 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Search of Relevant Points for Nearest-Neighbor Classification
Mar 07, 2022
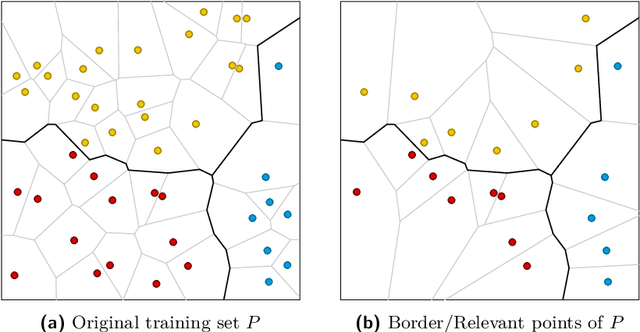
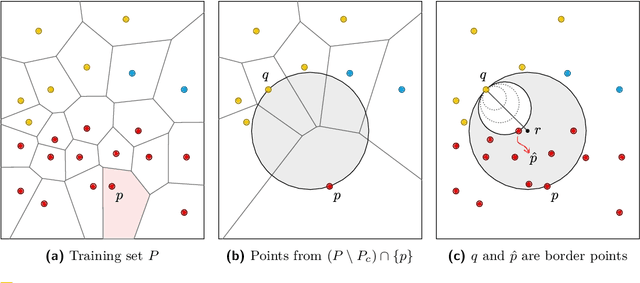
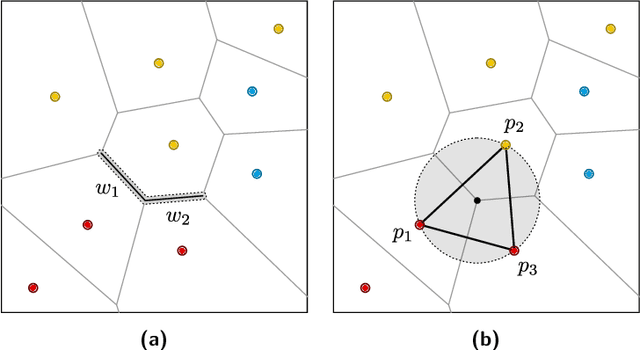
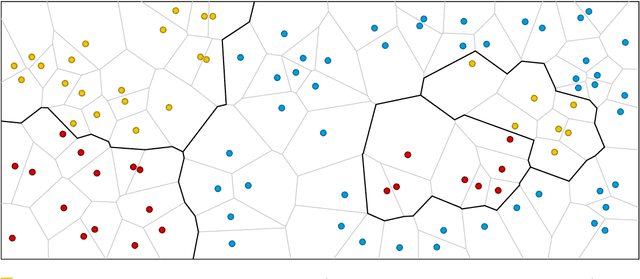
Given a training set $P \subset \mathbb{R}^d$, the nearest-neighbor classifier assigns any query point $q \in \mathbb{R}^d$ to the class of its closest point in $P$. To answer these classification queries, some training points are more relevant than others. We say a training point is relevant if its omission from the training set could induce the misclassification of some query point in $\mathbb{R}^d$. These relevant points are commonly known as border points, as they define the boundaries of the Voronoi diagram of $P$ that separate points of different classes. Being able to compute this set of points efficiently is crucial to reduce the size of the training set without affecting the accuracy of the nearest-neighbor classifier. Improving over a decades-long result by Clarkson, in a recent paper by Eppstein an output-sensitive algorithm was proposed to find the set of border points of $P$ in $O( n^2 + nk^2 )$ time, where $k$ is the size of such set. In this paper, we improve this algorithm to have time complexity equal to $O( nk^2 )$ by proving that the first steps of their algorithm, which require $O( n^2 )$ time, are unnecessary.
