 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DELMAR: Deep Linear Matrix Approximately Reconstruction to Extract Hierarchical Functional Connectivity in the Human Brain
May 20, 2022
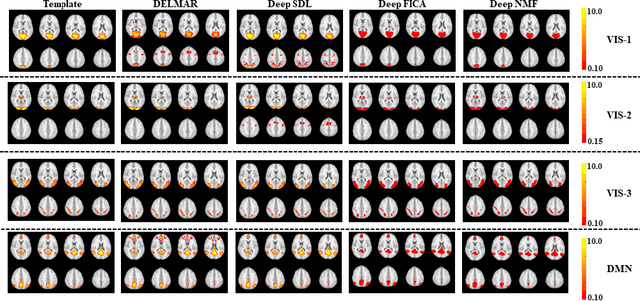
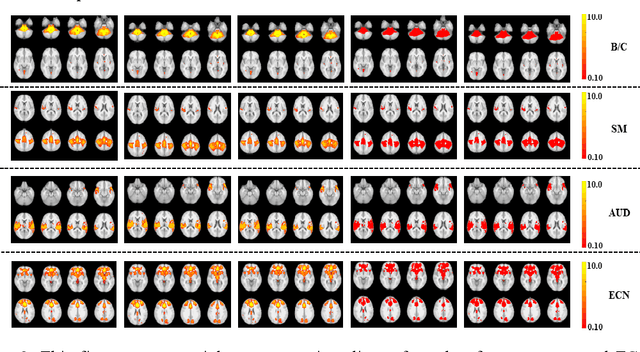
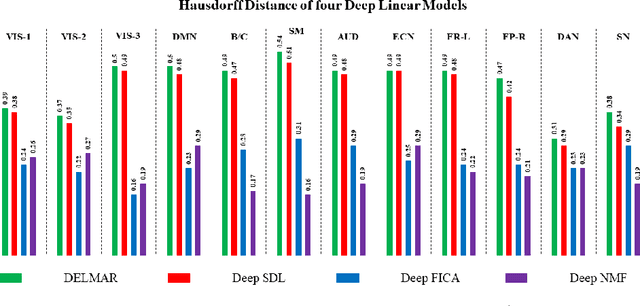

The Matrix Decomposition techniques have been a vital computational approach to analyzing the hierarchy of functional connectivity in the human brain. However, there are still four shortcomings of these methodologies: 1). Large training samples; 2). Manually tuning hyperparameters; 3). Time-consuming and require extensive computational source; 4). It cannot guarantee convergence to a unique fixed point. Therefore, we propose a novel deep matrix factorization technique called Deep Linear Matrix Approximate Reconstruction (DELMAR) to bridge the abovementioned gaps. The advantages of the proposed method are: at first, proposed DELMAR can estimate the important hyperparameters automatically; furthermore, DELMAR employs the matrix backpropagation to reduce the potential accumulative errors; finally, an orthogonal projection is introduced to update all variables of DELMAR rather than directly calculating the inverse matrices. The validation experiments of three peer methods and DELMAR using real functional MRI signal of the human brain demonstrates that our proposed method can efficiently identify the spatial feature in fMRI signal even faster and more accurately than other peer methods. Moreover, the theoretical analyses indicate that DELMAR can converge to the unique fixed point and even enable the accurate approximation of original input as DNNs.
Delving into High-Quality Synthetic Face Occlusion Segmentation Datasets
May 12, 2022


This paper performs comprehensive analysis on datasets for occlusion-aware face segmentation, a task that is crucial for many downstream applications. The collection and annotation of such datasets are time-consuming and labor-intensive. Although some efforts have been made in synthetic data generation, the naturalistic aspect of data remains less explored. In our study, we propose two occlusion generation techniques, Naturalistic Occlusion Generation (NatOcc), for producing high-quality naturalistic synthetic occluded faces; and Random Occlusion Generation (RandOcc), a more general synthetic occluded data generation method. We empirically show the effectiveness and robustness of both methods, even for unseen occlusions. To facilitate model evaluation, we present two high-resolution real-world occluded face datasets with fine-grained annotations, RealOcc and RealOcc-Wild, featuring both careful alignment preprocessing and an in-the-wild setting for robustness test. We further conduct a comprehensive analysis on a newly introduced segmentation benchmark, offering insights for future exploration.
