 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Target Sound Extraction with Timestamp Information
Apr 02, 2022
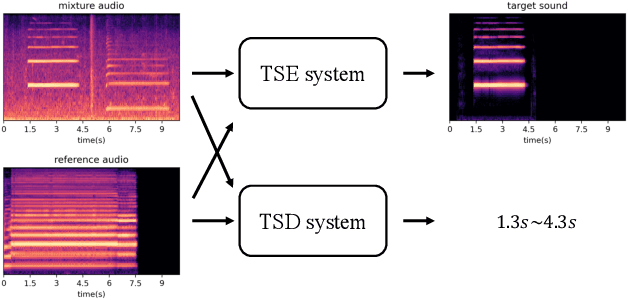
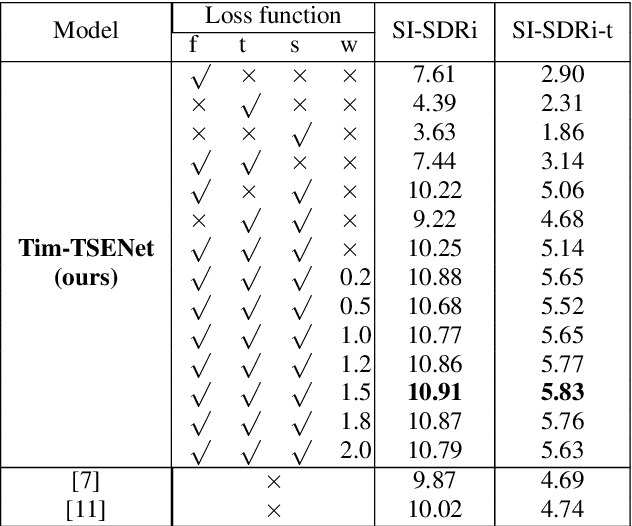
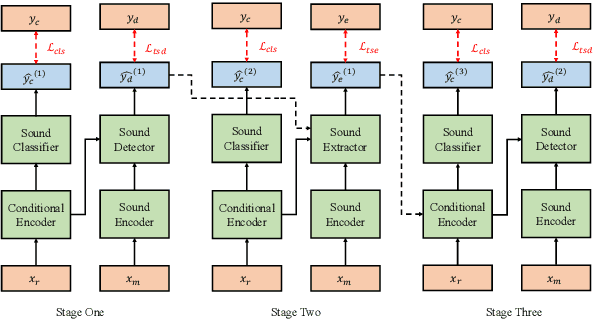
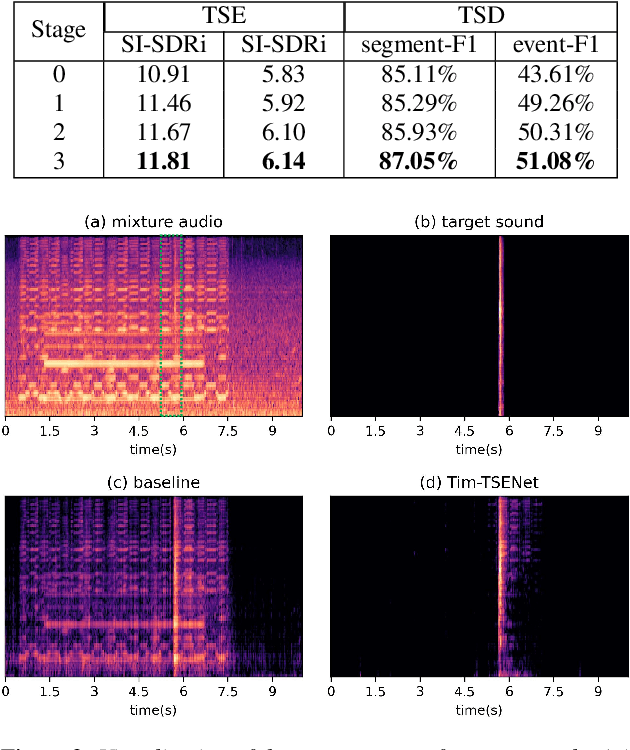
Target sound extraction (TSE) aims to extract the sound part of a target sound event class from a mixture audio with multiple sound events. The previous works mainly focus on the problems of weakly-labelled data, jointly learning and new classes, however, no one cares about the onset and offset times of the target sound event, which has been emphasized in the auditory scene analysis. In this paper, we study to utilize such timestamp information to help extract the target sound via a target sound detection network and a target-weighted time-frequency loss function. More specifically, we use the detection result of a target sound detection (TSD) network as the additional information to guide the learning of target sound extraction network. We also find that the result of TSE can further improve the performance of the TSD network, so that a mutual learning framework of the target sound detection and extraction is proposed. In addition, a target-weighted time-frequency loss function is designed to pay more attention to the temporal regions of the target sound during training. Experimental results on the synthesized data generated from the Freesound Datasets show that our proposed method can significantly improve the performance of TSE.