Channel Estimation based on Gaussian Mixture Models with Structured Covariances
May 07, 2022

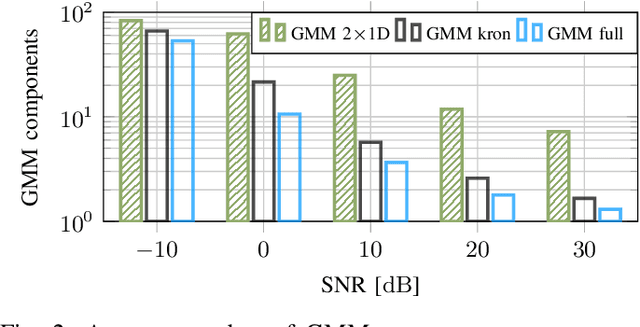
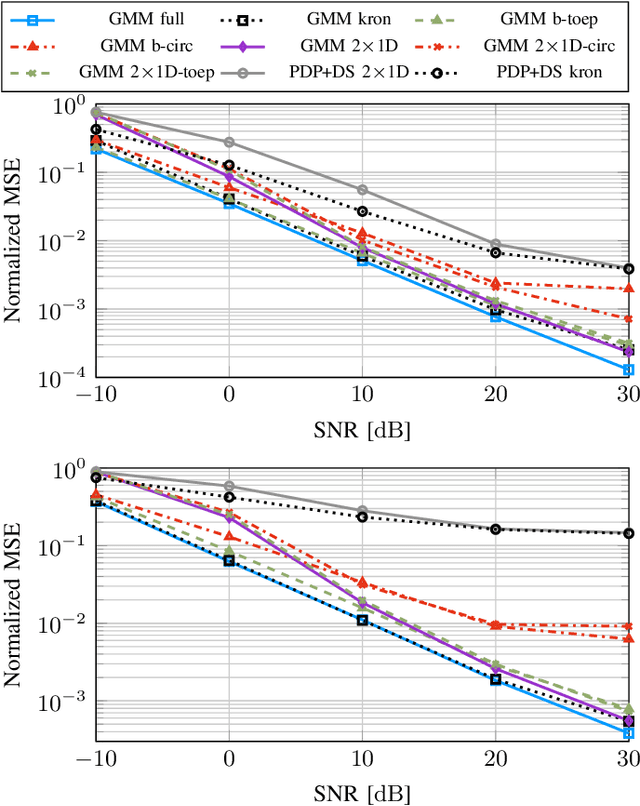
In this work, we propose variations of a Gaussian mixture model (GMM) based channel estimator that was recently proven to be asymptotically optimal in the minimum mean square error (MMSE) sense. We account for the need of low computational complexity in the online estimation and low cost for training and storage in practical applications. To this end, we discuss modifications of the underlying expectation-maximization (EM) algorithm, which is needed to fit the parameters of the GMM, to allow for structurally constrained covariances. Further, we investigate splitting the 2D time and frequency estimation problem in wideband systems into cascaded 1D estimations with the help of the GMM. The proposed cascaded GMM approach drastically reduces the complexity and memory requirements. We observe that due to the training on realistic channel data, the proposed GMM estimators seem to inherently perform a trade-off between saving complexity/parameters and estimation performance. We compare these low-complexity approaches to a practical and low cost method that relies on the power delay profile (PDP) and the Doppler spectrum (DS). We argue that, with the training on scenario-specific data from the environment, these practical baselines are outperformed by far with equal estimation complexity.
