 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Forecasting Solar Power Generation on the basis of Predictive and Corrective Maintenance Activities
May 17, 2022
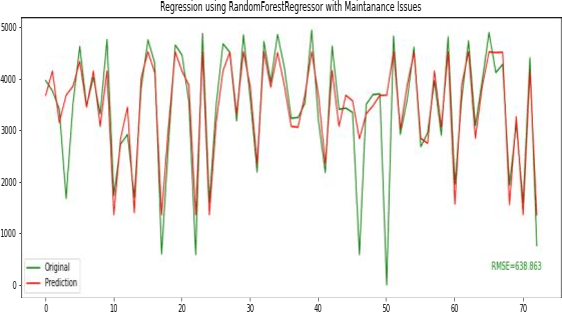

Solar energy forecasting has seen tremendous growth in the last decade using historical time series collected from a weather station, such as weather variables wind speed and direction, solar radiance, and temperature. It helps in the overall management of solar power plants. However, the solar power plant regularly requires preventive and corrective maintenance activities that further impact energy production. This paper presents a novel work for forecasting solar power energy production based on maintenance activities, problems observed at a power plant, and weather data. The results accomplished on the datasets obtained from the 1MW solar power plant of PDEU (our university) that has generated data set with 13 columns as daily entries from 2012 to 2020. There are 12 structured columns and one unstructured column with manual text entries about different maintenance activities, problems observed, and weather conditions daily. The unstructured column is used to create a new feature column vector using Hash Map, flag words, and stop words. The final dataset comprises five important feature vector columns based on correlation and causality analysis.
Towards a Real-time Measure of the Perception of Anthropomorphism in Human-robot Interaction
Jan 24, 2022
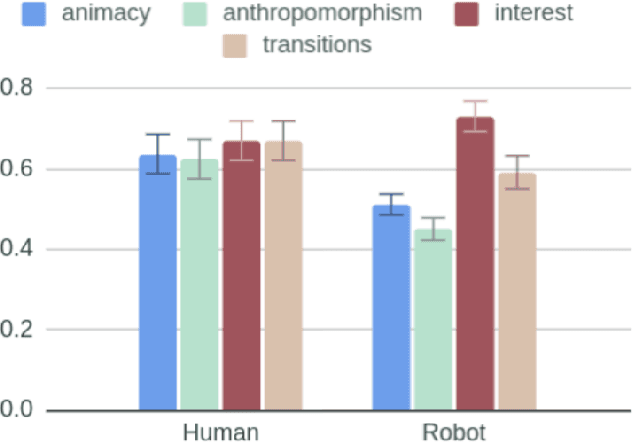
