 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
InducT-GCN: Inductive Graph Convolutional Networks for Text Classification
Jun 01, 2022

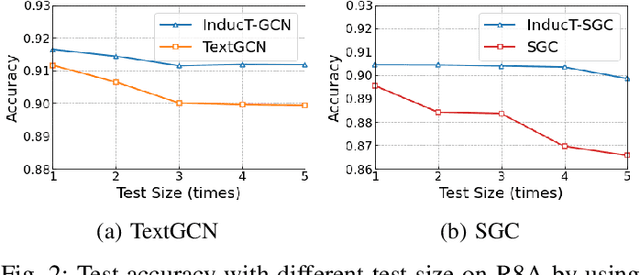
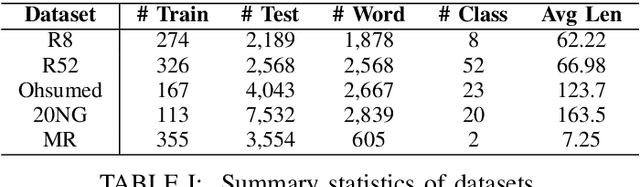
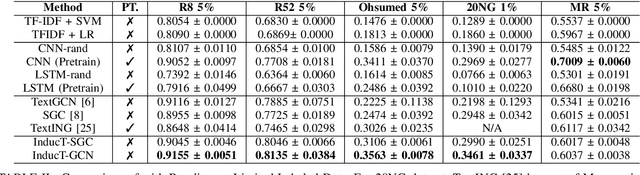
Text classification aims to assign labels to textual units by making use of global information. Recent studies have applied graph neural network (GNN) to capture the global word co-occurrence in a corpus. Existing approaches require that all the nodes (training and test) in a graph are present during training, which are transductive and do not naturally generalise to unseen nodes. To make those models inductive, they use extra resources, like pretrained word embedding. However, high-quality resource is not always available and hard to train. Under the extreme settings with no extra resource and limited amount of training set, can we still learn an inductive graph-based text classification model? In this paper, we introduce a novel inductive graph-based text classification framework, InducT-GCN (InducTive Graph Convolutional Networks for Text classification). Compared to transductive models that require test documents in training, we construct a graph based on the statistics of training documents only and represent document vectors with a weighted sum of word vectors. We then conduct one-directional GCN propagation during testing. Across five text classification benchmarks, our InducT-GCN outperformed state-of-the-art methods that are either transductive in nature or pre-trained additional resources. We also conducted scalability testing by gradually increasing the data size and revealed that our InducT-GCN can reduce the time and space complexity. The code is available on: https://github.com/usydnlp/InductTGCN.
PFGE: Parsimonious Fast Geometric Ensembling of DNNs
Feb 23, 2022
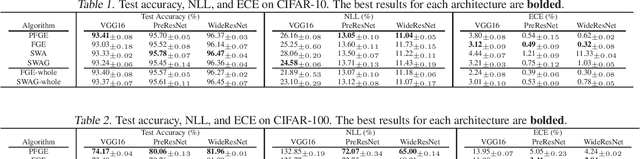
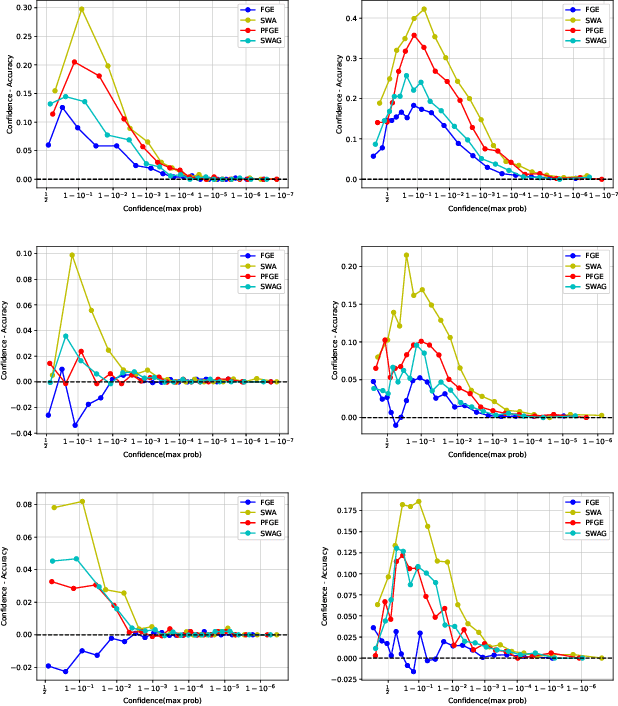

Ensemble methods have been widely used to improve the performance of machine learning methods in terms of generalization and uncertainty calibration, while they struggle to use in deep learning systems, as training an ensemble of deep neural networks (DNNs) and then deploying them for online prediction incur an extremely higher computational overhead of model training and test-time predictions. Recently, several advanced techniques, such as fast geometric ensembling (FGE) and snapshot ensemble, have been proposed. These methods can train the model ensembles in the same time as a single model, thus getting around the hurdle of training time. However, their overhead of model recording and test-time computations remains much higher than their single model based counterparts. Here we propose a parsimonious FGE (PFGE) that employs a lightweight ensemble of higher-performing DNNs generated by several successively-performed procedures of stochastic weight averaging. Experimental results across different advanced DNN architectures on different datasets, namely CIFAR-$\{$10,100$\}$ and Imagenet, demonstrate its performance. Results show that, compared with state-of-the-art methods, PFGE achieves better generalization performance and satisfactory calibration capability, while the overhead of model recording and test-time predictions is significantly reduced.