YOLOPose: Transformer-based Multi-Object 6D Pose Estimation using Keypoint Regression
May 05, 2022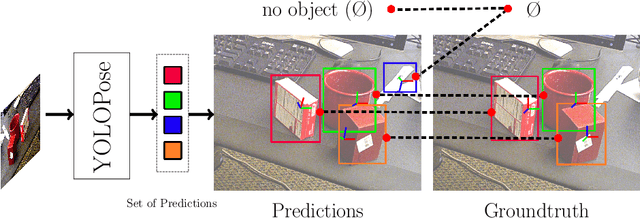
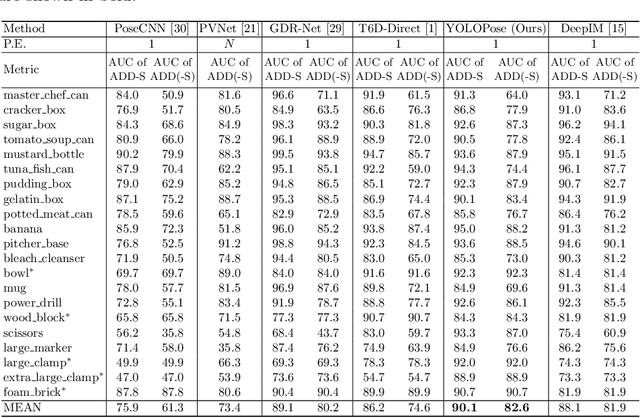
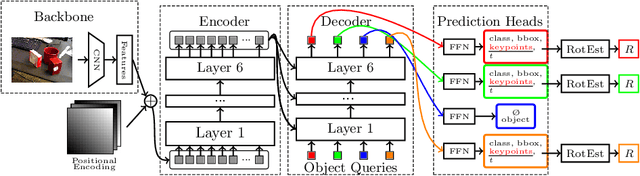
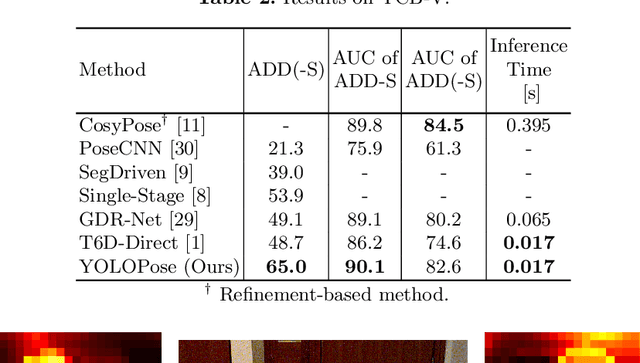
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods.
