 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Beam Decoding with Controlled Patience
Apr 29, 2022

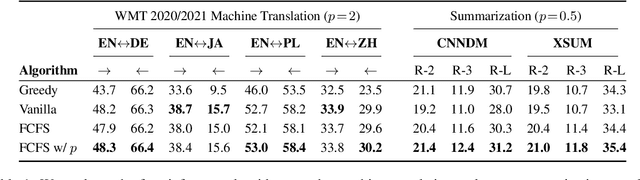


Text generation with beam search has proven successful in a wide range of applications. The commonly-used implementation of beam decoding follows a first come, first served heuristic: it keeps a set of already completed sequences over time steps and stops when the size of this set reaches the beam size. We introduce a patience factor, a simple modification to this decoding algorithm, that generalizes the stopping criterion and provides flexibility to the depth of search. Extensive empirical results demonstrate that the patience factor improves decoding performance of strong pretrained models on news text summarization and machine translation over diverse language pairs, with a negligible inference slowdown. Our approach only modifies one line of code and can be thus readily incorporated in any implementation.
Age of Information in the Presence of an Adversary
Feb 08, 2022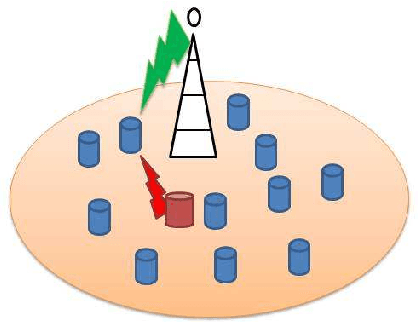
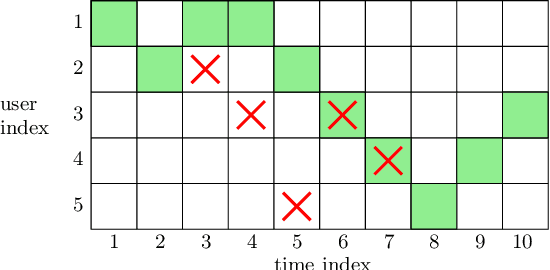
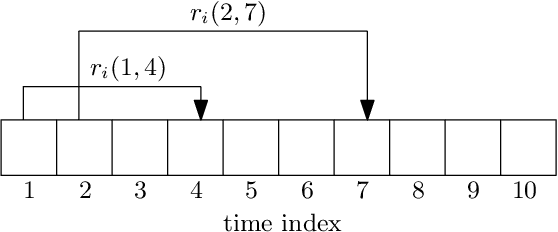
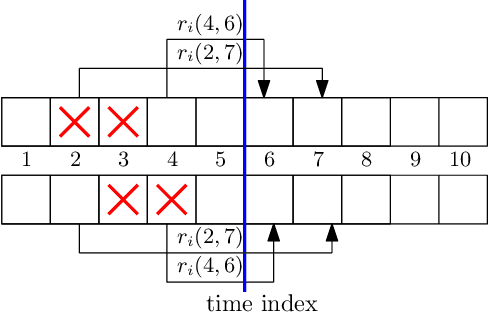
We consider a communication system where a base station serves $N$ users, one user at a time, over a wireless channel. We consider the timeliness of the communication of each user via the age of information metric. A constrained adversary can block at most a given fraction, $\alpha$, of the time slots over a horizon of $T$ slots, i.e., it can block at most $\alpha T$ slots. We show that an optimum adversary blocks $\alpha T$ consecutive time slots of a randomly selected user. The interesting consecutive property of the blocked time slots is due to the cumulative nature of the age metric.
