 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Digital Twins for Dynamic Management of Blockchain Systems
Apr 26, 2022
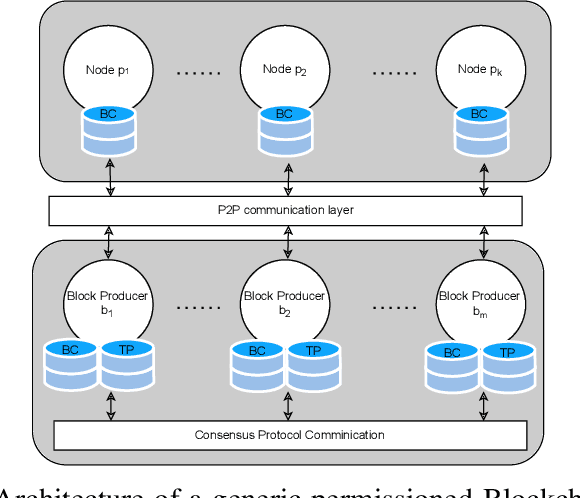
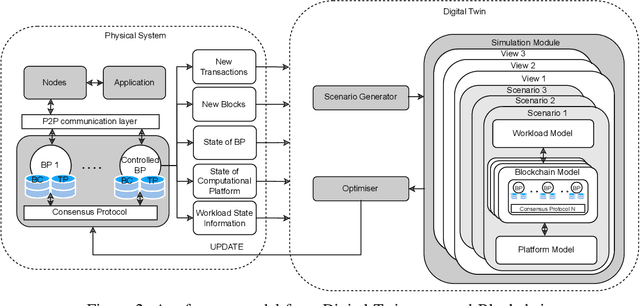
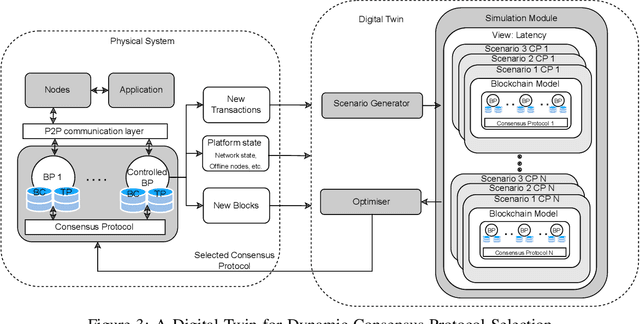
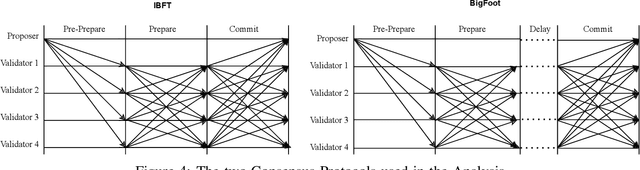
Blockchain systems are challenged by the so-called Trilemma tradeoff: decentralization, scalability and security. Infrastructure and node configuration, choice of the Consensus Protocol and complexity of the application transactions are cited amongst the factors that affect the tradeoffs balance. Given that Blockchains are complex, dynamic dynamic systems, a dynamic approach to their management and reconfiguration at runtime is deemed necessary to reflect the changes in the state of the infrastructure and application. This paper introduces the utilisation of Digital Twins for this purpose. The novel contribution of the paper is design of a framework and conceptual architecture of a Digital Twin that can assist in maintaining the Trilemma tradeoffs of time critical systems. The proposed Digital Twin is illustrated via an innovative approach to dynamic selection of Consensus Protocols. Simulations results show that the proposed framework can effectively support the dynamic adaptation and management of the Blockchain
Differentiable Zooming for Multiple Instance Learning on Whole-Slide Images
Apr 26, 2022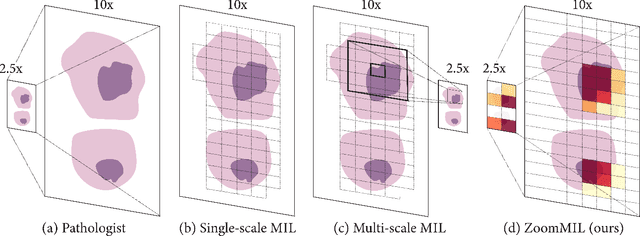
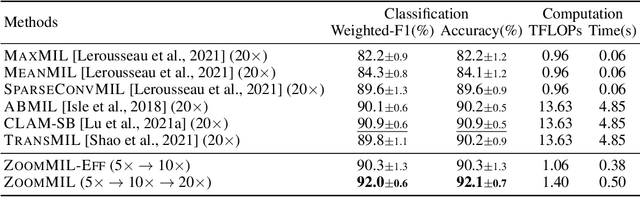
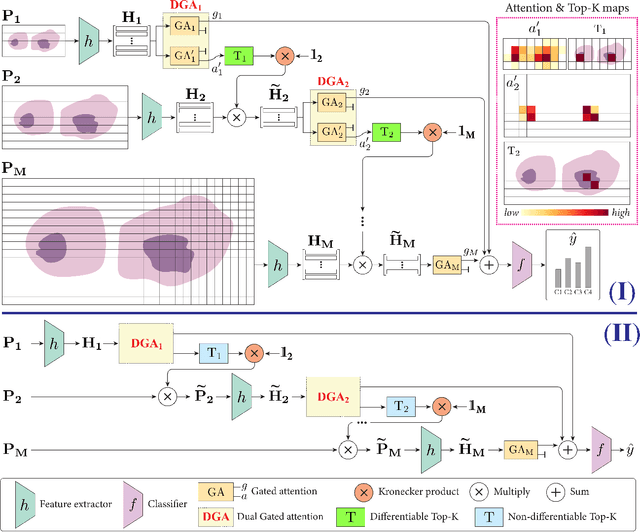
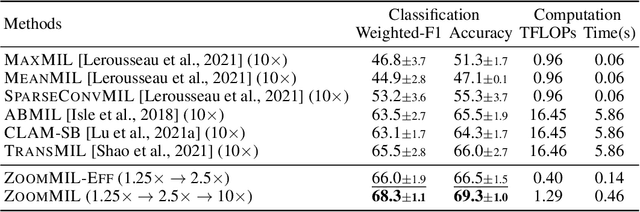
Multiple Instance Learning (MIL) methods have become increasingly popular for classifying giga-pixel sized Whole-Slide Images (WSIs) in digital pathology. Most MIL methods operate at a single WSI magnification, by processing all the tissue patches. Such a formulation induces high computational requirements, and constrains the contextualization of the WSI-level