 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Data Imputation: A Survey on Deep Learning Approaches
Nov 23, 2020
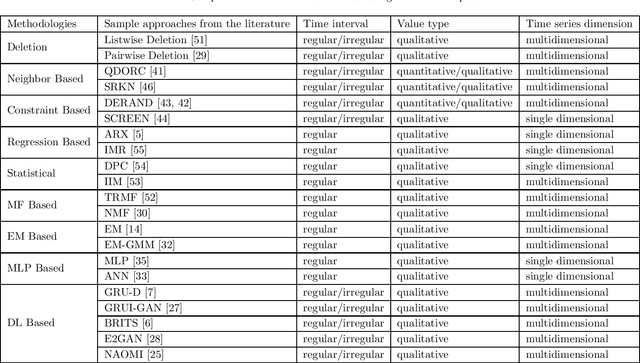
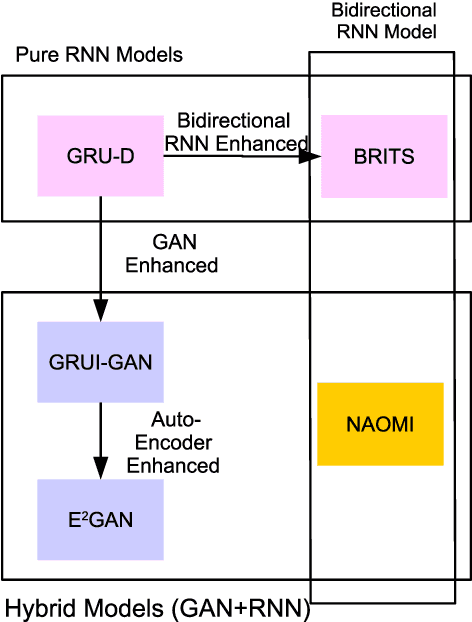

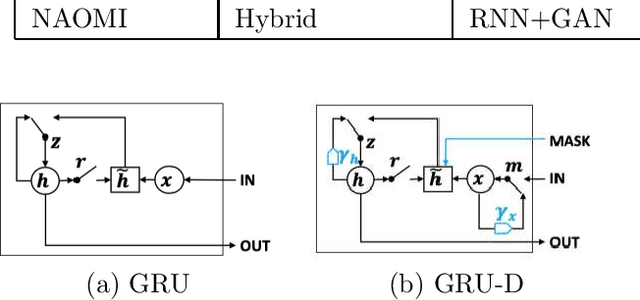
Time series are all around in real-world applications. However, unexpected accidents for example broken sensors or missing of the signals will cause missing values in time series, making the data hard to be utilized. It then does harm to the downstream applications such as traditional classification or regression, sequential data integration and forecasting tasks, thus raising the demand for data imputation. Currently, time series data imputation is a well-studied problem with different categories of methods. However, these works rarely take the temporal relations among the observations and treat the time series as normal structured data, losing the information from the time data. In recent, deep learning models have raised great attention. Time series methods based on deep learning have made progress with the usage of models like RNN, since it captures time information from data. In this paper, we mainly focus on time series imputation technique with deep learning methods, which recently made progress in this field. We will review and discuss their model architectures, their pros and cons as well as their effects to show the development of the time series imputation methods.
On Scale Space Radon Transform, Properties and Image Reconstruction
May 10, 2022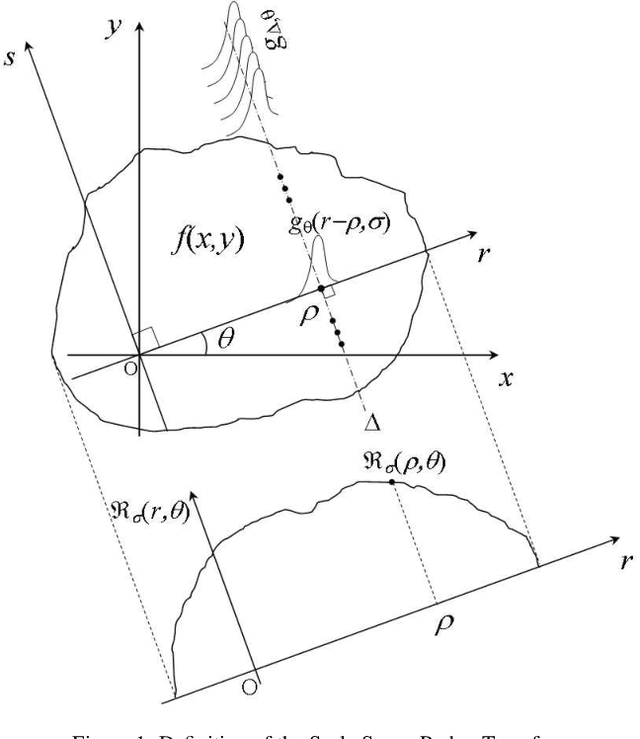
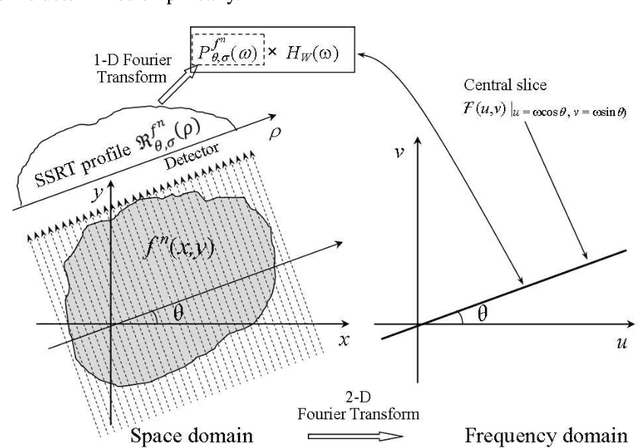
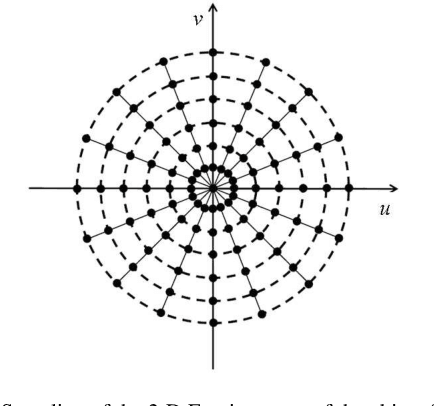
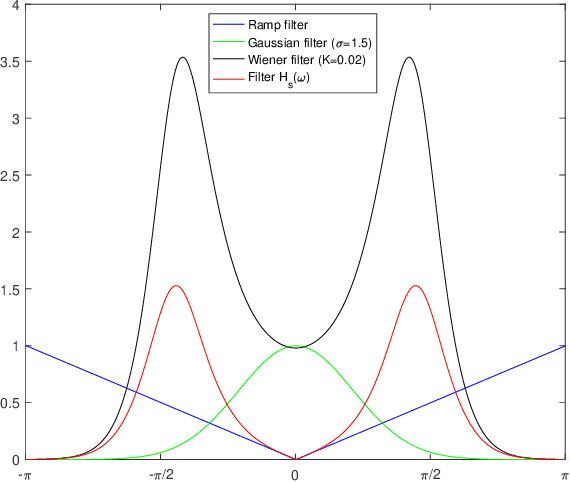
