 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Attribution-based Explanations that Provide Recourse Cannot be Robust
May 31, 2022
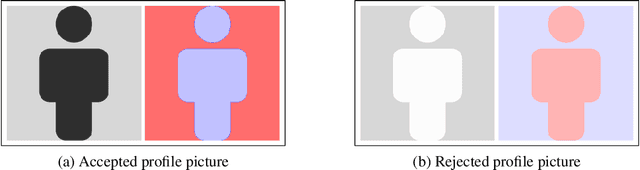
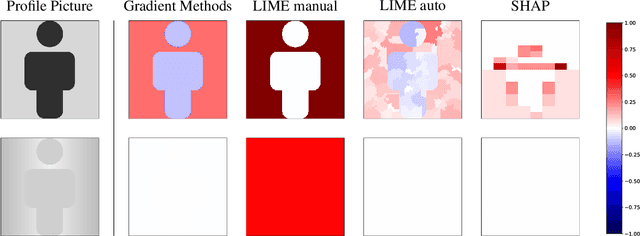

Different users of machine learning methods require different explanations, depending on their goals. To make machine learning accountable to society, one important goal is to get actionable options for recourse, which allow an affected user to change the decision $f(x)$ of a machine learning system by making limited changes to its input $x$. We formalize this by providing a general definition of recourse sensitivity, which needs to be instantiated with a utility function that describes which changes to the decisions are relevant to the user. This definition applies to local attribution methods, which attribute an importance weight to each input feature. It is often argued that such local attributions should be robust, in the sense that a small change in the input $x$ that is being explained, should not cause a large change in the feature weights. However, we prove formally that it is in general impossible for any single attribution method to be both recourse sensitive and robust at the same time. It follows that there must always exist counterexamples to at least one of these properties. We provide such counterexamples for several popular attribution methods, including LIME, SHAP, Integrated Gradients and SmoothGrad. Our results also cover counterfactual explanations, which may be viewed as attributions that describe a perturbation of $x$. We further discuss possible ways to work around our impossibility result, for instance by allowing the output to consist of sets with multiple attributions. Finally, we strengthen our impossibility result for the restricted case where users are only able to change a single attribute of x, by providing an exact characterization of the functions $f$ to which impossibility applies.
Temporal support vectors for spiking neuronal networks
May 28, 2022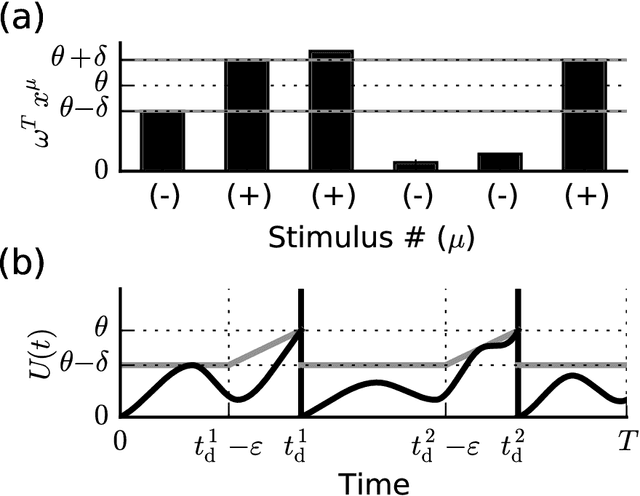
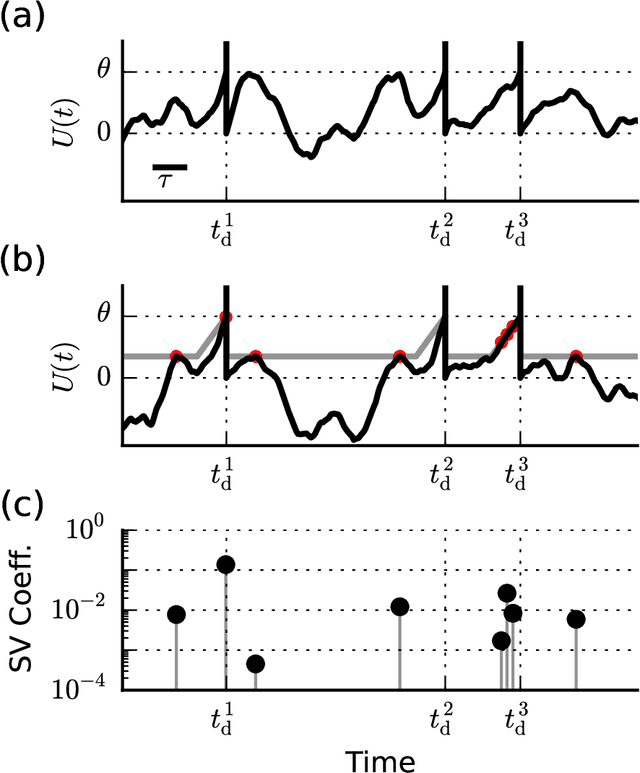
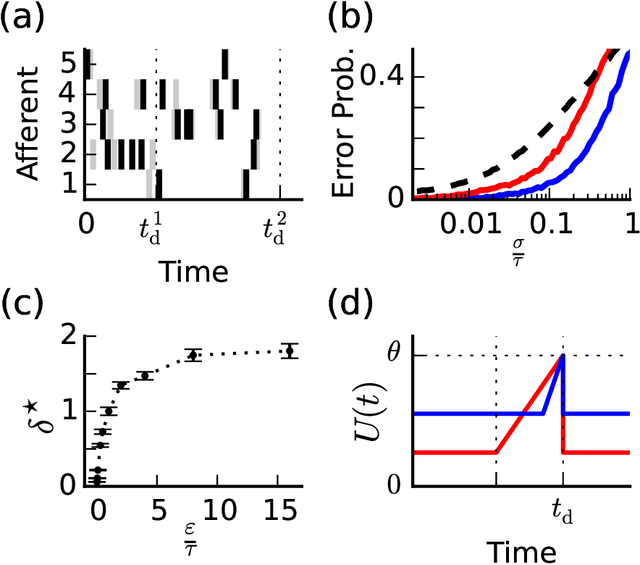
