 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VQA-GNN: Reasoning with Multimodal Semantic Graph for Visual Question Answering
May 23, 2022
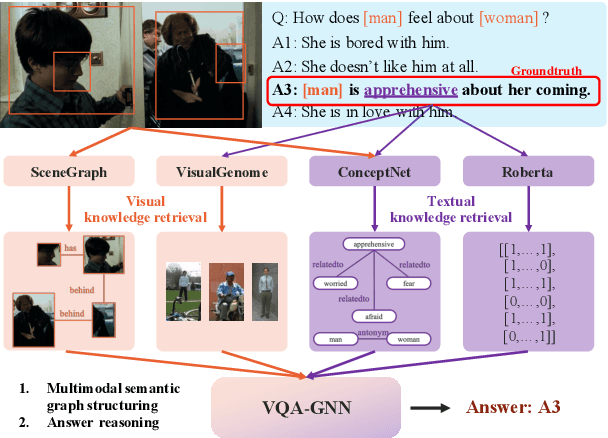
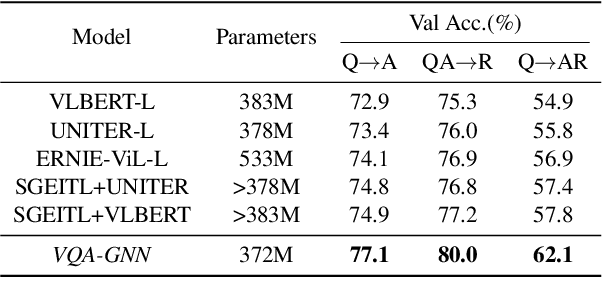
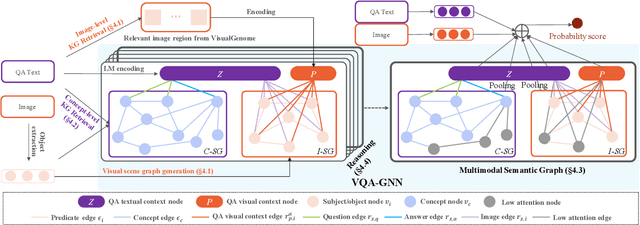

Visual understanding requires seamless integration between recognition and reasoning: beyond image-level recognition (e.g., detecting objects), systems must perform concept-level reasoning (e.g., inferring the context of objects and intents of people). However, existing methods only model the image-level features, and do not ground them and reason with background concepts such as knowledge graphs (KGs). In this work, we propose a novel visual question answering method, VQA-GNN, which unifies the image-level information and conceptual knowledge to perform joint reasoning of the scene. Specifically, given a question-image pair, we build a scene graph from the image, retrieve a relevant linguistic subgraph from ConceptNet and visual subgraph from VisualGenome, and unify these three graphs and the question into one joint graph, multimodal semantic graph. Our VQA-GNN then learns to aggregate messages and reason across different modalities captured by the multimodal semantic graph. In the evaluation on the VCR task, our method outperforms the previous scene graph-based Trans-VL models by over 4%, and VQA-GNN-Large, our model that fuses a Trans-VL further improves the state of the art by 2%, attaining the top of the VCR leaderboard at the time of submission. This result suggests the efficacy of our model in performing conceptual reasoning beyond image-level recognition for visual understanding. Finally, we demonstrate that our model is the first work to provide interpretability across visual and textual knowledge domains for the VQA task.
