 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wi-Fi Based Passive Human Motion Sensing for In-Home Healthcare Applications
Apr 13, 2022
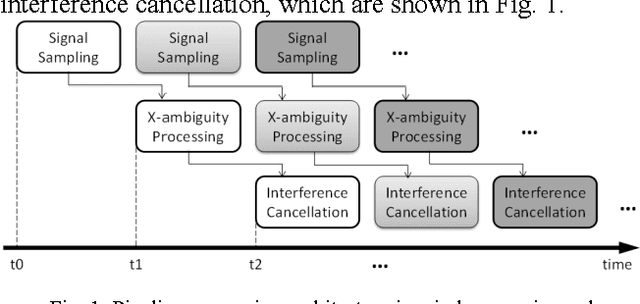
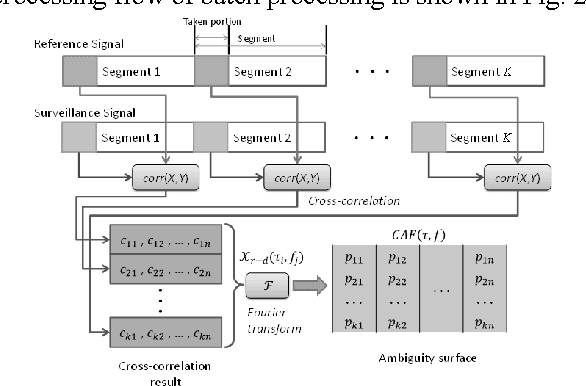
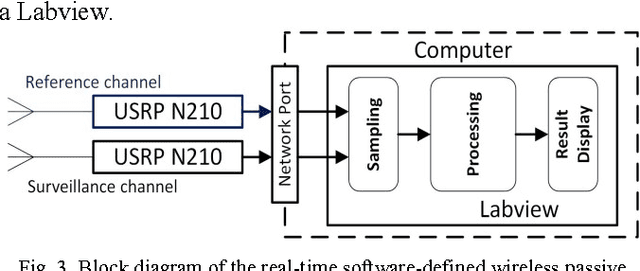
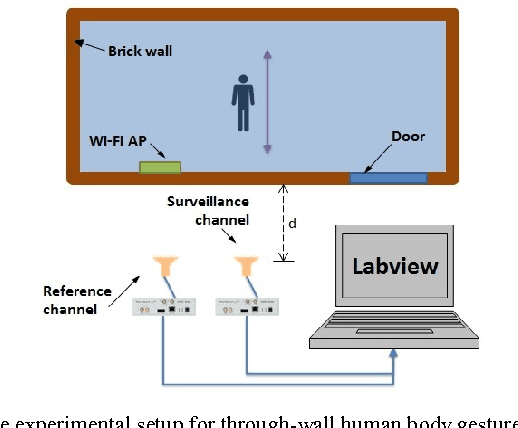
This paper introduces a Wi-Fi signal based passive wireless sensing system that has the capability to detect diverse indoor human movements, from whole body motions to limb movements and including breathing movements of the chest. The real time signal processing used for human body motion sensing and software defined radio demo system are described and verified in practical experiments scenarios, which include detection of through-wall human body movement, hand gesture or tremor, and even respiration. The experiment results offer potential for promising healthcare applications using Wi-Fi passive sensing in the home to monitor daily activities, to gather health data and detect emergency situations.
Nash, Conley, and Computation: Impossibility and Incompleteness in Game Dynamics
Mar 26, 2022


Under what conditions do the behaviors of players, who play a game repeatedly, converge to a Nash equilibrium? If one assumes that the players' behavior is a discrete-time or continuous-time rule whereby the current mixed strategy profile is mapped to the next, this becomes a problem in the theory of dynamical systems. We apply this theory, and in particular the concepts of chain recurrence, attractors, and Conley index, to prove a general impossibility result: there exist games for which any dynamics is bound to have starting points that do not end up at a Nash equilibrium. We also prove a stronger result for $\epsilon$-approximate Nash equilibria: there are games such that no game dynamics can converge (in an appropriate sense) to $\epsilon$-Nash equilibria, and in fact the set of such games has positive measure. Further numerical results demonstrate that this holds for any $\epsilon$ between zero and $0.09$. Our results establish that, although the notions of Nash equilibria (and its computation-inspired approximations) are universally applicable in all games, they are also fundamentally incomplete as predictors of long term behavior, regardless of the choice of dynamics.