Memorizing Transformers
Mar 16, 2022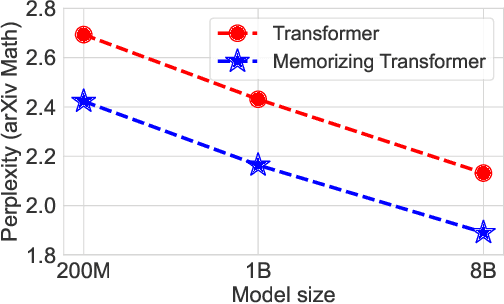
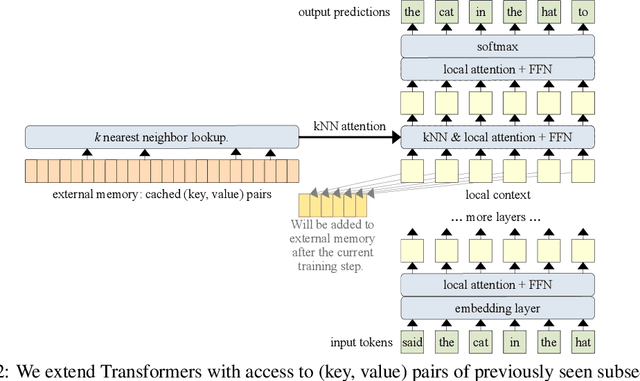

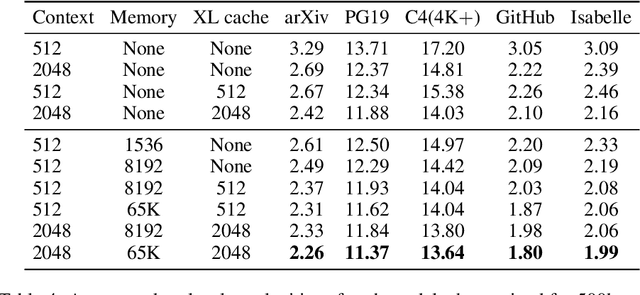
Language models typically need to be trained or finetuned in order to acquire new knowledge, which involves updating their weights. We instead envision language models that can simply read and memorize new data at inference time, thus acquiring new knowledge immediately. In this work, we extend language models with the ability to memorize the internal representations of past inputs. We demonstrate that an approximate kNN lookup into a non-differentiable memory of recent (key, value) pairs improves language modeling across various benchmarks and tasks, including generic webtext (C4), math papers (arXiv), books (PG-19), code (Github), as well as formal theorems (Isabelle). We show that the performance steadily improves when we increase the size of memory up to 262K tokens. On benchmarks including code and mathematics, we find that the model is capable of making use of newly defined functions and theorems during test time.
A Novel ISAC Transmission Framework based on Spatially-Spread Orthogonal Time Frequency Space Modulation
Sep 01, 2021
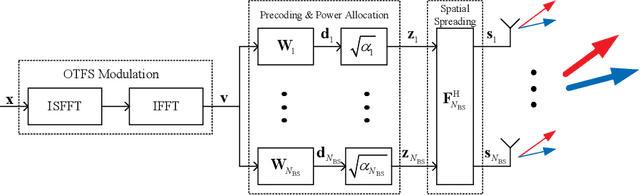

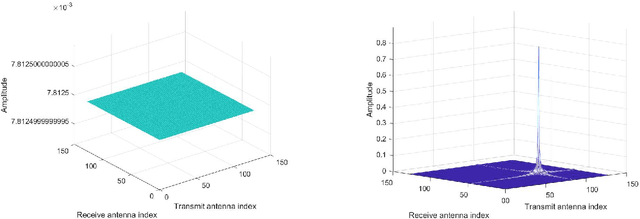
In this paper, we propose a novel integrated sensing and communication (ISAC) transmission framework based on the spatially-spread orthogonal time frequency space (SS-OTFS) modulation by considering the fact that communication channel strengths cannot be directly obtained from radar sensing. We first propose the concept of SS-OTFS modulation, where the key novelty is the angular domain discretization enabled by the spatial-spreading/de-spreading. This discretization gives rise to simple and insightful effective models for both radar sensing and communication, which result in simplified designs for the related estimation and detection problems. In particular, we design simple beam tracking, angle estimation, and power allocation schemes for radar sensing, by utilizing the special structure of the effective radar sensing matrix. Meanwhile, we provide a detailed analysis on the pair-wise error probability (PEP) for communication, which unveils the key conditions for both precoding and power allocation designs. Based on those conditions, we design a symbol-wise precoding scheme for communication based only on the delay, Doppler, and angle estimates from radar sensing, without the a priori knowledge of the communication channel fading coefficients, and also introduce the power allocation for communication. Furthermore, we notice that radar sensing and communication requires different power allocations. Therefore, we discuss the performances of both the radar sensing and communication with different power allocations and show that the power allocation should be designed leaning towards radar sensing in practical scenarios. The effectiveness of the proposed ISAC transmission framework is verified by our numerical results, which also agree with our analysis and discussions.