Aware of the importance of the good behavior in the scale space that a mathematical transform must have, we depict, in this paper, the basic properties and the inverse transform of the Scale Space Radon Transform (SSRT). To reconstruct the image from SSRT sinogram, the Filtered backprojection (FBP) technique is used in two different ways: (1) Deconvolve SSRT to obtain the estimated Radon transform (RT) and then, reconstruct image using classical FBP or (2) Adapt FBP technique to SSRT so that the Radon projections spectrum used in classical FBP is replaced by SSRT and Wiener filtering, expressed in the frequency domain. Comparison of image reconstruction techniques using SSRT and RT are performed on Shepp-Logan head phantom image. Using the Mean Absolute Error (MAE) as image reconstruction quality measure, the preliminary results present an outstanding performance for SSRT-based image reconstruction techniques compared to the RT-based one. Furthermore, the method (2) outperforms the method (1) in terms of computation time and adaptability for high level of noise when fairly large Gaussian kernel is used.
NeuroUnlock: Unlocking the Architecture of Obfuscated Deep Neural Networks
Jun 01, 2022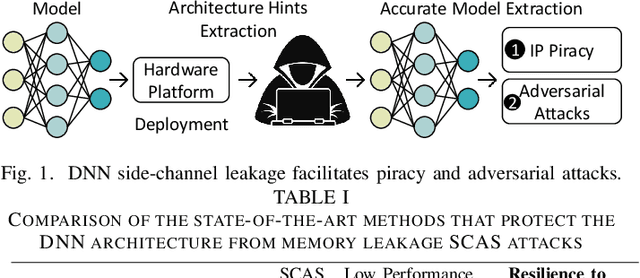

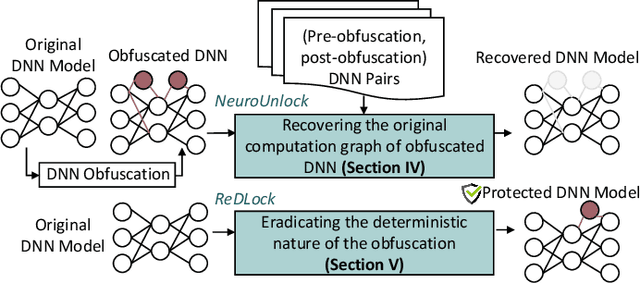
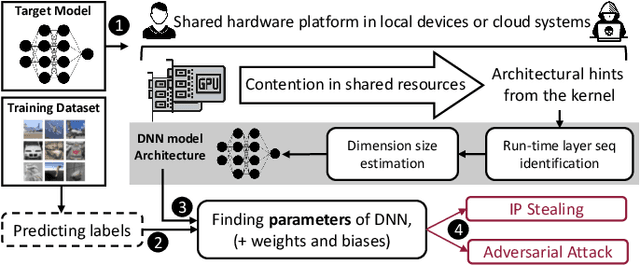
The advancements of deep neural networks (DNNs) have led to their deployment in diverse settings, including safety and security-critical applications. As a result, the characteristics of these models have become sensitive intellectual properties that require protection from malicious users. Extracting the architecture of a DNN through leaky side-channels (e.g., memory access) allows adversaries to (i) clone the model, and (ii) craft adversarial attacks. DNN obfuscation thwarts side-channel-based architecture stealing (SCAS) attacks by altering the run-time traces of a given DNN while preserving its functionality. In this work, we expose the vulnerability of state-of-the-art DNN obfuscation methods to