 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Batch Artifact Scanning Protocol: A new method using computed tomography (CT) to rapidly create three-dimensional models of objects from large collections en masse
May 05, 2022

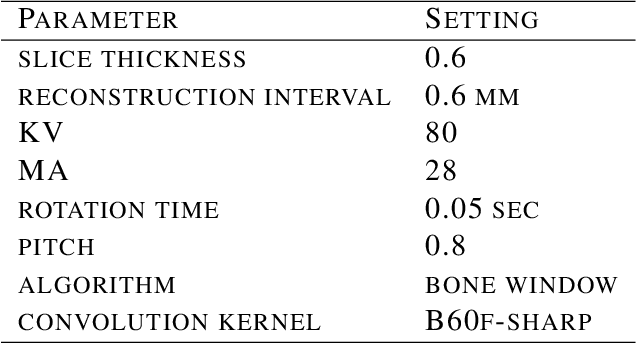

Within anthropology, the use of three-dimensional (3D) imaging has become increasingly standard and widespread since it broadens the available avenues for addressing a wide range of key issues. The ease with which 3D models can be shared has had major impacts for research, cultural heritage, education, science communication, and public engagement, as well as contributing to the preservation of the physical specimens and archiving collections in widely accessible data bases. Current scanning protocols have the ability to create the required research quality 3D models; however, they tend to be time and labor intensive and not practical when working with large collections. Here we describe a streamlined, Batch Artifact Scanning Protocol we have developed to rapidly create 3D models using a medical CT scanner. Though this method can be used on a variety of material types, we use a large collection of experimentally broken ungulate limb bones. Using the Batch Artifact Scanning Protocol, we were able to efficiently create 3D models of 2,474 bone fragments at a rate of less than $3$ minutes per specimen, as opposed to an average of 50 minutes per specimen using structured light scanning.
EXPERT: Public Benchmarks for Dynamic Heterogeneous Academic Graphs
Apr 14, 2022
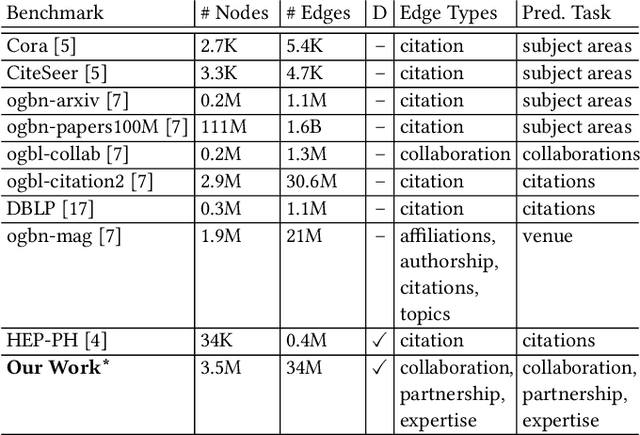

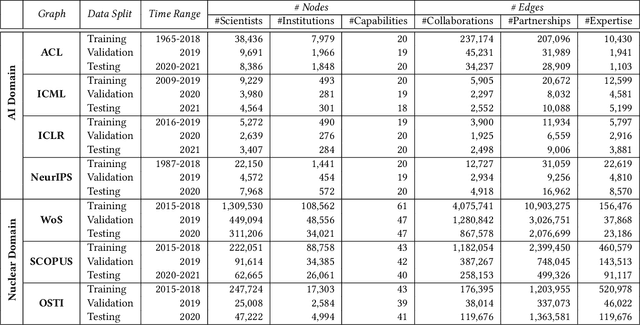
Machine learning models that learn from dynamic graphs face nontrivial challenges in learning and inference as both nodes and edges change over time. The existing large-scale graph benchmark datasets that are widely used by the community primarily focus on homogeneous node and edge attributes and are static. In this work, we present a variety of large scale, dynamic heterogeneous academic graphs to test the effectiveness of models developed for multi-step graph forecasting tasks. Our novel datasets cover both context and content information extracted from scientific publications across two communities: Artificial Intelligence (AI) and Nuclear Nonproliferation (NN). In addition, we propose a systematic approach to improve the existing evaluation procedures used in the graph forecasting models.
