 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Architecture Search for Diverse Tasks
Apr 15, 2022
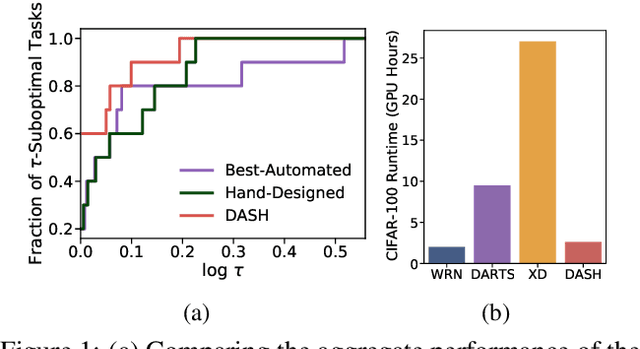

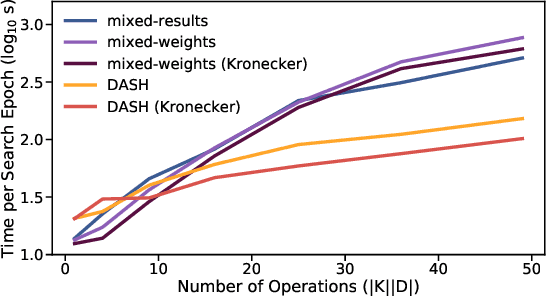
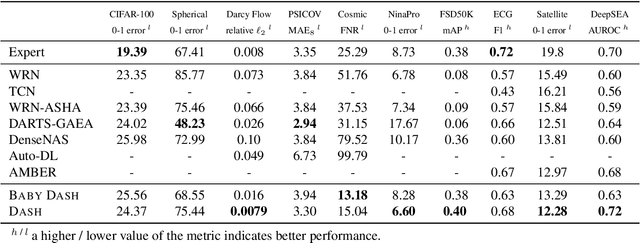
While neural architecture search (NAS) has enabled automated machine learning (AutoML) for well-researched areas, its application to tasks beyond computer vision is still under-explored. As less-studied domains are precisely those where we expect AutoML to have the greatest impact, in this work we study NAS for efficiently solving diverse problems. Seeking an approach that is fast, simple, and broadly applicable, we fix a standard convolutional network (CNN) topology and propose to search for the right kernel sizes and dilations its operations should take on. This dramatically expands the model's capacity to extract features at multiple resolutions for different types of data while only requiring search over the operation space. To overcome the efficiency challenges of naive weight-sharing in this search space, we introduce DASH, a differentiable NAS algorithm that computes the mixture-of-operations using the Fourier diagonalization of convolution, achieving both a better asymptotic complexity and an up-to-10x search time speedup in practice. We evaluate DASH on NAS-Bench-360, a suite of ten tasks designed for benchmarking NAS in diverse domains. DASH outperforms state-of-the-art methods in aggregate, attaining the best-known automated performance on seven tasks. Meanwhile, on six of the ten tasks, the combined search and retraining time is less than 2x slower than simply training a CNN backbone that is far less accurate.
