 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Online Semantic Mapping System for Extending and Enhancing Visual SLAM
Mar 08, 2022




We present a real-time semantic mapping approach for mobile vision systems with a 2D to 3D object detection pipeline and rapid data association for generated landmarks. Besides the semantic map enrichment the associated detections are further introduced as semantic constraints into a simultaneous localization and mapping (SLAM) system for pose correction purposes. This way, we are able generate additional meaningful information that allows to achieve higher-level tasks, while simultaneously leveraging the view-invariance of object detections to improve the accuracy and the robustness of the odometry estimation. We propose tracklets of locally associated object observations to handle ambiguous and false predictions and an uncertainty-based greedy association scheme for an accelerated processing time. Our system reaches real-time capabilities with an average iteration duration of 65~ms and is able to improve the pose estimation of a state-of-the-art SLAM by up to 68% on a public dataset. Additionally, we implemented our approach as a modular ROS package that makes it straightforward for integration in arbitrary graph-based SLAM methods.
Extremely Lightweight Quantization Robust Real-Time Single-Image Super Resolution for Mobile Devices
May 21, 2021
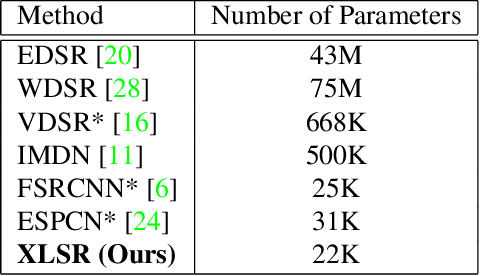
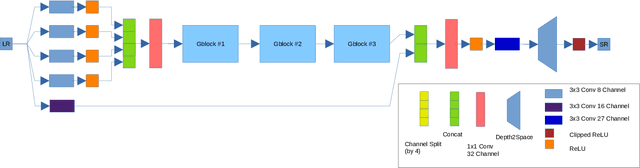

Single-Image Super Resolution (SISR) is a classical computer vision problem and it has been studied for over decades. With the recent success of deep learning methods, recent work on SISR focuses solutions with deep learning methodologies and achieves state-of-the-art results. However most of the state-of-the-art SISR methods contain millions of parameters and layers, which limits their practical applications. In this paper, we propose a hardware (Synaptics Dolphin NPU) limitation aware, extremely lightweight quantization robust real-time super resolution network (XLSR). The proposed model's building block is inspired from root modules for Image classification. We successfully applied root modules to SISR problem, further more to make the model uint8 quantization robust we used Clipped ReLU at the last layer of the network and achieved great balance between reconstruction quality and runtime. Furthermore, although the proposed network contains 30x fewer parameters than VDSR its performance surpasses it on Div2K validation set. The network proved itself by winning Mobile AI 2021 Real-Time Single Image Super Resolution Challenge.
Multi-Head Online Learning for Delayed Feedback Modeling
May 24, 2022
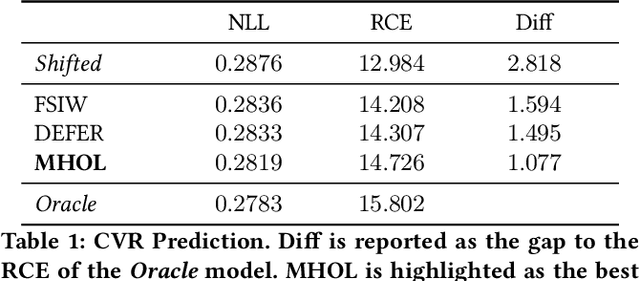
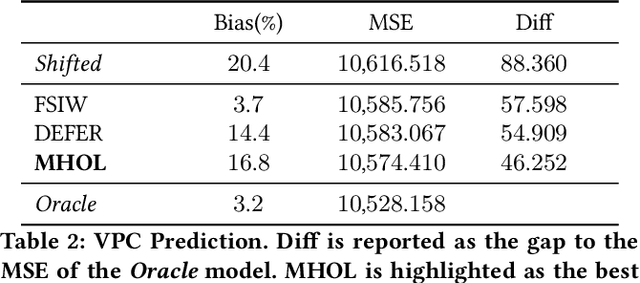
In online advertising, it is highly important to predict the probability and the value of a conversion (e.g., a purchase). It not only impacts user experience by showing relevant ads, but also affects ROI of advertisers and revenue of marketplaces. Unlike clicks, which often occur within minutes after impressions, conversions are expected to happen over a long period of time (e.g., 30 days for online shopping). It creates a challenge, as the true labels are only available after the long delays. Either inaccurate labels (partial conversions) are used, or models are trained on stale data (e.g., from 30 days ago). The problem is more eminent in online learning, which focuses on the live performance on the latest data. In this paper, a novel solution is presented to address this challenge using multi-head modeling. Unlike traditional methods, it directly quantizes conversions into multiple windows, such as day 1, day 2, day 3-7, and day 8-30. A sub-model is trained specifically on conversions within each window. Label freshness is maximally preserved in early models (e.g., day 1 and day 2), while late conversions are accurately utilized in models with longer delays (e.g., day 8-30). It is shown to greatly exceed the performance of known methods in online learning experiments for both conversion rate (CVR) and value per click (VPC) predictions. Lastly, as a general method for delayed feedback modeling, it can be combined with any advanced ML techniques to further improve the performance.