representation to a single scale. A few MIL methods extend to multiple scales, but are computationally more demanding. In this paper, inspired by the pathological diagnostic process, we propose ZoomMIL, a method that learns to perform multi-level zooming in an end-to-end manner. ZoomMIL builds WSI representations by aggregating tissue-context information from multiple magnifications. The proposed method outperforms the state-of-the-art MIL methods in WSI classification on two large datasets, while significantly reducing the computational demands with regard to Floating-Point Operations (FLOPs) and processing time by up to 40x.
Source Domain Subset Sampling for Semi-Supervised Domain Adaptation in Semantic Segmentation
May 03, 2022
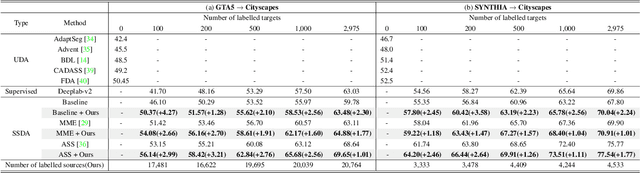
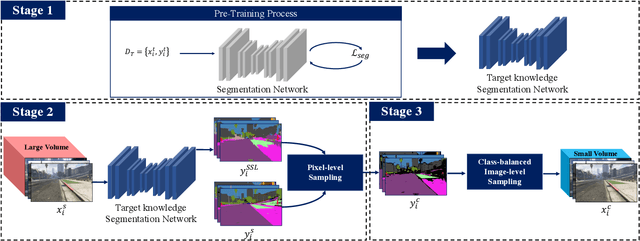
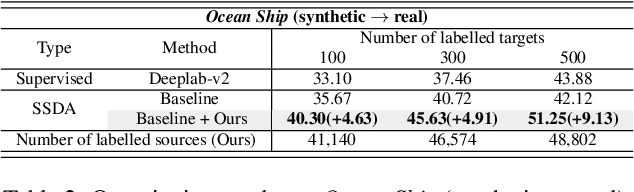
In this paper, we introduce source domain subset sampling (SDSS) as a new perspective of semi-supervised domain adaptation. We propose domain adaptation by sampling and exploiting only a meaningful subset from source data for training. Our key assumption is that the entire source domain data may contain samples that are unhelpful for the adaptation. Therefore, the domain adaptation can benefit from a subset of source data composed solely of helpful and relevant samples. The proposed method effectively subsamples full source data to generate a small-scale meaningful subset. Therefore, training time is reduced, and performance is improved with our subsampled source data. To further verify the scalability of our method, we construct a new dataset called Ocean Ship, which comprises 500 real and 200K synthetic sample images with ground-truth labels. The SDSS achieved a state-of-the-art performance when applied on GTA5 to Cityscapes and SYNTHIA to Cityscapes public benchmark datasets and a 9.13 mIoU improvement on our Ocean Ship dataset over a baseline model.
