 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improved Real-Time Monocular SLAM Using Semantic Segmentation on Selective Frames
Apr 30, 2021
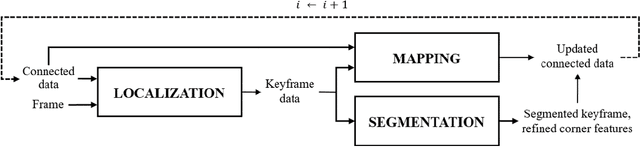
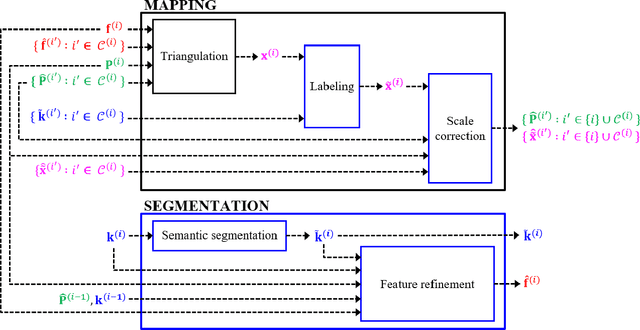
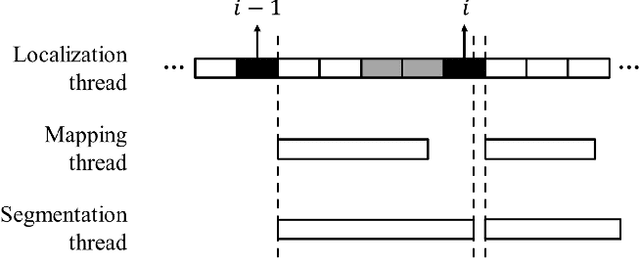
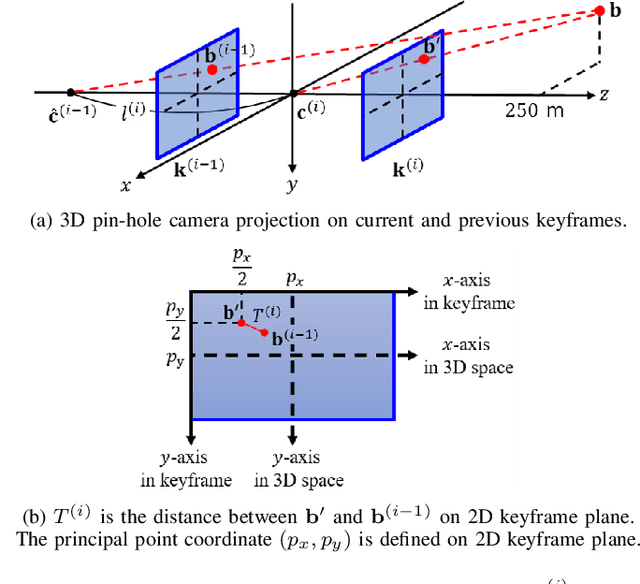
Monocular simultaneous localization and mapping (SLAM) is emerging in advanced driver assistance systems and autonomous driving, because a single camera is cheap and easy to install. Conventional monocular SLAM has two major challenges leading inaccurate localization and mapping. First, it is challenging to estimate scales in localization and mapping. Second, conventional monocular SLAM uses inappropriate mapping factors such as dynamic objects and low-parallax ares in mapping. This paper proposes an improved real-time monocular SLAM that resolves the aforementioned challenges by efficiently using deep learning-based semantic segmentation. To achieve the real-time execution of the proposed method, we apply semantic segmentation only to downsampled keyframes in parallel with mapping processes. In addition, the proposed method corrects scales of camera poses and three-dimensional (3D) points, using estimated ground plane from road-labeled 3D points and the real camera height. The proposed method also removes inappropriate corner features labeled as moving objects and low parallax areas. Experiments with six video sequences demonstrate that the proposed monocular SLAM system achieves significantly more accurate trajectory tracking accuracy compared to state-of-the-art monocular SLAM and comparable trajectory tracking accuracy compared to state-of-the-art stereo SLAM.
