 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Highly efficient reliability analysis of anisotropic heterogeneous slopes: Machine Learning aided Monte Carlo method
Apr 04, 2022
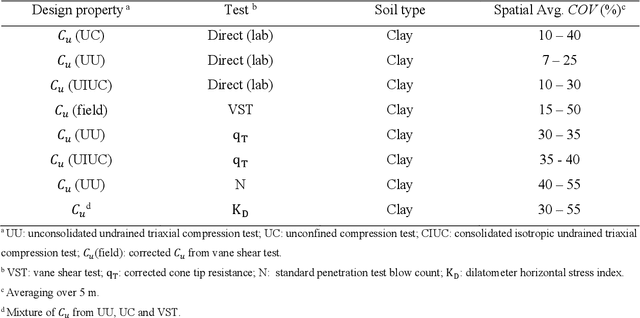
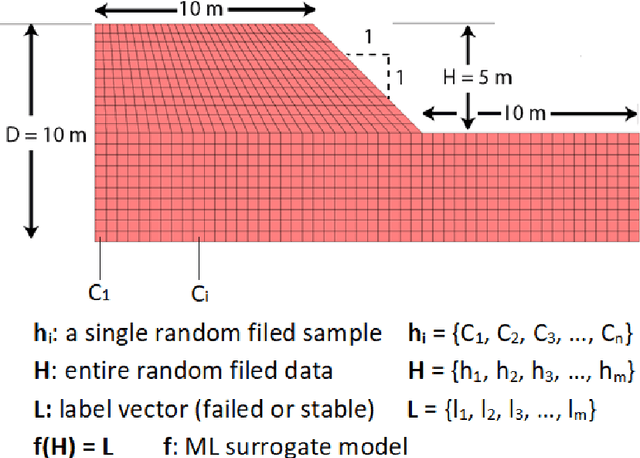
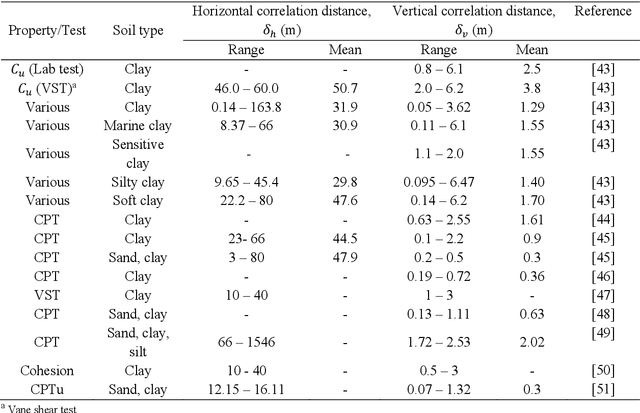
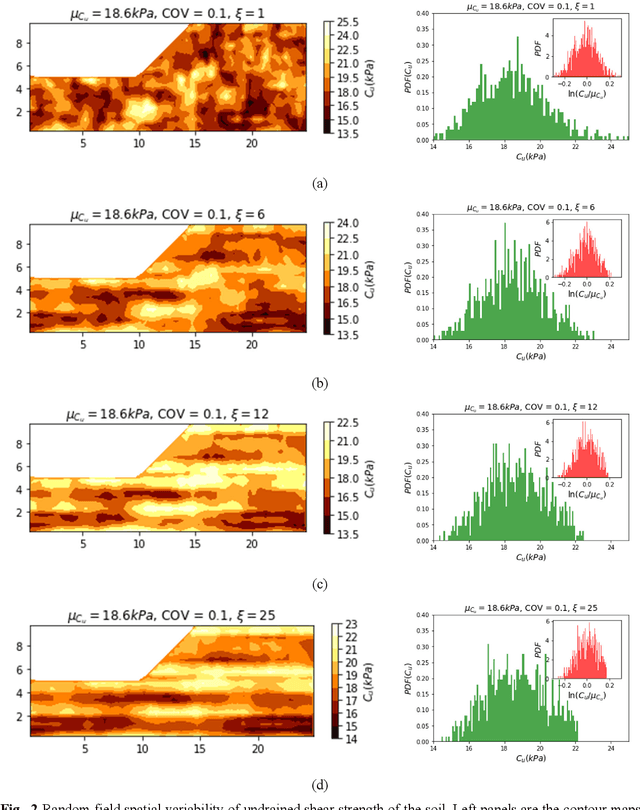
Machine Learning (ML) algorithms are increasingly used as surrogate models to increase the efficiency of stochastic reliability analyses in geotechnical engineering. This paper presents a highly efficient ML aided reliability technique that is able to accurately predict the results of a Monte Carlo (MC) reliability study, and yet performs 500 times faster. A complete MC reliability analysis on anisotropic heterogeneous slopes consisting of 120,000 simulated samples is conducted in parallel to the proposed ML aided stochastic technique. Comparing the results of the complete MC study and the proposed ML aided technique, the expected errors of the proposed method are realistically examined. Circumventing the time-consuming computation of factors of safety for the training datasets, the proposed technique is more efficient than previous methods. Different ML models, including Random Forest (RF), Support Vector Machine (SVM) and Artificial Neural Networks (ANN) are presented, optimised and compared. The effects of the size and type of training and testing datasets are discussed. The expected errors of the ML predicted probability of failure are characterised by different levels of soil heterogeneity and anisotropy. Using only 1% of MC samples to train ML surrogate models, the proposed technique can accurately predict the probability of failure with mean errors limited to 0.7%. The proposed technique reduces the computational time required for our study from 306 days to only 14 hours, providing 500 times higher efficiency.
