 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Solvers for Fast and Accurate Numerical Optimal Control
Mar 13, 2022
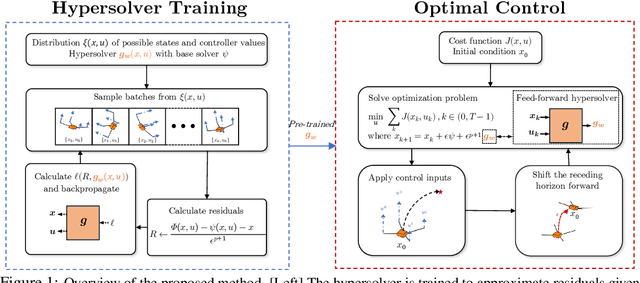

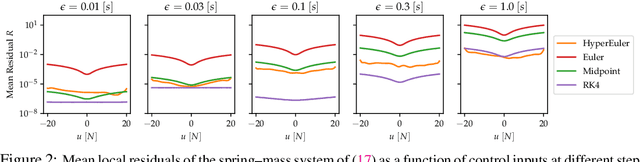
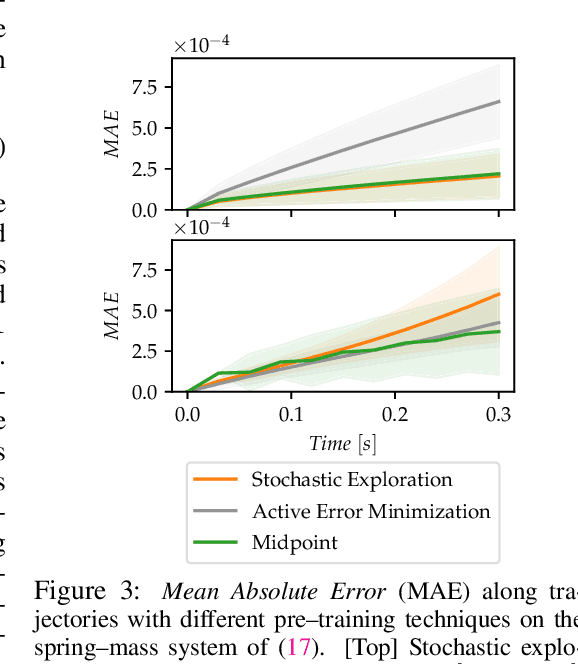
Synthesizing optimal controllers for dynamical systems often involves solving optimization problems with hard real-time constraints. These constraints determine the class of numerical methods that can be applied: computationally expensive but accurate numerical routines are replaced by fast and inaccurate methods, trading inference time for solution accuracy. This paper provides techniques to improve the quality of optimized control policies given a fixed computational budget. We achieve the above via a hypersolvers approach, which hybridizes a differential equation solver and a neural network. The performance is evaluated in direct and receding-horizon optimal control tasks in both low and high dimensions, where the proposed approach shows consistent Pareto improvements in solution accuracy and control performance.
CD-ROM: Complementary Deep-Reduced Order Model
Mar 10, 2022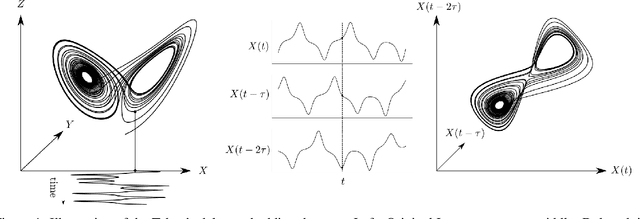

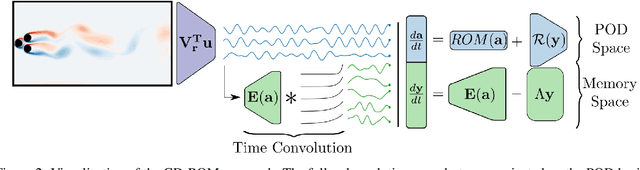
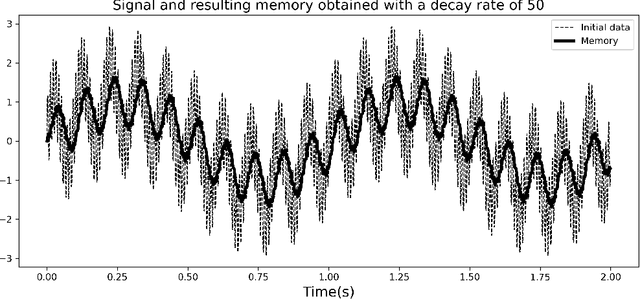
Model order reduction through the POD-Galerkin method can lead to dramatic gains in terms of computational efficiency in solving physical problems. However, the applicability of the method to non linear high-dimensional dynamical systems such as the Navier-Stokes equations has been shown to be limited, producing inaccurate and sometimes unstable models. This paper proposes a closure modeling approach for classical POD-Galerkin reduced order models (ROM). We use multi layer perceptrons (MLP) to learn a continuous in time closure model through the recently proposed Neural ODE method. Inspired by Taken's theorem as well as the Mori-Zwanzig formalism, we augment ROMs with a delay differential equation architecture to model non-Markovian effects in reduced models. The proposed model, called CD-ROM (Complementary Deep-Reduced Order Model) is able to retain information from past states of the system and use it to correct the imperfect reduced dynamics. The model can be integrated in time as a system of ordinary differential equations using any classical time marching scheme. We demonstrate the ability of our CD-ROM approach to improve the accuracy of POD-Galerkin models on two CFD examples, even in configurations unseen during training.
