 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Simplifying Multilingual News Clustering Through Projection From a Shared Space
Apr 28, 2022
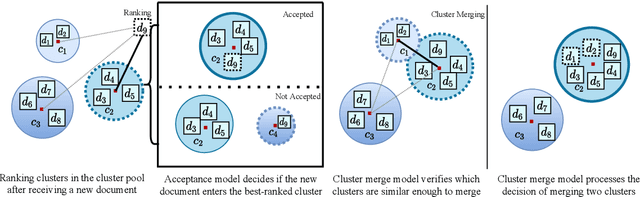
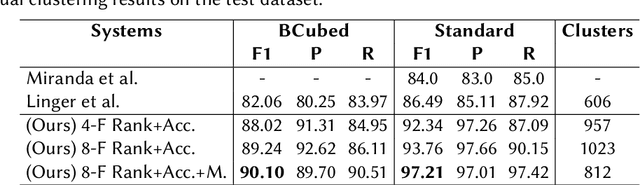
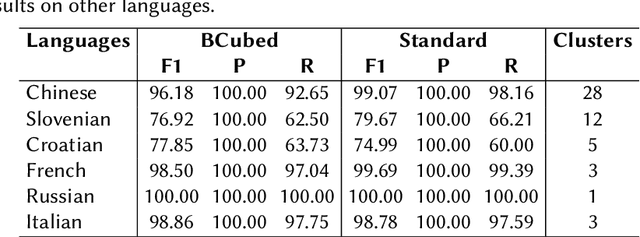
The task of organizing and clustering multilingual news articles for media monitoring is essential to follow news stories in real time. Most approaches to this task focus on high-resource languages (mostly English), with low-resource languages being disregarded. With that in mind, we present a much simpler online system that is able to cluster an incoming stream of documents without depending on language-specific features. We empirically demonstrate that the use of multilingual contextual embeddings as the document representation significantly improves clustering quality. We challenge previous crosslingual approaches by removing the precondition of building monolingual clusters. We model the clustering process as a set of linear classifiers to aggregate similar documents, and correct closely-related multilingual clusters through merging in an online fashion. Our system achieves state-of-the-art results on a multilingual news stream clustering dataset, and we introduce a new evaluation for zero-shot news clustering in multiple languages. We make our code available as open-source.
* 10 pages, 1 figure
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022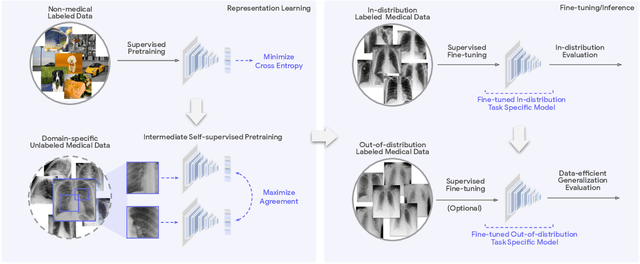