Slope stability predictions on spatially variable random fields using machine learning surrogate models
Apr 04, 2022
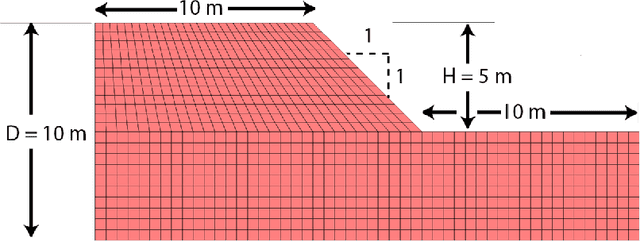
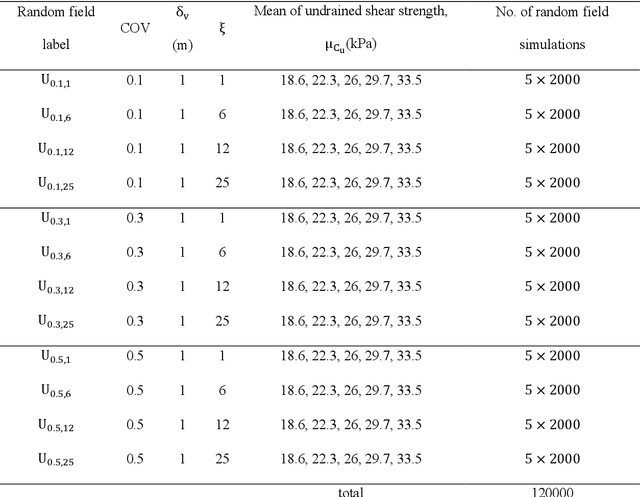
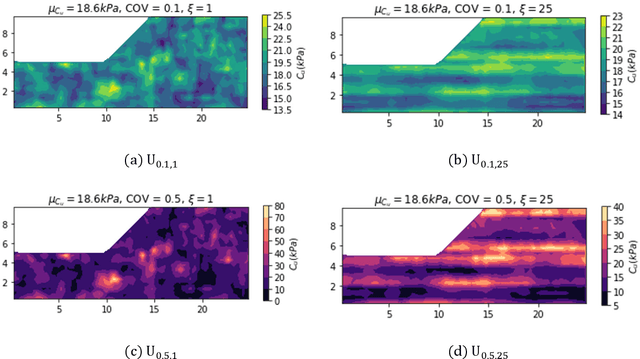
Random field Monte Carlo (MC) reliability analysis is a robust stochastic method to determine the probability of failure. This method, however, requires a large number of numerical simulations demanding high computational costs. This paper explores the efficiency of different machine learning (ML) algorithms used as surrogate models trained on a limited number of random field slope stability simulations in predicting the results of large datasets. The MC data in this paper require only the examination of failure or non-failure, circumventing the time-consuming calculation of factors of safety. An extensive dataset is generated, consisting of 120,000 finite difference MC slope stability simulations incorporating different levels of soil heterogeneity and anisotropy. The Bagging Ensemble, Random Forest and Support Vector classifiers are found to be the superior models for this problem amongst 9 different models and ensemble classifiers. Trained only on 0.47% of data (500 samples), the ML model can classify the entire 120,000 samples with an accuracy of %85 and AUC score of %91. The performance of ML methods in classifying the random field slope stability results generally reduces with higher anisotropy and heterogeneity of soil. The ML assisted MC reliability analysis proves a robust stochastic method where errors in the predicted probability of failure using %5 of MC data is only %0.46 in average. The approach reduced the computational time from 306 days to less than 6 hours.