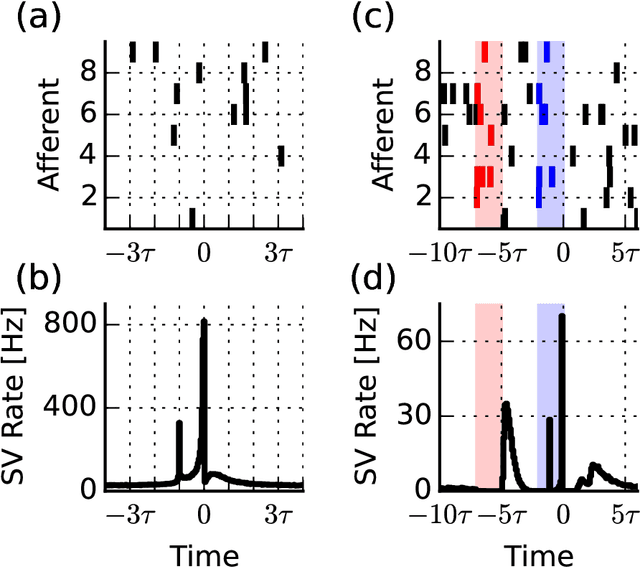
When neural circuits learn to perform a task, it is often the case that there are many sets of synaptic connections that are consistent with the task. However, only a small number of possible solutions are robust to noise in the input and are capable of generalizing their performance of the task to new inputs. Finding such good solutions is an important goal of learning systems in general and neuronal circuits in particular. For systems operating with static inputs and outputs, a well known approach to the problem is the large margin methods such as Support Vector Machines (SVM). By maximizing the distance of the data vectors from the decision surface, these solutions enjoy increased robustness to noise and enhanced generalization abilities. Furthermore, the use of the kernel method enables SVMs to perform classification tasks that require nonlinear decision surfaces. However, for dynamical systems with event based outputs, such as spiking neural networks and other continuous time threshold crossing systems, this optimality criterion is inapplicable due to the strong temporal correlations in their input and output. We introduce a novel extension of the static SVMs - The Temporal Support Vector Machine (T-SVM). The T-SVM finds a solution that maximizes a new construct - the dynamical margin. We show that T-SVM and its kernel extensions generate robust synaptic weight vectors in spiking neurons and enable their learning of tasks that require nonlinear spatial integration of synaptic inputs. We propose T-SVM with nonlinear kernels as a new model of the computational role of the nonlinearities and extensive morphologies of neuronal dendritic trees.
XLTime: A Cross-Lingual Knowledge Transfer Framework for Temporal Expression Extraction
May 03, 2022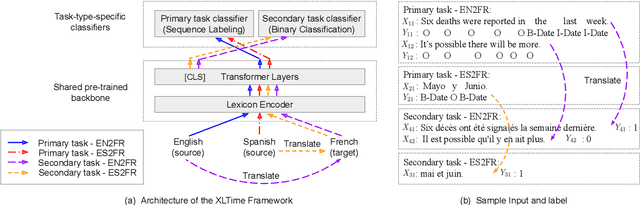
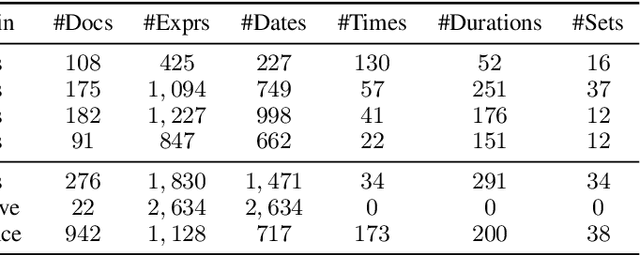
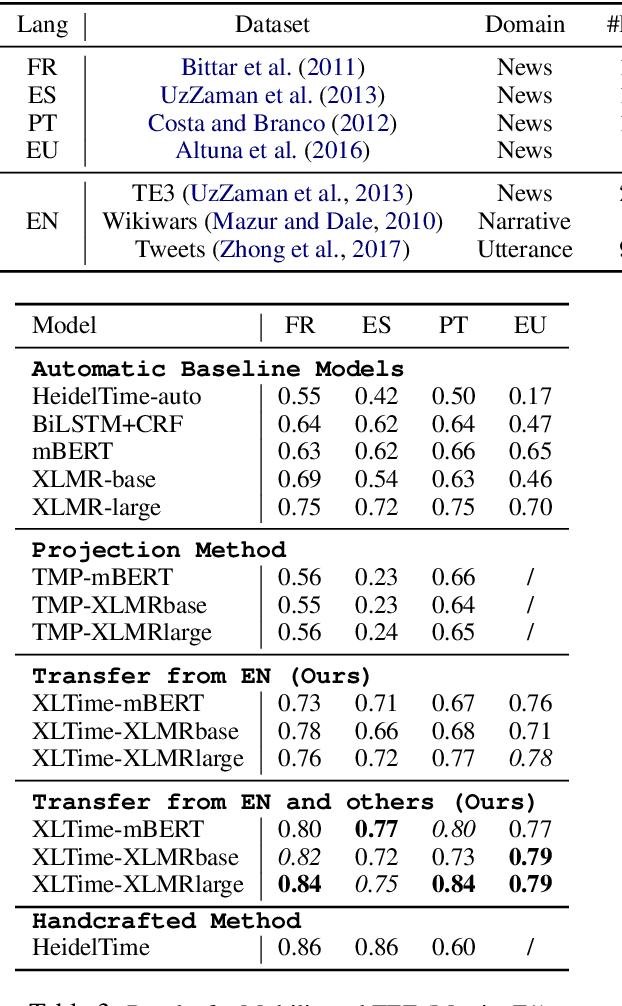
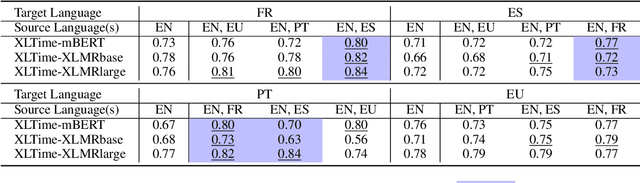
