 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Eventor: An Efficient Event-Based Monocular Multi-View Stereo Accelerator on FPGA Platform
Mar 29, 2022
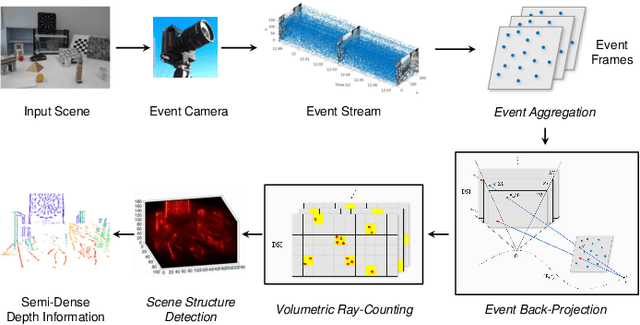
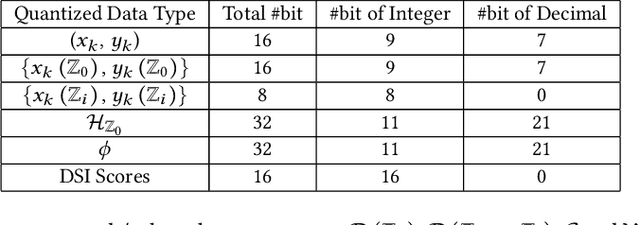
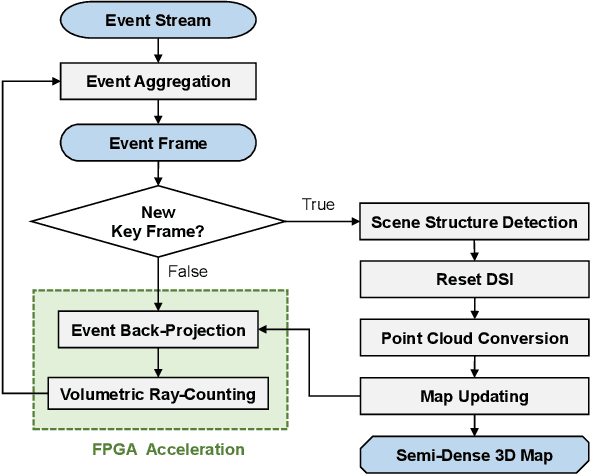
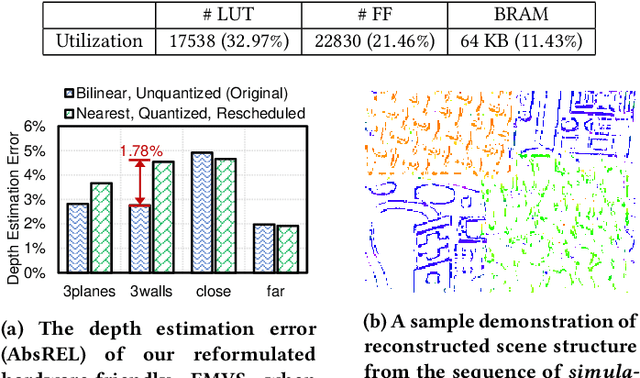
Event cameras are bio-inspired vision sensors that asynchronously represent pixel-level brightness changes as event streams. Event-based monocular multi-view stereo (EMVS) is a technique that exploits the event streams to estimate semi-dense 3D structure with known trajectory. It is a critical task for event-based monocular SLAM. However, the required intensive computation workloads make it challenging for real-time deployment on embedded platforms. In this paper, Eventor is proposed as a fast and efficient EMVS accelerator by realizing the most critical and time-consuming stages including event back-projection and volumetric ray-counting on FPGA. Highly paralleled and fully pipelined processing elements are specially designed via FPGA and integrated with the embedded ARM as a heterogeneous system to improve the throughput and reduce the memory footprint. Meanwhile, the EMVS algorithm is reformulated to a more hardware-friendly manner by rescheduling, approximate computing and hybrid data quantization. Evaluation results on DAVIS dataset show that Eventor achieves up to $24\times$ improvement in energy efficiency compared with Intel i5 CPU platform.
