 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
YOLOPose: Transformer-based Multi-Object 6D Pose Estimation using Keypoint Regression
May 05, 2022
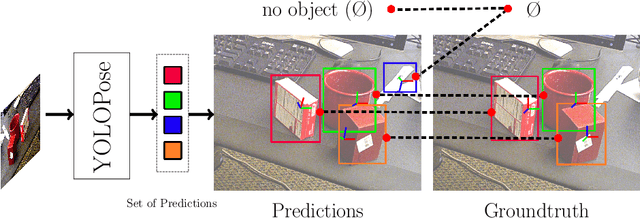
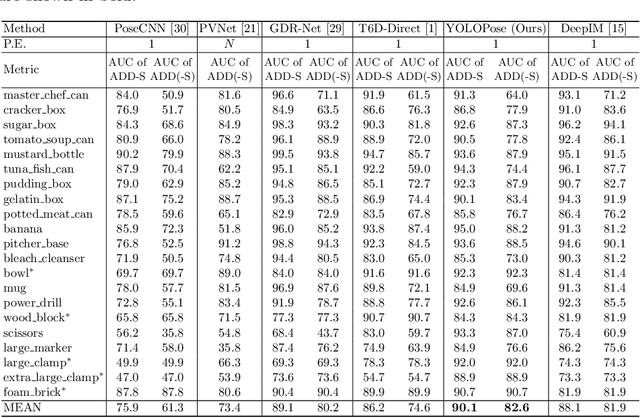
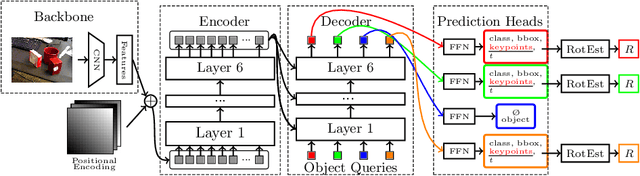
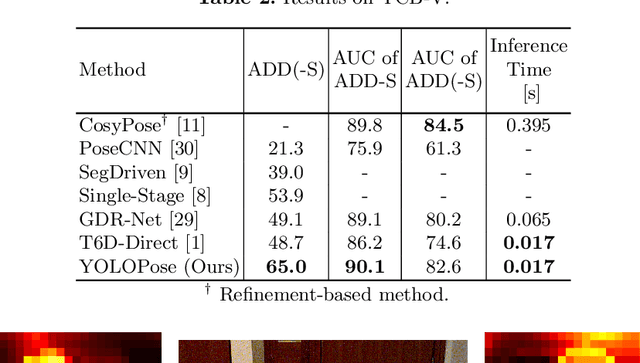
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods.
FastRIFE: Optimization of Real-Time Intermediate Flow Estimation for Video Frame Interpolation
Jun 01, 2021
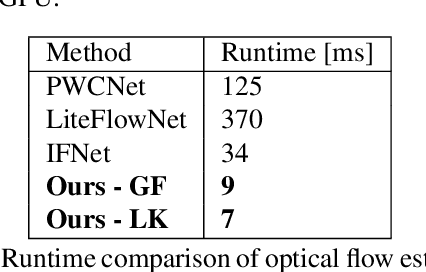


The problem of video inter-frame interpolation is an essential task in the field of image processing. Correctly increasing the number of frames in the recording while maintaining smooth movement allows to improve the quality of played video sequence, enables more effective compression and creating a slow-motion recording. This paper proposes the FastRIFE algorithm, which is some speed improvement of the RIFE (Real-Time Intermediate Flow Estimation) model. The novel method was examined and compared with other recently published algorithms. All source codes are available at https://gitlab.com/malwinq/interpolation-of-images-for-slow-motion-videos
Modeling Dynamic User Preference via Dictionary Learning for Sequential Recommendation
Apr 02, 2022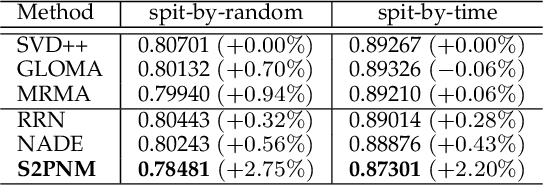
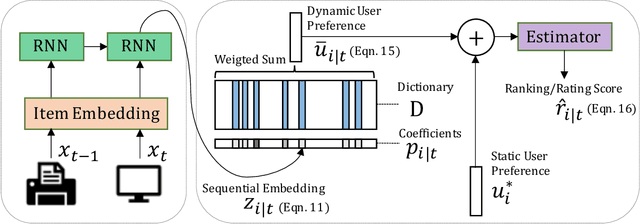

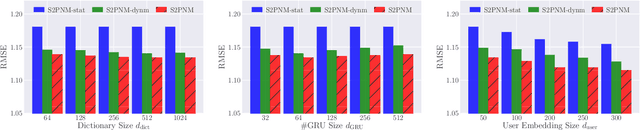
Capturing the dynamics in user preference is crucial to better predict user future behaviors because user preferences often drift over time. Many existing recommendation algorithms -- including both shallow and deep ones -- often model such dynamics independently, i.e., user static and dynamic preferences are not modeled under the same latent space, which makes it difficult to fuse them for recommendation. This paper considers the problem of embedding a user's sequential behavior into the latent space of user preferences, namely translating sequence to preference. To this end, we formulate the sequential recommendation task as a dictionary learning problem, which learns: 1) a shared dictionary matrix, each row of which represents a