Temporal Expression Extraction (TEE) is essential for understanding time in natural language. It has applications in Natural Language Processing (NLP) tasks such as question answering, information retrieval, and causal inference. To date, work in this area has mostly focused on English as there is a scarcity of labeled data for other languages. We propose XLTime, a novel framework for multilingual TEE. XLTime works on top of pre-trained language models and leverages multi-task learning to prompt cross-language knowledge transfer both from English and within the non-English languages. XLTime alleviates problems caused by a shortage of data in the target language. We apply XLTime with different language models and show that it outperforms the previous automatic SOTA methods on French, Spanish, Portuguese, and Basque, by large margins. XLTime also closes the gap considerably on the handcrafted HeidelTime method.
Outage Analysis of Aerial Semi-Grant-Free NOMA Systems
May 12, 2022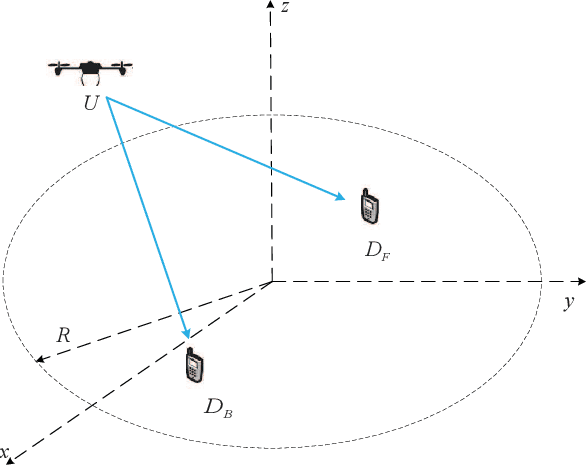
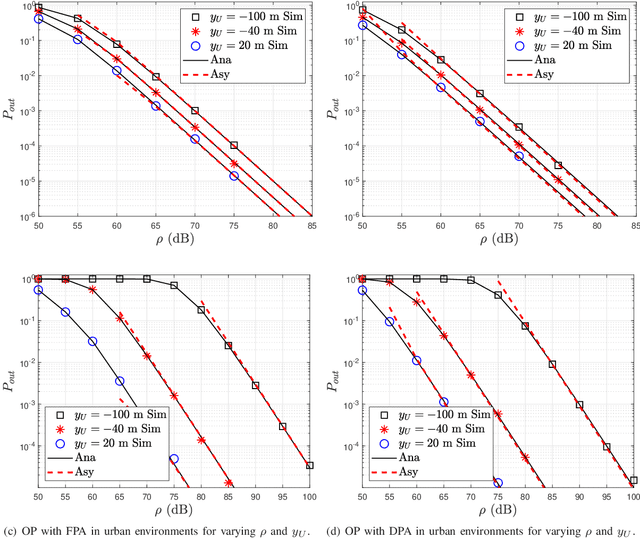
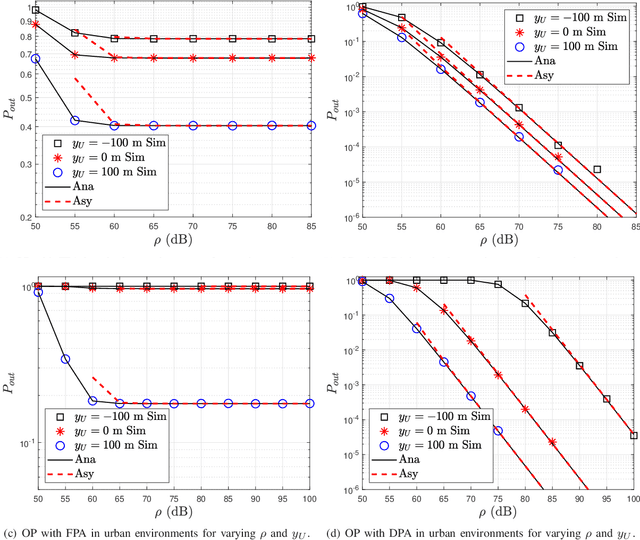

In this paper, we analyze the outage performance of unmanned aerial vehicles (UAVs)-enabled downlink non-orthogonal multiple access (NOMA) communication systems with the semi-grant-free (SGF) transmission scheme. A UAV provides coverage services for a grant-based (GB) user and one user is allowed to utilize the same channel resource opportunistically. The hybrid successive interference cancellation scheme is implemented in the downlink NOMA scenarios for the first time. The analytical expressions for the exact and asymptotic outage probability (OP) of the grant-free (GF) user are derived. The results demonstrate that no-zero diversity order can be achieved only under stringent conditions on users' quality of service requirements. Subsequently, we propose an efficient dynamic power allocation (DPA) scheme to relax such data rate constraints to address this issue. The analytical expressions for the exact and asymptotic OP of the GF user with the DPA scheme are derived. Finally, Monte Carlo simulation results are presented to validate the correctness of the derived analytical expressions and demonstrate the effects of the UAV's location and altitude on the OP of the GF user.