SwinVRNN: A Data-Driven Ensemble Forecasting Model via Learned Distribution Perturbation
May 26, 2022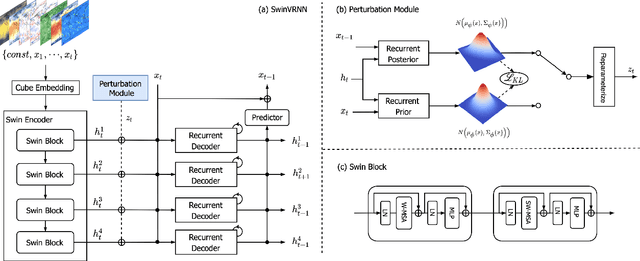


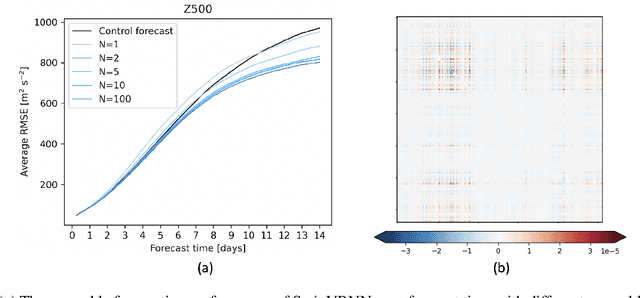
Data-driven approaches for medium-range weather forecasting are recently shown extraordinarily promising for ensemble forecasting for their fast inference speed compared to traditional numerical weather prediction (NWP) models, but their forecast accuracy can hardly match the state-of-the-art operational ECMWF Integrated Forecasting System (IFS) model. Previous data-driven attempts achieve ensemble forecast using some simple perturbation methods, like initial condition perturbation and Monte Carlo dropout. However, they mostly suffer unsatisfactory ensemble performance, which is arguably attributed to the sub-optimal ways of applying perturbation. We propose a Swin Transformer-based Variational Recurrent Neural Network (SwinVRNN), which is a stochastic weather forecasting model combining a SwinRNN predictor with a perturbation module. SwinRNN is designed as a Swin Transformer-based recurrent neural network, which predicts future states deterministically. Furthermore, to model the stochasticity in prediction, we design a perturbation module following the Variational Auto-Encoder paradigm to learn multivariate Gaussian distributions of a time-variant stochastic latent variable from data. Ensemble forecasting can be easily achieved by perturbing the model features leveraging noise sampled from the learned distribution. We also compare four categories of perturbation methods for ensemble forecasting, i.e. fixed distribution perturbation, learned distribution perturbation, MC dropout, and multi model ensemble. Comparisons on WeatherBench dataset show the learned distribution perturbation method using our SwinVRNN model achieves superior forecast accuracy and reasonable ensemble spread due to joint optimization of the two targets. More notably, SwinVRNN surpasses operational IFS on surface variables of 2-m temperature and 6-hourly total precipitation at all lead times up to five days.
Discrete Optimal Transport with Independent Marginals is #P-Hard
Mar 02, 2022We study the computational complexity of the optimal transport problem that evaluates the Wasserstein distance between the distributions of two K-dimensional discrete random vectors. The best known algorithms for this problem run in polynomial time in the maximum of the number of atoms of the two distributions. However, if the components of either random vector are independent, then this number can be exponential in K even though the size of the problem description scales linearly with K. We prove that the described optimal transport problem is #P-hard even if all components of the first random vector are independent uniform Bernoulli random variables, while the second random vector has merely two atoms, and even if only approximate solutions are sought. We also develop a dynamic programming-type algorithm that approximates the Wasserstein distance in pseudo-polynomial time when the components of the first random vector follow arbitrary independent discrete distributions, and we identify special problem instances that can be solved exactly in strongly polynomial time.