Sampling Complexity of Path Integral Methods for Trajectory Optimization
Mar 18, 2022
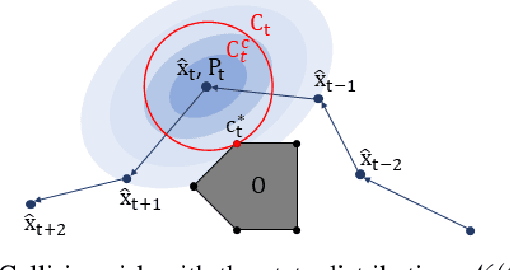
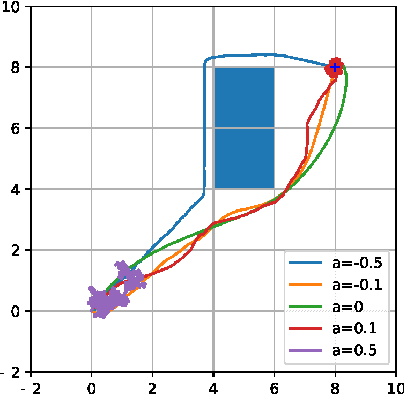
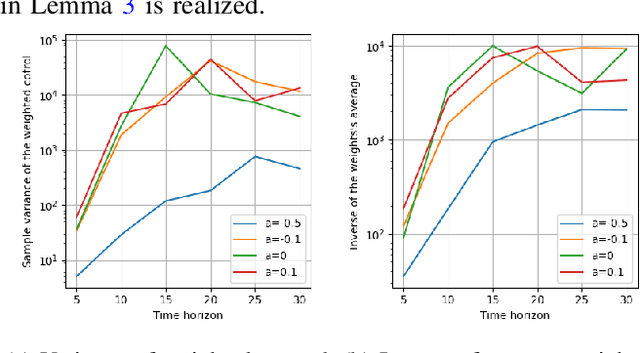
The use of random sampling in decision-making and control has become popular with the ease of access to graphic processing units that can generate and calculate multiple random trajectories for real-time robotic applications. In contrast to sequential optimization, the sampling-based method can take advantage of parallel computing to maintain constant control loop frequencies. Inspired by its wide applicability in robotic applications, we calculate a sampling complexity result applicable to general nonlinear systems considered in the path integral method, which is a sampling-based method. The result determines the required number of samples to satisfy the given error bounds of the estimated control signal from the optimal value with the predefined risk probability. The sampling complexity result shows that the variance of the estimated control value is upper-bounded in terms of the expectation of the cost. Then we apply the result to a linear time-varying dynamical system with quadratic cost and an indicator function cost to avoid constraint sets.