Composing General Audio Representation by Fusing Multilayer Features of a Pre-trained Model
May 17, 2022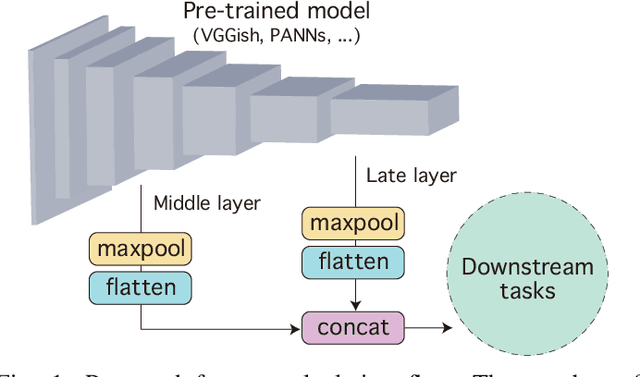
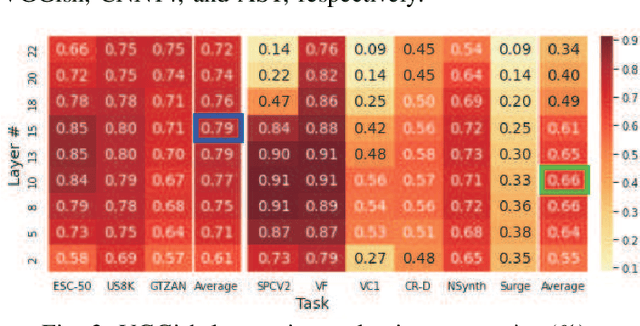

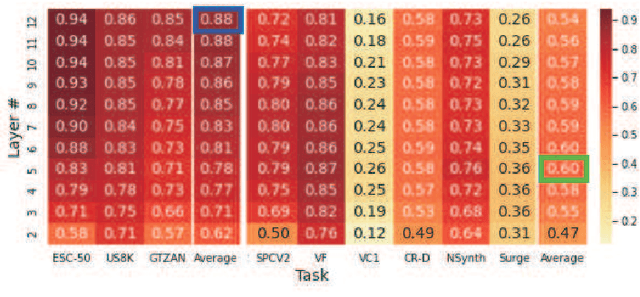
Many application studies rely on audio DNN models pre-trained on a large-scale dataset as essential feature extractors, and they extract features from the last layers. In this study, we focus on our finding that the middle layer features of existing supervised pre-trained models are more effective than the late layer features for some tasks. We propose a simple approach to compose features effective for general-purpose applications, consisting of two steps: (1) calculating feature vectors along the time frame from middle/late layer outputs, and (2) fusing them. This approach improves the utility of frequency and channel information in downstream processes, and combines the effectiveness of middle and late layer features for different tasks. As a result, the feature vectors become effective for general purposes. In the experiments using VGGish, PANNs' CNN14, and AST on nine downstream tasks, we first show that each layer output of these models serves different tasks. Then, we demonstrate that the proposed approach significantly improves their performance and brings it to a level comparable to that of the state-of-the-art. In particular, the performance of the non-semantic speech (NOSS) tasks greatly improves, especially on Speech commands V2 with VGGish of +77.1 (14.3% to 91.4%).
How to Guide Adaptive Depth Sampling?
May 20, 2022
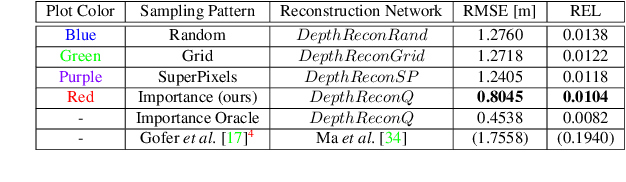
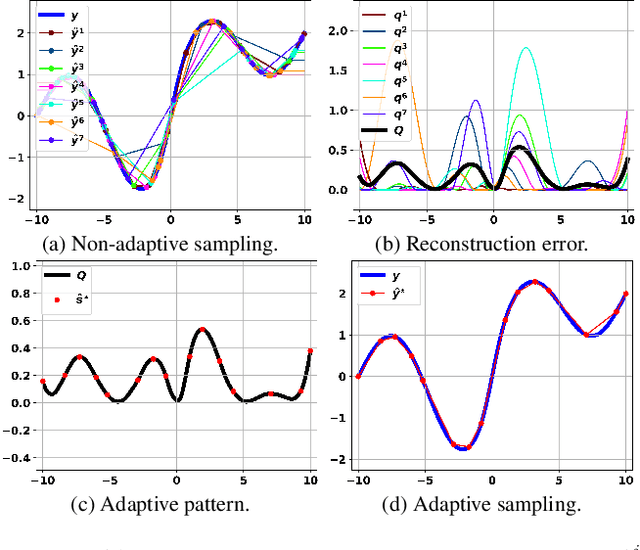

Recent advances in depth sensing technologies allow fast electronic maneuvering of the laser beam, as opposed to fixed mechanical rotations. This will enable future sensors, in principle, to vary in real-time the sampling pattern. We examine here the abstract problem of whether adapting the sampling pattern for a given frame can reduce the reconstruction error or allow a sparser pattern. We propose a constructive generic method to guide adaptive depth sampling algorithms. Given a sampling budget B, a depth predictor P and a desired quality measure M, we propose an Importance Map that highlights important sampling locations. This map is defined for a given frame as the per-pixel expected value of M produced by the predictor P, given a pattern of B random samples. This map can be well estimated in a training phase. We show that a neural network can learn to produce a highly faithful Importance Map, given an RGB image. We then suggest an algorithm to produce a sampling pattern for the scene, which is denser in regions that are harder to reconstruct. The sampling strategy of our modular framework can be adjusted according to hardware limitations, type of depth predictor, and any custom reconstruction error measure that should be minimized. We validate through simulations that our approach outperforms grid and random sampling patterns as well as recent state-of-the-art adaptive algorithms.
