 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rapid model transfer for medical image segmentation via iterative human-in-the-loop update: from labelled public to unlabelled clinical datasets for multi-organ segmentation in CT
Apr 13, 2022
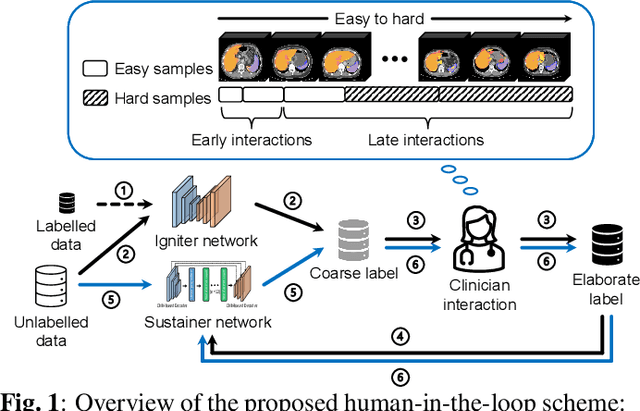
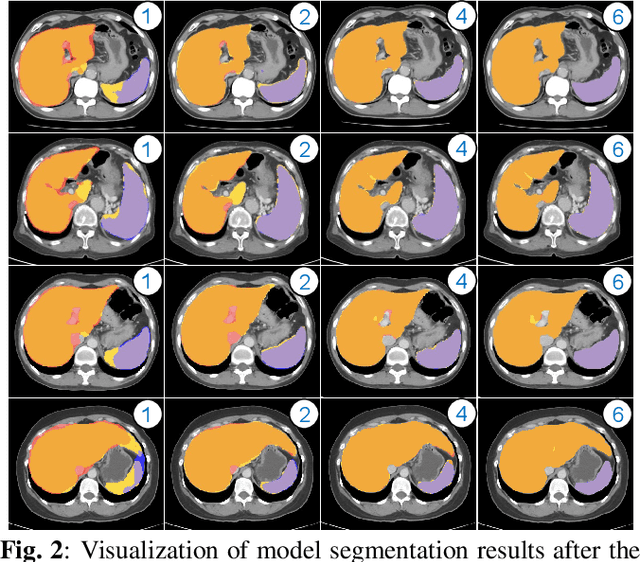
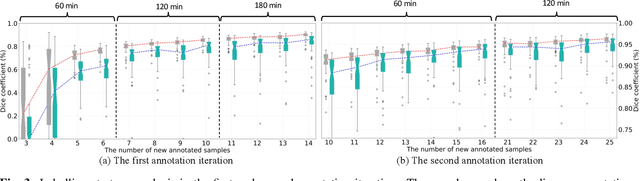
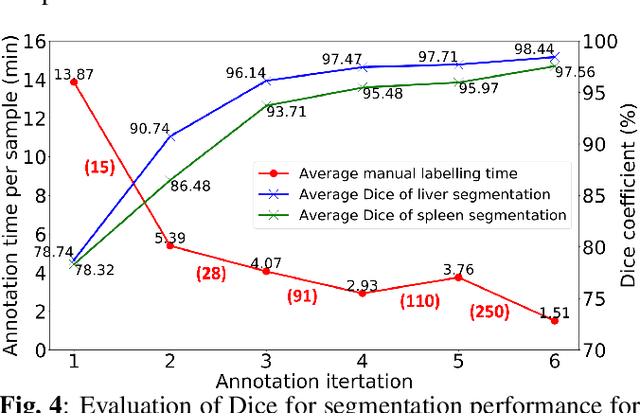
Despite the remarkable success on medical image analysis with deep learning, it is still under exploration regarding how to rapidly transfer AI models from one dataset to another for clinical applications. This paper presents a novel and generic human-in-the-loop scheme for efficiently transferring a segmentation model from a small-scale labelled dataset to a larger-scale unlabelled dataset for multi-organ segmentation in CT. To achieve this, we propose to use an igniter network which can learn from a small-scale labelled dataset and generate coarse annotations to start the process of human-machine interaction. Then, we use a sustainer network for our larger-scale dataset, and iteratively updated it on the new annotated data. Moreover, we propose a flexible labelling strategy for the annotator to reduce the initial annotation workload. The model performance and the time cost of annotation in each subject evaluated on our private dataset are reported and analysed. The results show that our scheme can not only improve the performance by 19.7% on Dice, but also expedite the cost time of manual labelling from 13.87 min to 1.51 min per CT volume during the model transfer, demonstrating the clinical usefulness with promising potentials.