Association rules over time
Oct 08, 2020

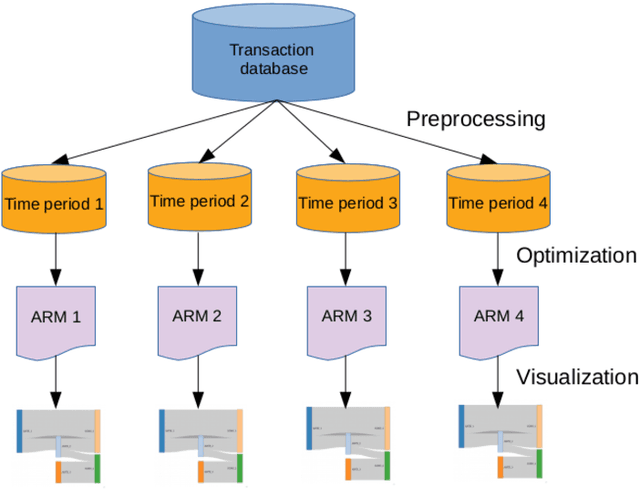
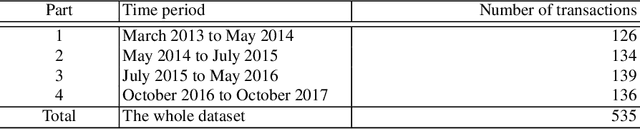
Decisions made nowadays by Artificial Intelligence powered systems are usually hard for users to understand. One of the more important issues faced by developers is exposed as how to create more explainable Machine Learning models. In line with this, more explainable techniques need to be developed, where visual explanation also plays a more important role. This technique could also be applied successfully for explaining the results of Association Rule Mining.This Chapter focuses on two issues: (1) How to discover the relevant association rules, and (2) How to express relations between more attributes visually. For the solution of the first issue, the proposed method uses Differential Evolution, while Sankey diagrams are adopted to solve the second one. This method was applied to a transaction database containing data generated by an amateur cyclist in past seasons, using a mobile device worn during the realization of training sessions that is divided into four time periods. The results of visualization showed that a trend in improving performance of an athlete can be indicated by changing the attributes appearing in the selected association rules in different time periods.
