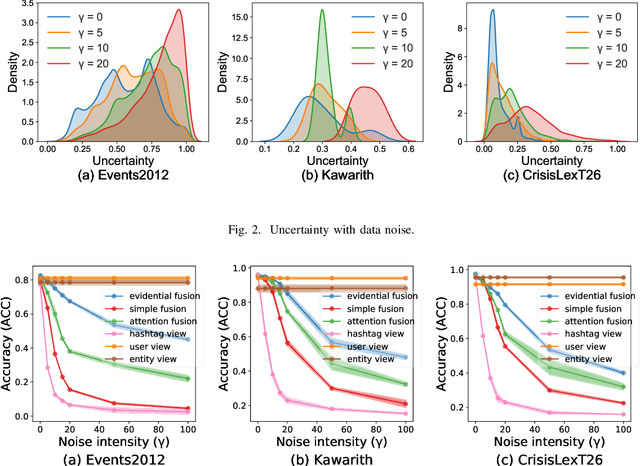
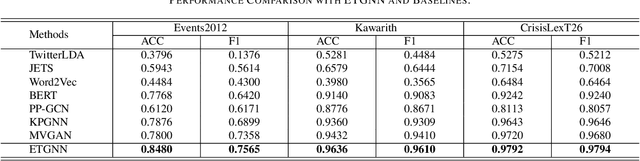
The rising popularity of online social network services has attracted lots of research on mining social media data, especially on mining social events. Social event detection, due to its wide applications, has now become a trivial task. State-of-the-art approaches exploiting Graph Neural Networks (GNNs) usually follow a two-step strategy: 1) constructing text graphs based on various views (\textit{co-user}, \textit{co-entities} and \textit{co-hashtags}); and 2) learning a unified text representation by a specific GNN model. Generally, the results heavily rely on the quality of the constructed graphs and the specific message passing scheme. However, existing methods have deficiencies in both aspects: 1) They fail to recognize the noisy information induced by unreliable views. 2) Temporal information which works as a vital indicator of events is neglected in most works. To this end, we propose ETGNN, a novel Evidential Temporal-aware Graph Neural Network. Specifically, we construct view-specific graphs whose nodes are the texts and edges are determined by several types of shared elements respectively. To incorporate temporal information into the message passing scheme, we introduce a novel temporal-aware aggregator which assigns weights to neighbours according to an adaptive time exponential decay formula. Considering the view-specific uncertainty, the representations of all views are converted into mass functions through evidential deep learning (EDL) neural networks, and further combined via Dempster-Shafer theory (DST) to make the final detection. Experimental results on three real-world datasets demonstrate the effectiveness of ETGNN in accuracy, reliability and robustness in social event detection.
Transformer-based out-of-distribution detection for clinically safe segmentation
May 21, 2022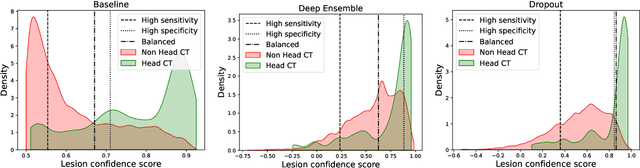
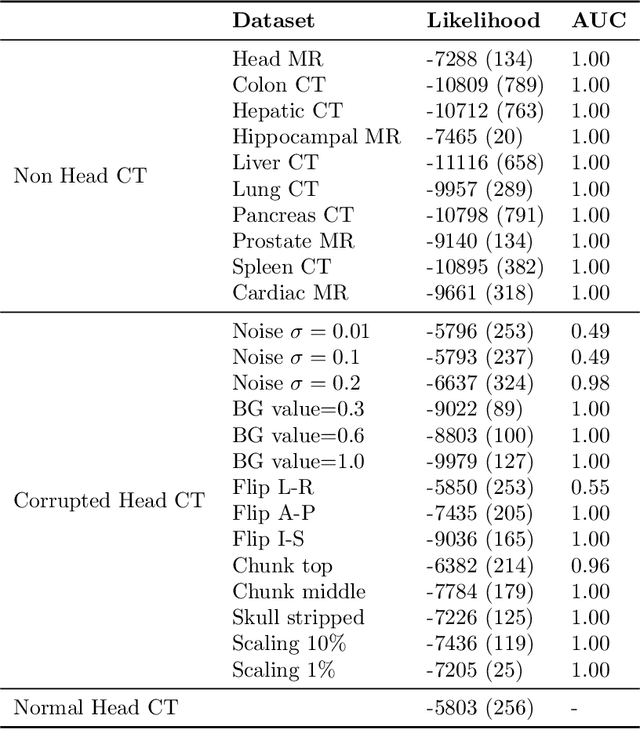
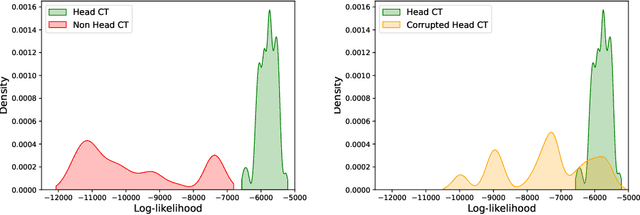
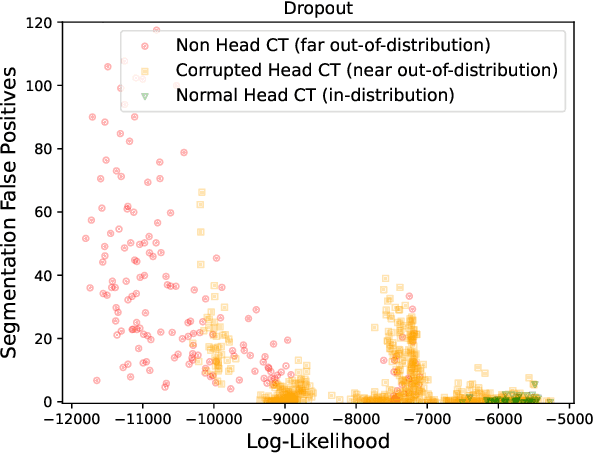