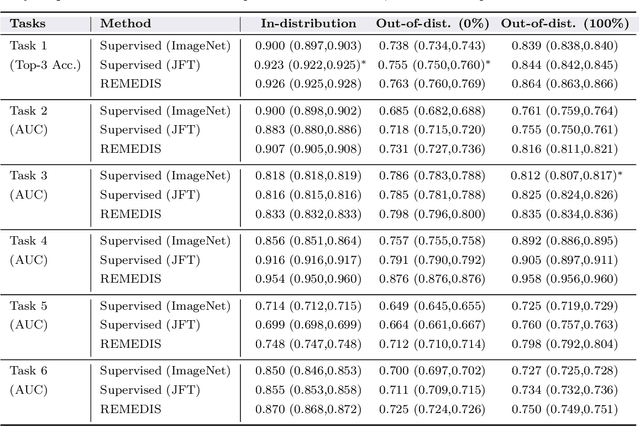
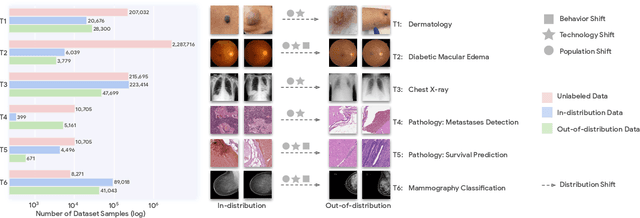

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
An Adaptive Incremental Gradient Method With Support for Non-Euclidean Norms
Apr 28, 2022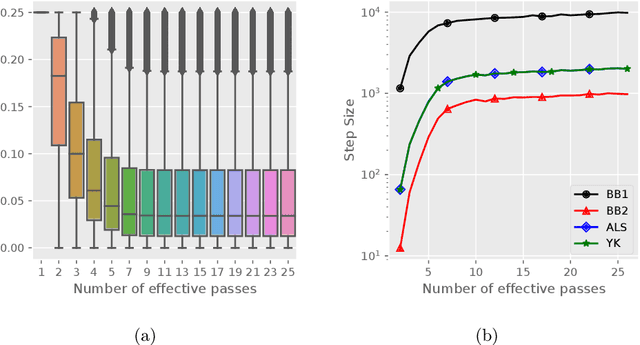
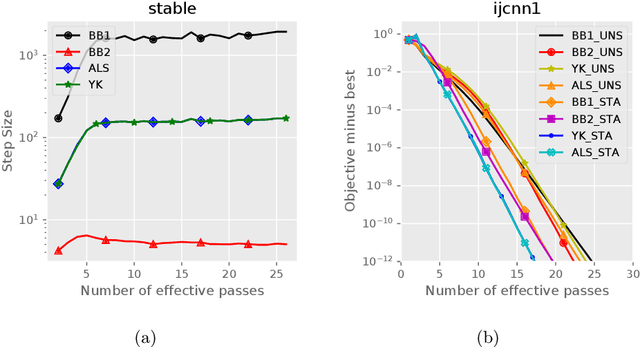
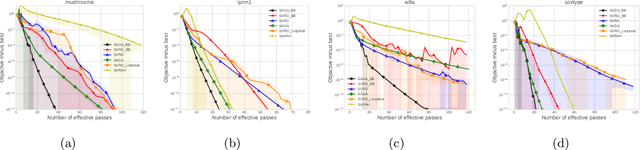
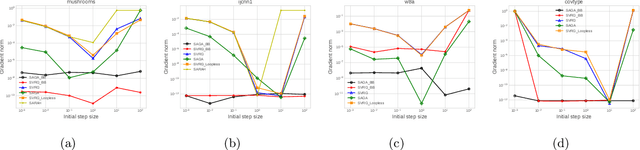
Stochastic variance reduced methods have shown strong performance in solving finite-sum problems. However, these methods usually require the users to manually tune the step-size, which is time-consuming or even infeasible for some large-scale optimization tasks. To overcome the problem, we propose and analyze several novel adaptive variants of the popular SAGA algorithm. Eventually, we design a variant of Barzilai-Borwein step-size which is tailored for the incremental gradient method to ensure memory efficiency and fast convergence. We establish its convergence guarantees under general settings that allow non-Euclidean norms in the definition of smoothness and the composite objectives, which cover a broad range of applications in machine learning. We improve the analysis of SAGA to support non-Euclidean norms, which fills the void of existing work. Numerical experiments on standard datasets demonstrate a competitive performance of the proposed algorithm compared with existing variance-reduced methods and their adaptive variants.