Transformer Tracking with Cyclic Shifting Window Attention
May 08, 2022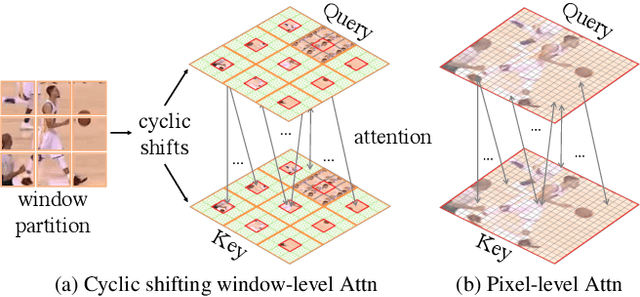
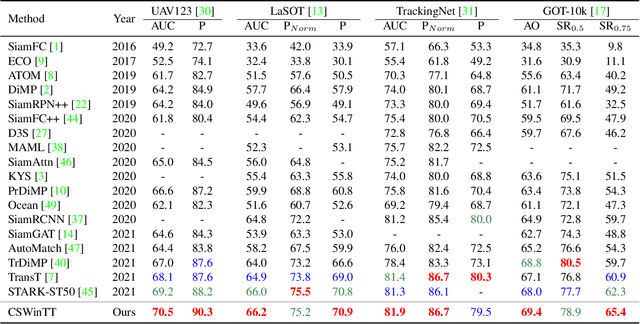
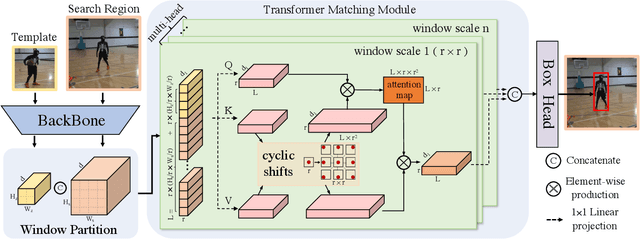
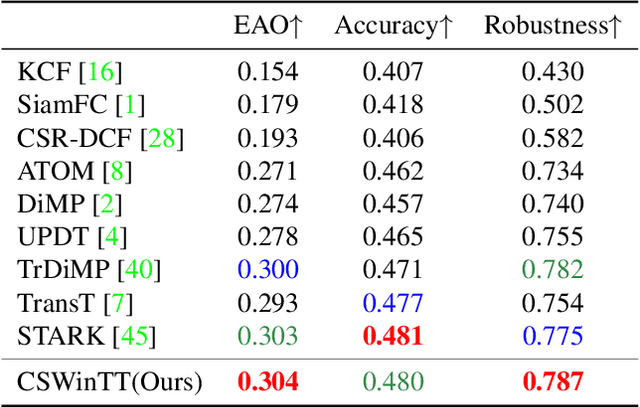
Transformer architecture has been showing its great strength in visual object tracking, for its effective attention mechanism. Existing transformer-based approaches adopt the pixel-to-pixel attention strategy on flattened image features and unavoidably ignore the integrity of objects. In this paper, we propose a new transformer architecture with multi-scale cyclic shifting window attention for visual object tracking, elevating the attention from pixel to window level. The cross-window multi-scale attention has the advantage of aggregating attention at different scales and generates the best fine-scale match for the target object. Furthermore, the cyclic shifting strategy brings greater accuracy by expanding the window samples with positional information, and at the same time saves huge amounts of computational power by removing redundant calculations. Extensive experiments demonstrate the superior performance of our method, which also sets the new state-of-the-art records on five challenging datasets, along with the VOT2020, UAV123, LaSOT, TrackingNet, and GOT-10k benchmarks.