FedWalk: Communication Efficient Federated Unsupervised Node Embedding with Differential Privacy
Jun 01, 2022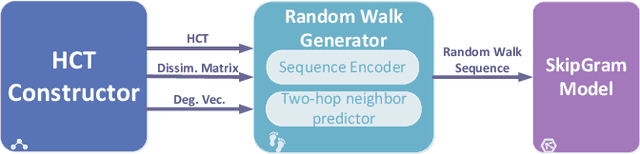
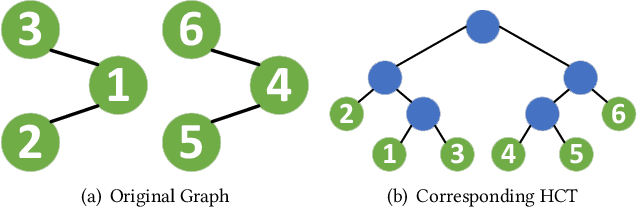
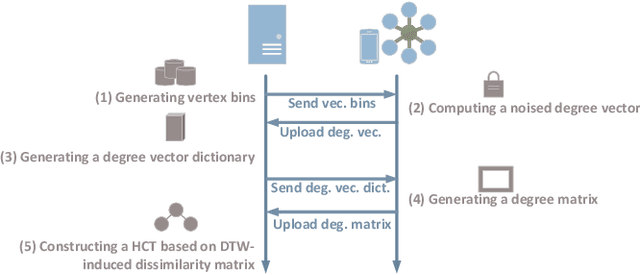
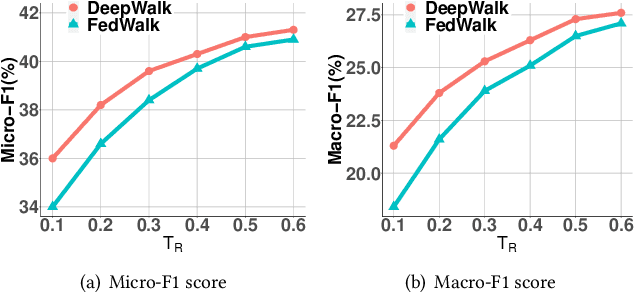
Node embedding aims to map nodes in the complex graph into low-dimensional representations. The real-world large-scale graphs and difficulties of labeling motivate wide studies of unsupervised node embedding problems. Nevertheless, previous effort mostly operates in a centralized setting where a complete graph is given. With the growing awareness of data privacy, data holders who are only aware of one vertex and its neighbours demand greater privacy protection. In this paper, we introduce FedWalk, a random-walk-based unsupervised node embedding algorithm that operates in such a node-level visibility graph with raw graph information remaining locally. FedWalk is designed to offer centralized competitive graph representation capability with data privacy protection and great communication efficiency. FedWalk instantiates the prevalent federated paradigm and contains three modules. We first design a hierarchical clustering tree (HCT) constructor to extract the structural feature of each node. A dynamic time warping algorithm seamlessly handles the structural heterogeneity across different nodes. Based on the constructed HCT, we then design a random walk generator, wherein a sequence encoder is designed to preserve privacy and a two-hop neighbor predictor is designed to save communication cost. The generated random walks are then used to update node embedding based on a SkipGram model. Extensive experiments on two large graphs demonstrate that Fed-Walk achieves competitive representativeness as a centralized node embedding algorithm does with only up to 1.8% Micro-F1 score and 4.4% Marco-F1 score loss while reducing about 6.7 times of inter-device communication per walk.