Restless Multi-Armed Bandits under Exogenous Global Markov Process
Feb 28, 2022
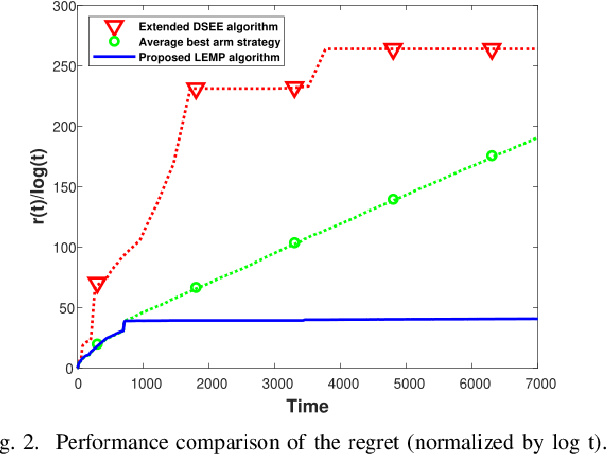
We consider an extension to the restless multi-armed bandit (RMAB) problem with unknown arm dynamics, where an unknown exogenous global Markov process governs the rewards distribution of each arm. Under each global state, the rewards process of each arm evolves according to an unknown Markovian rule, which is non-identical among different arms. At each time, a player chooses an arm out of N arms to play, and receives a random reward from a finite set of reward states. The arms are restless, that is, their local state evolves regardless of the player's actions. The objective is an arm-selection policy that minimizes the regret, defined as the reward loss with respect to a player that knows the dynamics of the problem, and plays at each time t the arm that maximizes the expected immediate value. We develop the Learning under Exogenous Markov Process (LEMP) algorithm, that achieves a logarithmic regret order with time, and a finite-sample bound on the regret is established. Simulation results support the theoretical study and demonstrate strong performances of LEMP.
RiskLoc: Localization of Multi-dimensional Root Causes by Weighted Risk
May 20, 2022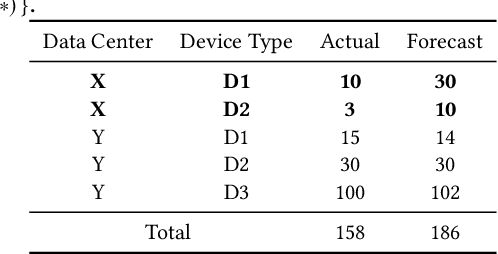
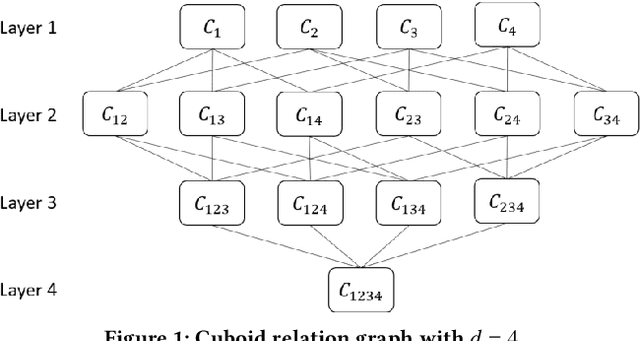
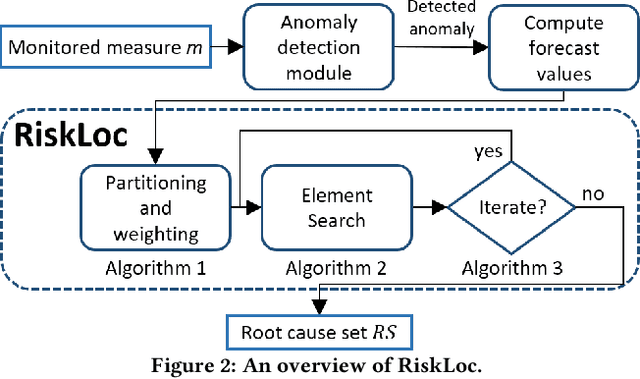
Failures and anomalies in large-scale software systems are unavoidable incidents. When an issue is detected, operators need to quickly and correctly identify its location to facilitate a swift repair. In this work, we consider the problem of identifying the root cause set that best explains an anomaly in multi-dimensional time series with categorical attributes. The huge search space is the main challenge, even for a small number of attributes and small value sets, the number of theoretical combinations is too large to brute force. Previous approaches have thus focused on reducing the search space, but they all suffer from various issues, requiring extensive manual parameter tuning, being too slow and thus impractical, or being incapable of finding more complex root causes. We propose RiskLoc to solve the problem of multidimensional root