 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Brachial Plexus Nerve Trunk Segmentation Using Deep Learning: A Comparative Study with Doctors' Manual Segmentation
May 17, 2022

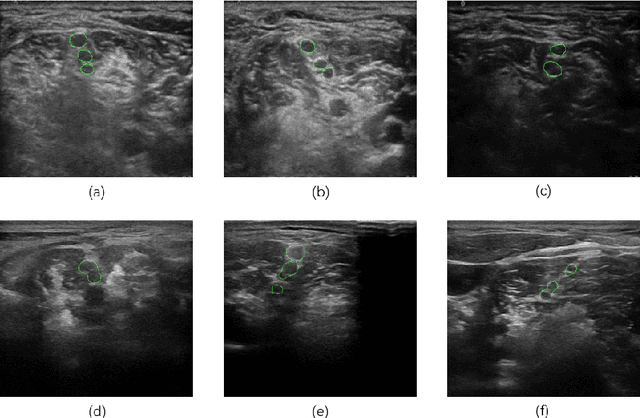
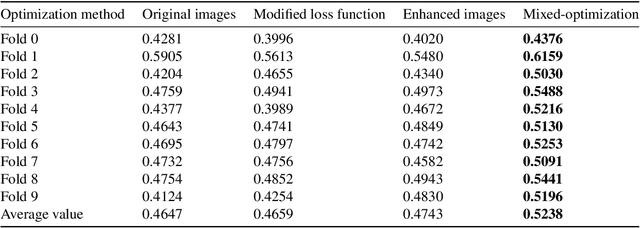
Ultrasound-guided nerve block anesthesia (UGNB) is a high-tech visual nerve block anesthesia method that can observe the target nerve and its surrounding structures, the puncture needle's advancement, and local anesthetics spread in real-time. The key in UGNB is nerve identification. With the help of deep learning methods, the automatic identification or segmentation of nerves can be realized, assisting doctors in completing nerve block anesthesia accurately and efficiently. Here, we establish a public dataset containing 320 ultrasound images of brachial plexus (BP). Three experienced doctors jointly produce the BP segmentation ground truth and label brachial plexus trunks. We design a brachial plexus segmentation system (BPSegSys) based on deep learning. BPSegSys achieves experienced-doctor-level nerve identification performance in various experiments. We evaluate BPSegSys' performance in terms of intersection-over-union (IoU), a commonly used performance measure for segmentation experiments. Considering three dataset groups in our established public dataset, the IoU of BPSegSys are 0.5238, 0.4715, and 0.5029, respectively, which exceed the IoU 0.5205, 0.4704, and 0.4979 of experienced doctors. In addition, we show that BPSegSys can help doctors identify brachial plexus trunks more accurately, with IoU improvement up to 27%, which has significant clinical application value.
Improved Real-Time Monocular SLAM Using Semantic Segmentation on Selective Frames
Apr 30, 2021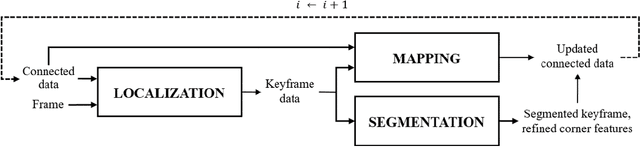