Detecting the Role of an Entity in Harmful Memes: Techniques and Their Limitations
May 09, 2022
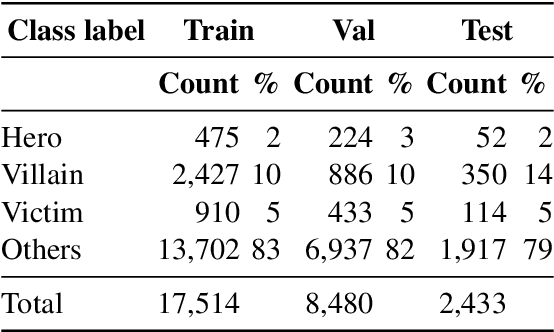

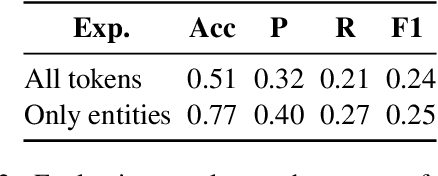
Harmful or abusive online content has been increasing over time, raising concerns for social media platforms, government agencies, and policymakers. Such harmful or abusive content can have major negative impact on society, e.g., cyberbullying can lead to suicides, rumors about COVID-19 can cause vaccine hesitance, promotion of fake cures for COVID-19 can cause health harms and deaths. The content that is posted and shared online can be textual, visual, or a combination of both, e.g., in a meme. Here, we describe our experiments in detecting the roles of the entities (hero, villain, victim) in harmful memes, which is part of the CONSTRAINT-2022 shared task, as well as our system for the task. We further provide a comparative analysis of different experimental settings (i.e., unimodal, multimodal, attention, and augmentation). For reproducibility, we make our experimental code publicly available. \url{https://github.com/robi56/harmful_memes_block_fusion}
Learning in Feedback-driven Recurrent Spiking Neural Networks using full-FORCE Training
May 26, 2022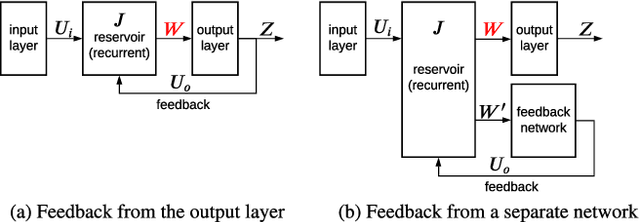
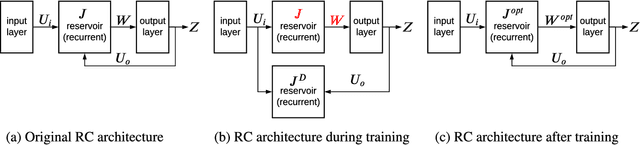
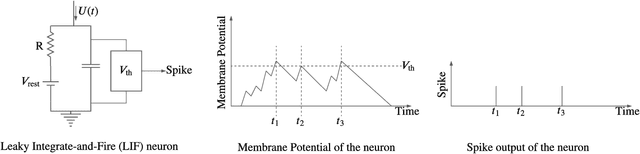
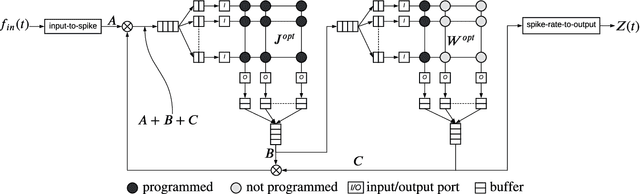
Feedback-driven recurrent spiking neural networks (RSNNs) are powerful computational models that can mimic dynamical systems. However, the presence of a feedback loop from the readout to the recurrent layer de-stabilizes the learning mechanism and prevents it from converging. Here, we propose a supervised training procedure for RSNNs, where a second network is introduced only during the training, to provide hint for the target dynamics. The proposed training procedure consists of generating targets for both recurrent and readout layers (i.e., for a full RSNN system). It uses the recursive least square-based First-Order and Reduced Control Error (FORCE) algorithm to fit the activity of each layer to its target. The proposed full-FORCE training procedure reduces the amount of modifications needed to keep the error between the output and target close to zero. These modifications control the feedback loop, which causes the training to converge. We demonstrate the improved performance and noise robustness of the proposed full-FORCE training procedure to model 8 dynamical systems using RSNNs with leaky integrate and fire (LIF) neurons and rate coding. For energy-efficient hardware implementation, an alternative time-to-first-spike (TTFS) coding is implemented for the full- FORCE training procedure. Compared to rate coding, full-FORCE with TTFS coding generates fewer spikes and facilitates faster convergence to the target dynamics.
