 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Constraint-Based Causal Structure Learning from Undersampled Graphs
May 18, 2022
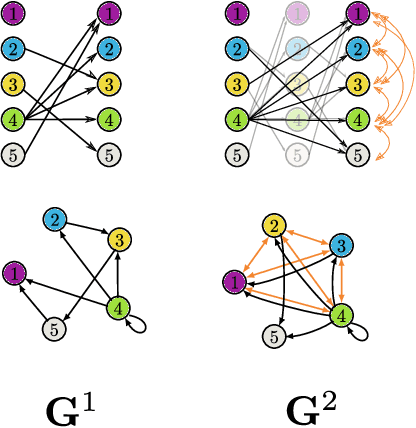
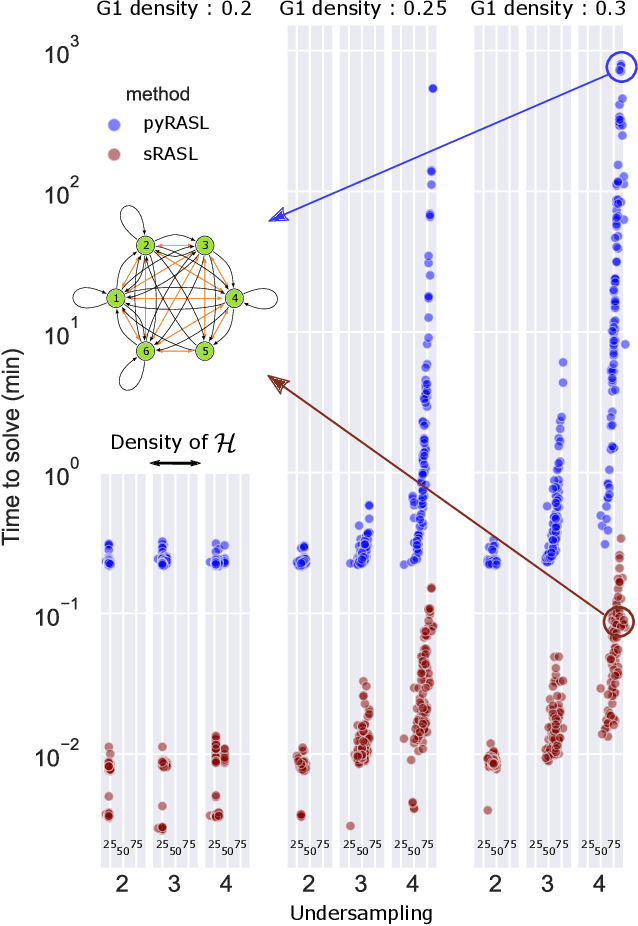
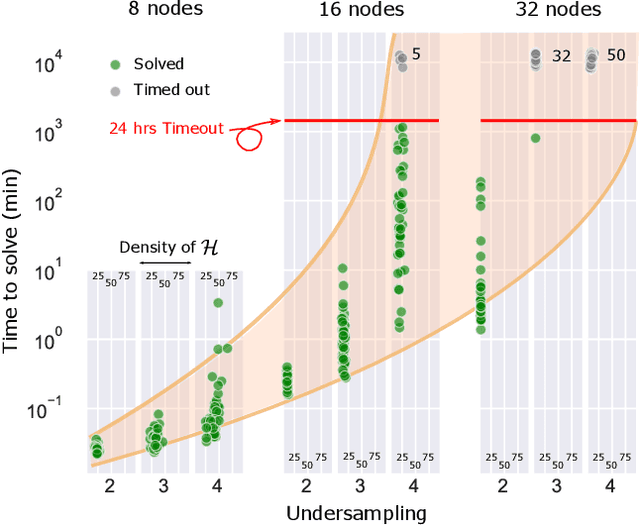
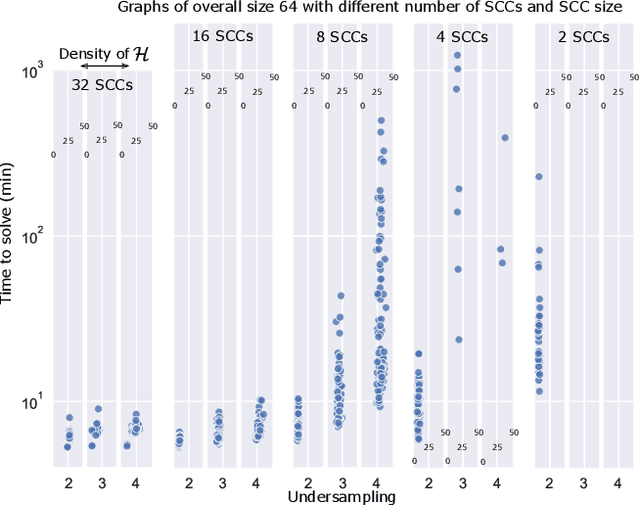
Graphical structures estimated by causal learning algorithms from time series data can provide highly misleading causal information if the causal timescale of the generating process fails to match the measurement timescale of the data. Although this problem has been recently recognized, practitioners have limited resources to respond to it, and so must continue using models that they know are likely misleading. Existing methods either (a) require that the difference between causal and measurement timescales is known; or (b) can handle only very small number of random variables when the timescale difference is unknown; or (c) apply to only pairs of variables, though with fewer assumptions about prior knowledge; or (d) return impractically too many solutions. This paper addresses all four challenges. We combine constraint programming with both theoretical insights into the problem structure and prior information about admissible causal interactions. The resulting system provides a practical approach that scales to significantly larger sets (>100) of random variables, does not require precise knowledge of the timescale difference, supports edge misidentification and parametric connection strengths, and can provide the optimum choice among many possible solutions. The cumulative impact of these improvements is gain of multiple orders of magnitude in speed and informativeness.