Efficient dynamic filter for robust and low computational feature extraction
May 03, 2022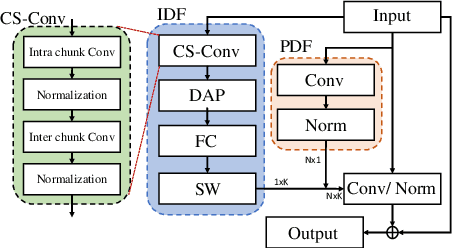
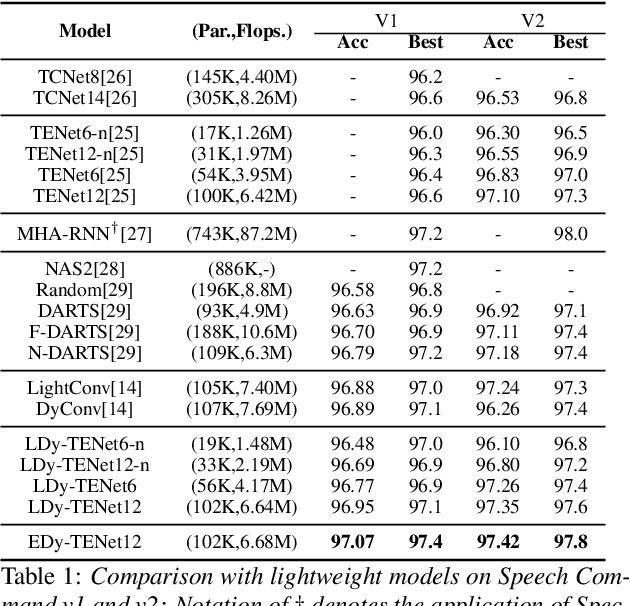
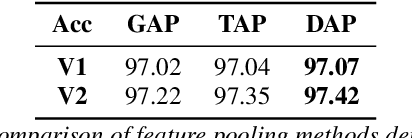
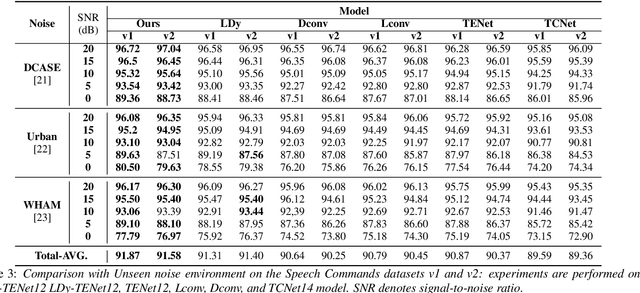
Unseen noise signal which is not considered in a model training process is difficult to anticipate and would lead to performance degradation. Various methods have been investigated to mitigate unseen noise. In our previous work, an Instance-level Dynamic Filter (IDF) and a Pixel Dynamic Filter (PDF) were proposed to extract noise-robust features. However, the performance of the dynamic filter might be degraded since simple feature pooling is used to reduce the computational resource in the IDF part. In this paper, we propose an efficient dynamic filter to enhance the performance of the dynamic filter. Instead of utilizing the simple feature mean, we separate Time-Frequency (T-F) features as non-overlapping chunks, and separable convolutions are carried out for each feature direction (inter chunks and intra chunks). Additionally, we propose Dynamic Attention Pooling that maps high dimensional features as low dimensional feature embeddings. These methods are applied to the IDF for keyword spotting and speaker verification tasks. We confirm that our proposed method performs better in unseen environments (unseen noise and unseen speakers) than state-of-the-art models.
Competitors-Aware Stochastic Lap Strategy Optimisation for Race Hybrid Vehicles
Feb 28, 2022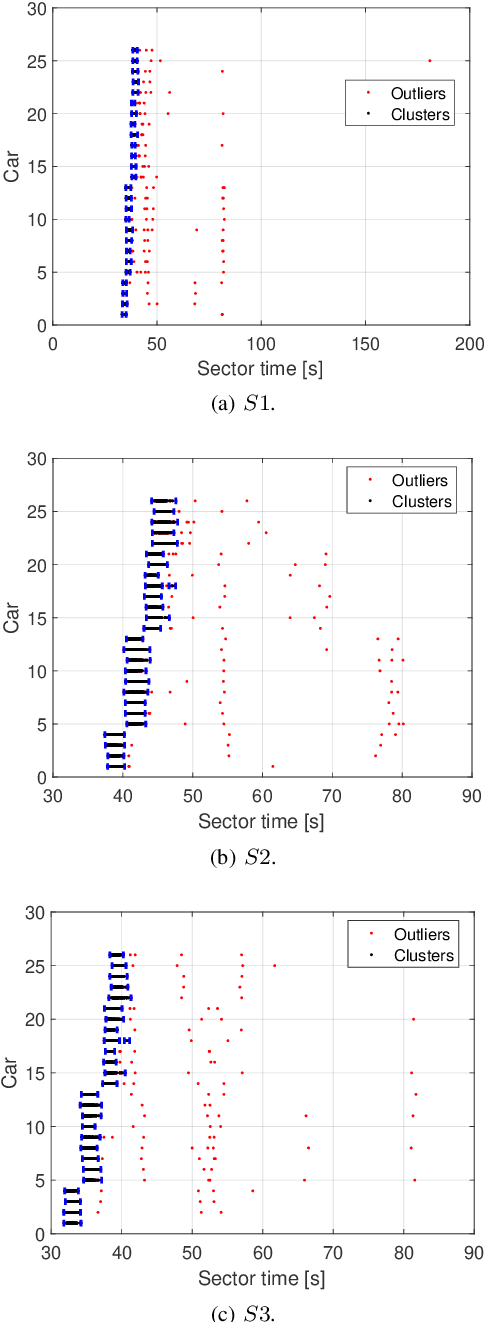
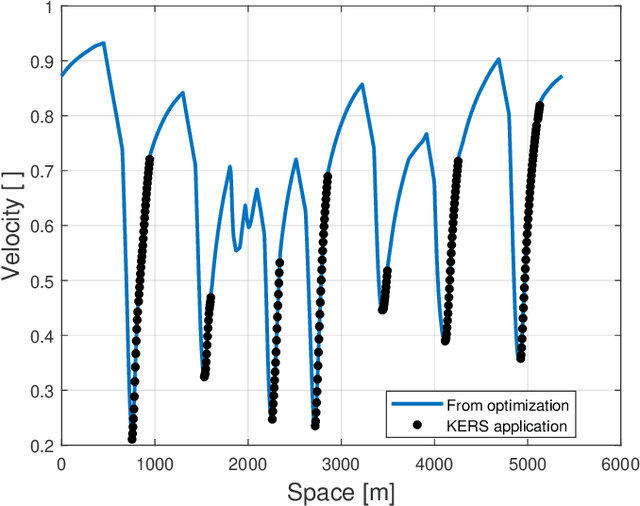
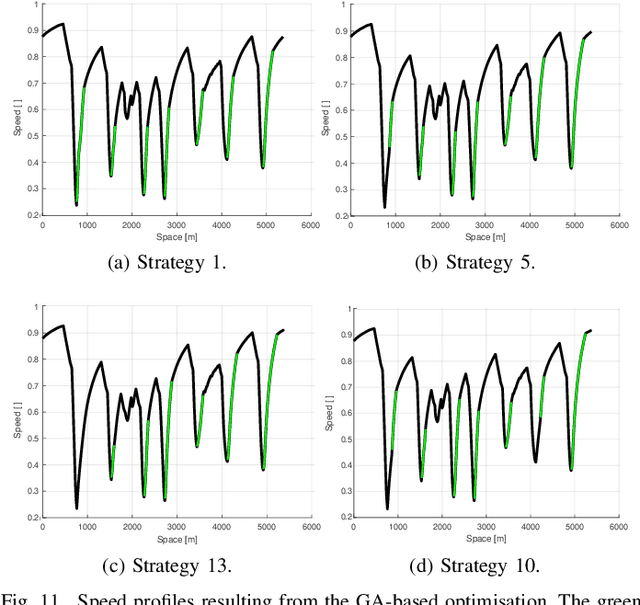
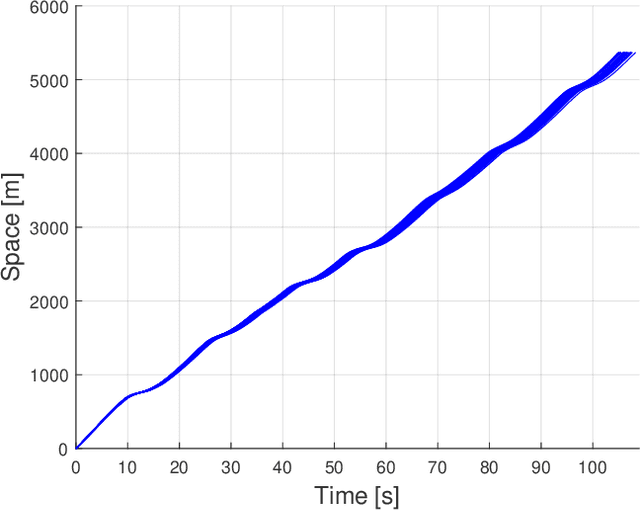