Attention Head Masking for Inference Time Content Selection in Abstractive Summarization
Apr 06, 2021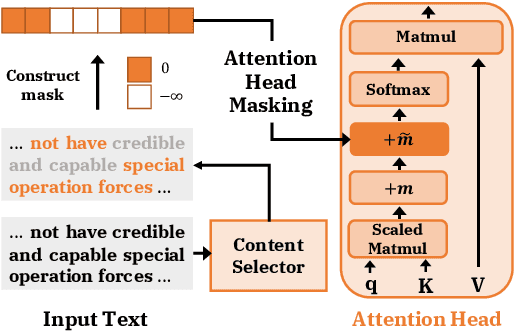
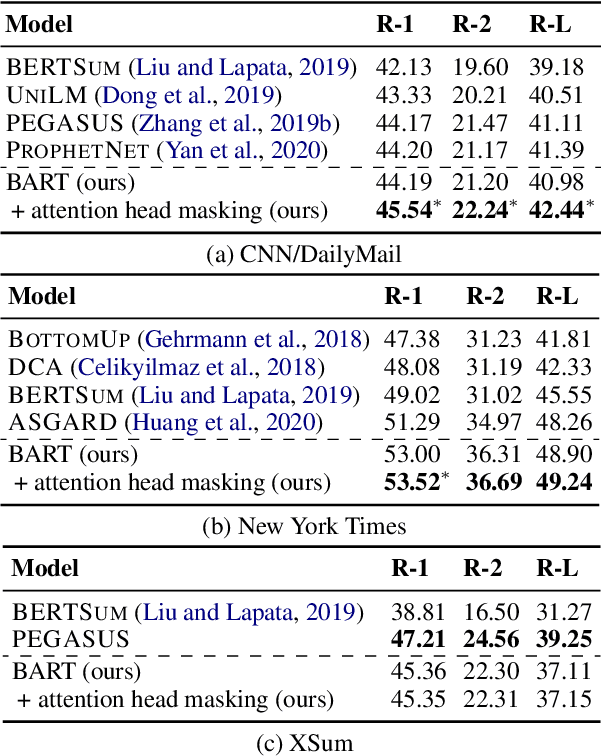
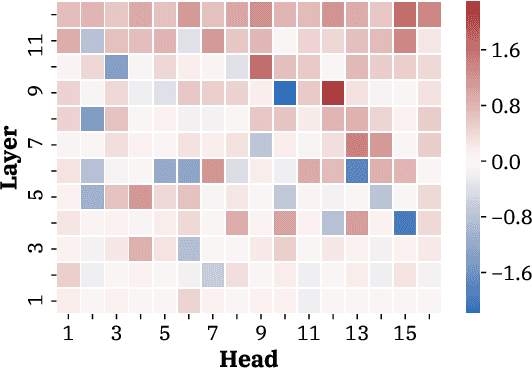

How can we effectively inform content selection in Transformer-based abstractive summarization models? In this work, we present a simple-yet-effective attention head masking technique, which is applied on encoder-decoder attentions to pinpoint salient content at inference time. Using attention head masking, we are able to reveal the relation between encoder-decoder attentions and content selection behaviors of summarization models. We then demonstrate its effectiveness on three document summarization datasets based on both in-domain and cross-domain settings. Importantly, our models outperform prior state-of-the-art models on CNN/Daily Mail and New York Times datasets. Moreover, our inference-time masking technique is also data-efficient, requiring only 20% of the training samples to outperform BART fine-tuned on the full CNN/DailyMail dataset.
