 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Complex Recurrent Variational Autoencoder for Speech Enhancement
Apr 05, 2022
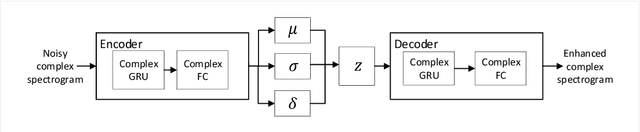
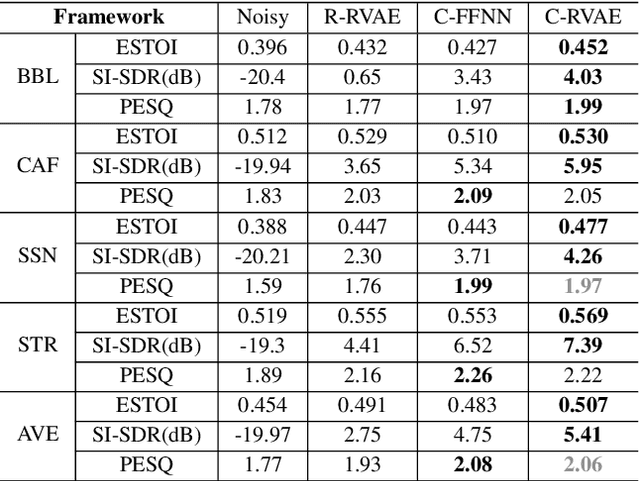
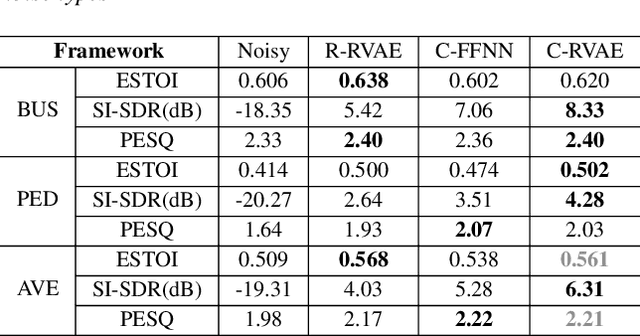
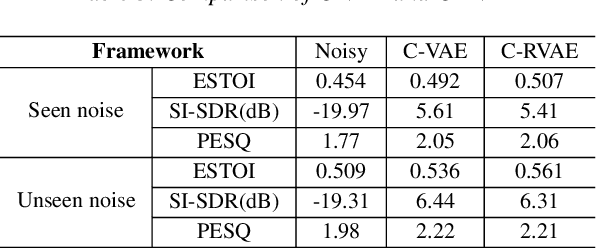
Commonly-used methods in speech enhancement are based on short-time fourier transform (STFT) representation, in particular on the magnitude of the STFT. This is because phase is naturally unstructured and intractable, and magnitude has shown more importance in speech enhancement. Nevertheless, phase has shown its significance in some research and cannot be ignored. Complex neural networks, with their inherent advantage, provide a solution for complex spectrogram processing. Complex variational autoencoder (VAE), as an extension of vanilla \acrshort{vae}, has shown positive results in complex spectrogram representation. However, the existing work on complex \acrshort{vae} only uses linear layers and merely applies the model on direct spectra representation. This paper extends the linear complex \acrshort{vae} to a non-linear one. Furthermore, on account of the temporal property of speech signals, a complex recurrent \acrshort{vae} is proposed. The proposed model has been applied on speech enhancement. As far as we know, it is the first time that a complex generative model is applied to speech enhancement. Experiments are based on the TIMIT dataset, while speech intelligibility and speech quality have been evaluated. The results show that, for speech enhancement, the proposed method has better performance on speech intelligibility and comparable performance on speech quality.