Algorithmic support of a personal virtual assistant for automating the processing of client requests
Mar 27, 2022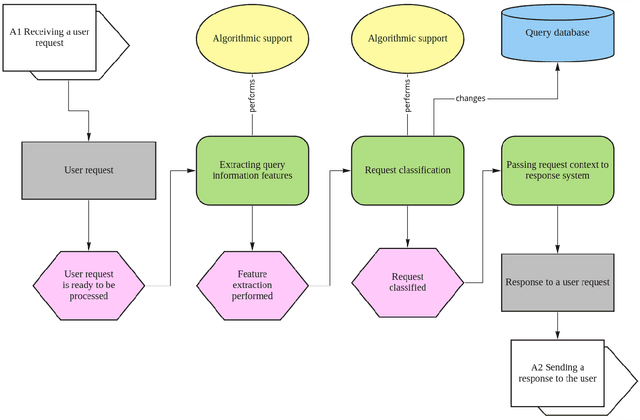
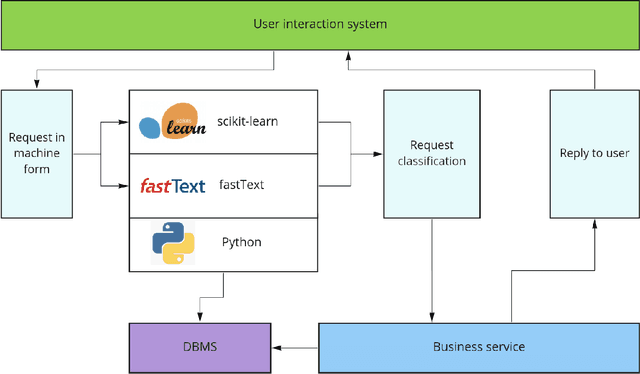
This article describes creating algorithmic support for the functioning of a personal virtual assistant, which allows automating the processing of customer requests. The study aims to reduce errors and processing time for a client request in business systems - text chats or voice channels using a text transcription system. The results of the development of algorithmic support and an assessment of the quality of work on synthetic data presented.
Adaptive Gaussian Fuzzy Classifier for Real-Time Emotion Recognition in Computer Games
Mar 05, 2021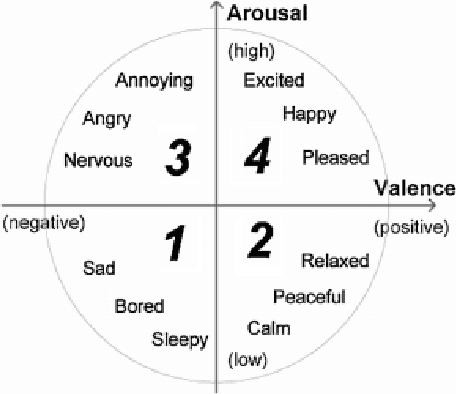
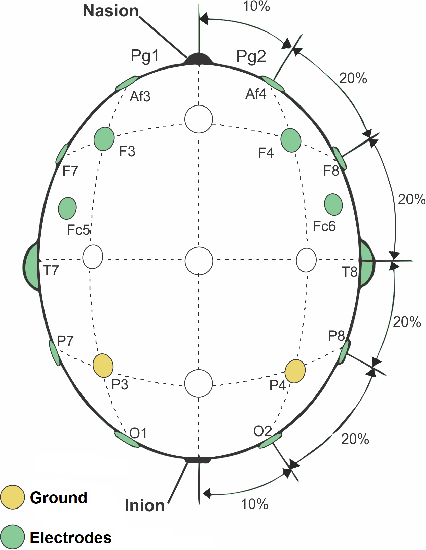
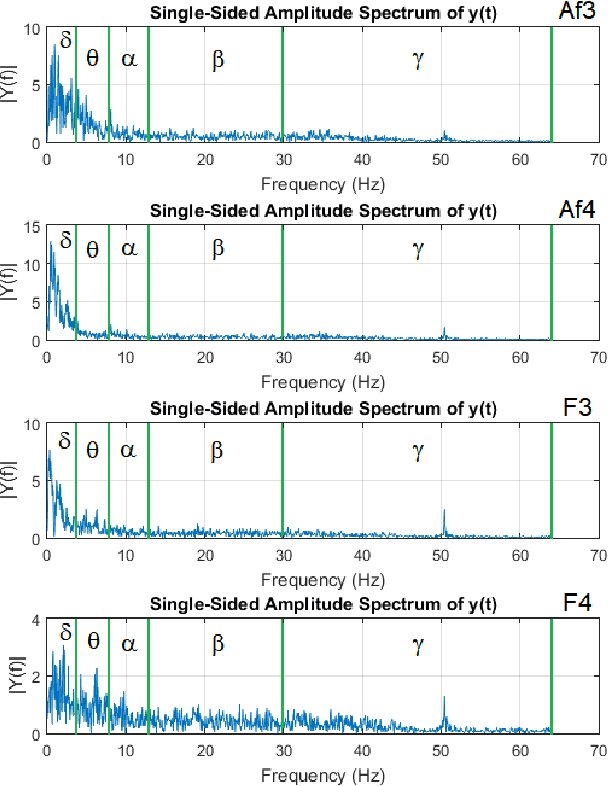
Human emotion recognition has become a need for more realistic and interactive machines and computer systems. The greatest challenge is the availability of high-performance algorithms to effectively manage individual differences and nonstationarities in physiological data streams, i.e., algorithms that self-customize to a user with no subject-specific calibration data. We describe an evolving Gaussian Fuzzy Classifier (eGFC), which is supported by an online semi-supervised learning algorithm to recognize emotion patterns from electroencephalogram (EEG) data streams. We extract features from the Fourier spectrum of EEG data. The data are provided by 28 individuals playing the games 'Train Sim World', 'Unravel', 'Slender The Arrival', and 'Goat Simulator' - a public dataset. Different emotions