Flexible Multiple-Objective Reinforcement Learning for Chip Placement
Apr 13, 2022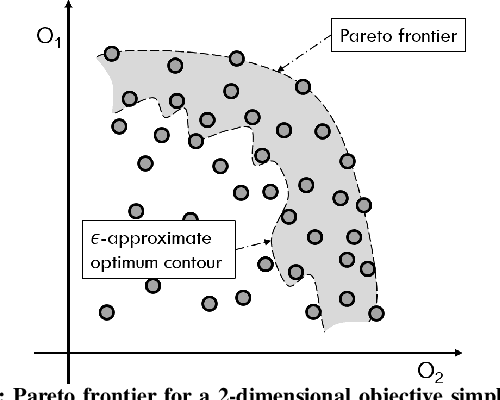
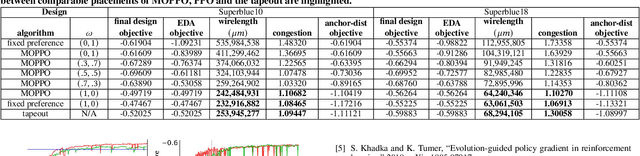
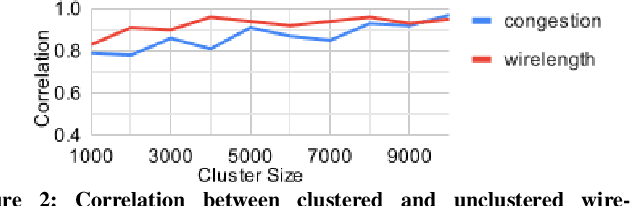

Recently, successful applications of reinforcement learning to chip placement have emerged. Pretrained models are necessary to improve efficiency and effectiveness. Currently, the weights of objective metrics (e.g., wirelength, congestion, and timing) are fixed during pretraining. However, fixed-weighed models cannot generate the diversity of placements required for engineers to accommodate changing requirements as they arise. This paper proposes flexible multiple-objective reinforcement learning (MORL) to support objective functions with inference-time variable weights using just a single pretrained model. Our macro placement results show that MORL can generate the Pareto frontier of multiple objectives effectively.
Optimizing One-pixel Black-box Adversarial Attacks
Apr 30, 2022

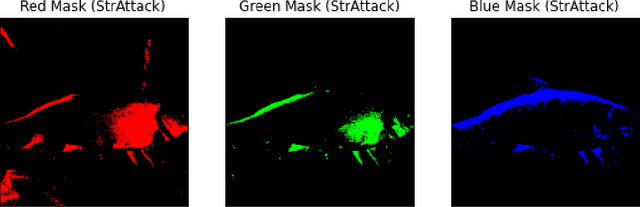

The output of Deep Neural Networks (DNN) can be altered by a small perturbation of the input in a black box setting by making multiple calls to the DNN. However, the high computation and time required makes the existing approaches unusable. This work seeks to improve the One-pixel (few-pixel) black-box adversarial attacks to reduce the number of calls to the network under attack. The One-pixel attack uses a non-gradient optimization algorithm to find pixel-level perturbations under the constraint of a fixed number of pixels, which causes the network to predict the wrong label for a given image. We show through experimental results how the choice of the optimization algorithm and initial positions to search can reduce function calls and increase attack success significantly, making the attack more practical in real-world settings.