Second Order Path Variationals in Non-Stationary Online Learning
May 04, 2022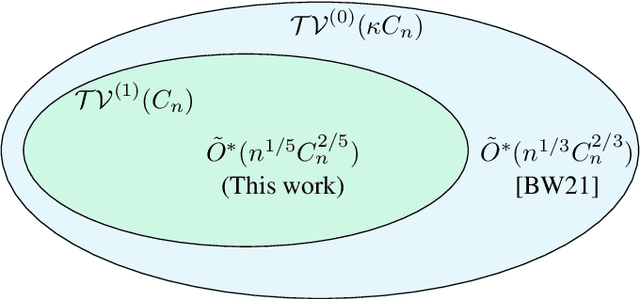


We consider the problem of universal dynamic regret minimization under exp-concave and smooth losses. We show that appropriately designed Strongly Adaptive algorithms achieve a dynamic regret of $\tilde O(d^2 n^{1/5} C_n^{2/5} \vee d^2)$, where $n$ is the time horizon and $C_n$ a path variational based on second order differences of the comparator sequence. Such a path variational naturally encodes comparator sequences that are piecewise linear -- a powerful family that tracks a variety of non-stationarity patterns in practice (Kim et al, 2009). The aforementioned dynamic regret rate is shown to be optimal modulo dimension dependencies and poly-logarithmic factors of $n$. Our proof techniques rely on analysing the KKT conditions of the offline oracle and requires several non-trivial generalizations of the ideas in Baby and Wang, 2021, where the latter work only leads to a slower dynamic regret rate of $\tilde O(d^{2.5}n^{1/3}C_n^{2/3} \vee d^{2.5})$ for the current problem.
RePAD: Real-time Proactive Anomaly Detection for Time Series
Jan 24, 2020

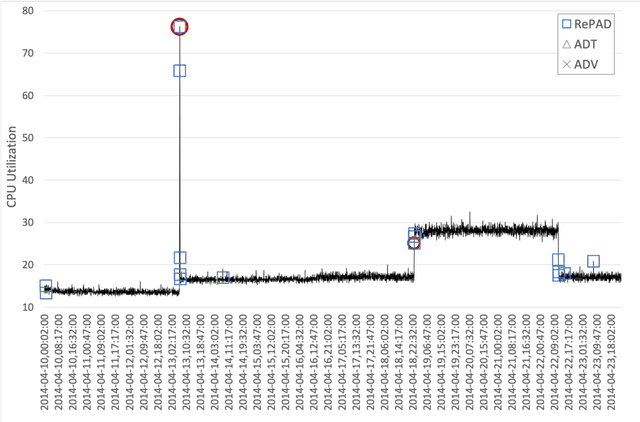

During the past decade, many anomaly detection approaches have been introduced in different fields such as network monitoring, fraud detection, and intrusion detection. However, they require understanding of data pattern and often need a long off-line period to build a model or network for the target data. Providing real-time and proactive anomaly detection for streaming time series without human intervention and domain knowledge is highly valuable since it greatly reduces human effort and enables appropriate countermeasures to be undertaken before a disastrous damage, failure, or other harmful event occurs. However, this issue has not been well studied yet. To address it, this paper proposes RePAD, which is a Real-time Proactive Anomaly Detection algorithm for streaming time series based on unsupervised Long Short-Term