Confidence Band Estimation for Survival Random Forests
Apr 26, 2022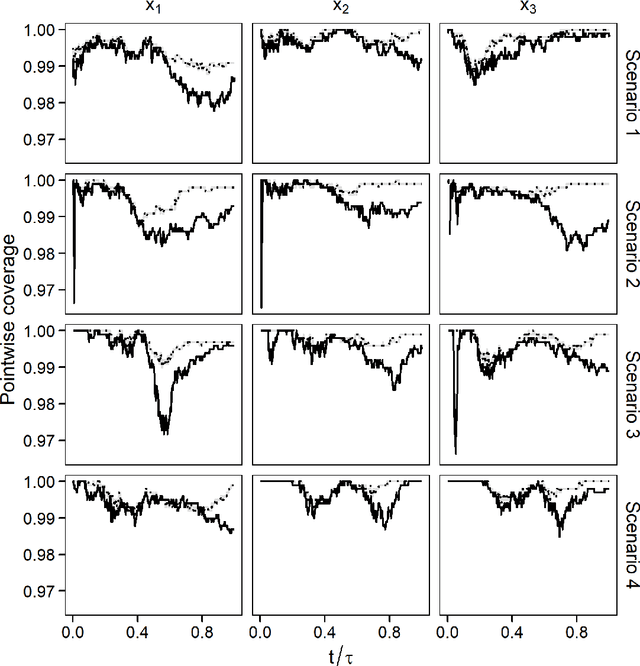
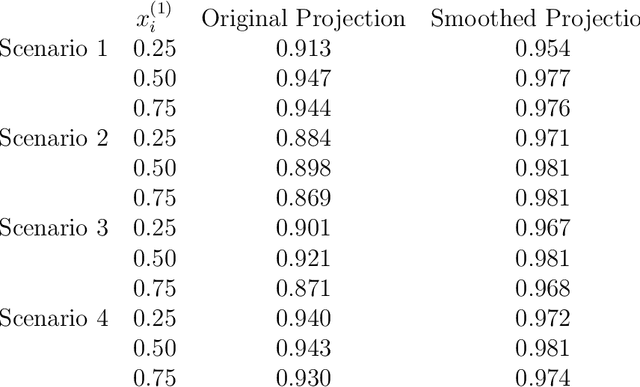
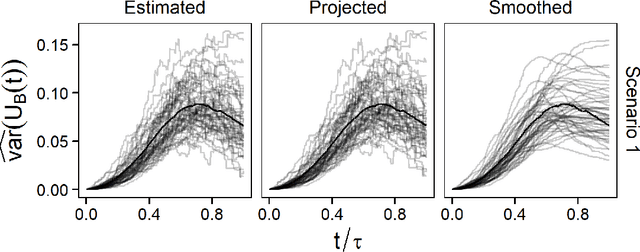
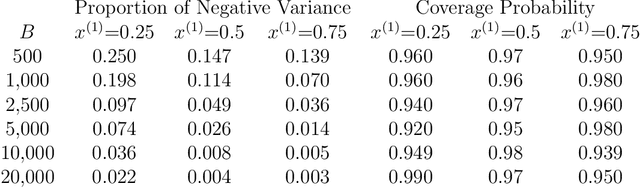
Survival random forest is a popular machine learning tool for modeling censored survival data. However, there is currently no statistically valid and computationally feasible approach for estimating its confidence band. This paper proposes an unbiased confidence band estimation by extending recent developments in infinite-order incomplete U-statistics. The idea is to estimate the variance-covariance matrix of the cumulative hazard function prediction on a grid of time points. We then generate the confidence band by viewing the cumulative hazard function estimation as a Gaussian process whose distribution can be approximated through simulation. This approach is computationally easy to implement when the subsampling size of a tree is no larger than half of the total training sample size. Numerical studies show that our proposed method accurately estimates the confidence band and achieves desired coverage rate. We apply this method to veterans' administration lung cancer data.