Cross-Utterance Conditioned VAE for Non-Autoregressive Text-to-Speech
May 09, 2022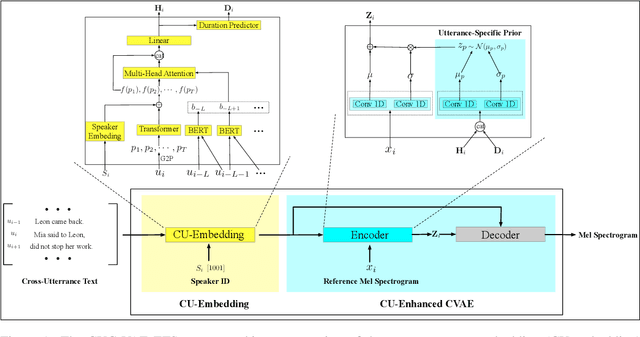
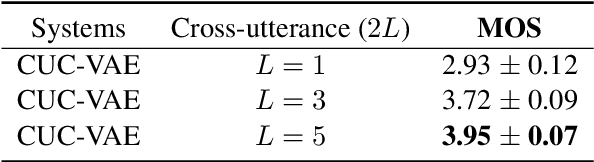

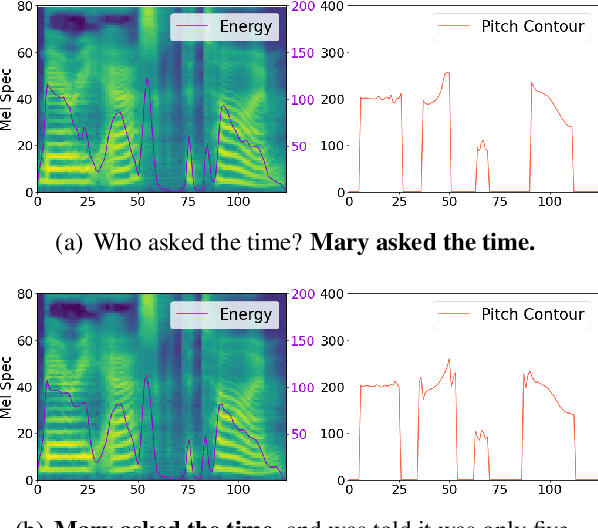
Modelling prosody variation is critical for synthesizing natural and expressive speech in end-to-end text-to-speech (TTS) systems. In this paper, a cross-utterance conditional VAE (CUC-VAE) is proposed to estimate a posterior probability distribution of the latent prosody features for each phoneme by conditioning on acoustic features, speaker information, and text features obtained from both past and future sentences. At inference time, instead of the standard Gaussian distribution used by VAE, CUC-VAE allows sampling from an utterance-specific prior distribution conditioned on cross-utterance information, which allows the prosody features generated by the TTS system to be related to the context and is more similar to how humans naturally produce prosody. The performance of CUC-VAE is evaluated via a qualitative listening test for naturalness, intelligibility and quantitative measurements, including word error rates and the standard deviation of prosody attributes. Experimental results on LJ-Speech and LibriTTS data show that the proposed CUC-VAE TTS system improves naturalness and prosody diversity with clear margins.