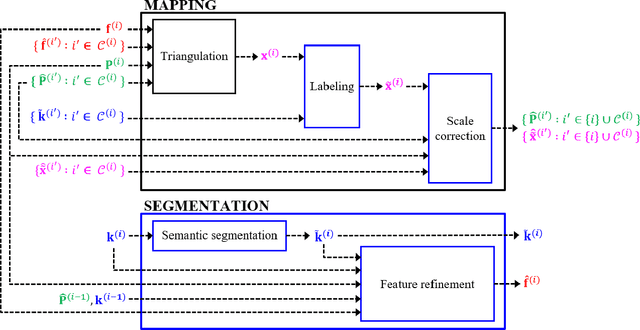
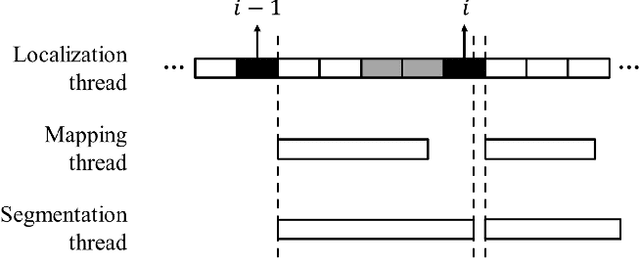
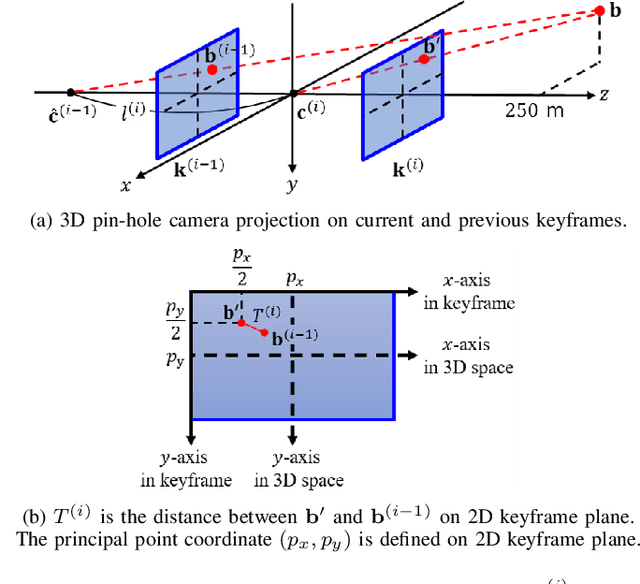
Monocular simultaneous localization and mapping (SLAM) is emerging in advanced driver assistance systems and autonomous driving, because a single camera is cheap and easy to install. Conventional monocular SLAM has two major challenges leading inaccurate localization and mapping. First, it is challenging to estimate scales in localization and mapping. Second, conventional monocular SLAM uses inappropriate mapping factors such as dynamic objects and low-parallax ares in mapping. This paper proposes an improved real-time monocular SLAM that resolves the aforementioned challenges by efficiently using deep learning-based semantic segmentation. To achieve the real-time execution of the proposed method, we apply semantic segmentation only to downsampled keyframes in parallel with mapping processes. In addition, the proposed method corrects scales of camera poses and three-dimensional (3D) points, using estimated ground plane from road-labeled 3D points and the real camera height. The proposed method also removes inappropriate corner features labeled as moving objects and low parallax areas. Experiments with six video sequences demonstrate that the proposed monocular SLAM system achieves significantly more accurate trajectory tracking accuracy compared to state-of-the-art monocular SLAM and comparable trajectory tracking accuracy compared to state-of-the-art stereo SLAM.
Modern strategies for time series regression
Oct 29, 2020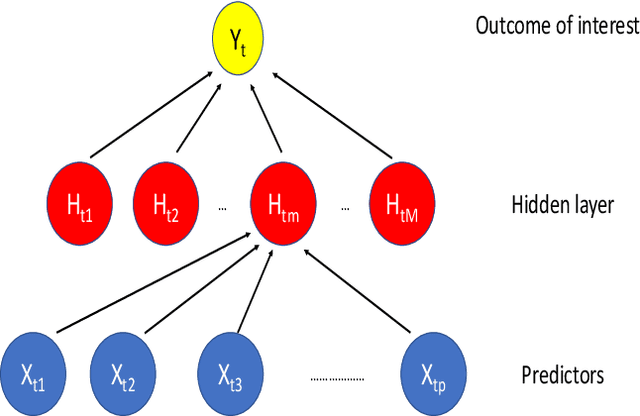
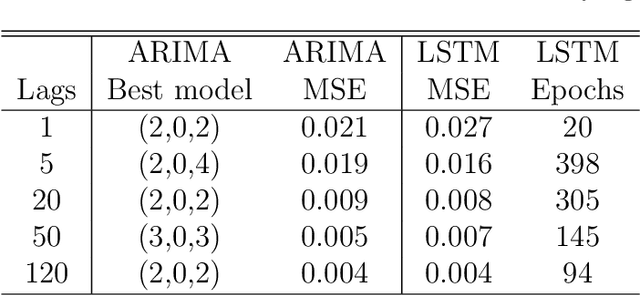

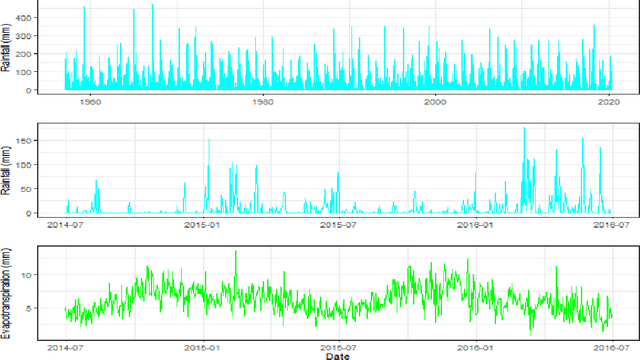