Forecast Evaluation for Data Scientists: Common Pitfalls and Best Practices
Apr 04, 2022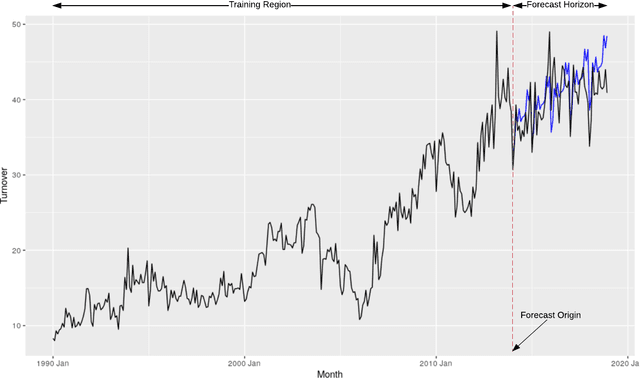
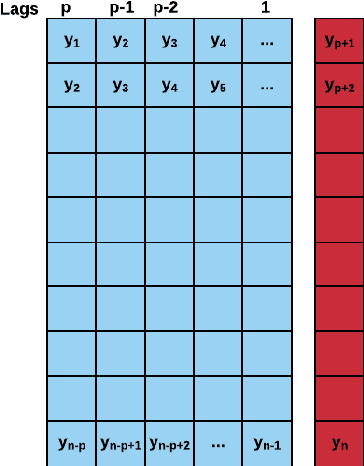

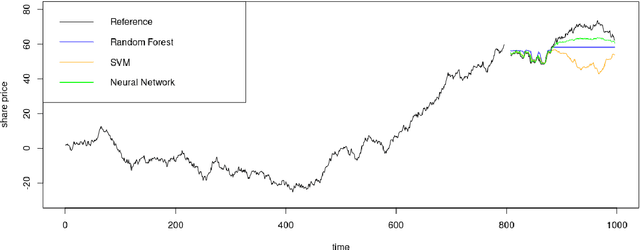
Machine Learning (ML) and Deep Learning (DL) methods are increasingly replacing traditional methods in many domains involved with important decision making activities. DL techniques tailor-made for specific tasks such as image recognition, signal processing, or speech analysis are being introduced at a fast pace with many improvements. However, for the domain of forecasting, the current state in the ML community is perhaps where other domains such as Natural Language Processing and Computer Vision were at several years ago. The field of forecasting has mainly been fostered by statisticians/econometricians; consequently the related concepts are not the mainstream knowledge among general ML practitioners. The different non-stationarities associated with time series challenge the data-driven ML models. Nevertheless, recent trends in the domain have shown that with the availability of massive amounts of time series, ML techniques are quite competent in forecasting, when related pitfalls are properly handled. Therefore, in this work we provide a tutorial-like compilation of the details of one of the most important steps in the overall forecasting process, namely the evaluation. This way, we intend to impart the information of forecast evaluation to fit the context of ML, as means of bridging the knowledge gap between traditional methods of forecasting and state-of-the-art ML techniques. We elaborate on the different problematic characteristics of time series such as non-normalities and non-stationarities and how they are associated with common pitfalls in forecast evaluation. Best practices in forecast evaluation are outlined with respect to the different steps such as data partitioning, error calculation, statistical testing, and others. Further guidelines are also provided along selecting valid and suitable error measures depending on the specific characteristics of the dataset at hand.
Phase Vocoder Done Right
Feb 15, 2022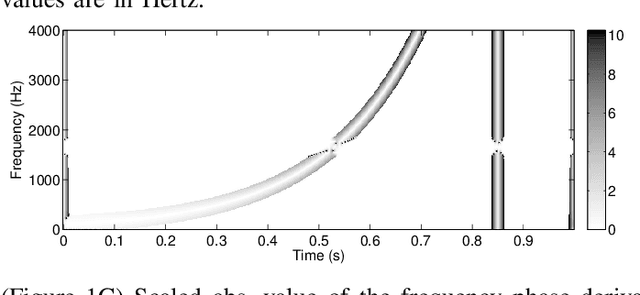

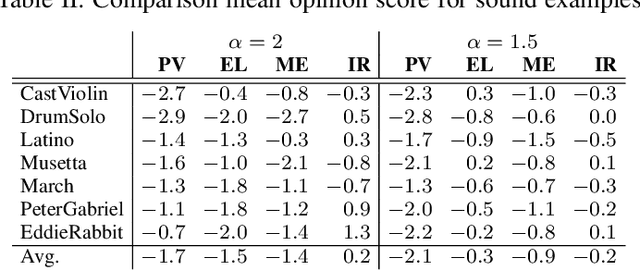
The phase vocoder (PV) is a widely spread technique for processing audio signals. It employs a short-time Fourier transform (STFT) analysis-modify-synthesis loop and is typically used for time-scaling of signals by means of using different time steps for STFT analysis and synthesis. The main challenge of PV used for that purpose is the correction of the STFT phase. In this paper, we introduce a novel method for phase correction based on phase gradient estimation and its integration. The method does not require explicit peak picking and tracking nor does it require detection of transients and their separate treatment. Yet, the method does not suffer from the typical phase vocoder artifacts even for extreme time stretching factors.