RD-Optimized Trit-Plane Coding of Deep Compressed Image Latent Tensors
Mar 25, 2022
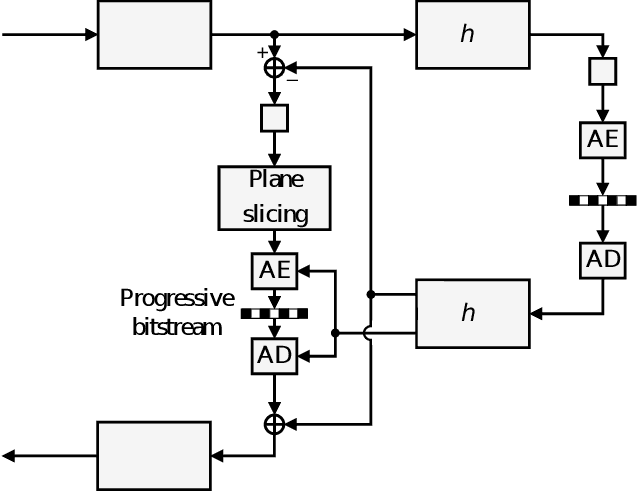
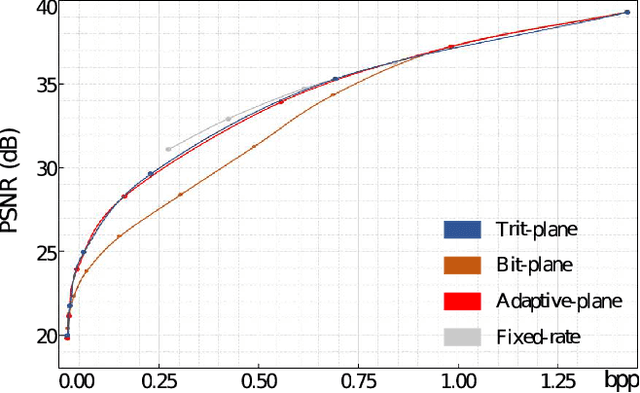

DPICT is the first learning-based image codec supporting fine granular scalability. In this paper, we describe how to implement two key components of DPICT efficiently: trit-plane slicing and RD-prioritized transmission. In DPICT, we transform an image into a latent tensor, represent the tensor in ternary digits (trits), and encode the trits in the decreasing order of significance. For entropy encoding, we should compute the probability of each trit, which demands high time complexity in both the encoder and the decoder. To reduce the complexity, we develop a parallel computing scheme for the probabilities and describe it in detail with pseudo-codes. Moreover, in this paper, we compare the trit-plane slicing in DPICT with the alternative bit-plane slicing. Experimental results show that the time complexity is reduced significantly by the parallel computing and that the trit-plane slicing provides better rate-distortion performances than the bit-plane slicing.