Locality Matters: A Locality-Biased Linear Attention for Automatic Speech Recognition
Mar 29, 2022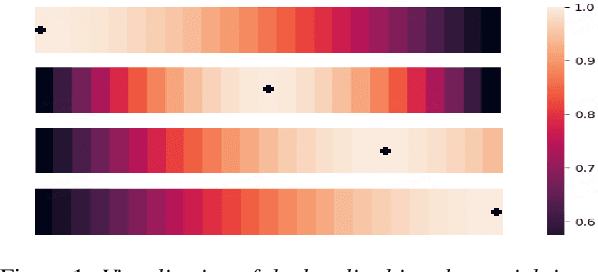
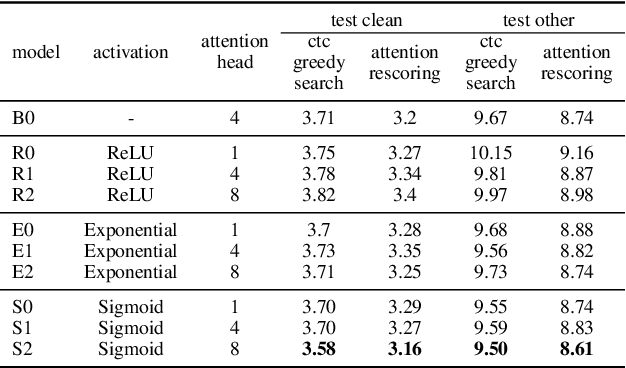
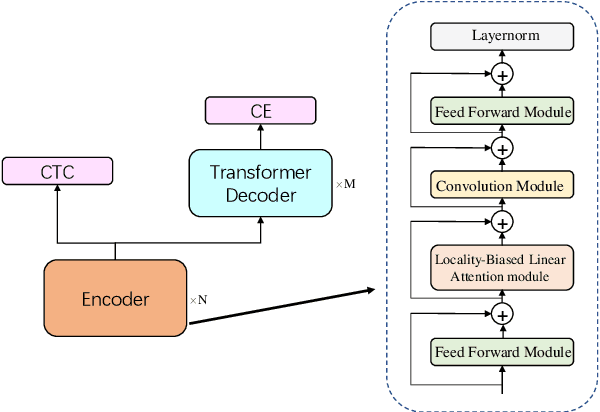
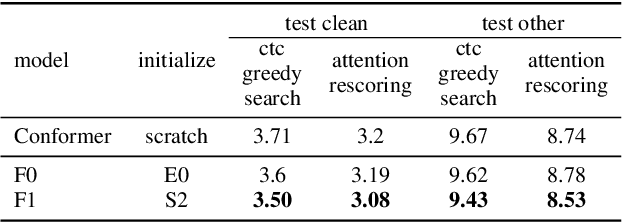
Conformer has shown a great success in automatic speech recognition (ASR) on many public benchmarks. One of its crucial drawbacks is the quadratic time-space complexity with respect to the input sequence length, which prohibits the model to scale-up as well as process longer input audio sequences. To solve this issue, numerous linear attention methods have been proposed. However, these methods often have limited performance on ASR as they treat tokens equally in modeling, neglecting the fact that the neighbouring tokens are often more connected than the distanced tokens. In this paper, we take this fact into account and propose a new locality-biased linear attention for Conformer. It not only achieves higher accuracy than the vanilla Conformer, but also enjoys linear space-time computational complexity. To be specific, we replace the softmax attention with a locality-biased linear attention (LBLA) mechanism in Conformer blocks. The LBLA contains a kernel function to ensure the linear complexities and a cosine reweighing matrix to impose more weights on neighbouring tokens. Extensive experiments on the LibriSpeech corpus show that by introducing this locality bias to the Conformer, our method achieves a lower word error rate with more than 22% inference speed.