Optimal Prediction Intervals for Macroeconomic Time Series Using Chaos and NSGA II
Feb 23, 2021

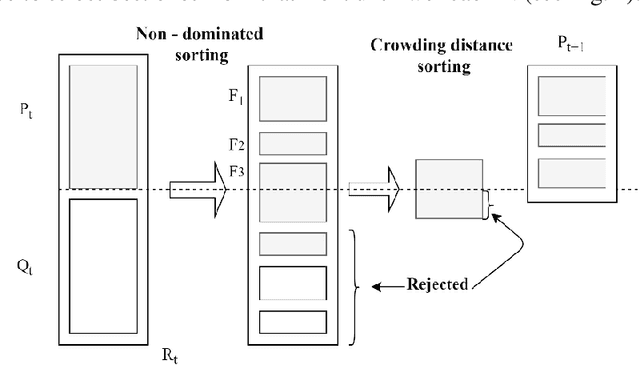

In a first-of-its-kind study, this paper proposes the formulation of constructing prediction intervals (PIs) in a time series as a bi-objective optimization problem and solves it with the help of Nondominated Sorting Genetic Algorithm (NSGA-II). We also proposed modeling the chaos present in the time series as a preprocessor in order to model the deterministic uncertainty present in the time series. Even though the proposed models are general in purpose, they are used here for quantifying the uncertainty in macroeconomic time series forecasting. Ideal PIs should be as narrow as possible while capturing most of the data points. Based on these two objectives, we formulated a bi-objective optimization problem to generate PIs in 2-stages, wherein reconstructing the phase space using Chaos theory (stage-1) is followed by generating optimal point prediction using NSGA-II and these point predictions are in turn used to obtain PIs (stage-2). We also proposed a 3-stage hybrid, wherein the 3rd stage invokes NSGA-II too in order to solve the problem of constructing PIs from the point prediction obtained in 2nd stage. The proposed models when applied to the macroeconomic time series, yielded better results in terms of both prediction interval coverage probability (PICP) and prediction interval average width (PIAW) compared to the state-of-the-art Lower Upper Bound Estimation Method (LUBE) with Gradient Descent (GD). The 3-stage model yielded better PICP compared to the 2-stage model but showed similar performance in PIAW with added computation cost of running NSGA-II second time.
