 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Skeleton-based Action Recognition with Continual Spatio-Temporal Graph Convolutional Networks
Mar 21, 2022
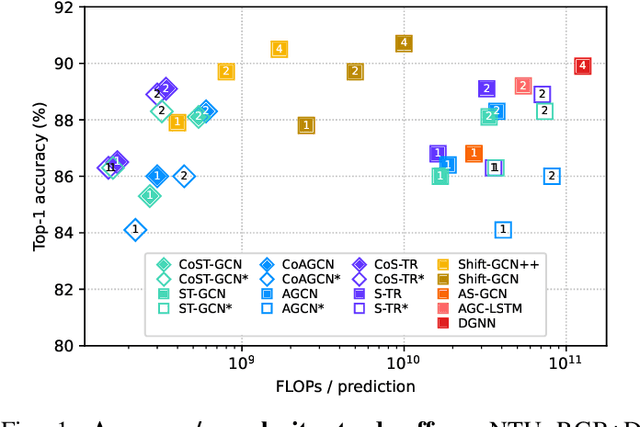
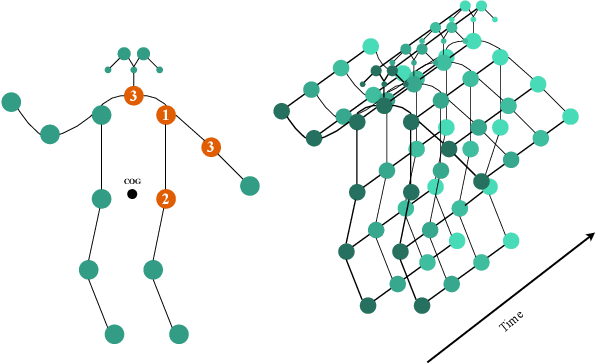
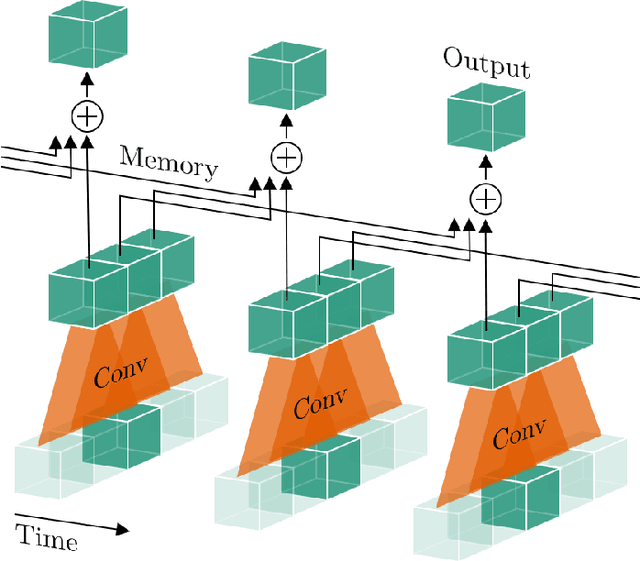
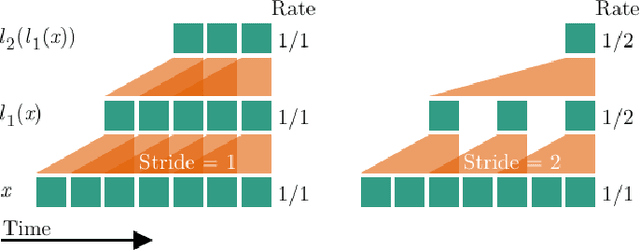
Graph-based reasoning over skeleton data has emerged as a promising approach for human action recognition. However, the application of prior graph-based methods, which predominantly employ whole temporal sequences as their input, to the setting of online inference entails considerable computational redundancy. In this paper, we tackle this issue by reformulating the Spatio-Temporal Graph Convolutional Neural Network as a Continual Inference Network, which can perform step-by-step predictions in time without repeat frame processing. To evaluate our method, we create a continual version of ST-GCN, CoST-GCN, alongside two derived methods with different self-attention mechanisms, CoAGCN and CoS-TR. We investigate weight transfer strategies and architectural modifications for inference acceleration, and perform experiments on the NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400 datasets. Retaining similar predictive accuracy, we observe up to 109x reduction in time complexity, on-hardware accelerations of 26x, and reductions in maximum allocated memory of 52% during online inference.