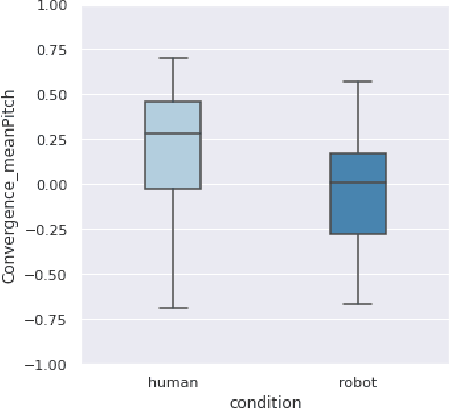
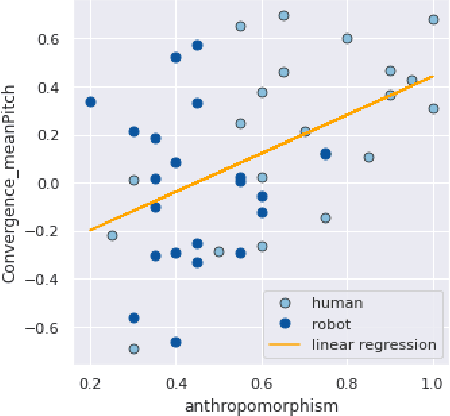
How human-like do conversational robots need to look to enable long-term human-robot conversation? One essential aspect of long-term interaction is a human's ability to adapt to the varying degrees of a conversational partner's engagement and emotions. Prosodically, this can be achieved through (dis)entrainment. While speech-synthesis has been a limiting factor for many years, restrictions in this regard are increasingly mitigated. These advancements now emphasise the importance of studying the effect of robot embodiment on human entrainment. In this study, we conducted a between-subjects online human-robot interaction experiment in an educational use-case scenario where a tutor was either embodied through a human or a robot face. 43 English-speaking participants took part in the study for whom we analysed the degree of acoustic-prosodic entrainment to the human or robot face, respectively. We found that the degree of subjective and objective perception of anthropomorphism positively correlates with acoustic-prosodic entrainment.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 24, 2022
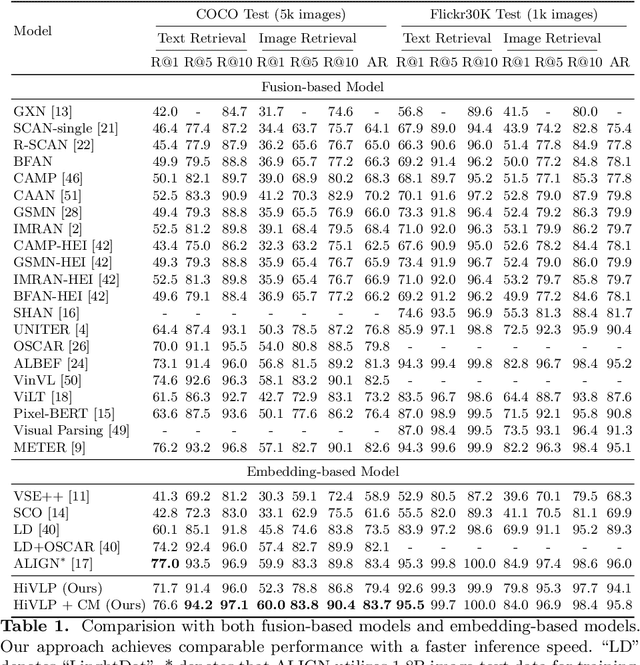
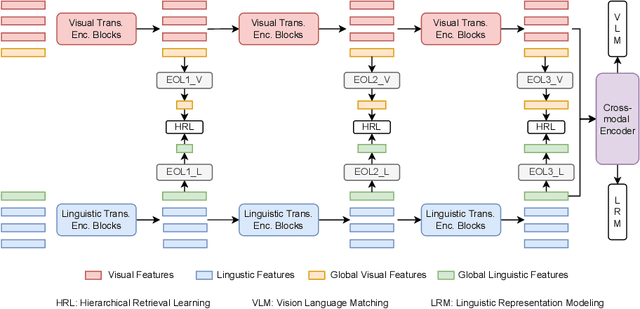
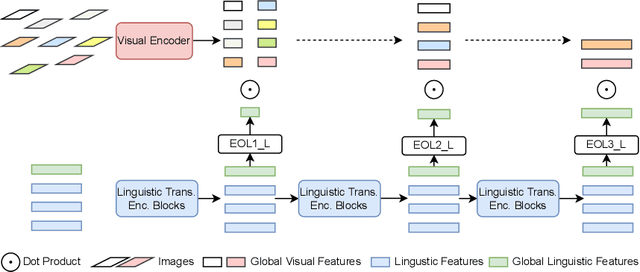
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
Bang-Bang Control Of A Tail-less Morphing Wing Flight
May 12, 2022
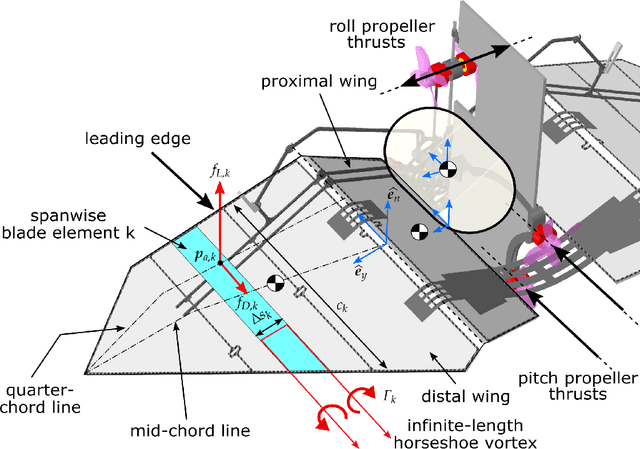
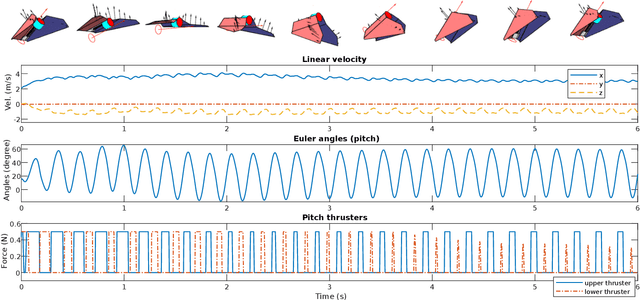