Wi-Fi and Bluetooth Contact Tracing Without User Intervention
Mar 31, 2022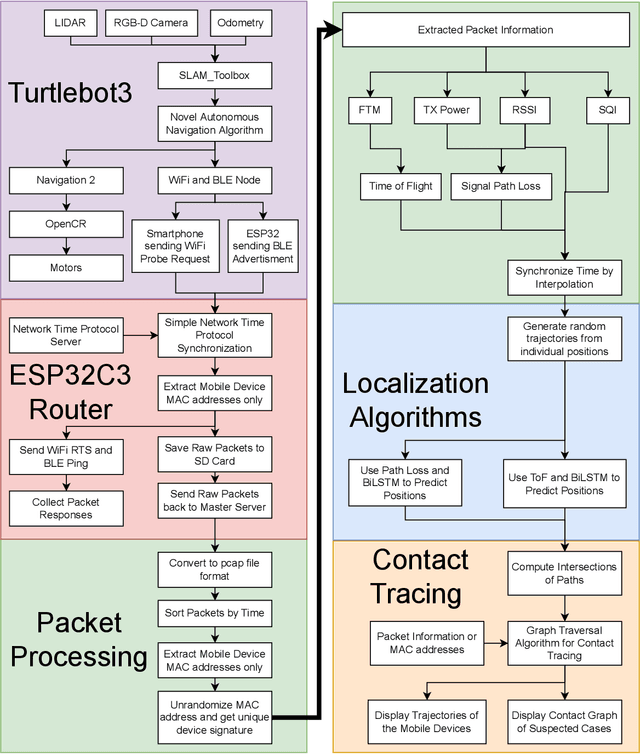
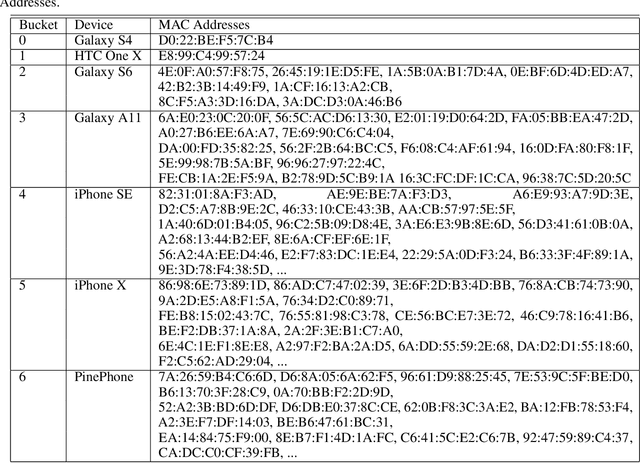
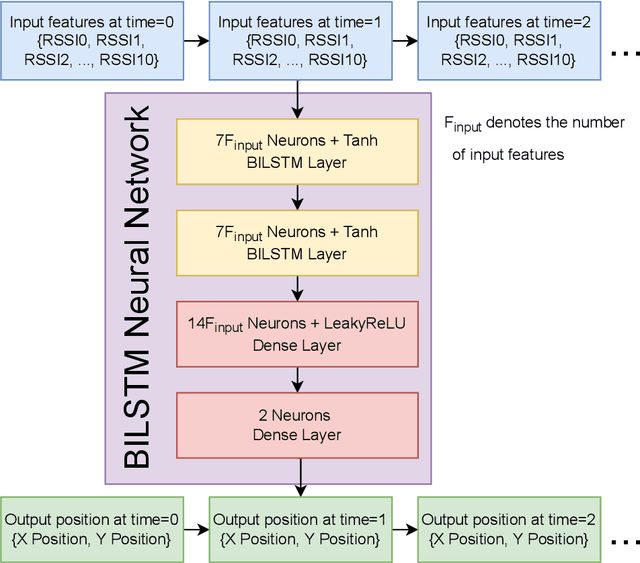
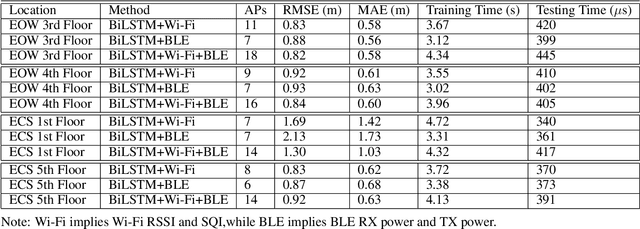
A custom Wi-Fi and Bluetooth indoor contact tracing system is created to find detailed paths of infected individuals without any user intervention. The system tracks smartphones, but it does not require smartphone applications, connecting to the routers, or any other extraneous devices on the users. A custom Turtlebot3 is used for site surveying, where it simulates mobile device movement and packet transmission. Transmit power, receive power, and round trip time are collected by a custom ESP32C3 router. MAC randomization is defeated to identify unique smartphones. Subsequently, the wireless parameters above are converted to signal path loss and time of flight. Bidirectional long short term memory takes the wireless parameters and predicts the detailed paths of the users within 1 m. Public health authorities can use the contact tracing website to find the detailed paths of the suspected cases using the smartphone models and initial positions of confirm cases. The system can also track indirect contact transmissions originating from surfaces and droplets due to having absolute positions of users.
PFGE: Parsimonious Fast Geometric Ensembling of DNNs