FLICU: A Federated Learning Workflow for Intensive Care Unit Mortality Prediction
May 30, 2022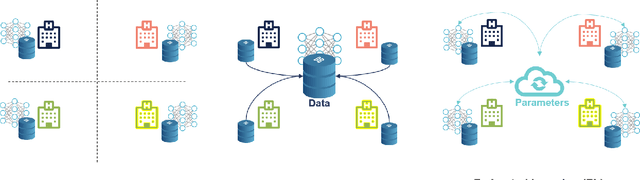
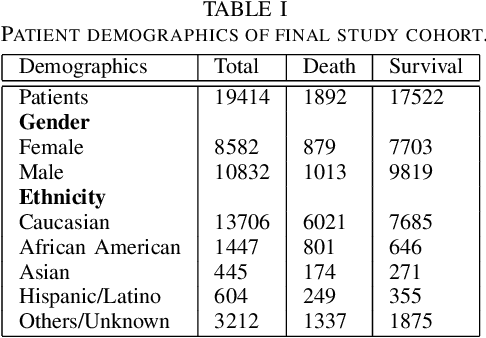
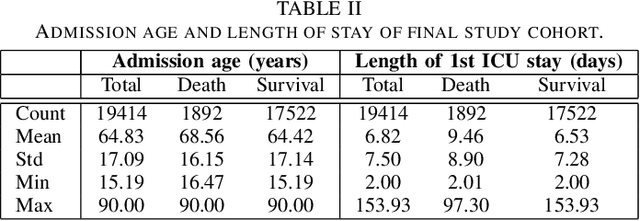
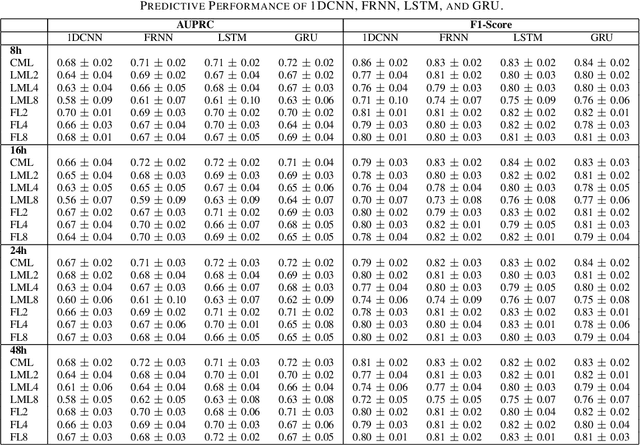
Although Machine Learning (ML) can be seen as a promising tool to improve clinical decision-making for supporting the improvement of medication plans, clinical procedures, diagnoses, or medication prescriptions, it remains limited by access to healthcare data. Healthcare data is sensitive, requiring strict privacy practices, and typically stored in data silos, making traditional machine learning challenging. Federated learning can counteract those limitations by training machine learning models over data silos while keeping the sensitive data localized. This study proposes a federated learning workflow for ICU mortality prediction. Hereby, the applicability of federated learning as an alternative to centralized machine learning and local machine learning is investigated by introducing federated learning to the binary classification problem of predicting ICU mortality. We extract multivariate time series data from the MIMIC-III database (lab values and vital signs), and benchmark the predictive performance of four deep sequential classifiers (FRNN, LSTM, GRU, and 1DCNN) varying the patient history window lengths (8h, 16h, 24h, 48h) and the number of FL clients (2, 4, 8). The experiments demonstrate that both centralized machine learning and federated learning are comparable in terms of AUPRC and F1-score. Furthermore, the federated approach shows superior performance over local machine learning. Thus, the federated approach can be seen as a valid and privacy-preserving alternative to centralized machine learning for classifying ICU mortality when sharing sensitive patient data between hospitals is not possible.