Scalable and Low-Latency Federated Learning with Cooperative Mobile Edge Networking
May 25, 2022
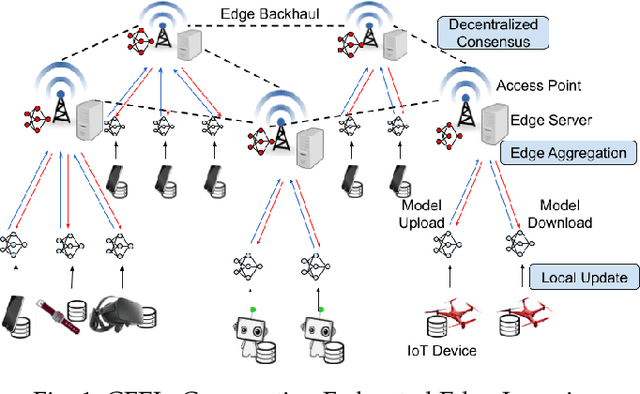

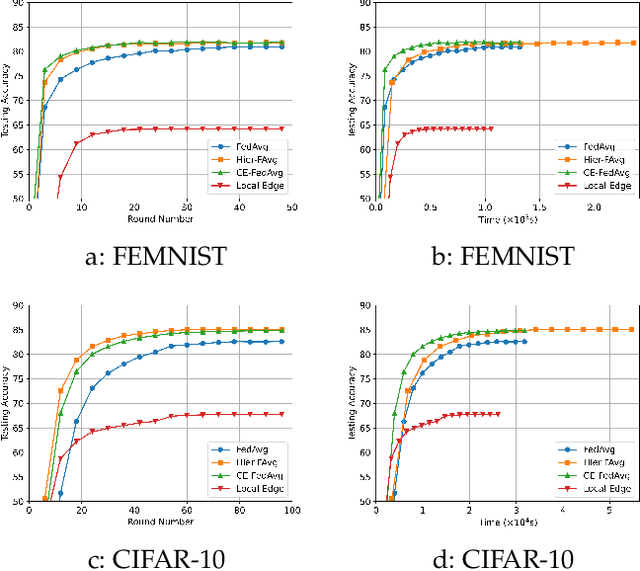
Federated learning (FL) enables collaborative model training without centralizing data. However, the traditional FL framework is cloud-based and suffers from high communication latency. On the other hand, the edge-based FL framework that relies on an edge server co-located with access point for model aggregation has low communication latency but suffers from degraded model accuracy due to the limited coverage of edge server. In light of high-accuracy but high-latency cloud-based FL and low-latency but low-accuracy edge-based FL, this paper proposes a new FL framework based on cooperative mobile edge networking called cooperative federated edge learning (CFEL) to enable both high-accuracy and low-latency distributed intelligence at mobile edge networks. Considering the unique two-tier network architecture of CFEL, a novel federated optimization method dubbed cooperative edge-based federated averaging (CE-FedAvg) is further developed, wherein each edge server both coordinates collaborative model training among the devices within its own coverage and cooperates with other edge servers to learn a shared global model through decentralized consensus. Experimental results based on benchmark datasets show that CFEL can largely speed up the convergence speed and reduce the training time to achieve a target model accuracy compared with prior FL frameworks.
Efficient Neural Networks for Real-time Analog Audio Effect Modeling
Feb 11, 2021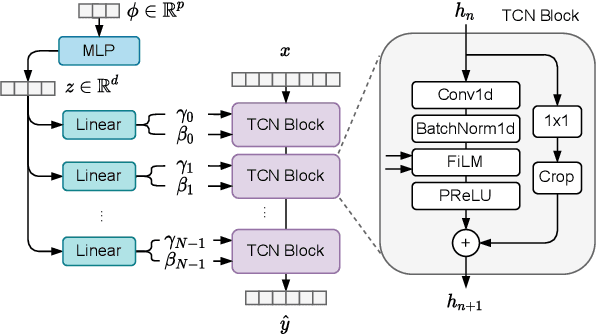
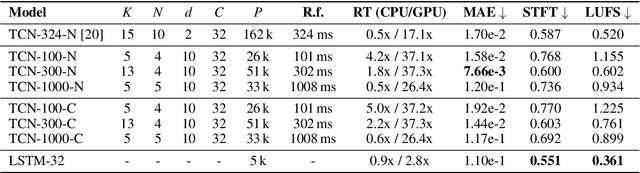
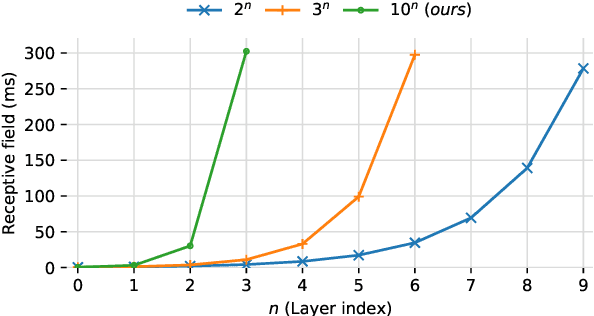
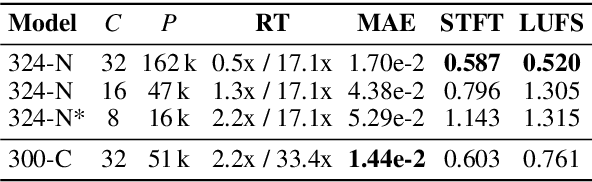
Deep learning approaches have demonstrated success in the task of modeling analog audio effects such as distortion and overdrive. Nevertheless, challenges remain in modeling more complex effects, such as dynamic range compressors, along with their variable parameters. Previous methods are computationally complex, and noncausal, prohibiting real-time operation, which is critical for use in audio production contexts. They additionally utilize large training datasets, which are time-intensive to generate. In this work, we demonstrate that shallower temporal convolutional networks (TCNs) that exploit very large dilation factors for significant receptive field can achieve state-of-the-art performance, while remaining efficient. Not only are these models found to be perceptually similar to the original effect, they achieve a 4x speedup, enabling real-time operation on CPU, and can be trained using only 1% of the data from previous methods.