partial signal of user dynamic preferences shared across users; and 2) a posterior distribution estimator using a deep autoregressive model integrated with Gated Recurrent Unit (GRU), which can select related rows of the dictionary to represent a user's dynamic preferences conditioned on his/her past behaviors. Qualitative studies on the Netflix dataset demonstrate that the proposed method can capture the user preference drifts over time and quantitative studies on multiple real-world datasets demonstrate that the proposed method can achieve higher accuracy compared with state-of-the-art factorization and neural sequential recommendation methods. The code is available at https://github.com/cchao0116/S2PNM-TKDE2021.
Space-Time Video Regularity and Visual Fidelity: Compression, Resolution and Frame Rate Adaptation
Mar 31, 2021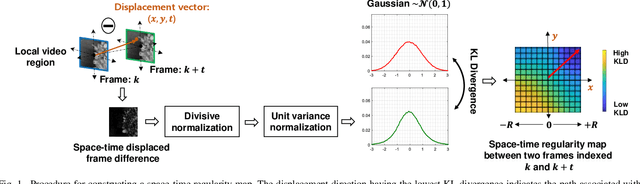
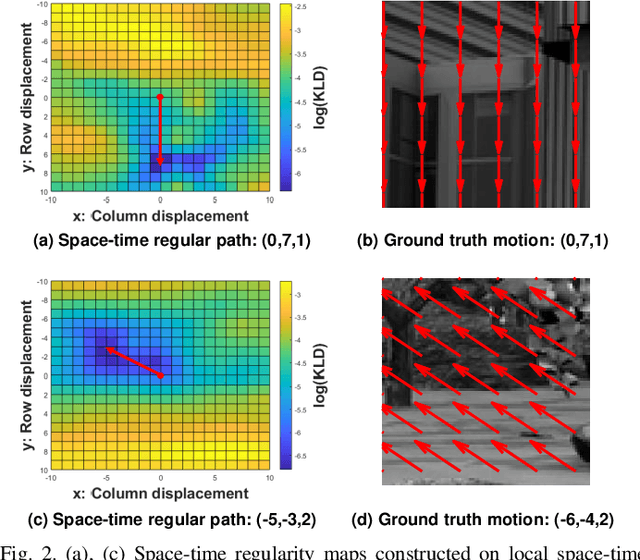
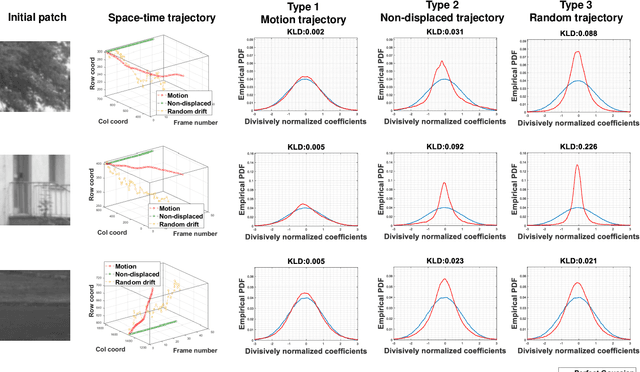
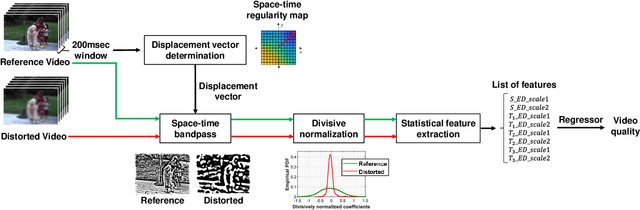
In order to be able to deliver today's voluminous amount of video contents through limited bandwidth channels in a perceptually optimal way, it is important to consider perceptual trade-offs of compression and space-time downsampling protocols. In this direction, we have studied and developed new models of natural video statistics (NVS), which are useful because high-quality videos contain statistical regularities that are disturbed by distortions. Specifically, we model the statistics of divisively normalized difference between neighboring frames that are relatively displaced. In an extensive empirical study, we found that those paths of space-time displaced frame differences that provide maximal regularity against our NVS model generally align best with motion trajectories. Motivated by this, we build a new video quality prediction engine that extracts NVS features from displaced frame differences, and combines them in a learned regressor that can accurately predict perceptual quality. As a stringent test of the new model, we apply it to the difficult problem of predicting the quality of videos subjected not only to compression, but