Face Detection on Mobile: Five Implementations and Analysis
May 12, 2022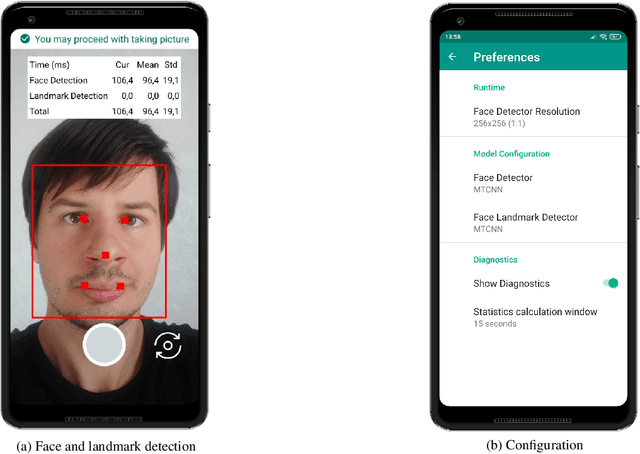
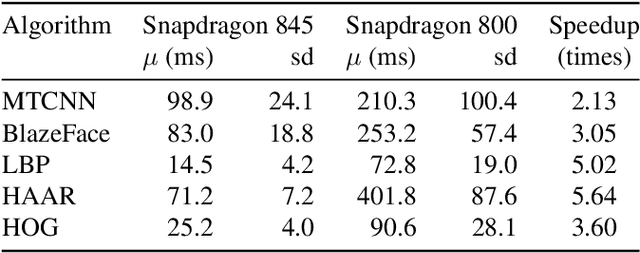
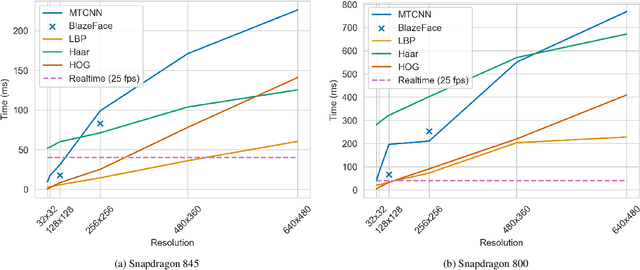
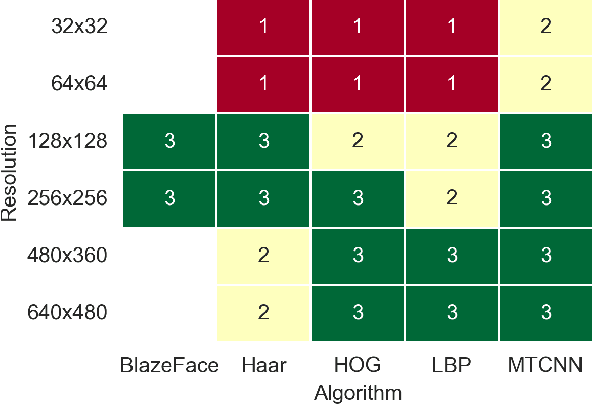
In many practical cases face detection on smartphones or other highly portable devices is a necessity. Applications include mobile face access control systems, driver status tracking, emotion recognition, etc. Mobile devices have limited processing power and should have long-enough battery life even with face detection application running. Thus, striking the right balance between algorithm quality and complexity is crucial. In this work we adapt 5 algorithms to mobile. These algorithms are based on handcrafted or neural-network-based features and include: Viola-Jones (Haar cascade), LBP, HOG, MTCNN, BlazeFace. We analyze inference time of these algorithms on different devices with different input image resolutions. We provide guidance, which algorithms are the best fit for mobile face access control systems and potentially other mobile applications. Interestingly, we note that cascaded algorithms perform faster on scenes without faces, while BlazeFace is slower on empty scenes. Exploiting this behavior might be useful in practice.