Composing General Audio Representation by Fusing Multilayer Features of a Pre-trained Model
May 17, 2022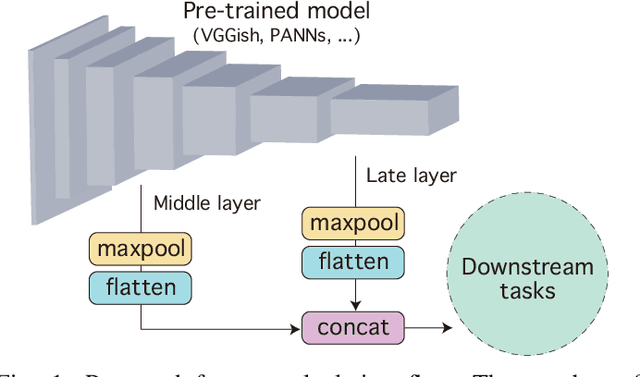
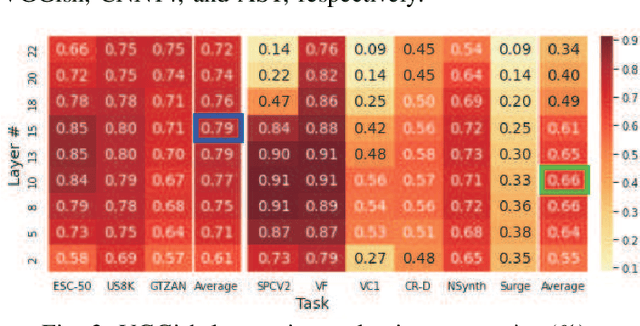

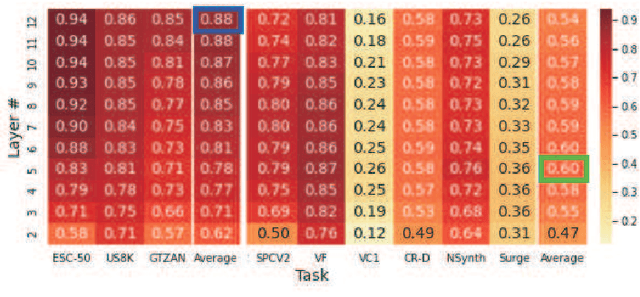
Many application studies rely on audio DNN models pre-trained on a large-scale dataset as essential feature extractors, and they extract features from the last layers. In this study, we focus on our finding that the middle layer features of existing supervised pre-trained models are more effective than the late layer features for some tasks. We propose a simple approach to compose features effective for general-purpose applications, consisting of two steps: (1) calculating feature vectors along the time frame from middle/late layer outputs, and (2) fusing them. This approach improves the utility of frequency and channel information in downstream processes, and combines the effectiveness of middle and late layer features for different tasks. As a result, the feature vectors become effective for general purposes. In the experiments using VGGish, PANNs' CNN14, and AST on nine downstream tasks, we first show that each layer output of these models serves different tasks. Then, we demonstrate that the proposed approach significantly improves their performance and brings it to a level comparable to that of the state-of-the-art. In particular, the performance of the non-semantic speech (NOSS) tasks greatly improves, especially on Speech commands V2 with VGGish of +77.1 (14.3% to 91.4%).