Bats' dynamic morphing wings are known to be extremely high-dimensional, and they employ the combination of inertial dynamics and aerodynamics manipulations to showcase extremely agile maneuvers. Bats heavily rely on their highly flexible wings and are capable of dynamically morphing their wings to adjust aerodynamic and inertial forces applied to their wing and perform sharp banking turns. There are technical hardware and control challenges in copying the morphing wing flight capabilities of flying animals. This work is majorly focused on the modeling and control aspects of stable, tail-less, morphing wing flight. A classical control approach using bang-bang control is proposed to stabilize a bio-inspired morphing wing robot called Aerobat. Robot-environment interactions based on horseshoe vortex shedding and Wagner functions is derived to realistically evaluate the feasibility of the bang-bang control, which is then implemented on the robot in experiments to demonstrate first-time closed-loop stable flights of Aerobat.
Time-Ordered Recent Event (TORE) Volumes for Event Cameras
Mar 10, 2021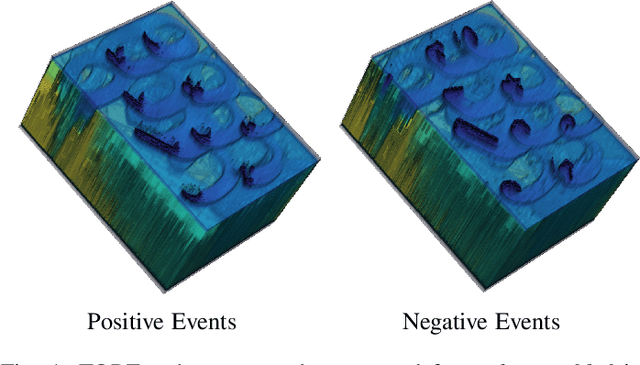

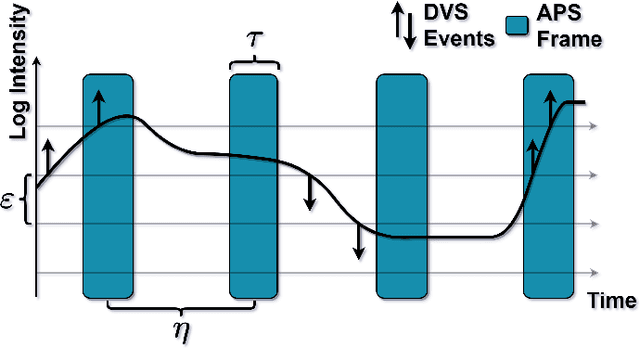
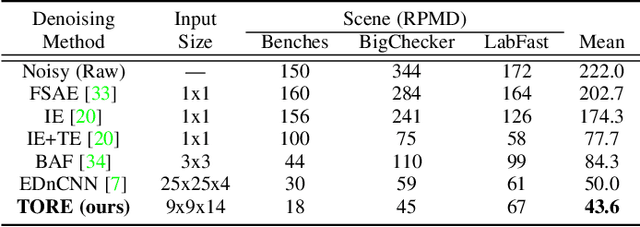
Event cameras are an exciting, new sensor modality enabling high-speed imaging with extremely low-latency and wide dynamic range. Unfortunately, most machine learning architectures are not designed to directly handle sparse data, like that generated from event cameras. Many state-of-the-art algorithms for event cameras rely