Exploration, Exploitation, and Engagement in Multi-Armed Bandits with Abandonment
May 26, 2022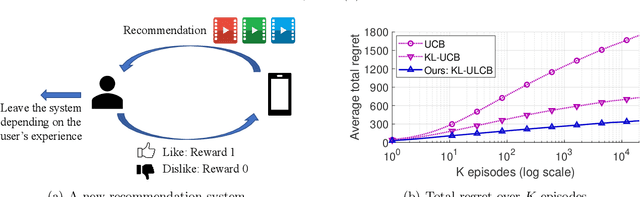

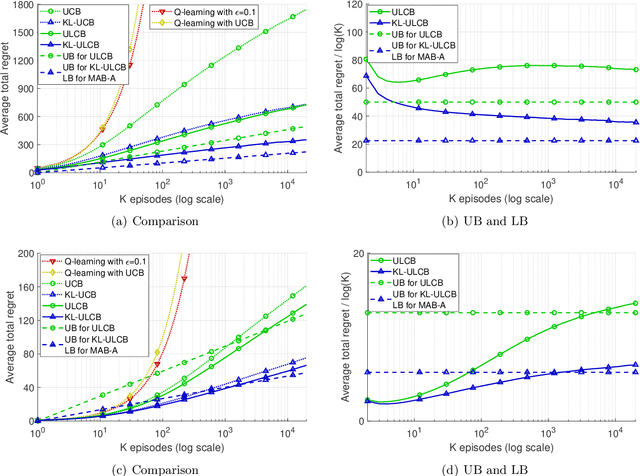

Multi-armed bandit (MAB) is a classic model for understanding the exploration-exploitation trade-off. The traditional MAB model for recommendation systems assumes the user stays in the system for the entire learning horizon. In new online education platforms such as ALEKS or new video recommendation systems such as TikTok and YouTube Shorts, the amount of time a user spends on the app depends on how engaging the recommended contents are. Users may temporarily leave the system if the recommended items cannot engage the users. To understand the exploration, exploitation, and engagement in these systems, we propose a new model, called MAB-A where "A" stands for abandonment and the abandonment probability depends on the current recommended item and the user's past experience (called state). We propose two algorithms, ULCB and KL-ULCB, both of which do more exploration (being optimistic) when the user likes the previous recommended item and less exploration (being pessimistic) when the user does not like the previous item. We prove that both ULCB and KL-ULCB achieve logarithmic regret, $O(\log K)$, where $K$ is the number of visits (or episodes). Furthermore, the regret bound under KL-ULCB is asymptotically sharp. We also extend the proposed algorithms to the general-state setting. Simulation results confirm our theoretical analysis and show that the proposed algorithms have significantly lower regrets than the traditional UCB and KL-UCB, and Q-learning-based algorithms.
Energy-Efficient Resource Allocation for Aggregated RF/VLC Systems
Jun 03, 2022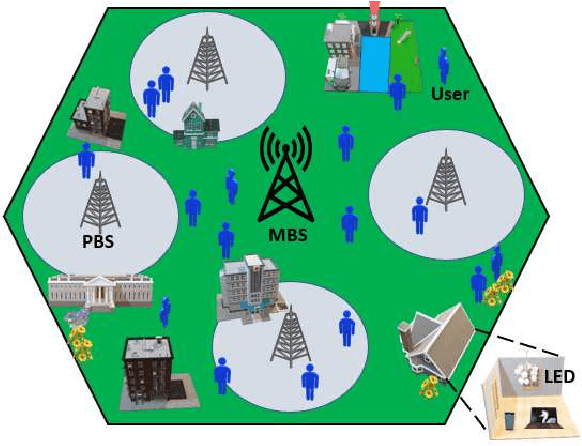
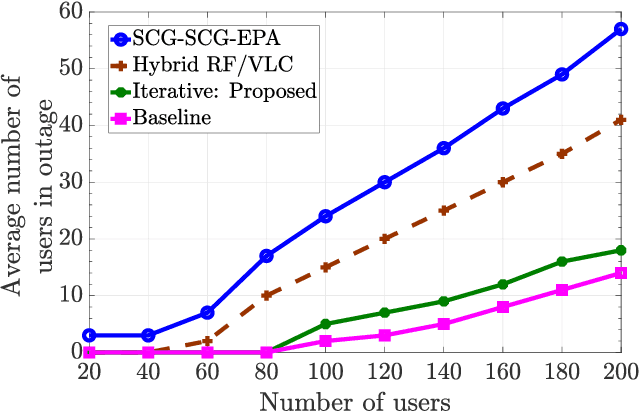
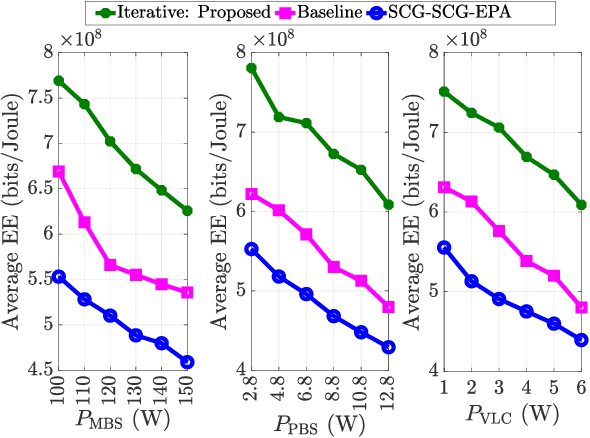
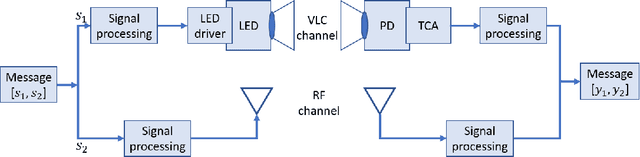