In a clinical setting it is essential that deployed image processing systems are robust to the full range of inputs they might encounter and, in particular, do not make confidently wrong predictions. The most popular approach to safe processing is to train networks that can provide a measure of their uncertainty, but these tend to fail for inputs that are far outside the training data distribution. Recently, generative modelling approaches have been proposed as an alternative; these can quantify the likelihood of a data sample explicitly, filtering out any out-of-distribution (OOD) samples before further processing is performed. In this work, we focus on image segmentation and evaluate several approaches to network uncertainty in the far-OOD and near-OOD cases for the task of segmenting haemorrhages in head CTs. We find all of these approaches are unsuitable for safe segmentation as they provide confidently wrong predictions when operating OOD. We propose performing full 3D OOD detection using a VQ-GAN to provide a compressed latent representation of the image and a transformer to estimate the data likelihood. Our approach successfully identifies images in both the far- and near-OOD cases. We find a strong relationship between image likelihood and the quality of a model's segmentation, making this approach viable for filtering images unsuitable for segmentation. To our knowledge, this is the first time transformers have been applied to perform OOD detection on 3D image data.
Frequency Hopping Joint Radar-Communications with Hybrid Sub-pulse Frequency and Duration
Apr 26, 2022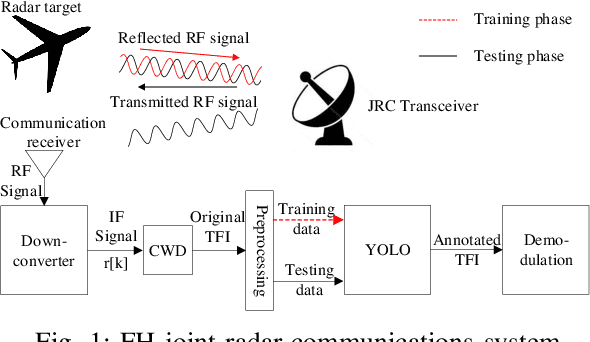
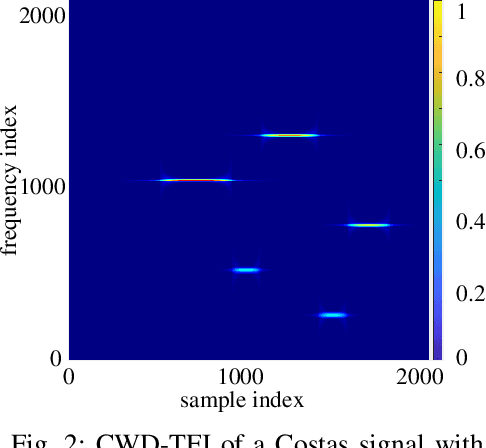
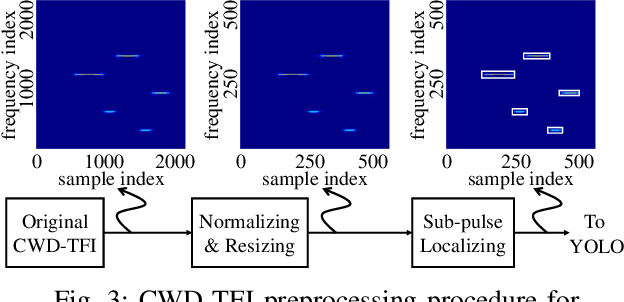
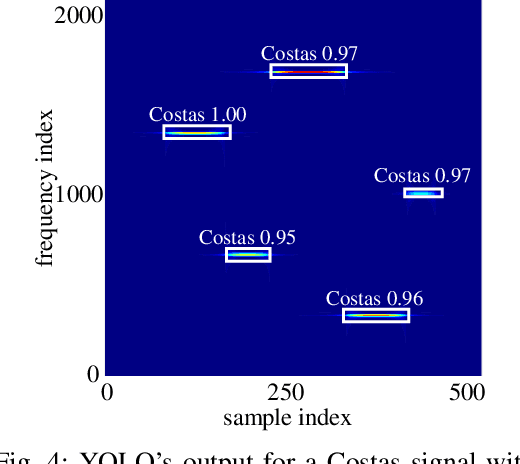
Frequency-hopping (FH) joint radar-communications (JRC) can offer excellent security for integrated sensing and communication systems. However, existing JRC schemes mainly embed information using only the sub-pulse frequencies and hence the data rate is limited. In this paper, we propose to use both sub-pulse frequencies and durations for information modulation, leading to higher communication data rates. For information demodulation, we propose a novel scheme by using the time-frequency analysis (TFA) technique and a "you only look once" (YOLO)-based detection system. As such, our system does not require channel estimation, simplifying the transmission signal frame design. Simulation results demonstrate the effectiveness of our scheme, and show that it is robust against the Doppler shift and timing offset between the transceiver and the communication receiver.
LRH-Net: A Multi-Level Knowledge Distillation Approach for Low-Resource Heart Network
Apr 11, 2022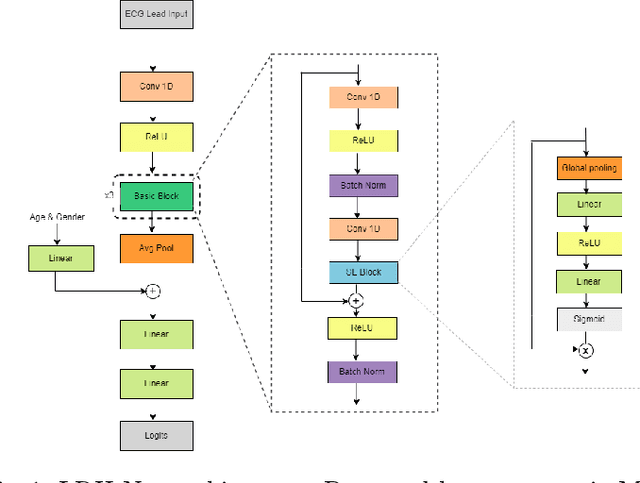
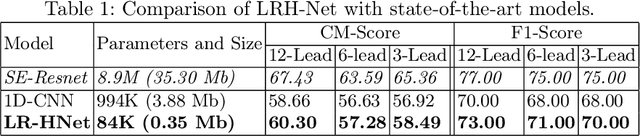
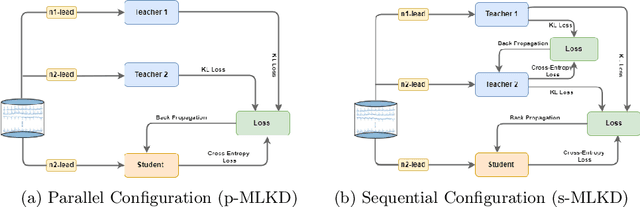
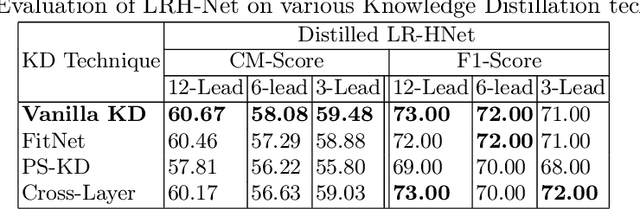
An electrocardiogram (ECG) monitors the electrical activity generated by the heart and is used to detect fatal cardiovascular diseases (CVDs). Conventionally, to capture the precise electrical activity, clinical experts use multiple-lead ECGs (typically 12 leads). But in recent times, large-size deep learning models have been used to detect these diseases. However, such models require heavy compute resources like huge memory and long inference time. To alleviate these shortcomings, we propose a low-parameter model, named Low Resource Heart-Network (LRH-Net), which uses fewer leads to detect ECG anomalies in a resource-constrained environment. A multi-level knowledge distillation process is used on top of that to get better generalization performance on our proposed model. The multi-level knowledge distillation process distills the knowledge to LRH-Net trained on a reduced number of leads from higher parameter (teacher) models trained on multiple leads to reduce the performance gap. The proposed model is evaluated on the PhysioNet-2020 challenge dataset with constrained input. The parameters of the LRH-Net are 106x less than our teacher model for detecting CVDs. The performance of the LRH-Net was scaled up to 3.2% and the inference time scaled down by 75% compared to the teacher model. In contrast to the compute- and parameter-intensive deep learning techniques, the proposed methodology uses a subset of ECG leads using the low resource LRH-Net, making it eminently suitable for deployment on edge devices.