Merging of neural networks
Apr 21, 2022
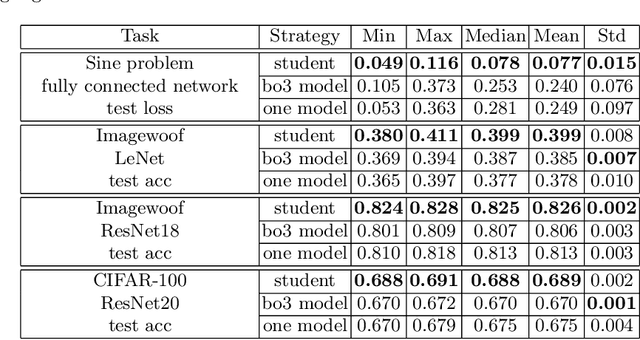


We propose a simple scheme for merging two neural networks trained with different starting initialization into a single one with the same size as the original ones. We do this by carefully selecting channels from each input network. Our procedure might be used as a finalization step after one tries multiple starting seeds to avoid an unlucky one. We also show that training two networks and merging them leads to better performance than training a single network for an extended period of time. Availability: https://github.com/fmfi-compbio/neural-network-merging
Time-Ordered Recent Event (TORE) Volumes for Event Cameras
Mar 10, 2021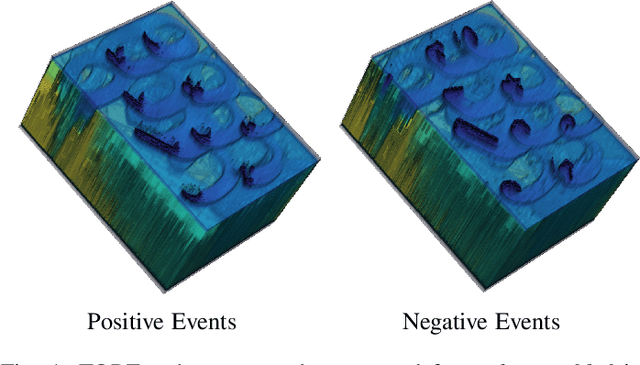

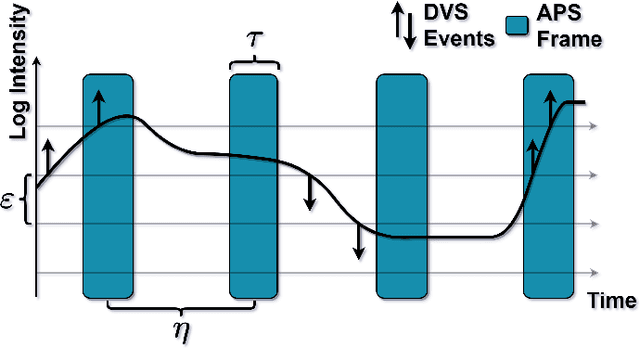
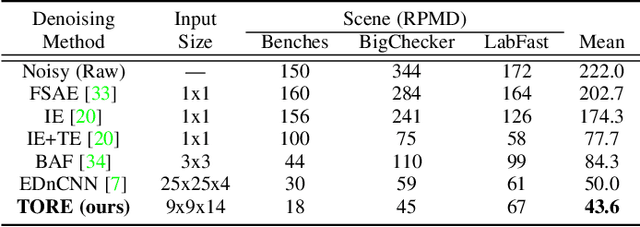
Event cameras are an exciting, new sensor modality enabling high-speed imaging with extremely low-latency and wide dynamic range. Unfortunately, most machine learning architectures are not designed to directly handle sparse data, like that generated from event cameras. Many state-of-the-art algorithms for event cameras rely on interpolated event representations - obscuring crucial timing information, increasing the data volume, and limiting overall network performance. This paper details an event representation called Time-Ordered Recent Event (TORE) volumes. TORE volumes are designed to compactly store raw spike timing information with minimal information loss. This bio-inspired design is memory efficient, computationally fast, avoids time-blocking (i.e. fixed and predefined frame rates), and contains "local memory" from past data. The design is evaluated on a wide range of challenging tasks (e.g. event denoising, image reconstruction, classification, and human pose estimation) and is shown to dramatically improve state-of-the-art performance. TORE volumes are an easy-to-implement replacement for any algorithm currently utilizing event representations.
