 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Differentiable Zooming for Multiple Instance Learning on Whole-Slide Images
Apr 30, 2022
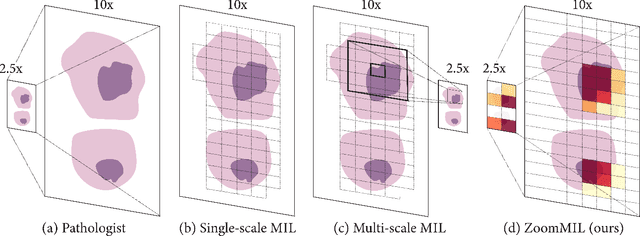
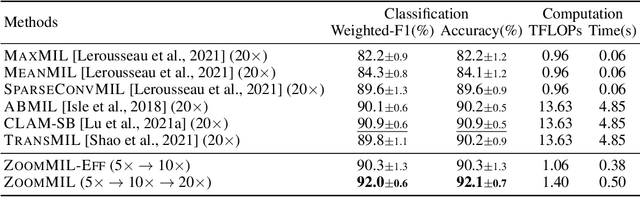
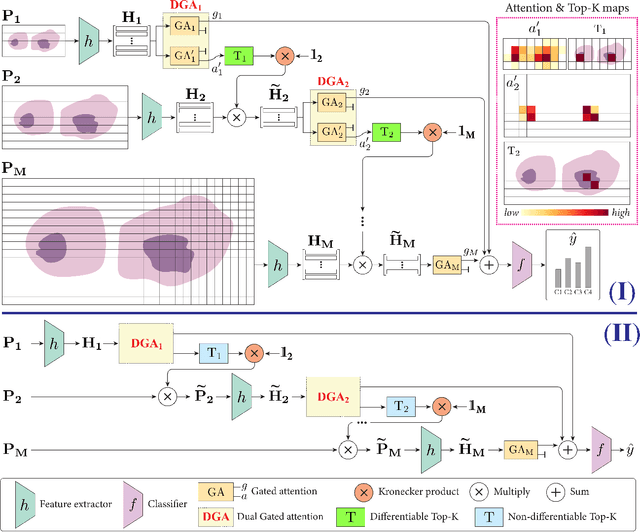
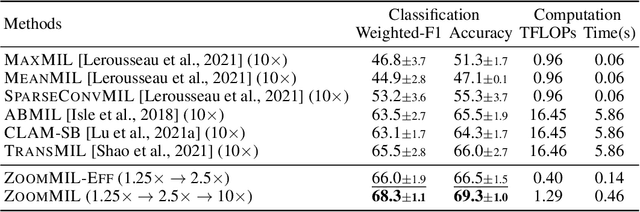
Multiple Instance Learning (MIL) methods have become increasingly popular for classifying giga-pixel sized Whole-Slide Images (WSIs) in digital pathology. Most MIL methods operate at a single WSI magnification, by processing all the tissue patches. Such a formulation induces high computational requirements, and constrains the contextualization of the WSI-level representation to a single scale. A few MIL methods extend to multiple scales, but are computationally more demanding. In this paper, inspired by the pathological diagnostic process, we propose ZoomMIL, a method that learns to perform multi-level zooming in an end-to-end manner. ZoomMIL builds WSI representations by aggregating tissue-context information from multiple magnifications. The proposed method outperforms the state-of-the-art MIL methods in WSI classification on two large datasets, while significantly reducing the computational demands with regard to Floating-Point Operations (FLOPs) and processing time by up to 40x.