On the Role of Field of View for Occlusion Removal with Airborne Optical Sectioning
Apr 28, 2022
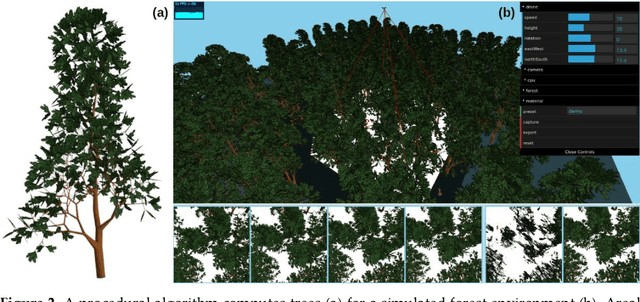

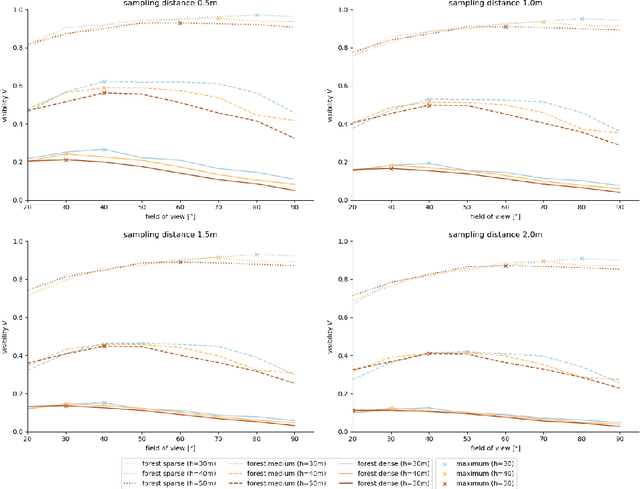
Occlusion caused by vegetation is an essential problem for remote sensing applications in areas, such as search and rescue, wildfire detection, wildlife observation, surveillance, border control, and others. Airborne Optical Sectioning (AOS) is an optical, wavelength-independent synthetic aperture imaging technique that supports computational occlusion removal in real-time. It can be applied with manned or unmanned aircrafts, such as drones. In this article, we demonstrate a relationship between forest density and field of view (FOV) of applied imaging systems. This finding was made with the help of a simulated procedural forest model which offers the consideration of more realistic occlusion properties than our previous statistical model. While AOS has been explored with automatic and autonomous research prototypes in the past, we present a free AOS integration for DJI systems. It enables bluelight organizations and others to use and explore AOS with compatible, manually operated, off-the-shelf drones. The (digitally cropped) default FOV for this implementation was chosen based on our new finding.
A Hitchhiker`s Guide through the Bio-image Analysis Software Universe
Apr 15, 2022
Modern research in the life sciences is unthinkable without computational methods for extracting, quantifying and visualizing information derived from biological microscopy imaging data. In the past decade, we observed a dramatic increase in available software packages for these purposes. As it is increasingly difficult to keep track of the number of available image analysis platforms, tool collections, components and emerging technologies, we provide a conservative overview of software we use in daily routine and give insights into emerging new tools. We give guidance on which aspects to consider when choosing the right platform, including aspects such as image data type, skills of the team, infrastructure and community at the institute and availability of time and budget.
Parameter Tuning of Time-Frequency Masking Algorithms for Reverberant Artifact Removal within the Cochlear Implant Stimulus
Aug 12, 2021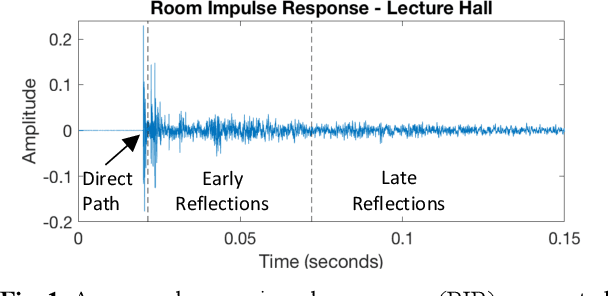
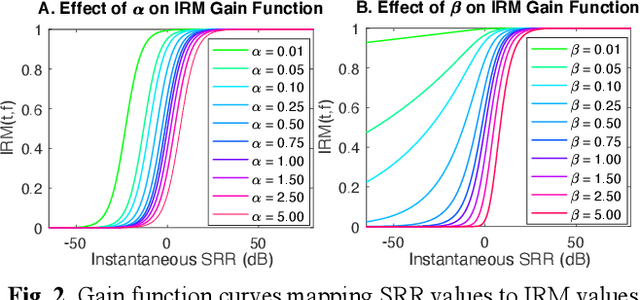
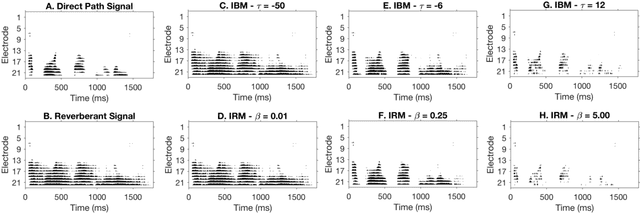
