 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scalable and Efficient Training of Large Convolutional Neural Networks with Differential Privacy
May 21, 2022
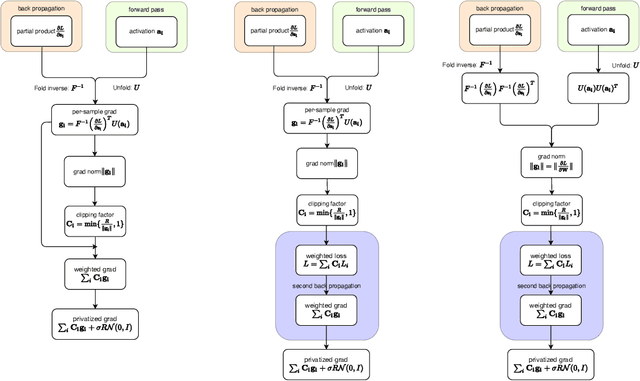
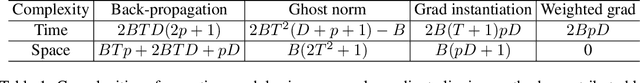

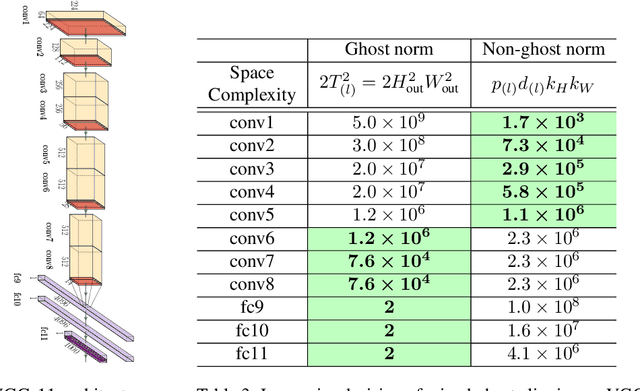
Large convolutional neural networks (CNN) can be difficult to train in the differentially private (DP) regime, since the optimization algorithms require a computationally expensive operation, known as the per-sample gradient clipping. We propose an efficient and scalable implementation of this clipping on convolutional layers, termed as the mixed ghost clipping, that significantly eases the private training in terms of both time and space complexities, without affecting the accuracy. The improvement in efficiency is rigorously studied through the first complexity analysis for the mixed ghost clipping and existing DP training algorithms. Extensive experiments on vision classification tasks, with large ResNet, VGG, and Vision Transformers, demonstrate that DP training with mixed ghost clipping adds $1\sim 10\%$ memory overhead and $<2\times$ slowdown to the standard non-private training. Specifically, when training VGG19 on CIFAR10, the mixed ghost clipping is $3\times$ faster than state-of-the-art Opacus library with $18\times$ larger maximum batch size. To emphasize the significance of efficient DP training on convolutional layers, we achieve 96.7\% accuracy on CIFAR10 and 83.0\% on CIFAR100 at $\epsilon=1$ using BEiT, while the previous best results are 94.8\% and 67.4\%, respectively. We open-source a privacy engine (\url{https://github.com/JialinMao/private_CNN}) that implements DP training of CNN with a few lines of code.
Contrastive learning of strong-mixing continuous-time stochastic processes
Mar 03, 2021Contrastive learning is a family of self-supervised methods where a model is trained to solve a classification task constructed from unlabeled data. It has recently emerged as one of the leading learning paradigms in the absence of labels across many different domains (e.g. brain imaging, text, images). However, theoretical understanding of many aspects of training, both statistical and algorithmic, remain fairly elusive. In this work, we study the setting of time series -- more precisely, when we get data from a strong-mixing continuous-time stochastic process. We show that a properly constructed contrastive learning task can be used to estimate the transition kernel for small-to-mid-range intervals in the diffusion case. Moreover, we give sample complexity bounds for solving this task and quantitatively characterize what the value of the contrastive loss implies for distributional closeness of the learned kernel. As a byproduct, we illuminate the appropriate settings for the contrastive distribution, as well as other hyperparameters in this setup.