also to downsampling in space and/or time. We show that the new quality model achieves state-of-the-art (SOTA) prediction performance compared on the new ETRI-LIVE Space-Time Subsampled Video Quality (STSVQ) database, which is dedicated to this problem. Downsampling protocols are of high interest to the streaming video industry, given rapid increases in frame resolutions and frame rates.
CGC: Contrastive Graph Clustering for Community Detection and Tracking
Apr 05, 2022
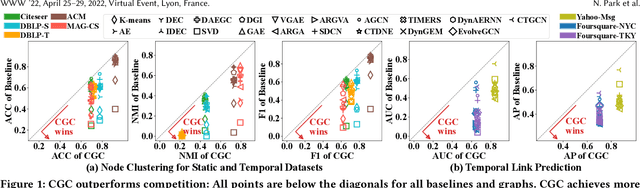
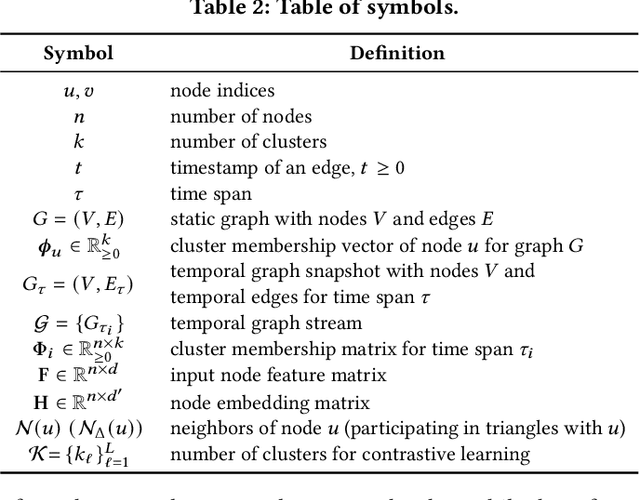
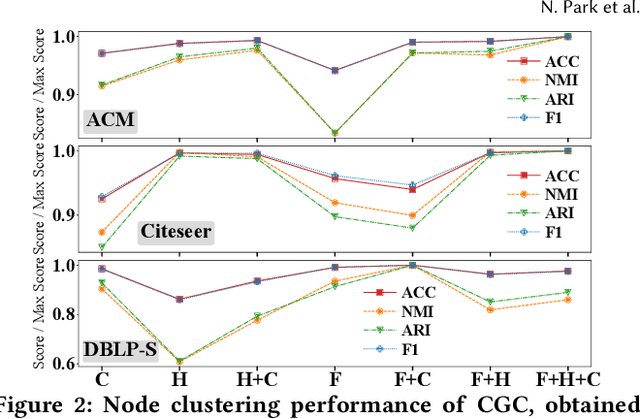
Given entities and their interactions in the web data, which may have occurred at different time, how can we find communities of entities and track their evolution? In this paper, we approach this important task from graph clustering perspective. Recently, state-of-the-art clustering performance in various domains has been achieved by deep clustering methods. Especially, deep graph clustering (DGC) methods have successfully extended deep clustering to graph-structured data by learning node representations and cluster assignments in a joint optimization framework. Despite some differences in modeling choices (e.g., encoder architectures), existing DGC methods are mainly based on autoencoders and use the same clustering objective with relatively minor adaptations. Also, while many real-world graphs are dynamic, previous DGC methods considered only static graphs. In this work, we develop CGC, a novel end-to-end framework for graph clustering, which fundamentally differs from existing methods. CGC learns node embeddings and cluster assignments in a contrastive graph learning framework, where positive and negative samples are carefully selected in a multi-level scheme such that they reflect hierarchical community structures and network homophily. Also, we extend CGC for time-evolving data, where temporal graph clustering is performed in an incremental learning fashion, with the ability to detect change points. Extensive evaluation on real-world graphs demonstrates that the proposed CGC consistently outperforms existing methods.