On the Decentralization of Blockchain-enabled Asynchronous Federated Learning
May 20, 2022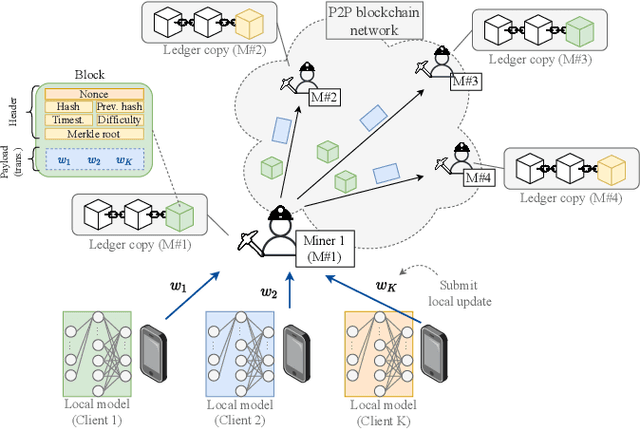
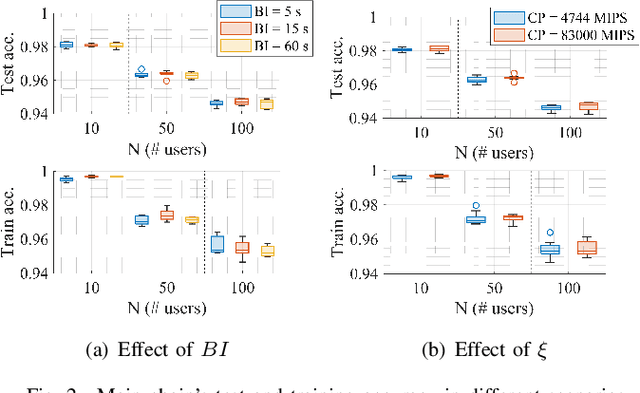
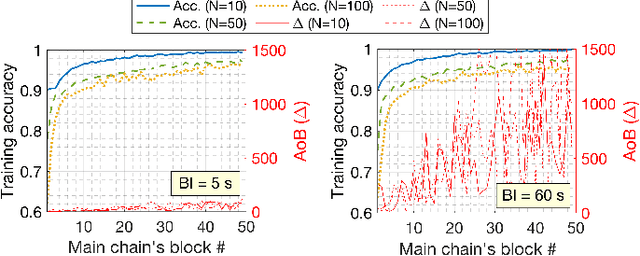
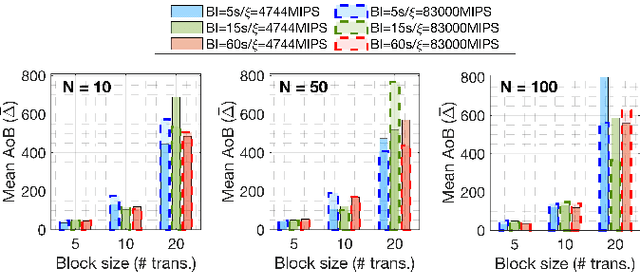
Federated learning (FL), thanks in part to the emergence of the edge computing paradigm, is expected to enable true real-time applications in production environments. However, its original dependence on a central server for orchestration raises several concerns in terms of security, privacy, and scalability. To solve some of these worries, blockchain technology is expected to bring decentralization, robustness, and enhanced trust to FL. The empowerment of FL through blockchain (also referred to as FLchain), however, has some implications in terms of ledger inconsistencies and age of information (AoI), which are naturally inherited from the blockchain's fully decentralized operation. Such issues stem from the fact that, given the temporary ledger versions in the blockchain, FL devices may use different models for training, and that, given the asynchronicity of the FL operation, stale local updates (computed using outdated models) may be generated. In this paper, we shed light on the implications of the FLchain setting and study the effect that both the AoI and ledger inconsistencies have on the FL performance. To that end, we provide a faithful simulation tool that allows capturing the decentralized and asynchronous nature of the FLchain operation.