Secure Federated Learning for Neuroimaging
May 11, 2022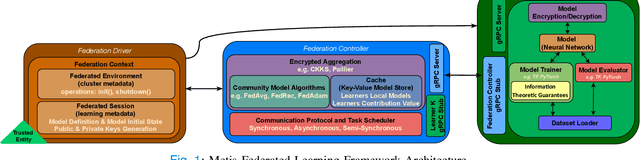
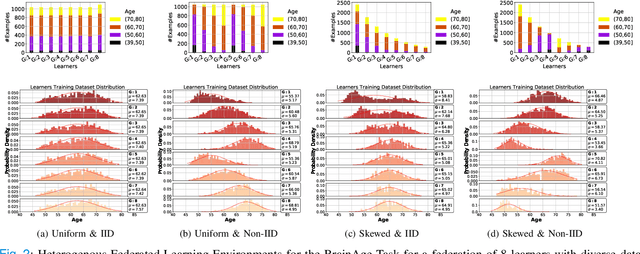
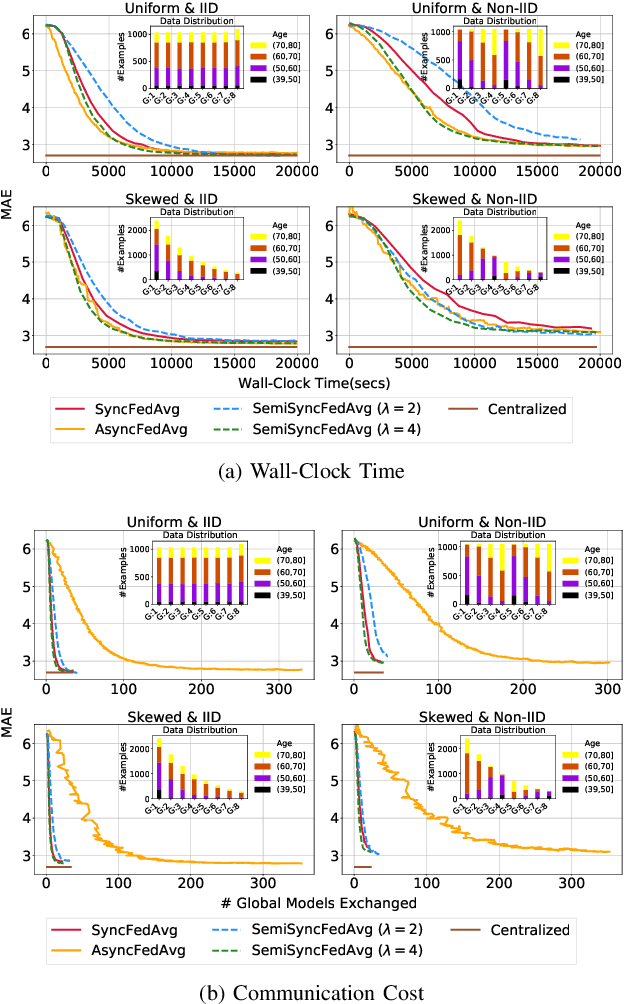
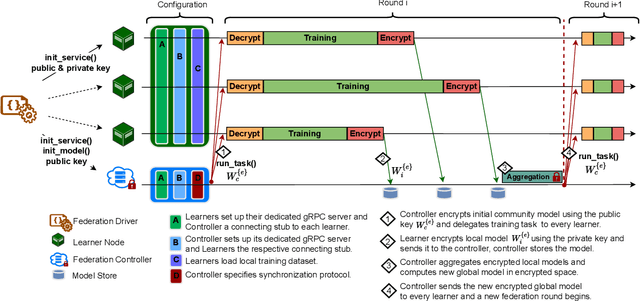
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
UnseenNet: Fast Training Detector for Any Unseen Concept
Mar 26, 2022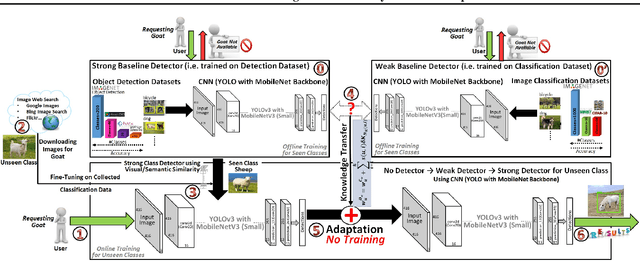
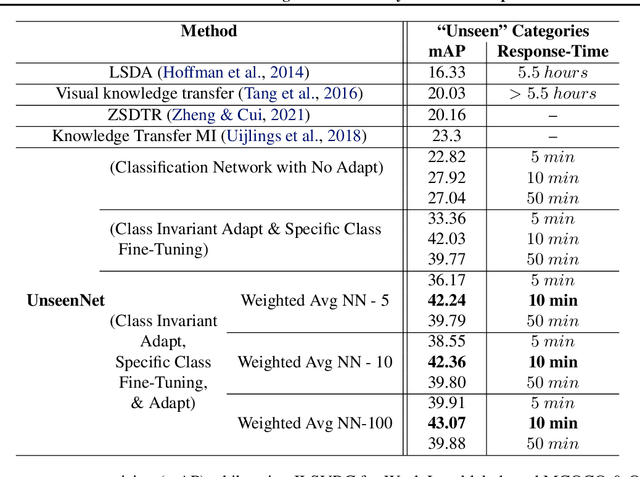
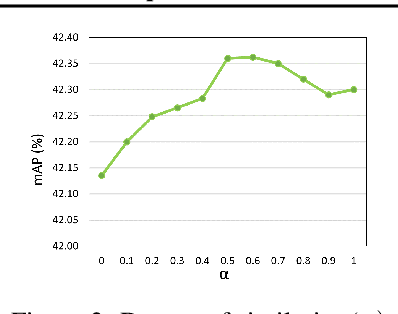
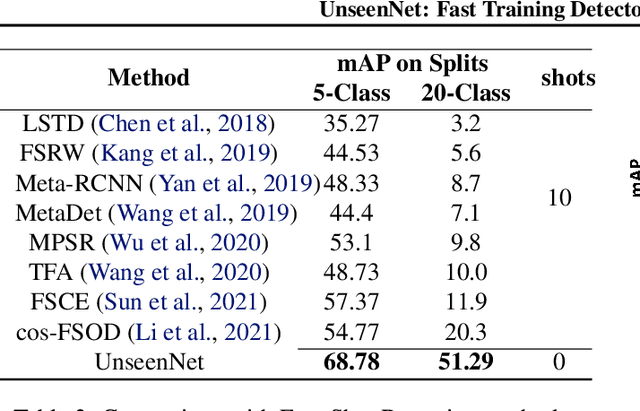
Training of object detection models using less data is currently the focus of existing N-shot learning models in computer vision. Such methods use object-level labels and takes hours to train on unseen classes. There are many cases where we have large amount of image-level labels available for training but cannot be utilized by few shot object detection models for training. There is a need for a machine learning framework that can be used for training any unseen class and can become useful in real-time situations. In this paper, we proposed an "Unseen Class Detector" that can be trained within a very short time for any possible unseen class without bounding boxes with competitive accuracy. We build our approach on "Strong" and "Weak" baseline detectors, which we trained on existing object detection and image classification datasets, respectively. Unseen concepts are fine-tuned on the strong baseline detector using only image-level labels and further adapted by transferring the classifier-detector knowledge between baselines. We use semantic as well as visual similarities to identify the source class (i.e. Sheep) for the fine-tuning and adaptation of unseen class (i.e. Goat). Our model (UnseenNet) is trained on the ImageNet classification dataset for unseen classes and tested on an object detection dataset (OpenImages). UnseenNet improves the mean average precision (mAP) by 10% to 30% over existing baselines (semi-supervised and few-shot) of object detection on different unseen class splits. Moreover, training time of our model is <10 min for each unseen class. Qualitative results demonstrate that UnseenNet is suitable not only for few classes of Pascal VOC but for unseen classes of any dataset or web. Code is available at https://github.com/Asra-Aslam/UnseenNet.