Linear TDOA-based Measurements for Distributed Estimation and Localized Tracking
Apr 26, 2022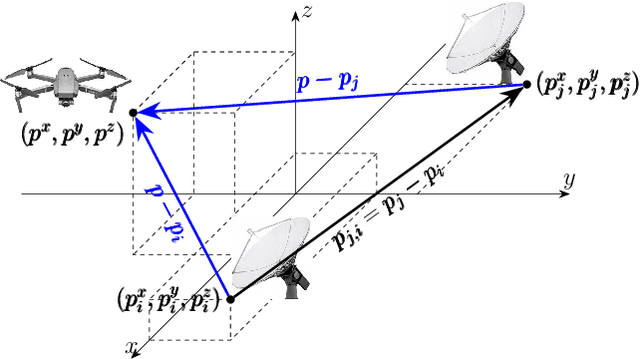
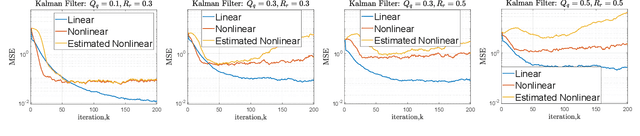
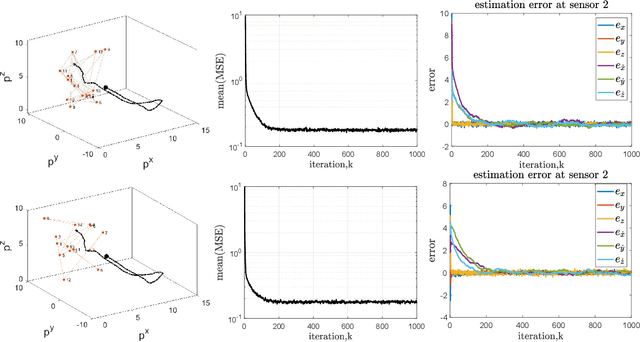

We propose a linear time-difference-of-arrival (TDOA) measurement model to improve \textit{distributed} estimation performance for localized target tracking. We design distributed filters over sparse (possibly large-scale) communication networks using consensus-based data-fusion techniques. The proposed distributed and localized tracking protocols considerably reduce the sensor network's required connectivity and communication rate. We, further, consider $\kappa$-redundant observability and fault-tolerant design in case of losing communication links or sensor nodes. We present the minimal conditions on the remaining sensor network (after link/node removal) such that the distributed observability is still preserved and, thus, the sensor network can track the (single) maneuvering target. The motivation is to reduce the communication load versus the processing load, as the computational units are, in general, less costly than the communication devices. We evaluate the tracking performance via simulations in MATLAB.
TrimBERT: Tailoring BERT for Trade-offs
Feb 24, 2022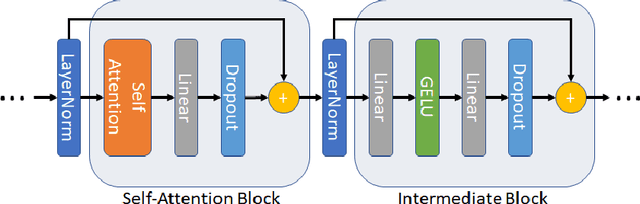
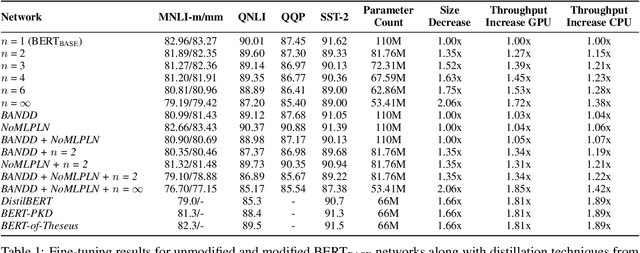


Models based on BERT have been extremely successful in solving a variety of natural language processing (NLP) tasks. Unfortunately, many of these large models require a great deal of computational resources and/or time for pre-training and fine-tuning which limits wider adoptability. While self-attention layers have been well-studied, a strong justification for inclusion of the intermediate layers which follow them remains missing in the literature. In this work, we show that reducing the number of intermediate layers in BERT-Base results in minimal fine-tuning accuracy loss of downstream tasks while significantly decreasing model size and training time. We further mitigate two key bottlenecks, by replacing all softmax operations in the self-attention layers with a computationally simpler alternative and removing half of all layernorm operations. This further decreases the training time while maintaining a high level of fine-tuning accuracy.