KNN-Diffusion: Image Generation via Large-Scale Retrieval
Apr 06, 2022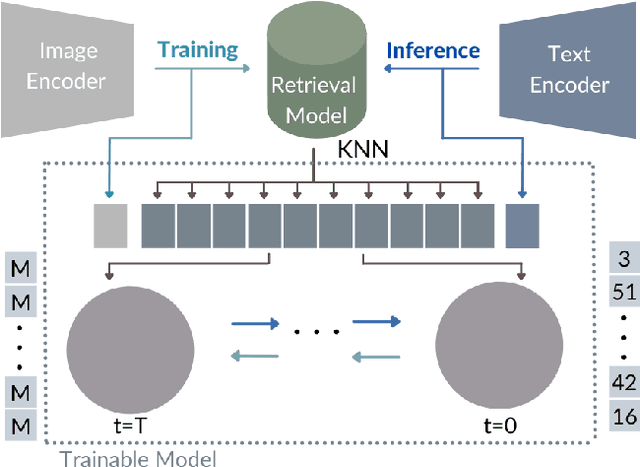
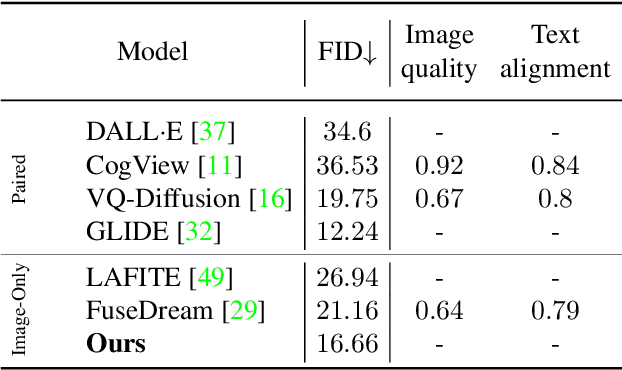
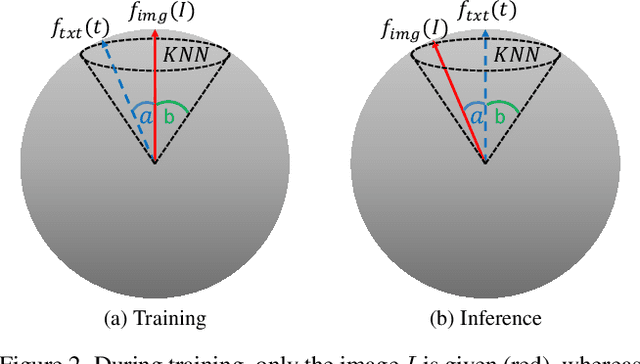

While the availability of massive Text-Image datasets is shown to be extremely useful in training large-scale generative models (e.g. DDPMs, Transformers), their output typically depends on the quality of both the input text, as well as the training dataset. In this work, we show how large-scale retrieval methods, in particular efficient K-Nearest-Neighbors (KNN) search, can be used in order to train a model to adapt to new samples. Learning to adapt enables several new capabilities. Sifting through billions of records at inference time is extremely efficient and can alleviate the need to train or memorize an adequately large generative model. Additionally, fine-tuning trained models to new samples can be achieved by simply adding them to the table. Rare concepts, even without any presence in the training set, can be then leveraged during test time without any modification to the generative model. Our diffusion-based model trains on images only, by leveraging a joint Text-Image multi-modal metric. Compared to baseline methods, our generations achieve state of the art results both in human evaluations as well as with perceptual scores when tested on a public multimodal dataset of natural images, as well as on a collected dataset of 400 million Stickers.
How to Guide Adaptive Depth Sampling?