Trends in Workplace Wearable Technologies and Connected-Worker Solutions for Next-Generation Occupational Safety, Health, and Productivity
May 24, 2022The workplace influences the safety, health, and productivity of workers at multiple levels. To protect and promote total worker health, smart hardware, and software tools have emerged for the identification, elimination, substitution, and control of occupational hazards. Wearable devices enable constant monitoring of individual workers and the environment, whereas connected worker solutions provide contextual information and decision support. Here, the recent trends in commercial workplace technologies to monitor and manage occupational risks, injuries, accidents, and diseases are reviewed. Workplace safety wearables for safe lifting, ergonomics, hazard identification, sleep monitoring, fatigue management, and heat and cold stress are discussed. Examples of workplace productivity wearables for asset tracking, augmented reality, gesture and motion control, brain wave sensing, and work stress management are given. Workplace health wearables designed for work-related musculoskeletal disorders, functional movement disorders, respiratory hazards, cardiovascular health, outdoor sun exposure, and continuous glucose monitoring are shown. Connected worker platforms are discussed with information about the architecture, system modules, intelligent operations, and industry applications. Predictive analytics provide contextual information about occupational safety risks, resource allocation, equipment failure, and predictive maintenance. Altogether, these examples highlight the ground-level benefits of real-time visibility about frontline workers, work environment, distributed assets, workforce efficiency, and safety compliance
Unsupervised Flow-Aligned Sequence-to-Sequence Learning for Video Restoration
May 20, 2022
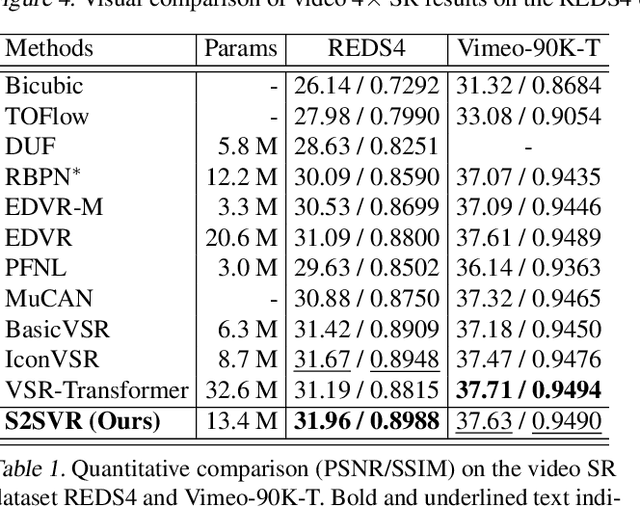
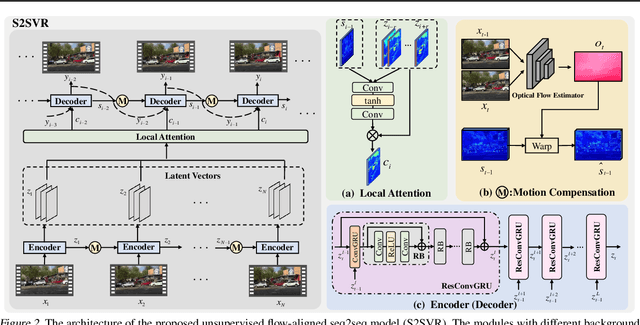
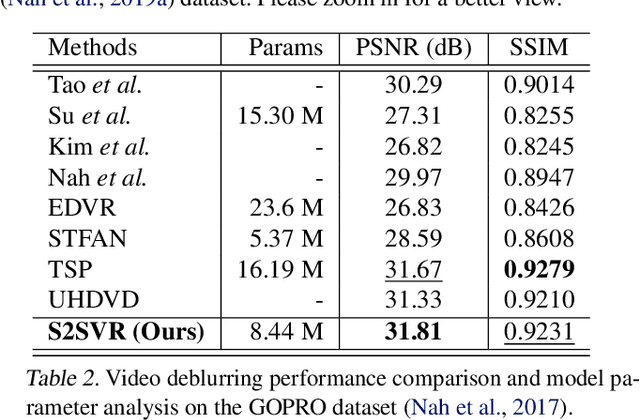