MeSHup: A Corpus for Full Text Biomedical Document Indexing
Apr 28, 2022
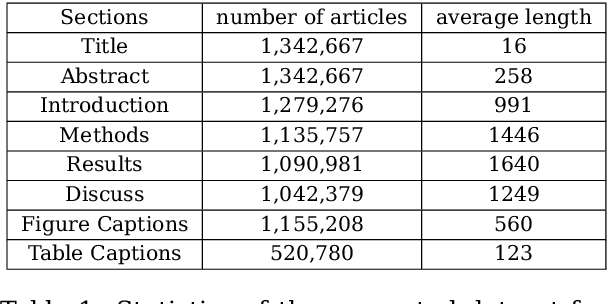
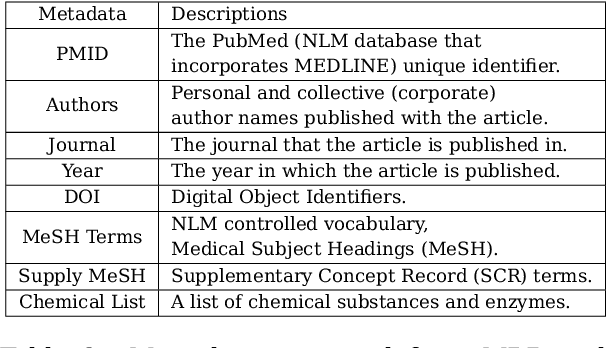
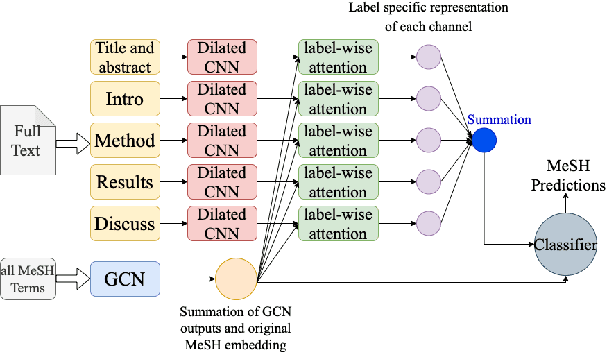
Medical Subject Heading (MeSH) indexing refers to the problem of assigning a given biomedical document with the most relevant labels from an extremely large set of MeSH terms. Currently, the vast number of biomedical articles in the PubMed database are manually annotated by human curators, which is time consuming and costly; therefore, a computational system that can assist the indexing is highly valuable. When developing supervised MeSH indexing systems, the availability of a large-scale annotated text corpus is desirable. A publicly available, large corpus that permits robust evaluation and comparison of various systems is important to the research community. We release a large scale annotated MeSH indexing corpus, MeSHup, which contains 1,342,667 full text articles in English, together with the associated MeSH labels and metadata, authors, and publication venues that are collected from the MEDLINE database. We train an end-to-end model that combines features from documents and their associated labels on our corpus and report the new baseline.