May 20, 2022
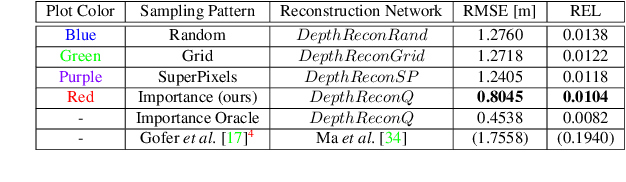
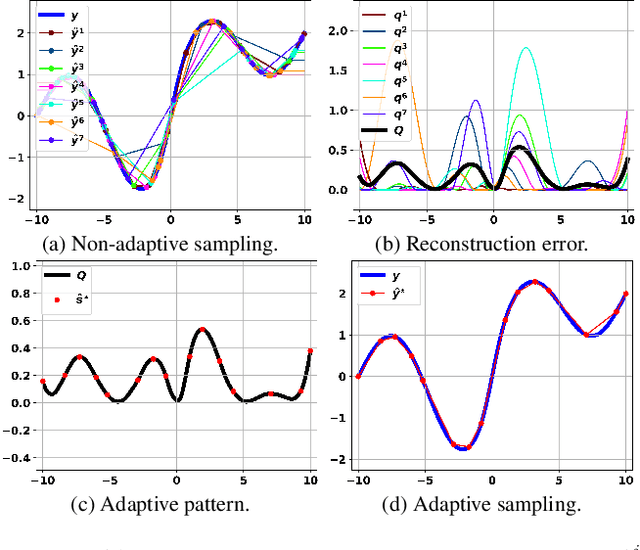

Recent advances in depth sensing technologies allow fast electronic maneuvering of the laser beam, as opposed to fixed mechanical rotations. This will enable future sensors, in principle, to vary in real-time the sampling pattern. We examine here the abstract problem of whether adapting the sampling pattern for a given frame can reduce the reconstruction error or allow a sparser pattern. We propose a constructive generic method to guide adaptive depth sampling algorithms. Given a sampling budget B, a depth predictor P and a desired quality measure M, we propose an Importance Map that highlights important sampling locations. This map is defined for a given frame as the per-pixel expected value of M produced by the predictor P, given a pattern of B random samples. This map can be well estimated in a training phase. We show that a neural network can learn to produce a highly faithful Importance Map, given an RGB image. We then suggest an algorithm to produce a sampling pattern for the scene, which is denser in regions that are harder to reconstruct. The sampling strategy of our modular framework can be adjusted according to hardware limitations, type of depth predictor, and any custom reconstruction error measure that should be minimized. We validate through simulations that our approach outperforms grid and random sampling patterns as well as recent state-of-the-art adaptive algorithms.
Networked Sensing with AI-Empowered Environment Estimation: Exploiting Macro-Diversity and Array Gain in Perceptive Mobile Networks