SuperVoice: Text-Independent Speaker Verification Using Ultrasound Energy in Human Speech
May 28, 2022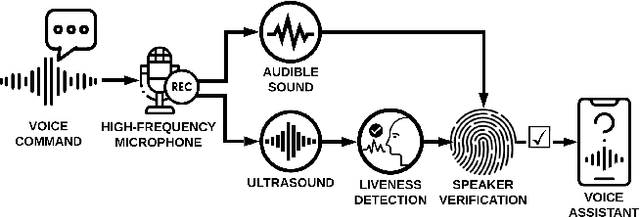
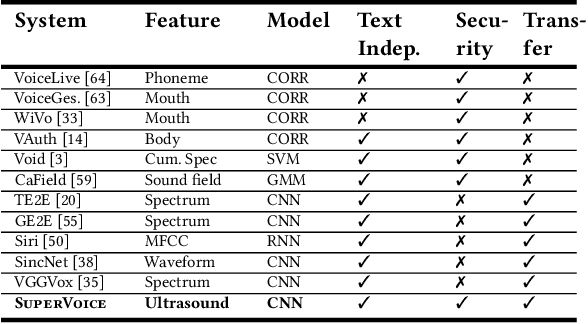
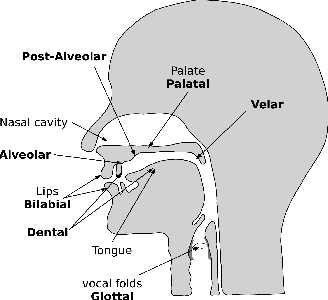
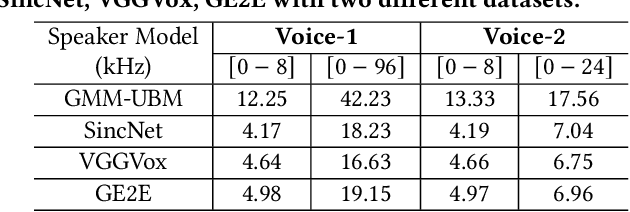
Voice-activated systems are integrated into a variety of desktop, mobile, and Internet-of-Things (IoT) devices. However, voice spoofing attacks, such as impersonation and replay attacks, in which malicious attackers synthesize the voice of a victim or simply replay it, have brought growing security concerns. Existing speaker verification techniques distinguish individual speakers via the spectrographic features extracted from an audible frequency range of voice commands. However, they often have high error rates and/or long delays. In this paper, we explore a new direction of human voice research by scrutinizing the unique characteristics of human speech at the ultrasound frequency band. Our research indicates that the high-frequency ultrasound components (e.g. speech fricatives) from 20 to 48 kHz can significantly enhance the security and accuracy of speaker verification. We propose a speaker verification system, SUPERVOICE that uses a two-stream DNN architecture with a feature fusion mechanism to generate distinctive speaker models. To test the system, we create a speech dataset with 12 hours of audio (8,950 voice samples) from 127 participants. In addition, we create a second spoofed voice dataset to evaluate its security. In order to balance between controlled recordings and real-world applications, the audio recordings are collected from two quiet rooms by 8 