How to properly model the inter-frame relation within the video sequence is an important but unsolved challenge for video restoration (VR). In this work, we propose an unsupervised flow-aligned sequence-to-sequence model (S2SVR) to address this problem. On the one hand, the sequence-to-sequence model, which has proven capable of sequence modeling in the field of natural language processing, is explored for the first time in VR. Optimized serialization modeling shows potential in capturing long-range dependencies among frames. On the other hand, we equip the sequence-to-sequence model with an unsupervised optical flow estimator to maximize its potential. The flow estimator is trained with our proposed unsupervised distillation loss, which can alleviate the data discrepancy and inaccurate degraded optical flow issues of previous flow-based methods. With reliable optical flow, we can establish accurate correspondence among multiple frames, narrowing the domain difference between 1D language and 2D misaligned frames and improving the potential of the sequence-to-sequence model. S2SVR shows superior performance in multiple VR tasks, including video deblurring, video super-resolution, and compressed video quality enhancement. Code and models are publicly available at https://github.com/linjing7/VR-Baseline
Time series classification for predictive maintenance on event logs
Nov 22, 2020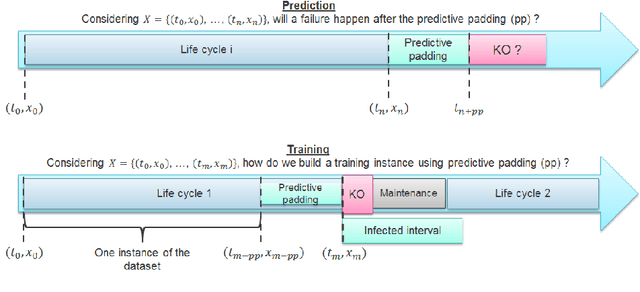
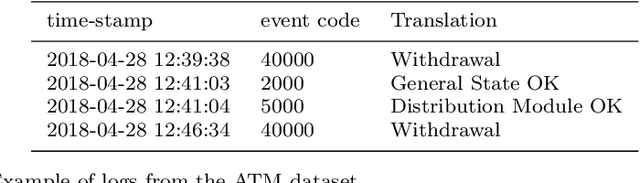
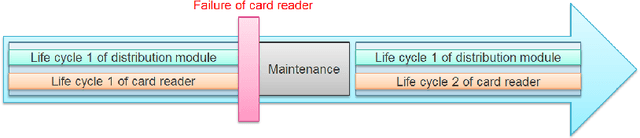
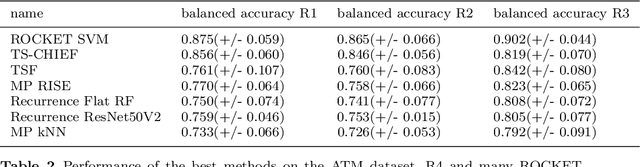
Time series classification (TSC) gained a lot of attention in the pastdecade and number of methods for representing and classifying time series havebeen proposed. Nowadays, methods based on convolutional networks and ensembletechniques represent the state of the art for time series classification. Techniquestransforming time series to image or text also provide reliable ways to extractmeaningful features or representations of time series. We compare the state-of-the-art representation and classification methods on a specific application, thatis predictive maintenance from sequences of event logs. The contributions of thispaper are twofold: introducing a new data set for predictive maintenance on auto-mated teller machines (ATMs) log data and comparing the performance of differentrepresentation methods for predicting the occurrence of a breakdown. The prob-lem is difficult since unlike the classic case of predictive maintenance via signalsfrom sensors, we have sequences of discrete event logs occurring at any time andthe lengths of the sequences, corresponding to life cycles, vary a lot.