Attention-based Reinforcement Learning for Real-Time UAV Semantic Communication
May 22, 2021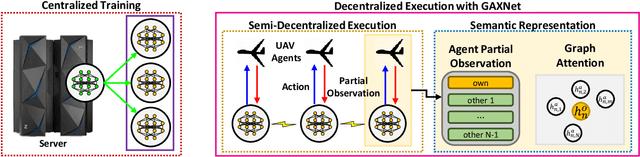
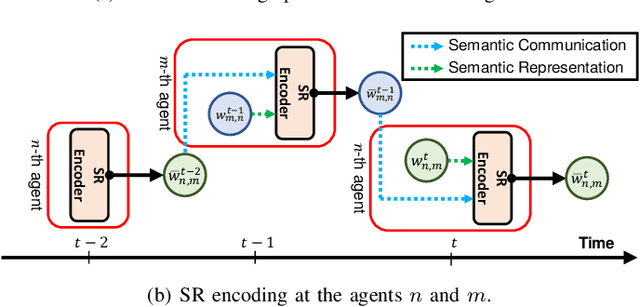
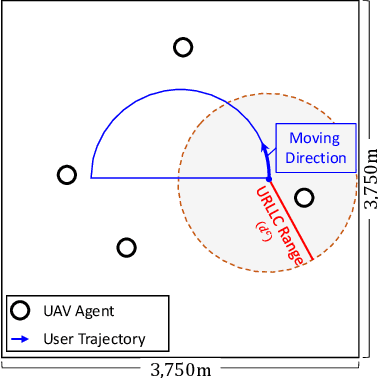
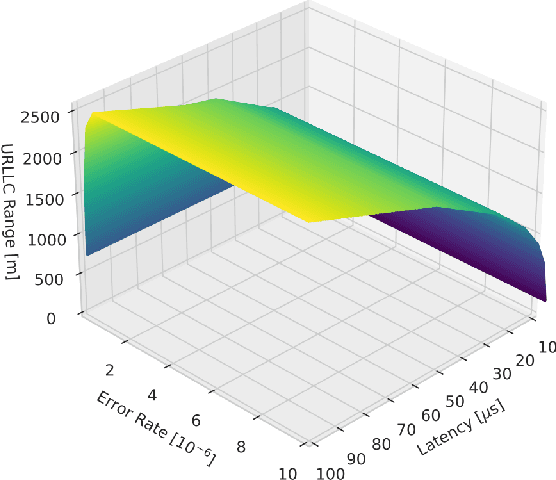
In this article, we study the problem of air-to-ground ultra-reliable and low-latency communication (URLLC) for a moving ground user. This is done by controlling multiple unmanned aerial vehicles (UAVs) in real time while avoiding inter-UAV collisions. To this end, we propose a novel multi-agent deep reinforcement learning (MADRL) framework, coined a graph attention exchange network (GAXNet). In GAXNet, each UAV constructs an attention graph locally measuring the level of attention to its neighboring UAVs, while exchanging the attention weights with other UAVs so as to reduce the attention mismatch between them. Simulation results corroborates that GAXNet achieves up to 4.5x higher rewards during training. At execution, without incurring inter-UAV collisions, GAXNet achieves 6.5x lower latency with the target 0.0000001 error rate, compared to a state-of-the-art baseline framework.
Streaming Inference for Infinite Non-Stationary Clustering
May 02, 2022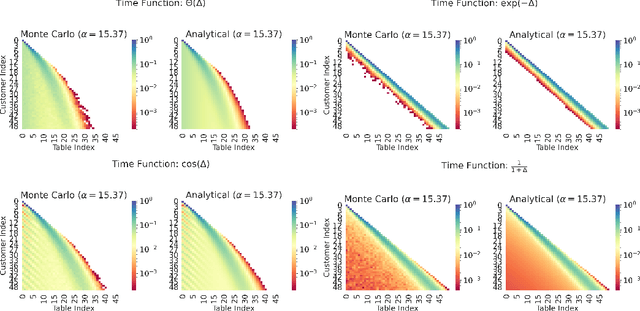



Learning from a continuous stream of non-stationary data in an unsupervised manner is arguably one of the most common and most challenging settings facing intelligent agents. Here, we attack learning under all three conditions (unsupervised, streaming, non-stationary) in the context of clustering, also known as mixture modeling. We introduce a novel clustering algorithm that endows mixture models with the ability to create new clusters online, as demanded by the data, in a probabilistic, time-varying, and principled manner. To achieve this, we first define a novel stochastic process called the Dynamical Chinese Restaurant Process (Dynamical CRP), which is a non-exchangeable distribution over partitions of a set; next, we show that the Dynamical CRP provides a non-stationary prior over cluster assignments and yields an efficient streaming variational inference algorithm. We conclude with experiments showing that the Dynamical CRP can be applied on diverse synthetic and real data with Gaussian and non-Gaussian likelihoods.