Detection of Gaussianity using envelopes
Mar 30, 2022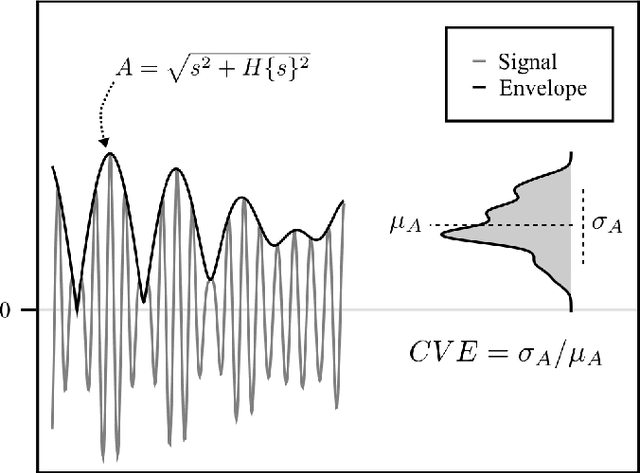
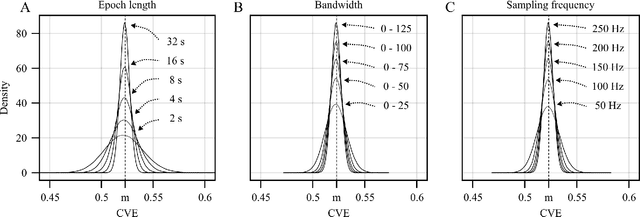
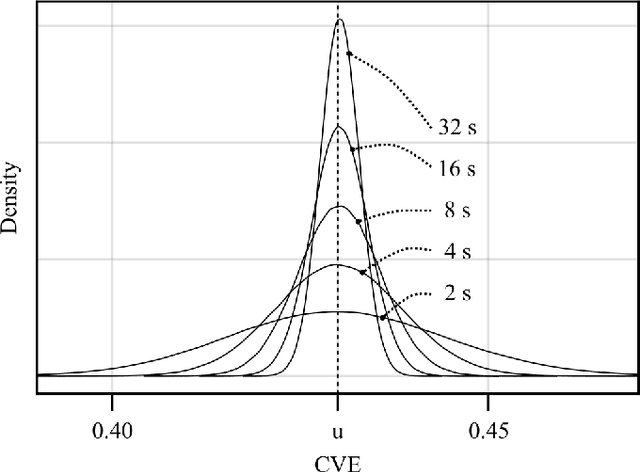
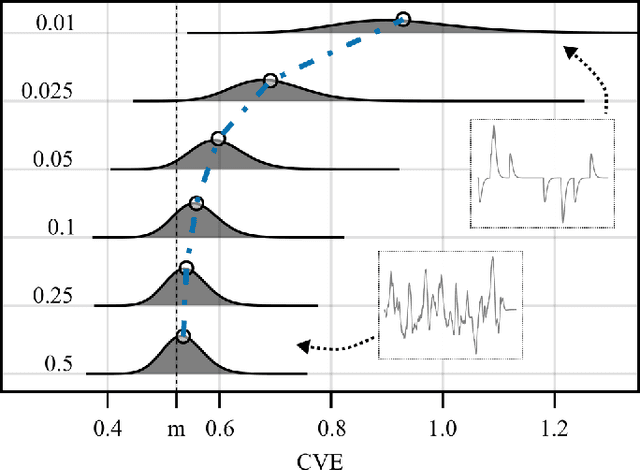
Here we introduce a new solution for Gaussianity testing using the envelope of a signal. The coefficient of variation ($\frac{std}{mean}$) of the envelope (CVE) of zero-mean Gaussian noise is a universal constant equal to $m = \sqrt{(4-\pi)/\pi}\approx 0.523$. Thus, for any signal the result CVE = $m$ can be used as a fingerprint to assess Gaussianity. Interestingly, the CVE is also unique for uniform noise time series or low density Filtered Poisson Processes. Here we summarize the mathematics and computer methods behind using the CVE for Gaussianity testing in time series. In particular, we describe how to perform Gaussianity testing in a step-by-step fashion for experimental data using the Hilbert transform, showing that the sampling rate as well as the duration and the filtering of the data stream affect the analysis. Additionally, through the use of the Fourier transform phase randomization, we reveal the interconnections among CVE, Gaussianity, and temporal modulation profiles. Furthermore, we use the CVE to assess the degree of synchronization in Kuramoto and Matthews-Mirollo-Strogatz models and show that CVE is relevant to the study of coupled oscillators systems. CVE Gaussianity testing provides a new tool for signal classification.