Unmanned Aerial Vehicles Meet Reflective Intelligent Surfaces to Improve Coverage and Secrecy
May 05, 2022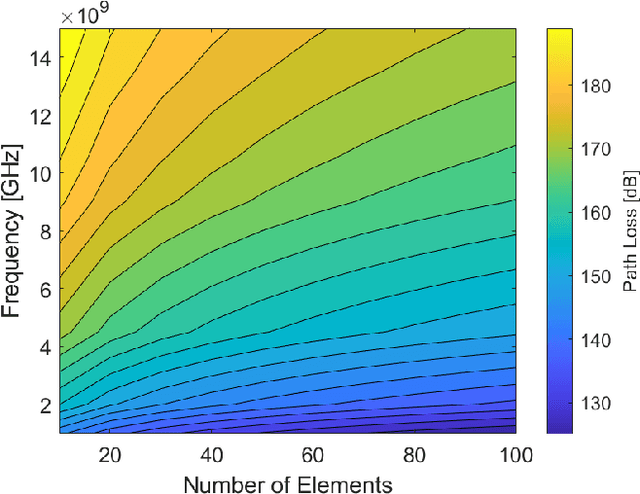
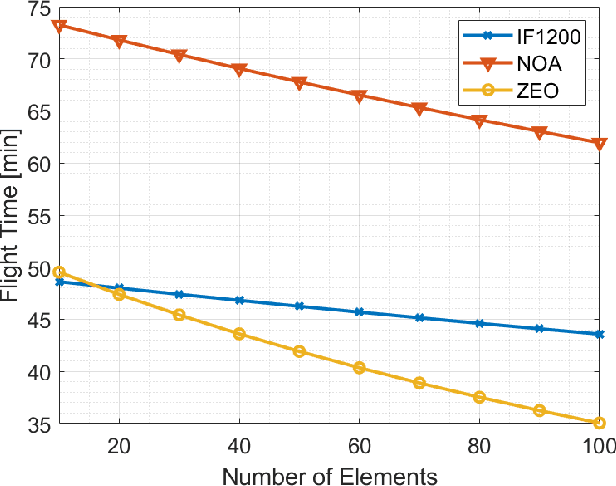
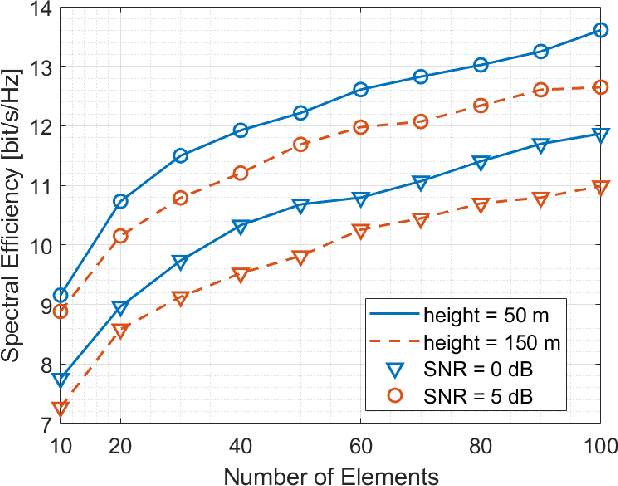
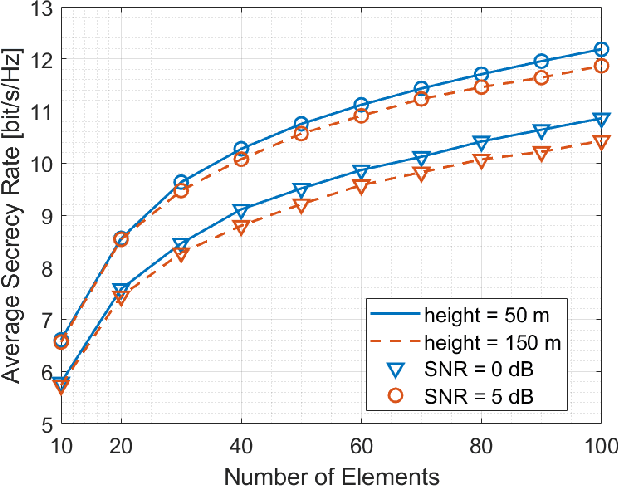
The high configurability and low cost of Reflective Intelligent Surfaces (RISs) made them a promising solution for enhancing the capabilities of Beyond Fifth-Generation (B5G) networks. Recent works proposed to mount RISs on Unmanned Aerial Vehicles (UAVs), combining the high network configurability provided by RIS with the mobility brought by UAVs. However, the RIS represents an additional weight that impacts the battery lifetime of the UAV. Furthermore, the practicality of the resulting link in terms of communication channel quality and security have not been assessed in detail. In this paper, we highlight all the essential features that need to be considered for the practical deployment of RIS-enabled UAVs. We are the first to show how the RIS size and its power consumption impact the UAV flight time. We then assess how the RIS size, carrier frequency, and UAV flying altitude affects the path loss. Lastly, we propose a novel particle swarm-based approach to maximize coverage and improve the confidentiality of transmissions in a cellular scenario with the support of RISs carried by UAVs.