Factory: Fast Contact for Robotic Assembly
May 07, 2022
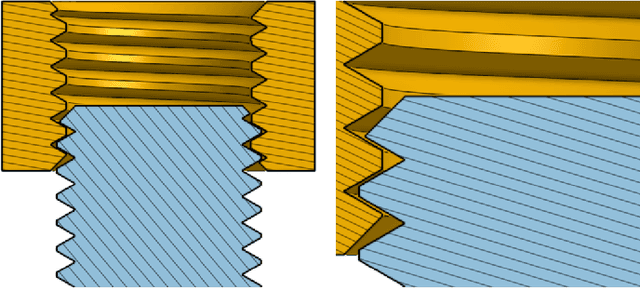


Robotic assembly is one of the oldest and most challenging applications of robotics. In other areas of robotics, such as perception and grasping, simulation has rapidly accelerated research progress, particularly when combined with modern deep learning. However, accurately, efficiently, and robustly simulating the range of contact-rich interactions in assembly remains a longstanding challenge. In this work, we present Factory, a set of physics simulation methods and robot learning tools for such applications. We achieve real-time or faster simulation of a wide range of contact-rich scenes, including simultaneous simulation of 1000 nut-and-bolt interactions. We provide $60$ carefully-designed part models, 3 robotic assembly environments, and 7 robot controllers for training and testing virtual robots. Finally, we train and evaluate proof-of-concept reinforcement learning policies for nut-and-bolt assembly. We aim for Factory to open the doors to using simulation for robotic assembly, as well as many other contact-rich applications in robotics. Please see https://sites.google.com/nvidia.com/factory for supplementary content, including videos.
FullSubNet+: Channel Attention FullSubNet with Complex Spectrograms for Speech Enhancement
Mar 26, 2022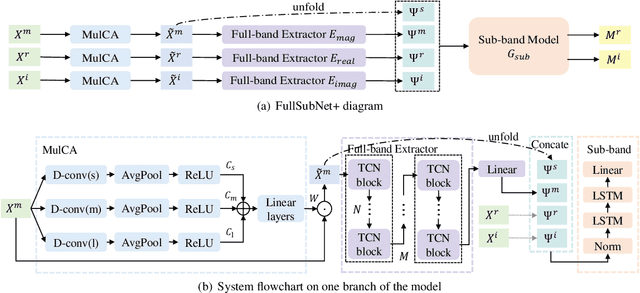
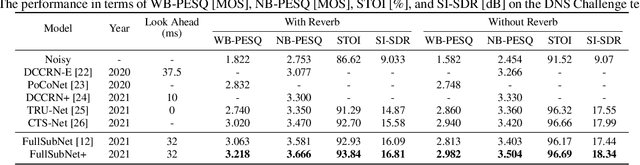
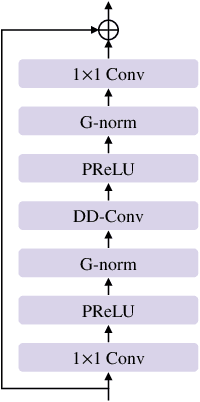

Previously proposed FullSubNet has achieved outstanding performance in Deep Noise Suppression (DNS) Challenge and attracted much attention. However, it still encounters issues such as input-output mismatch and coarse processing for frequency bands. In this paper, we propose an extended single-channel real-time speech enhancement framework called FullSubNet+ with following significant improvements. First, we design a lightweight multi-scale time sensitive channel attention (MulCA) module which adopts multi-scale convolution and channel attention mechanism to help the network focus on more discriminative frequency bands for noise reduction. Then, to make full use of the phase information in noisy speech, our model takes all the magnitude, real and imaginary spectrograms as inputs. Moreover, by replacing the long short-term memory (LSTM) layers in original full-band model with stacked temporal convolutional network (TCN) blocks, we design a more efficient full-band module called full-band extractor. The experimental results in DNS Challenge dataset show the superior performance of our FullSubNet+, which reaches the state-of-the-art (SOTA) performance and outperforms other existing speech enhancement approaches.