Efficient Space-time Video Super Resolution using Low-Resolution Flow and Mask Upsampling
Apr 12, 2021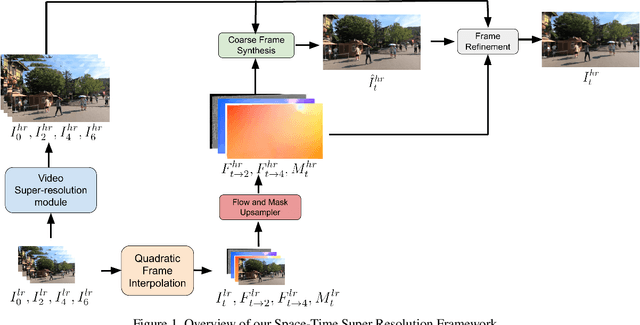
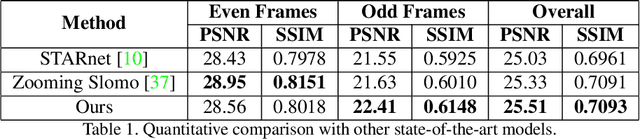

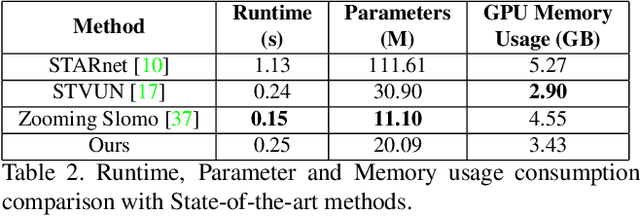
This paper explores an efficient solution for Space-time Super-Resolution, aiming to generate High-resolution Slow-motion videos from Low Resolution and Low Frame rate videos. A simplistic solution is the sequential running of Video Super Resolution and Video Frame interpolation models. However, this type of solutions are memory inefficient, have high inference time, and could not make the proper use of space-time relation property. To this extent, we first interpolate in LR space using quadratic modeling. Input LR frames are super-resolved using a state-of-the-art Video Super-Resolution method. Flowmaps and blending mask which are used to synthesize LR interpolated frame is reused in HR space using bilinear upsampling. This leads to a coarse estimate of HR intermediate frame which often contains artifacts along motion boundaries. We use a refinement network to improve the quality of HR intermediate frame via residual learning. Our model is lightweight and performs better than current state-of-the-art models in REDS STSR Validation set.
Learning Latent Causal Dynamics
Feb 23, 2022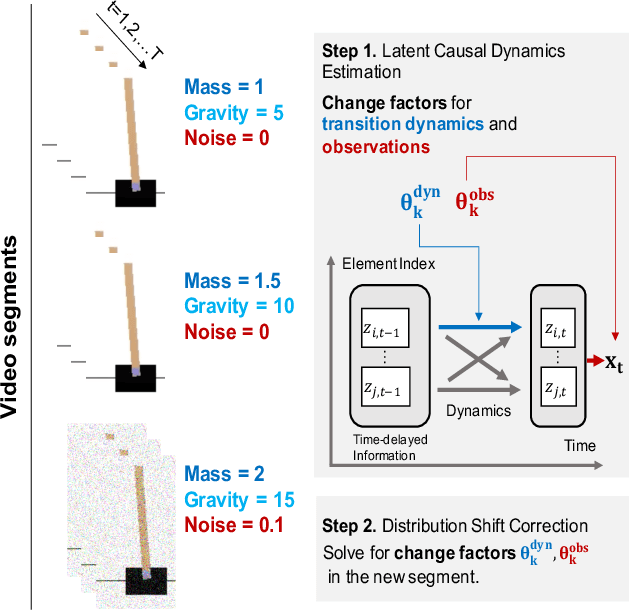
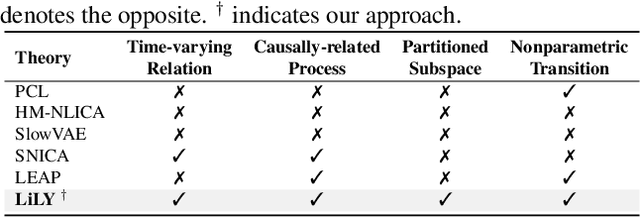
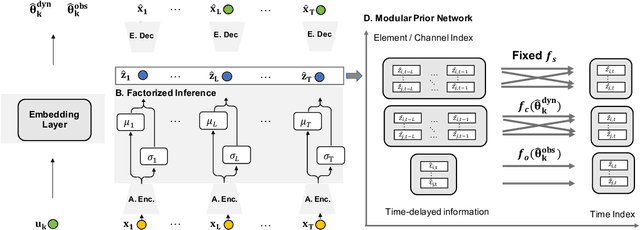
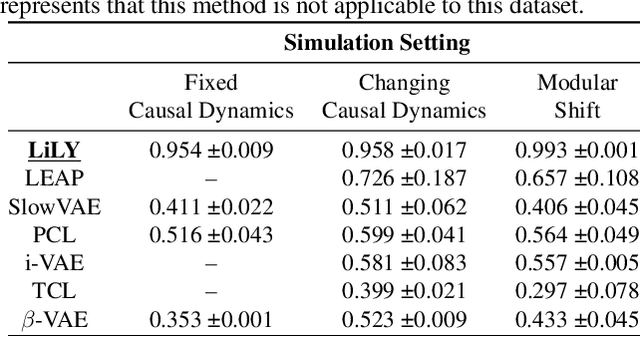
One critical challenge of time-series modeling is how to learn and quickly correct the model under unknown distribution shifts. In this work, we propose a principled framework, called LiLY, to first recover time-delayed latent causal variables and identify their relations from measured temporal data under different distribution shifts. The correction step is then formulated as learning the low-dimensional change factors with a few samples from the new environment, leveraging the identified causal structure. Specifically, the framework factorizes unknown distribution shifts into transition distribution changes caused by fixed dynamics and time-varying latent causal relations, and by global changes in observation. We establish