World Endurance Championship (WEC) racing events are characterised by a relevant performance gap among competitors. The fastest vehicles category, consisting in hybrid vehicles, has to respect energy usage constraints set by the technical regulation. Considering absence of competitors, i.e. traffic conditions, the optimal energy usage strategy for lap time minimisation is typically computed through a constrained optimisation problem. To the best of our knowledge, the majority of state-of-the-art works neglects competitors. This leads to a mismatch with the real world, where traffic generates considerable time losses. To bridge this gap, we propose a new framework to offline compute optimal strategies for the powertrain energy management considering competitors. Through analysis of the available data from previous events, statistics on the sector times and overtaking probabilities are extracted to encode the competitors' behaviour. Adopting a multi-agent model, the statistics are then used to generate realistic Monte Carlo (MC) simulation of their position along the track. The simulator is then adopted to identify the optimal strategy as follows. We develop a longitudinal vehicle model for the ego-vehicle and implement an optimisation problem for lap time minimisation in absence of traffic, based on Genetic Algorithms. Solving the optimisation problem for a variety of constraints generates a set of candidate optimal strategies. Stochastic Dynamic Programming is finally implemented to choose the best strategy considering competitors, whose motion is generated by the MC simulator. Our approach, validated on data from a real stint of race, allows to significantly reduce the lap time.