different recording devices, including 7 smartphones and an ultrasound microphone. Our evaluation shows that SUPERVOICE achieves 0.58% equal error rate in the speaker verification task, it only takes 120 ms for testing an incoming utterance, outperforming all existing speaker verification systems. Moreover, within 91 ms processing time, SUPERVOICE achieves 0% equal error rate in detecting replay attacks launched by 5 different loudspeakers.
Tensor-based Channel Tracking for RIS-Empowered Multi-User MIMO Wireless Systems
Feb 19, 2022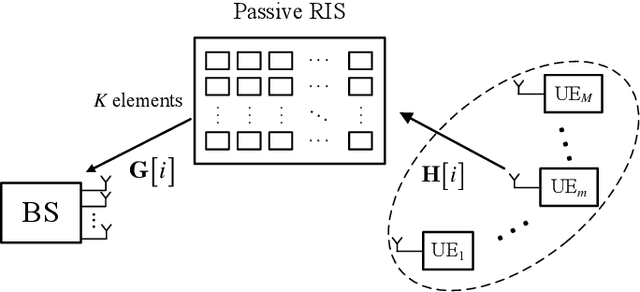
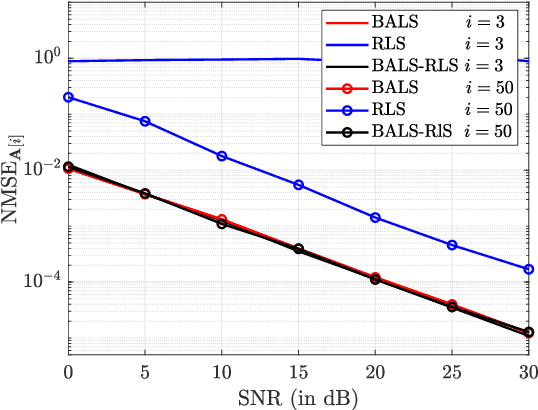
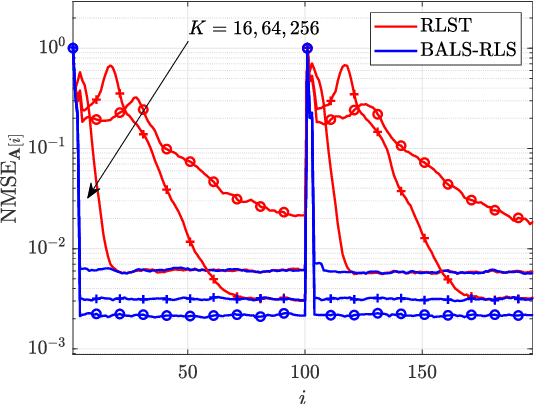
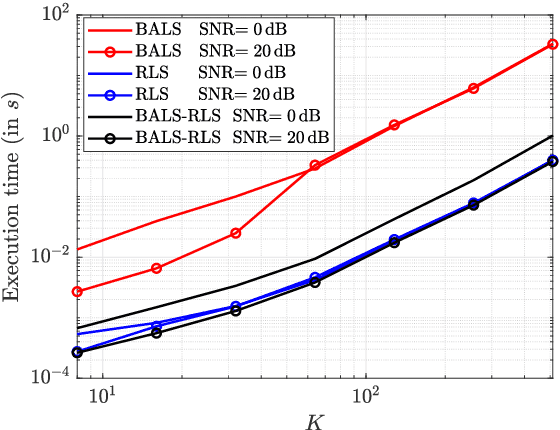
The accurate estimation of Channel State Information (CSI) is of crucial importance for the successful operation of Multiple-Input Multiple-Output (MIMO) communication systems, especially in a Multi-User (MU) time-varying environment and when employing the emerging technology of Reconfigurable Intelligent Surfaces (RISs). Their predominantly passive nature renders the estimation of the channels involved in the user-RIS-base station link a quite challenging problem. Moreover, the time-varying nature of most of the realistic wireless channels drives up the cost of real-time channel tracking significantly, especially when RISs of massive size are deployed. In this paper, we develop a channel tracking scheme for the uplink of RIS-enabled MU MIMO systems in the presence of channel fading. The starting point is a tensor representation of the received signal and we rely on its PARAllel FACtor (PARAFAC) analysis to both get the initial estimate and track the channel time variation. Simulation results for various system settings are reported, which validate the feasibility and effectiveness of the proposed channel tracking approach.