Faster Rates of Convergence to Stationary Points in Differentially Private Optimization
Jun 02, 2022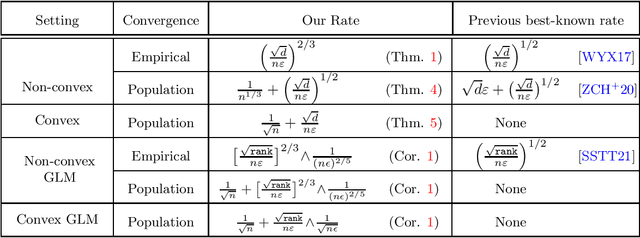
We study the problem of approximating stationary points of Lipschitz and smooth functions under $(\varepsilon,\delta)$-differential privacy (DP) in both the finite-sum and stochastic settings. A point $\widehat{w}$ is called an $\alpha$-stationary point of a function $F:\mathbb{R}^d\rightarrow\mathbb{R}$ if $\|\nabla F(\widehat{w})\|\leq \alpha$. We provide a new efficient algorithm that finds an $\tilde{O}\big(\big[\frac{\sqrt{d}}{n\varepsilon}\big]^{2/3}\big)$-stationary point in the finite-sum setting, where $n$ is the number of samples. This improves on the previous best rate of $\tilde{O}\big(\big[\frac{\sqrt{d}}{n\varepsilon}\big]^{1/2}\big)$. We also give a new construction that improves over the existing rates in the stochastic optimization setting, where the goal is to find approximate stationary points of the population risk. Our construction finds a $\tilde{O}\big(\frac{1}{n^{1/3}} + \big[\frac{\sqrt{d}}{n\varepsilon}\big]^{1/2}\big)$-stationary point of the population risk in time linear in $n$. Furthermore, under the additional assumption of convexity, we completely characterize the sample complexity of finding stationary points of the population risk (up to polylog factors) and show that the optimal rate on population stationarity is $\tilde \Theta\big(\frac{1}{\sqrt{n}}+\frac{\sqrt{d}}{n\varepsilon}\big)$. Finally, we show that our methods can be used to provide dimension-independent rates of $O\big(\frac{1}{\sqrt{n}}+\min\big(\big[\frac{\sqrt{rank}}{n\varepsilon}\big]^{2/3},\frac{1}{(n\varepsilon)^{2/5}}\big)\big)$ on population stationarity for Generalized Linear Models (GLM), where $rank$ is the rank of the design matrix, which improves upon the previous best known rate.
Online Continual Learning for Embedded Devices
Mar 21, 2022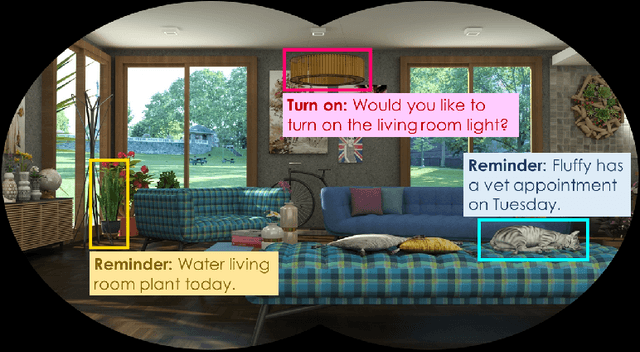
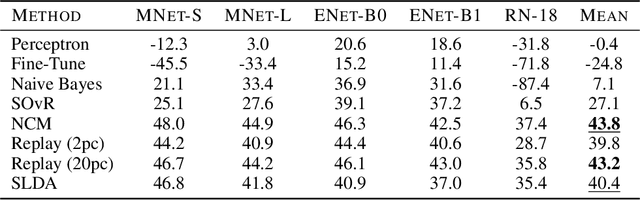

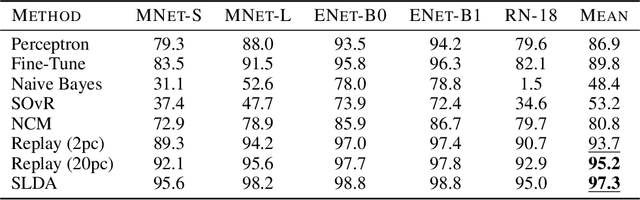
Real-time on-device continual learning is needed for new applications such as home robots, user personalization on smartphones, and augmented/virtual reality headsets. However, this setting poses unique challenges: embedded devices have limited memory and compute capacity and conventional machine learning models suffer from catastrophic forgetting when updated on non-stationary data streams. While several online continual learning models have been developed, their effectiveness for embedded applications has not been rigorously studied. In this paper, we first identify criteria that online continual learners must meet to effectively perform real-time, on-device learning. We then study the efficacy of several online continual learning methods when used with mobile neural networks. We measure their performance, memory usage, compute requirements, and ability to generalize to out-of-domain inputs.