Neural System Level Synthesis: Learning over All Stabilizing Policies for Nonlinear Systems
Mar 22, 2022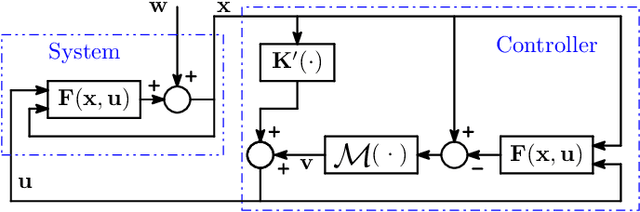

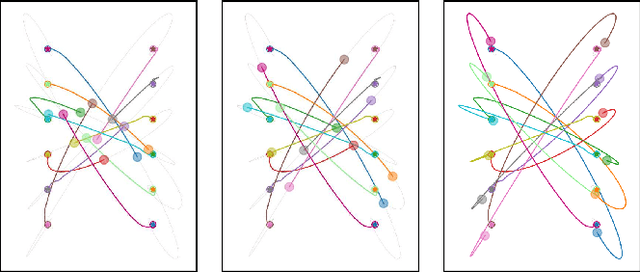
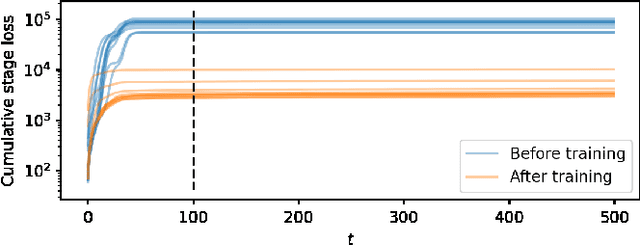
We address the problem of designing stabilizing control policies for nonlinear systems in discrete-time, while minimizing an arbitrary cost function. When the system is linear and the cost is convex, the System Level Synthesis (SLS) approach offers an exact solution based on convex programming. Beyond this case, a globally optimal solution cannot be found in a tractable way, in general. In this paper, we develop a parametrization of all and only the control policies stabilizing a given time-varying nonlinear system in terms of the combined effect of 1) a strongly stabilizing base controller and 2) a stable SLS operator to be freely designed. Based on this result, we propose a Neural SLS (Neur-SLS) approach guaranteeing closed-loop stability during and after parameter optimization, without requiring any constraints to be satisfied. We exploit recent Deep Neural Network (DNN) models based on Recurrent Equilibrium Networks (RENs) to learn over a rich class of nonlinear stable operators, and demonstrate the effectiveness of the proposed approach in numerical examples.
Robust and Efficient Medical Imaging with Self-Supervision
May 19, 2022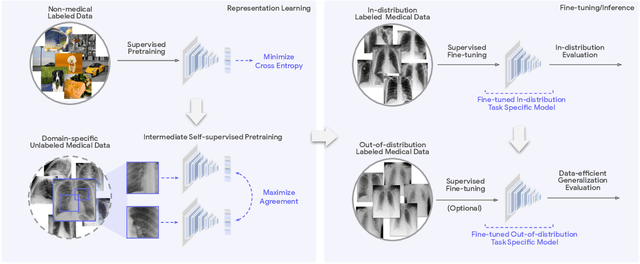
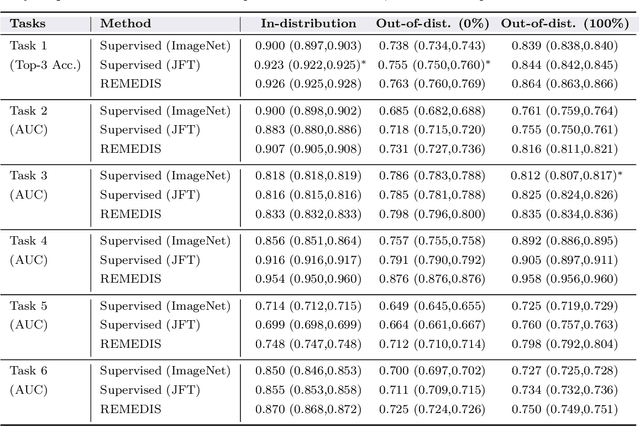
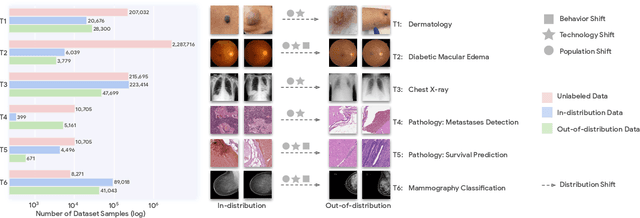

Recent progress in Medical Artificial Intelligence (AI) has delivered systems that can reach clinical expert level performance. However, such systems tend to demonstrate sub-optimal "out-of-distribution" performance when evaluated in clinical settings different from the training environment. A common mitigation strategy is to develop separate systems for each clinical setting using site-specific data [1]. However, this quickly becomes impractical as medical data is time-consuming to acquire and expensive to annotate [2]. Thus, the problem of "data-efficient generalization" presents an ongoing difficulty for Medical AI development. Although progress in representation learning shows promise, their benefits have not been rigorously studied, specifically for out-of-distribution settings. To meet these challenges, we present REMEDIS, a unified representation learning strategy to improve robustness and data-efficiency of medical imaging AI. REMEDIS uses a generic combination of large-scale supervised transfer learning with self-supervised learning and requires little task-specific customization. We study a diverse range of medical imaging tasks and simulate three realistic application scenarios using retrospective data. REMEDIS exhibits significantly improved in-distribution performance with up to 11.5% relative improvement in diagnostic accuracy over a strong supervised baseline. More importantly, our strategy leads to strong data-efficient generalization of medical imaging AI, matching strong supervised baselines using between 1% to 33% of retraining data across tasks. These results suggest that REMEDIS can significantly accelerate the life-cycle of medical imaging AI development thereby presenting an important step forward for medical imaging AI to deliver broad impact.