Exploiting Session Information in BERT-based Session-aware Sequential Recommendation
May 04, 2022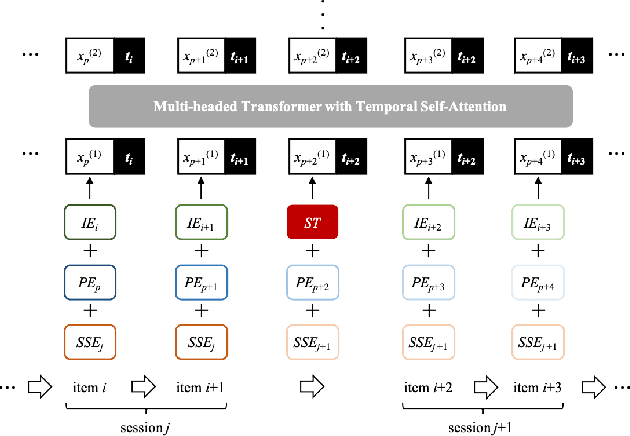
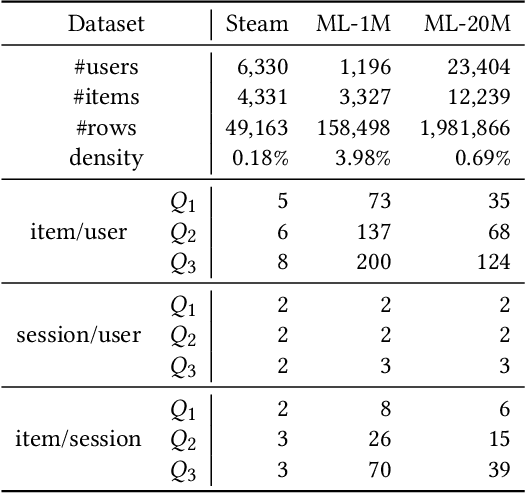
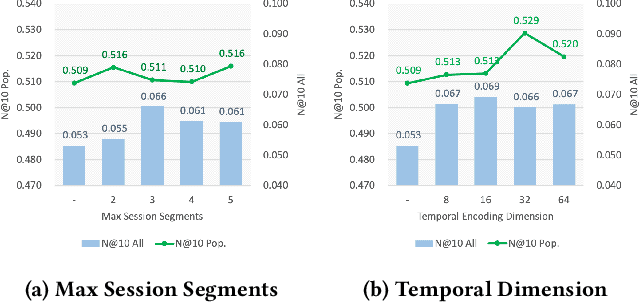
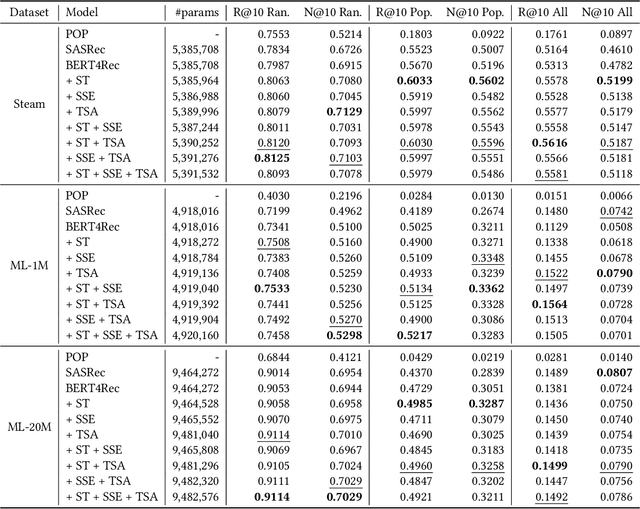
In recommendation systems, utilizing the user interaction history as sequential information has resulted in great performance improvement. However, in many online services, user interactions are commonly grouped by sessions that presumably share preferences, which requires a different approach from ordinary sequence representation techniques. To this end, sequence representation models with a hierarchical structure or various viewpoints have been developed but with a rather complex network structure. In this paper, we propose three methods to improve recommendation performance by exploiting session information while minimizing additional parameters in a BERT-based sequential recommendation model: using session tokens, adding session segment embeddings, and a time-aware self-attention. We demonstrate the feasibility of the proposed methods through experiments on widely used recommendation datasets.