on interpolated event representations - obscuring crucial timing information, increasing the data volume, and limiting overall network performance. This paper details an event representation called Time-Ordered Recent Event (TORE) volumes. TORE volumes are designed to compactly store raw spike timing information with minimal information loss. This bio-inspired design is memory efficient, computationally fast, avoids time-blocking (i.e. fixed and predefined frame rates), and contains "local memory" from past data. The design is evaluated on a wide range of challenging tasks (e.g. event denoising, image reconstruction, classification, and human pose estimation) and is shown to dramatically improve state-of-the-art performance. TORE volumes are an easy-to-implement replacement for any algorithm currently utilizing event representations.
Exploring the combination of deep-learning based direct segmentation and deformable image registration for cone-beam CT based auto-segmentation for adaptive radiotherapy
Jun 07, 2022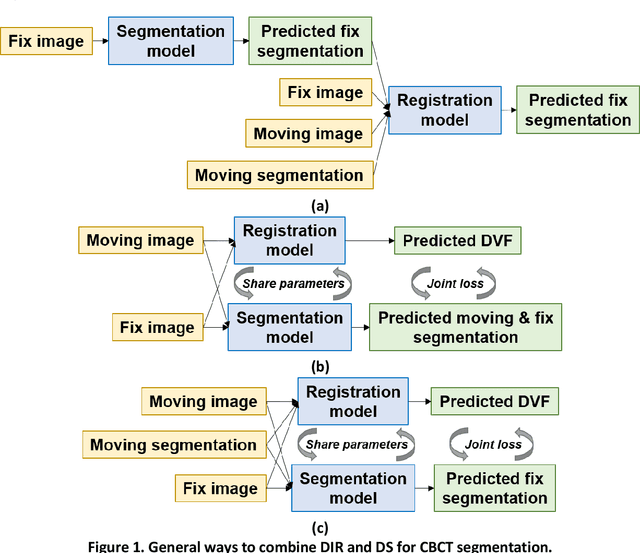
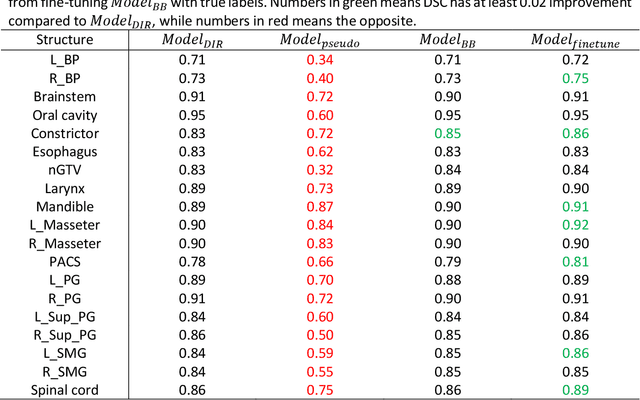
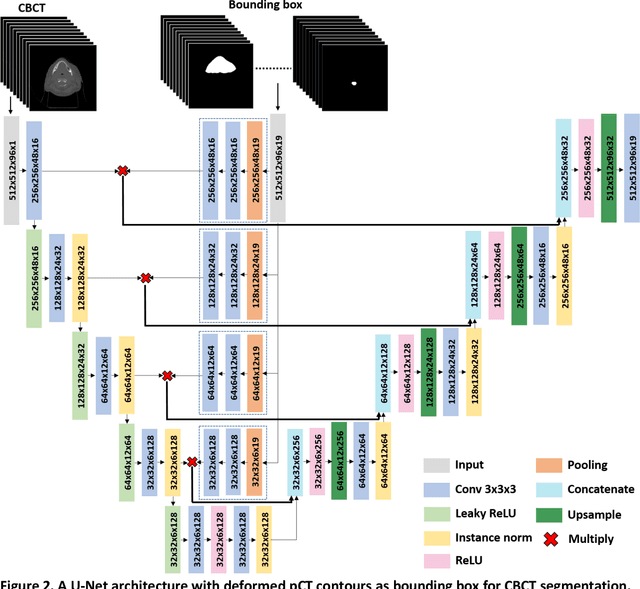
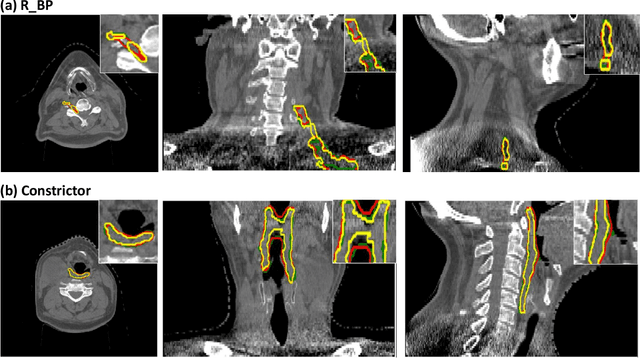
CBCT-based online adaptive radiotherapy (ART) calls for accurate auto-segmentation models to reduce the time cost for physicians to edit contours, since the patient is immobilized on the treatment table waiting for treatment to start. However, auto-segmentation of CBCT images is a difficult task, majorly due to low image quality and lack of true labels for training a deep learning (DL) model. Meanwhile CBCT auto-segmentation in ART is a unique task compared to other segmentation problems, where manual contours on planning CT (pCT) are available. To make use of this prior knowledge, we propose to combine deformable image registration (DIR) and direct segmentation (DS) on CBCT for head and neck patients. First, we use deformed pCT contours derived from multiple DIR methods between pCT and CBCT as pseudo labels for training. Second, we use deformed pCT contours as bounding box to constrain the region of interest for DS. Meanwhile deformed pCT contours are used as pseudo labels for training, but are generated from different DIR algorithms from bounding box. Third, we fine-tune the model with bounding box on true labels. We found that DS on CBCT trained with pseudo labels and without utilizing any prior knowledge has very poor segmentation performance compared to DIR-only segmentation. However, adding deformed pCT contours as bounding box in the DS network can dramatically improve segmentation performance, comparable to DIR-only segmentation. The DS model with bounding box can be further improved by fine-tuning it with some real labels. Experiments showed that 7 out of 19 structures have at least 0.2 dice similarity coefficient increase compared to DIR-only segmentation. Utilizing deformed pCT contours as pseudo labels for training and as bounding box for shape and location feature extraction in a DS model is a good way to combine DIR and DS.