Spatiotemporal convolutional network for time-series prediction and causal inference
Jul 03, 2021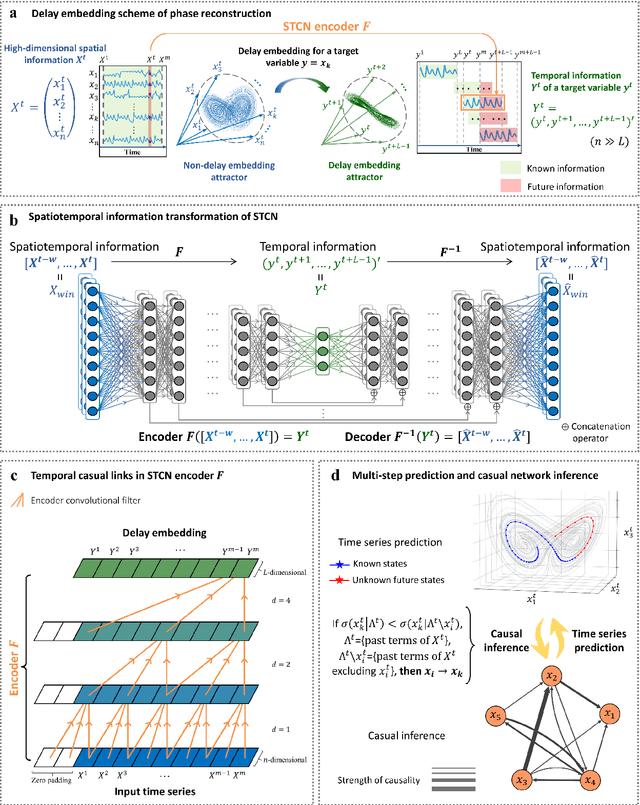
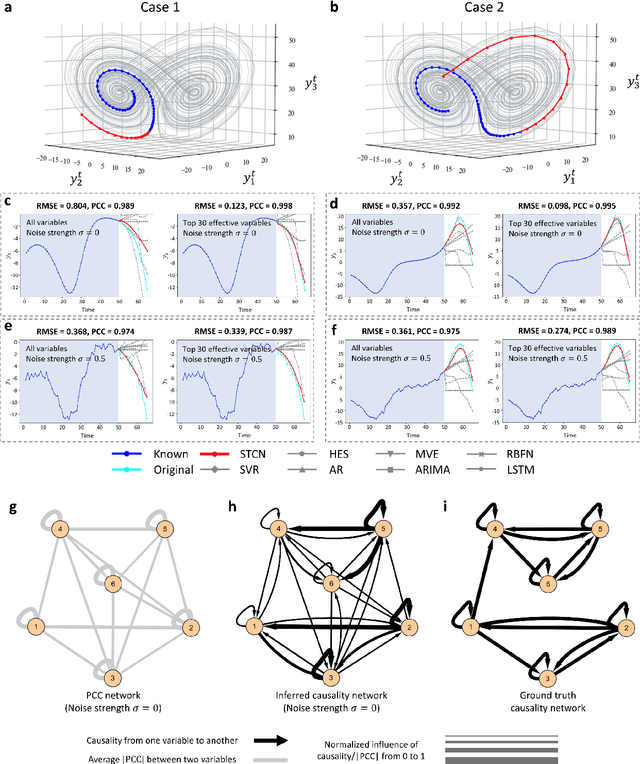
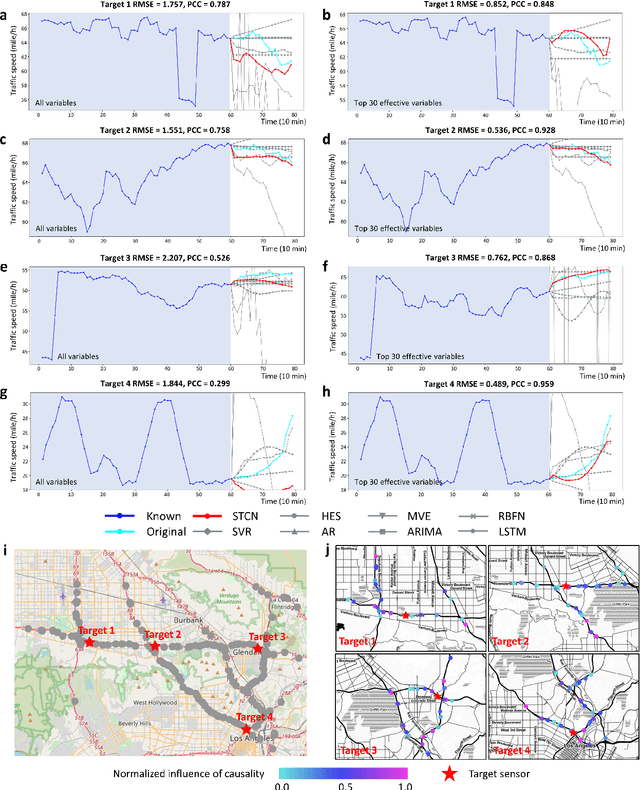
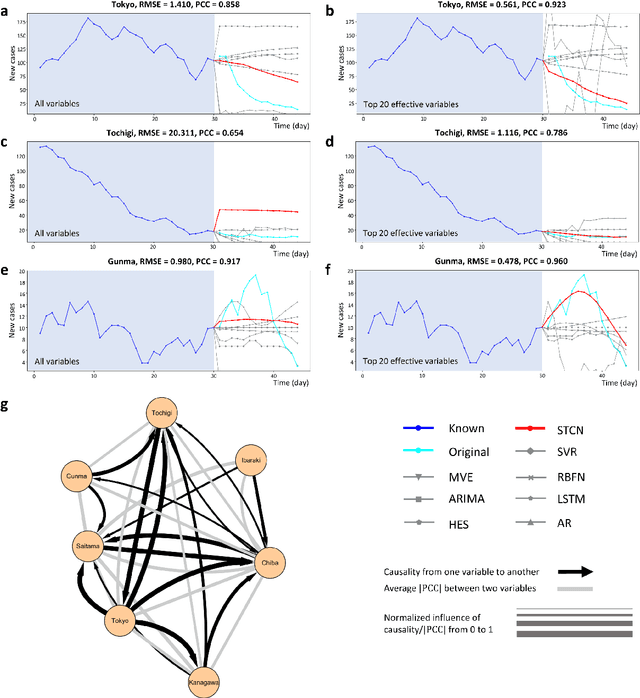
Making predictions in a robust way is not easy for nonlinear systems. In this work, a neural network computing framework, i.e., a spatiotemporal convolutional network (STCN), was developed to efficiently and accurately render a multistep-ahead prediction of a time series by employing a spatial-temporal information (STI) transformation. The STCN combines the advantages of both the temporal convolutional network (TCN) and the STI equation, which maps the high-dimensional/spatial data to the future temporal values of a target variable, thus naturally providing the prediction of the target variable. From the observed variables, the STCN also infers the causal factors of the target variable in the sense of Granger causality, which are in turn selected as effective spatial information to improve the prediction robustness. The STCN was successfully applied to both benchmark systems and real-world datasets, all of which show superior and robust performance in multistep-ahead prediction, even when the data were perturbed by noise. From both theoretical and computational viewpoints, the STCN has great potential in practical applications in artificial intelligence (AI) or machine learning fields as a model-free method based only on the observed data, and also opens a new way to explore the observed high-dimensional data in a dynamical manner for machine learning.