cause localization. RiskLoc applies a 2-way partitioning scheme and assigns element weights that linearly increase with the distance from the partitioning point. A risk score is assigned to each element that integrates two factors, 1) its weighted proportion within the abnormal partition, and 2) the relative change in the deviation score adjusted for the ripple effect property. Extensive experiments on multiple datasets verify the effectiveness and efficiency of RiskLoc, and for a comprehensive evaluation, we introduce three synthetically generated datasets that complement existing datasets. We demonstrate that RiskLoc consistently outperforms state-of-the-art baselines, especially in more challenging root cause scenarios, with gains in F1-score up to 57% over the second-best approach with comparable running times.
Robust Subset Selection by Greedy and Evolutionary Pareto Optimization
May 03, 2022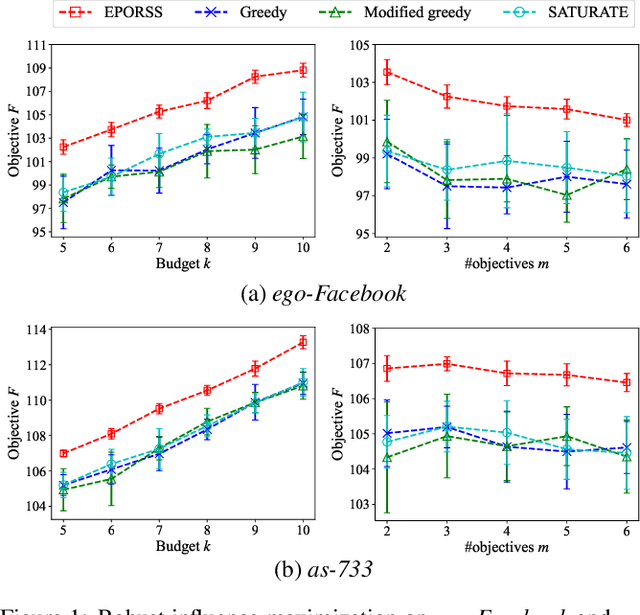
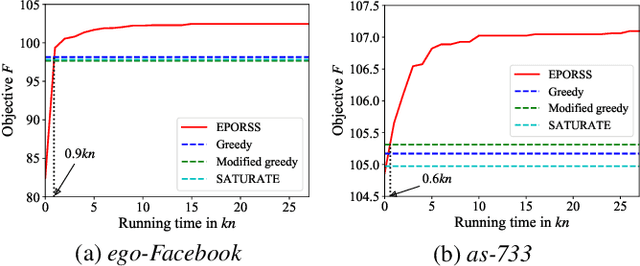
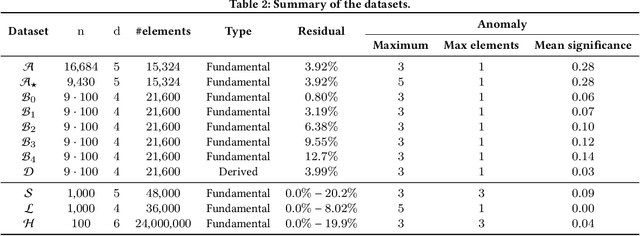
Subset selection, which aims to select a subset from a ground set to maximize some objective function, arises in various applications such as influence maximization and sensor placement. In real-world scenarios, however, one often needs to find a subset which is robust against (i.e., is good over) a number of possible objective functions due to uncertainty, resulting in the problem of robust subset selection. This paper considers robust subset selection with monotone objective functions, relaxing the submodular property required by previous studies. We first show that the greedy algorithm can obtain an approximation ratio of $1-e^{-\beta\opgamma}$, where $\beta$ and $\opgamma$ are the correlation and submodularity ratios of the objective functions, respectively; and then propose EPORSS, an evolutionary Pareto optimization algorithm that can utilize more time to find better subsets. We prove that EPORSS can also be theoretically grounded, achieving a similar approximation guarantee to the greedy algorithm. In addition, we derive the lower bound of $\beta$ for the application of robust influence maximization, and further conduct experiments to validate the performance of the greedy algorithm and EPORSS.