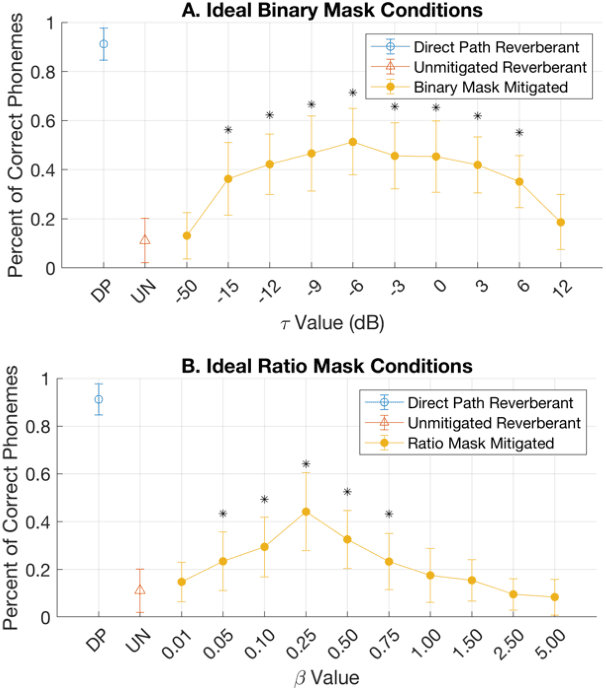
Cochlear implant users struggle to understand speech in reverberant environments. To restore speech perception, artifacts dominated by reverberant reflections can be removed from the cochlear implant stimulus. Artifacts can be identified and removed by applying a matrix of gain values, a technique referred to as time-frequency masking. Gain values are determined by an oracle algorithm that uses knowledge of the undistorted signal to minimize retention of the signal components dominated by reverberant reflections. In practice, gain values are estimated from the distorted signal, with the oracle algorithm providing the estimation objective. Different oracle techniques exist for determining gain values, and each technique must be parameterized to set the amount of signal retention. This work assesses which oracle masking strategies and parameterizations lead to the best improvements in speech intelligibility for cochlear implant users in reverberant conditions using online speech intelligibility testing of normal-hearing individuals with vocoding.
DIANES: A DEI Audit Toolkit for News Sources
Mar 21, 2022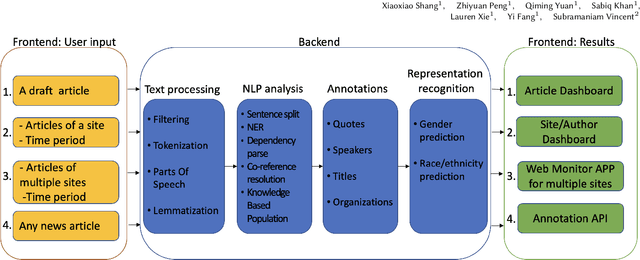
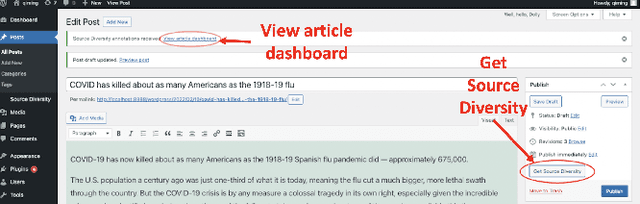
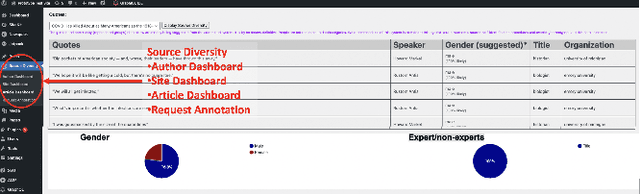
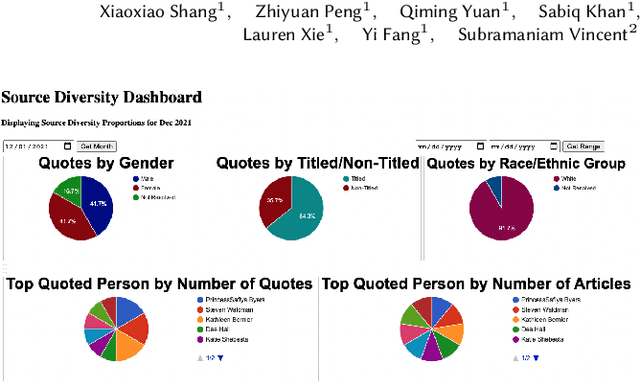
Professional news media organizations have always touted the importance that they give to multiple perspectives. However, in practice the traditional approach to all-sides has favored people in the dominant culture. Hence it has come under ethical critique under the new norms of diversity, equity, and inclusion (DEI). When DEI is applied to journalism, it goes beyond conventional notions of impartiality and bias and instead democratizes the journalistic practice of sourcing -- who is quoted or interviewed, who is not, how often, from which demographic group, gender, and so forth. There is currently no real-time or on-demand tool in the hands of reporters to analyze the persons they quote. In this paper, we present DIANES, a DEI Audit Toolkit for News Sources. It consists of a natural language processing pipeline on the backend to extract quotes, speakers, titles, and organizations from news articles in real time. On the frontend, DIANES offers the WordPress plugins, a Web monitor, and a DEI annotation API service, to help news media monitor their own quoting patterns and push themselves towards DEI norms.