Visible light communication (VLC) is envisioned as a core component of future wireless communication networks due to, among others, the huge unlicensed bandwidth it offers and the fact that it does not cause any interference to existing radio frequency (RF) communication systems. Most research on RF and VLC coexistence has focused on hybrid designs where data transmission to any user could originate from either an RF or a VLC access point (AP). However, hybrid RF/VLC systems fail to exploit the distinct transmission characteristics of RF and VLC systems to fully reap the benefits they can offer. Aggregated RF/VLC systems, in which any user can be served simultaneously by both RF and VLC APs, have recently emerged as a more promising and robust design for the coexistence of RF and VLC systems. To this end, this paper, for the first time, investigates AP assignment, subchannel allocation (SA), and transmit power allocation (PA) to optimize the energy efficiency (EE) of aggregated RF/VLC systems while considering the effects of interference and VLC line-of-sight link blockages. A novel and challenging EE optimization problem is formulated for which an efficient joint solution based on alternating optimization is developed. More particularly, an energy-efficient AP assignment algorithm based on matching theory is proposed. Then, a low-complexity SA scheme that allocates subchannels to users based on their channel conditions is developed. Finally, an effective PA algorithm is presented by utilizing the quadratic transform approach and a multi-objective optimization framework. Extensive simulation results reveal that: 1) the proposed joint AP assignment, SA, and PA solution obtains significant EE, sum-rate, and outage performance gains with low complexity, and 2) the aggregated RF/VLC system provides considerable performance improvement compared to hybrid RF/VLC systems.
Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination
Jun 03, 2022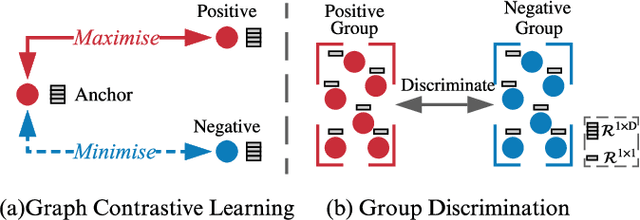
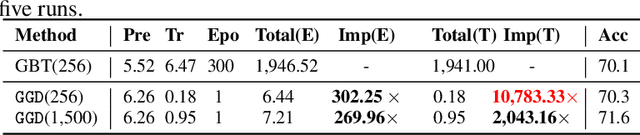
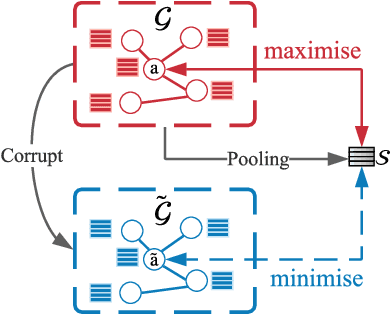
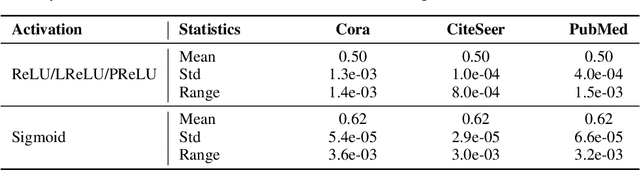
Graph contrastive learning (GCL) alleviates the heavy reliance on label information for graph representation learning (GRL) via self-supervised learning schemes. The core idea is to learn by maximising mutual information for similar instances, which requires similarity computation between two node instances. However, this operation can be computationally expensive. For example, the time complexity of two commonly adopted contrastive loss functions (i.e., InfoNCE and JSD estimator) for a node is $O(ND)$ and $O(D)$, respectively, where $N$ is the number of nodes, and $D$ is the embedding dimension. Additionally, GCL normally requires a large number of training epochs to be well-trained on large-scale datasets. Inspired by an observation of a technical defect (i.e., inappropriate usage of Sigmoid function) commonly used in two representative GCL works, DGI and MVGRL, we revisit GCL and introduce a new learning paradigm for self-supervised GRL, namely, Group Discrimination (GD), and propose a novel GD-based method called Graph Group Discrimination (GGD). Instead of similarity computation, GGD directly discriminates two groups of summarised node instances with a simple binary cross-entropy loss. As such, GGD only requires $O(1)$ for loss computation of a node. In addition, GGD requires much fewer training epochs to obtain competitive performance compared with GCL methods on large-scale datasets. These two advantages endow GGD with the very efficient property. Extensive experiments show that GGD outperforms state-of-the-art