LQoCo: Learning to Optimize Cache Capacity Overloading in Storage Systems
Mar 21, 2022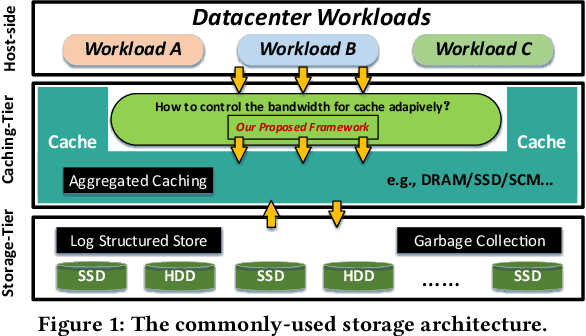

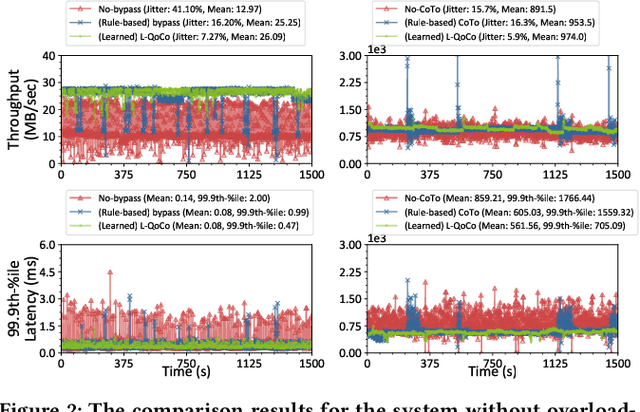
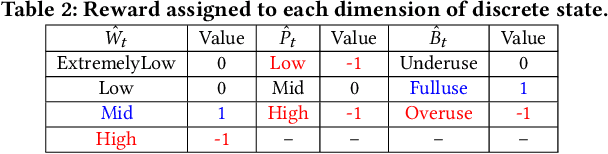
Cache plays an important role to maintain high and stable performance (i.e. high throughput, low tail latency and throughput jitter) in storage systems. Existing rule-based cache management methods, coupled with engineers' manual configurations, cannot meet ever-growing requirements of both time-varying workloads and complex storage systems, leading to frequent cache overloading. In this paper, we for the first time propose a light-weight learning-based cache bandwidth control technique, called \LQoCo which can adaptively control the cache bandwidth so as to effectively prevent cache overloading in storage systems. Extensive experiments with various workloads on real systems show that LQoCo, with its strong adaptability and fast learning ability, can adapt to various workloads to effectively control cache bandwidth, thereby significantly improving the storage performance (e.g. increasing the throughput by 10\%-20\% and reducing the throughput jitter and tail latency by 2X-6X and 1.5X-4X, respectively, compared with two representative rule-based methods).
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022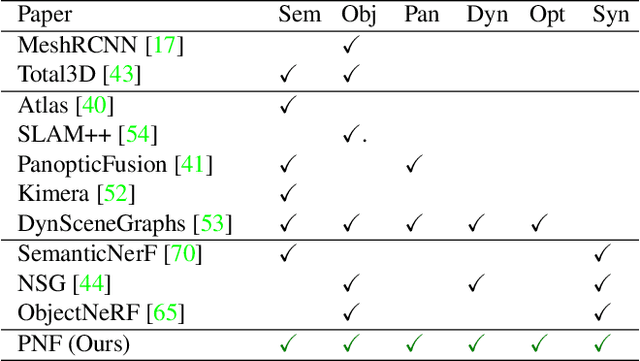