Learning Latent Causal Dynamics
Feb 16, 2022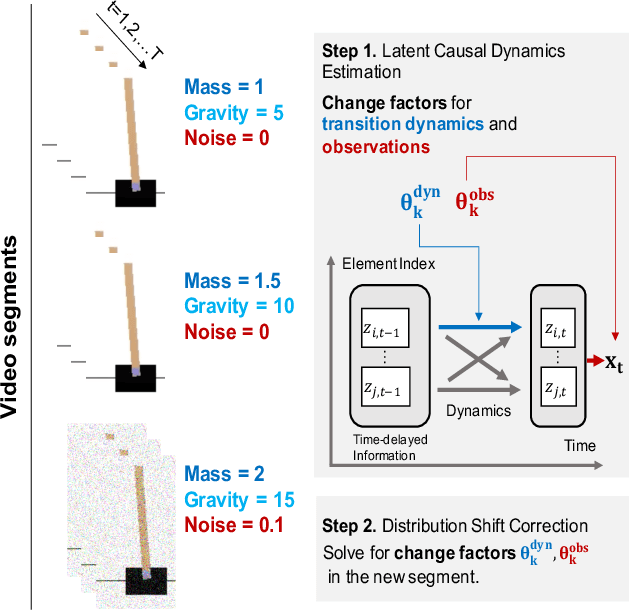
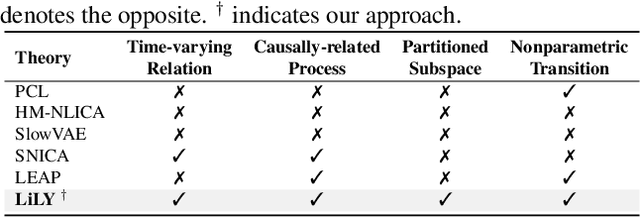
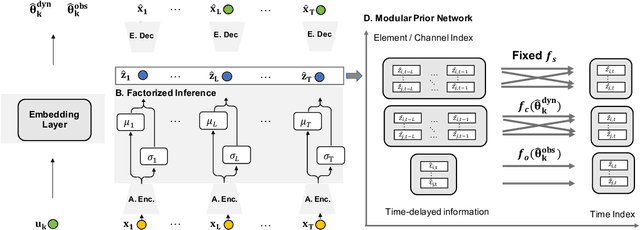
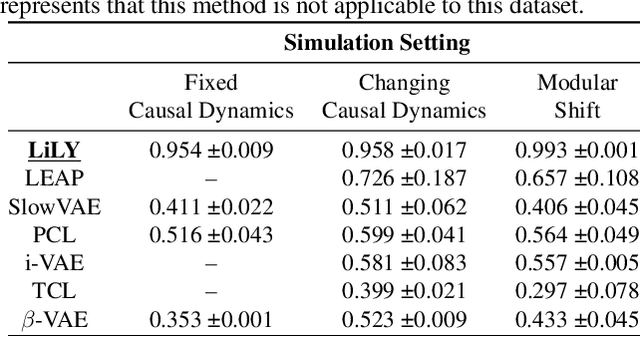
One critical challenge of time-series modeling is how to learn and quickly correct the model under unknown distribution shifts. In this work, we propose a principled framework, called LiLY, to first recover time-delayed latent causal variables and identify their relations from measured temporal data under different distribution shifts. The correction step is then formulated as learning the low-dimensional change factors with a few samples from the new environment, leveraging the identified causal structure. Specifically, the framework factorizes unknown distribution shifts into transition distribution changes caused by fixed dynamics and time-varying latent causal relations, and by global changes in observation. We establish the identifiability theories of nonparametric latent causal dynamics from their nonlinear mixtures under fixed dynamics and under changes. Through experiments, we show that time-delayed latent causal influences are reliably identified from observed variables under different distribution changes. By exploiting this modular representation of changes, we can efficiently learn to correct the model under unknown distribution shifts with only a few samples.
Modulation and Classification of Mixed Signals Based on Deep Learning