self-supervised methods on 8 datasets. In particular, GGD can be trained in 0.18 seconds (6.44 seconds including data preprocessing) on ogbn-arxiv, which is orders of magnitude (10,000+ faster than GCL baselines} while consuming much less memory. Trained with 9 hours on ogbn-papers100M with billion edges, GGD outperforms its GCL counterparts in both accuracy and efficiency.
Electricity Price Forecasting: The Dawn of Machine Learning
Apr 02, 2022
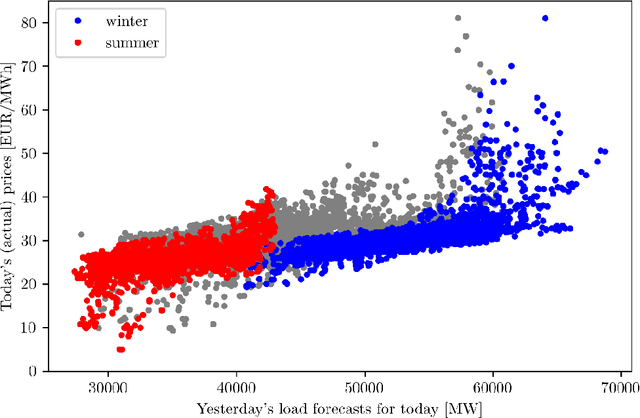
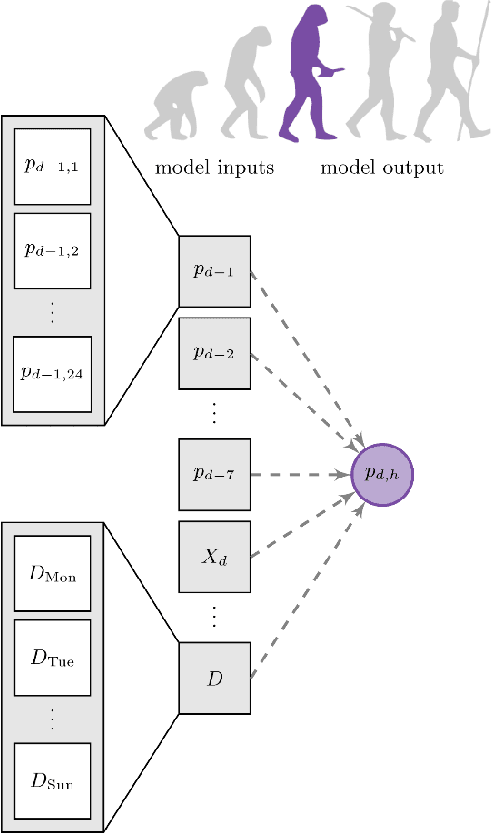
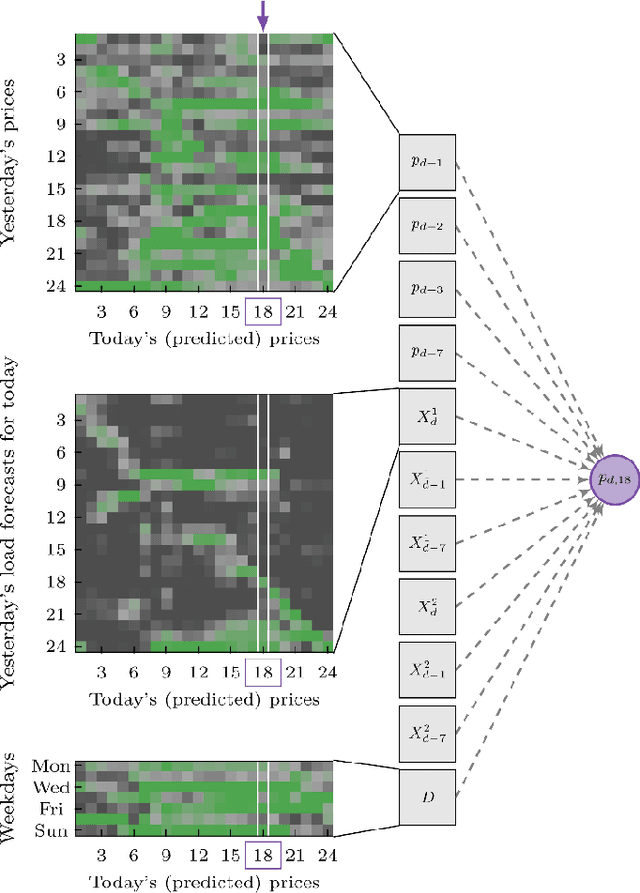
Electricity price forecasting (EPF) is a branch of forecasting on the interface of electrical engineering, statistics, computer science, and finance, which focuses on predicting prices in wholesale electricity markets for a whole spectrum of horizons. These range from a few minutes (real-time/intraday auctions and continuous trading), through days (day-ahead auctions), to weeks, months or even years (exchange and over-the-counter traded futures and forward contracts). Over the last 25 years, various methods and computational tools have been applied to intraday and day-ahead EPF. Until the early 2010s, the field was dominated by relatively small linear regression models and (artificial) neural networks, typically with no more than two dozen inputs. As time passed, more data and more computational power became available. The models grew larger to the extent where expert knowledge was no longer enough to manage the complex structures. This, in turn, led to the introduction of machine learning (ML) techniques in this rapidly developing and fascinating area. Here, we provide an overview of the main trends and EPF models as of 2022.
Do Residual Neural Networks discretize Neural Ordinary Differential Equations?