prevail, namely, boredom, calmness, horror and joy. We analyze the effect of individual electrodes, time window lengths, and frequency bands on the accuracy of user-independent eGFCs. We conclude that both brain hemispheres may assist classification, especially electrodes on the frontal (Af3-Af4), occipital (O1-O2), and temporal (T7-T8) areas. We observe that patterns may be eventually found in any frequency band; however, the Alpha (8-13Hz), Delta (1-4Hz), and Theta (4-8Hz) bands, in this order, are the highest correlated with emotion classes. eGFC has shown to be effective for real-time learning of EEG data. It reaches a 72.2% accuracy using a variable rule base, 10-second windows, and 1.8ms/sample processing time in a highly-stochastic time-varying 4-class classification problem.
Generative Retrieval for Long Sequences
Apr 27, 2022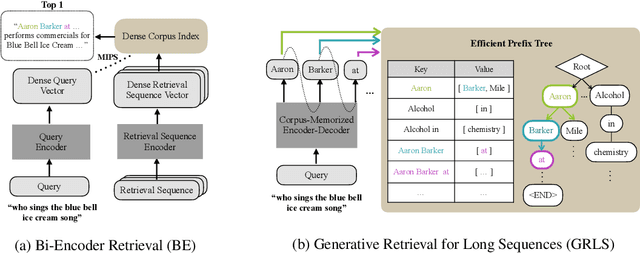
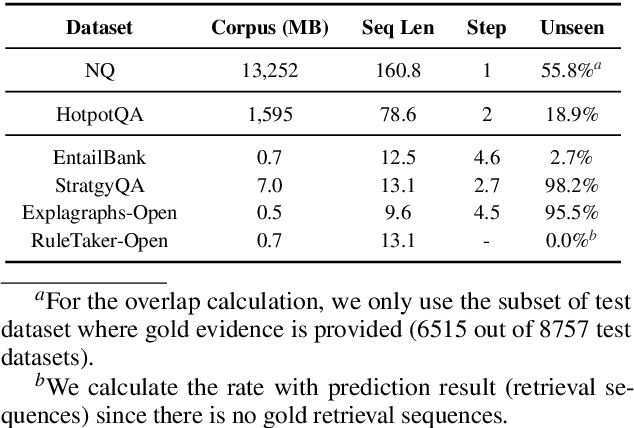
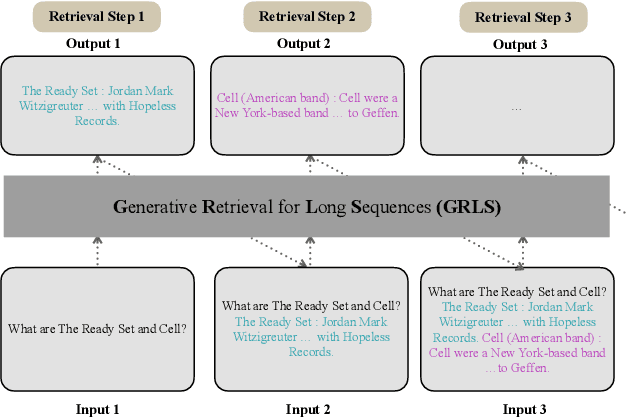
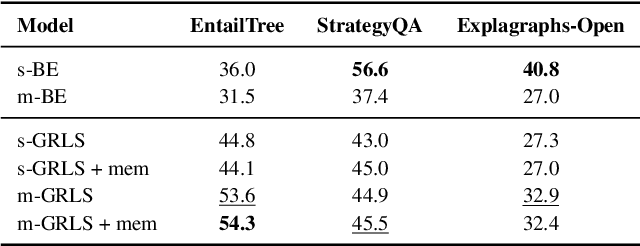
Text retrieval is often formulated as mapping the query and the target items (e.g., passages) to the same vector space and finding the item whose embedding is closest to that of the query. In this paper, we explore a generative approach as an alternative, where we use an encoder-decoder model to memorize the target corpus in a generative manner and then finetune it on query-to-passage generation. As GENRE(Cao et al., 2021) has shown that entities can be retrieved in a generative way, our work can be considered as its generalization to longer text. We show that it consistently achieves comparable performance to traditional bi-encoder retrieval on diverse datasets and is especially