the identifiability theories of nonparametric latent causal dynamics from their nonlinear mixtures under fixed dynamics and under changes. Through experiments, we show that time-delayed latent causal influences are reliably identified from observed variables under different distribution changes. By exploiting this modular representation of changes, we can efficiently learn to correct the model under unknown distribution shifts with only a few samples.
2D versus 3D Convolutional Spiking Neural Networks Trained with Unsupervised STDP for Human Action Recognition
May 26, 2022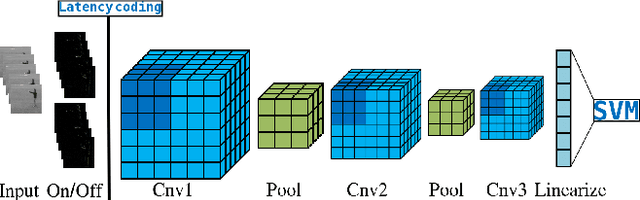
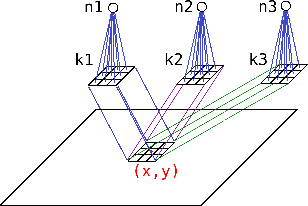
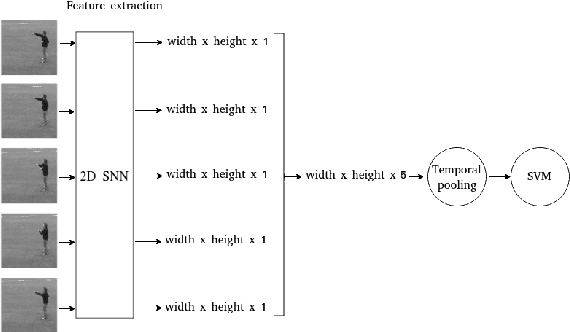
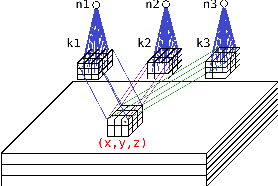
Current advances in technology have highlighted the importance of video analysis in the domain of computer vision. However, video analysis has considerably high computational costs with traditional artificial neural networks (ANNs). Spiking neural networks (SNNs) are third generation biologically plausible models that process the information in the form of spikes. Unsupervised learning with SNNs using the spike timing dependent plasticity (STDP) rule has the potential to overcome some bottlenecks of regular artificial neural networks, but STDP-based SNNs are still immature and their performance is far behind that of ANNs. In this work, we study the performance of SNNs when challenged with the task of human action recognition, because this task has many real-time applications in computer vision, such as video surveillance. In this paper we introduce a multi-layered 3D convolutional SNN model trained with unsupervised STDP. We compare the performance of this model to those of a 2D STDP-based SNN when challenged with the KTH and Weizmann datasets. We also compare single-layer and multi-layer versions of these models in order to get an accurate assessment of their performance. We show that STDP-based convolutional SNNs can learn motion patterns using 3D kernels, thus enabling motion-based recognition from videos. Finally, we give evidence that 3D convolution is superior to 2D convolution with STDP-based SNNs, especially when dealing with long video sequences.