May 29, 2022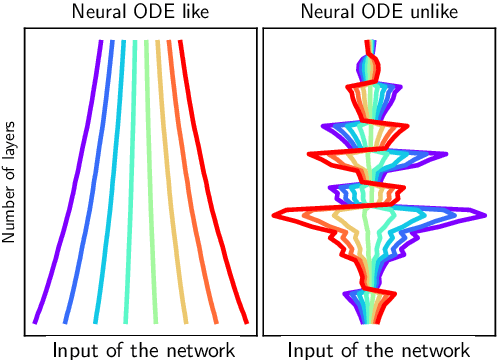
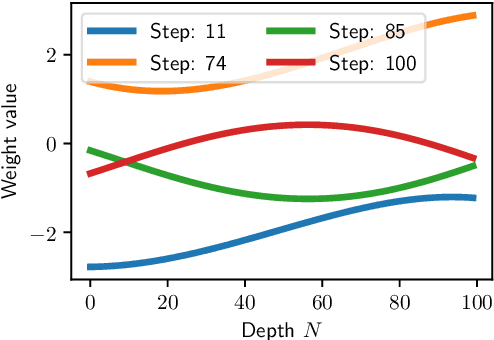
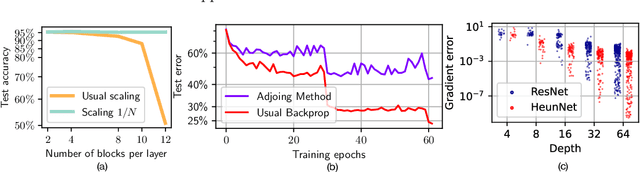
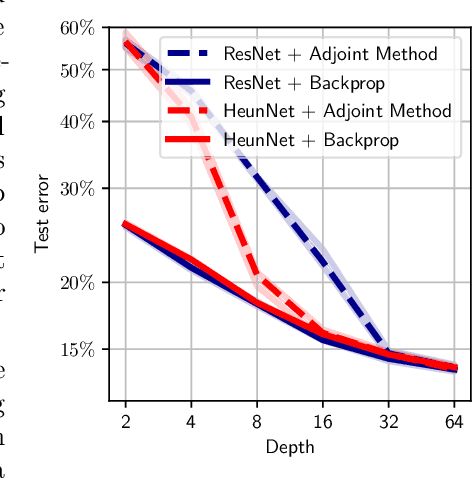
Neural Ordinary Differential Equations (Neural ODEs) are the continuous analog of Residual Neural Networks (ResNets). We investigate whether the discrete dynamics defined by a ResNet are close to the continuous one of a Neural ODE. We first quantify the distance between the ResNet's hidden state trajectory and the solution of its corresponding Neural ODE. Our bound is tight and, on the negative side, does not go to 0 with depth N if the residual functions are not smooth with depth. On the positive side, we show that this smoothness is preserved by gradient descent for a ResNet with linear residual functions and small enough initial loss. It ensures an implicit regularization towards a limit Neural ODE at rate 1 over N, uniformly with depth and optimization time. As a byproduct of our analysis, we consider the use of a memory-free discrete adjoint method to train a ResNet by recovering the activations on the fly through a backward pass of the network, and show that this method theoretically succeeds at large depth if the residual functions are Lipschitz with the input. We then show that Heun's method, a second order ODE integration scheme, allows for better gradient estimation with the adjoint method when the residual functions are smooth with depth. We experimentally validate that our adjoint method succeeds at large depth, and that Heun method needs fewer layers to succeed. We finally use the adjoint method successfully for fine-tuning very deep ResNets without memory consumption in the residual layers.