Reinforcement Learning for Branch-and-Bound Optimisation using Retrospective Trajectories
May 28, 2022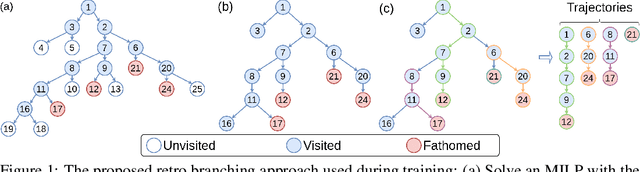
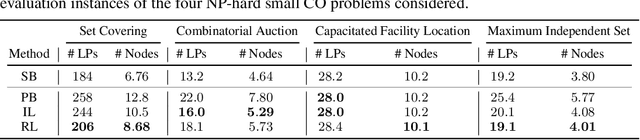
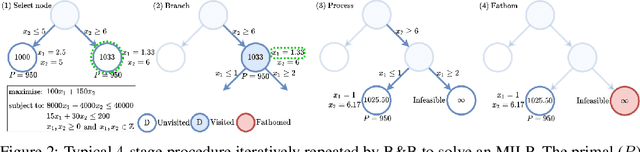
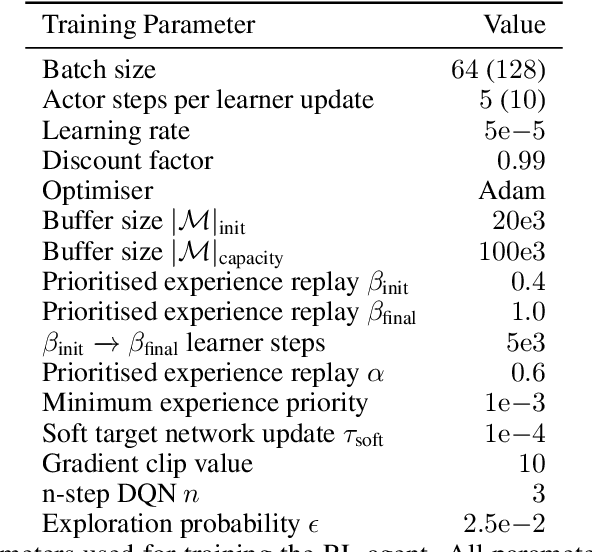
Combinatorial optimisation problems framed as mixed integer linear programmes (MILPs) are ubiquitous across a range of real-world applications. The canonical branch-and-bound (B&B) algorithm seeks to exactly solve MILPs by constructing a search tree of increasingly constrained sub-problems. In practice, its solving time performance is dependent on heuristics, such as the choice of the next variable to constrain ('branching'). Recently, machine learning (ML) has emerged as a promising paradigm for branching. However, prior works have struggled to apply reinforcement learning (RL), citing sparse rewards, difficult exploration, and partial observability as significant challenges. Instead, leading ML methodologies resort to approximating high quality handcrafted heuristics with imitation learning (IL), which precludes the discovery of novel policies and requires expensive data labelling. In this work, we propose retro branching; a simple yet effective approach to RL for branching. By retrospectively deconstructing the search tree into multiple paths each contained within a sub-tree, we enable the agent to learn from shorter trajectories with more predictable next states. In experiments on four combinatorial tasks, our approach enables learning-to-branch without any expert guidance or pre-training. We outperform the current state-of-the-art RL branching algorithm by 3-5x and come within 20% of the best IL method's performance on MILPs with 500 constraints and 1000 variables, with ablations verifying that our retrospectively constructed trajectories are essential to achieving these results.