Stable Online Control of Linear Time-Varying Systems
Apr 30, 2021
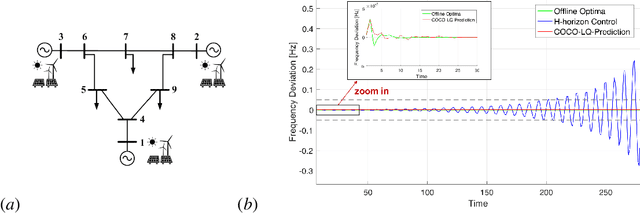

Linear time-varying (LTV) systems are widely used for modeling real-world dynamical systems due to their generality and simplicity. Providing stability guarantees for LTV systems is one of the central problems in control theory. However, existing approaches that guarantee stability typically lead to significantly sub-optimal cumulative control cost in online settings where only current or short-term system information is available. In this work, we propose an efficient online control algorithm, COvariance Constrained Online Linear Quadratic (COCO-LQ) control, that guarantees input-to-state stability for a large class of LTV systems while also minimizing the control cost. The proposed method incorporates a state covariance constraint into the semi-definite programming (SDP) formulation of the LQ optimal controller. We empirically demonstrate the performance of COCO-LQ in both synthetic experiments and a power system frequency control example.
Drawing out of Distribution with Neuro-Symbolic Generative Models
Jun 03, 2022
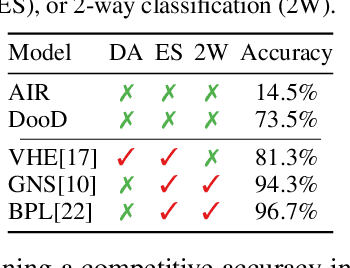
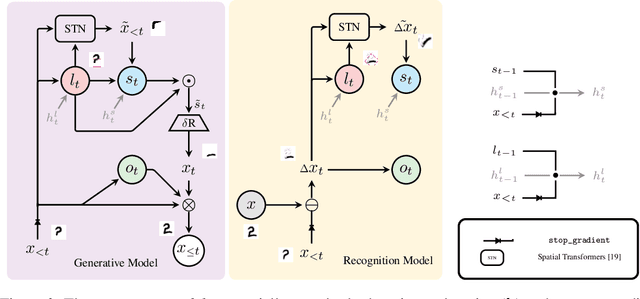
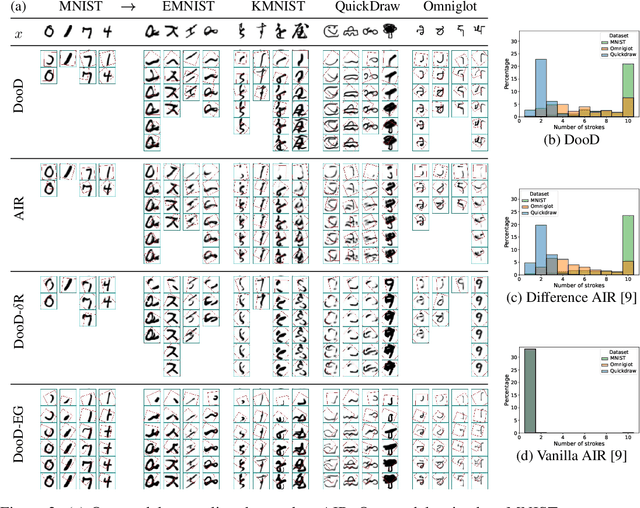
Learning general-purpose representations from perceptual inputs is a hallmark of human intelligence. For example, people can write out numbers or characters, or even draw doodles, by characterizing these tasks as different instantiations of the same generic underlying process -- compositional arrangements of different forms of pen strokes. Crucially, learning to do one task, say writing, implies reasonable competence at another, say drawing, on account of this shared process. We present Drawing out of Distribution (DooD), a neuro-symbolic generative model of stroke-based drawing that can learn such general-purpose representations. In contrast to prior work, DooD operates directly on images, requires no supervision or expensive test-time inference, and performs unsupervised amortised inference with a symbolic stroke model that better enables both interpretability and generalization. We evaluate DooD on its ability to generalise across both data and tasks. We first perform zero-shot transfer from one dataset (e.g. MNIST) to another (e.g. Quickdraw), across five different datasets, and show that DooD clearly outperforms different baselines. An analysis of the learnt representations further highlights the benefits of adopting a symbolic stroke model. We then adopt a subset of the Omniglot challenge tasks, and evaluate its ability to generate new exemplars (both unconditionally and conditionally), and perform one-shot classification, showing that DooD matches the state of the art. Taken together, we demonstrate that DooD does indeed capture general-purpose representations across both data and task, and takes a further step towards building general and robust concept-learning systems.