Multivariate Quantile Bayesian Structural Time Series (MQBSTS) Model
Oct 04, 2020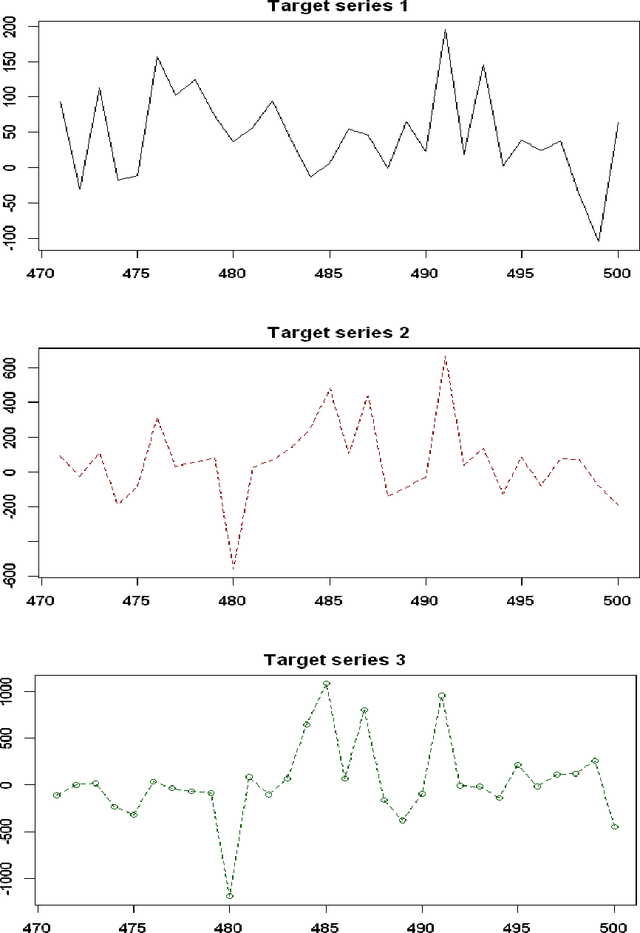

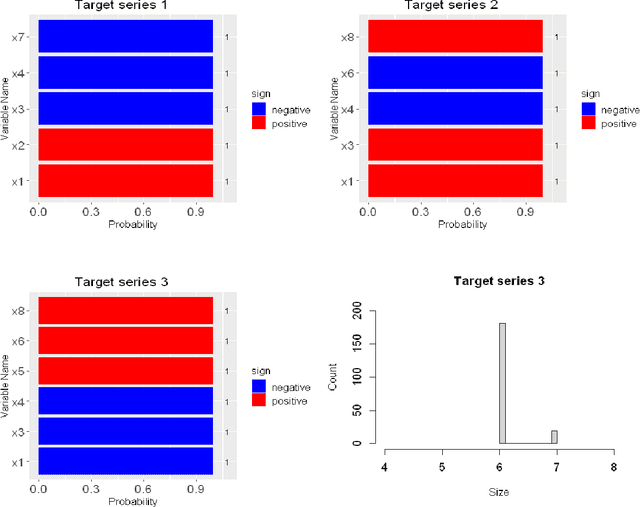
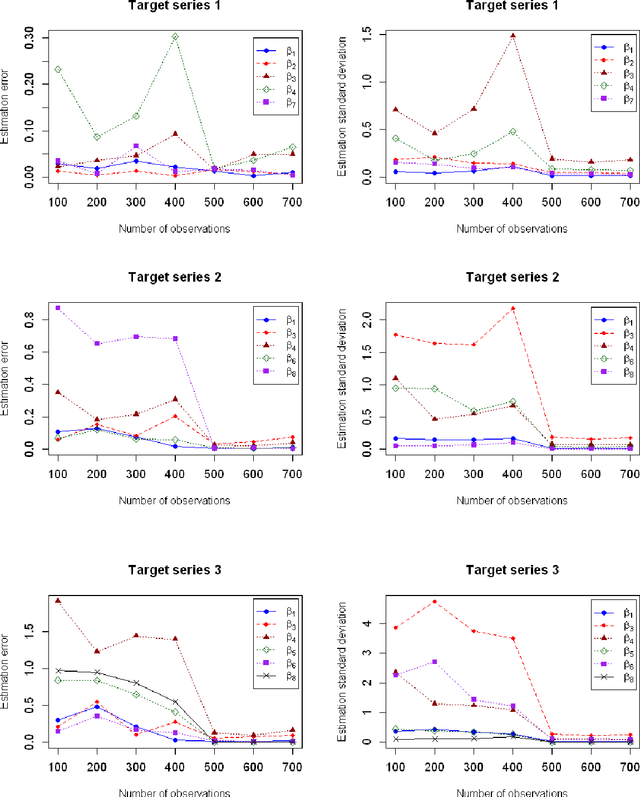
In this paper, we propose the multivariate quantile Bayesian structural time series (MQBSTS) model for the joint quantile time series forecast, which is the first such model for correlated multivariate time series to the author's best knowledge. The MQBSTS model also enables quantile based feature selection in its regression component where each time series has its own pool of contemporaneous external time series predictors, which is the first time that a fully