Networked Sensing with AI-Empowered Environment Estimation: Exploiting Macro-Diversity and Array Gain in Perceptive Mobile Networks
May 23, 2022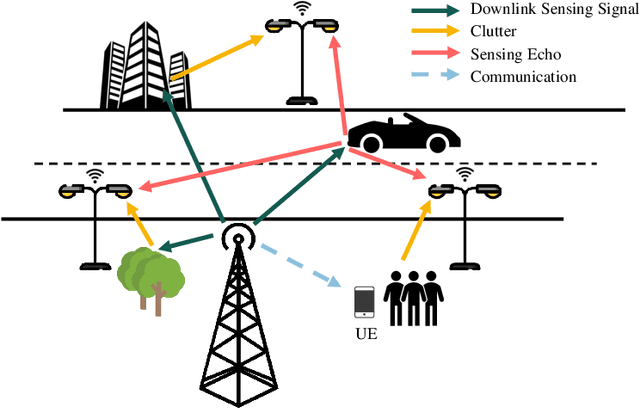
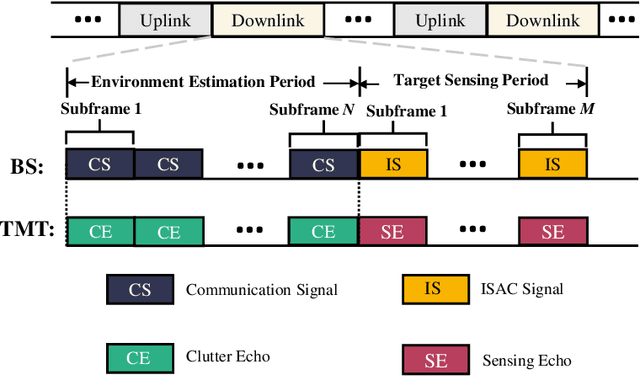
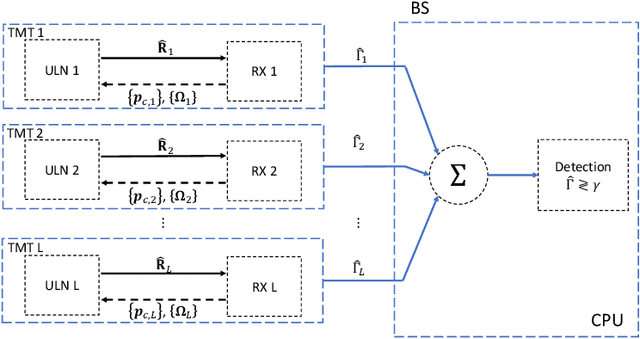
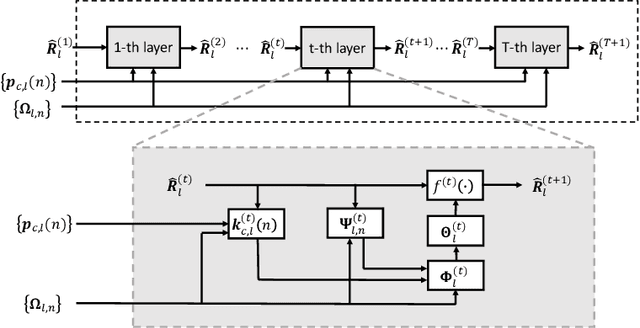
Sensing will be an important service for future wireless networks to assist innovative applications like autonomous driving and environment monitoring. This paper considers the design of perceptive mobile networks (PMNs) where target monitoring terminals (TMTs) are deployed over the traditional cellular networks for jointly sensing the targets in the presence of environment clutter. Different from traditional radar, the cellular structure of PMNs offers multiple perspectives for target sensing (TS), but the joint processing among distributed sensing nodes also causes heavy computation and communication workload over the network. In this paper, we first propose a two-stage protocol where communication signals are utilized for environment estimation (EE) and TS in two consecutive time periods, respectively. A \textit{networked} sensing detector is then derived to exploit the perspectives provided by multiple TMTs for sensing the same target. The macro-diversity from multiple TMTs and the array gain from multiple receive antennas at each TMT are analyzed to reveal the benefit of networked sensing. Furthermore, we derive the sufficient condition that one TMT's contribution to the networked sensing is positive, based on which a TMT selection algorithm is proposed. To reduce the computation burden and efficiently estimate the environment, we propose a model-driven deep-learning algorithm that utilizes partially-sampled data for EE. Simulation results confirm the benefits of networked sensing and validate the higher efficiency of the proposed EE algorithm than existing methods.
Discrete Optimal Transport with Independent Marginals is #P-Hard
Mar 02, 2022We study the computational complexity of the optimal transport problem that evaluates the Wasserstein distance between the distributions of two K-dimensional discrete random vectors. The best known algorithms for this problem run in polynomial time in the maximum of the number of atoms of the two distributions. However, if the components of either random vector are independent, then this number can be exponential in K even though the size of the problem description scales linearly with K. We prove that the described optimal transport problem is #P-hard even if all components of the first random vector are independent uniform Bernoulli random variables, while the second random vector has merely two atoms, and even if only approximate solutions are sought. We also develop a dynamic programming-type algorithm that approximates the Wasserstein distance in pseudo-polynomial time when the components of the first random vector follow arbitrary independent discrete distributions, and we identify special problem instances that can be solved exactly in strongly polynomial time.