Statistical-Computational Trade-offs in Tensor PCA and Related Problems via Communication Complexity
Apr 15, 2022
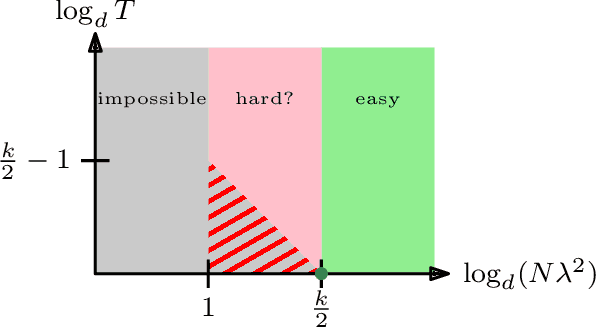
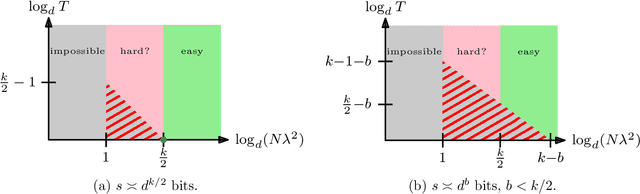

Tensor PCA is a stylized statistical inference problem introduced by Montanari and Richard to study the computational difficulty of estimating an unknown parameter from higher-order moment tensors. Unlike its matrix counterpart, Tensor PCA exhibits a statistical-computational gap, i.e., a sample size regime where the problem is information-theoretically solvable but conjectured to be computationally hard. This paper derives computational lower bounds on the run-time of memory bounded algorithms for Tensor PCA using communication complexity. These lower bounds specify a trade-off among the number of passes through the data sample, the sample size, and the memory required by any algorithm that successfully solves Tensor PCA. While the lower bounds do not rule out polynomial-time algorithms, they do imply that many commonly-used algorithms, such as gradient descent and power method, must have a higher iteration count when the sample size is not large enough. Similar lower bounds are obtained for Non-Gaussian Component Analysis, a family of statistical estimation problems in which low-order moment tensors carry no information about the unknown parameter. Finally, stronger lower bounds are obtained for an asymmetric variant of Tensor PCA and related statistical estimation problems. These results explain why many estimators for these problems use a memory state that is significantly larger than the effective dimensionality of the parameter of interest.
Secure and Private Source Coding with Private Key and Decoder Side Information
May 10, 2022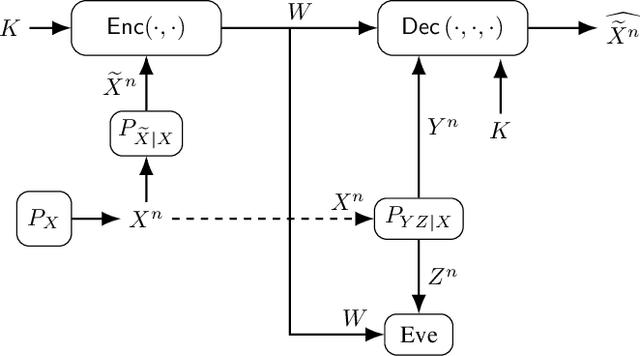
The problem of secure source coding with multiple terminals is extended by considering a remote source whose noisy measurements are the correlated random variables used for secure source reconstruction. The main additions to the problem include 1) all terminals noncausally observe a noisy measurement of the remote source; 2) a private key is available to all legitimate terminals; 3) the public communication link between the encoder and decoder is rate-limited; 4) the secrecy leakage to the eavesdropper is measured with respect to the encoder input, whereas the privacy leakage is measured with respect to the remote source. Exact rate regions are characterized for a lossy source coding problem with a private key, remote source, and decoder side information under security, privacy, communication, and distortion constraints. By replacing the distortion constraint with a reliability constraint, we obtain the exact rate region also for the lossless case. Furthermore, the lossy rate region for scalar discrete-time Gaussian sources and measurement channels is established.