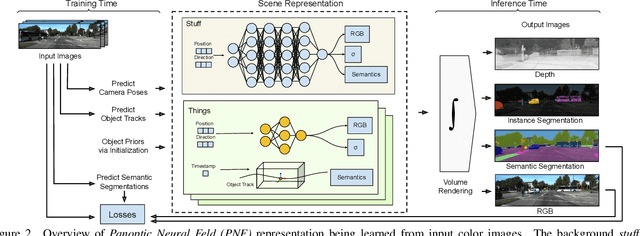
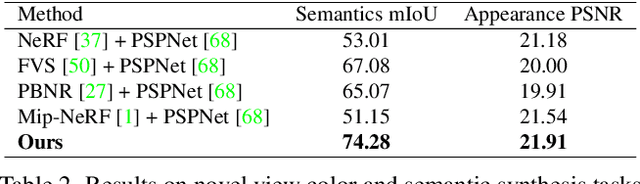
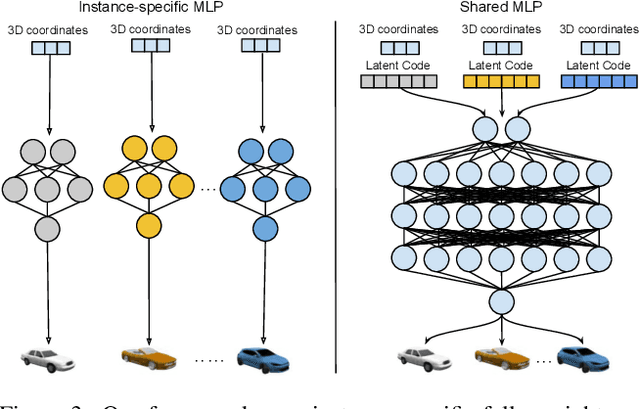
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
Online multi-resolution fusion of space-borne multispectral images
Apr 26, 2022
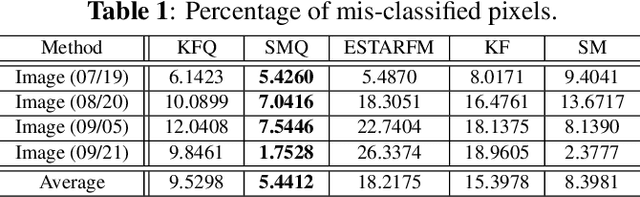
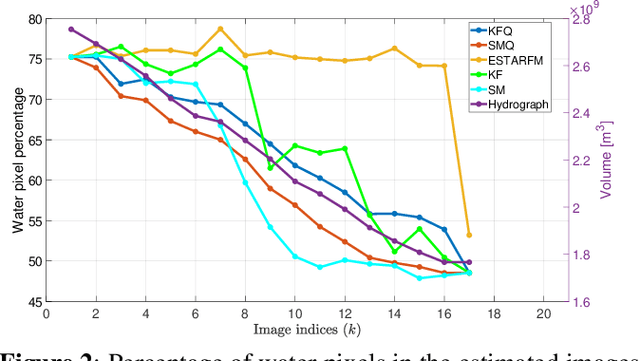
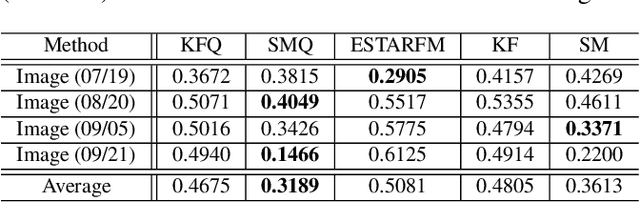
Satellite imaging has a central role in monitoring, detecting and estimating the intensity of key natural phenomena. One important feature of satellite images is the trade-off between spatial/spectral resolution and their revisiting time, a consequence of design and physical constraints imposed by satellite orbit among other technical limitations. In this paper, we focus on fusing multi-temporal, multi-spectral images where data acquired from different instruments with different spatial resolutions is used. We leverage the spatial relationship between images at multiple modalities to generate high-resolution image sequences at higher revisiting rates. To achieve this goal, we formulate the fusion method as a recursive state estimation problem and study its performance in filtering and smoothing contexts. The proposed strategy clearly outperforms competing methodologies, which is shown in the paper for real data acquired by the Landsat and MODIS instruments.