Multi-Faceted Representation Learning with Hybrid Architecture for Time Series Classification
Dec 21, 2020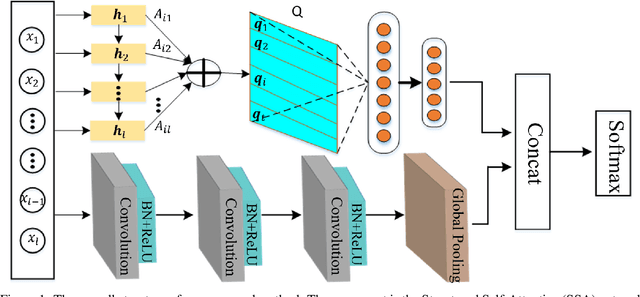
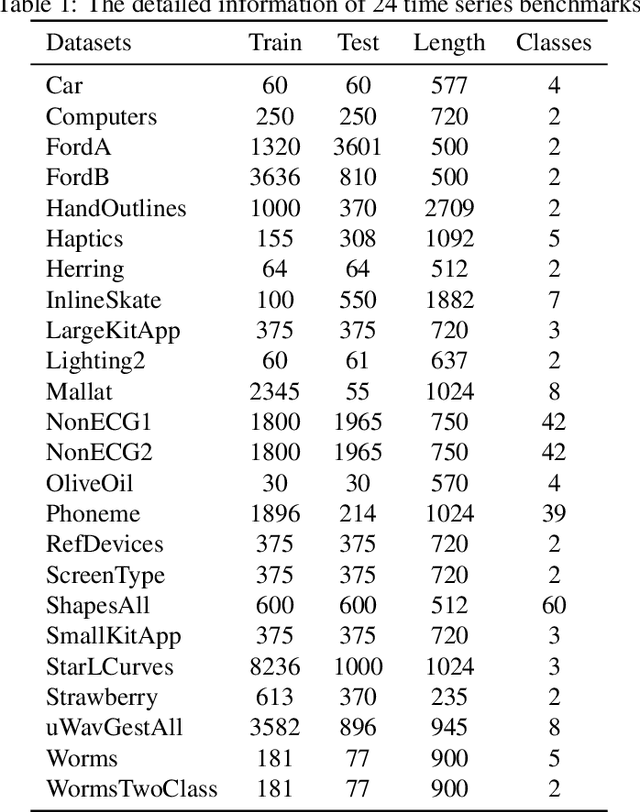
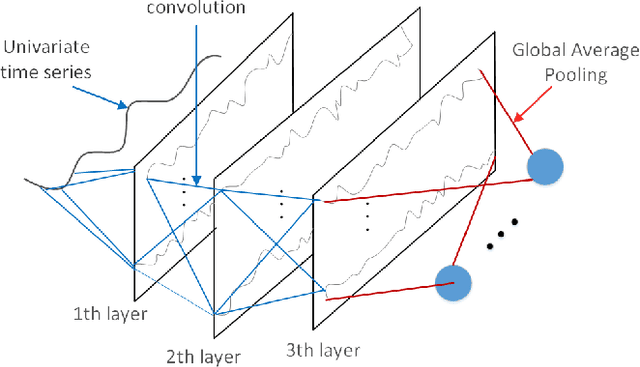
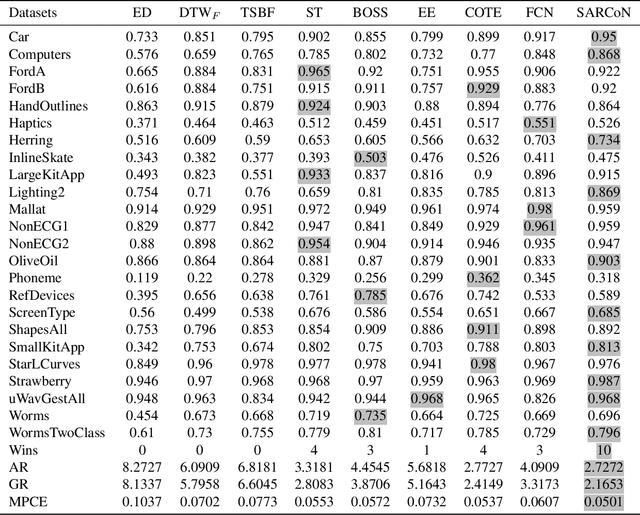
Time series classification problems exist in many fields and have been explored for a couple of decades. However, they still remain challenging, and their solutions need to be further improved for real-world applications in terms of both accuracy and efficiency. In this paper, we propose a hybrid neural architecture, called Self-Attentive Recurrent Convolutional Networks (SARCoN), to learn multi-faceted representations for univariate time series. SARCoN is the synthesis of long short-term memory networks with self-attentive mechanisms and Fully Convolutional Networks, which work in parallel to learn the representations of univariate time series from different perspectives. The component modules of the proposed architecture are trained jointly in an end-to-end manner and they classify the input time series in a cooperative way. Due to its domain-agnostic nature, SARCoN is able to generalize a diversity of domain tasks. Our experimental results show that, compared to the state-of-the-art approaches for time series classification, the proposed architecture can achieve remarkable improvements for a set of univariate time series benchmarks from the UCR repository. Moreover, the self-attention and the global average pooling in the proposed architecture enable visible