Time-Supervised Primary Object Segmentation
Aug 16, 2020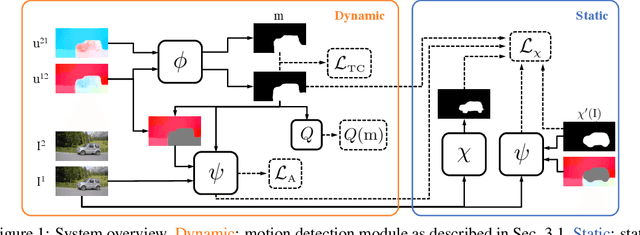



We describe an unsupervised method to detect and segment portions of live scenes that, at some point in time, are seen moving as a coherent whole, which we refer to as primary objects. Our method first segments motions by minimizing the mutual information between partitions of the image domain, which bootstraps a static object detection model that takes a single image as input. The two models are mutually reinforced within a feedback loop, enabling extrapolation to previously unseen classes of objects. Our method requires video for training, but can be used on either static images or videos at inference time. As the volume of our training sets grows, more and more objects are seen moving, thus turning our method into unsupervised (or time-supervised) training to segment primary objects. The resulting system outperforms the state-of-the-art in both video object segmentation and salient object detection benchmarks, even when compared to methods that use explicit manual annotation.
A Machine Learning Approach for Prosumer Management in Intraday Electricity Markets
Mar 11, 2022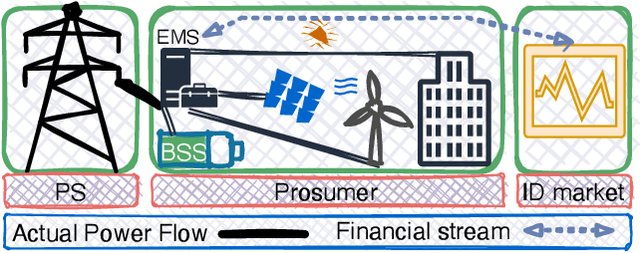
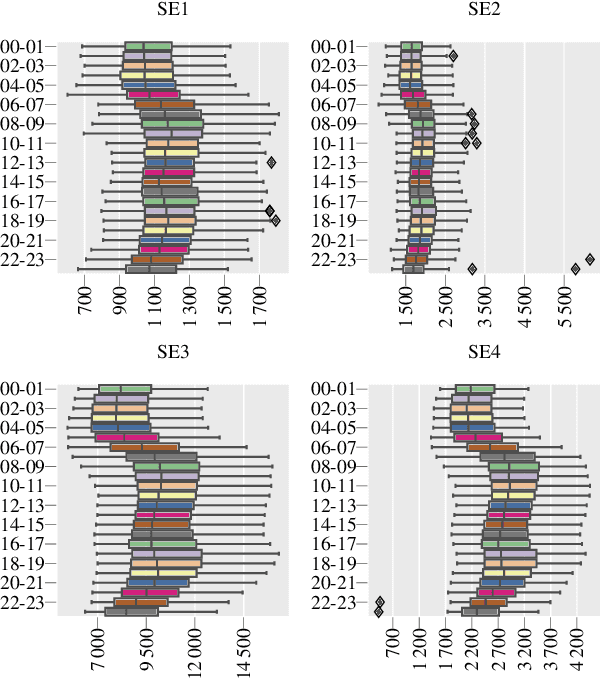
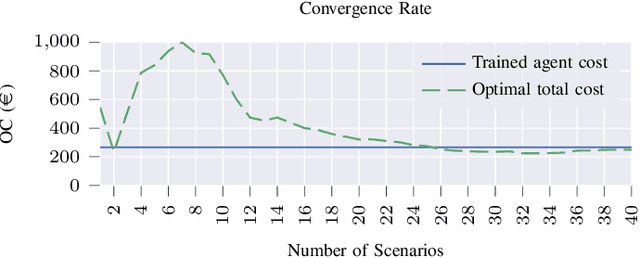
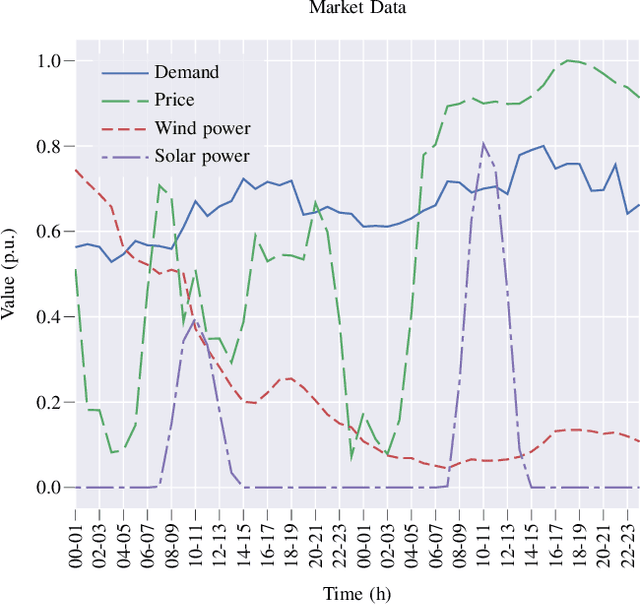
Prosumer operators are dealing with extensive challenges to participate in short-term electricity markets while taking uncertainties into account. Challenges such as variation in demand, solar energy, wind power, and electricity prices as well as faster response time in intraday electricity markets. Machine learning approaches could resolve these challenges due to their ability to continuous learning of complex relations and providing a real-time response. Such approaches are applicable with presence of the high performance computing and big data. To tackle these challenges, a Markov decision process is proposed and solved with a reinforcement learning algorithm with proper observations and actions employing tabular Q-learning. Trained agent converges to a policy which is similar to the global optimal solution. It increases the prosumer's profit by 13.39% compared to the well-known stochastic optimization approach.