Learning Disentangled Textual Representations via Statistical Measures of Similarity
May 07, 2022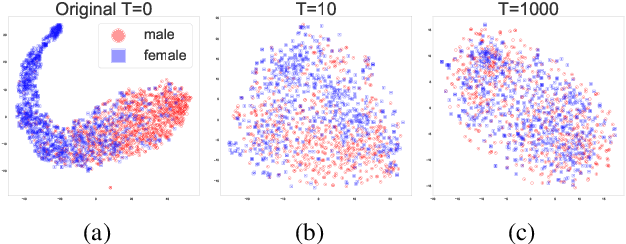
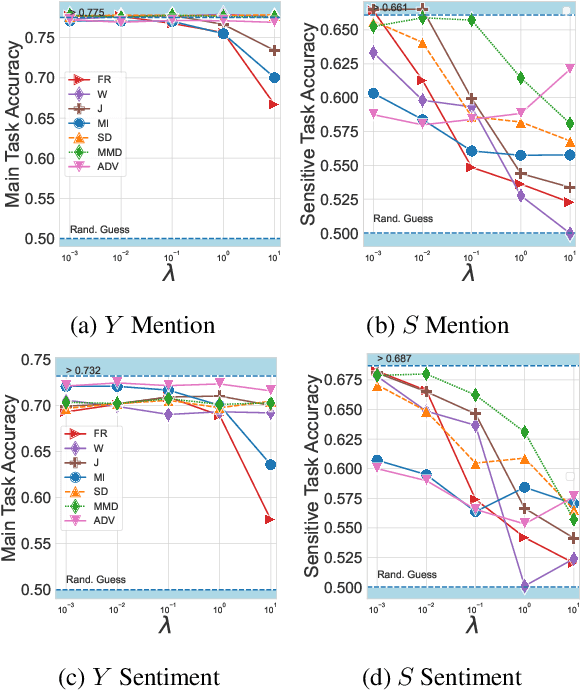
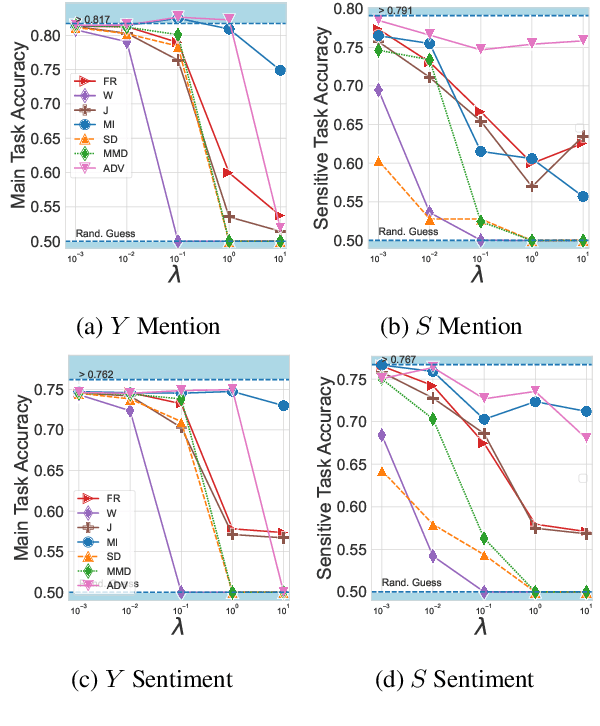
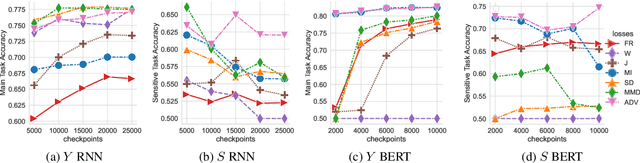
When working with textual data, a natural application of disentangled representations is fair classification where the goal is to make predictions without being biased (or influenced) by sensitive attributes that may be present in the data (e.g., age, gender or race). Dominant approaches to disentangle a sensitive attribute from textual representations rely on learning simultaneously a penalization term that involves either an adversarial loss (e.g., a discriminator) or an information measure (e.g., mutual information). However, these methods require the training of a deep neural network with several parameter updates for each update of the representation model. As a matter of fact, the resulting nested optimization loop is both time consuming, adding complexity to the optimization dynamic, and requires a fine hyperparameter selection (e.g., learning rates, architecture). In this work, we introduce a family of regularizers for learning disentangled representations that do not require training. These regularizers are based on statistical measures of similarity between the conditional probability distributions with respect to the sensitive attributes. Our novel regularizers do not require additional training, are faster and do not involve additional tuning while achieving better results both when combined with pretrained and randomly initialized text encoders.