May 23, 2022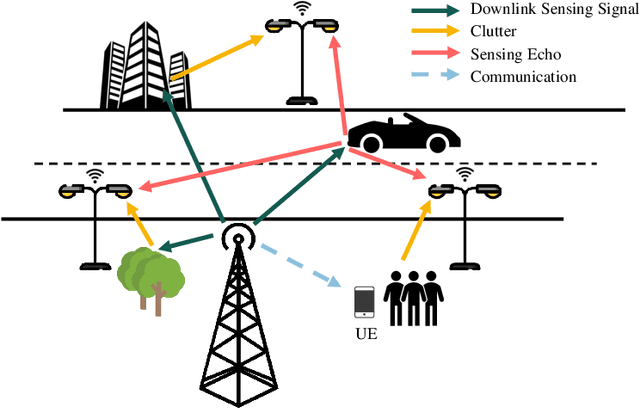
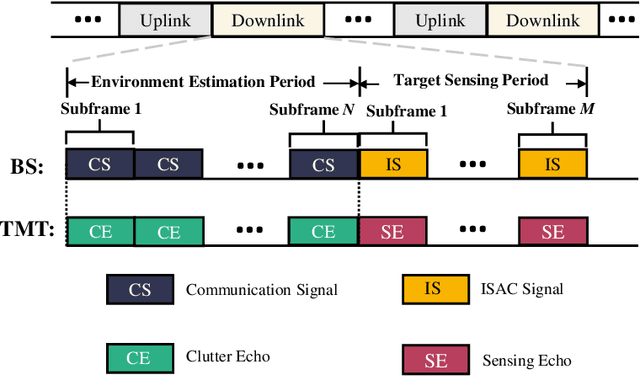
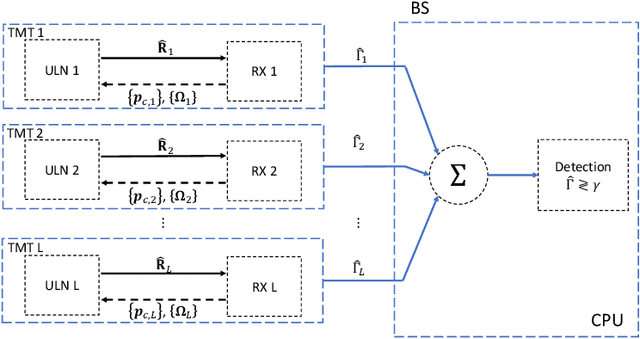
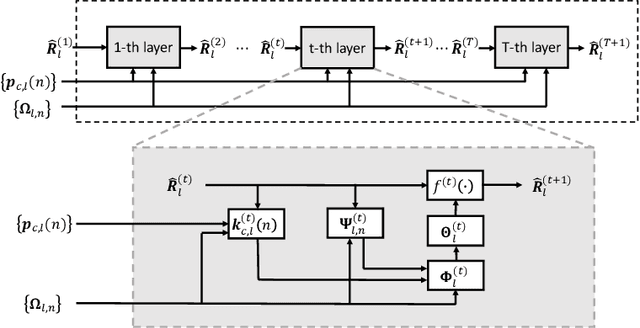
Sensing will be an important service for future wireless networks to assist innovative applications like autonomous driving and environment monitoring. This paper considers the design of perceptive mobile networks (PMNs) where target monitoring terminals (TMTs) are deployed over the traditional cellular networks for jointly sensing the targets in the presence of environment clutter. Different from traditional radar, the cellular structure of PMNs offers multiple perspectives for target sensing (TS), but the joint processing among distributed sensing nodes also causes heavy computation and communication workload over the network. In this paper, we first propose a two-stage protocol where communication signals are utilized for environment estimation (EE) and TS in two consecutive time periods, respectively. A \textit{networked} sensing detector is then derived to exploit the perspectives provided by multiple TMTs for sensing the same target. The macro-diversity from multiple TMTs and the array gain from multiple receive antennas at each TMT are analyzed to reveal the benefit of networked sensing. Furthermore, we derive the sufficient condition that one TMT's contribution to the networked sensing is positive, based on which a TMT selection algorithm is proposed. To reduce the computation burden and efficiently estimate the environment, we propose a model-driven deep-learning algorithm that utilizes partially-sampled data for EE. Simulation results confirm the benefits of networked sensing and validate the higher efficiency of the proposed EE algorithm than existing methods.