Forward Signal Propagation Learning
Apr 04, 2022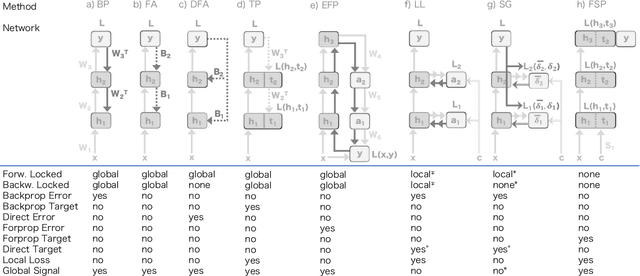
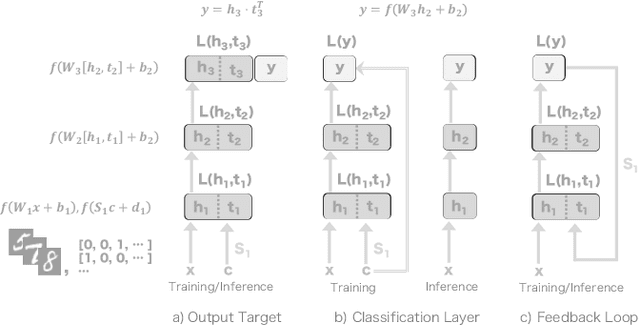
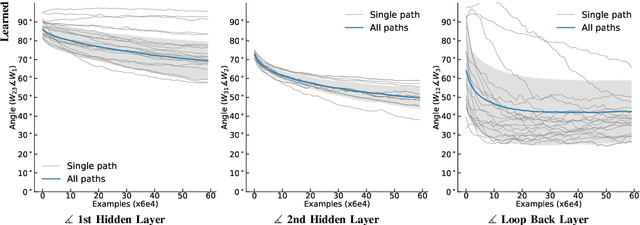
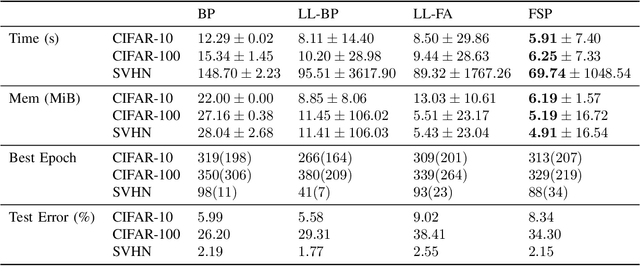
We propose a new learning algorithm for propagating a learning signal and updating neural network parameters via a forward pass, as an alternative to backpropagation. In forward signal propagation learning (sigprop), there is only the forward path for learning and inference, so there are no additional structural or computational constraints on learning, such as feedback connectivity, weight transport, or a backward pass, which exist under backpropagation. Sigprop enables global supervised learning with only a forward path. This is ideal for parallel training of layers or modules. In biology, this explains how neurons without feedback connections can still receive a global learning signal. In hardware, this provides an approach for global supervised learning without backward connectivity. Sigprop by design has better compatibility with models of learning in the brain and in hardware than backpropagation and alternative approaches to relaxing learning constraints. We also demonstrate that sigprop is more efficient in time and memory than they are. To further explain the behavior of sigprop, we provide evidence that sigprop provides useful learning signals in context to backpropagation. To further support relevance to biological and hardware learning, we use sigprop to train continuous time neural networks with Hebbian updates and train spiking neural networks without surrogate functions.