Conditional Simulation Using Diffusion Schrödinger Bridges
Feb 27, 2022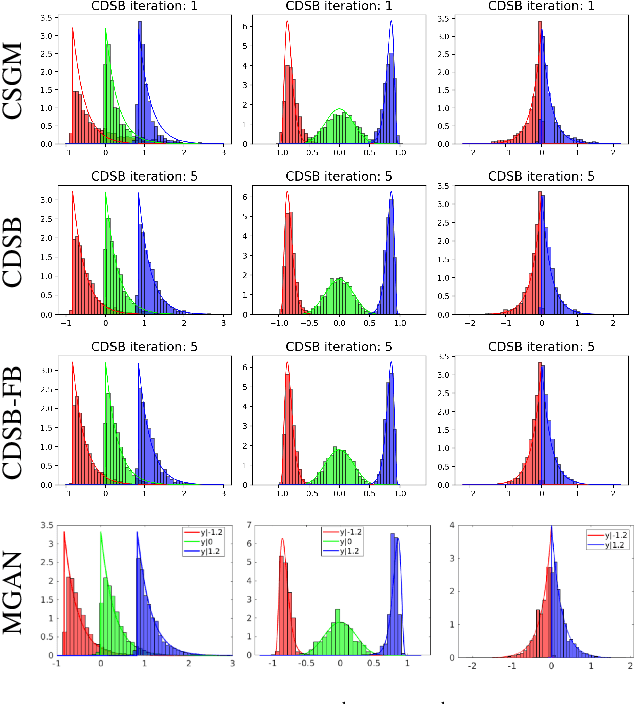


Denoising diffusion models have recently emerged as a powerful class of generative models. They provide state-of-the-art results, not only for unconditional simulation, but also when used to solve conditional simulation problems arising in a wide range of inverse problems such as image inpainting or deblurring. A limitation of these models is that they are computationally intensive at generation time as they require simulating a diffusion process over a long time horizon. When performing unconditional simulation, a Schr\"odinger bridge formulation of generative modeling leads to a theoretically grounded algorithm shortening generation time which is complementary to other proposed acceleration techniques. We extend here the Schr\"odinger bridge framework to conditional simulation. We demonstrate this novel methodology on various applications including image super-resolution and optimal filtering for state-space models.
V4D: Voxel for 4D Novel View Synthesis
May 28, 2022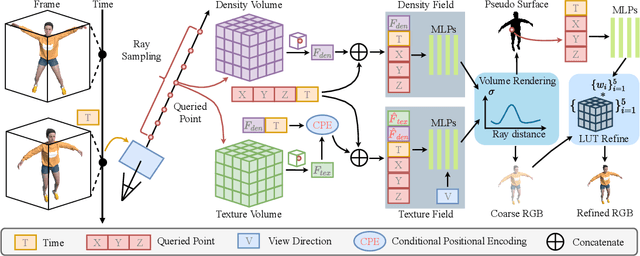
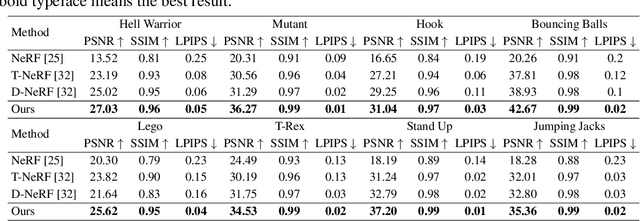
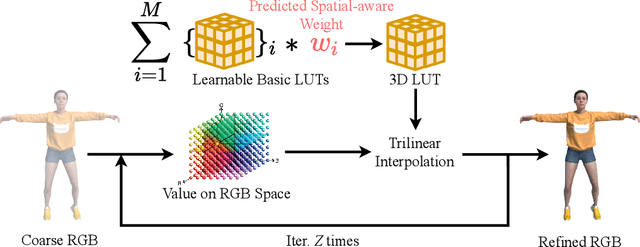
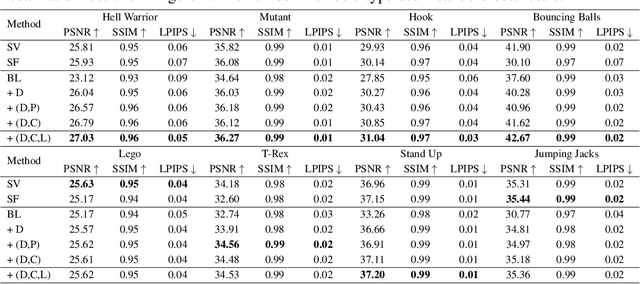
Neural radiance fields have made a remarkable breakthrough in the novel view synthesis task at the 3D static scene. However, for the 4D circumstance (e.g., dynamic scene), the performance of the existing method is still limited by the capacity of the neural network, typically in a multilayer perceptron network (MLP). In this paper, we present the method to model the 4D neural radiance field by the 3D voxel, short as V4D, where the 3D voxel has two formats. The first one is to regularly model the bounded 3D space and then use the sampled local 3D feature with the time index to model the density field and the texture field. The second one is in look-up tables (LUTs) format that is for the pixel-level refinement, where the pseudo-surface produced by the volume rendering is utilized as the guidance information to learn a 2D pixel-level refinement mapping. The proposed LUTs-based refinement module achieves the performance gain with a little computational cost and could serve as the plug-and-play module in the novel view synthesis task. Moreover, we propose a more effective conditional positional encoding toward the 4D data that achieves performance gain with negligible computational burdens. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance by a large margin. At last, the proposed V4D is also a computational-friendly method in both the training and testing phase, where we achieve 2 times faster in the training phase and 10 times faster in the inference phase compared with the state-of-the-art method.