This paper discusses several modern approaches to regression analysis involving time series data where some of the predictor variables are also indexed by time. We discuss classical statistical approaches as well as methods that have been proposed recently in the machine learning literature. The approaches are compared and contrasted, and it will be seen that there are advantages and disadvantages to most currently available approaches. There is ample room for methodological developments in this area. The work is motivated by an application involving the prediction of water levels as a function of rainfall and other climate variables in an aquifer in eastern Australia.
AI Based Digital Twin Model for Cattle Caring
May 09, 2022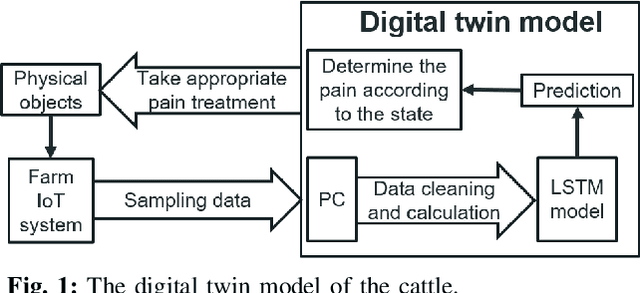
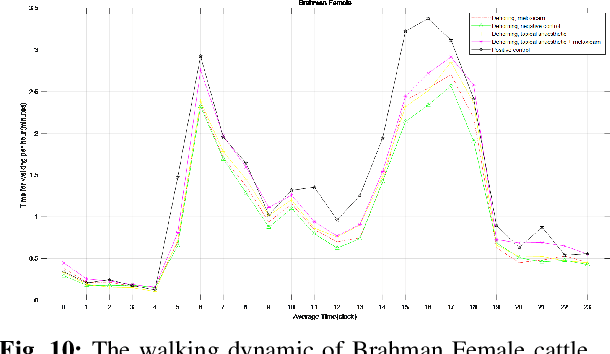
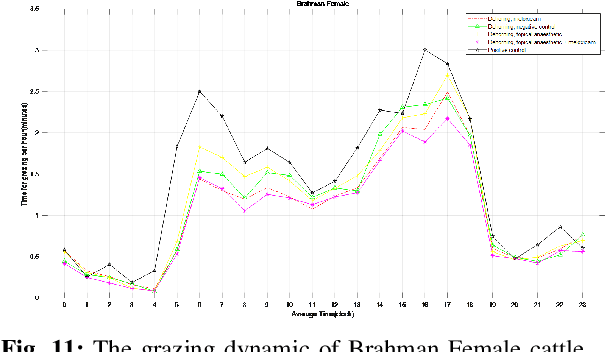
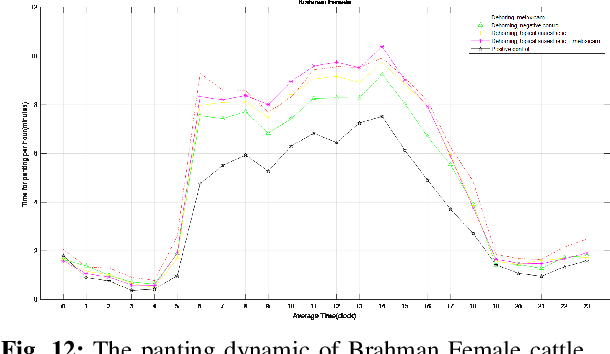
In this paper, we developed innovative digital twins of cattle status that are powered by artificial intelligence (AI). The work was built on a farm IoT system that remotely monitors and tracks the state of cattle. A digital twin model of cattle health based on Deep Learning (DL) was generated using the sensor data acquired from the farm IoT system. The health and physiological cycle of cattle can be monitored in real time, and the state of the next physiological cycle of cattle can be anticipated using this model. The basis of this work is the vast amount of data which is required to validate the legitimacy of the digital twins model. In terms of behavioural state, it was found that the cattle treated with a combination of topical anaesthetic and meloxicam exhibits the least pain reaction. The digital twins model developed in this work can be used to monitor the health of cattle
Beam Decoding with Controlled Patience
Apr 29, 2022
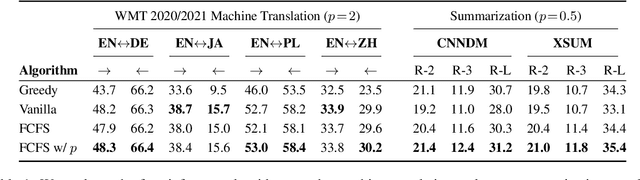