interpretability by facilitating the identification of the contribution regions of the original time series. An overall analysis confirms that multi-faceted representations of time series aid in capturing deep temporal corrections within complex time series, which is essential for the improvement of time series classification performance. Our work provides a novel angle that deepens the understanding of time series classification, qualifying our proposed model as an ideal choice for real-world applications.
Hardware System Implementation for Human Detection using HOG and SVM Algorithm
May 05, 2022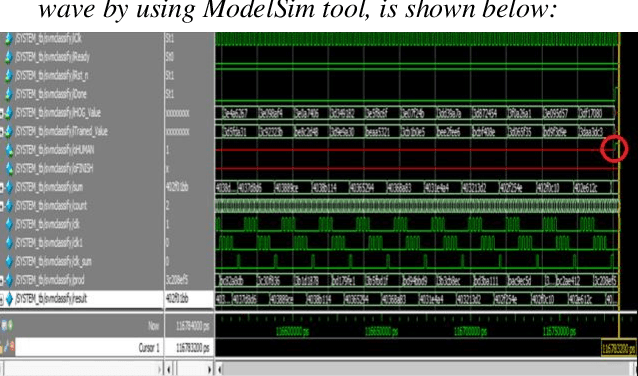
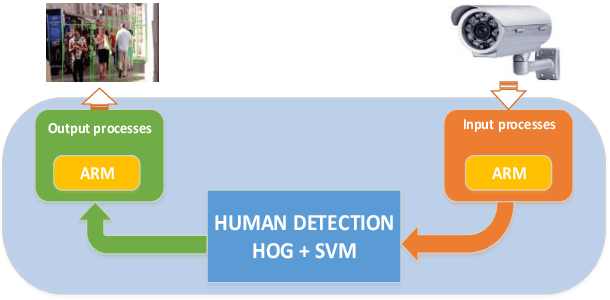


Human detection is a popular issue and has been widely used in many applications. However, including complexities in computation, leading to the human detection system implemented hardly in real-time applications. This paper presents the architecture of hardware, a human detection system that was simulated in the ModelSim tool. As a co-processor, this system was built to off-load to Central Processor Unit (CPU) and speed up the computation timing. The 130x66 RGB pixels of static input image attracted features and classify by using the Histogram of Oriented Gradient (HOG) algorithm and Support Vector Machine (SVM) algorithm, respectively. As a result, the accuracy rate of this system reaches 84.35 percent. And the timing for detection decreases to 0.757 ms at 50MHz frequency (54 times faster when this system was implemented in software by using the Matlab tool).