Hippocluster: an efficient, hippocampus-inspired algorithm for graph clustering
May 19, 2022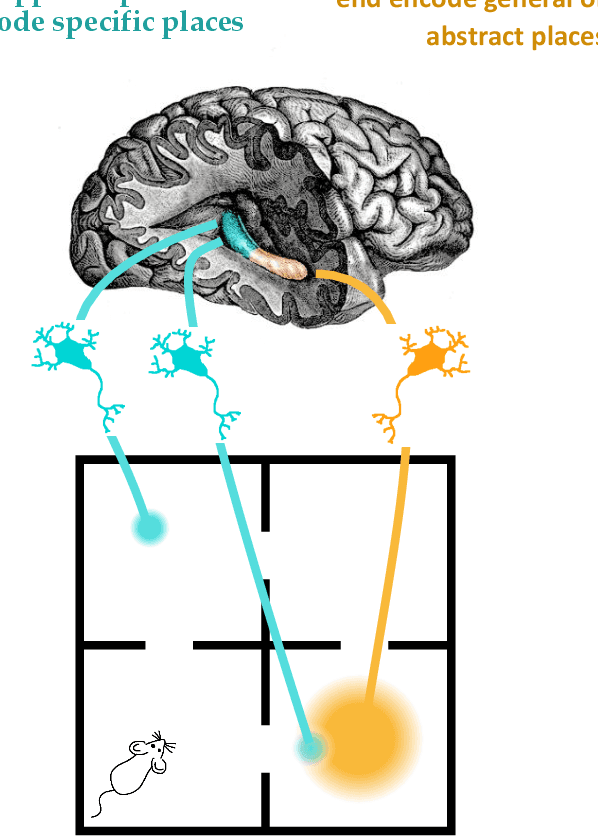
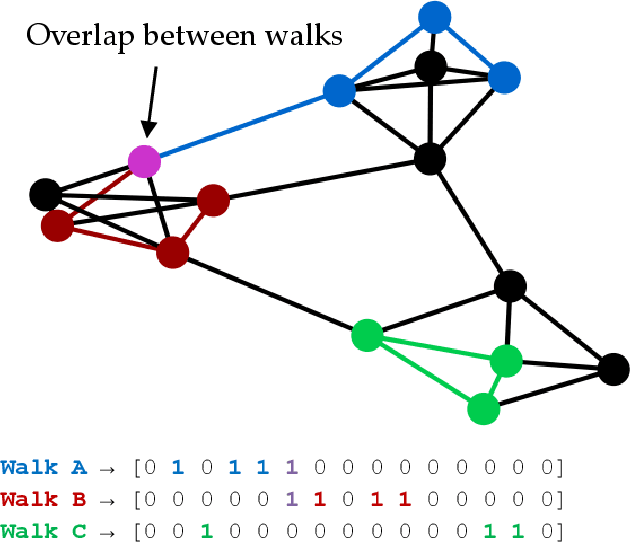
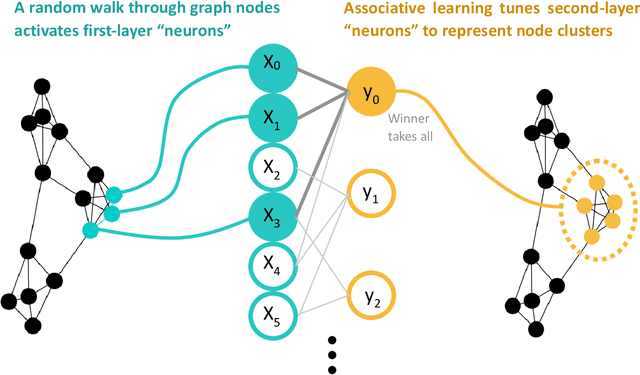
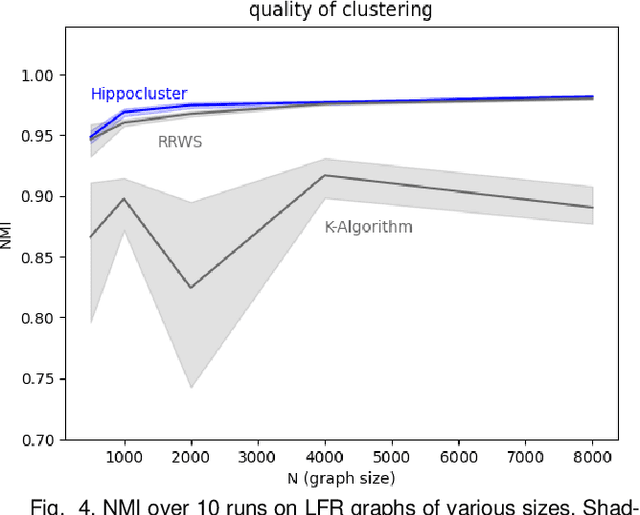
Random walks can reveal communities or clusters in networks, because they are more likely to stay within a cluster than leave it. Thus, one family of community detection algorithms uses random walks to measure distance between pairs of nodes in various ways, and then applies K-Means or other generic clustering methods to these distances. Interestingly, information processing in the brain may suggest a simpler method of learning clusters directly from random walks. Drawing inspiration from the hippocampus, we describe a simple two-layer neural learning framework. Neurons in one layer are associated with graph nodes and simulate random walks. These simulations cause neurons in the second layer to become tuned to graph clusters through simple associative learning. We show that if these neuronal interactions are modelled a particular way, the system is essentially a variant of K-Means clustering applied directly in the walk-space, bypassing the usual step of computing node distances/similarities. The result is an efficient graph clustering method. Biological information processing systems are known for high efficiency and adaptability. In tests on benchmark graphs, our framework demonstrates this high data-efficiency, low memory use, low complexity, and real-time adaptation to graph changes, while still achieving clustering quality comparable to other algorithms.