Text generation with beam search has proven successful in a wide range of applications. The commonly-used implementation of beam decoding follows a first come, first served heuristic: it keeps a set of already completed sequences over time steps and stops when the size of this set reaches the beam size. We introduce a patience factor, a simple modification to this decoding algorithm, that generalizes the stopping criterion and provides flexibility to the depth of search. Extensive empirical results demonstrate that the patience factor improves decoding performance of strong pretrained models on news text summarization and machine translation over diverse language pairs, with a negligible inference slowdown. Our approach only modifies one line of code and can be thus readily incorporated in any implementation.
FontNet: Closing the gap to font designer performance in font synthesis
May 13, 2022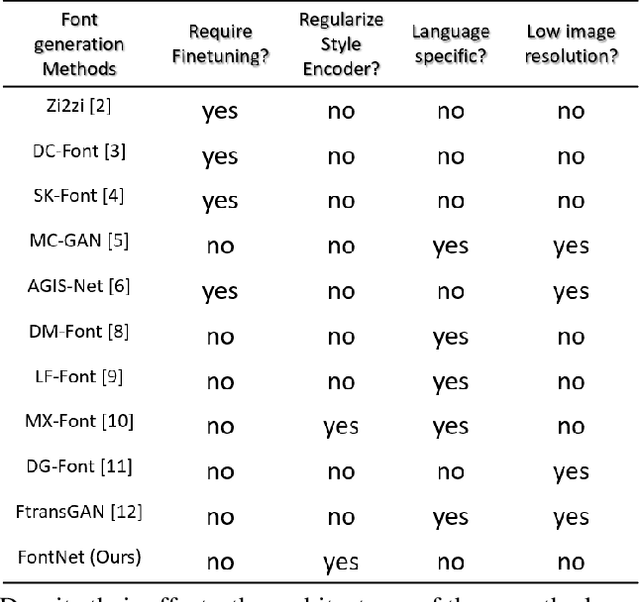
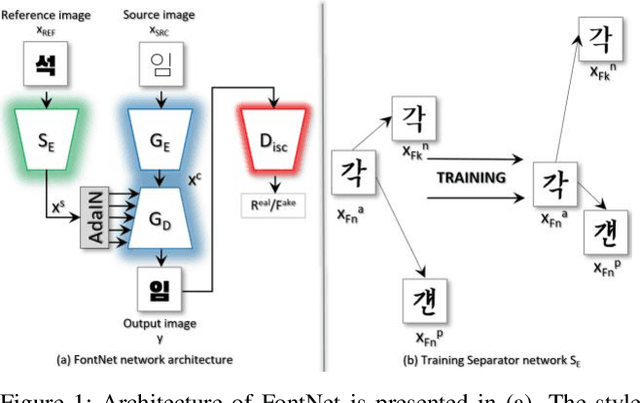
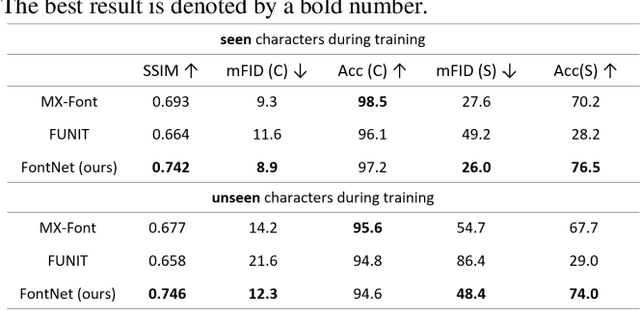

Font synthesis has been a very active topic in recent years because manual font design requires domain expertise and is a labor-intensive and time-consuming job. While remarkably successful, existing methods for font synthesis have major shortcomings; they require finetuning for unobserved font style with large reference images, the recent few-shot font synthesis methods are either designed for specific language systems or they operate on low-resolution images which limits their use. In this paper, we tackle this font synthesis problem by learning the font style in the embedding space. To this end, we propose a model, called FontNet, that simultaneously learns to separate font styles in the embedding space where distances directly correspond to a measure of font similarity, and