Unmanned Aerial Vehicles Meet Reflective Intelligent Surfaces to Improve Coverage and Secrecy
May 05, 2022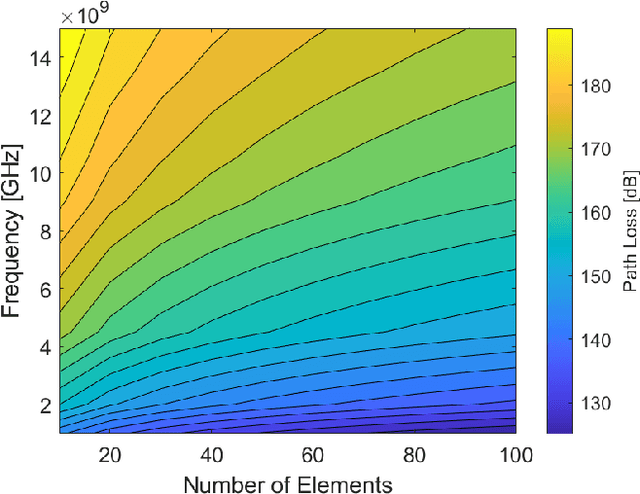
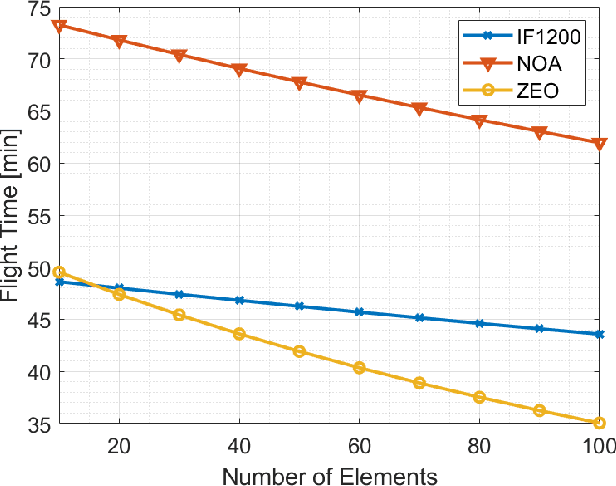
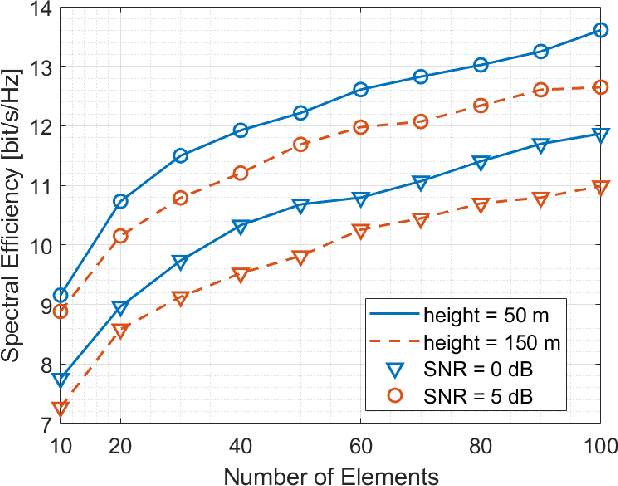
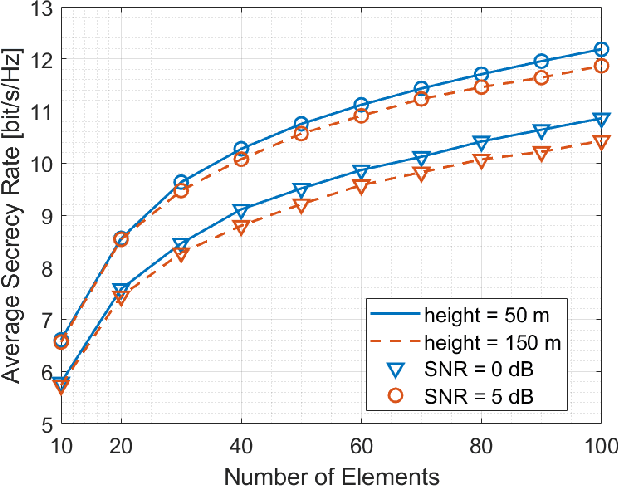
The high configurability and low cost of Reflective Intelligent Surfaces (RISs) made them a promising solution for enhancing the capabilities of Beyond Fifth-Generation (B5G) networks. Recent works proposed to mount RISs on Unmanned Aerial Vehicles (UAVs), combining the high network configurability provided by RIS with the mobility brought by UAVs. However, the RIS represents an additional weight that impacts the battery lifetime of the UAV. Furthermore, the practicality of the resulting link in terms of communication channel quality and security have not been assessed in detail. In this paper, we highlight all the essential features that need to be considered for the practical deployment of RIS-enabled UAVs. We are the first to show how the RIS size and its power consumption impact the UAV flight time. We then assess how the RIS size, carrier frequency, and UAV flying altitude affects the path loss. Lastly, we propose a novel particle swarm-based approach to maximize coverage and improve the confidentiality of transmissions in a cellular scenario with the support of RISs carried by UAVs.
TransTab: Learning Transferable Tabular Transformers Across Tables
May 19, 2022
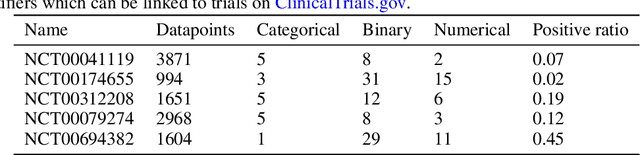
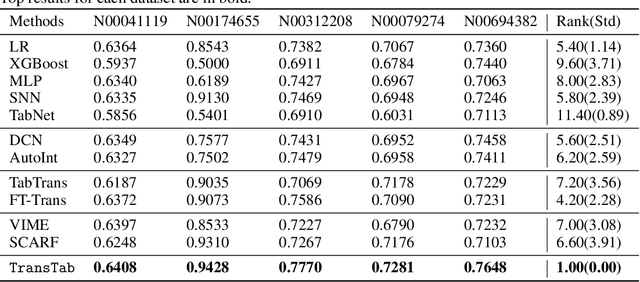
Tabular data (or tables) are the most widely used data format in machine learning (ML). However, ML models often assume the table structure keeps fixed in training and testing. Before ML modeling, heavy data cleaning is required to merge disparate tables with different columns. This preprocessing often incurs significant data waste (e.g., removing unmatched columns and samples). How to learn ML models from multiple tables with partially overlapping columns? How to incrementally update ML models