Time series classification for predictive maintenance on event logs
Nov 22, 2020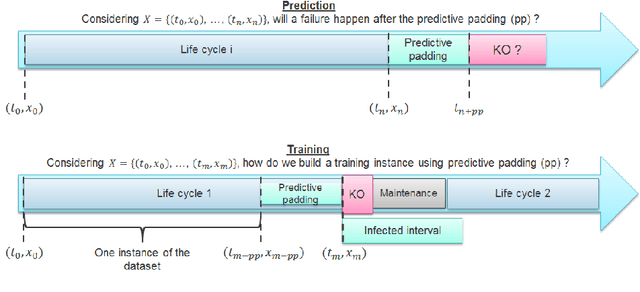
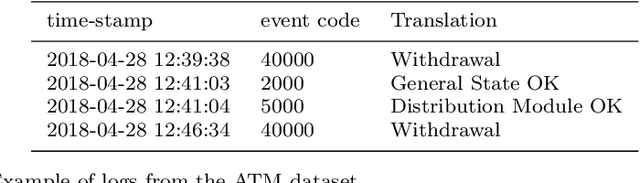
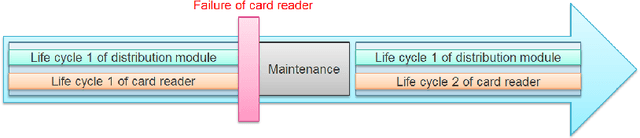
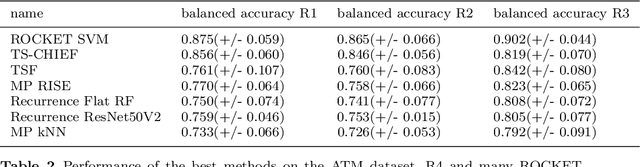
Time series classification (TSC) gained a lot of attention in the pastdecade and number of methods for representing and classifying time series havebeen proposed. Nowadays, methods based on convolutional networks and ensembletechniques represent the state of the art for time series classification. Techniquestransforming time series to image or text also provide reliable ways to extractmeaningful features or representations of time series. We compare the state-of-the-art representation and classification methods on a specific application, thatis predictive maintenance from sequences of event logs. The contributions of thispaper are twofold: introducing a new data set for predictive maintenance on auto-mated teller machines (ATMs) log data and comparing the performance of differentrepresentation methods for predicting the occurrence of a breakdown. The prob-lem is difficult since unlike the classic case of predictive maintenance via signalsfrom sensors, we have sequences of discrete event logs occurring at any time andthe lengths of the sequences, corresponding to life cycles, vary a lot.
How Human is Human Evaluation? Improving the Gold Standard for NLG with Utility Theory
May 24, 2022
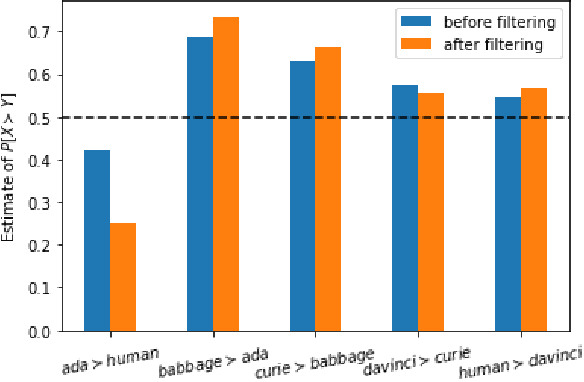

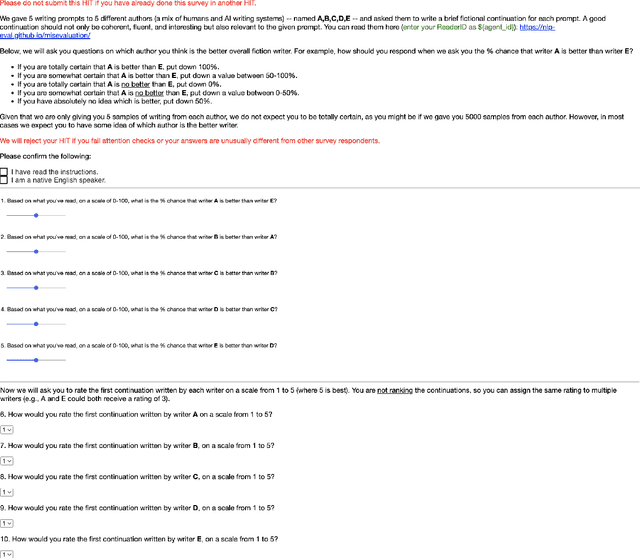
Human ratings are treated as the gold standard in NLG evaluation. The standard protocol is to collect ratings of generated text, average across annotators, and then rank NLG systems by their average scores. However, little consideration has been given as to whether this approach faithfully captures human preferences. In this work, we analyze this standard protocol through the lens of utility theory in economics. We first identify the implicit assumptions it makes about annotators and find that these assumptions are often violated in practice, in which case annotator ratings become an unfaithful reflection of their preferences. The most egregious violations come from using Likert scales, which provably reverse the direction of the true preference in certain cases. We suggest improvements to the standard protocol to make it more theoretically sound, but even in its improved form, it cannot be used to evaluate open-ended tasks like story generation. For the latter, we propose a new evaluation protocol called $\textit{system-level probabilistic assessment}$ (SPA). In our experiments, we find that according to SPA, annotators prefer larger GPT-3 variants to smaller ones -- as expected -- with all comparisons being statistically significant. In contrast, the standard protocol only yields significant results half the time.