Multivariate Quantile Function Forecaster
Feb 23, 2022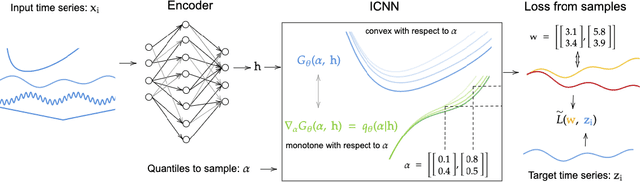
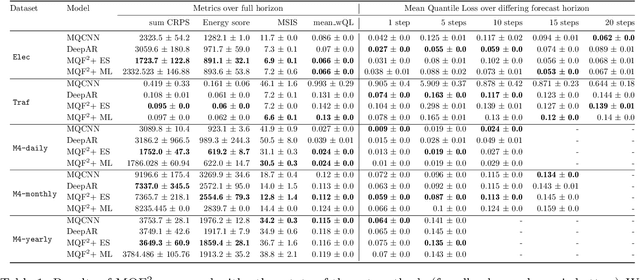
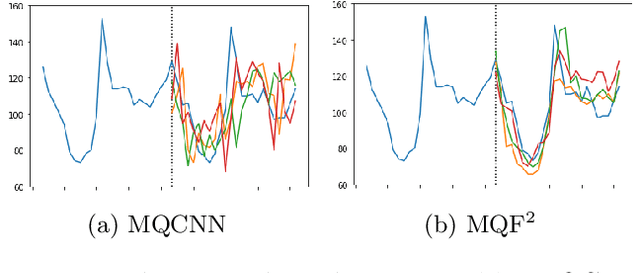
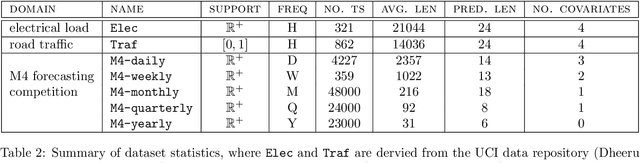
We propose Multivariate Quantile Function Forecaster (MQF$^2$), a global probabilistic forecasting method constructed using a multivariate quantile function and investigate its application to multi-horizon forecasting. Prior approaches are either autoregressive, implicitly capturing the dependency structure across time but exhibiting error accumulation with increasing forecast horizons, or multi-horizon sequence-to-sequence models, which do not exhibit error accumulation, but also do typically not model the dependency structure across time steps. MQF$^2$ combines the benefits of both approaches, by directly making predictions in the form of a multivariate quantile function, defined as the gradient of a convex function which we parametrize using input-convex neural networks. By design, the quantile function is monotone with respect to the input quantile levels and hence avoids quantile crossing. We provide two options to train MQF$^2$: with energy score or with maximum likelihood. Experimental results on real-world and synthetic datasets show that our model has comparable performance with state-of-the-art methods in terms of single time step metrics while capturing the time dependency structure.