Feb 14, 2022
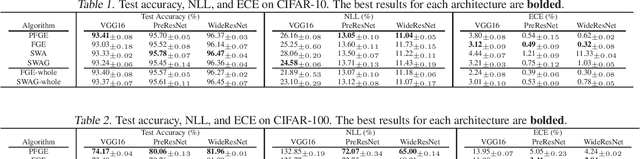
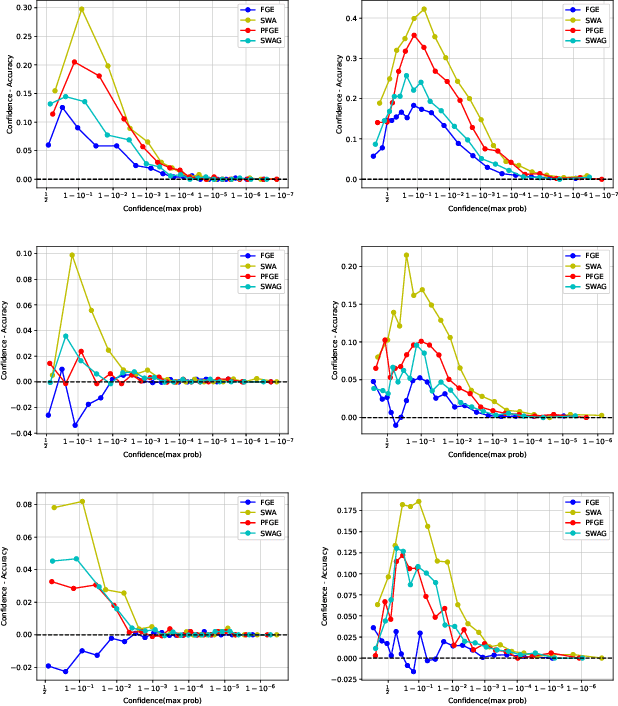

Ensemble methods have been widely used to improve the generalization performance of machine learning methods, while they are struggling to apply in deep learning, as training an ensemble of deep neural networks (DNNs) and then employing them for inference incur an extremely high cost for model training and test-time computation. Recently, several advanced techniques, such as fast geometric ensembling (FGE) and snapshot ensemble (SNE), have been proposed. These methods can train the model ensembles in the same time as a single model, thus getting round of the hurdle of training time. However, their costs for model recording and test-time computation remain much higher than their single model based counterparts. Here we propose a parsimonious FGE (PFGE) algorithm that employs a lightweight ensemble of higher-performing DNNs, which are generated by a series of successively performed stochastic weight averaging procedures. Experimental results across different advanced DNN architectures on different datasets, namely CIFAR-{10,100} and Imagenet, demonstrate its performance. Results show that, compared with state-of-the-art methods, PFGE has a comparable even better performance in terms of generalization and calibration, at a much-reduced cost for model recording and test-time computation.