as more columns become available over time? Can we leverage model pretraining on multiple distinct tables? How to train an ML model which can predict on an unseen table? To answer all those questions, we propose to relax fixed table structures by introducing a Transferable Tabular Transformer (TransTab) for tables. The goal of TransTab is to convert each sample (a row in the table) to a generalizable embedding vector, and then apply stacked transformers for feature encoding. One methodology insight is combining column description and table cells as the raw input to a gated transformer model. The other insight is to introduce supervised and self-supervised pretraining to improve model performance. We compare TransTab with multiple baseline methods on diverse benchmark datasets and five oncology clinical trial datasets. Overall, TransTab ranks 1.00, 1.00, 1.78 out of 12 methods in supervised learning, feature incremental learning, and transfer learning scenarios, respectively; and the proposed pretraining leads to 2.3\% AUC lift on average over the supervised learning.}
A First Runtime Analysis of the NSGA-II on a Multimodal Problem
Apr 28, 2022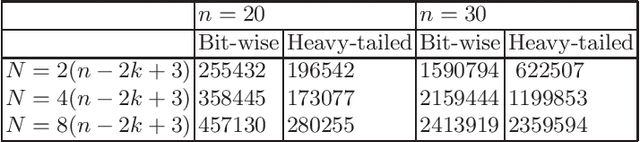
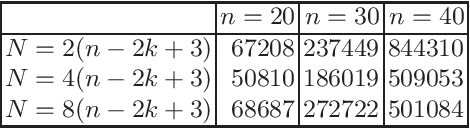
Very recently, the first mathematical runtime analyses of the multi-objective evolutionary optimizer NSGA-II have been conducted (AAAI 2022, GECCO 2022 (to appear), arxiv 2022). We continue this line of research with a first runtime analysis of this algorithm on a benchmark problem consisting of two multimodal objectives. We prove that if the population size $N$ is at least four times the size of the Pareto front, then the NSGA-II with four different ways to select parents and bit-wise mutation optimizes the OneJumpZeroJump benchmark with jump size~$2 \le k \le n/4$ in time $O(N n^k)$. When using fast mutation, a recently proposed heavy-tailed mutation operator, this guarantee improves by a factor of $k^{\Omega(k)}$. Overall, this work shows that the NSGA-II copes with the local optima of the OneJumpZeroJump problem at least as well as the global SEMO algorithm.