Reachability Constrained Reinforcement Learning
May 16, 2022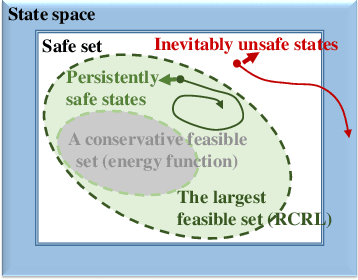
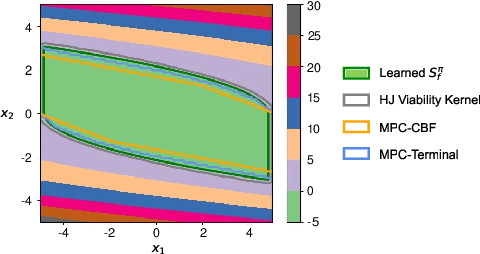
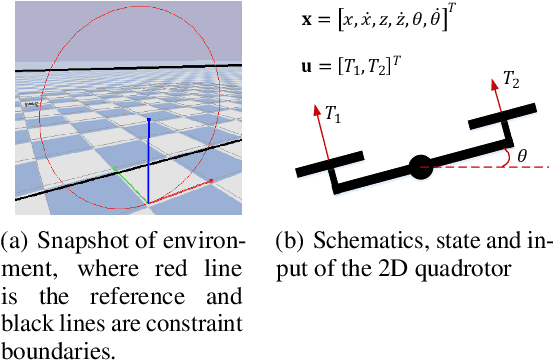
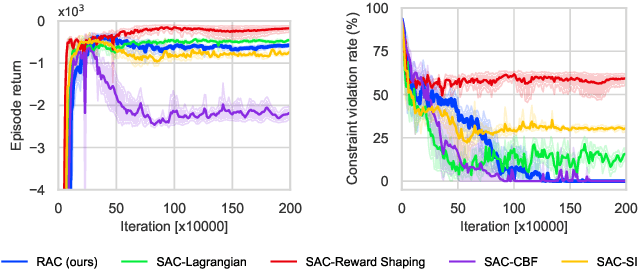
Constrained Reinforcement Learning (CRL) has gained significant interest recently, since the satisfaction of safety constraints is critical for real world problems. However, existing CRL methods constraining discounted cumulative costs generally lack rigorous definition and guarantee of safety. On the other hand, in the safe control research, safety is defined as persistently satisfying certain state constraints. Such persistent safety is possible only on a subset of the state space, called feasible set, where an optimal largest feasible set exists for a given environment. Recent studies incorporating safe control with CRL using energy-based methods such as control barrier function (CBF), safety index (SI) leverage prior conservative estimation of feasible sets, which harms performance of the learned policy. To deal with this problem, this paper proposes a reachability CRL (RCRL) method by using reachability analysis to characterize the largest feasible sets. We characterize the feasible set by the established self-consistency condition, then a safety value function can be learned and used as constraints in CRL. We also use the multi-time scale stochastic approximation theory to prove that the proposed algorithm converges to a local optimum, where the largest feasible set can be guaranteed. Empirical results on different benchmarks such as safe-control-gym and Safety-Gym validate the learned feasible set, the performance in optimal criteria, and constraint satisfaction of RCRL, compared to state-of-the-art CRL baselines.
Functional Time Series Forecasting: Functional Singular Spectrum Analysis Approaches
Dec 06, 2020
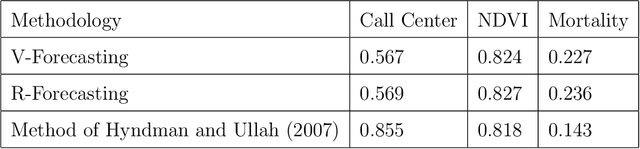
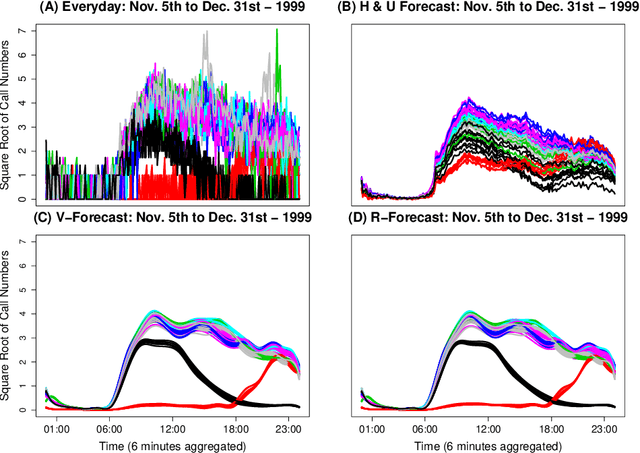
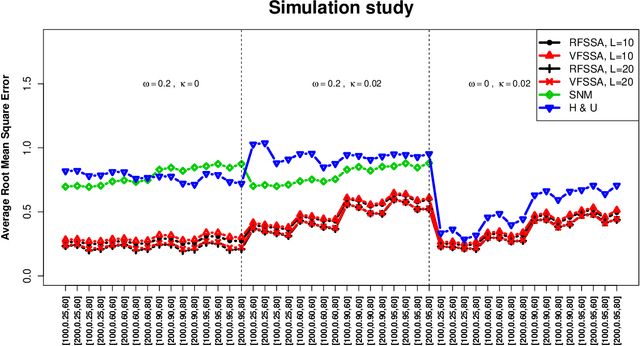
In this paper, we propose two nonparametric methods used in the forecasting of functional time-dependent data, namely functional singular spectrum analysis recurrent forecasting and vector forecasting. Both algorithms utilize the results of functional singular spectrum analysis and past observations in order to predict future data points where recurrent forecasting predicts one function at a time and the vector forecasting makes predictions using functional vectors. We compare our forecasting methods to a gold standard algorithm used in the prediction of functional, time-dependent data by way of simulation and real data and we find our techniques do better for periodic stochastic processes.