Reinforcement Learning with Intrinsic Affinity for Personalized Asset Management
Apr 20, 2022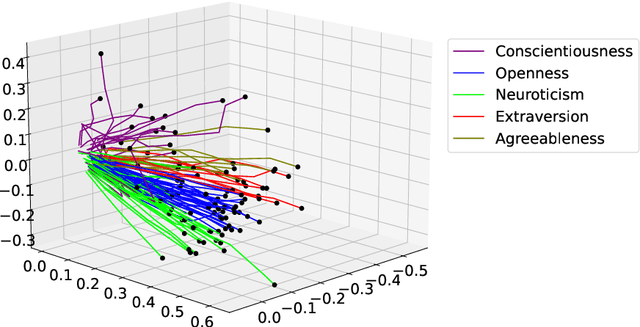
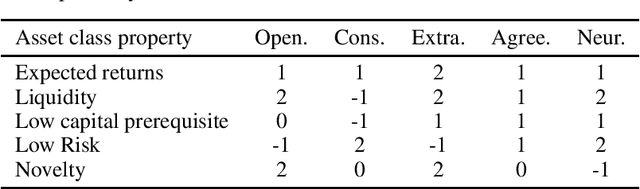
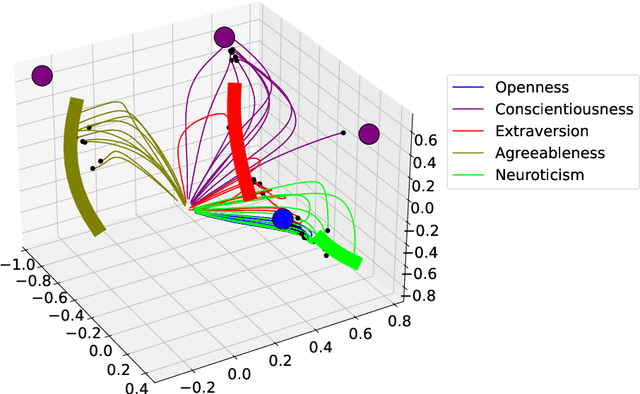
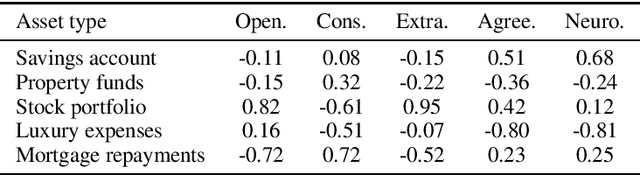
The common purpose of applying reinforcement learning (RL) to asset management is the maximization of profit. The extrinsic reward function used to learn an optimal strategy typically does not take into account any other preferences or constraints. We have developed a regularization method that ensures that strategies have global intrinsic affinities, i.e., different personalities may have preferences for certain assets which may change over time. We capitalize on these intrinsic policy affinities to make our RL model inherently interpretable. We demonstrate how RL agents can be trained to orchestrate such individual policies for particular personality profiles and still achieve high returns.
Multi-task Optimization Based Co-training for Electricity Consumption Prediction
May 31, 2022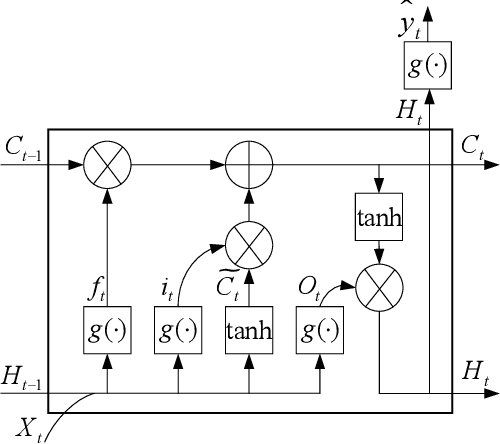
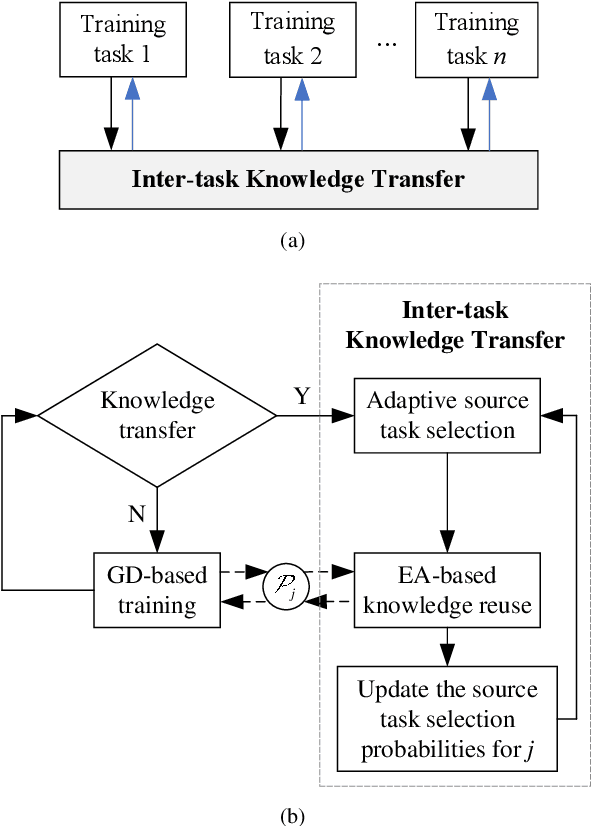
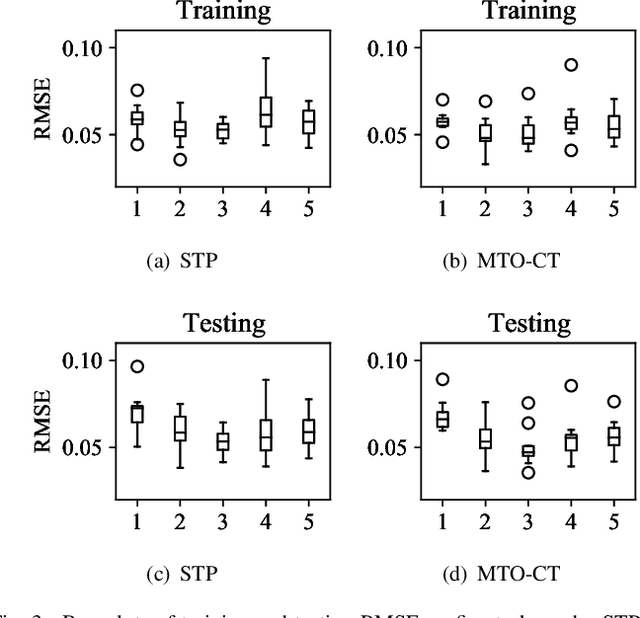
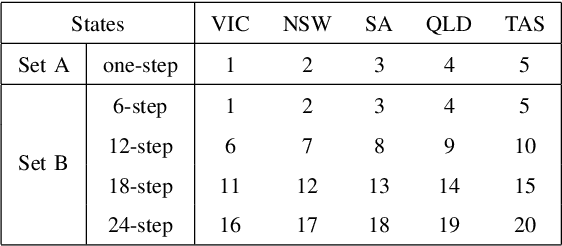
Real-world electricity consumption prediction may involve different tasks, e.g., prediction for different time steps ahead or different geo-locations. These tasks are often solved independently without utilizing some common problem-solving knowledge that could be extracted and shared among these tasks to augment the performance of solving each task. In this work, we propose a multi-task optimization (MTO) based co-training (MTO-CT) framework, where the models for solving different tasks are co-trained via an MTO paradigm in which solving each task may benefit from the knowledge gained from when solving some other tasks to help its solving process. MTO-CT leverages long short-term memory (LSTM) based model as the predictor where the knowledge is represented via connection weights and biases. In MTO-CT, an inter-task knowledge transfer module is designed to transfer knowledge between