A First Runtime Analysis of the NSGA-II on a Multimodal Problem
Apr 28, 2022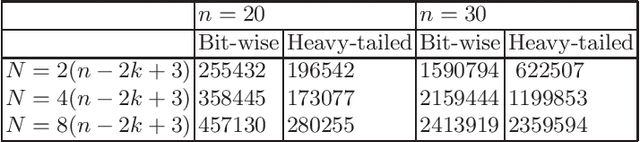
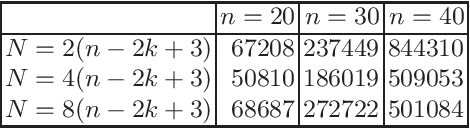
Very recently, the first mathematical runtime analyses of the multi-objective evolutionary optimizer NSGA-II have been conducted (AAAI 2022, GECCO 2022 (to appear), arxiv 2022). We continue this line of research with a first runtime analysis of this algorithm on a benchmark problem consisting of two multimodal objectives. We prove that if the population size $N$ is at least four times the size of the Pareto front, then the NSGA-II with four different ways to select parents and bit-wise mutation optimizes the OneJumpZeroJump benchmark with jump size~$2 \le k \le n/4$ in time $O(N n^k)$. When using fast mutation, a recently proposed heavy-tailed mutation operator, this guarantee improves by a factor of $k^{\Omega(k)}$. Overall, this work shows that the NSGA-II copes with the local optima of the OneJumpZeroJump problem at least as well as the global SEMO algorithm.