High-Cardinality Geometrical Constellation Shaping for the Nonlinear Fibre Channel
May 09, 2022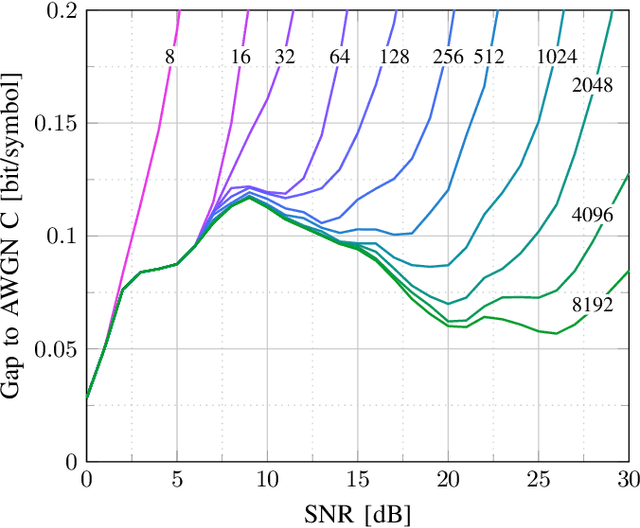
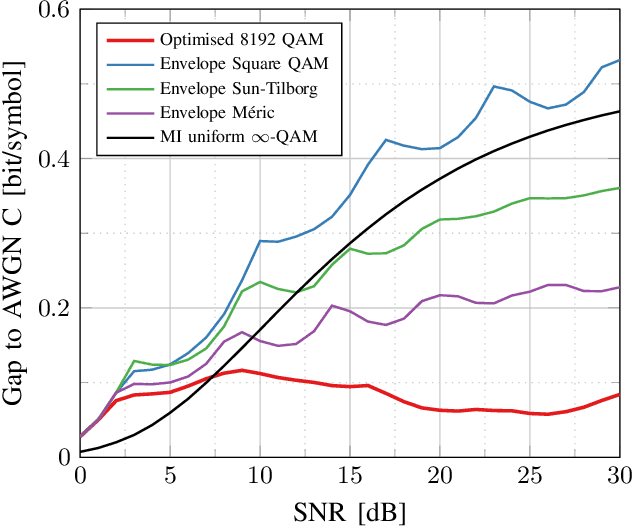
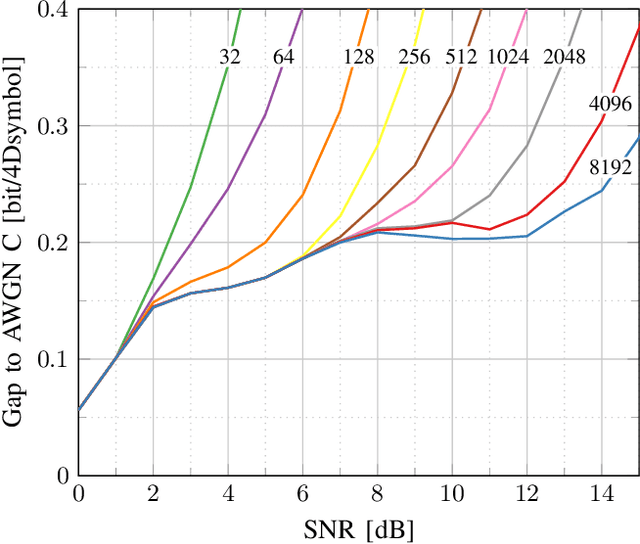
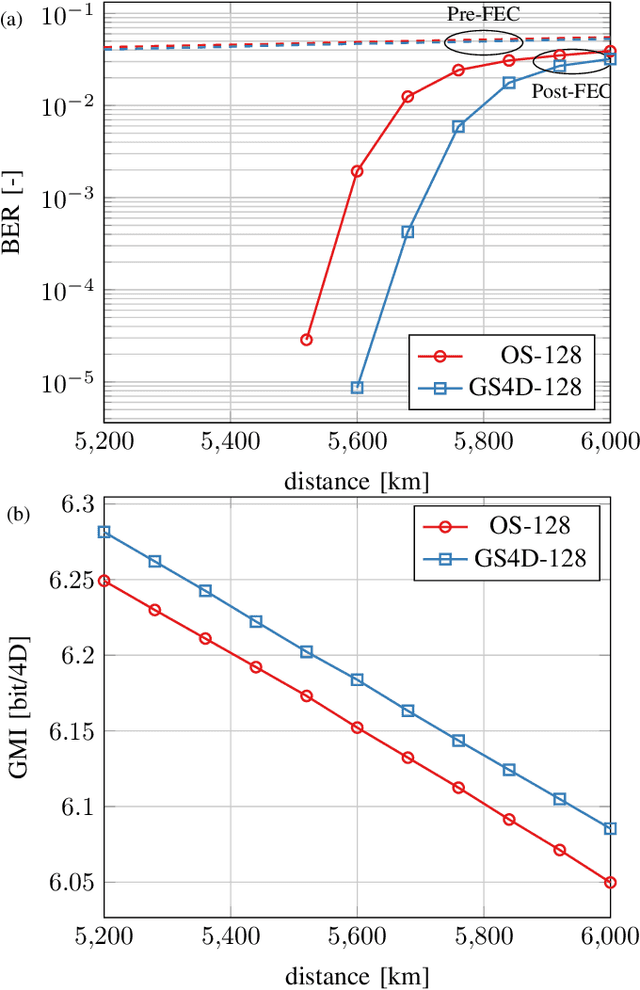
This paper presents design methods for highly efficient optimisation of geometrically shaped constellations to maximise data throughput in optical communications. It describes methods to analytically calculate the information-theoretical loss and the gradient of this loss as a function of the input constellation shape. The gradients of the \ac{MI} and \ac{GMI} are critical to the optimisation of geometrically-shaped constellations. It presents the analytical derivative of the achievable information rate metrics with respect to the input constellation. The proposed method allows for improved design of higher cardinality and higher-dimensional constellations for optimising both linear and nonlinear fibre transmission throughput. Near-capacity achieving constellations with up to 8192 points for both 2 and 4 dimensions, with generalised mutual information (GMI) within 0.06 bit/2Dsymbol of additive white Gaussian noise channel (AWGN) capacity, are presented. Additionally, a design algorithm reducing the design computation time from days to minutes is introduced, allowing the presentation of optimised constellations for both linear AWGN and nonlinear fibre channels for a wide range of signal-to-noise ratios.