Adjusting for Autocorrelated Errors in Neural Networks for Time Series Regression and Forecasting
Feb 01, 2021
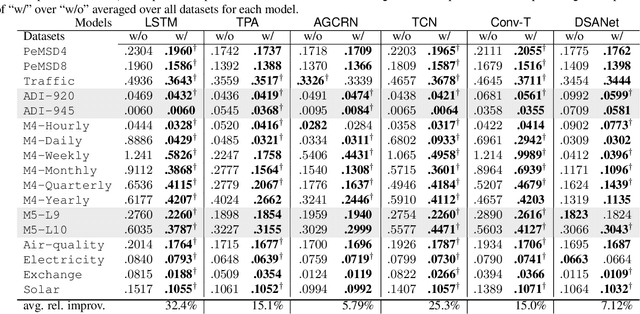
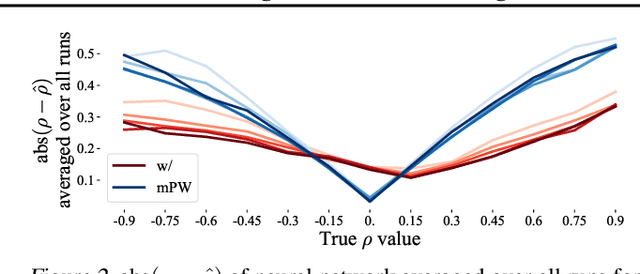
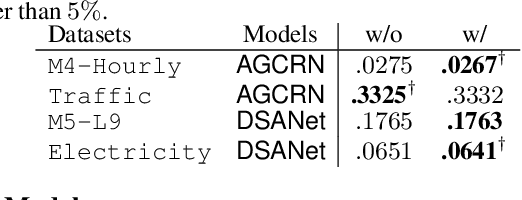
In many cases, it is difficult to generate highly accurate models for time series data using a known parametric model structure. In response, an increasing body of research focuses on using neural networks to model time series approximately. A common assumption in training neural networks on time series is that the errors at different time steps are uncorrelated. However, due to the temporality of the data, errors are actually autocorrelated in many cases, which makes such maximum likelihood estimation inaccurate. In this paper, we propose to learn the autocorrelation coefficient jointly with the model parameters in order to adjust for autocorrelated errors. For time series regression, large-scale experiments indicate that our method outperforms the Prais-Winsten method, especially when the autocorrelation is strong. Furthermore, we broaden our method to time series forecasting and apply it with various state-of-the-art models. Results across a wide range of real-world datasets show that our method enhances performance in almost all cases.
High-Cardinality Geometrical Constellation Shaping for the Nonlinear Fibre Channel