Exact Gaussian Processes for Massive Datasets via Non-Stationary Sparsity-Discovering Kernels
May 18, 2022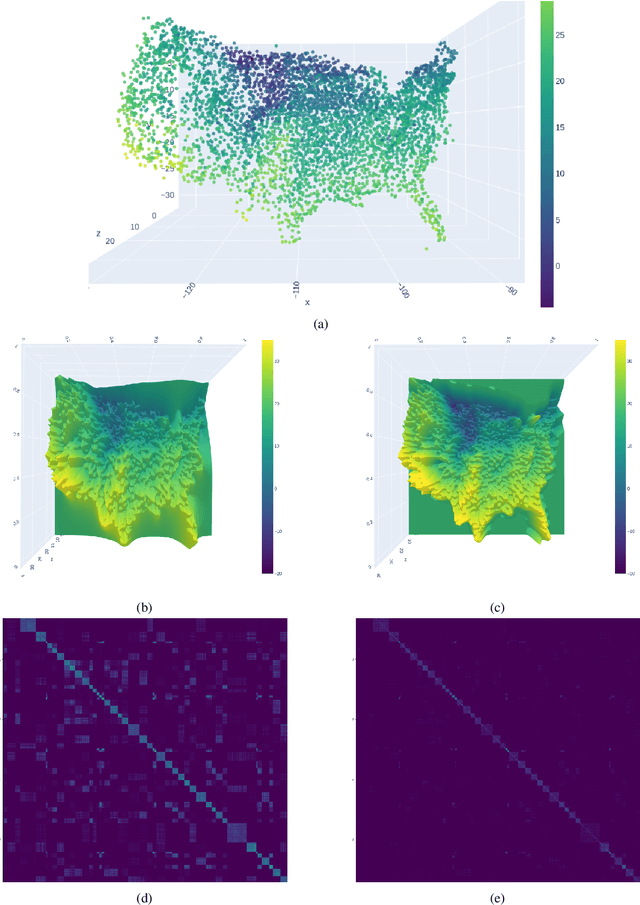
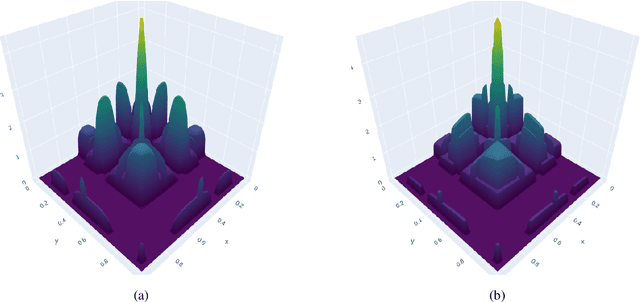
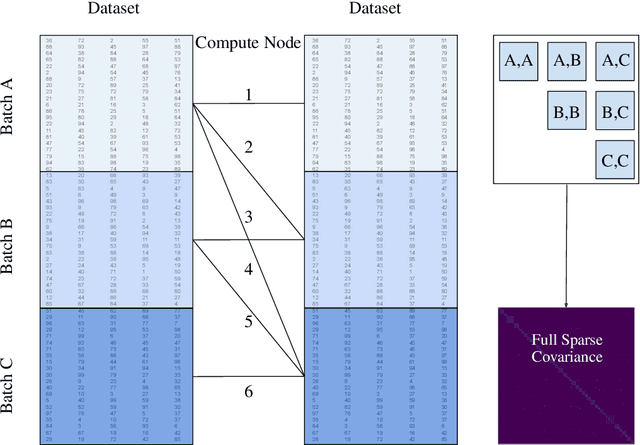
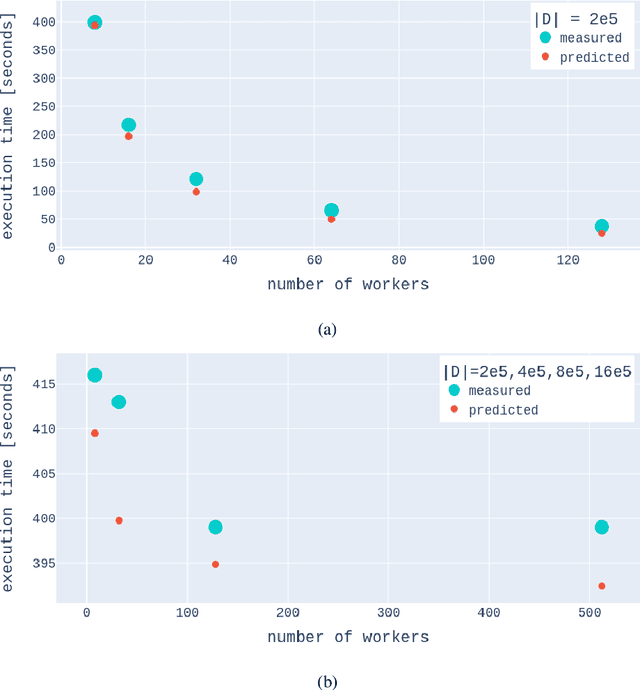
A Gaussian Process (GP) is a prominent mathematical framework for stochastic function approximation in science and engineering applications. This success is largely attributed to the GP's analytical tractability, robustness, non-parametric structure, and natural inclusion of uncertainty quantification. Unfortunately, the use of exact GPs is prohibitively expensive for large datasets due to their unfavorable numerical complexity of $O(N^3)$ in computation and $O(N^2)$ in storage. All existing methods addressing this issue utilize some form of approximation -- usually considering subsets of the full dataset or finding representative pseudo-points that render the covariance matrix well-structured and sparse. These approximate methods can lead to inaccuracies in function approximations and often limit the user's flexibility in designing expressive kernels. Instead of inducing sparsity via data-point geometry and structure, we propose to take advantage of naturally-occurring sparsity by allowing the kernel to discover -- instead of induce -- sparse structure. The premise of this paper is that GPs, in their most native form, are often naturally sparse, but commonly-used kernels