Lagrangian Motion Magnification with Double Sparse Optical Flow Decomposition
Apr 15, 2022
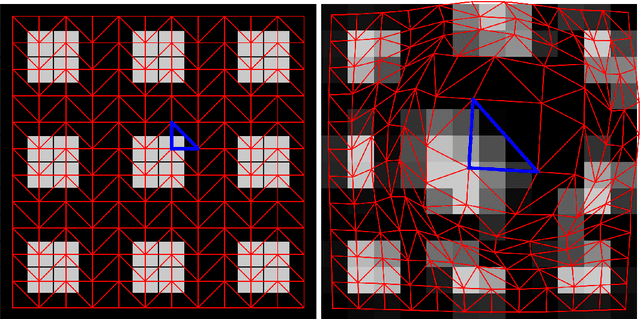
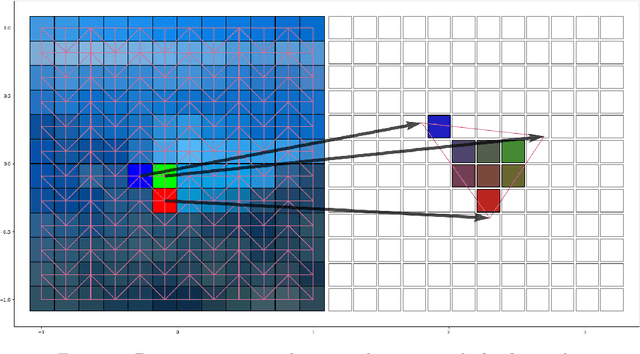
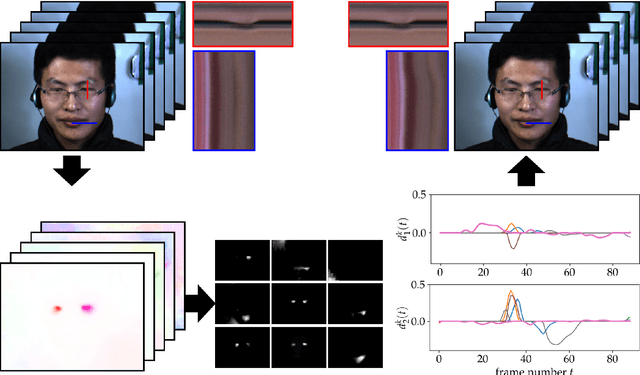
Motion magnification techniques aim at amplifying and hence revealing subtle motion in videos. There are basically two main approaches to reach this goal, namely via Eulerian or Lagrangian techniques. While the first one magnifies motion implicitly by operating directly on image pixels, the Lagrangian approach uses optical flow techniques to extract and amplify pixel trajectories. Microexpressions are fast and spatially small facial expressions that are difficult to detect. In this paper, we propose a novel approach for local Lagrangian motion magnification of facial micromovements. Our contribution is three-fold: first, we fine-tune the recurrent all-pairs field transforms for optical flows (RAFT) deep learning approach for faces by adding ground truth obtained from the variational dense inverse search (DIS) for optical flow algorithm applied to the CASME II video set of faces. This enables us to produce optical flows of facial videos in an efficient and sufficiently accurate way. Second, since facial micromovements are both local in space and time, we propose to approximate the optical flow field by sparse components both in space and time leading to a double sparse decomposition. Third, we use this decomposition to magnify micro-motions in specific areas of the face, where we introduce a new forward warping strategy using a triangular splitting of the image grid and barycentric interpolation of the RGB vectors at the corners of the transformed triangles. We demonstrate the very good performance of our approach by various examples.