strong at retrieving highly structured items, such as reasoning chains and graph relations, while demonstrating superior GPU memory and time complexity. We also conjecture that generative retrieval is complementary to traditional retrieval, as we find that an ensemble of both outperforms homogeneous ensembles.
Collaborative Target Search with a Visual Drone Swarm: An Adaptive Curriculum Embedded Multi-stage Reinforcement Learning Approach
Apr 27, 2022

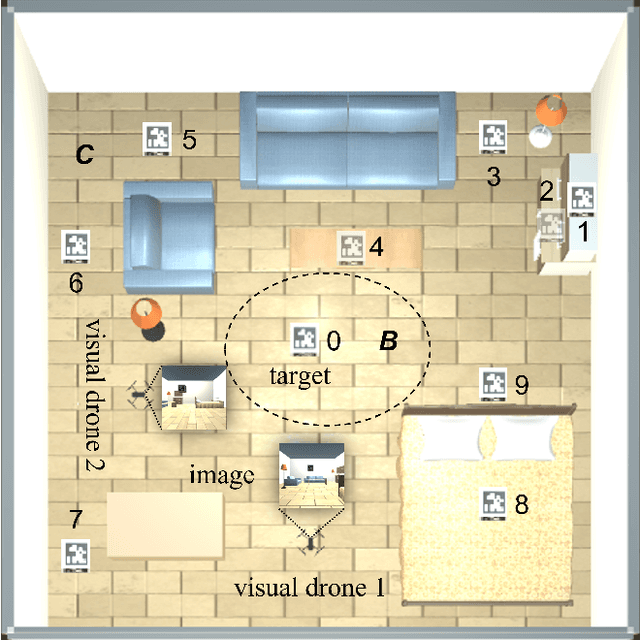
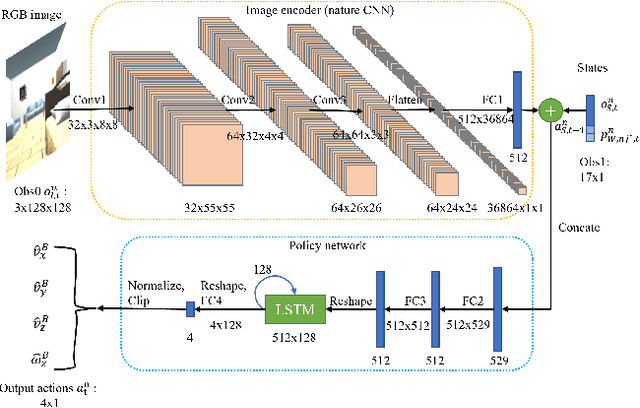
Equipping drones with target search capabilities is desirable for applications in disaster management scenarios and smart warehouse delivery systems. Instead of deploying a single drone, an intelligent drone swarm that can collaborate with one another in maneuvering among obstacles will be more effective in accomplishing the target search in a shorter amount of time. In this work, we propose a data-efficient reinforcement learning-based approach, Adaptive Curriculum Embedded Multi-Stage Learning (ACEMSL), to address the challenges of carrying out a collaborative target search with a visual drone swarm, namely the 3D sparse reward space exploration and the collaborative behavior requirement. Specifically, we develop an adaptive embedded curriculum, where the task difficulty level can be adaptively adjusted according to the success rate achieved in training. Meanwhile, with multi-stage learning, ACEMSL allows data-efficient training and individual-team reward allocation for the collaborative drone swarm. The effectiveness and generalization capability of our approach are validated using simulations and actual flight tests.