Residual Q-Networks for Value Function Factorizing in Multi-Agent Reinforcement Learning
May 30, 2022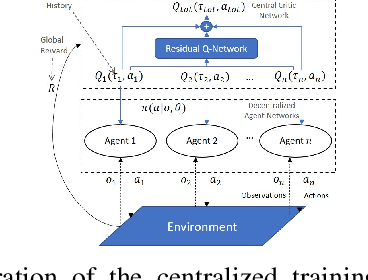
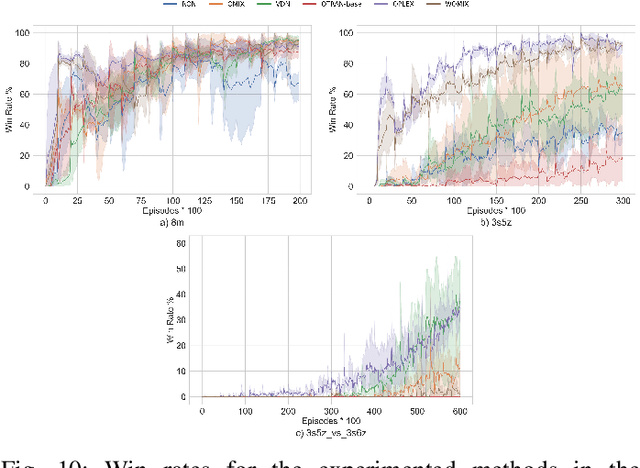
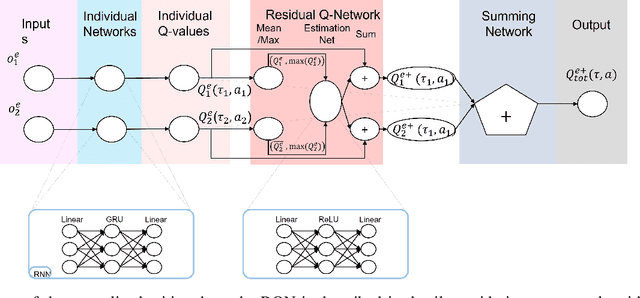
Multi-Agent Reinforcement Learning (MARL) is useful in many problems that require the cooperation and coordination of multiple agents. Learning optimal policies using reinforcement learning in a multi-agent setting can be very difficult as the number of agents increases. Recent solutions such as Value Decomposition Networks (VDN), QMIX, QTRAN and QPLEX adhere to the centralized training and decentralized execution scheme and perform factorization of the joint action-value functions. However, these methods still suffer from increased environmental complexity, and at times fail to converge in a stable manner. We propose a novel concept of Residual Q-Networks (RQNs) for MARL, which learns to transform the individual Q-value trajectories in a way that preserves the Individual-Global-Max criteria (IGM), but is more robust in factorizing action-value functions. The RQN acts as an auxiliary network that accelerates convergence and will become obsolete as the agents reach the training objectives. The performance of the proposed method is compared against several state-of-the-art techniques such as QPLEX, QMIX, QTRAN and VDN, in a range of multi-agent cooperative tasks. The results illustrate that the proposed method, in general, converges faster, with increased stability and shows robust performance in a wider family of environments. The improvements in results are more prominent in environments with severe punishments for non-cooperative behaviours and especially in the absence of complete state information during training time.