DDoS-UNet: Incorporating temporal information using Dynamic Dual-channel UNet for enhancing super-resolution of dynamic MRI
Feb 10, 2022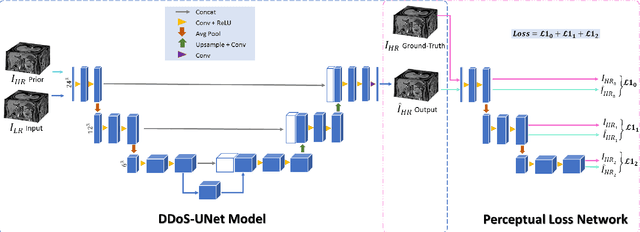
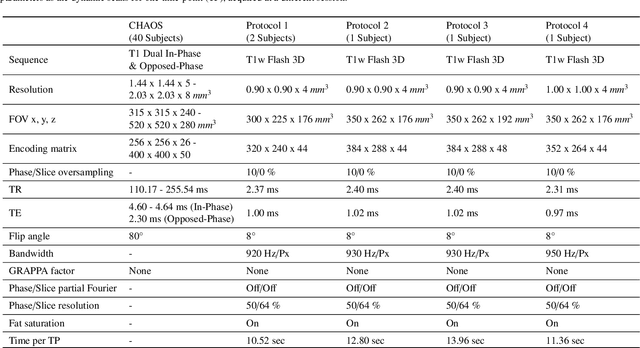

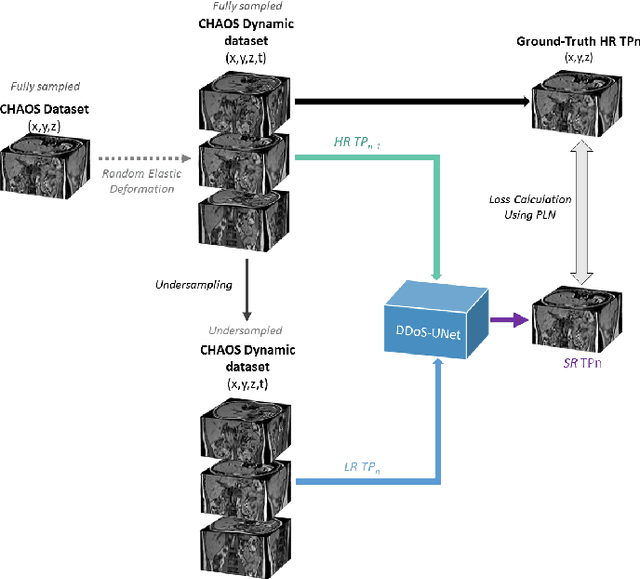
Magnetic resonance imaging (MRI) provides high spatial resolution and excellent soft-tissue contrast without using harmful ionising radiation. Dynamic MRI is an essential tool for interventions to visualise movements or changes of the target organ. However, such MRI acquisition with high temporal resolution suffers from limited spatial resolution - also known as the spatio-temporal trade-off of dynamic MRI. Several approaches, including deep learning based super-resolution approaches, have been proposed to mitigate this trade-off. Nevertheless, such an approach typically aims to super-resolve each time-point separately, treating them as individual volumes. This research addresses the problem by creating a deep learning model which attempts to learn both spatial and temporal relationships. A modified 3D UNet model, DDoS-UNet, is proposed - which takes the low-resolution volume of the current time-point along with a prior image volume. Initially, the network is supplied with a static high-resolution planning scan as the prior image along with the low-resolution input to super-resolve the first time-point. Then it continues step-wise by using the super-resolved time-points as the prior image while super-resolving the subsequent time-points. The model performance was tested with 3D dynamic data that was undersampled to different in-plane levels. The proposed network achieved an average SSIM value of 0.951$\pm$0.017 while reconstructing the lowest resolution data (i.e. only 4\% of the k-space acquired) - which could result in a theoretical acceleration factor of 25. The proposed approach can be used to reduce the required scan-time while achieving high spatial resolution.