do not allow us to exploit this sparsity. The core concept of exact, and at the same time sparse GPs relies on kernel definitions that provide enough flexibility to learn and encode not only non-zero but also zero covariances. This principle of ultra-flexible, compactly-supported, and non-stationary kernels, combined with HPC and constrained optimization, lets us scale exact GPs well beyond 5 million data points.
A Duality-based Approach for Real-time Obstacle Avoidance between Polytopes with Control Barrier Functions
Jul 18, 2021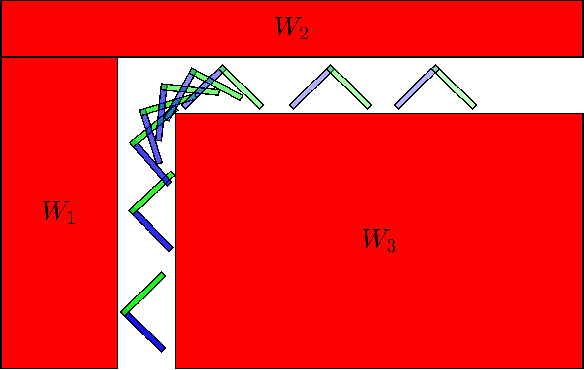
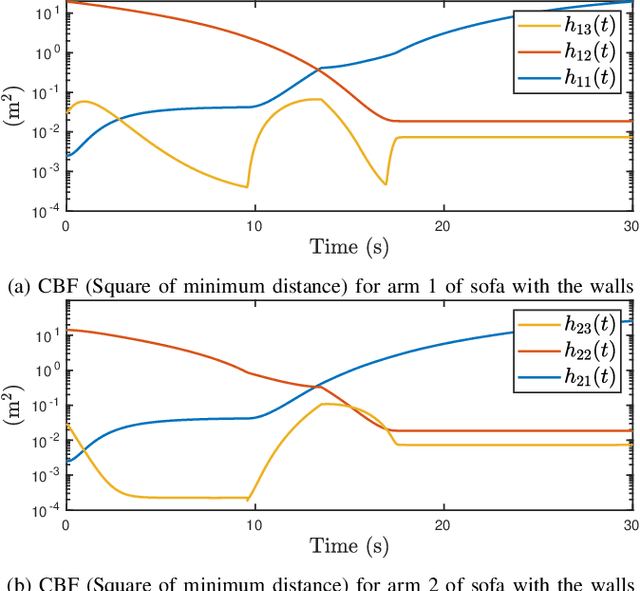
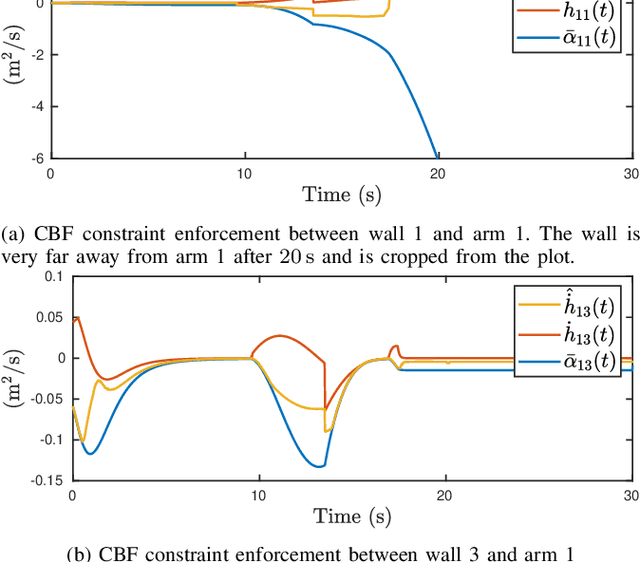

Developing controllers for obstacle avoidance between polytopes is a challenging and necessary problem for navigation in a tight space. Traditional approaches can only formulate the obstacle avoidance problem as an offline optimization problem. To address these challenges, we propose a duality-based safety-critical optimal control using control barrier functions for obstacle avoidance between polytopes, which can be solved in real-time with a QP-based optimization problem. A dual optimization problem is introduced to represent the minimum distance between polytopes and the Lagrangian function for the dual form is applied to construct a control barrier function. We demonstrate the proposed controller on a moving sofa problem where non-conservative maneuvers can be achieved in a tight space.