The Devil is in the Details: On the Pitfalls of Vocabulary Selection in Neural Machine Translation
May 13, 2022
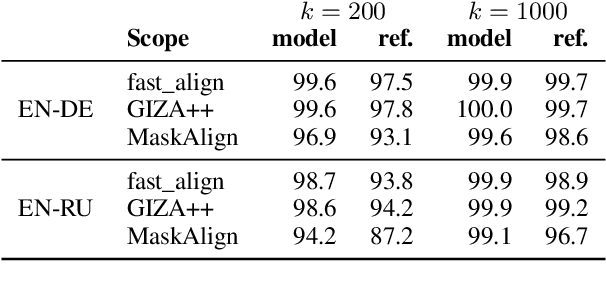
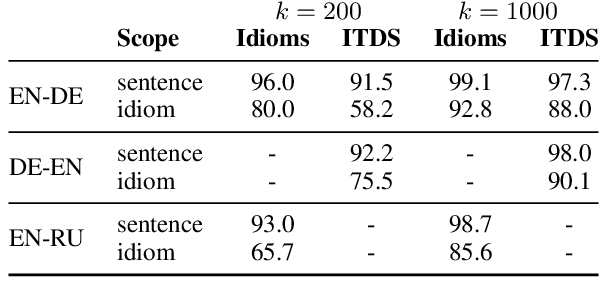
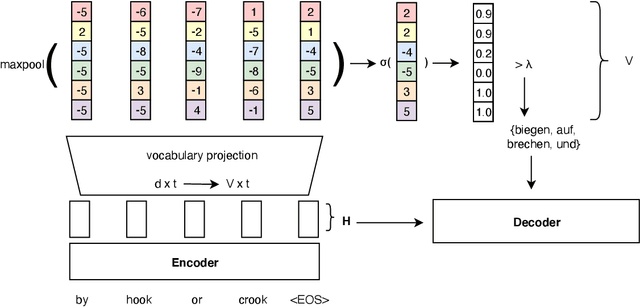
Vocabulary selection, or lexical shortlisting, is a well-known technique to improve latency of Neural Machine Translation models by constraining the set of allowed output words during inference. The chosen set is typically determined by separately trained alignment model parameters, independent of the source-sentence context at inference time. While vocabulary selection appears competitive with respect to automatic quality metrics in prior work, we show that it can fail to select the right set of output words, particularly for semantically non-compositional linguistic phenomena such as idiomatic expressions, leading to reduced translation quality as perceived by humans. Trading off latency for quality by increasing the size of the allowed set is often not an option in real-world scenarios. We propose a model of vocabulary selection, integrated into the neural translation model, that predicts the set of allowed output words from contextualized encoder representations. This restores translation quality of an unconstrained system, as measured by human evaluations on WMT newstest2020 and idiomatic expressions, at an inference latency competitive with alignment-based selection using aggressive thresholds, thereby removing the dependency on separately trained alignment models.
RD-Optimized Trit-Plane Coding of Deep Compressed Image Latent Tensors
Mar 25, 2022
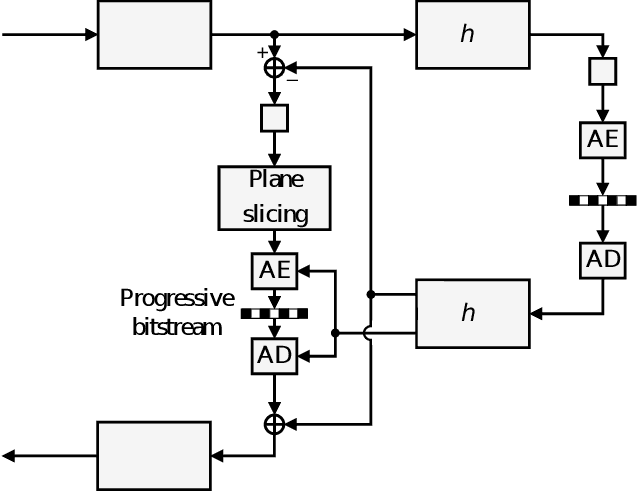
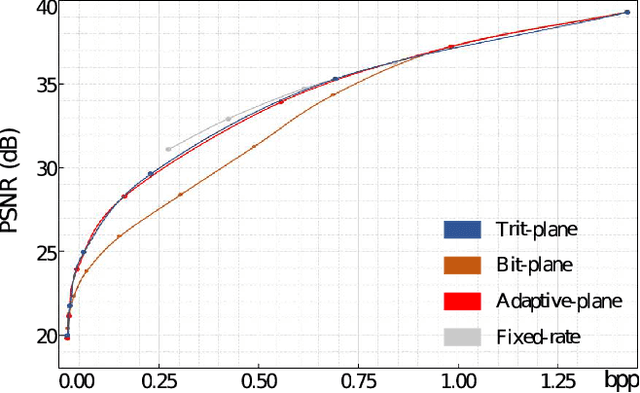

DPICT is the first learning-based image codec supporting fine granular scalability. In this paper, we describe how to implement two key components of DPICT efficiently: trit-plane slicing and RD-prioritized transmission. In DPICT, we transform an image into a latent tensor, represent the tensor in ternary digits (trits), and encode the trits in the decreasing order of significance. For entropy encoding, we should compute the probability of each trit, which demands high time complexity in both the encoder and the decoder. To reduce the complexity, we develop a parallel computing scheme for the probabilities and describe it in detail with pseudo-codes. Moreover, in this paper, we compare the trit-plane slicing in DPICT with the alternative bit-plane slicing. Experimental results show that the time complexity is reduced significantly by the parallel computing and that the trit-plane slicing provides better rate-distortion performances than the bit-plane slicing.