Outdoor Monocular Depth Estimation: A Research Review
May 03, 2022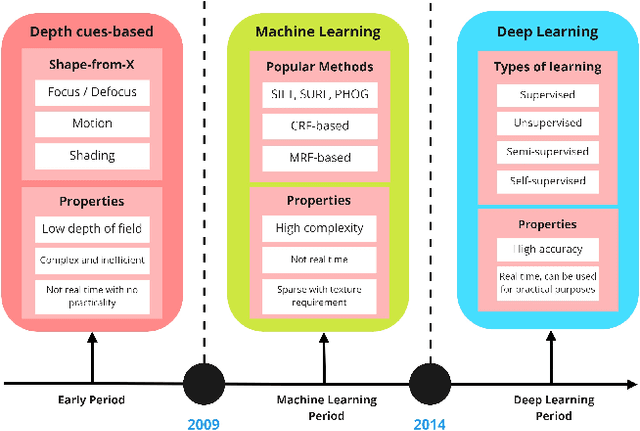
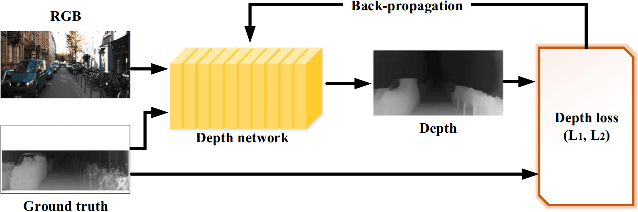
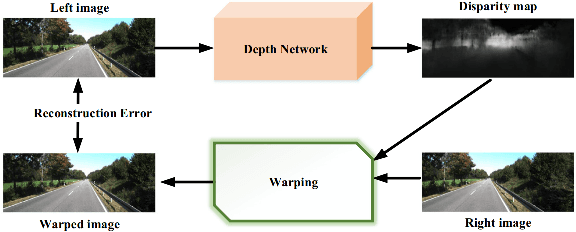
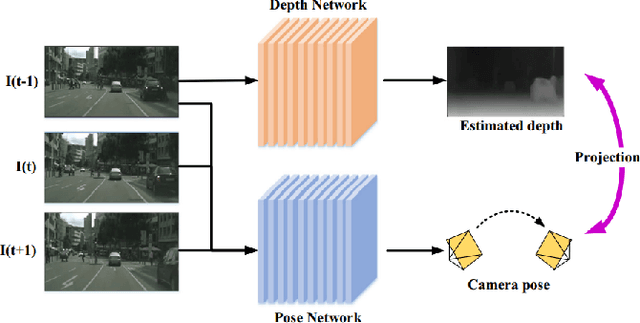
Depth estimation is an important task, applied in various methods and applications of computer vision. While the traditional methods of estimating depth are based on depth cues and require specific equipment such as stereo cameras and configuring input according to the approach being used, the focus at the current time is on a single source, or monocular, depth estimation. The recent developments in Convolution Neural Networks along with the integration of classical methods in these deep learning approaches have led to a lot of advancements in the depth estimation problem. The problem of outdoor depth estimation, or depth estimation in wild, is a very scarcely researched field of study. In this paper, we give an overview of the available datasets, depth estimation methods, research work, trends, challenges, and opportunities that exist for open research. To our knowledge, no openly available survey work provides a comprehensive collection of outdoor depth estimation techniques and research scope, making our work an essential contribution for people looking to enter this field of study.