Modelling Evolutionary and Stationary User Preferences for Temporal Sets Prediction
Apr 13, 2022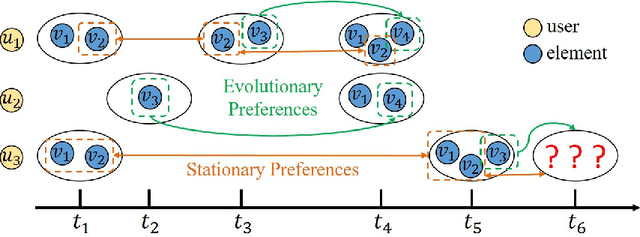

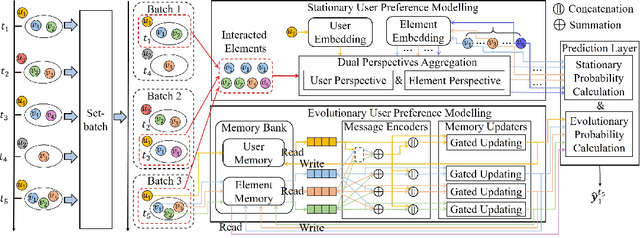

Given a sequence of sets, where each set is associated with a timestamp and contains an arbitrary number of elements, the task of temporal sets prediction aims to predict the elements in the subsequent set. Previous studies for temporal sets prediction mainly capture each user's evolutionary preference by learning from his/her own sequence. Although insightful, we argue that: 1) the collaborative signals latent in different users' sequences are essential but have not been exploited; 2) users also tend to show stationary preferences while existing methods fail to consider. To this end, we propose an integrated learning framework to model both the evolutionary and the stationary preferences of users for temporal sets prediction, which first constructs a universal sequence by chronologically arranging all the user-set interactions, and then learns on each user-set interaction. In particular, for each user-set interaction, we first design an evolutionary user preference modelling component to track the user's time-evolving preference and exploit the latent collaborative signals among different users. This component maintains a memory bank to store memories of the related user and elements, and continuously updates their memories based on the currently encoded messages and the past memories. Then, we devise a stationary user preference modelling module to discover each user's personalized characteristics according to the historical sequence, which adaptively aggregates the previously interacted elements from dual perspectives with the guidance of the user's and elements' embeddings. Finally, we develop a set-batch algorithm to improve the model efficiency, which can create time-consistent batches in advance and achieve 3.5x training speedups on average. Experiments on real-world datasets demonstrate the effectiveness and good interpretability of our approach.