these attacks. We present NeuroUnlock, a novel SCAS attack against obfuscated DNNs. Our NeuroUnlock employs a sequence-to-sequence model that learns the obfuscation procedure and automatically reverts it, thereby recovering the original DNN architecture. We demonstrate the effectiveness of NeuroUnlock by recovering the architecture of 200 randomly generated and obfuscated DNNs running on the Nvidia RTX 2080 TI graphics processing unit (GPU). Moreover, NeuroUnlock recovers the architecture of various other obfuscated DNNs, such as the VGG-11, VGG-13, ResNet-20, and ResNet-32 networks. After recovering the architecture, NeuroUnlock automatically builds a near-equivalent DNN with only a 1.4% drop in the testing accuracy. We further show that launching a subsequent adversarial attack on the recovered DNNs boosts the success rate of the adversarial attack by 51.7% in average compared to launching it on the obfuscated versions. Additionally, we propose a novel methodology for DNN obfuscation, ReDLock, which eradicates the deterministic nature of the obfuscation and achieves 2.16X more resilience to the NeuroUnlock attack. We release the NeuroUnlock and the ReDLock as open-source frameworks.
Interpretable Machine Learning Models for Modal Split Prediction in Transportation Systems
Mar 27, 2022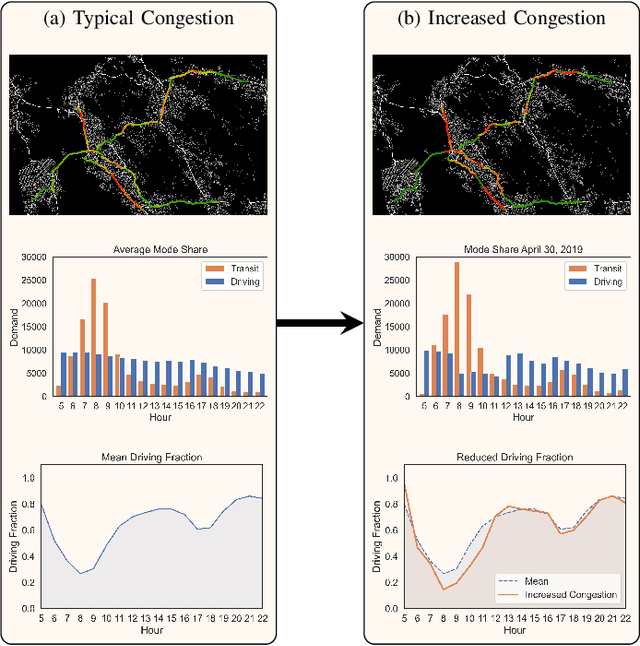
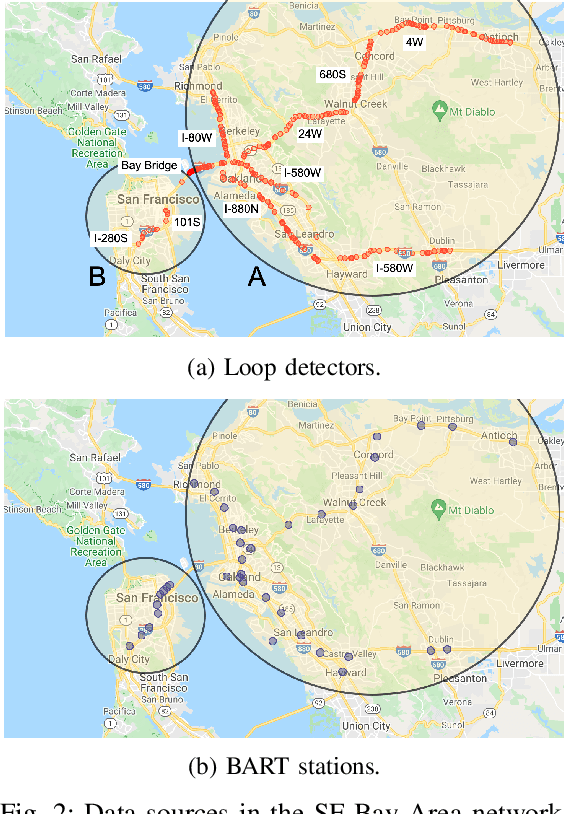
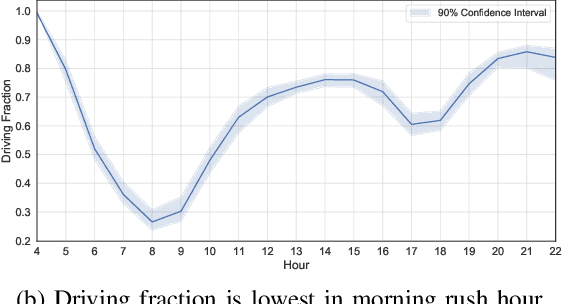
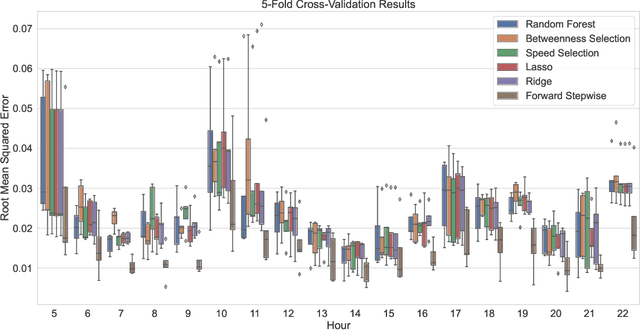
Modal split prediction in transportation networks has the potential to support network operators in managing traffic congestion and improving transit service reliability. We focus on the problem of hourly prediction of the fraction of travelers choosing one mode of transportation over another using high-dimensional travel time data. We use logistic regression as base model and employ various