Topologically-Aware Deformation Fields for Single-View 3D Reconstruction
May 21, 2022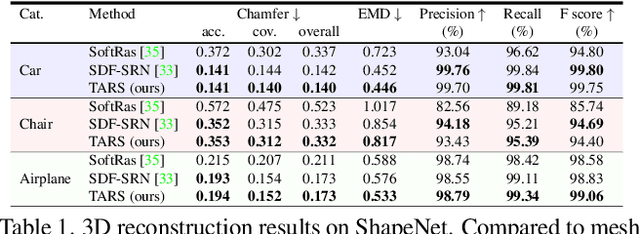
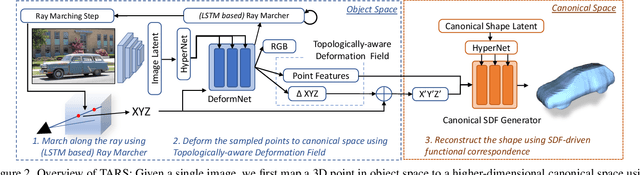

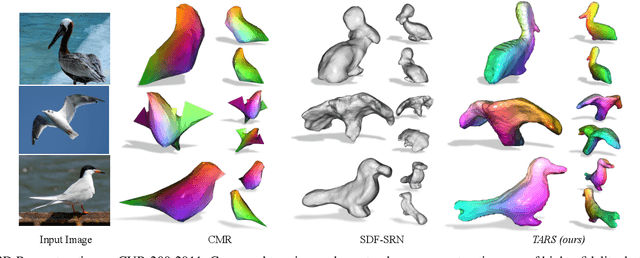
We present a framework for learning 3D object shapes and dense cross-object 3D correspondences from just an unaligned category-specific image collection. The 3D shapes are generated implicitly as deformations to a category-specific signed distance field and are learned in an unsupervised manner solely from unaligned image collections and their poses without any 3D supervision. Generally, image collections on the internet contain several intra-category geometric and topological variations, for example, different chairs can have different topologies, which makes the task of joint shape and correspondence estimation much more challenging. Because of this, prior works either focus on learning each 3D object shape individually without modeling cross-instance correspondences or perform joint shape and correspondence estimation on categories with minimal intra-category topological variations. We overcome these restrictions by learning a topologically-aware implicit deformation field that maps a 3D point in the object space to a higher dimensional point in the category-specific canonical space. At inference time, given a single image, we reconstruct the underlying 3D shape by first implicitly deforming each 3D point in the object space to the learned category-specific canonical space using the topologically-aware deformation field and then reconstructing the 3D shape as a canonical signed distance field. Both canonical shape and deformation field are learned end-to-end in an inverse-graphics fashion using a learned recurrent ray marcher (SRN) as a differentiable rendering module. Our approach, dubbed TARS, achieves state-of-the-art reconstruction fidelity on several datasets: ShapeNet, Pascal3D+, CUB, and Pix3D chairs. Result videos and code at https://shivamduggal4.github.io/tars-3D/