Feature extraction using Spectral Clustering for Gene Function Prediction
Mar 25, 2022

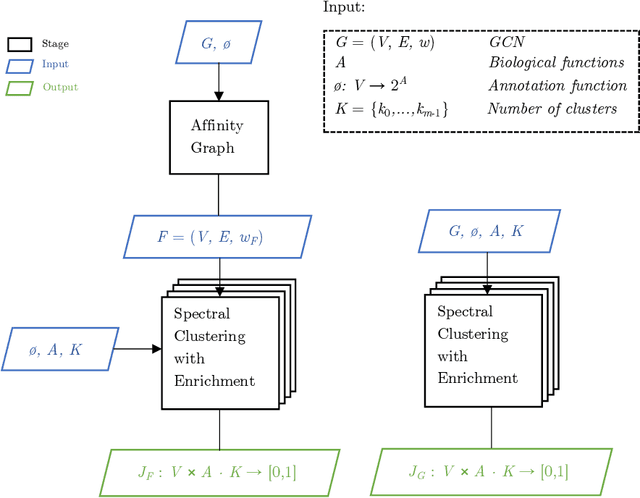
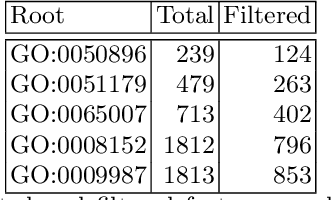
Gene annotation addresses the problem of predicting unknown associations between gene and functions (e.g., biological processes) of a specific organism. Despite recent advances, the cost and time demanded by annotation procedures that rely largely on in vivo biological experiments remain prohibitively high. This paper presents a novel in silico approach for to the annotation problem that combines cluster analysis and hierarchical multi-label classification (HMC). The approach uses spectral clustering to extract new features from the gene co-expression network (GCN) and enrich the prediction task. HMC is used to build multiple estimators that consider the hierarchical structure of gene functions. The proposed approach is applied to a case study on Zea mays, one of the most dominant and productive crops in the world. The results illustrate how in silico approaches are key to reduce the time and costs of gene annotation. More specifically, they highlight the importance of: (i) building new features that represent the structure of gene relationships in GCNs to annotate genes; and (ii) taking into account the structure of biological processes to obtain consistent predictions.
Analysis of OODA Loop based on Adversarial for Complex Game Environments
Mar 25, 2022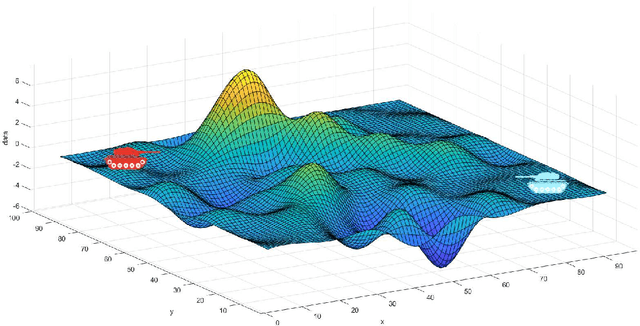
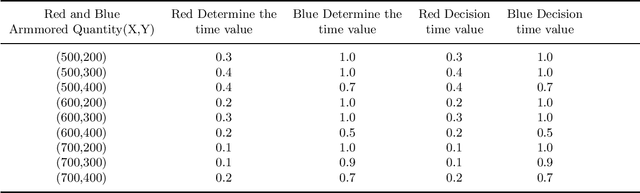
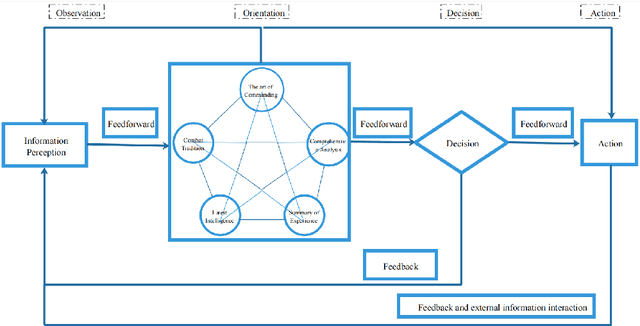
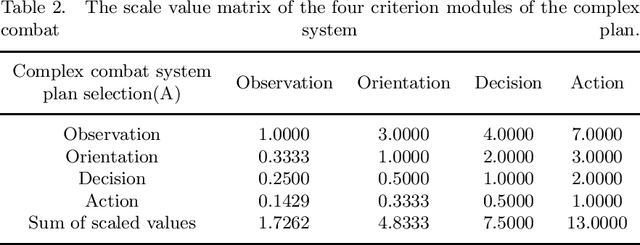
To address the problem of imperfect confrontation strategy caused by the lack of information of game environment in the simulation of non-complete information dynamic countermeasure modeling for intelligent game, the hierarchical analysis game strategy of confrontation model based on OODA ring (Observation, Orientation, Decision, Action) theory is proposed. At the same time, taking into account the trend of unmanned future warfare, NetLogo software simulation is used to construct a dynamic derivation of the confrontation between two tanks. In the validation process, the OODA loop theory is used to describe the operation process of the complex system between red and blue sides, and the four-step cycle of observation, judgment, decision and execution is carried out according to the number of armor of both sides, and then the OODA loop system adjusts the judgment and decision time coefficients for the next confrontation cycle according to the results of the first cycle. Compared with traditional simulation methods that consider objective factors such as loss rate and support rate, the OODA-loop-based hierarchical game analysis can analyze the confrontation situation more comprehensively.