regularization techniques for variable selection to prevent overfitting and resolve multicollinearity issues. Importantly, we interpret the prediction accuracy results with respect to the inherent variability of modal splits and travelers' aggregate responsiveness to changes in travel time. By visualizing model parameters, we conclude that the subset of segments found important for predictive accuracy changes from hour-to-hour and include segments that are topologically central and/or highly congested. We apply our approach to the San Francisco Bay Area freeway and rapid transit network and demonstrate superior prediction accuracy and interpretability of our method compared to pre-specified variable selection methods.
ASP-Based Declarative Process Mining
May 04, 2022
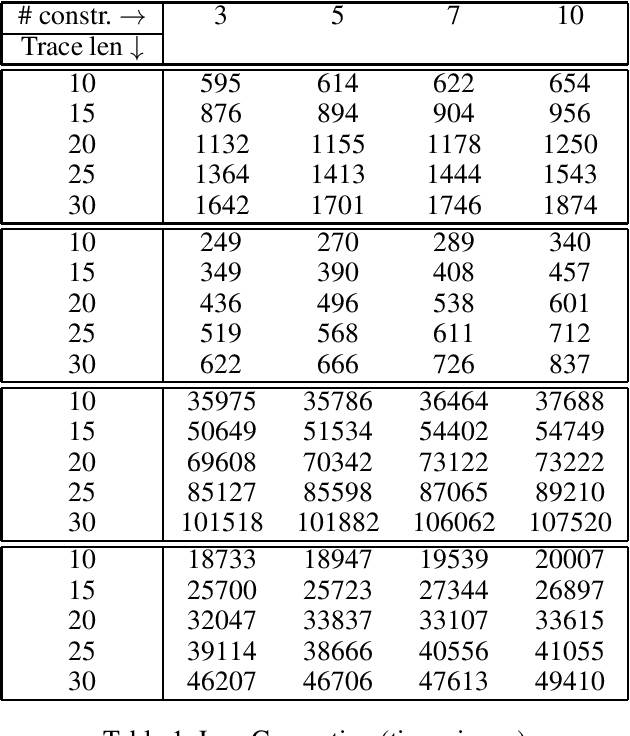
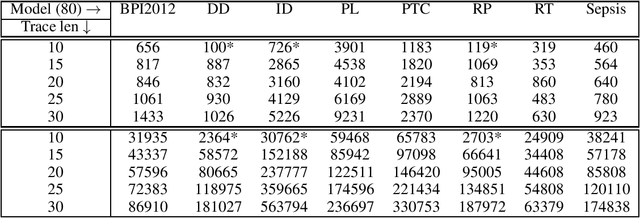
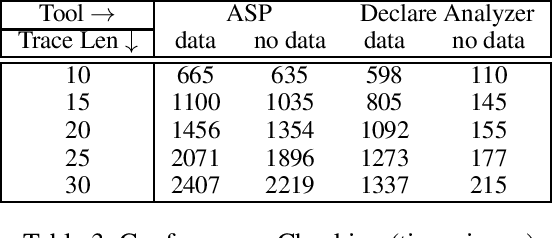
We put forward Answer Set Programming (ASP) as a solution approach for three classical problems in Declarative Process Mining: Log Generation, Query Checking, and Conformance Checking. These problems correspond to different ways of analyzing business processes under execution, starting from sequences of recorded events, a.k.a. event logs. We tackle them in their data-aware variant, i.e., by considering events that carry a payload (set of attribute-value pairs), in addition to the performed activity, specifying processes declaratively with an extension of linear-time temporal logic over finite traces (LTLf). The data-aware setting is significantly more challenging than the control-flow one: Query Checking is still open, while the existing approaches for the other two problems do not scale well. The contributions of the work include an ASP encoding schema for the three problems, their solution, and experiments showing the feasibility of the approach.