Quantifying Language Variation Acoustically with Few Resources
May 05, 2022
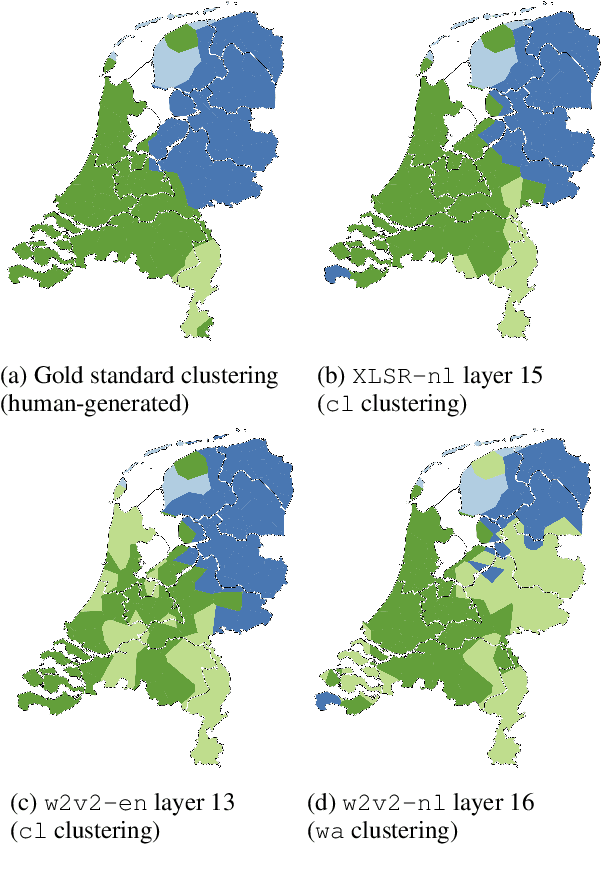
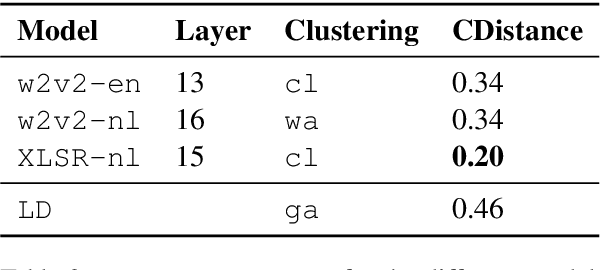
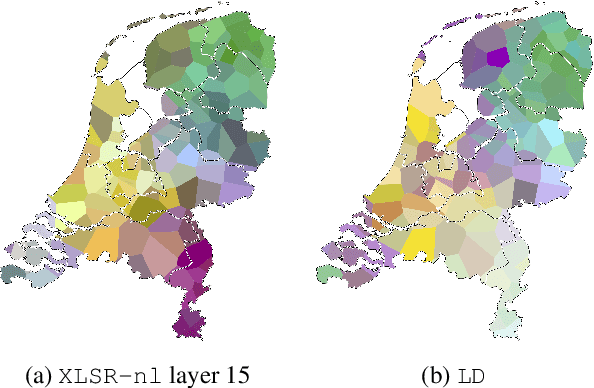
Deep acoustic models represent linguistic information based on massive amounts of data. Unfortunately, for regional languages and dialects such resources are mostly not available. However, deep acoustic models might have learned linguistic information that transfers to low-resource languages. In this study, we evaluate whether this is the case through the task of distinguishing low-resource (Dutch) regional varieties. By extracting embeddings from the hidden layers of various wav2vec 2.0 models (including new models which are pre-trained and/or fine-tuned on Dutch) and using dynamic time warping, we compute pairwise pronunciation differences averaged over 10 words for over 100 individual dialects from four (regional) languages. We then cluster the resulting difference matrix in four groups and compare these to a gold standard, and a partitioning on the basis of comparing phonetic transcriptions. Our results show that acoustic models outperform the (traditional) transcription-based approach without requiring phonetic transcriptions, with the best performance achieved by the multilingual XLSR-53 model fine-tuned on Dutch. On the basis of only six seconds of speech, the resulting clustering closely matches the gold standard.