ISALT: Inference-based schemes adaptive to large time-stepping for locally Lipschitz ergodic systems
Feb 25, 2021
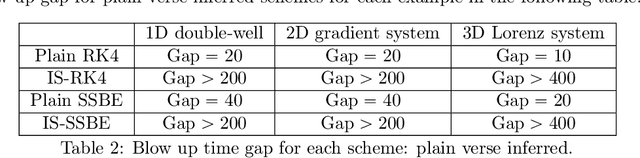
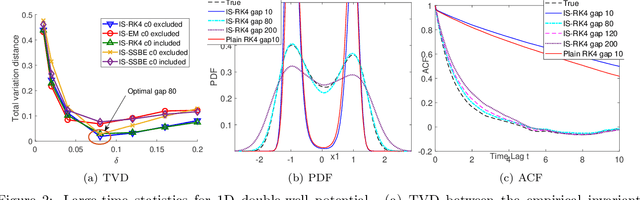
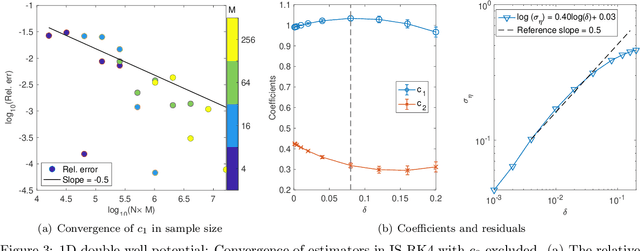
Efficient simulation of SDEs is essential in many applications, particularly for ergodic systems that demand efficient simulation of both short-time dynamics and large-time statistics. However, locally Lipschitz SDEs often require special treatments such as implicit schemes with small time-steps to accurately simulate the ergodic measure. We introduce a framework to construct inference-based schemes adaptive to large time-steps (ISALT) from data, achieving a reduction in time by several orders of magnitudes. The key is the statistical learning of an approximation to the infinite-dimensional discrete-time flow map. We explore the use of numerical schemes (such as the Euler-Maruyama, a hybrid RK4, and an implicit scheme) to derive informed basis functions, leading to a parameter inference problem. We introduce a scalable algorithm to estimate the parameters by least squares, and we prove the convergence of the estimators as data size increases. We test the ISALT on three non-globally Lipschitz SDEs: the 1D double-well potential, a 2D multi-scale gradient system, and the 3D stochastic Lorenz equation with degenerate noise. Numerical results show that ISALT can tolerate time-step magnitudes larger than plain numerical schemes. It reaches optimal accuracy in reproducing the invariant measure when the time-step is medium-large.
Robust Modeling of Unknown Dynamical Systems via Ensemble Averaged Learning
Mar 07, 2022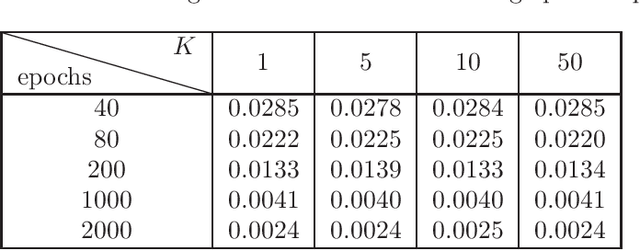
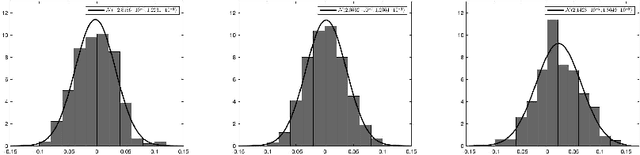

Recent work has focused on data-driven learning of the evolution of unknown systems via deep neural networks (DNNs), with the goal of conducting long time prediction of the evolution of the unknown system. Training a DNN with low generalization error is a particularly important task in this case as error is accumulated over time. Because of the inherent randomness in DNN training, chiefly in stochastic optimization, there is uncertainty in the resulting prediction, and therefore in the generalization error. Hence, the generalization error can be viewed as a random variable with some probability distribution. Well-trained DNNs, particularly those with many hyperparameters, typically result in probability distributions for generalization error with low bias but high variance. High variance causes variability and unpredictably in the results of a trained DNN. This paper presents a computational technique which decreases the variance of the generalization error, thereby improving the reliability of the DNN model to generalize consistently. In the proposed ensemble averaging method, multiple models are independently trained and model predictions are averaged at each time step. A mathematical foundation for the method is presented, including results regarding the distribution of the local truncation error. In addition, three time-dependent differential equation problems are considered as numerical examples, demonstrating the effectiveness of the method to decrease variance of DNN predictions generally.