Gradient flows and randomised thresholding: sparse inversion and classification
Mar 22, 2022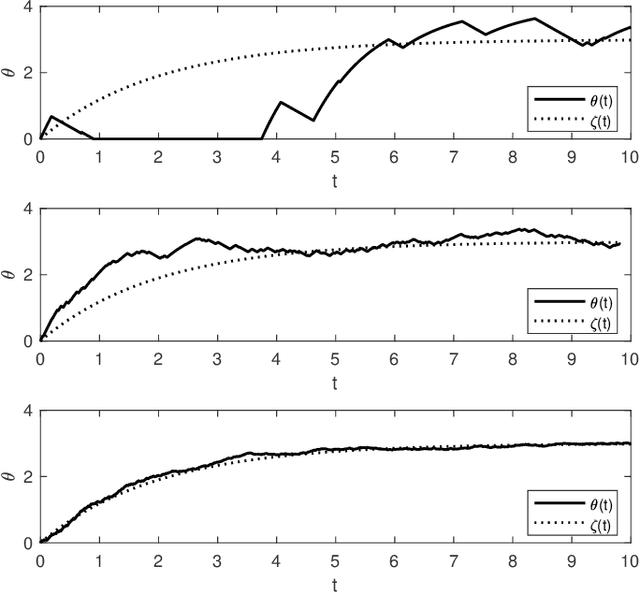
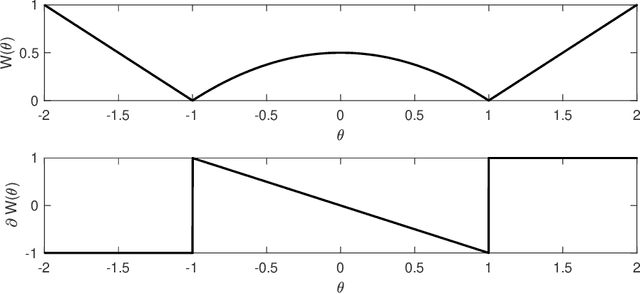

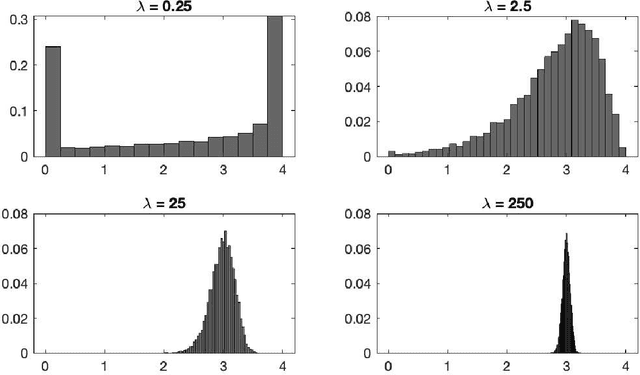
Sparse inversion and classification problems are ubiquitous in modern data science and imaging. They are often formulated as non-smooth minimisation problems. In sparse inversion, we minimise, e.g., the sum of a data fidelity term and an L1/LASSO regulariser. In classification, we consider, e.g., the sum of a data fidelity term and a non-smooth Ginzburg--Landau energy. Standard (sub)gradient descent methods have shown to be inefficient when approaching such problems. Splitting techniques are much more useful: here, the target function is partitioned into a sum of two subtarget functions -- each of which can be efficiently optimised. Splitting proceeds by performing optimisation steps alternately with respect to each of the two subtarget functions. In this work, we study splitting from a stochastic continuous-time perspective. Indeed, we define a differential inclusion that follows one of the two subtarget function's negative subgradient at each point in time. The choice of the subtarget function is controlled by a binary continuous-time Markov process. The resulting dynamical system is a stochastic approximation of the underlying subgradient flow. We investigate this stochastic approximation for an L1-regularised sparse inversion flow and for a discrete Allen-Cahn equation minimising a Ginzburg--Landau energy. In both cases, we study the longtime behaviour of the stochastic dynamical system and its ability to approximate the underlying subgradient flow at any accuracy. We illustrate our theoretical findings in a simple sparse estimation problem and also in a low-dimensional classification problem.