On Designing Data Models for Energy Feature Stores
May 09, 2022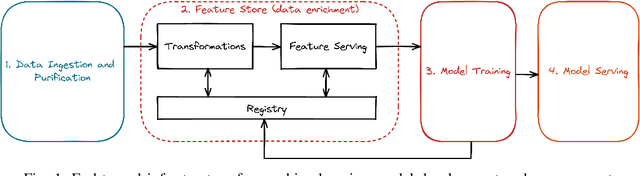
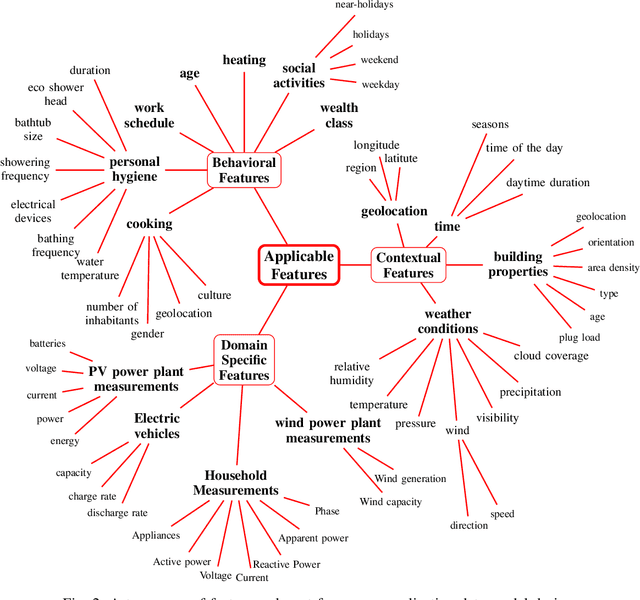
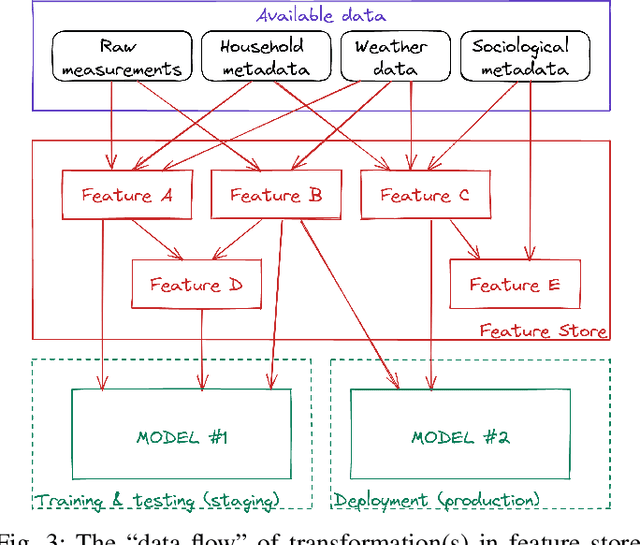

The digitization of the energy infrastructure enables new, data driven, applications often supported by machine learning models. However, domain specific data transformations, pre-processing and management in modern data driven pipelines is yet to be addressed. In this paper we perform a first time study on data models, energy feature engineering and feature management solutions for developing ML-based energy applications. We first propose a taxonomy for designing data models suitable for energy applications, analyze feature engineering techniques able to transform the data model into features suitable for ML model training and finally also analyze available designs for feature stores. Using a short-term forecasting dataset, we show the benefits of designing richer data models and engineering the features on the performance of the resulting models. Finally, we benchmark three complementary feature management solutions, including an open-source feature store.