An End-to-End Integrated Computation and Communication Architecture for Goal-oriented Networking: A Perspective on Live Surveillance Video
Apr 05, 2022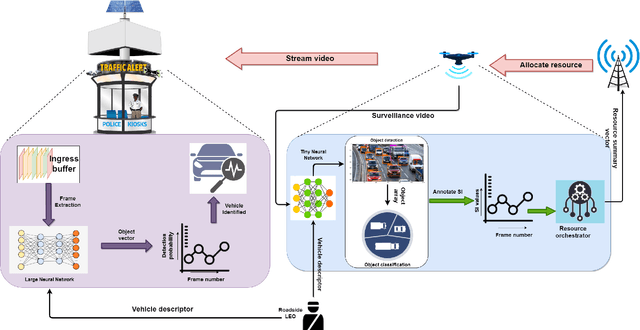
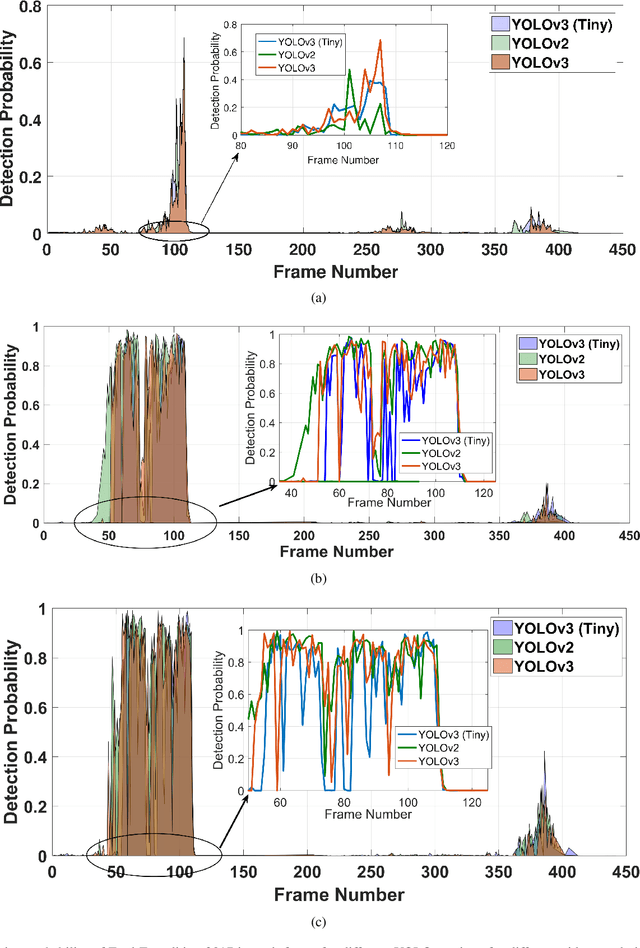
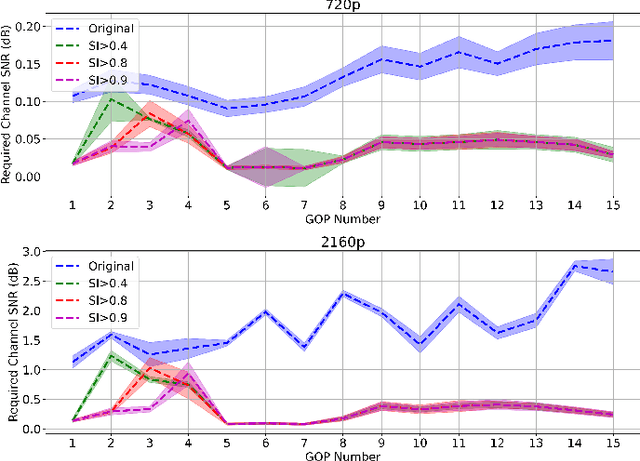
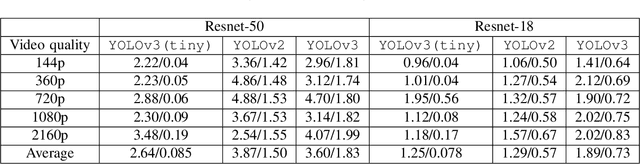
Real-time video surveillance has become a crucial technology for smart cities, made possible through the large-scale deployment of mobile and fixed video cameras. In this paper, we propose situation-aware streaming, for real-time identification of important events from live-feeds at the source rather than a cloud based analysis. For this, we first identify the frames containing a specific situation and assign them a high scale-of-importance (SI). The identification is made at the source using a tiny neural network (having a small number of hidden layers), which incurs a small computational resource, albeit at the cost of accuracy. The frames with a high SI value are then streamed with a certain required Signal-to-Noise-Ratio (SNR) to retain the frame quality, while the remaining ones are transmitted with a small SNR. The received frames are then analyzed using a deep neural network (with many hidden layers) to extract the situation accurately. We show that the proposed scheme is able to reduce the required power consumption of the transmitter by 38.5% for 2160p (UHD) video, while achieving a classification accuracy of 97.5%, for the given situation.