Hierarchical Constrained Stochastic Shortest Path Planning via Cost Budget Allocation
May 11, 2022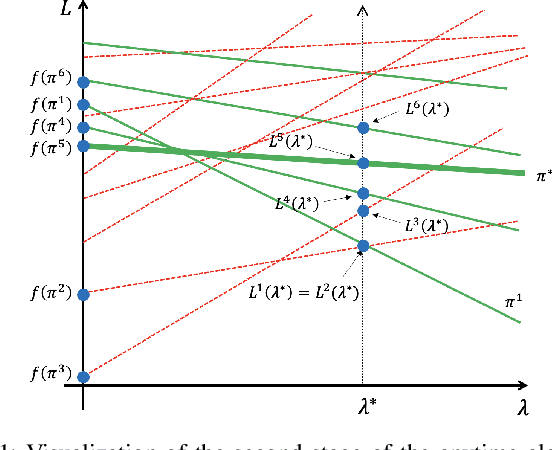
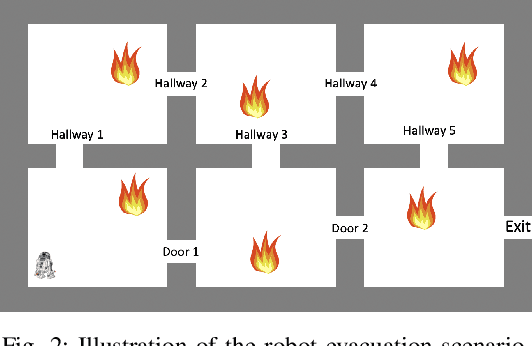
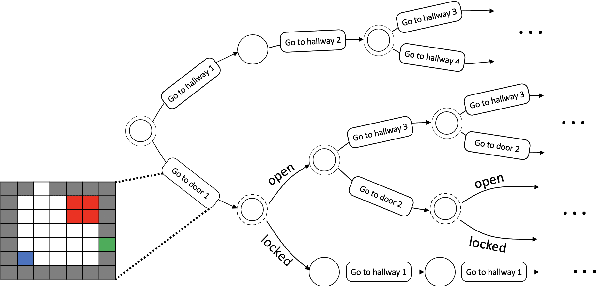
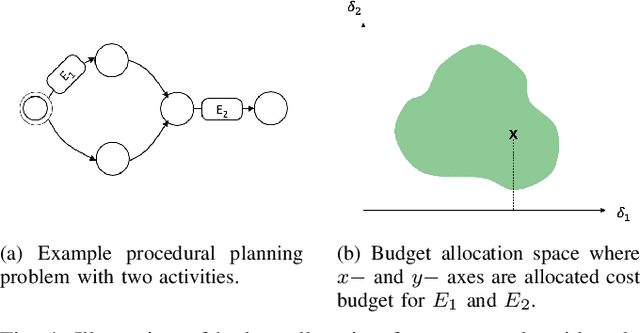
Stochastic sequential decision making often requires hierarchical structure in the problem where each high-level action should be further planned with primitive states and actions. In addition, many real-world applications require a plan that satisfies constraints on the secondary costs such as risk measure or fuel consumption. In this paper, we propose a hierarchical constrained stochastic shortest path problem (HC-SSP) that meets those two crucial requirements in a single framework. Although HC-SSP provides a useful framework to model such planning requirements in many real-world applications, the resulting problem has high complexity and makes it difficult to find an optimal solution fast which prevents user from applying it to real-time and risk-sensitive applications. To address this problem, we present an algorithm that iteratively allocates cost budget to lower level planning problems based on branch-and-bound scheme to find a feasible solution fast and incrementally update the incumbent solution. We demonstrate the proposed algorithm in an evacuation scenario and prove the advantage over a state-of-the-art mathematical programming based approach.