Memory (LSTM). RePAD utilizes short-term historic data points to predict and determine whether or not the upcoming data point is a sign that an anomaly is likely to happen in the near future. By dynamically adjusting the detection threshold over time, RePAD is able to tolerate minor pattern change in time series and detect anomalies either proactively or on time. Experiments based on two time series datasets collected from the Numenta Anomaly Benchmark demonstrate that RePAD is able to proactively detect anomalies and provide early warnings in real time without human intervention and domain knowledge.
Classifying Human Activities using Machine Learning and Deep Learning Techniques
May 19, 2022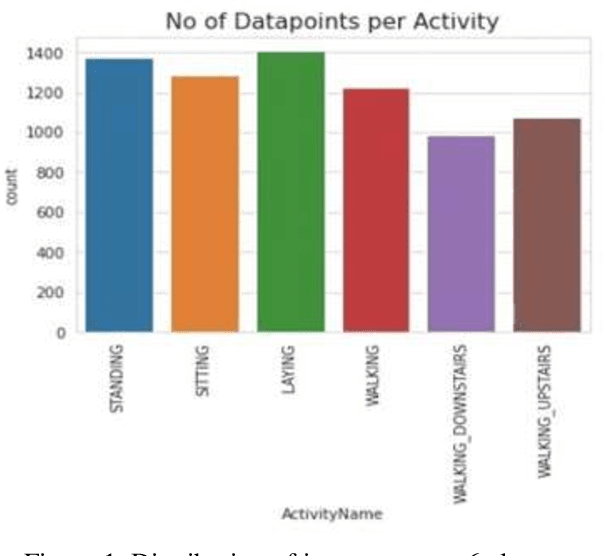

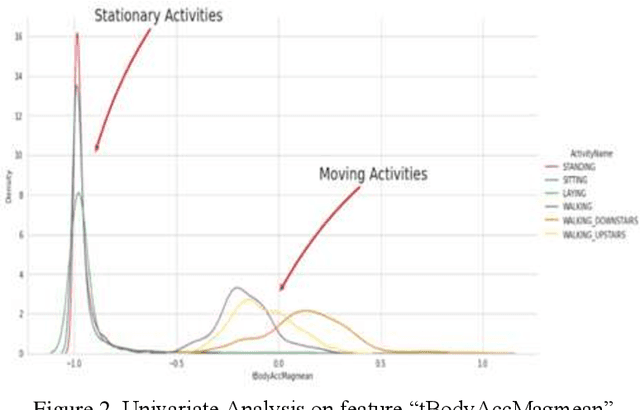

Human Activity Recognition (HAR) describes the machines ability to recognize human actions. Nowadays, most people on earth are health conscious, so people are more interested in tracking their daily activities using Smartphones or Smart Watches, which can help them manage their daily routines in a healthy way. With this objective, Kaggle has conducted a competition to classify 6 different human activities distinctly based on the inertial signals obtained from 30 volunteers smartphones. The main challenge in HAR is to overcome the difficulties of separating human activities based on the given data such that no two activities overlap. In this experimentation, first, Data visualization is done on expert generated features with the help of t distributed Stochastic Neighborhood Embedding followed by applying various Machine Learning techniques like Logistic Regression, Linear SVC, Kernel SVM, Decision trees to better classify the 6 distinct human activities. Moreover, Deep Learning techniques like Long Short-Term Memory (LSTM), Bi-Directional LSTM, Recurrent Neural Network (RNN), and Gated Recurrent Unit (GRU) are trained using raw time series data. Finally, metrics like Accuracy, Confusion matrix, precision and recall are used to evaluate the performance of the Machine Learning and Deep Learning models. Experiment results proved that the Linear Support Vector Classifier in machine learning and Gated Recurrent Unit in Deep Learning provided better accuracy for human activity recognition compared to other classifiers.