different tasks, where the most helpful source tasks are selected by using the probability matching and stochastic universal selection, and evolutionary operations like mutation and crossover are performed for reusing the knowledge from selected source tasks in a target task. We use electricity consumption data from five states in Australia to design two sets of tasks at different scales: a) one-step ahead prediction for each state (five tasks) and b) 6-step, 12-step, 18-step, and 24-step ahead prediction for each state (20 tasks). The performance of MTO-CT is evaluated on solving each of these two sets of tasks in comparison to solving each task in the set independently without knowledge sharing under the same settings, which demonstrates the superiority of MTO-CT in terms of prediction accuracy.
Introducing Non-Linearity into Quantum Generative Models
May 28, 2022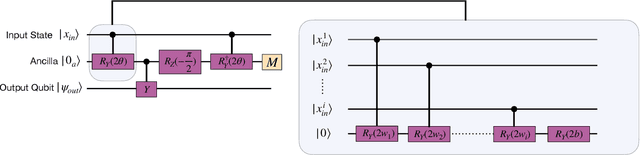
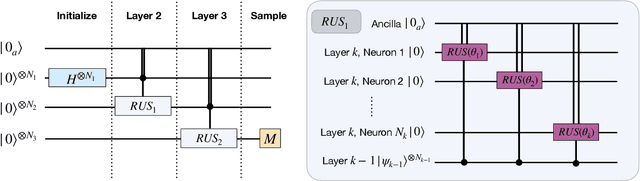
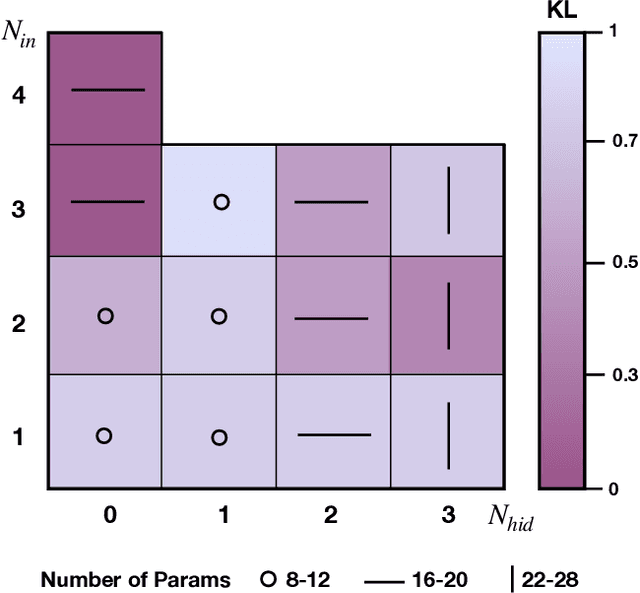
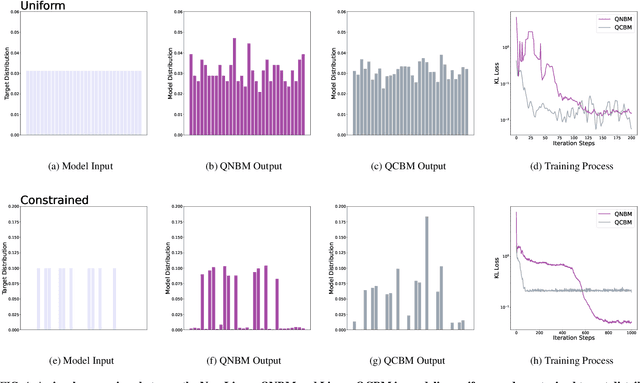
The evolution of an isolated quantum system is linear, and hence quantum algorithms are reversible, including those that utilize quantum circuits as generative machine learning models. However, some of the most successful classical generative models, such as those based on neural networks, involve highly non-linear and thus non-reversible dynamics. In this paper, we explore the effect of these dynamics in quantum generative modeling by introducing a model that adds non-linear activations via a neural network structure onto the standard Born Machine framework - the Quantum Neuron Born Machine (QNBM). To achieve this, we utilize a previously introduced Quantum Neuron subroutine, which is a repeat-until-success circuit with mid-circuit measurements and classical control. After introducing the QNBM, we investigate how its performance depends on network size, by training a 3-layer QNBM with 4 output neurons and various input and hidden layer sizes. We then compare our non-linear QNBM to the linear Quantum Circuit Born Machine (QCBM). We allocate similar time