Residual Local Feature Network for Efficient Super-Resolution
May 16, 2022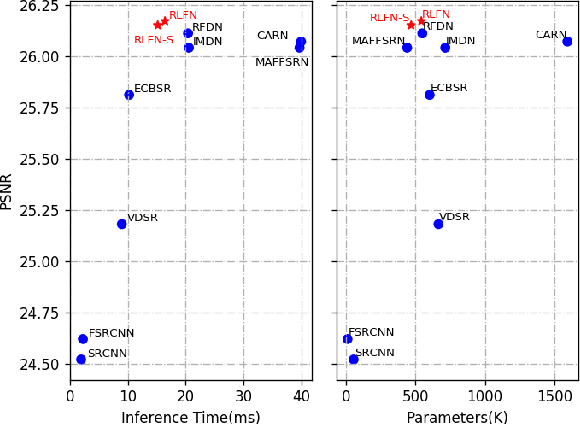
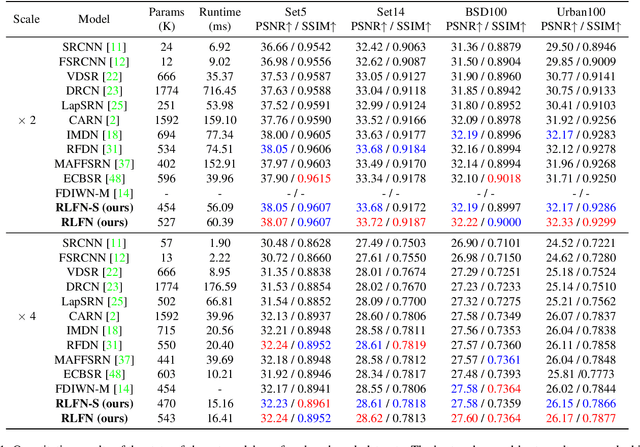
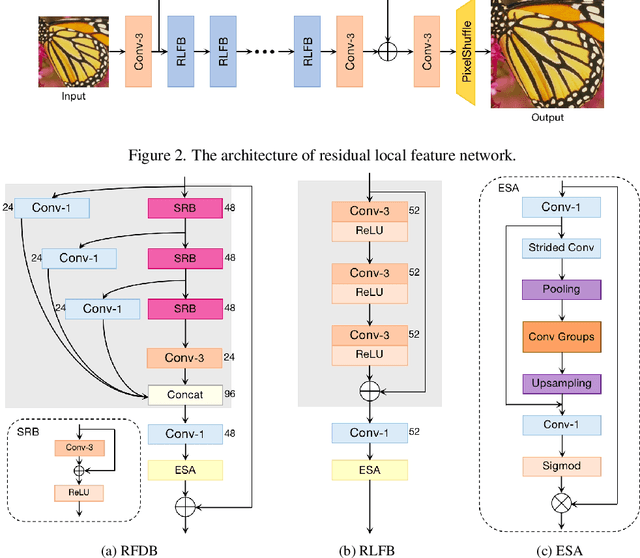
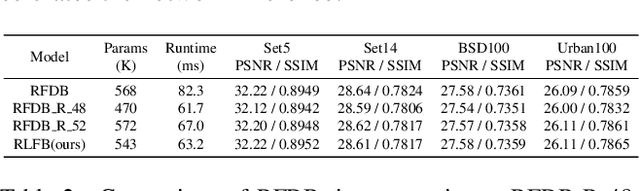
Deep learning based approaches has achieved great performance in single image super-resolution (SISR). However, recent advances in efficient super-resolution focus on reducing the number of parameters and FLOPs, and they aggregate more powerful features by improving feature utilization through complex layer connection strategies. These structures may not be necessary to achieve higher running speed, which makes them difficult to be deployed to resource-constrained devices. In this work, we propose a novel Residual Local Feature Network (RLFN). The main idea is using three convolutional layers for residual local feature learning to simplify feature aggregation, which achieves a good trade-off between model performance and inference time. Moreover, we revisit the popular contrastive loss and observe that the selection of intermediate features of its feature extractor has great influence on the performance. Besides, we propose a novel multi-stage warm-start training strategy. In each stage, the pre-trained weights from previous stages are utilized to improve the model performance. Combined with the improved contrastive loss and training strategy, the proposed RLFN outperforms all the state-of-the-art efficient image SR models in terms of runtime while maintaining both PSNR and SSIM for SR. In addition, we won the first place in the runtime track of the NTIRE 2022 efficient super-resolution challenge. Code will be available at https://github.com/fyan111/RLFN.
Offline Distillation for Robot Lifelong Learning with Imbalanced Experience
Apr 12, 2022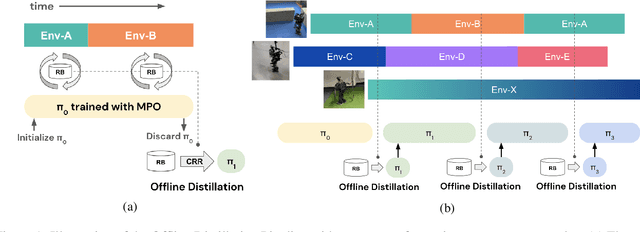