4D Dual-Tree Complex Wavelets for Time-Dependent Data
Mar 29, 2021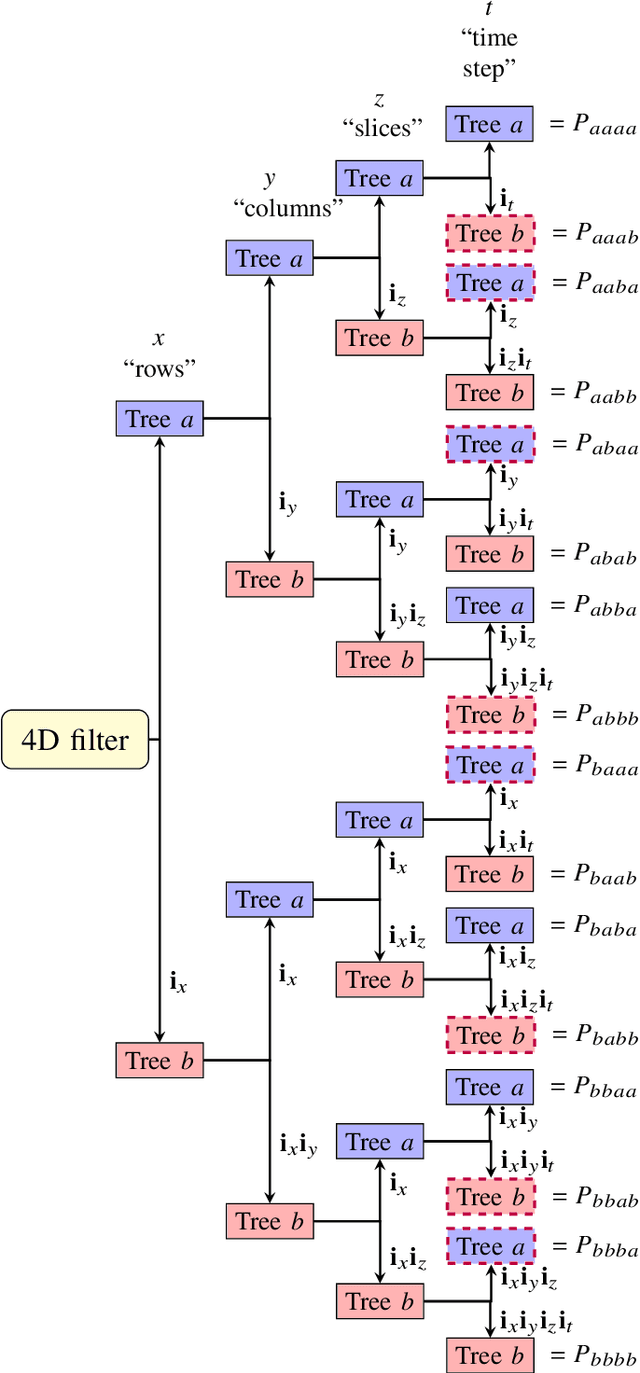
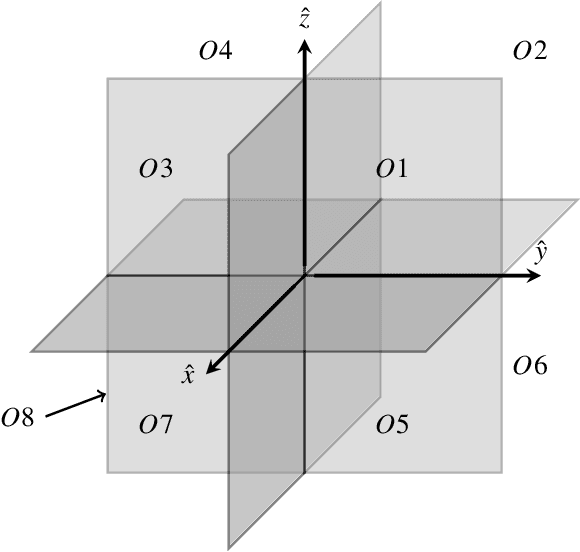


The dual-tree complex wavelet transform (DT-$\mathbb{C}$WT) is extended to the 4D setting. Key properties of 4D DT-$\mathbb{C}$WT, such as directional sensitivity and shift-invariance, are discussed and illustrated in a tomographic application. The inverse problem of reconstructing a dynamic three-dimensional target from X-ray projection measurements can be formulated as 4D space-time tomography. The results suggest that 4D DT-$\mathbb{C}$WT offers simple implementations combined with useful theoretical properties for tomographic reconstruction.
MultiEarth 2022 -- Multimodal Learning for Earth and Environment Workshop and Challenge
Apr 27, 2022
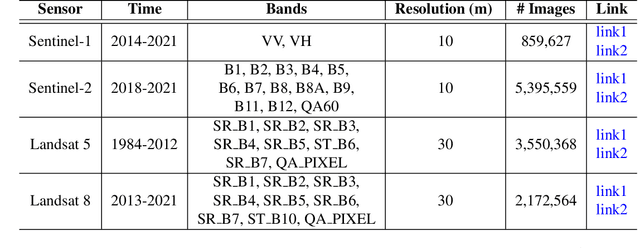


The Multimodal Learning for Earth and Environment Challenge (MultiEarth 2022) will be the first competition aimed at the monitoring and analysis of deforestation in the Amazon rainforest at any time and in any weather conditions. The goal of the Challenge is to provide a common benchmark for multimodal information processing and to bring together the earth and environmental science communities as well as multimodal representation learning communities to compare the relative merits of the various multimodal learning methods to deforestation estimation under well-defined and strictly comparable conditions. MultiEarth 2022 will have three sub-challenges: 1) matrix completion, 2) deforestation estimation, and 3) image-to-image translation. This paper presents the challenge guidelines, datasets, and evaluation metrics for the three sub-challenges. Our challenge website is available at https://sites.google.com/view/rainforest-challenge.