Sacrificing CSI for a Greater Good: RIS-enabled Opportunistic Rate Splitting
Mar 28, 2022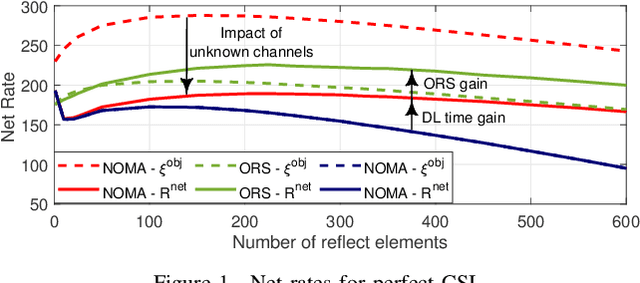
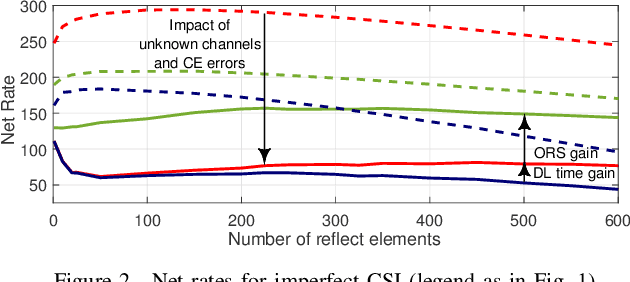
In reconfigurable intelligent surface (RIS)-assisted systems, the optimization of the phase shifts requires separate acquisition of the channel state information (CSI) for the direct and RIS-assisted channels, posing significant design challenges. In this paper, a novel scheme is proposed, which considers practical limitations like pilot overhead and channel estimation (CE) errors to increase the net performance. More specifically, at the cost of unpredictable interference, a portion of the CSI for the RIS-assisted channels is sacrificed in order to reduce the CE time. By alternating the CSI between coherence blocks and employing rate splitting, it becomes possible to mitigate the interference, thereby compensating the adverse effect of the sacrificed CSI. Numerical simulations validate that the proposed scheme exhibits better performance in terms of achievable net rate, resulting in gains of up to 160% compared non-orthogonal multiple access (NOMA), when CE time and CE errors are considered.
DeVRF: Fast Deformable Voxel Radiance Fields for Dynamic Scenes
May 31, 2022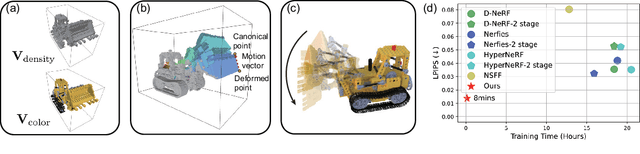
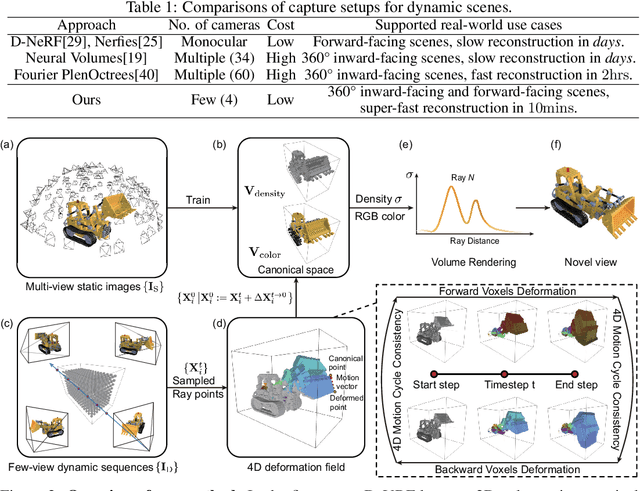
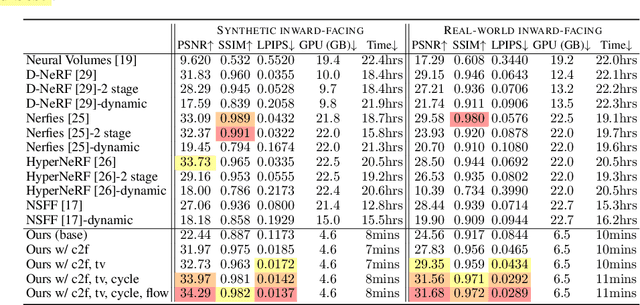

Modeling dynamic scenes is important for many applications such as virtual reality and telepresence. Despite achieving unprecedented fidelity for novel view synthesis in dynamic scenes, existing methods based on Neural Radiance Fields (NeRF) suffer from slow convergence (i.e., model training time measured in days). In this paper, we present DeVRF, a novel representation to accelerate learning dynamic radiance fields. The core of DeVRF is to model both the 3D canonical space and 4D deformation field of a dynamic, non-rigid scene with explicit and discrete voxel-based representations. However, it is quite challenging to train such a representation which has a large number of model parameters, often resulting in overfitting issues. To overcome this challenge, we devise a novel static-to-dynamic learning paradigm together with a new data capture setup that is convenient to deploy in practice. This paradigm unlocks efficient learning of deformable radiance fields via utilizing the 3D volumetric canonical space learnt from multi-view static images to ease the learning of 4D voxel deformation field with only few-view dynamic sequences. To further improve the efficiency of our DeVRF and its synthesized novel view's quality, we conduct thorough explorations and identify a set of strategies. We evaluate DeVRF on both synthetic and real-world dynamic scenes with different types of deformation. Experiments demonstrate that DeVRF achieves two orders of magnitude speedup (100x faster) with on-par high-fidelity results compared to the previous state-of-the-art approaches. The code and dataset will be released in https://github.com/showlab/DeVRF.