Parallel Training of GRU Networks with a Multi-Grid Solver for Long Sequences
Mar 07, 2022

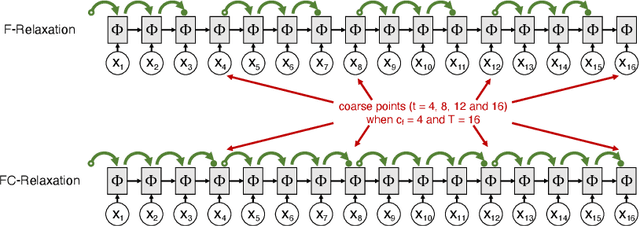

Parallelizing Gated Recurrent Unit (GRU) networks is a challenging task, as the training procedure of GRU is inherently sequential. Prior efforts to parallelize GRU have largely focused on conventional parallelization strategies such as data-parallel and model-parallel training algorithms. However, when the given sequences are very long, existing approaches are still inevitably performance limited in terms of training time. In this paper, we present a novel parallel training scheme (called parallel-in-time) for GRU based on a multigrid reduction in time (MGRIT) solver. MGRIT partitions a sequence into multiple shorter sub-sequences and trains the sub-sequences on different processors in parallel. The key to achieving speedup is a hierarchical correction of the hidden state to accelerate end-to-end communication in both the forward and backward propagation phases of gradient descent. Experimental results on the HMDB51 dataset, where each video is an image sequence, demonstrate that the new parallel training scheme achieves up to 6.5$\times$ speedup over a serial approach. As efficiency of our new parallelization strategy is associated with the sequence length, our parallel GRU algorithm achieves significant performance improvement as the sequence length increases.