Beyond Distributional Hypothesis: Let Language Models Learn Meaning-Text Correspondence
May 08, 2022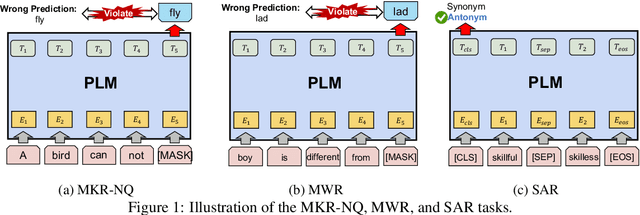
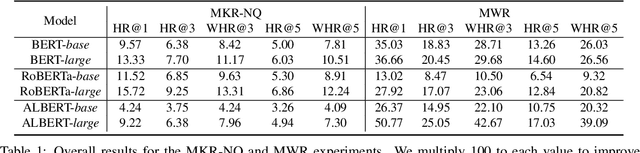
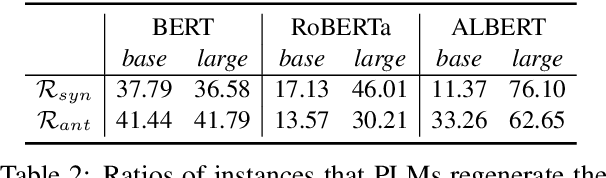
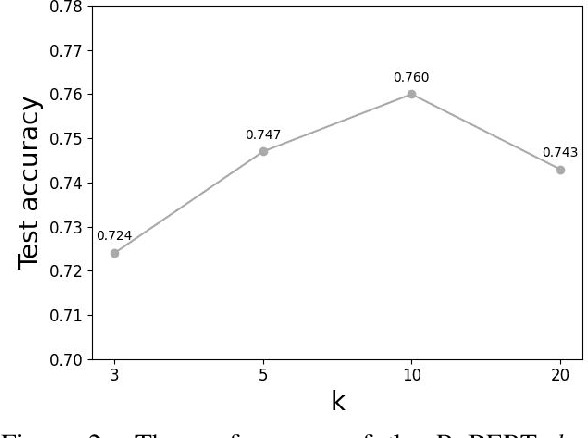
The logical negation property (LNP), which implies generating different predictions for semantically opposite inputs, is an important property that a trustworthy language model must satisfy. However, much recent evidence shows that large-size pre-trained language models (PLMs) do not satisfy this property. In this paper, we perform experiments using probing tasks to assess PLM's LNP understanding. Unlike previous studies that only examined negation expressions, we expand the boundary of the investigation to lexical semantics. Through experiments, we observe that PLMs violate the LNP frequently. To alleviate the issue, we propose a novel intermediate training task, names meaning-matching, designed to directly learn a meaning-text correspondence, instead of relying on the distributional hypothesis. Through multiple experiments, we find that the task enables PLMs to learn lexical semantic information. Also, through fine-tuning experiments on 7 GLUE tasks, we confirm that it is a safe intermediate task that guarantees a similar or better performance of downstream tasks. Finally, we observe that our proposed approach outperforms our previous counterparts despite its time and resource efficiency.
PP-Rec: News Recommendation with Personalized User Interest and Time-aware News Popularity
Jun 02, 2021
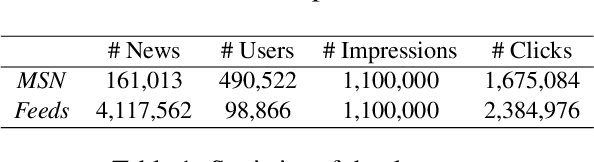
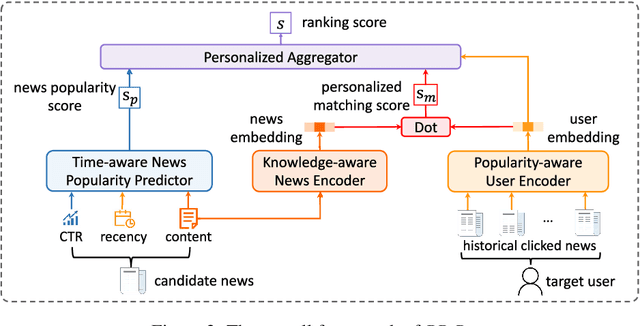
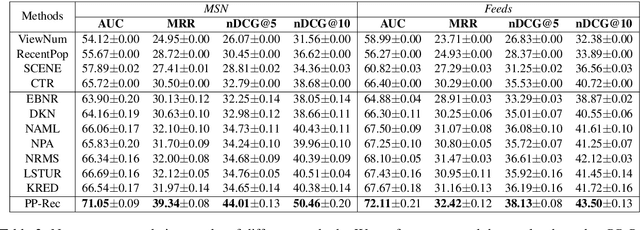
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
MESH2IR: Neural Acoustic Impulse Response Generator for Complex 3D Scenes
May 18, 2022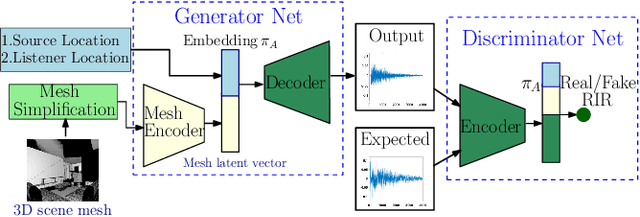
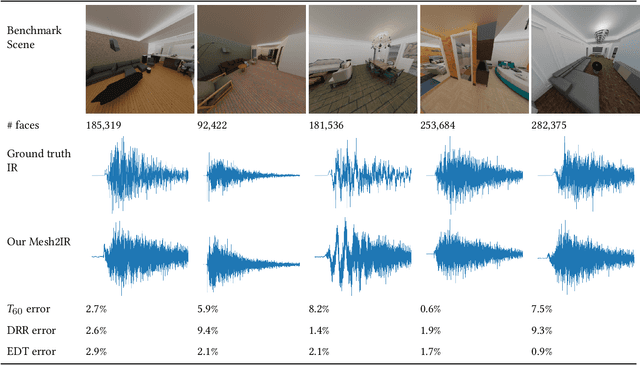
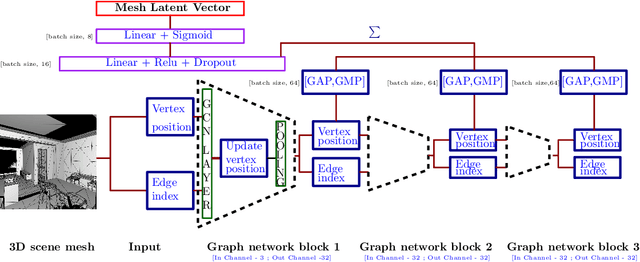
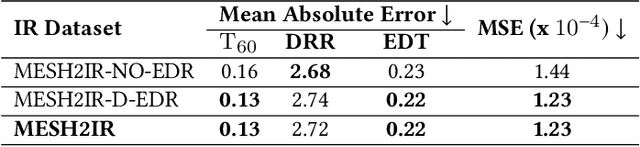