Minimum Cost Intervention Design for Causal Effect Identification
May 04, 2022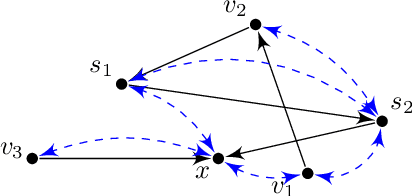
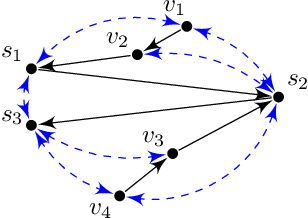
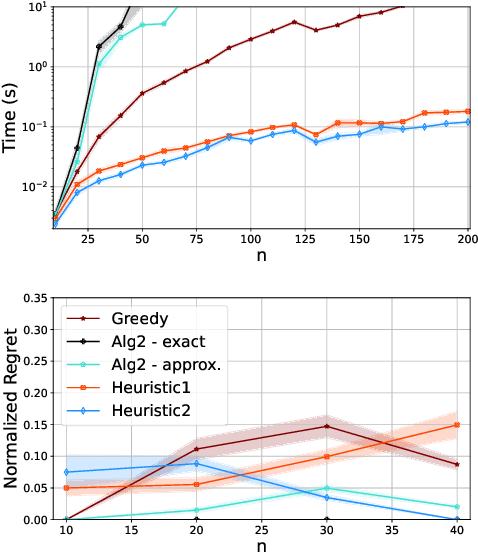
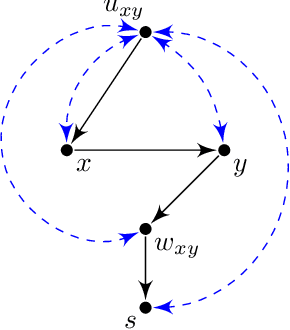
Pearl's do calculus is a complete axiomatic approach to learn the identifiable causal effects from observational data. When such an effect is not identifiable, it is necessary to perform a collection of often costly interventions in the system to learn the causal effect. In this work, we consider the problem of designing the collection of interventions with the minimum cost to identify the desired effect. First, we prove that this problem is NP-hard, and subsequently propose an algorithm that can either find the optimal solution or a logarithmic-factor approximation of it. This is done by establishing a connection between our problem and the minimum hitting set problem. Additionally, we propose several polynomial-time heuristic algorithms to tackle the computational complexity of the problem. Although these algorithms could potentially stumble on sub-optimal solutions, our simulations show that they achieve small regrets on random graphs.
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
May 27, 2022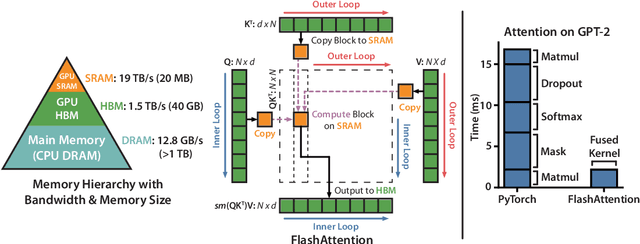

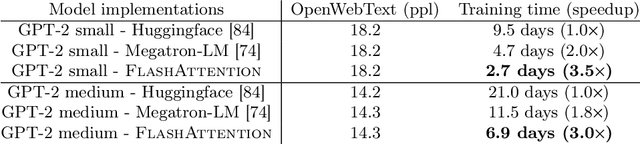
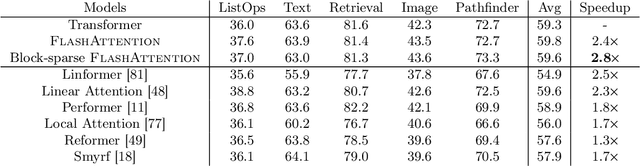
Transformers are slow and memory-hungry on long sequences, since the time and memory complexity of self-attention are quadratic in sequence length. Approximate attention methods have attempted to address this problem by trading off model quality to reduce the compute complexity, but often do not achieve wall-clock speedup. We argue that a missing principle is making attention algorithms IO-aware -- accounting for reads and writes between levels of GPU memory. We propose FlashAttention, an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM. We analyze the IO complexity of FlashAttention, showing that it requires fewer HBM accesses than standard attention, and is optimal for a range of SRAM sizes. We also extend FlashAttention to block-sparse attention, yielding an approximate attention algorithm that is faster than any existing approximate attention method. FlashAttention trains Transformers faster than existing baselines: 15% end-to-end wall-clock speedup on BERT-large (seq. length 512) compared to the MLPerf 1.1 training speed record, 3$\times$ speedup on GPT-2 (seq. length 1K), and 2.4$\times$ speedup on long-range arena (seq. length 1K-4K). FlashAttention and block-sparse FlashAttention enable longer context in Transformers, yielding higher quality models (0.7 better perplexity on GPT-2 and 6.4 points of lift on long-document classification) and entirely new capabilities: the first Transformers to achieve better-than-chance performance on the Path-X challenge (seq. length 16K, 61.4% accuracy) and Path-256 (seq. length 64K, 63.1% accuracy).