Neuro-Symbolic Artificial Intelligence (AI) for Intent based Semantic Communication
May 22, 2022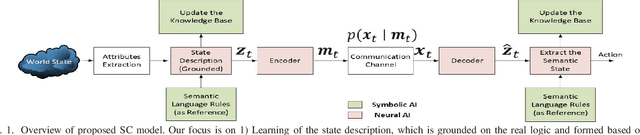
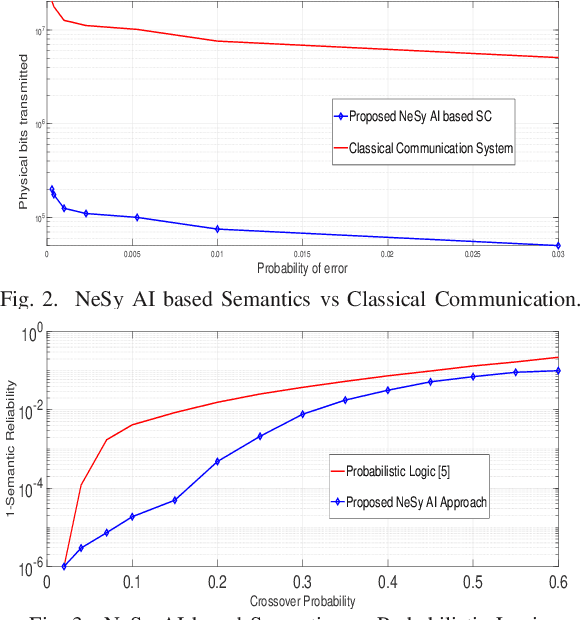
Intent-based networks that integrate sophisticated machine reasoning technologies will be a cornerstone of future wireless 6G systems. Intent-based communication requires the network to consider the semantics (meanings) and effectiveness (at end-user) of the data transmission. This is essential if 6G systems are to communicate reliably with fewer bits while simultaneously providing connectivity to heterogeneous users. In this paper, contrary to state of the art, which lacks explainability of data, the framework of neuro-symbolic artificial intelligence (NeSy AI) is proposed as a pillar for learning causal structure behind the observed data. In particular, the emerging concept of generative flow networks (GFlowNet) is leveraged for the first time in a wireless system to learn the probabilistic structure which generates the data. Further, a novel optimization problem for learning the optimal encoding and decoding functions is rigorously formulated with the intent of achieving higher semantic reliability. Novel analytical formulations are developed to define key metrics for semantic message transmission, including semantic distortion, semantic similarity, and semantic reliability. These semantic measure functions rely on the proposed definition of semantic content of the knowledge base and this information measure is reflective of the nodes' reasoning capabilities. Simulation results validate the ability to communicate efficiently (with less bits but same semantics) and significantly better compared to a conventional system which does not exploit the reasoning capabilities.
Optimal Prediction Intervals for Macroeconomic Time Series Using Chaos and NSGA II
Feb 23, 2021

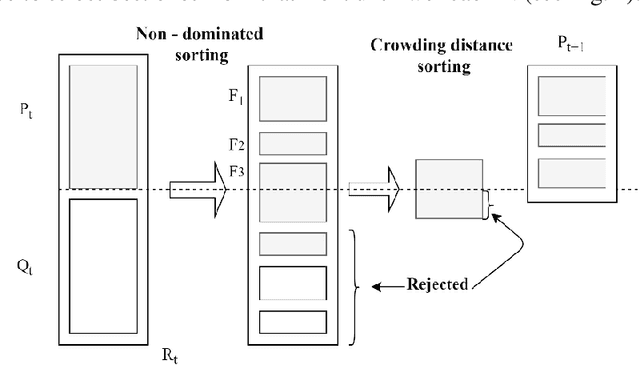

In a first-of-its-kind study, this paper proposes the formulation of constructing prediction intervals (PIs) in a time series as a bi-objective optimization problem and solves it with the help of Nondominated Sorting Genetic Algorithm (NSGA-II). We also proposed modeling the chaos present in the time series as a preprocessor in order to model the deterministic uncertainty present in the time series. Even though the proposed models are general in purpose, they are used here for quantifying the uncertainty in macroeconomic time series forecasting. Ideal PIs should be as narrow as possible while capturing most of the data points. Based on these two objectives, we formulated a bi-objective optimization problem to generate PIs in 2-stages, wherein reconstructing the phase space using Chaos theory (stage-1) is followed by generating optimal point prediction using NSGA-II and these point predictions are in turn used to obtain PIs (stage-2). We also proposed a 3-stage hybrid, wherein the 3rd stage invokes NSGA-II too in order to solve the problem of constructing PIs from the point prediction obtained in 2nd stage. The proposed models when applied to the macroeconomic time series, yielded better results in terms of both prediction interval coverage probability (PICP) and prediction interval average width (PIAW) compared to the state-of-the-art Lower Upper Bound Estimation Method (LUBE) with Gradient Descent (GD). The 3-stage model yielded better PICP compared to the 2-stage model but showed similar performance in PIAW with added computation cost of running NSGA-II second time.