translates input images into the given observed or unobserved font style. Additionally, we design the network architecture and training procedure that can be adopted for any language system and can produce high-resolution font images. Thanks to this approach, our proposed method outperforms the existing state-of-the-art font generation methods on both qualitative and quantitative experiments.
Time Series Data Imputation: A Survey on Deep Learning Approaches
Nov 23, 2020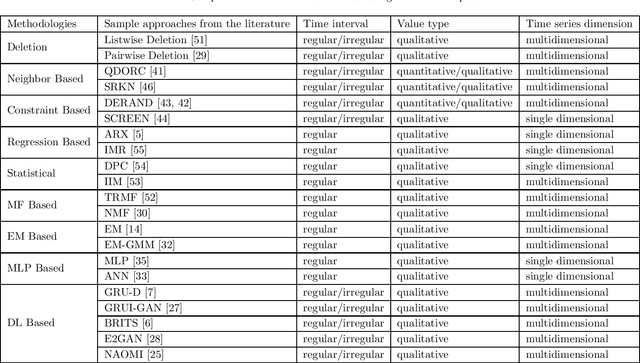
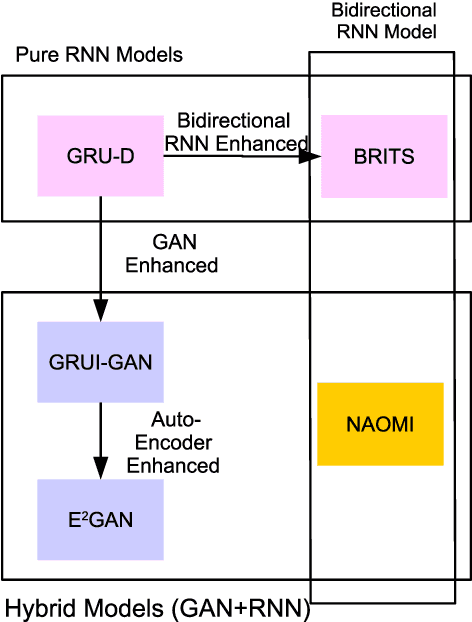

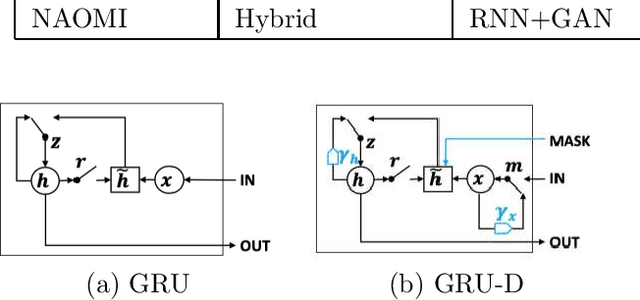
Time series are all around in real-world applications. However, unexpected accidents for example broken sensors or missing of the signals will cause missing values in time series, making the data hard to be utilized. It then does harm to the downstream applications such as traditional classification or regression, sequential data integration and forecasting tasks, thus raising the demand for data imputation. Currently, time series data imputation is a well-studied problem with different categories of methods. However, these works rarely take the temporal relations among the observations and treat the time series as normal structured data, losing the information from the time data. In recent, deep learning models have raised great attention. Time series methods based on deep learning have made progress with the usage of models like RNN, since it captures time information from data. In this paper, we mainly focus on time series imputation technique with deep learning methods, which recently made progress in this field. We will review and discuss their model architectures, their pros and cons as well as their effects to show the development of the time series imputation methods.