Inference for Interpretable Machine Learning: Fast, Model-Agnostic Confidence Intervals for Feature Importance
Jun 05, 2022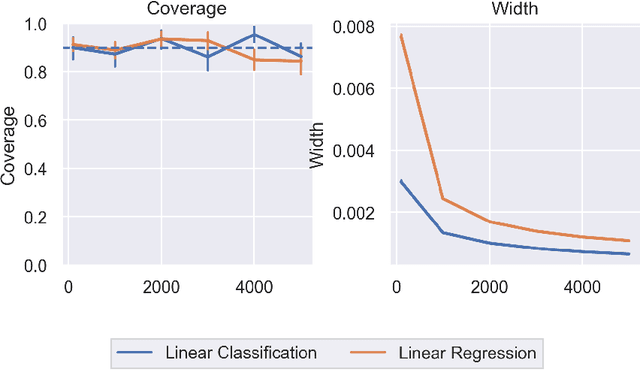
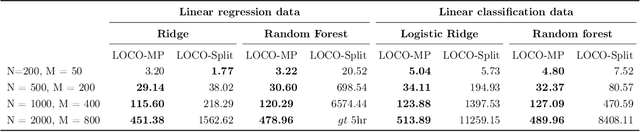
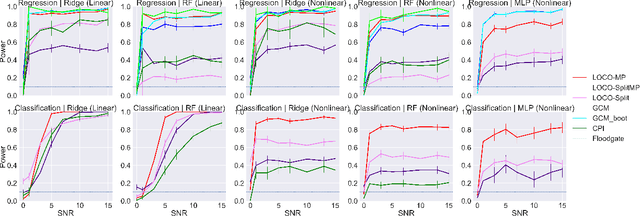
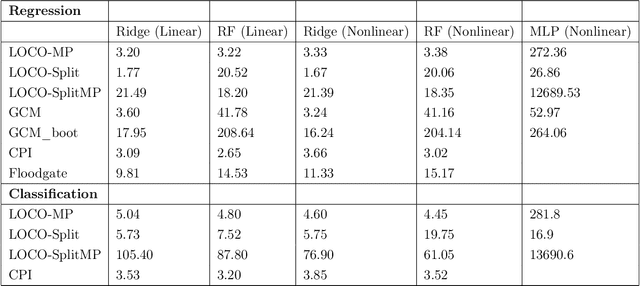
In order to trust machine learning for high-stakes problems, we need models to be both reliable and interpretable. Recently, there has been a growing body of work on interpretable machine learning which generates human understandable insights into data, models, or predictions. At the same time, there has been increased interest in quantifying the reliability and uncertainty of machine learning predictions, often in the form of confidence intervals for predictions using conformal inference. Yet, there has been relatively little attention given to the reliability and uncertainty of machine learning interpretations, which is the focus of this paper. Our goal is to develop confidence intervals for a widely-used form of machine learning interpretation: feature importance. We specifically seek to develop universal model-agnostic and assumption-light confidence intervals for feature importance that will be valid for any machine learning model and for any regression or classification task. We do so by leveraging a form of random observation and feature subsampling called minipatch ensembles and show that our approach provides assumption-light asymptotic coverage for the feature importance score of any model. Further, our approach is fast as computations needed for inference come nearly for free as part of the ensemble learning process. Finally, we also show that our same procedure can be leveraged to provide valid confidence intervals for predictions, hence providing fast, simultaneous quantification of the uncertainty of both model predictions and interpretations. We validate our intervals on a series of synthetic and real data examples, showing that our approach detects the correct important features and exhibits many computational and statistical advantages over existing methods.