It's the Same Old Story! Enriching Event-Centric Knowledge Graphs by Narrative Aspects
May 08, 2022
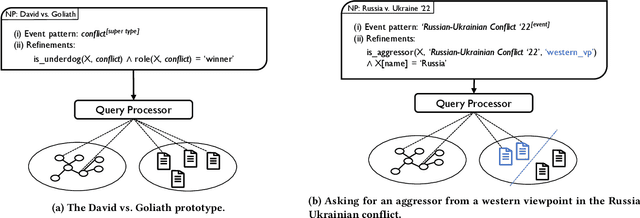
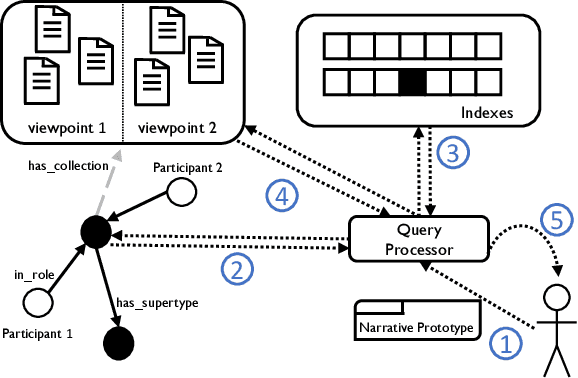
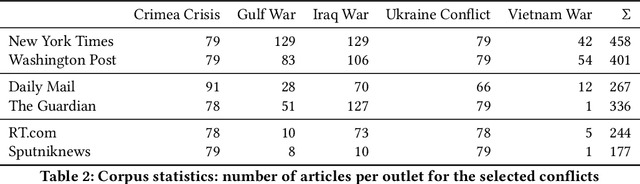
Our lives are ruled by events of varying importance ranging from simple everyday occurrences to incidents of societal dimension. And a lot of effort is taken to exchange information and discuss about such events: generally speaking, stringent narratives are formed to reduce complexity. But when considering complex events like the current conflict between Russia and Ukraine it is easy to see that those events cannot be grasped by objective facts alone, like the start of the conflict or respective troop sizes. There are different viewpoints and assessments to consider, a different understanding of the roles taken by individual participants, etc. So how can such subjective and viewpoint-dependent information be effectively represented together with all objective information? Recently event-centric knowledge graphs have been proposed for objective event representation in the otherwise primarily entity-centric domain of knowledge graphs. In this paper we introduce a novel and lightweight structure for event-centric knowledge graphs, which for the first time allows for queries incorporating viewpoint-dependent and narrative aspects. Our experiments prove the effective incorporation of subjective attributions for event participants and show the benefits of specifically tailored indexes for narrative query processing.