Unified Chinese License Plate Detection and Recognition with High Efficiency
May 07, 2022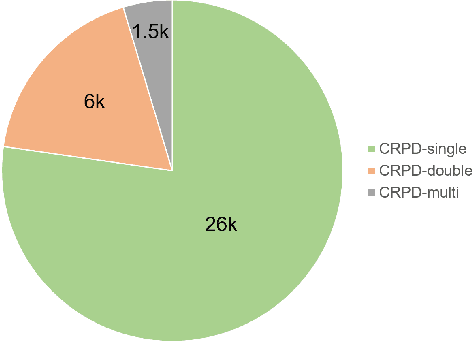
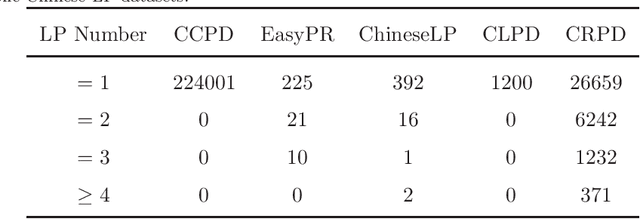

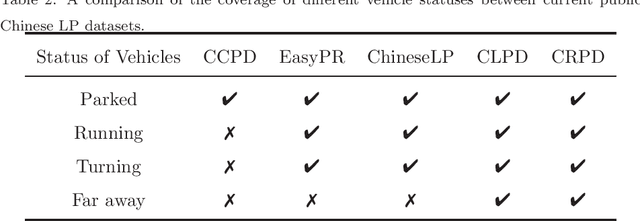
Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.
Time Division Multiplexing: From a Co-Prime Sampling Point of View
Jun 01, 2021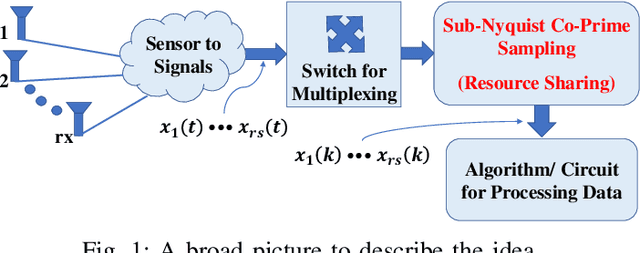
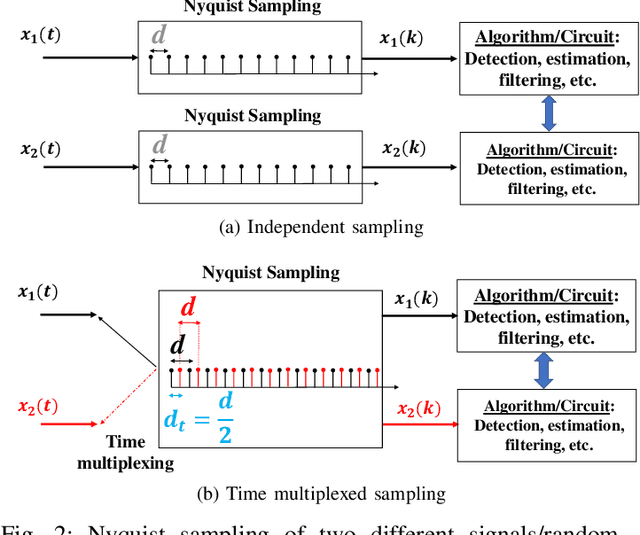

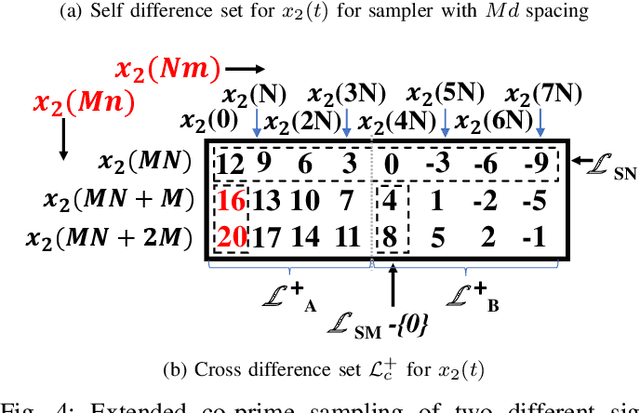
Co-prime sampling is a strategy for acquiring the signal below the Nyquist rate. The prototype and extended co-prime samplers require two low rate sub-samplers. One of the sub-samplers in the extended co-prime scheme is not utilized for every alternate co-prime period. Therefore, this paper proposes a time multiplexing strategy to utilize the vacant slots. It describes the deviation from the existing theory. Closed-form expressions for weight functions are provided. Acquisition of two signals is described with three samplers as well as two samplers. A generalized structure is also proposed with an extremely sparse co-prime sampling strategy.