Reinforcement Re-ranking with 2D Grid-based Recommendation Panels
Apr 11, 2022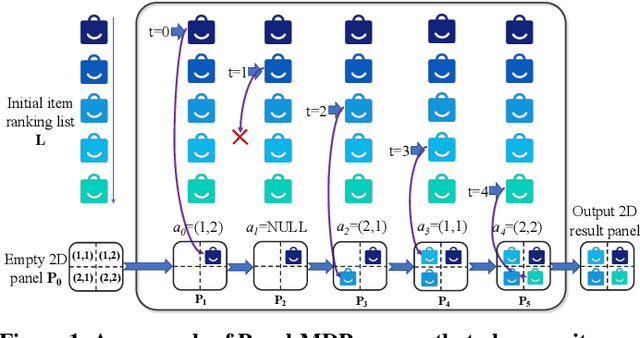

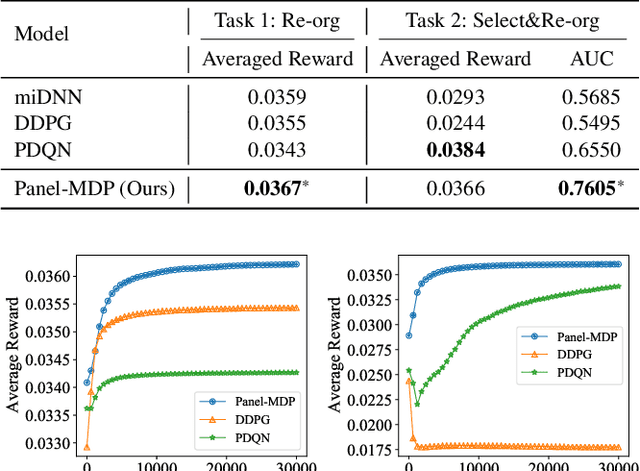
Modern recommender systems usually present items as one-dimensional ranking list. Recently there is a trend in e-commerce that the recommended items are organized as two-dimensional grid-based panels where users can view the items in both vertical and horizontal directions. Presenting items in grid-based result panels poses new challenges to recommender systems because existing models are all designed to output sequential lists while the slots in a grid-based panel have no explicit order. Directly converting the item rankings into grids (e.g., pre-defining an order on the slots)overlooks the user-specific behavioral patterns on grid-based pan-els and inevitably hurts the user experiences. To address this issue, we propose a novel Markov decision process (MDP) to place the items in 2D grid-based result panels at the final re-ranking stage of the recommender systems. The model, referred to as Panel-MDP, takes an initial item ranking from the early stages as the input. Then, it defines the MDP discrete time steps as the ranks in the initial ranking list, and the actions as the slots in the grid-based panels, plus a NULL action. At each time step, Panel-MDP sequentially takes an action of selecting one slot for placing an item of the initial ranking list, or discarding the item if NULL action is selected. The process is continued until all of the slots are filled. The reinforcement learning algorithm of DQN is employed to implement and learn the parameters in the Panel-MDP. Experiments on a dataset collected from a widely-used e-commerce app demonstrated the superiority ofPanel-MDP in terms of recommending 2D grid-based result panels.