May 20, 2022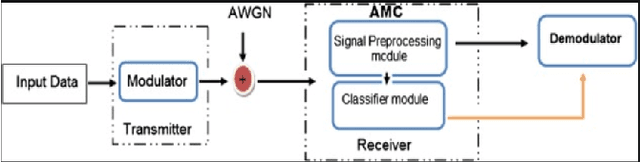
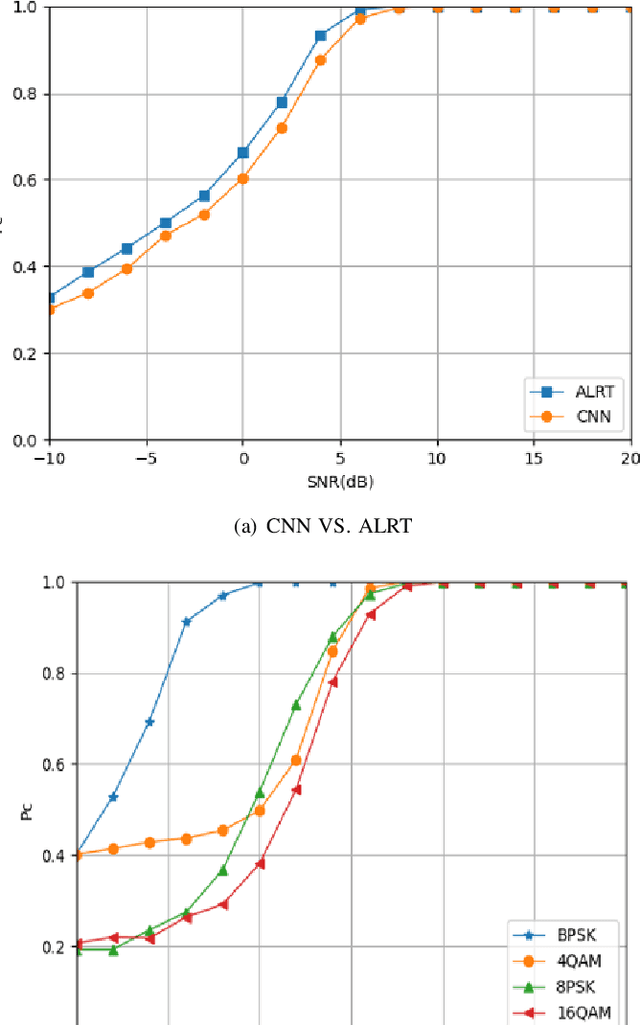
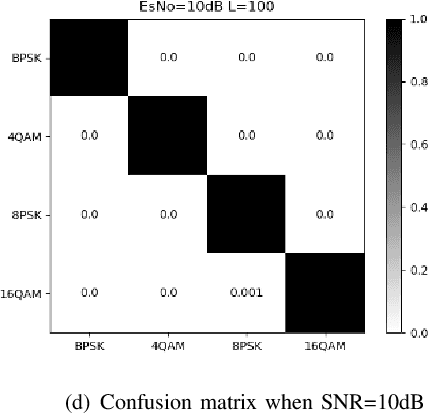
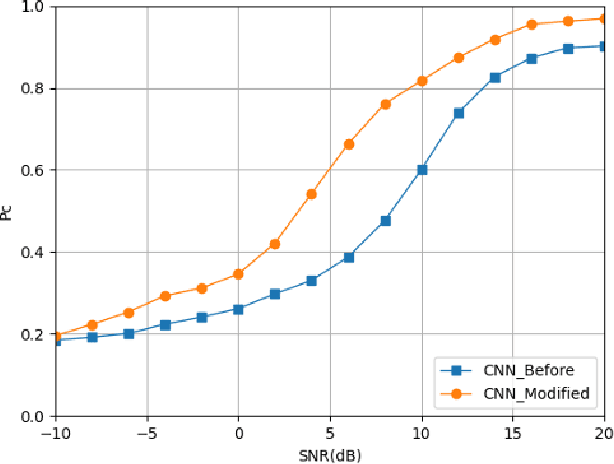
With the rapid development of information nowadays, spectrum resources are becoming more and more scarce, leading to a shift in the research direction from the modulation classification of a single signal to the modulation classification of multiple signals on the same channel. Therefore, the emergence of an effective mixed signals automatic modulation classification technology have important significance. Considering that NOMA technology has deeper requirements for the modulation classification of mixed signals under different power, this paper mainly introduces and uses a variety of deep learning networks to classify such mixed signals. First, the modulation classification of a single signal based on the existing CNN model is reproduced. We then develop new methods to improve the basic CNN structure and apply it to the modulation classification of mixed signals. Meanwhile, the effects of the number of training sets, the type of training sets and the training methods on the recognition accuracy of mixed signals are studied. Second, we investigate some deep learning models based on CNN (ResNet34, hierarchical structure) and other deep learning models (LSTM, CLDNN). It can be seen although the time and space complexity of these algorithms have increased, different deep learning models have different effects on the modulation classification problem of mixed signals at different power. Generally speaking, higher accuracy gains can be achieved.