May 09, 2022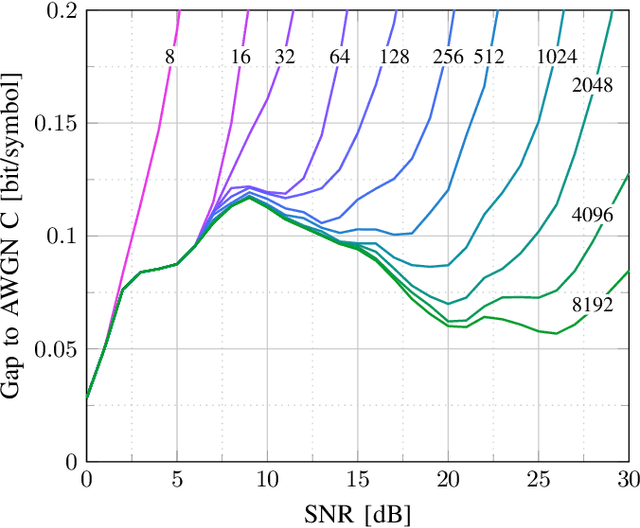
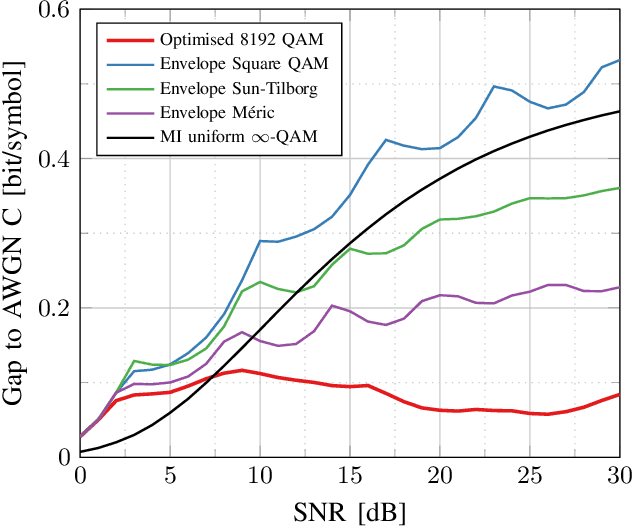
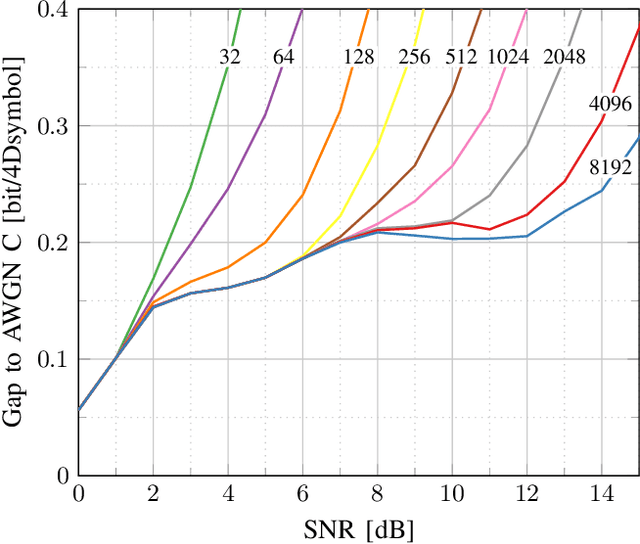
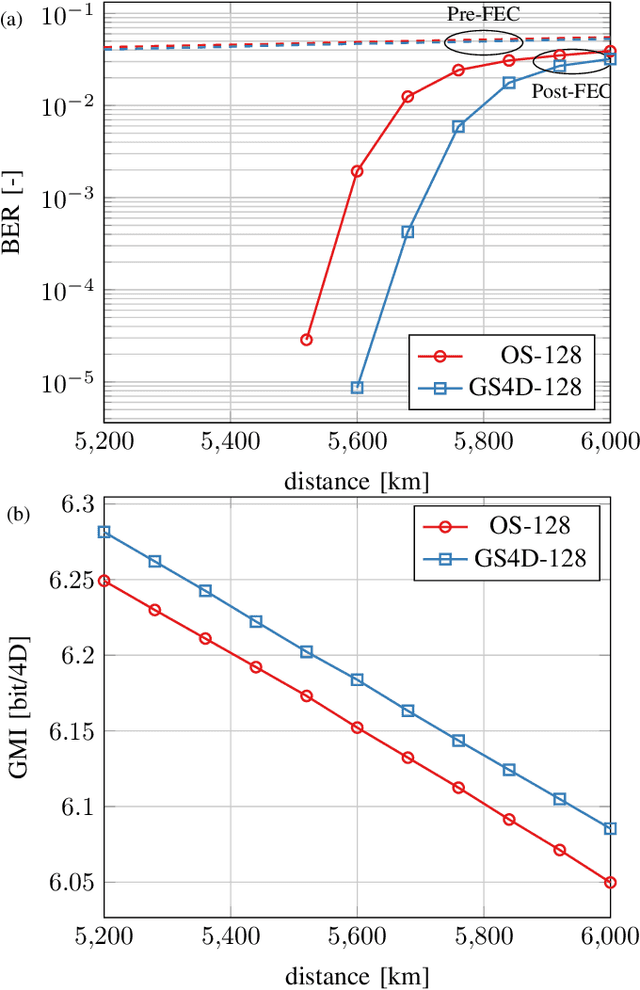
This paper presents design methods for highly efficient optimisation of geometrically shaped constellations to maximise data throughput in optical communications. It describes methods to analytically calculate the information-theoretical loss and the gradient of this loss as a function of the input constellation shape. The gradients of the \ac{MI} and \ac{GMI} are critical to the optimisation of geometrically-shaped constellations. It presents the analytical derivative of the achievable information rate metrics with respect to the input constellation. The proposed method allows for improved design of higher cardinality and higher-dimensional constellations for optimising both linear and nonlinear fibre transmission throughput. Near-capacity achieving constellations with up to 8192 points for both 2 and 4 dimensions, with generalised mutual information (GMI) within 0.06 bit/2Dsymbol of additive white Gaussian noise channel (AWGN) capacity, are presented. Additionally, a design algorithm reducing the design computation time from days to minutes is introduced, allowing the presentation of optimised constellations for both linear AWGN and nonlinear fibre channels for a wide range of signal-to-noise ratios.