Electricity Price Forecasting: The Dawn of Machine Learning
Apr 02, 2022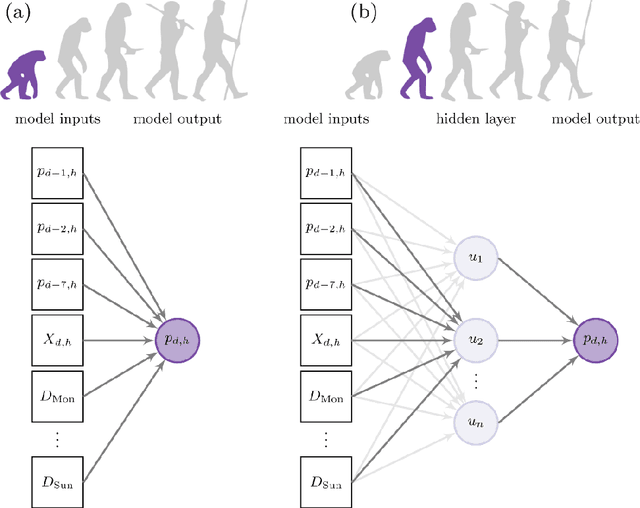
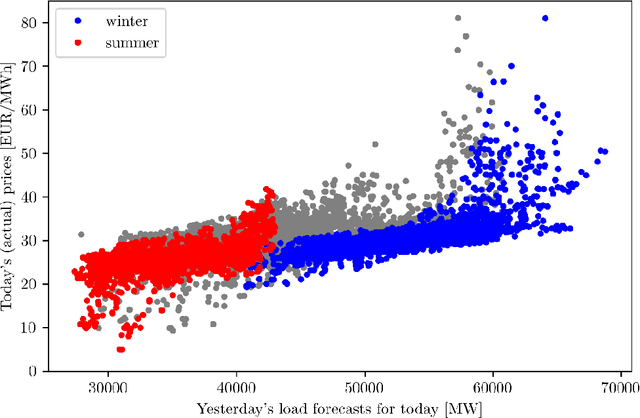
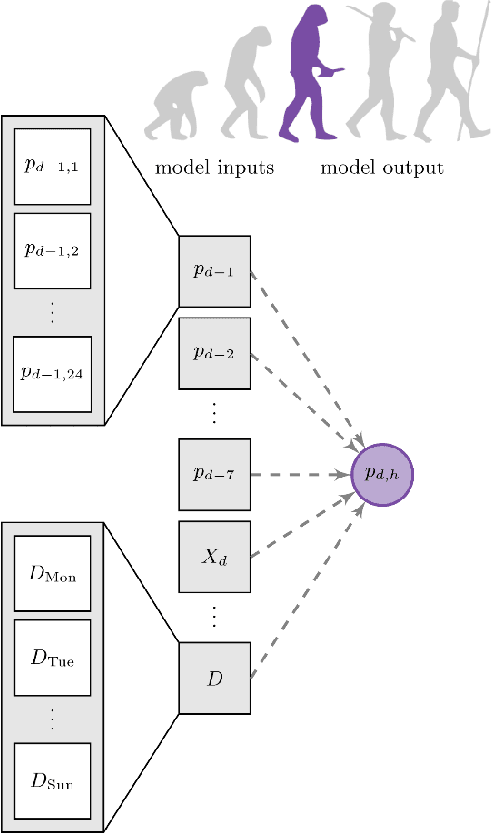
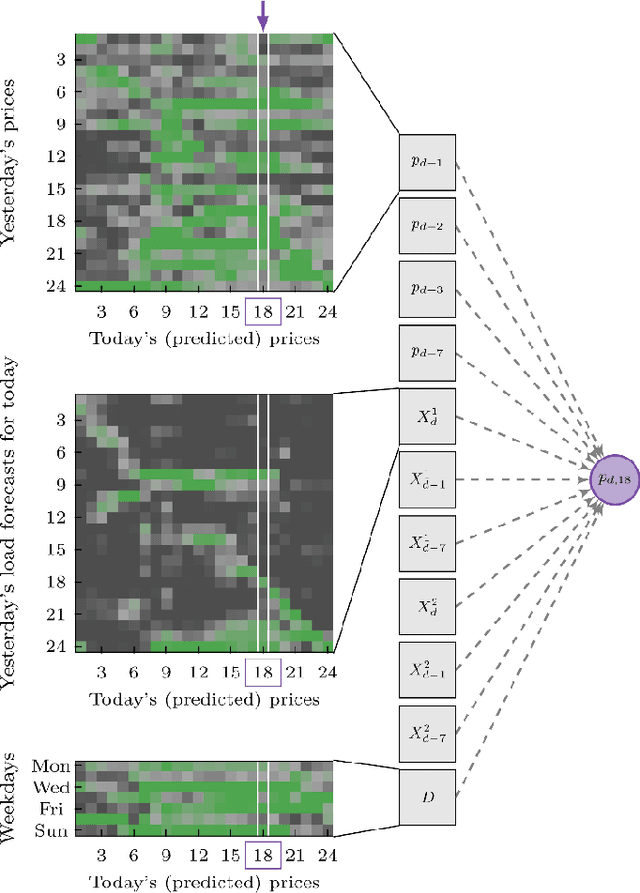
Electricity price forecasting (EPF) is a branch of forecasting on the interface of electrical engineering, statistics, computer science, and finance, which focuses on predicting prices in wholesale electricity markets for a whole spectrum of horizons. These range from a few minutes (real-time/intraday auctions and continuous trading), through days (day-ahead auctions), to weeks, months or even years (exchange and over-the-counter traded futures and forward contracts). Over the last 25 years, various methods and computational tools have been applied to intraday and day-ahead EPF. Until the early 2010s, the field was dominated by relatively small linear regression models and (artificial) neural networks, typically with no more than two dozen inputs. As time passed, more data and more computational power became available. The models grew larger to the extent where expert knowledge was no longer enough to manage the complex structures. This, in turn, led to the introduction of machine learning (ML) techniques in this rapidly developing and fascinating area. Here, we provide an overview of the main trends and EPF models as of 2022.