Semi-Markov Offline Reinforcement Learning for Healthcare
Mar 21, 2022
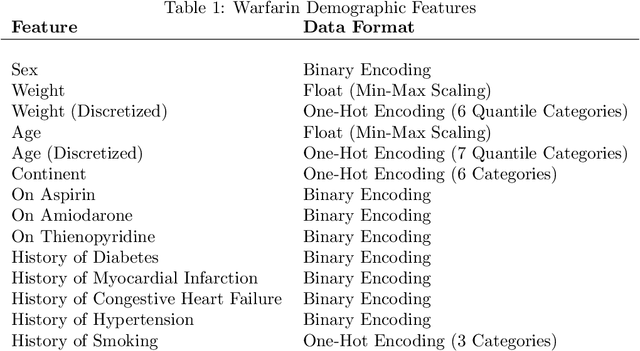
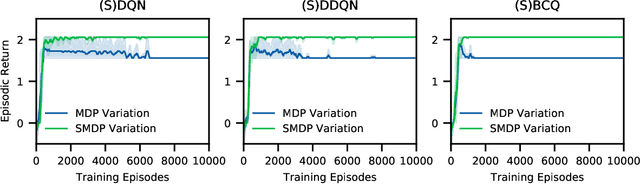
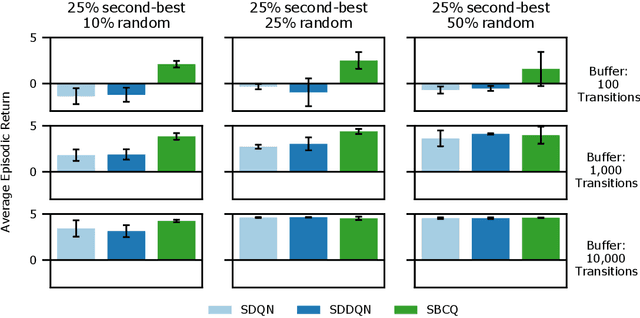
Reinforcement learning (RL) tasks are typically framed as Markov Decision Processes (MDPs), assuming that decisions are made at fixed time intervals. However, many applications of great importance, including healthcare, do not satisfy this assumption, yet they are commonly modelled as MDPs after an artificial reshaping of the data. In addition, most healthcare (and similar) problems are offline by nature, allowing for only retrospective studies. To address both challenges, we begin by discussing the Semi-MDP (SMDP) framework, which formally handles actions of variable timings. We next present a formal way to apply SMDP modifications to nearly any given value-based offline RL method. We use this theory to introduce three SMDP-based offline RL algorithms, namely, SDQN, SDDQN, and SBCQ. We then experimentally demonstrate that only these SMDP-based algorithms learn the optimal policy in variable-time environments, whereas their MDP counterparts do not. Finally, we apply our new algorithms to a real-world offline dataset pertaining to warfarin dosing for stroke prevention and demonstrate similar results.