M2R2: Missing-Modality Robust emotion Recognition framework with iterative data augmentation
May 05, 2022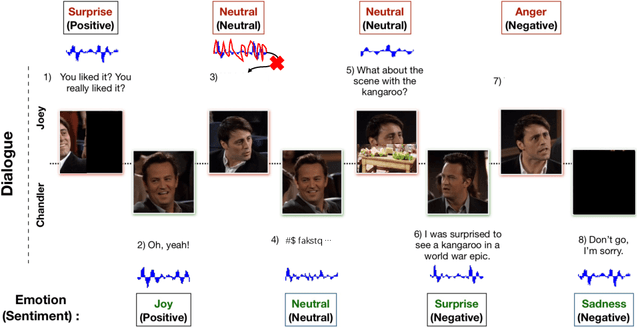
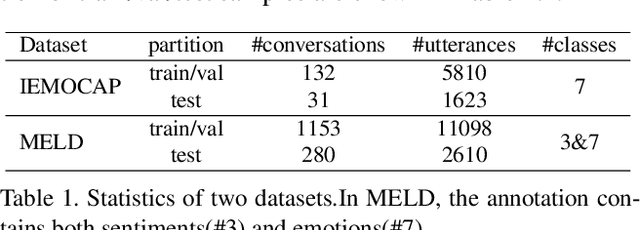
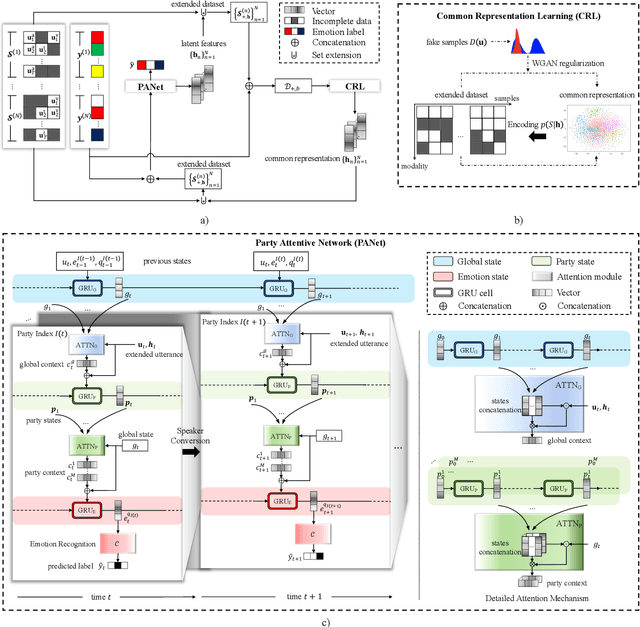
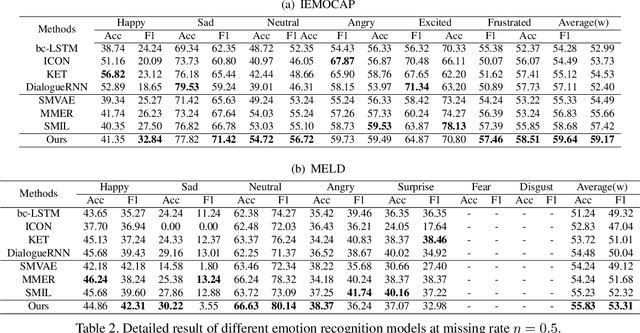
This paper deals with the utterance-level modalities missing problem with uncertain patterns on emotion recognition in conversation (ERC) task. Present models generally predict the speaker's emotions by its current utterance and context, which is degraded by modality missing considerably. Our work proposes a framework Missing-Modality Robust emotion Recognition (M2R2), which trains emotion recognition model with iterative data augmentation by learned common representation. Firstly, a network called Party Attentive Network (PANet) is designed to classify emotions, which tracks all the speakers' states and context. Attention mechanism between speaker with other participants and dialogue topic is used to decentralize dependence on multi-time and multi-party utterances instead of the possible incomplete one. Moreover, the Common Representation Learning (CRL) problem is defined for modality-missing problem. Data imputation methods improved by the adversarial strategy are used here to construct extra features to augment data. Extensive experiments and case studies validate the effectiveness of our methods over baselines for modality-missing emotion recognition on two different datasets.