Enhancing Satellite Imagery using Deep Learning for the Sensor To Shooter Timeline
Mar 30, 2022
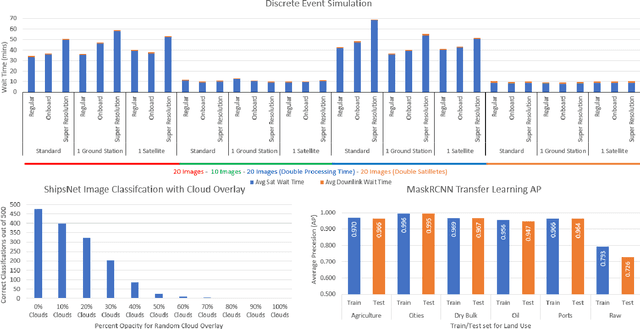

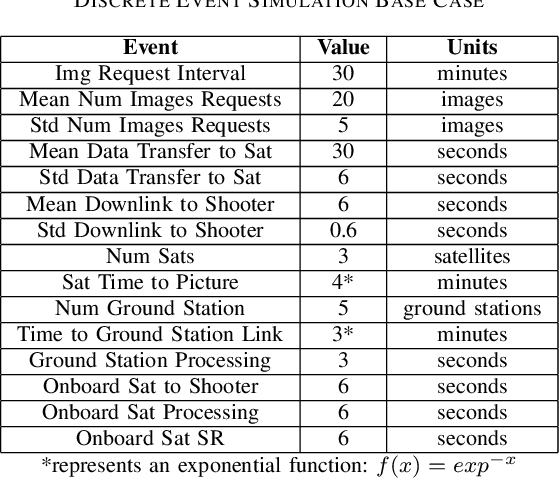
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
Video-based Formative and Summative Assessment of Surgical Tasks using Deep Learning
Mar 17, 2022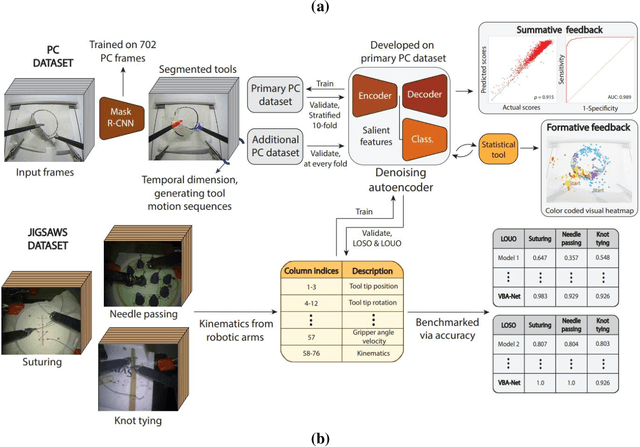
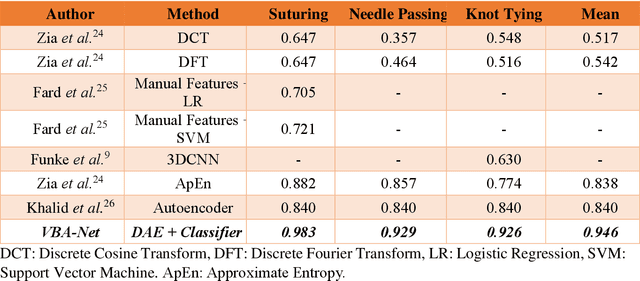
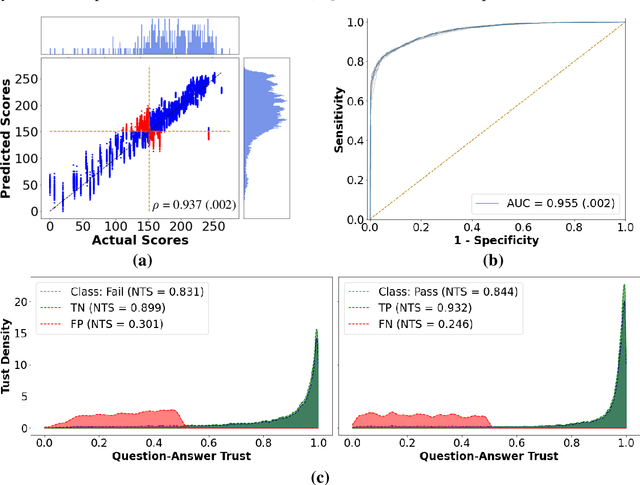
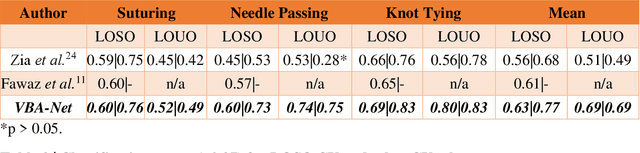
To ensure satisfactory clinical outcomes, surgical skill assessment must be objective, time-efficient, and preferentially automated - none of which is currently achievable. Video-based assessment (VBA) is being deployed in intraoperative and simulation settings to evaluate technical skill execution. However, VBA remains manually- and time-intensive and prone to subjective interpretation and poor inter-rater reliability. Herein, we propose a deep learning (DL) model that can automatically and objectively provide a high-stakes summative assessment of surgical skill execution based on video feeds and low-stakes formative assessment to guide surgical skill acquisition. Formative assessment is generated using heatmaps of visual features that correlate with surgical performance. Hence, the DL model paves the way to the quantitative and reproducible evaluation of surgical tasks from videos with the potential for broad dissemination in surgical training, certification, and credentialing.