Safely: Safe Stochastic Motion Planning Under Constrained Sensing via Duality
Mar 05, 2022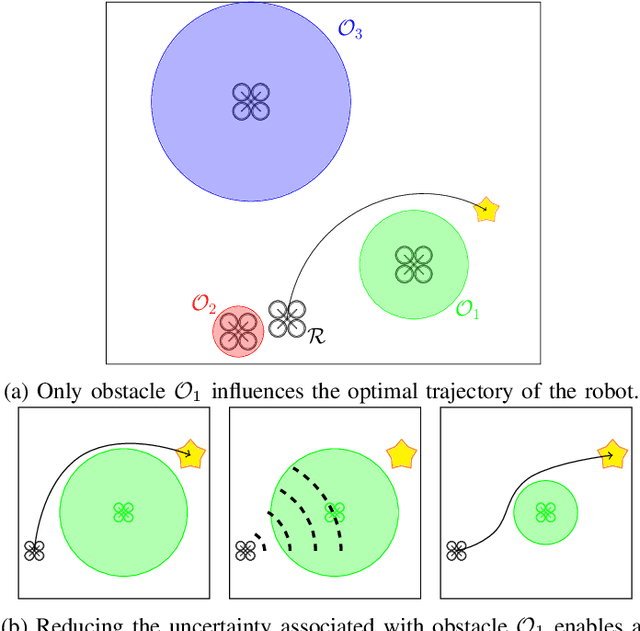
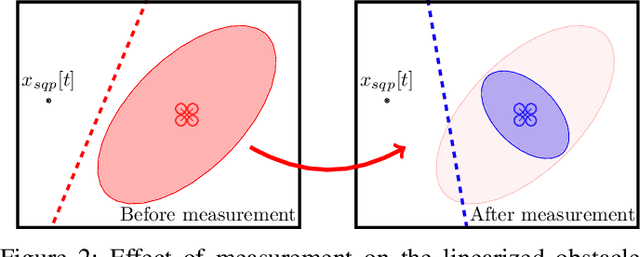

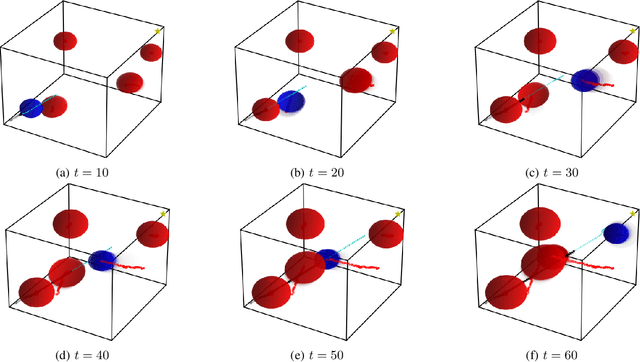
Consider a robot operating in an uncertain environment with stochastic, dynamic obstacles. Despite the clear benefits for trajectory optimization, it is often hard to keep track of each obstacle at every time step due to sensing and hardware limitations. We introduce the Safely motion planner, a receding-horizon control framework, that simultaneously synthesizes both a trajectory for the robot to follow as well as a sensor selection strategy that prescribes trajectory-relevant obstacles to measure at each time step while respecting the sensing constraints of the robot. We perform the motion planning using sequential quadratic programming, and prescribe obstacles to sense based on the duality information associated with the convex subproblems. We guarantee safety by ensuring that the probability of the robot colliding with any of the obstacles is below a prescribed threshold at every time step of the planned robot trajectory. We demonstrate the efficacy of the Safely motion planner through software and hardware experiments.