Eventor: An Efficient Event-Based Monocular Multi-View Stereo Accelerator on FPGA Platform
Mar 29, 2022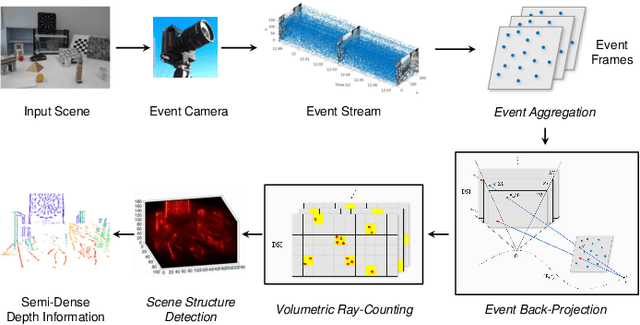
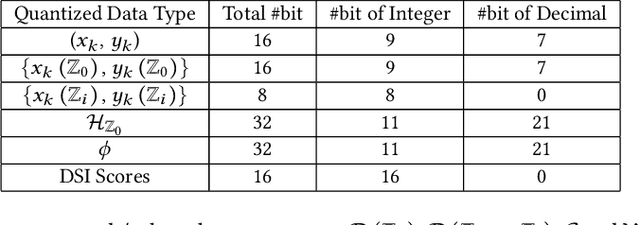
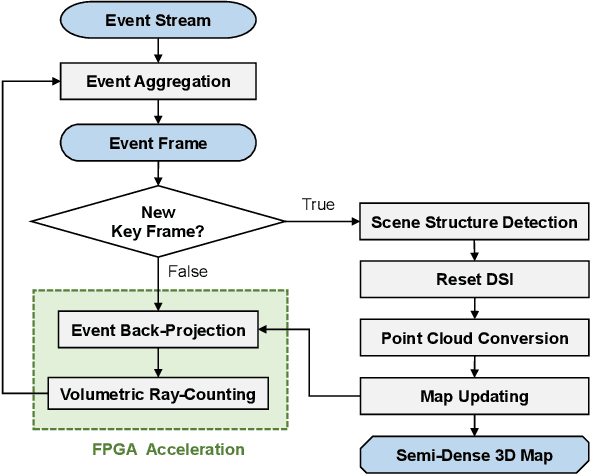
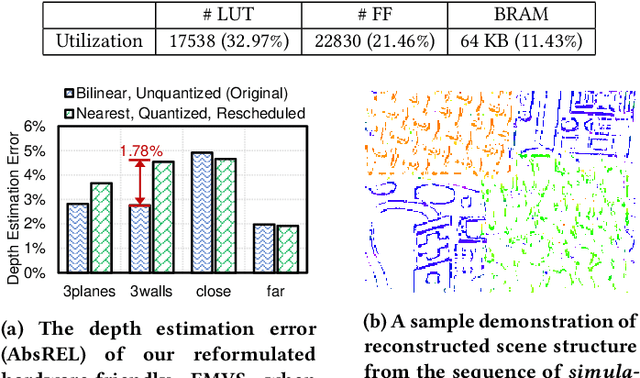
Event cameras are bio-inspired vision sensors that asynchronously represent pixel-level brightness changes as event streams. Event-based monocular multi-view stereo (EMVS) is a technique that exploits the event streams to estimate semi-dense 3D structure with known trajectory. It is a critical task for event-based monocular SLAM. However, the required intensive computation workloads make it challenging for real-time deployment on embedded platforms. In this paper, Eventor is proposed as a fast and efficient EMVS accelerator by realizing the most critical and time-consuming stages including event back-projection and volumetric ray-counting on FPGA. Highly paralleled and fully pipelined processing elements are specially designed via FPGA and integrated with the embedded ARM as a heterogeneous system to improve the throughput and reduce the memory footprint. Meanwhile, the EMVS algorithm is reformulated to a more hardware-friendly manner by rescheduling, approximate computing and hybrid data quantization. Evaluation results on DAVIS dataset show that Eventor achieves up to $24\times$ improvement in energy efficiency compared with Intel i5 CPU platform.