Multi-Agent Reinforcement Learning is a Sequence Modeling Problem
May 30, 2022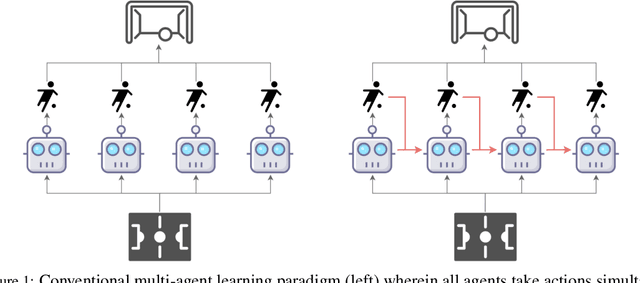
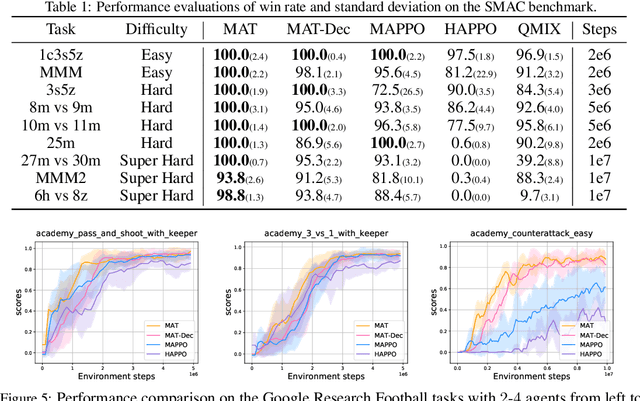
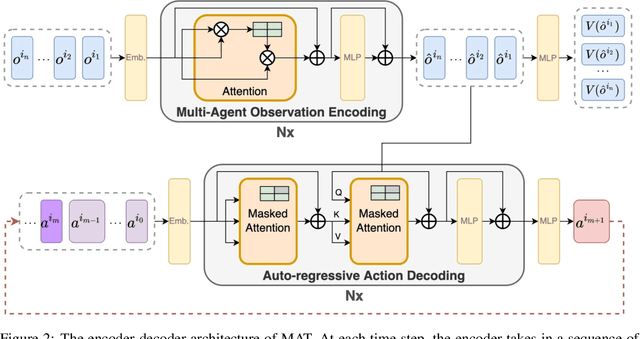
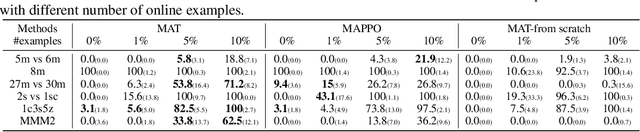
Large sequence model (SM) such as GPT series and BERT has displayed outstanding performance and generalization capabilities on vision, language, and recently reinforcement learning tasks. A natural follow-up question is how to abstract multi-agent decision making into an SM problem and benefit from the prosperous development of SMs. In this paper, we introduce a novel architecture named Multi-Agent Transformer (MAT) that effectively casts cooperative multi-agent reinforcement learning (MARL) into SM problems wherein the task is to map agents' observation sequence to agents' optimal action sequence. Our goal is to build the bridge between MARL and SMs so that the modeling power of modern sequence models can be unleashed for MARL. Central to our MAT is an encoder-decoder architecture which leverages the multi-agent advantage decomposition theorem to transform the joint policy search problem into a sequential decision making process; this renders only linear time complexity for multi-agent problems and, most importantly, endows MAT with monotonic performance improvement guarantee. Unlike prior arts such as Decision Transformer fit only pre-collected offline data, MAT is trained by online trials and errors from the environment in an on-policy fashion. To validate MAT, we conduct extensive experiments on StarCraftII, Multi-Agent MuJoCo, Dexterous Hands Manipulation, and Google Research Football benchmarks. Results demonstrate that MAT achieves superior performance and data efficiency compared to strong baselines including MAPPO and HAPPO. Furthermore, we demonstrate that MAT is an excellent few-short learner on unseen tasks regardless of changes in the number of agents. See our project page at https://sites.google.com/view/multi-agent-transformer.