Adversarial Learning of Hard Positives for Place Recognition
May 08, 2022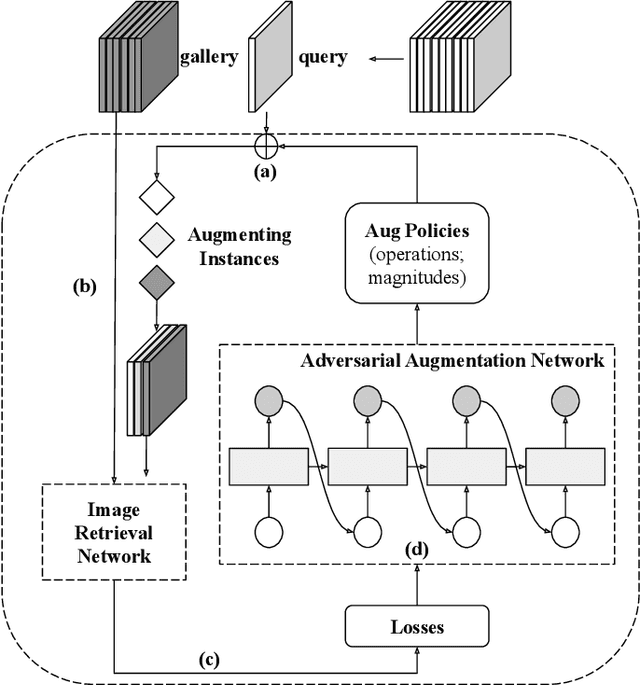
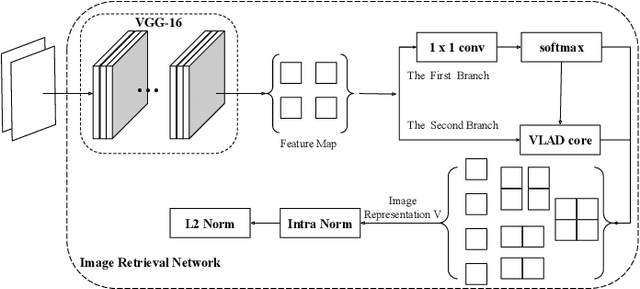

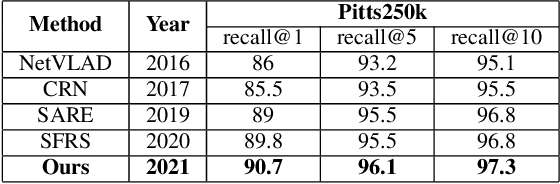
Image retrieval methods for place recognition learn global image descriptors that are used for fetching geo-tagged images at inference time. Recent works have suggested employing weak and self-supervision for mining hard positives and hard negatives in order to improve localization accuracy and robustness to visibility changes (e.g. in illumination or view point). However, generating hard positives, which is essential for obtaining robustness, is still limited to hard-coded or global augmentations. In this work we propose an adversarial method to guide the creation of hard positives for training image retrieval networks. Our method learns local and global augmentation policies which will increase the training loss, while the image retrieval network is forced to learn more powerful features for discriminating increasingly difficult examples. This approach allows the image retrieval network to generalize beyond the hard examples presented in the data and learn features that are robust to a wide range of variations. Our method achieves state-of-the-art recalls on the Pitts250 and Tokyo 24/7 benchmarks and outperforms recent image retrieval methods on the rOxford and rParis datasets by a noticeable margin.
Combining Reciprocity and CSI Feedback in MIMO Systems
May 04, 2022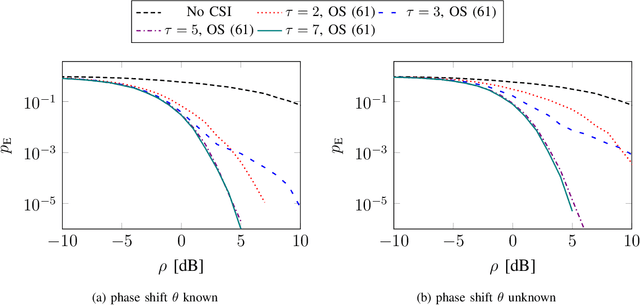
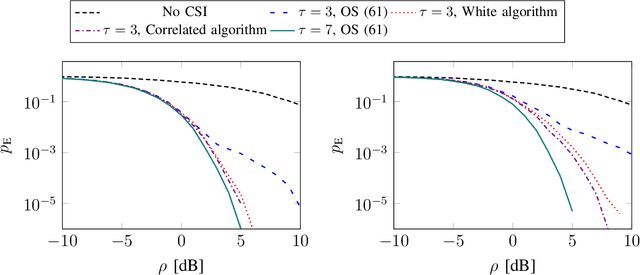
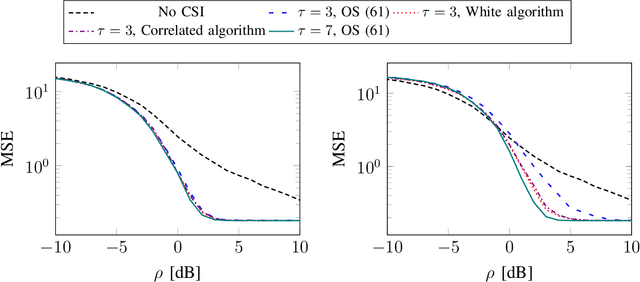
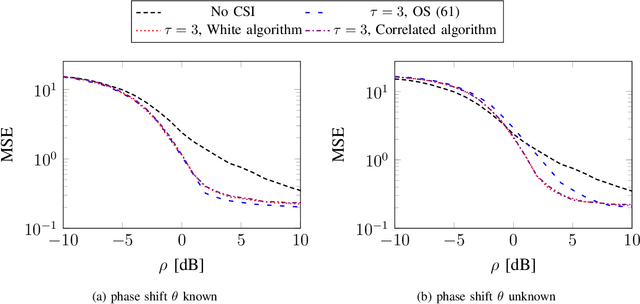
Reciprocity-based time-division duplex (TDD) Massive MIMO (multiple-input multiple-output) systems utilize channel estimates obtained in the uplink to perform precoding in the downlink. However, this method has been criticized of breaking down, in the sense that the channel estimates are not good enough to spatially separate multiple user terminals, at low uplink reference signal signal-to-noise ratios, due to insufficient channel estimation quality. Instead, codebook-based downlink precoding has been advocated for as an alternative solution in order to bypass this problem. We analyze this problem by considering a "grid-of-beams world" with a finite number of possible downlink channel realizations. Assuming that the terminal accurately can detect the downlink channel, we show that in the case where reciprocity holds, carefully designing a mapping between the downlink channel and the uplink reference signals will perform better than both the conventional TDD Massive MIMO and frequency-division duplex (FDD) Massive MIMO approach. We derive elegant metrics for designing this mapping, and further, we propose algorithms that find good sequence mappings.