Backdoor Attacks on Bayesian Neural Networks using Reverse Distribution
May 18, 2022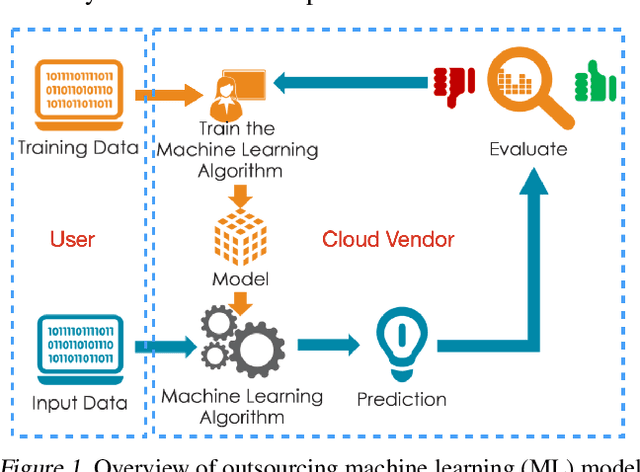

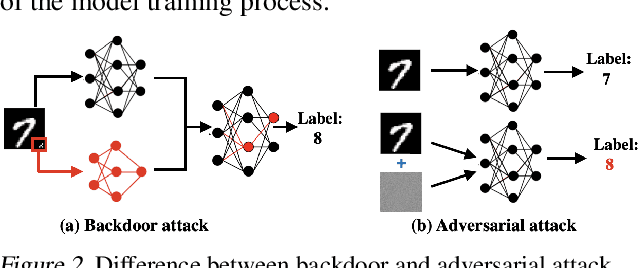
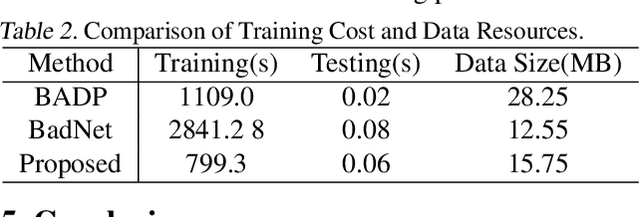
Due to cost and time-to-market constraints, many industries outsource the training process of machine learning models (ML) to third-party cloud service providers, popularly known as ML-asa-Service (MLaaS). MLaaS creates opportunity for an adversary to provide users with backdoored ML models to produce incorrect predictions only in extremely rare (attacker-chosen) scenarios. Bayesian neural networks (BNN) are inherently immune against backdoor attacks since the weights are designed to be marginal distributions to quantify the uncertainty. In this paper, we propose a novel backdoor attack based on effective learning and targeted utilization of reverse distribution. This paper makes three important contributions. (1) To the best of our knowledge, this is the first backdoor attack that can effectively break the robustness of BNNs. (2) We produce reverse distributions to cancel the original distributions when the trigger is activated. (3) We propose an efficient solution for merging probability distributions in BNNs. Experimental results on diverse benchmark datasets demonstrate that our proposed attack can achieve the attack success rate (ASR) of 100%, while the ASR of the state-of-the-art attacks is lower than 60%.