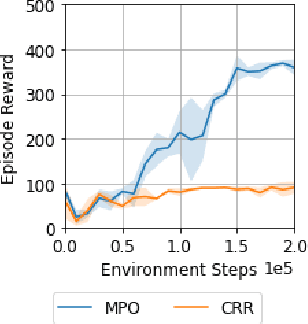
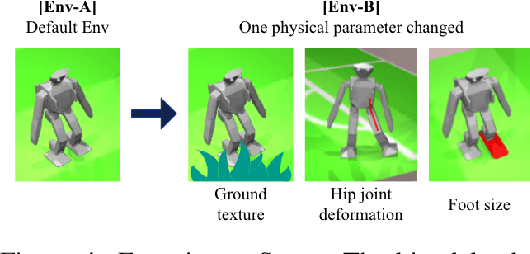
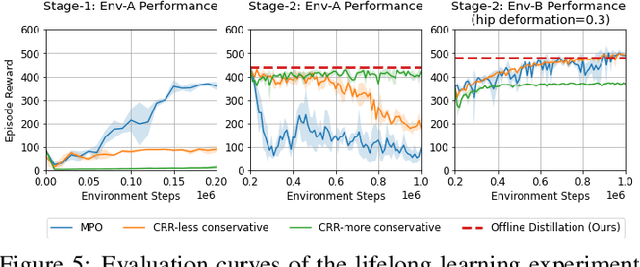
Robots will experience non-stationary environment dynamics throughout their lifetime: the robot dynamics can change due to wear and tear, or its surroundings may change over time. Eventually, the robots should perform well in all of the environment variations it has encountered. At the same time, it should still be able to learn fast in a new environment. We investigate two challenges in such a lifelong learning setting: first, existing off-policy algorithms struggle with the trade-off between being conservative to maintain good performance in the old environment and learning efficiently in the new environment. We propose the Offline Distillation Pipeline to break this trade-off by separating the training procedure into interleaved phases of online interaction and offline distillation. Second, training with the combined datasets from multiple environments across the lifetime might create a significant performance drop compared to training on the datasets individually. Our hypothesis is that both the imbalanced quality and size of the datasets exacerbate the extrapolation error of the Q-function during offline training over the "weaker" dataset. We propose a simple fix to the issue by keeping the policy closer to the dataset during the distillation phase. In the experiments, we demonstrate these challenges and the proposed solutions with a simulated bipedal robot walking task across various environment changes. We show that the Offline Distillation Pipeline achieves better performance across all the encountered environments without affecting data collection. We also provide a comprehensive empirical study to support our hypothesis on the data imbalance issue.