HiT-DVAE: Human Motion Generation via Hierarchical Transformer Dynamical VAE
Apr 04, 2022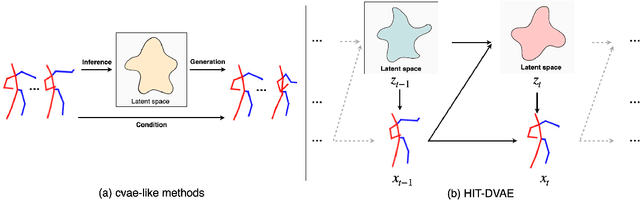
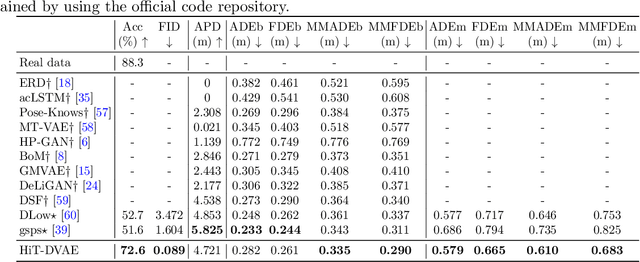
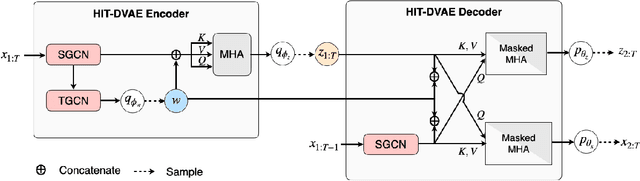
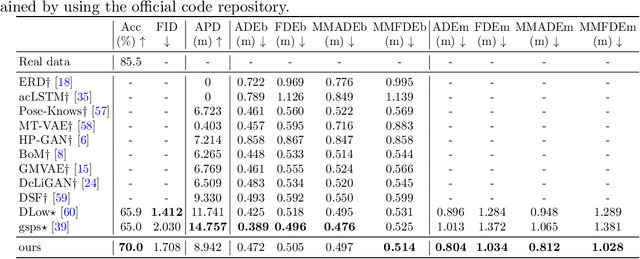
Studies on the automatic processing of 3D human pose data have flourished in the recent past. In this paper, we are interested in the generation of plausible and diverse future human poses following an observed 3D pose sequence. Current methods address this problem by injecting random variables from a single latent space into a deterministic motion prediction framework, which precludes the inherent multi-modality in human motion generation. In addition, previous works rarely explore the use of attention to select which frames are to be used to inform the generation process up to our knowledge. To overcome these limitations, we propose Hierarchical Transformer Dynamical Variational Autoencoder, HiT-DVAE, which implements auto-regressive generation with transformer-like attention mechanisms. HiT-DVAE simultaneously learns the evolution of data and latent space distribution with time correlated probabilistic dependencies, thus enabling the generative model to learn a more complex and time-varying latent space as well as diverse and realistic human motions. Furthermore, the auto-regressive generation brings more flexibility on observation and prediction, i.e. one can have any length of observation and predict arbitrary large sequences of poses with a single pre-trained model. We evaluate the proposed method on HumanEva-I and Human3.6M with various evaluation methods, and outperform the state-of-the-art methods on most of the metrics.
Do Time Constraints Re-Prioritize Attention to Shapes During Visual Photo Inspection?