Refining Diagnosis Paths for Medical Diagnosis based on an Augmented Knowledge Graph
Apr 28, 2022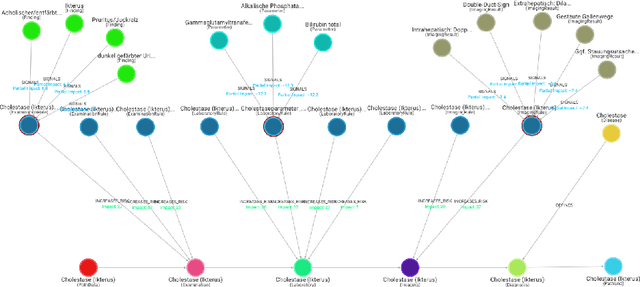


Medical diagnosis is the process of making a prediction of the disease a patient is likely to have, given a set of symptoms and observations. This requires extensive expert knowledge, in particular when covering a large variety of diseases. Such knowledge can be coded in a knowledge graph -- encompassing diseases, symptoms, and diagnosis paths. Since both the knowledge itself and its encoding can be incomplete, refining the knowledge graph with additional information helps physicians making better predictions. At the same time, for deployment in a hospital, the diagnosis must be explainable and transparent. In this paper, we present an approach using diagnosis paths in a medical knowledge graph. We show that those graphs can be refined using latent representations with RDF2vec, while the final diagnosis is still made in an explainable way. Using both an intrinsic as well as an expert-based evaluation, we show that the embedding-based prediction approach is beneficial for refining the graph with additional valid conditions.
Generating Reliable Process Event Streams and Time Series Data based on Neural Networks
Mar 09, 2021
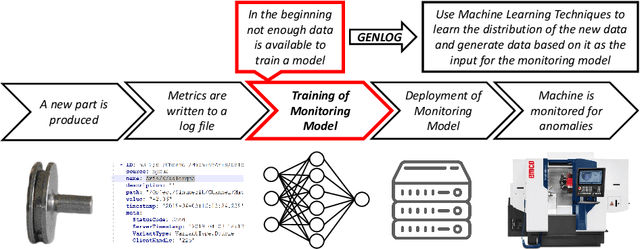

Domains such as manufacturing and medicine crave for continuous monitoring and analysis of their processes, especially in combination with time series as produced by sensors. Time series data can be exploited to, for example, explain and predict concept drifts during runtime. Generally, a certain data volume is required in order to produce meaningful analysis results. However, reliable data sets are often missing, for example, if event streams and times series data are collected separately, in case of a new process, or if it is too expensive to obtain a sufficient data volume. Additional challenges arise with preparing time series data from multiple event sources, variations in data collection frequency, and concept drift. This paper proposes the GENLOG approach to generate reliable event and time series data that follows the distribution of the underlying input data set. GENLOG employs data resampling and enables the user to select different parts of the log data to orchestrate the training of a recurrent neural network for stream generation. The generated data is sampled back to its original sample rate and is embedded into a template representing the log data format it originated from. Overall, GENLOG can boost small data sets and consequently the application of online process mining.