Age of Information in the Presence of an Adversary
Feb 08, 2022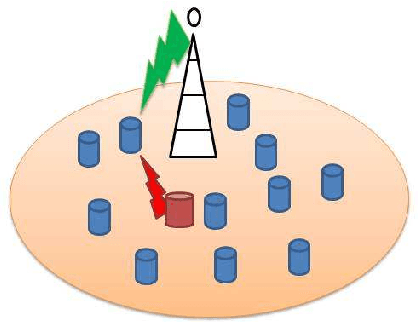
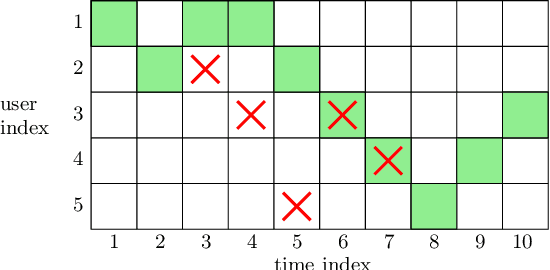
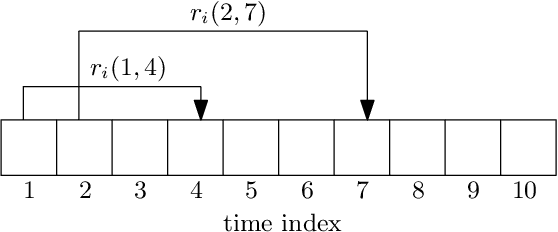
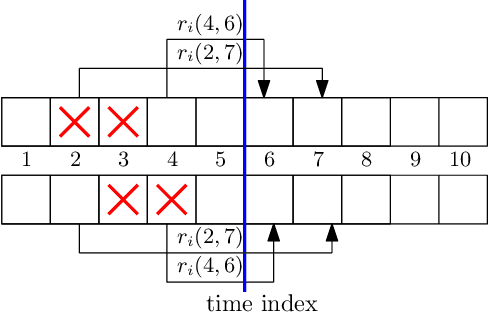
We consider a communication system where a base station serves $N$ users, one user at a time, over a wireless channel. We consider the timeliness of the communication of each user via the age of information metric. A constrained adversary can block at most a given fraction, $\alpha$, of the time slots over a horizon of $T$ slots, i.e., it can block at most $\alpha T$ slots. We show that an optimum adversary blocks $\alpha T$ consecutive time slots of a randomly selected user. The interesting consecutive property of the blocked time slots is due to the cumulative nature of the age metric.
Efficient Textured Mesh Recovery from Multiple Views with Differentiable Rendering
May 25, 2022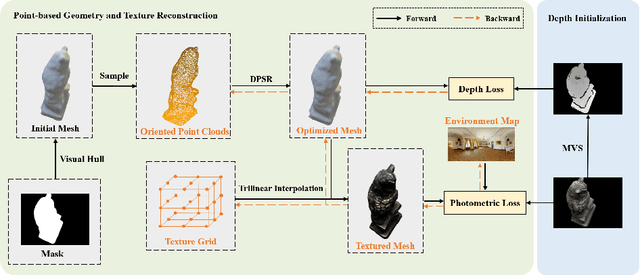
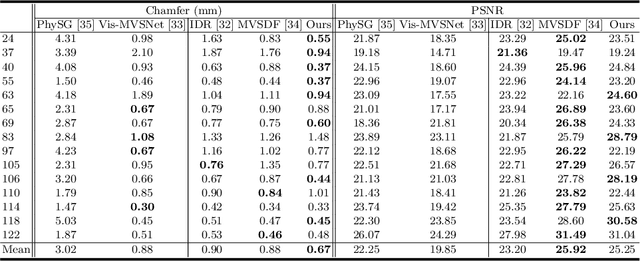


Despite of the promising results on shape and color recovery using self-supervision, the multi-layer perceptrons-based methods usually costs hours to train the deep neural network due to the implicit surface representation. Moreover, it is quite computational intensive to render a single image, since a forward network inference is required for each pixel. To tackle these challenges, in this paper, we propose an efficient coarse-to-fine approach to recover the textured mesh from multi-view images. Specifically, we take advantage of a differentiable Poisson Solver to represent the shape, which is able to produce topology-agnostic and watertight surfaces. To account for the depth information, we optimize the shape geometry by minimizing the difference between the rendered mesh with the depth predicted by the learning-based multi-view stereo algorithm. In contrast to the implicit neural representation on shape and color, we introduce a physically based inverse rendering scheme to jointly estimate the lighting and reflectance of the objects, which is able to render the high resolution image at real-time. Additionally, we fine-tune the extracted mesh by inverse rendering to obtain the mesh with fine details and high fidelity image. We have conducted the extensive experiments on several multi-view stereo datasets, whose promising results demonstrate the efficacy of our proposed approach. We will make our full implementation publicly available.