A hybrid multi-object segmentation framework with model-based B-splines for microbial single cell analysis
May 03, 2022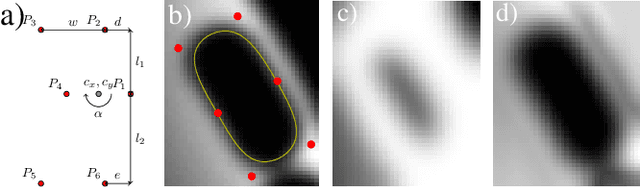
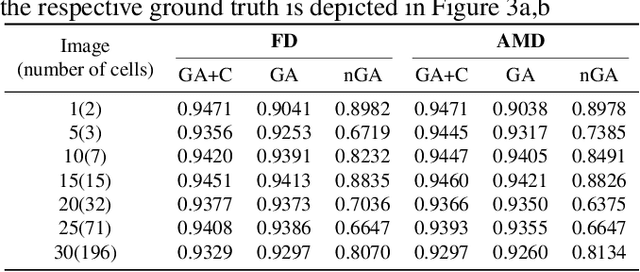
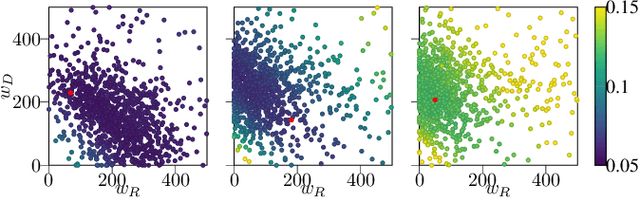
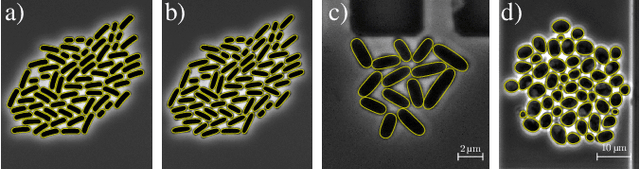
In this paper, we propose a hybrid approach for multi-object microbial cell segmentation. The approach combines an ML-based detection with a geometry-aware variational-based segmentation using B-splines that are parametrized based on a geometric model of the cell shape. The detection is done first using YOLOv5. In a second step, each detected cell is segmented individually. Thus, the segmentation only needs to be done on a per-cell basis, which makes it amenable to a variational approach that incorporates prior knowledge on the geometry. Here, the contour of the segmentation is modelled as closed uniform cubic B-spline, whose control points are parametrized using the known cell geometry. Compared to purely ML-based segmentation approaches, which need accurate segmentation maps as training data that are very laborious to produce, our method just needs bounding boxes as training data. Still, the proposed method performs on par with ML-based segmentation approaches usually used in this context. We study the performance of the proposed method on time-lapse microscopy data of Corynebacterium glutamicum.