Apr 14, 2021
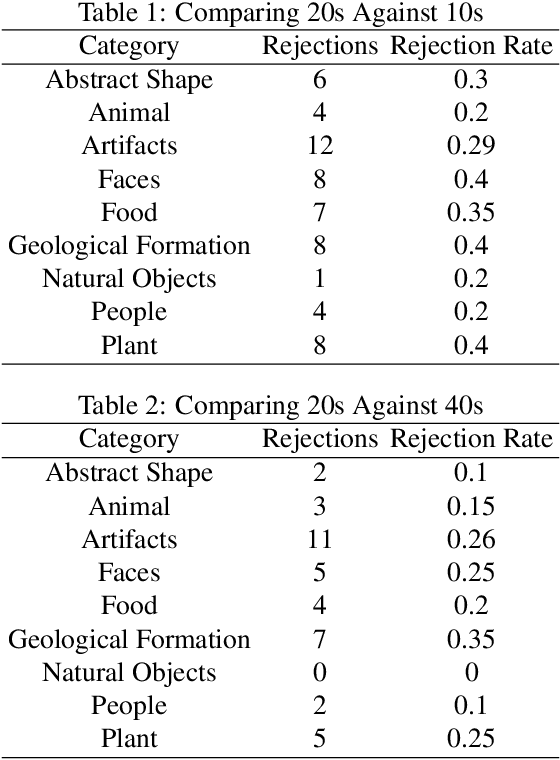


People's visual experiences of the world are easy to carve up and examine along natural language boundaries, e.g., by category labels, attribute labels, etc. However, it is more difficult to elicit detailed visuospatial information about what a person attends to, e.g., the specific shape of a tree. Paying attention to the shapes of things not only feeds into well defined tasks like visual category learning, but it is also what enables us to differentiate similarly named objects and to take on creative visual pursuits, like poetically describing the shape of a thing, or finding shapes in the clouds or stars. We use a new data collection method that elicits people's prioritized attention to shapes during visual photo inspection by asking them to trace important parts of the image under varying time constraints. Using data collected via crowdsourcing over a set of 187 photographs, we examine changes in patterns of visual attention across individuals, across image types, and across time constraints.
Modelling Evolutionary and Stationary User Preferences for Temporal Sets Prediction
Apr 14, 2022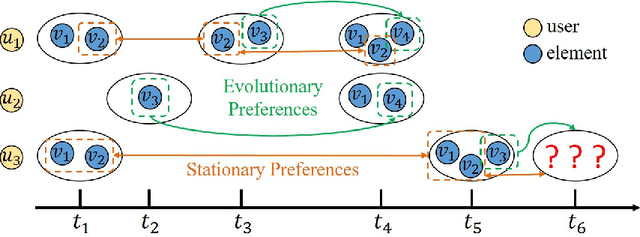

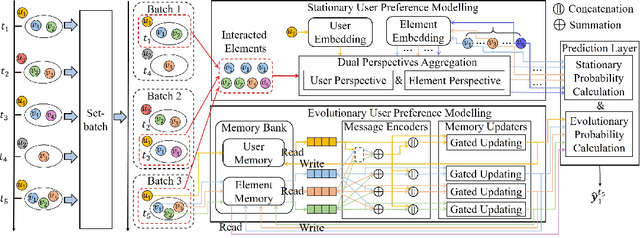

Given a sequence of sets, where each set is associated with a timestamp and contains an arbitrary number of elements, the task of temporal sets prediction aims to predict the elements in the subsequent set. Previous studies for temporal sets prediction mainly capture each user's evolutionary preference by learning from his/her own sequence. Although insightful, we argue that: 1) the collaborative signals latent in different users' sequences are essential but have not been exploited; 2) users also tend to show stationary preferences while existing methods fail to consider. To this end, we propose an integrated learning framework to model both the evolutionary and the stationary preferences of users for temporal sets prediction, which first constructs a universal sequence by chronologically arranging all the user-set interactions, and then learns on each user-set interaction. In particular, for each user-set interaction, we first design an evolutionary user preference modelling component to track the user's time-evolving preference and exploit the latent collaborative signals among different users. This component maintains a memory bank to store memories of the related user and elements, and continuously updates their memories based on the currently encoded messages and the past memories. Then, we devise a stationary user preference modelling module to discover each user's personalized characteristics according to the historical sequence, which adaptively aggregates the previously interacted elements from dual perspectives with the guidance of the user's and elements' embeddings. Finally, we develop a set-batch algorithm to improve the model efficiency, which can create time-consistent batches in advance and achieve 3.5x training speedups on average. Experiments on real-world datasets demonstrate the effectiveness and good interpretability of our approach.