Introducing Block-Toeplitz Covariance Matrices to Remaster Linear Discriminant Analysis for Event-related Potential Brain-computer Interfaces
Feb 16, 2022
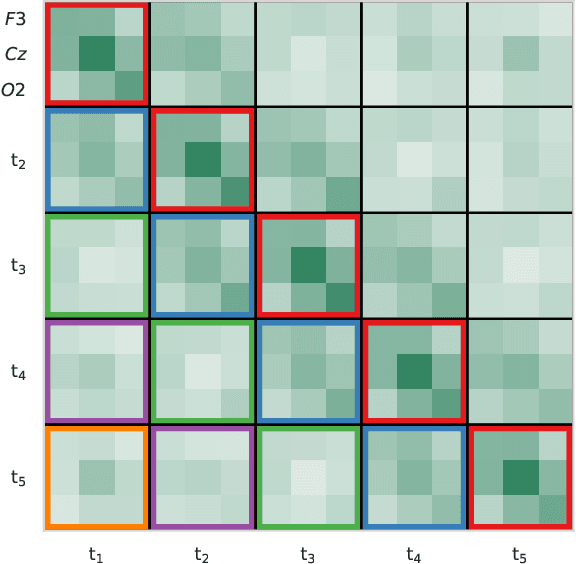
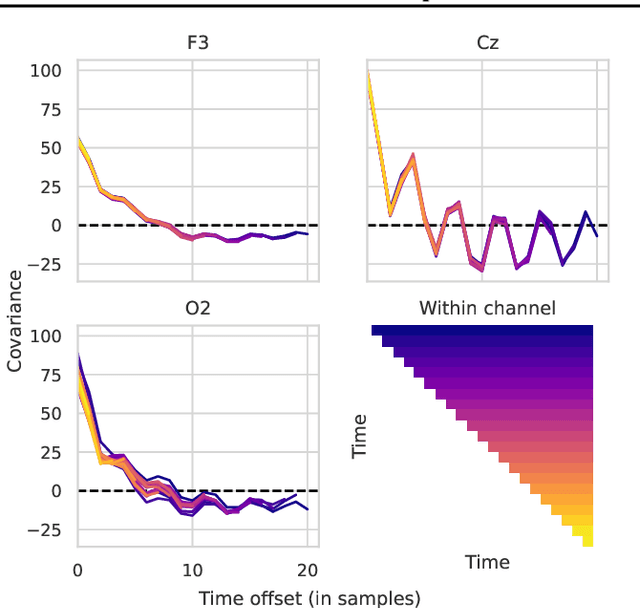
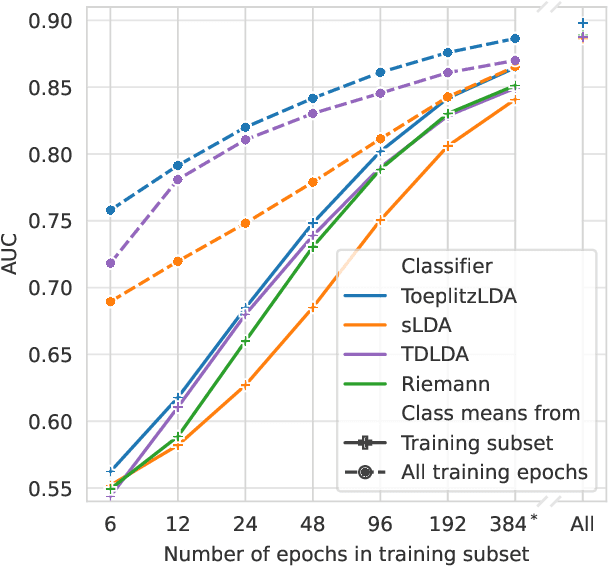
Covariance matrices of noisy multichannel electroencephalogram time series data are hard to estimate due to high dimensionality. In brain-computer interfaces (BCI) based on event-related potentials and a linear discriminant analysis (LDA) for classification, the state of the art to address this problem is by shrinkage regularization. We propose a novel idea to tackle this problem by enforcing a block-Toeplitz structure for the covariance matrix of the LDA, which implements an assumption of signal stationarity in short time windows for each channel. On data of 213 subjects collected under 13 event-related potential BCI protocols, the resulting 'ToeplitzLDA' significantly increases the binary classification performance compared to shrinkage regularized LDA (up to 6 AUC points) and Riemannian classification approaches (up to 2 AUC points). This translates to greatly improved application level performances, as exemplified on data recorded during an unsupervised visual speller application, where spelling errors could be reduced by 81% on average for 25 subjects. Aside from lower memory and time complexity for LDA training, ToeplitzLDA proved to be almost invariant even to a twenty-fold time dimensionality enlargement, which reduces the need of expert knowledge regarding feature extraction.
S-DABT: Schedule and Dependency-Aware Bug Triage in Open-Source Bug Tracking Systems
Apr 12, 2022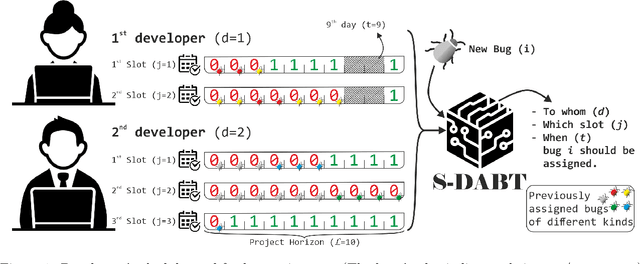