Positional Information is All You Need: A Novel Pipeline for Self-Supervised SVDE from Videos
May 18, 2022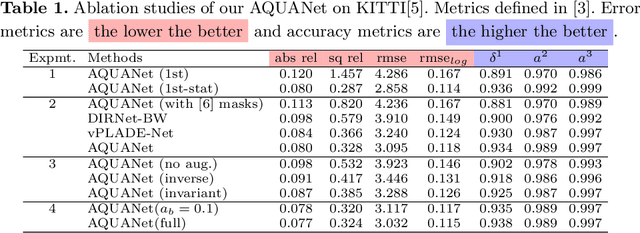
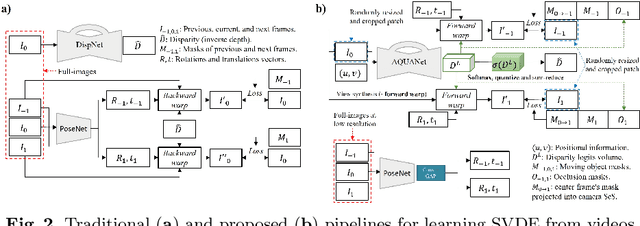
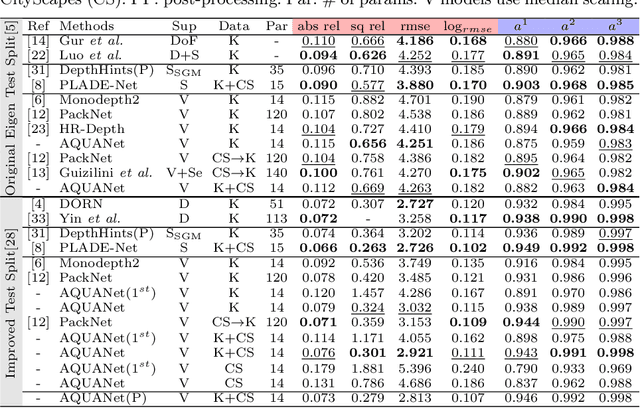
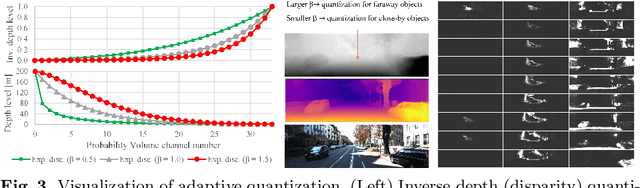
Recently, much attention has been drawn to learning the underlying 3D structures of a scene from monocular videos in a fully self-supervised fashion. One of the most challenging aspects of this task is handling the independently moving objects as they break the rigid-scene assumption. For the first time, we show that pixel positional information can be exploited to learn SVDE (Single View Depth Estimation) from videos. Our proposed moving object (MO) masks, which are induced by shifted positional information (SPI) and referred to as `SPIMO' masks, are very robust and consistently remove the independently moving objects in the scenes, allowing for better learning of SVDE from videos. Additionally, we introduce a new adaptive quantization scheme that assigns the best per-pixel quantization curve for our depth discretization. Finally, we employ existing boosting techniques in a new way to further self-supervise the depth of the moving objects. With these features, our pipeline is robust against moving objects and generalizes well to high-resolution images, even when trained with small patches, yielding state-of-the-art (SOTA) results with almost 8.5x fewer parameters than the previous works that learn from videos. We present extensive experiments on KITTI and CityScapes that show the effectiveness of our method.