Unsupervised Key Event Detection from Massive Text Corpora
Jun 08, 2022
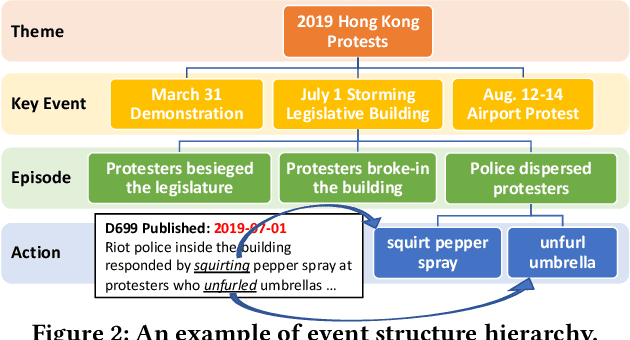
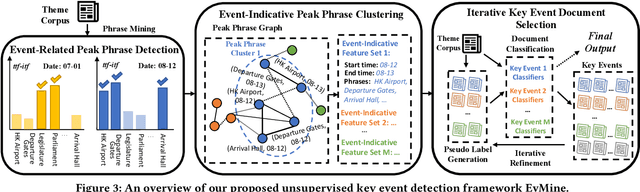
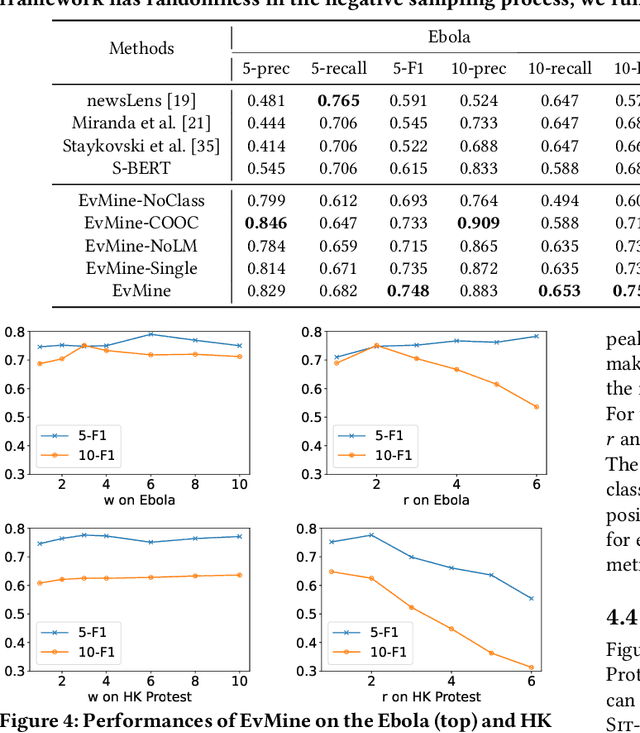
Automated event detection from news corpora is a crucial task towards mining fast-evolving structured knowledge. As real-world events have different granularities, from the top-level themes to key events and then to event mentions corresponding to concrete actions, there are generally two lines of research: (1) theme detection identifies from a news corpus major themes (e.g., "2019 Hong Kong Protests" vs. "2020 U.S. Presidential Election") that have very distinct semantics; and (2) action extraction extracts from one document mention-level actions (e.g., "the police hit the left arm of the protester") that are too fine-grained for comprehending the event. In this paper, we propose a new task, key event detection at the intermediate level, aiming to detect from a news corpus key events (e.g., "HK Airport Protest on Aug. 12-14"), each happening at a particular time/location and focusing on the same topic. This task can bridge event understanding and structuring and is inherently challenging because of the thematic and temporal closeness of key events and the scarcity of labeled data due to the fast-evolving nature of news articles. To address these challenges, we develop an unsupervised key event detection framework, EvMine, that (1) extracts temporally frequent peak phrases using a novel ttf-itf score, (2) merges peak phrases into event-indicative feature sets by detecting communities from our designed peak phrase graph that captures document co-occurrences, semantic similarities, and temporal closeness signals, and (3) iteratively retrieves documents related to each key event by training a classifier with automatically generated pseudo labels from the event-indicative feature sets and refining the detected key events using the retrieved documents. Extensive experiments and case studies show EvMine outperforms all the baseline methods and its ablations on two real-world news corpora.