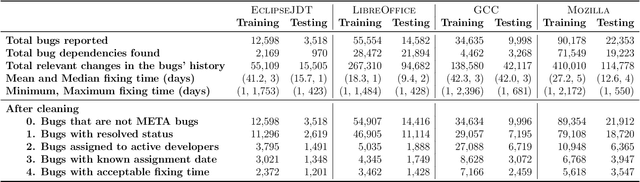
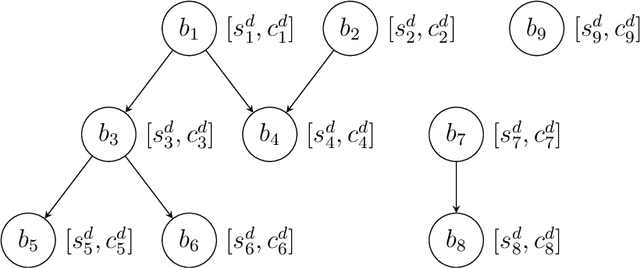
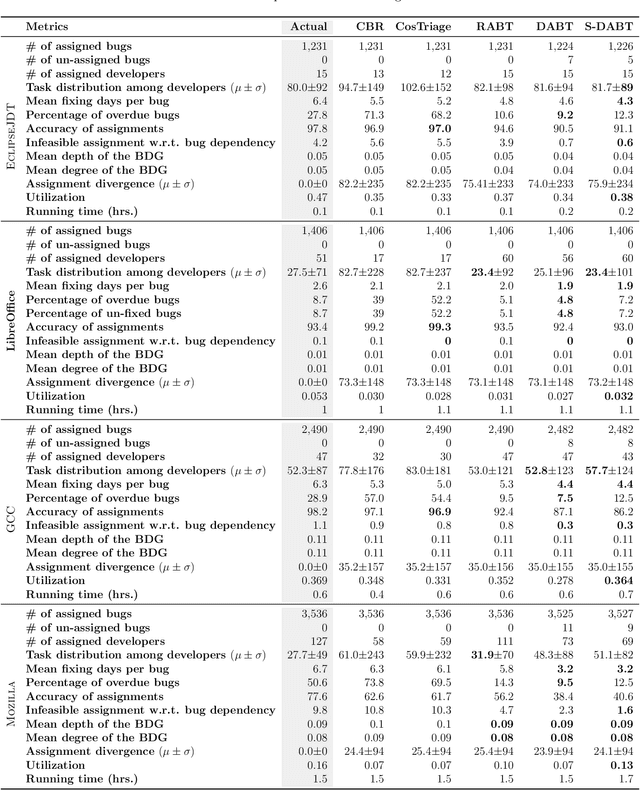
Fixing bugs in a timely manner lowers various potential costs in software maintenance. However, manual bug fixing scheduling can be time-consuming, cumbersome, and error-prone. In this paper, we propose the Schedule and Dependency-aware Bug Triage (S-DABT), a bug triaging method that utilizes integer programming and machine learning techniques to assign bugs to suitable developers. Unlike prior works that largely focus on a single component of the bug reports, our approach takes into account the textual data, bug fixing costs, and bug dependencies. We further incorporate the schedule of developers in our formulation to have a more comprehensive model for this multifaceted problem. As a result, this complete formulation considers developers' schedules and the blocking effects of the bugs while covering the most significant aspects of the previously proposed methods. Our numerical study on four open-source software systems, namely, EclipseJDT, LibreOffice, GCC, and Mozilla, shows that taking into account the schedules of the developers decreases the average bug fixing times. We find that S-DABT leads to a high level of developer utilization through a fair distribution of the tasks among the developers and efficient use of the free spots in their schedules. Via the simulation of the issue tracking system, we also show how incorporating the schedule in the model formulation reduces the bug fixing time, improves the assignment accuracy, and utilizes the capability of each developer without much comprising in the model run times. We