and memory resources to each model, such that the only major difference is the qubit overhead required by the QNBM. With gradient-based training, we show that while both models can easily learn a trivial uniform probability distribution, on a more challenging class of distributions, the QNBM achieves an almost 3x smaller error rate than a QCBM with a similar number of tunable parameters. We therefore show that non-linearity is a useful resource in quantum generative models, and we put forth the QNBM as a new model with good generative performance and potential for quantum advantage.
Binarizing by Classification: Is soft function really necessary?
May 16, 2022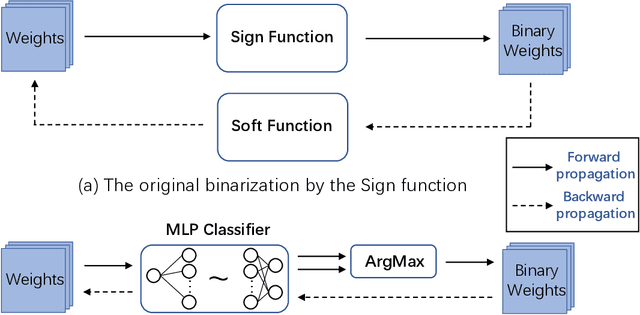

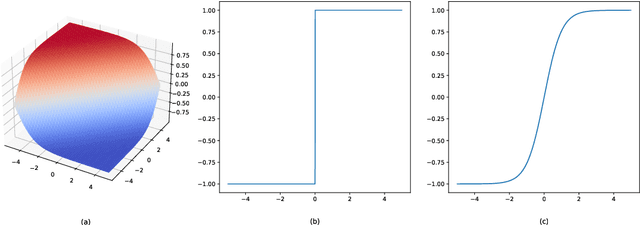
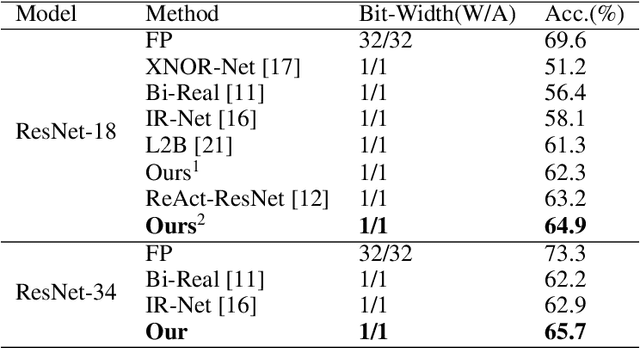
Binary neural network leverages the $Sign$ function to binarize real values, and its non-derivative property inevitably brings huge gradient errors during backpropagation. Although many hand-designed soft functions have been proposed to approximate gradients, their mechanism is not clear and there are still huge performance gaps between binary models and their full-precision counterparts. To address this, we propose to tackle network binarization as a binary classification problem and use a multi-layer perceptron (MLP) as the classifier. The MLP-based classifier can fit any continuous function theoretically and is adaptively learned to binarize networks and backpropagate gradients without any specific soft function. With this view, we further prove experimentally that even a simple linear function can outperform previous complex soft functions. Extensive experiments demonstrate that the proposed method yields surprising performance both in image classification and human pose estimation tasks. Specifically, we achieve 65.7% top-1 accuracy of ResNet-34 on ImageNet dataset, with an absolute improvement of 2.8%. When evaluating on the challenging Microsoft COCO keypoint dataset, the proposed method enables binary networks to achieve a mAP of 60.6 for the first time, on par with some full-precision methods.