Active Source Free Domain Adaptation
May 22, 2022
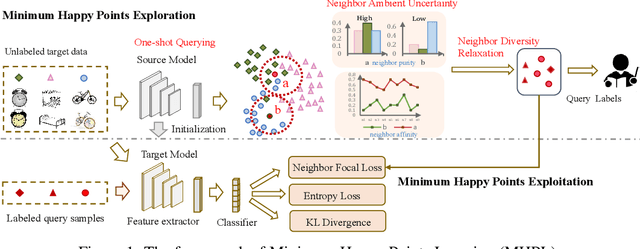

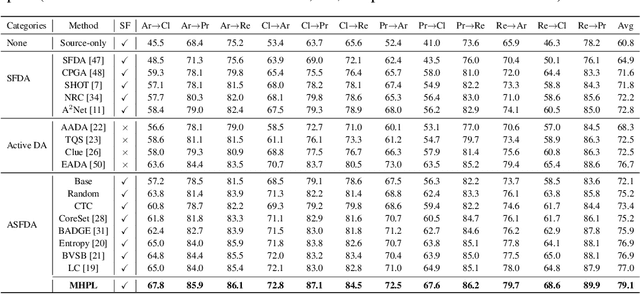
Source free domain adaptation (SFDA) aims to transfer a trained source model to the unlabeled target domain without accessing the source data. However, the SFDA setting faces an effect bottleneck due to the absence of source data and target supervised information, as evidenced by the limited performance gains of newest SFDA methods. In this paper, for the first time, we introduce a more practical scenario called active source free domain adaptation (ASFDA) that permits actively selecting a few target data to be labeled by experts. To achieve that, we first find that those satisfying the properties of neighbor-chaotic, individual-different, and target-like are the best points to select, and we define them as the minimum happy (MH) points. We then propose minimum happy points learning (MHPL) to actively explore and exploit MH points. We design three unique strategies: neighbor ambient uncertainty, neighbor diversity relaxation, and one-shot querying, to explore the MH points. Further, to fully exploit MH points in the learning process, we design a neighbor focal loss that assigns the weighted neighbor purity to the cross-entropy loss of MH points to make the model focus more on them. Extensive experiments verify that MHPL remarkably exceeds the various types of baselines and achieves significant performance gains at a small cost of labeling.
ArrowGAN : Learning to Generate Videos by Learning Arrow of Time
Jan 11, 2021

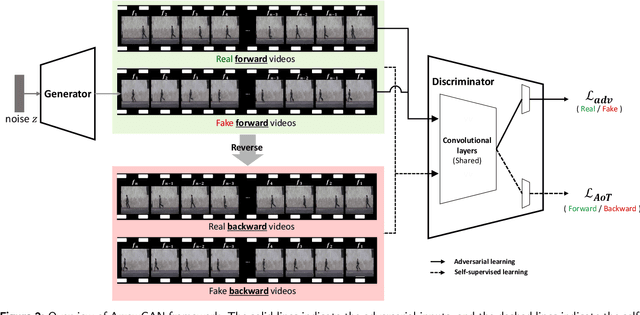

Training GANs on videos is even more sophisticated than on images because videos have a distinguished dimension: time. While recent methods designed a dedicated architecture considering time, generated videos are still far from indistinguishable from real videos. In this paper, we introduce ArrowGAN framework, where the discriminators learns to classify arrow of time as an auxiliary task and the generators tries to synthesize forward-running videos. We argue that the auxiliary task should be carefully chosen regarding the target domain. In addition, we explore categorical ArrowGAN with recent techniques in conditional image generation upon ArrowGAN framework, achieving the state-of-the-art performance on categorical video generation. Our extensive experiments validate the effectiveness of arrow of time as a self-supervisory task, and demonstrate that all our components of categorical ArrowGAN lead to the improvement regarding video inception score and Frechet video distance on three datasets: Weizmann, UCFsports, and UCF-101.