find that S-DABT decreases the complexity of the bug dependency graph by prioritizing blocking bugs and effectively reduces the infeasible assignment ratio due to bug dependencies. Consequently, we recommend considering developers' schedules while automating bug triage.
PetsGAN: Rethinking Priors for Single Image Generation
Mar 03, 2022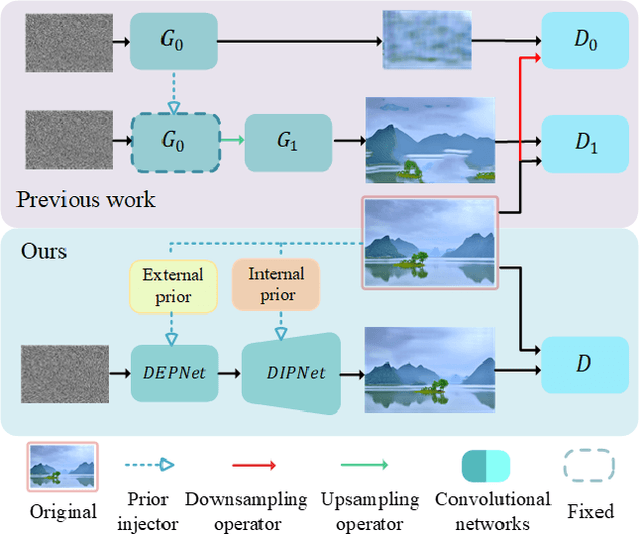
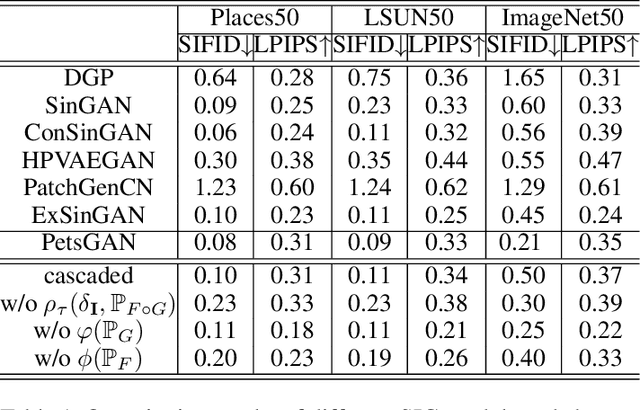

Single image generation (SIG), described as generating diverse samples that have similar visual content with the given single image, is first introduced by SinGAN which builds a pyramid of GANs to progressively learn the internal patch distribution of the single image. It also shows great potentials in a wide range of image manipulation tasks. However, the paradigm of SinGAN has limitations in terms of generation quality and training time. Firstly, due to the lack of high-level information, SinGAN cannot handle the object images well as it does on the scene and texture images. Secondly, the separate progressive training scheme is time-consuming and easy to cause artifact accumulation. To tackle these problems, in this paper, we dig into the SIG problem and improve SinGAN by fully-utilization of internal and external priors. The main contributions of this paper include: 1) We introduce to SIG a regularized latent variable model. To the best of our knowledge, it is the first time to give a clear formulation and optimization goal of SIG, and all the existing methods for SIG can be regarded as special cases of this model. 