Deep Visual Geo-localization Benchmark
Apr 07, 2022
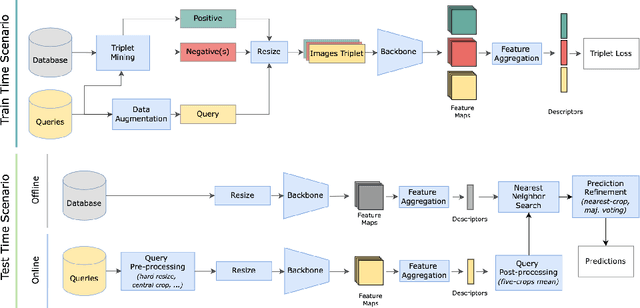
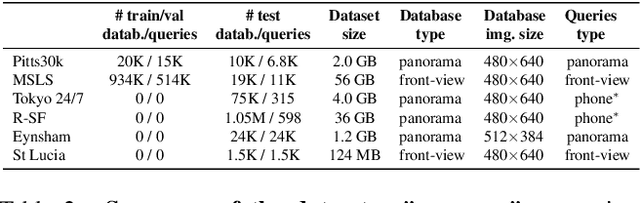

In this paper, we propose a new open-source benchmarking framework for Visual Geo-localization (VG) that allows to build, train, and test a wide range of commonly used architectures, with the flexibility to change individual components of a geo-localization pipeline. The purpose of this framework is twofold: i) gaining insights into how different components and design choices in a VG pipeline impact the final results, both in terms of performance (recall@N metric) and system requirements (such as execution time and memory consumption); ii) establish a systematic evaluation protocol for comparing different methods. Using the proposed framework, we perform a large suite of experiments which provide criteria for choosing backbone, aggregation and negative mining depending on the use-case and requirements. We also assess the impact of engineering techniques like pre/post-processing, data augmentation and image resizing, showing that better performance can be obtained through somewhat simple procedures: for example, downscaling the images' resolution to 80% can lead to similar results with a 36% savings in extraction time and dataset storage requirement. Code and trained models are available at https://deep-vg-bench.herokuapp.com/.
Towards Real-time Semantic RGB-D SLAM in Dynamic Environments
Apr 03, 2021


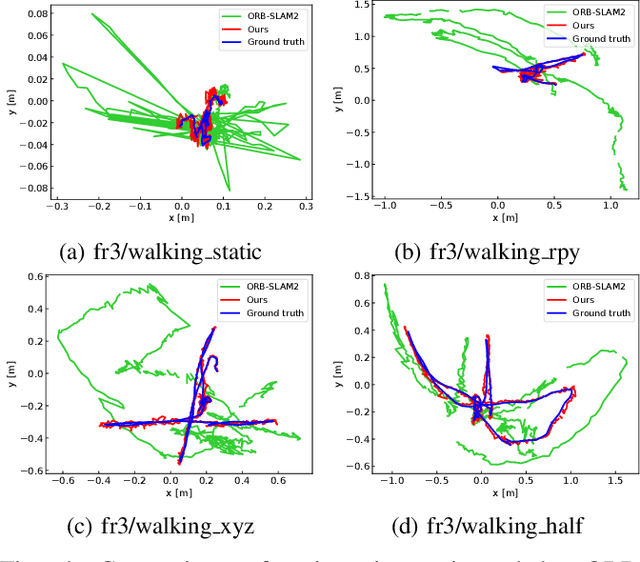
Most of the existing visual SLAM methods heavily rely on a static world assumption and easily fail in dynamic environments. Some recent works eliminate the influence of dynamic objects by introducing deep learning-based semantic information to SLAM systems. However such methods suffer from high computational cost and cannot handle unknown objects. In this paper, we propose a real-time semantic RGB-D SLAM system for dynamic environments that is capable of detecting both known and unknown moving objects. To reduce the computational cost, we only perform semantic segmentation on keyframes to remove known dynamic objects, and maintain a static map for robust camera tracking. Furthermore, we propose an efficient geometry module to detect unknown moving objects by clustering the depth image into a few regions and identifying the dynamic regions via their reprojection errors. The proposed method is evaluated on public datasets and real-world conditions. To the best of our knowledge, it is one of the first semantic RGB-D SLAM systems that run in real-time on a low-power embedded platform and provide high localization accuracy in dynamic environments.