A Survey of Left Atrial Appendage Segmentation and Analysis in 3D and 4D Medical Images
May 13, 2022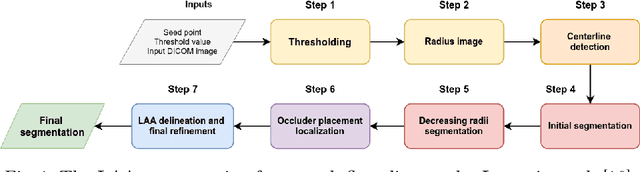
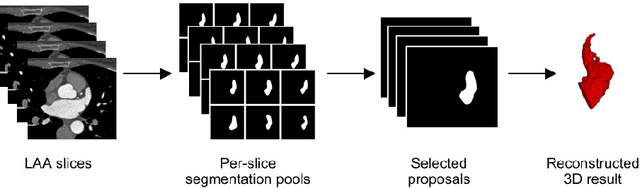
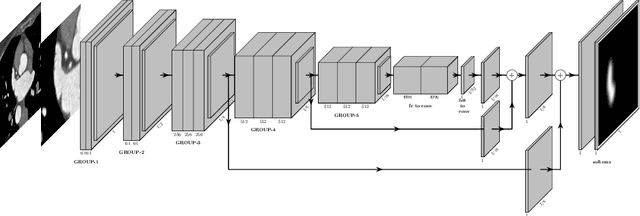
Atrial fibrillation (AF) is a cardiovascular disease identified as one of the main risk factors for stroke. The majority of strokes due to AF are caused by clots originating in the left atrial appendage (LAA). LAA occlusion is an effective procedure for reducing stroke risk. Planning the procedure using pre-procedural imaging and analysis has shown benefits. The analysis is commonly done by manually segmenting the appendage on 2D slices. Automatic LAA segmentation methods could save an expert's time and provide insightful 3D visualizations and accurate automatic measurements to aid in medical procedures. Several semi- and fully-automatic methods for segmenting the appendage have been proposed. This paper provides a review of automatic LAA segmentation methods on 3D and 4D medical images, including CT, MRI, and echocardiogram images. We classify methods into heuristic and model-based methods, as well as into semi- and fully-automatic methods. We summarize and compare the proposed methods, evaluate their effectiveness, and present current challenges in the field and approaches to overcome them.
Data Augmentation with Paraphrase Generation and Entity Extraction for Multimodal Dialogue System
May 09, 2022
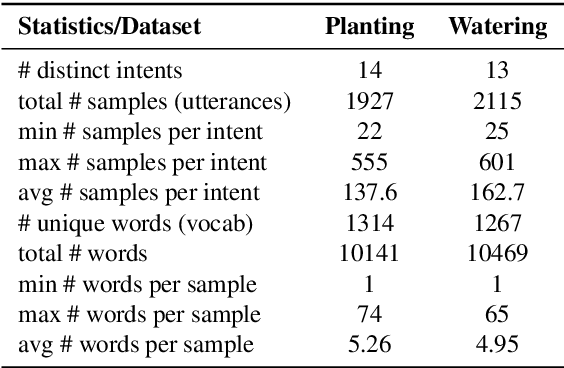
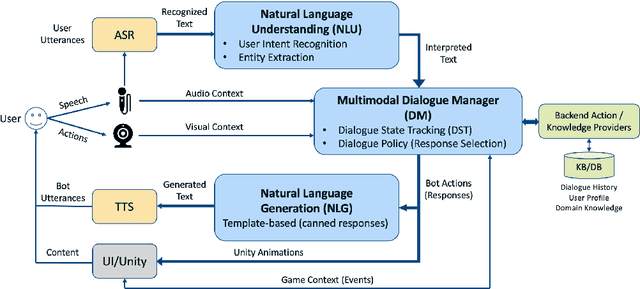
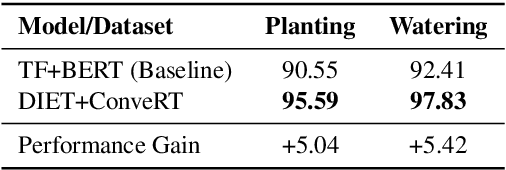
Contextually aware intelligent agents are often required to understand the users and their surroundings in real-time. Our goal is to build Artificial Intelligence (AI) systems that can assist children in their learning process. Within such complex frameworks, Spoken Dialogue Systems (SDS) are crucial building blocks to handle efficient task-oriented communication with children in game-based learning settings. We are working towards a multimodal dialogue system for younger kids learning basic math concepts. Our focus is on improving the Natural Language Understanding (NLU) module of the task-oriented SDS pipeline with limited datasets. This work explores the potential benefits of data augmentation with paraphrase generation for the NLU models trained on small task-specific datasets. We also investigate the effects of extracting entities for conceivably further data expansion. We have shown that paraphrasing with model-in-the-loop (MITL) strategies using small seed data is a promising approach yielding improved performance results for the Intent Recognition task.