Follow-the-Perturbed-Leader for Adversarial Markov Decision Processes with Bandit Feedback
May 26, 2022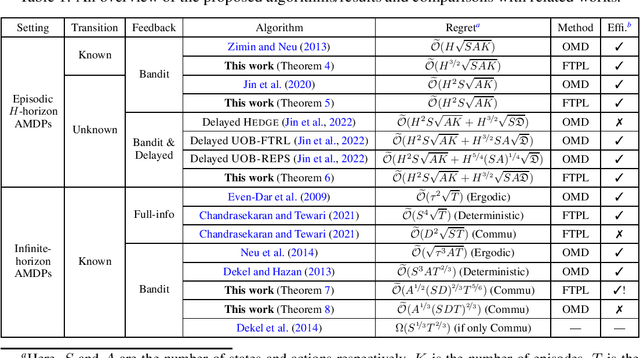
We consider regret minimization for Adversarial Markov Decision Processes (AMDPs), where the loss functions are changing over time and adversarially chosen, and the learner only observes the losses for the visited state-action pairs (i.e., bandit feedback). While there has been a surge of studies on this problem using Online-Mirror-Descent (OMD) methods, very little is known about the Follow-the-Perturbed-Leader (FTPL) methods, which are usually computationally more efficient and also easier to implement since it only requires solving an offline planning problem. Motivated by this, we take a closer look at FTPL for learning AMDPs, starting from the standard episodic finite-horizon setting. We find some unique and intriguing difficulties in the analysis and propose a workaround to eventually show that FTPL is also able to achieve near-optimal regret bounds in this case. More importantly, we then find two significant applications: First, the analysis of FTPL turns out to be readily generalizable to delayed bandit feedback with order-optimal regret, while OMD methods exhibit extra difficulties (Jin et al., 2022). Second, using FTPL, we also develop the first no-regret algorithm for learning communicating AMDPs in the infinite-horizon setting with bandit feedback and stochastic transitions. Our algorithm is efficient assuming access to an offline planning oracle, while even for the easier full-information setting, the only existing algorithm (Chandrasekaran and Tewari, 2021) is computationally inefficient.
Research on the correlation between text emotion mining and stock market based on deep learning
May 09, 2022This paper discusses how to crawl the data of financial forums such as stock bar, and conduct emotional analysis combined with the in-depth learning model. This paper will use the Bert model to train the financial corpus and predict the Shenzhen stock index. Through the comparative study of the maximal information coefficient (MIC), it is found that the emotional characteristics obtained by applying the BERT model to the financial corpus can be reflected in the fluctuation of the stock market, which is conducive to effectively improve the prediction accuracy. At the same time, this paper combines in-depth learning with financial texts to further explore the impact mechanism of investor sentiment on the stock market through in-depth learning, which will help the national regulatory authorities and policy departments to formulate more reasonable policies and guidelines for maintaining the stability of the stock market.