Automatic Expert Selection for Multi-Scenario and Multi-Task Search
May 28, 2022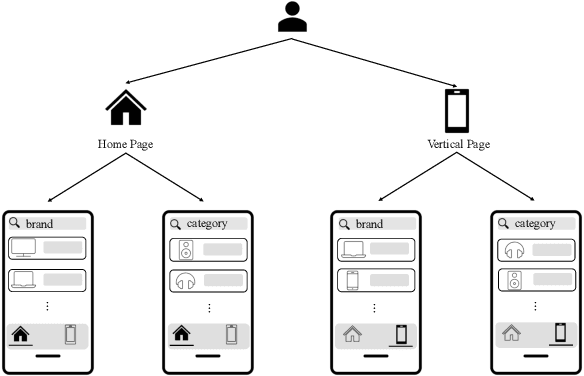
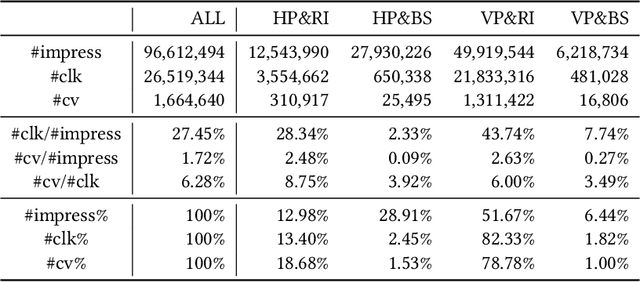
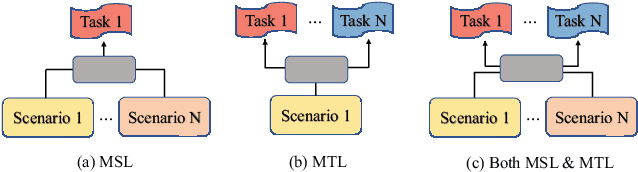
Multi-scenario learning (MSL) enables a service provider to cater for users' fine-grained demands by separating services for different user sectors, e.g., by user's geographical region. Under each scenario there is a need to optimize multiple task-specific targets e.g., click through rate and conversion rate, known as multi-task learning (MTL). Recent solutions for MSL and MTL are mostly based on the multi-gate mixture-of-experts (MMoE) architecture. MMoE structure is typically static and its design requires domain-specific knowledge, making it less effective in handling both MSL and MTL. In this paper, we propose a novel Automatic Expert Selection framework for Multi-scenario and Multi-task search, named AESM^{2}. AESM^{2} integrates both MSL and MTL into a unified framework with an automatic structure learning. Specifically, AESM^{2} stacks multi-task layers over multi-scenario layers. This hierarchical design enables us to flexibly establish intrinsic connections between different scenarios, and at the same time also supports high-level feature extraction for different tasks. At each multi-scenario/multi-task layer, a novel expert selection algorithm is proposed to automatically identify scenario-/task-specific and shared experts for each input. Experiments over two real-world large-scale datasets demonstrate the effectiveness of AESM^{2} over a battery of strong baselines. Online A/B test also shows substantial performance gain on multiple metrics. Currently, AESM^{2} has been deployed online for serving major traffic.