Computing Multiple Image Reconstructions with a Single Hypernetwork
Mar 16, 2022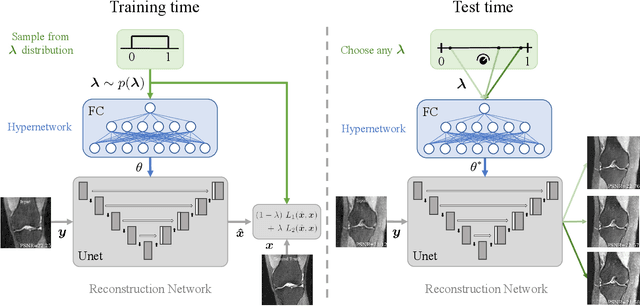
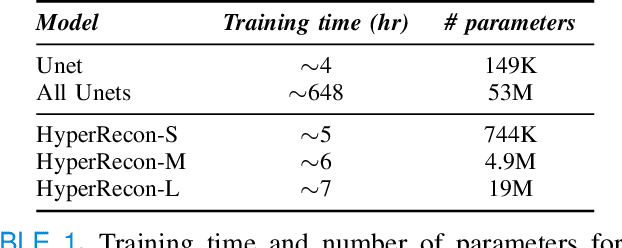

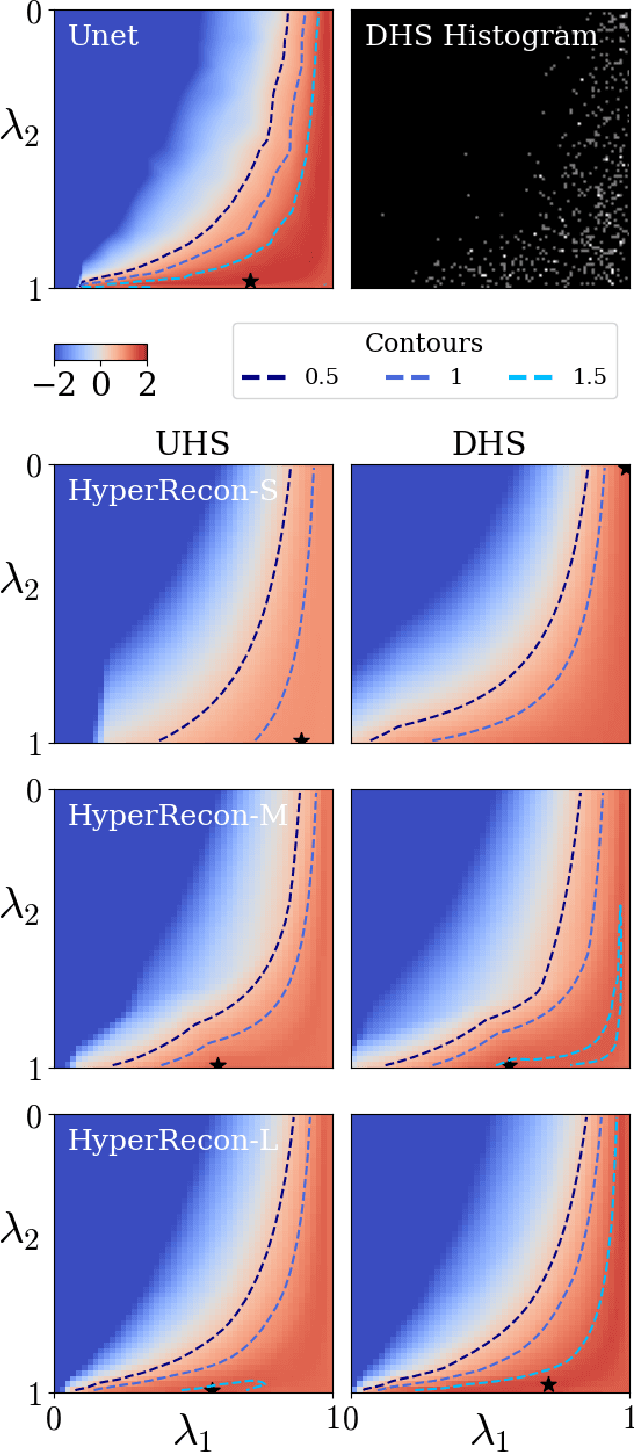
Deep learning based techniques achieve state-of-the-art results in a wide range of image reconstruction tasks like compressed sensing. These methods almost always have hyperparameters, such as the weight coefficients that balance the different terms in the optimized loss function. The typical approach is to train the model for a hyperparameter setting determined with some empirical or theoretical justification. Thus, at inference time, the model can only compute reconstructions corresponding to the pre-determined hyperparameter values. In this work, we present a hypernetwork-based approach, called HyperRecon, to train reconstruction models that are agnostic to hyperparameter settings. At inference time, HyperRecon can efficiently produce diverse reconstructions, which would each correspond to different hyperparameter values. In this framework, the user is empowered to select the most useful output(s) based on their own judgement. We demonstrate our method in compressed sensing, super-resolution and denoising tasks, using two large-scale and publicly-available MRI datasets. Our code is available at https://github.com/alanqrwang/hyperrecon.