A Framework for Interactive Knowledge-Aided Machine Teaching
Apr 21, 2022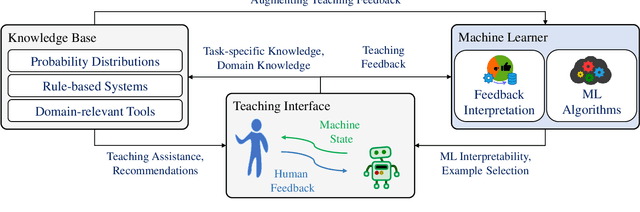
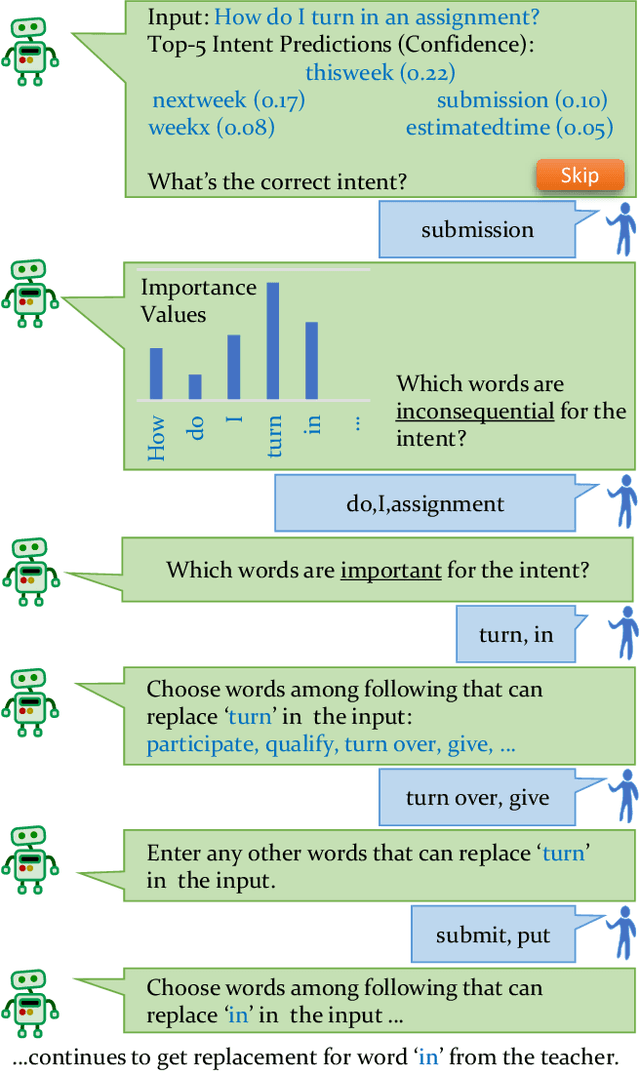
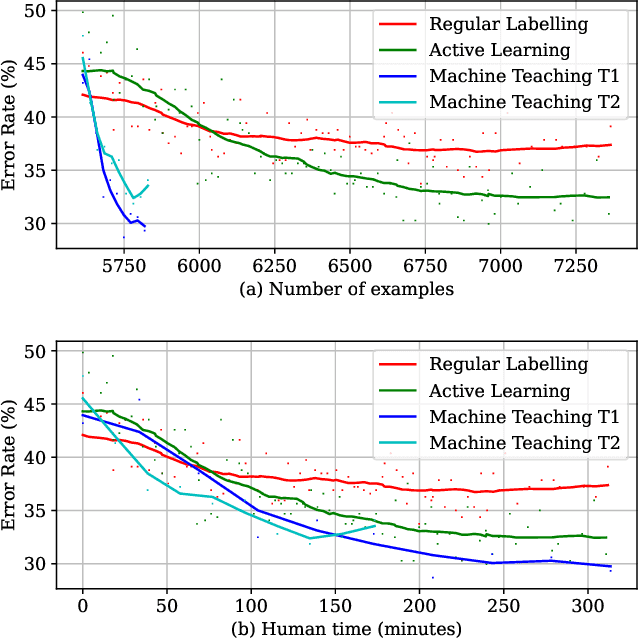
Machine Teaching (MT) is an interactive process where humans train a machine learning model by playing the role of a teacher. The process of designing an MT system involves decisions that can impact both efficiency of human teachers and performance of machine learners. Previous research has proposed and evaluated specific MT systems but there is limited discussion on a general framework for designing them. We propose a framework for designing MT systems and also detail a system for the text classification problem as a specific instance. Our framework focuses on three components i.e. teaching interface, machine learner, and knowledge base; and their relations describe how each component can benefit the others. Our preliminary experiments show how MT systems can reduce both human teaching time and machine learner error rate.