2) We design a novel Prior-based end-to-end training GAN (PetsGAN) to overcome the problems of SinGAN. Our method gets rid of the time-consuming progressive training scheme and can be trained end-to-end. 3) We construct abundant qualitative and quantitative experiments to show the superiority of our method on both generated image quality, diversity, and the training speed. Moreover, we apply our method to other image manipulation tasks (e.g., style transfer, harmonization), and the results further prove the effectiveness and efficiency of our method.
COSTI: a New Classifier for Sequences of Temporal Intervals
Apr 28, 2022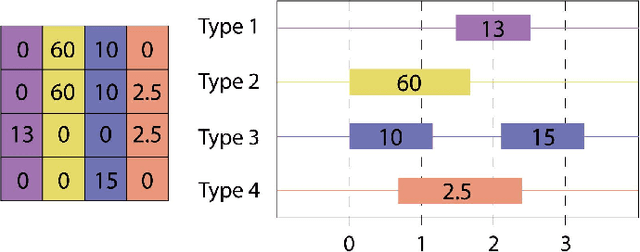
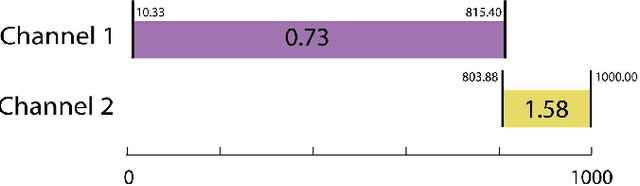
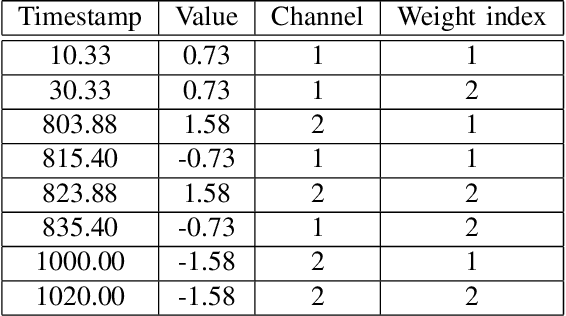
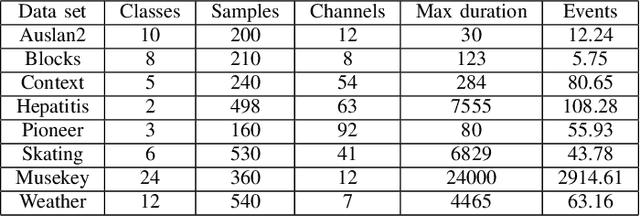
Classification of sequences of temporal intervals is a part of time series analysis which concerns series of events. We propose a new method of transforming the problem to a task of multivariate series classification. We use one of the state-of-the-art algorithms from the latter domain on the new representation to obtain significantly better accuracy than the state-of-the-art methods from the former field. We discuss limitations of this workflow and address them by developing a novel method for classification termed COSTI (short for Classification of Sequences of Temporal Intervals) operating directly on sequences of temporal intervals. The proposed method remains at a high level of accuracy and obtains better performance while avoiding shortcomings connected to operating on transformed data. We propose a generalized version of the problem of classification of temporal intervals, where each event is supplemented with information about its intensity. We also provide two new data sets where this information is of substantial value.