Attention-based Reinforcement Learning for Real-Time UAV Semantic Communication
May 22, 2021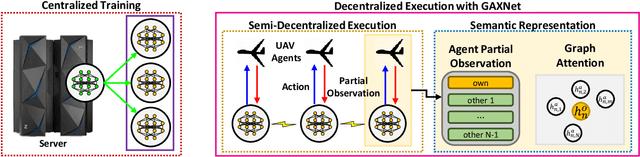
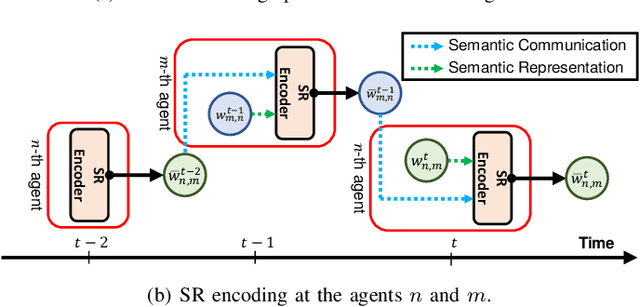
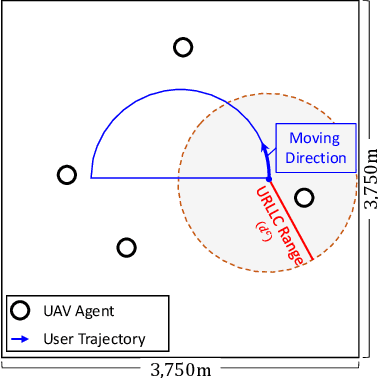
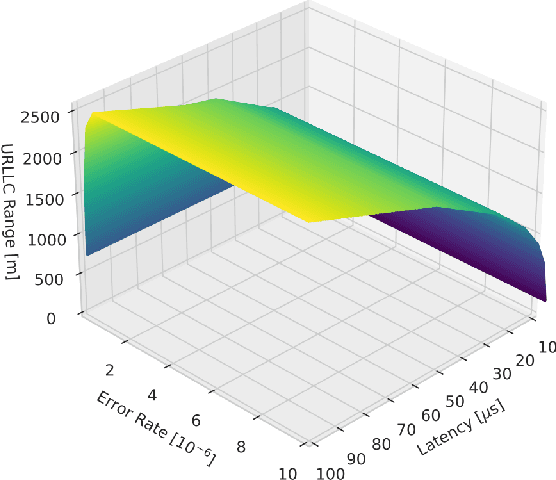
In this article, we study the problem of air-to-ground ultra-reliable and low-latency communication (URLLC) for a moving ground user. This is done by controlling multiple unmanned aerial vehicles (UAVs) in real time while avoiding inter-UAV collisions. To this end, we propose a novel multi-agent deep reinforcement learning (MADRL) framework, coined a graph attention exchange network (GAXNet). In GAXNet, each UAV constructs an attention graph locally measuring the level of attention to its neighboring UAVs, while exchanging the attention weights with other UAVs so as to reduce the attention mismatch between them. Simulation results corroborates that GAXNet achieves up to 4.5x higher rewards during training. At execution, without incurring inter-UAV collisions, GAXNet achieves 6.5x lower latency with the target 0.0000001 error rate, compared to a state-of-the-art baseline framework.