On the Use of Dimension Reduction or Signal Separation Methods for Nitrogen River Pollution Source Identification
Apr 27, 2022
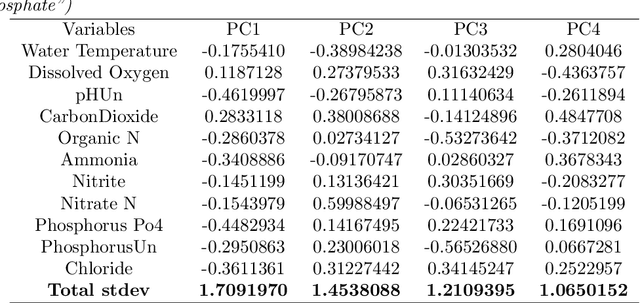
Identification of the current and expected future pollution sources to rivers is crucial for sound environmental management. For this purpose numerous approaches were proposed that can be clustered under physical based models, stable isotope analysis and mixing methods, mass balance methods, time series analysis, land cover analysis, and spatial statistics. Another extremely common method is Principal Component Analysis, as well as its modifications, such as Absolute Principal Component Score. they have been applied to the source identification problems for nitrogen entry to rivers. This manuscript is checking whether PCA can really be a powerful method to uncover nitrogen pollution sources considering its theoretical background and assumptions. Moreover, slightly similar techniques, Independent Component Analysis and Factor Analysis will also be considered.
Spatiotemporal convolutional network for time-series prediction and causal inference
Jul 03, 2021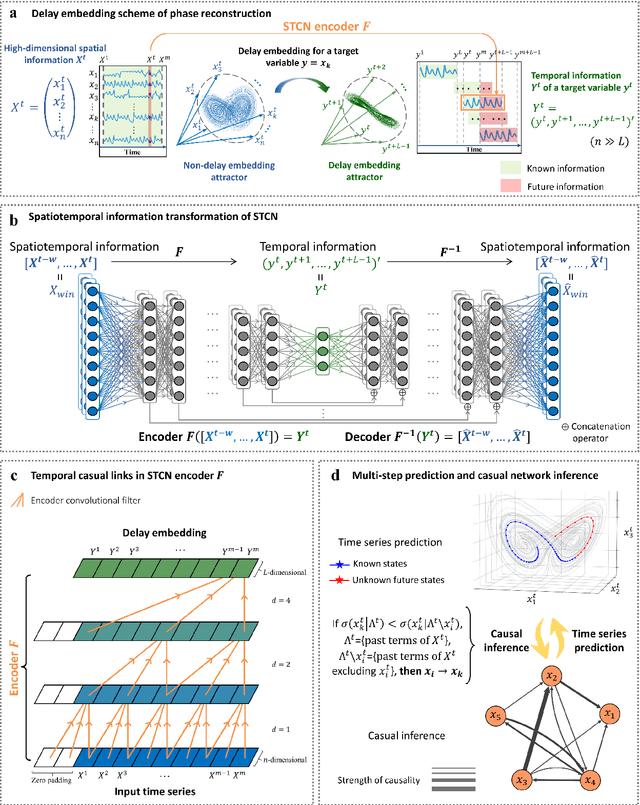
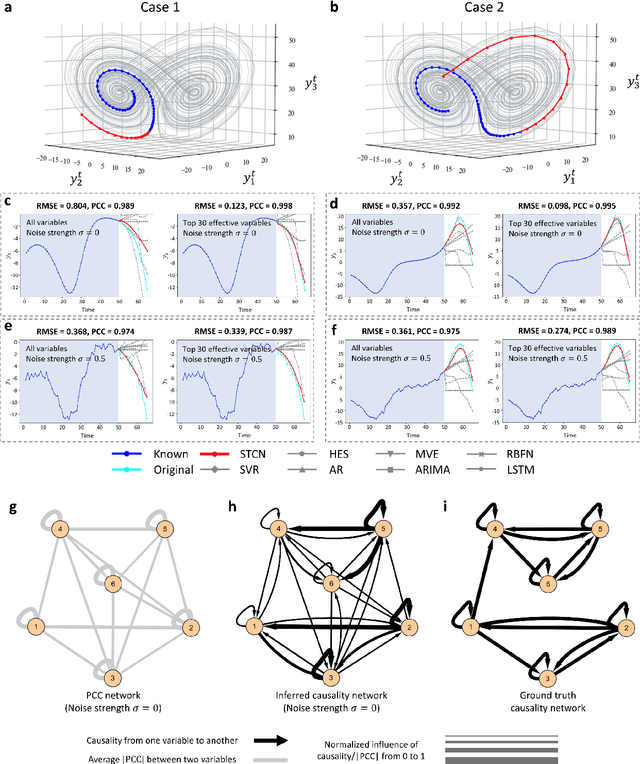
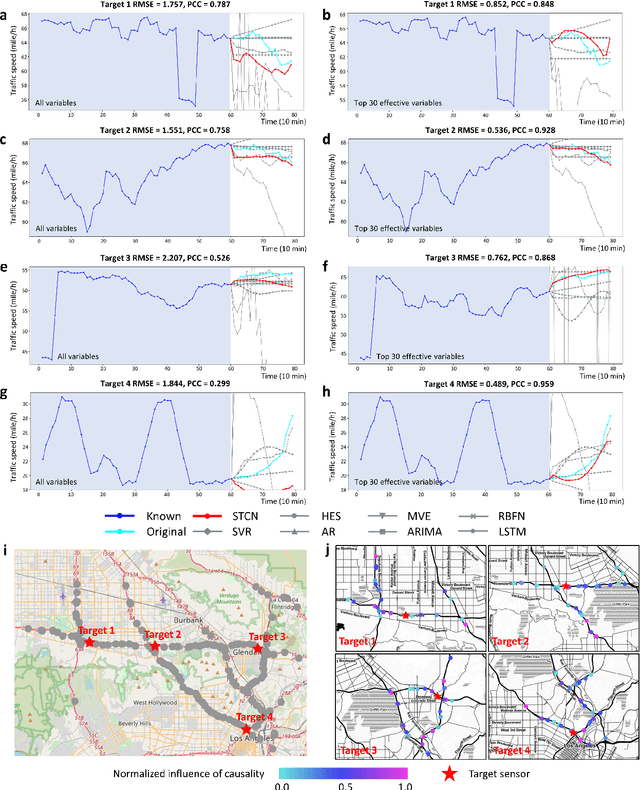
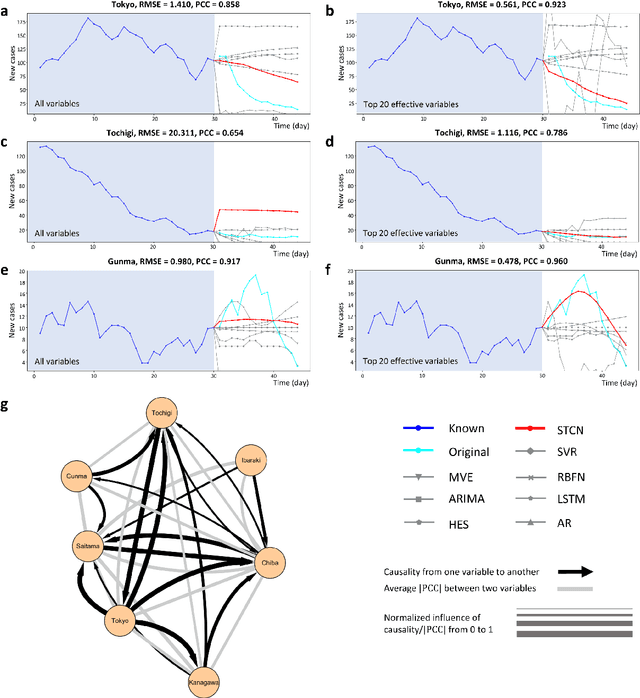
Making predictions in a robust way is not easy for nonlinear systems. In this work, a neural network computing framework, i.e., a spatiotemporal convolutional network (STCN), was developed to efficiently and accurately render a multistep-ahead prediction of a time series by employing a spatial-temporal information (STI) transformation. The STCN combines the advantages of both the temporal convolutional network (TCN) and the STI equation, which maps the high-dimensional/spatial data to the future temporal values of a target variable, thus naturally providing the prediction of the target variable. From the observed variables, the STCN also infers the causal factors of the target variable in the sense of Granger causality, which are in turn selected as effective spatial information to improve the prediction robustness. The STCN was successfully applied to both benchmark systems and real-world datasets, all of which show superior and robust performance in multistep-ahead prediction, even when the data were perturbed by noise. From both theoretical and computational viewpoints, the STCN has great potential in practical applications in artificial intelligence (AI) or machine learning fields as a model-free method based only on the observed data, and also opens a new way to explore the observed high-dimensional data in a dynamical manner for machine learning.