Weakly-supervised Temporal Path Representation Learning with Contrastive Curriculum Learning -- Extended Version
Apr 15, 2022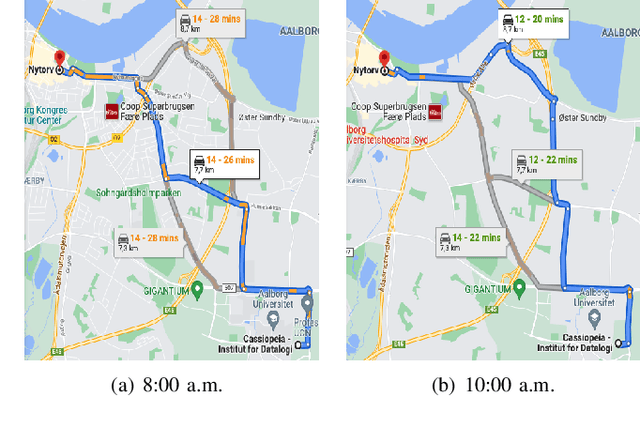
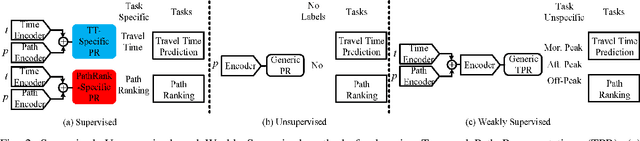
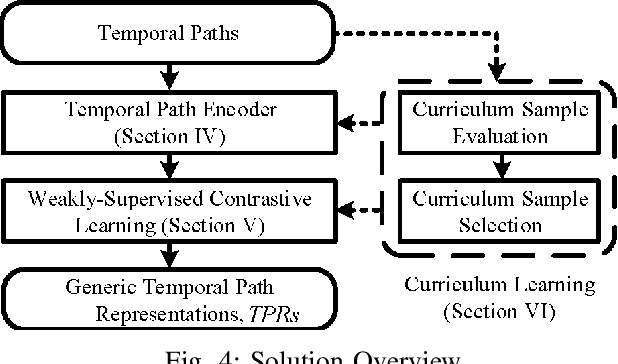
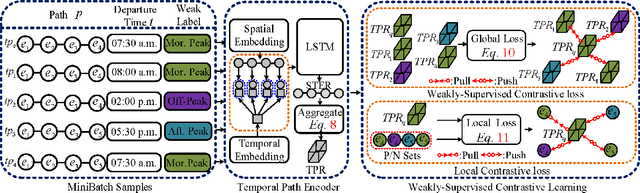
In step with the digitalization of transportation, we are witnessing a growing range of path-based smart-city applications, e.g., travel-time estimation and travel path ranking. A temporal path(TP) that includes temporal information, e.g., departure time, into the path is fundamental to enable such applications. In this setting, it is essential to learn generic temporal path representations(TPRs) that consider spatial and temporal correlations simultaneously and that can be used in different applications, i.e., downstream tasks. Existing methods fail to achieve the goal since (i) supervised methods require large amounts of task-specific labels when training and thus fail to generalize the obtained TPRs to other tasks; (ii) through unsupervised methods can learn generic representations, they disregard the temporal aspect, leading to sub-optimal results. To contend with the limitations of existing solutions, we propose a Weakly-Supervised Contrastive (WSC) learning model. We first propose a temporal path encoder that encodes both the spatial and temporal information of a temporal path into a TPR. To train the encoder, we introduce weak labels that are easy and inexpensive to obtain and are relevant to different tasks, e.g., temporal labels indicating peak vs. off-peak hours from departure times. Based on the weak labels, we construct meaningful positive and negative temporal path samples by considering both spatial and temporal information, which facilities training the encoder using contrastive learning by pulling closer to the positive samples' representations while pushing away the negative samples' representations. To better guide contrastive learning, we propose a learning strategy based on Curriculum Learning such that the learning performs from easy to hard training instances. Experiments studies verify the effectiveness of the proposed method.