PatchX: Explaining Deep Models by Intelligible Pattern Patches for Time-series Classification
Feb 11, 2021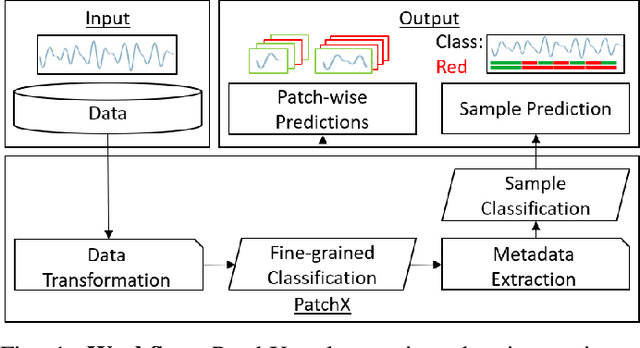
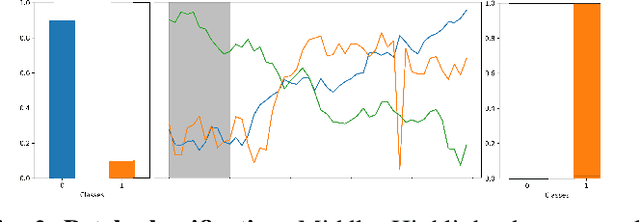
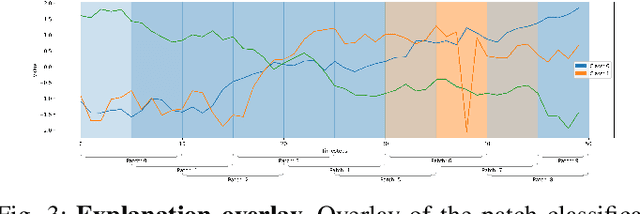
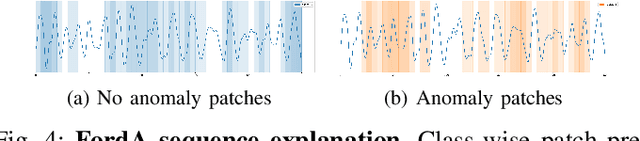
The classification of time-series data is pivotal for streaming data and comes with many challenges. Although the amount of publicly available datasets increases rapidly, deep neural models are only exploited in a few areas. Traditional methods are still used very often compared to deep neural models. These methods get preferred in safety-critical, financial, or medical fields because of their interpretable results. However, their performance and scale-ability are limited, and finding suitable explanations for time-series classification tasks is challenging due to the concepts hidden in the numerical time-series data. Visualizing complete time-series results in a cognitive overload concerning our perception and leads to confusion. Therefore, we believe that patch-wise processing of the data results in a more interpretable representation. We propose a novel hybrid approach that utilizes deep neural networks and traditional machine learning algorithms to introduce an interpretable and scale-able time-series classification approach. Our method first performs a fine-grained classification for the patches followed by sample level classification.
Explainable Multivariate Time Series Classification: A Deep Neural Network Which Learns To Attend To Important Variables As Well As Informative Time Intervals
Nov 23, 2020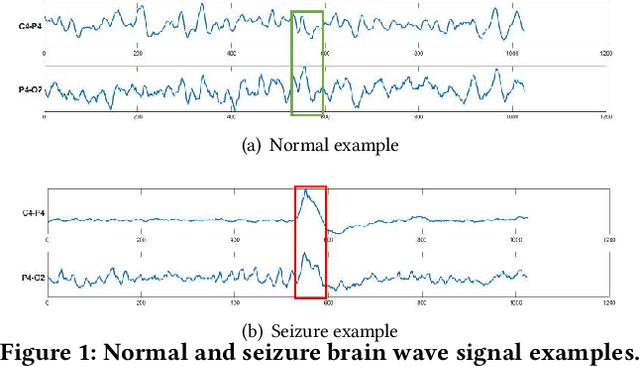

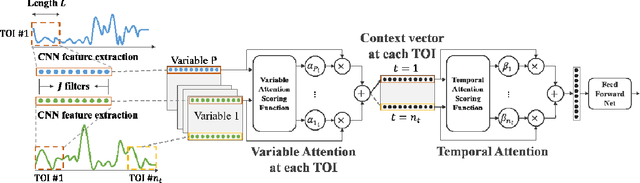

Time series data is prevalent in a wide variety of real-world applications and it calls for trustworthy and explainable models for people to understand and fully trust decisions made by AI solutions. We consider the problem of building explainable classifiers from multi-variate time series data. A key criterion to understand such predictive models involves elucidating and quantifying the contribution of time varying input variables to the classification. Hence, we introduce a novel, modular, convolution-based feature extraction and attention mechanism that simultaneously identifies the variables as well as time intervals which determine the classifier output. We present results of extensive experiments with several benchmark data sets that show that the proposed method outperforms the state-of-the-art baseline methods on multi-variate time series classification task. The results of our case studies demonstrate that the variables and time intervals identified by the proposed method make sense relative to available domain knowledge.