We propose a mesh-based neural network (MESH2IR) to generate acoustic impulse responses (IRs) for indoor 3D scenes represented using a mesh. The IRs are used to create a high-quality sound experience in interactive applications and audio processing. Our method can handle input triangular meshes with arbitrary topologies (2K - 3M triangles). We present a novel training technique to train MESH2IR using energy decay relief and highlight its benefits. We also show that training MESH2IR on IRs preprocessed using our proposed technique significantly improves the accuracy of IR generation. We reduce the non-linearity in the mesh space by transforming 3D scene meshes to latent space using a graph convolution network. Our MESH2IR is more than 200 times faster than a geometric acoustic algorithm on a CPU and can generate more than 10,000 IRs per second on an NVIDIA GeForce RTX 2080 Ti GPU for a given furnished indoor 3D scene. The acoustic metrics are used to characterize the acoustic environment. We show that the acoustic metrics of the IRs predicted from our MESH2IR match the ground truth with less than 10% error. We also highlight the benefits of MESH2IR on audio and speech processing applications such as speech dereverberation and speech separation. To the best of our knowledge, ours is the first neural-network-based approach to predict IRs from a given 3D scene mesh in real-time.
Keypoints Tracking via Transformer Networks
Mar 24, 2022
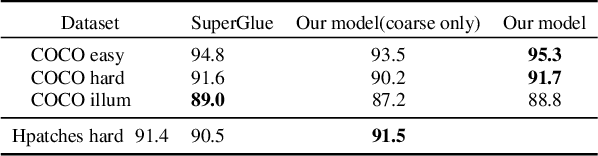
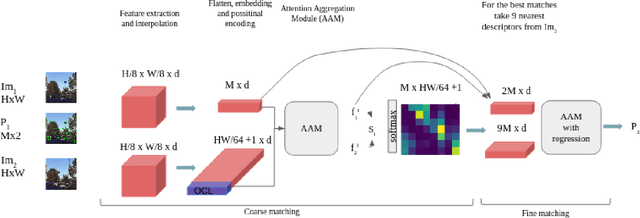

In this thesis, we propose a pioneering work on sparse keypoints tracking across images using transformer networks. While deep learning-based keypoints matching have been widely investigated using graph neural networks - and more recently transformer networks, they remain relatively too slow to operate in real-time and are particularly sensitive to the poor repeatability of the keypoints detectors. In order to address these shortcomings, we propose to study the particular case of real-time and robust keypoints tracking. Specifically, we propose a novel architecture which ensures a fast and robust estimation of the keypoints tracking between successive images of a video sequence. Our method takes advantage of a recent breakthrough in computer vision, namely, visual transformer networks. Our method consists of two successive stages, a coarse matching followed by a fine localization of the keypoints' correspondences prediction. Through various experiments, we demonstrate that our approach achieves competitive results and demonstrates high robustness against adverse conditions, such as illumination change, occlusion and viewpoint differences.