Accelerating Federated Edge Learning via Topology Optimization
Apr 01, 2022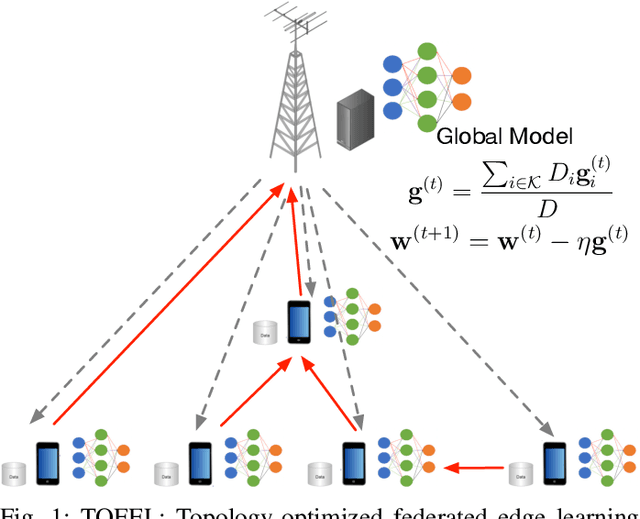
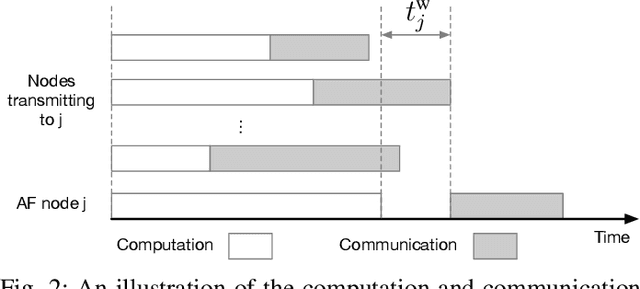

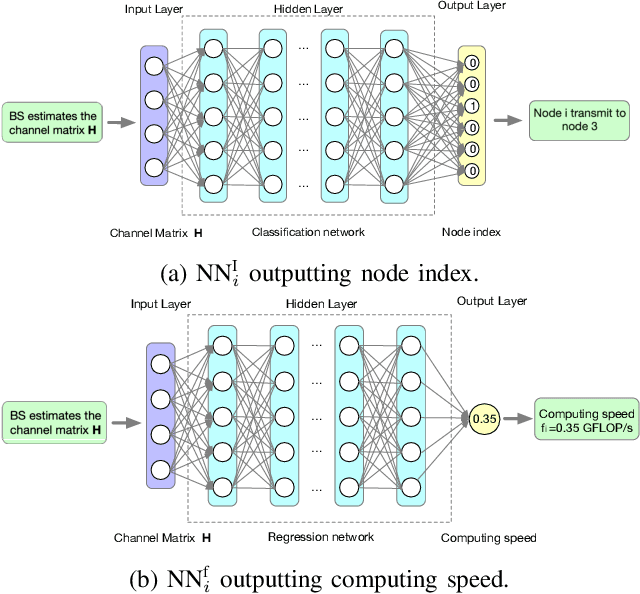
Federated edge learning (FEEL) is envisioned as a promising paradigm to achieve privacy-preserving distributed learning. However, it consumes excessive learning time due to the existence of straggler devices. In this paper, a novel topology-optimized federated edge learning (TOFEL) scheme is proposed to tackle the heterogeneity issue in federated learning and to improve the communication-and-computation efficiency. Specifically, a problem of jointly optimizing the aggregation topology and computing speed is formulated to minimize the weighted summation of energy consumption and latency. To solve the mixed-integer nonlinear problem, we propose a novel solution method of penalty-based successive convex approximation, which converges to a stationary point of the primal problem under mild conditions. To facilitate real-time decision making, an imitation-learning based method is developed, where deep neural networks (DNNs) are trained offline to mimic the penalty-based method, and the trained imitation DNNs are deployed at the edge devices for online inference. Thereby, an efficient imitate-learning based approach is seamlessly integrated into the TOFEL framework. Simulation results demonstrate that the proposed TOFEL scheme accelerates the federated learning process, and achieves a higher energy efficiency. Moreover, we apply the scheme to 3D object detection with multi-vehicle point cloud datasets in the CARLA simulator. The results confirm the superior learning performance of the TOFEL scheme over conventional designs with the same resource and deadline constraints.