Multi-Faceted Representation Learning with Hybrid Architecture for Time Series Classification
Dec 21, 2020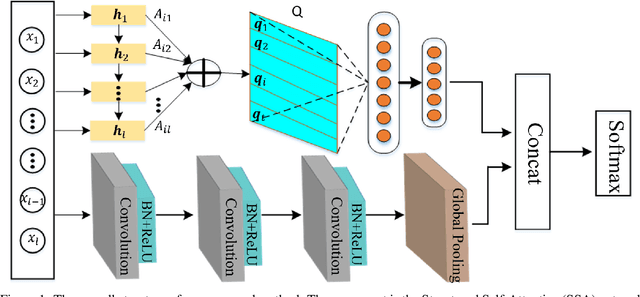
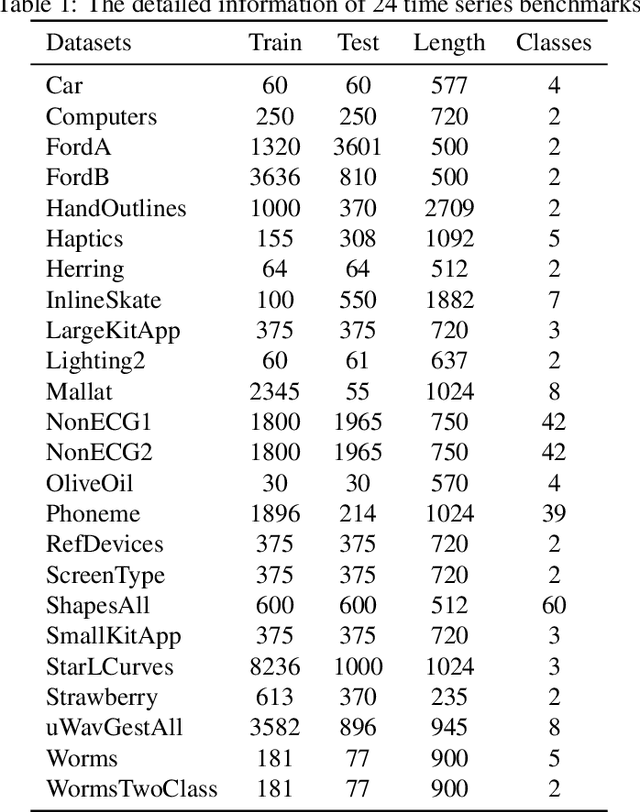
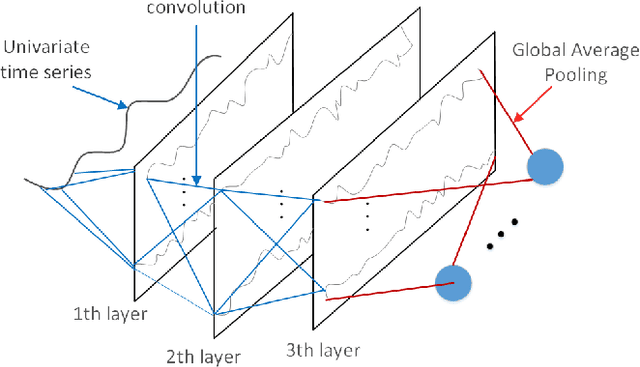
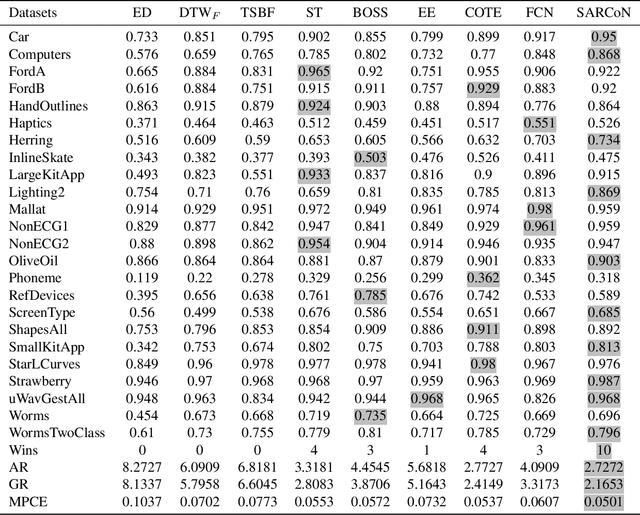
Time series classification problems exist in many fields and have been explored for a couple of decades. However, they still remain challenging, and their solutions need to be further improved for real-world applications in terms of both accuracy and efficiency. In this paper, we propose a hybrid neural architecture, called Self-Attentive Recurrent Convolutional Networks (SARCoN), to learn multi-faceted representations for univariate time series. SARCoN is the synthesis of long short-term memory networks with self-attentive mechanisms and Fully Convolutional Networks, which work in parallel to learn the representations of univariate time series from different perspectives. The component modules of the proposed architecture are trained jointly in an end-to-end manner and they classify the input time series in a cooperative way. Due to its domain-agnostic nature, SARCoN is able to generalize a diversity of domain tasks. Our experimental results show that, compared to the state-of-the-art approaches for time series classification, the proposed architecture can achieve remarkable improvements for a set of univariate time series benchmarks from the UCR repository. Moreover, the self-attention and the global average pooling in the proposed architecture enable visible interpretability by facilitating the identification of the contribution regions of the original time series. An overall analysis confirms that multi-faceted representations of time series aid in capturing deep temporal corrections within complex time series, which is essential for the improvement of time series classification performance. Our work provides a novel angle that deepens the understanding of time series classification, qualifying our proposed model as an ideal choice for real-world applications.