M2R2: Missing-Modality Robust emotion Recognition framework with iterative data augmentation
May 05, 2022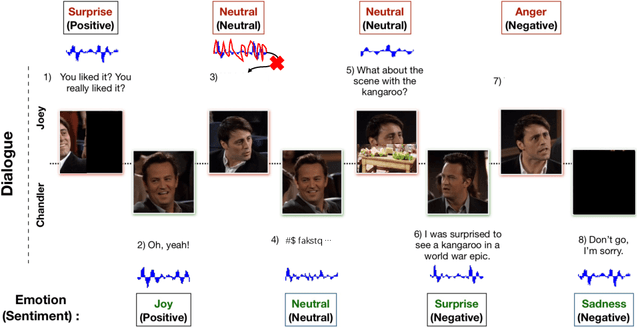
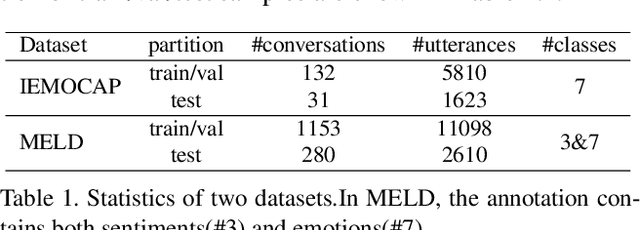
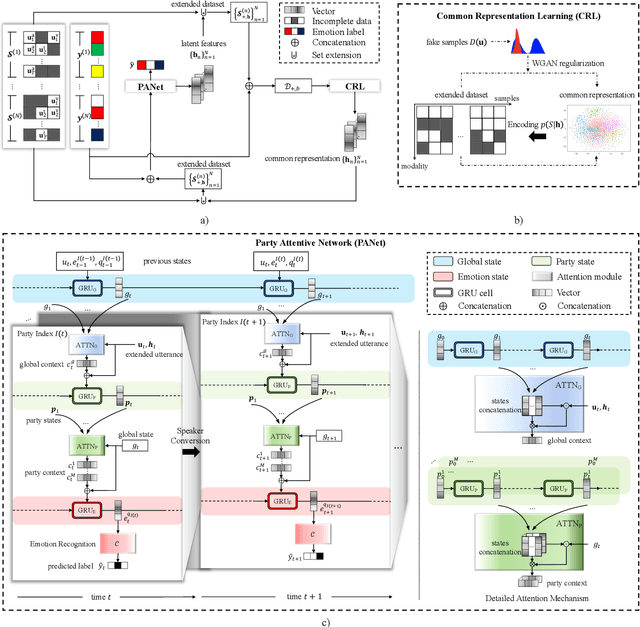
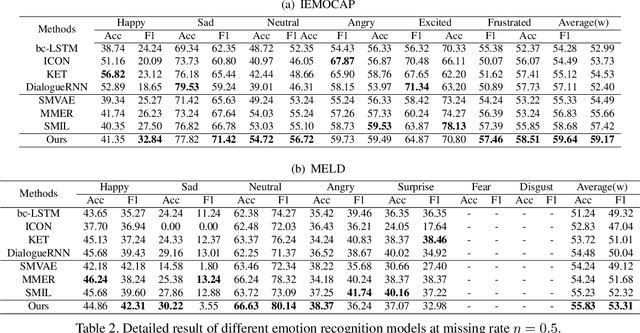
This paper deals with the utterance-level modalities missing problem with uncertain patterns on emotion recognition in conversation (ERC) task. Present models generally predict the speaker's emotions by its current utterance and context, which is degraded by modality missing considerably. Our work proposes a framework Missing-Modality Robust emotion Recognition (M2R2), which trains emotion recognition model with iterative data augmentation by learned common representation. Firstly, a network called Party Attentive Network (PANet) is designed to classify emotions, which tracks all the speakers' states and context. Attention mechanism between speaker with other participants and dialogue topic is used to decentralize dependence on multi-time and multi-party utterances instead of the possible incomplete one. Moreover, the Common Representation Learning (CRL) problem is defined for modality-missing problem. Data imputation methods improved by the adversarial strategy are used here to construct extra features to augment data. Extensive experiments and case studies validate the effectiveness of our methods over baselines for modality-missing emotion recognition on two different datasets.