Efficient Video Instance Segmentation via Tracklet Query and Proposal
Mar 03, 2022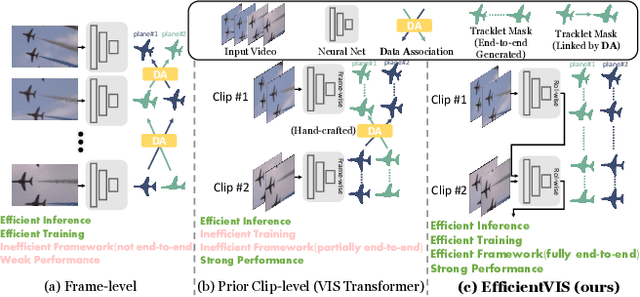
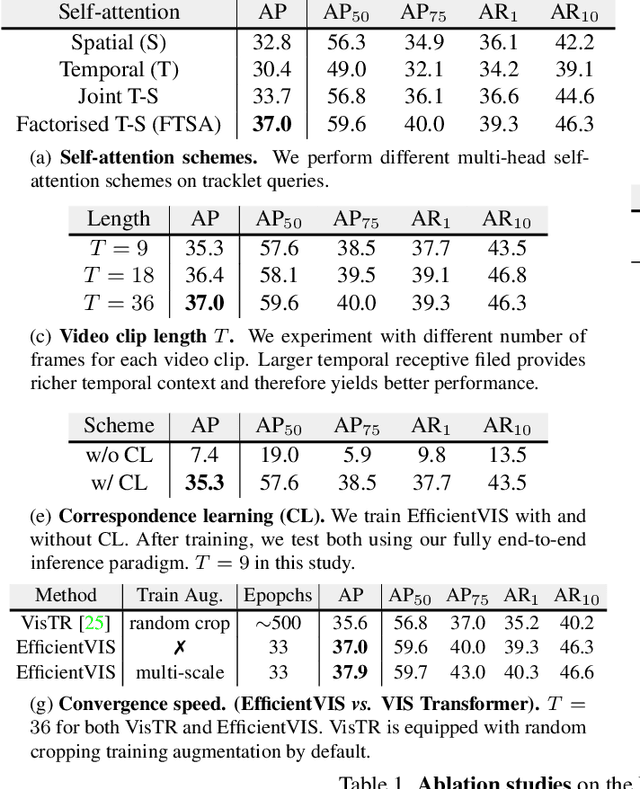
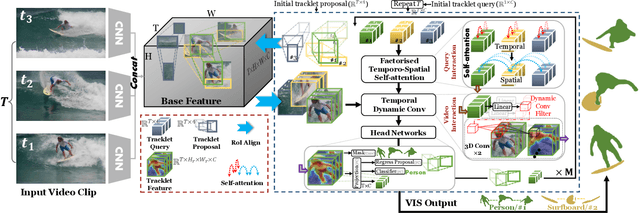
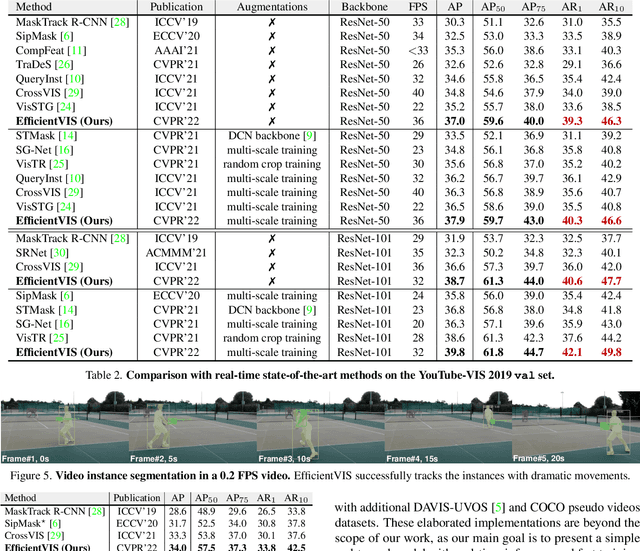
Video Instance Segmentation (VIS) aims to simultaneously classify, segment, and track multiple object instances in videos. Recent clip-level VIS takes a short video clip as input each time showing stronger performance than frame-level VIS (tracking-by-segmentation), as more temporal context from multiple frames is utilized. Yet, most clip-level methods are neither end-to-end learnable nor real-time. These limitations are addressed by the recent VIS transformer (VisTR) which performs VIS end-to-end within a clip. However, VisTR suffers from long training time due to its frame-wise dense attention. In addition, VisTR is not fully end-to-end learnable in multiple video clips as it requires a hand-crafted data association to link instance tracklets between successive clips. This paper proposes EfficientVIS, a fully end-to-end framework with efficient training and inference. At the core are tracklet query and tracklet proposal that associate and segment regions-of-interest (RoIs) across space and time by an iterative query-video interaction. We further propose a correspondence learning that makes tracklets linking between clips end-to-end learnable. Compared to VisTR, EfficientVIS requires 15x fewer training epochs while achieving state-of-the-art accuracy on the YouTube-VIS benchmark. Meanwhile, our method enables whole video instance segmentation in a single end-to-end pass without data association at all.