data-driven quantile feature selection technique applicable to time series data to the author's best knowledge. Different from most machine learning algorithms, the MQBSTS model has very few hyper-parameters to tune, requires small datasets to train, converges fast, and is executable on ordinary personal computers. Extensive examinations on simulated data and empirical data confirmed that the MQBSTS model has superior performance in feature selection, parameter estimation, and forecast.
Extraction of Unaliased High-Frequency Micro-Doppler Signature using FMCW radar
Apr 20, 2022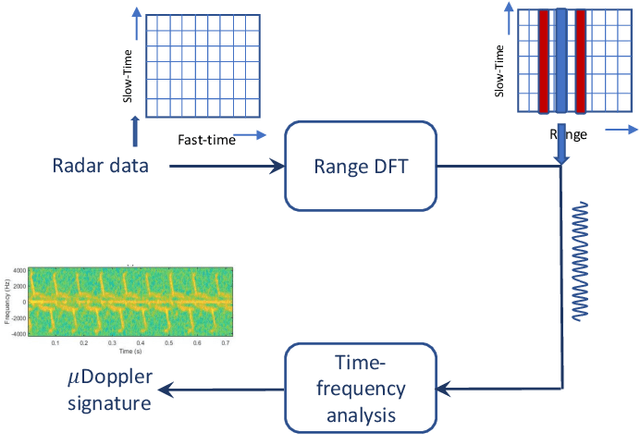
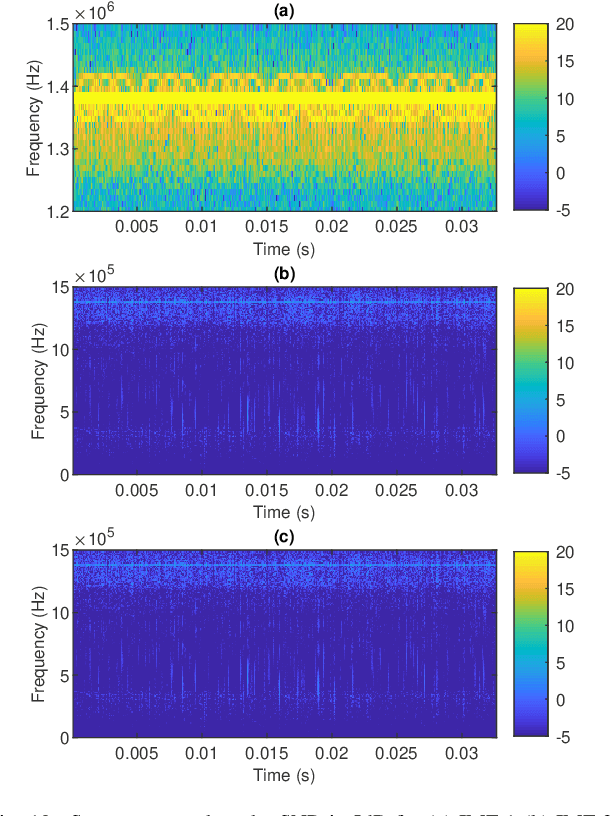
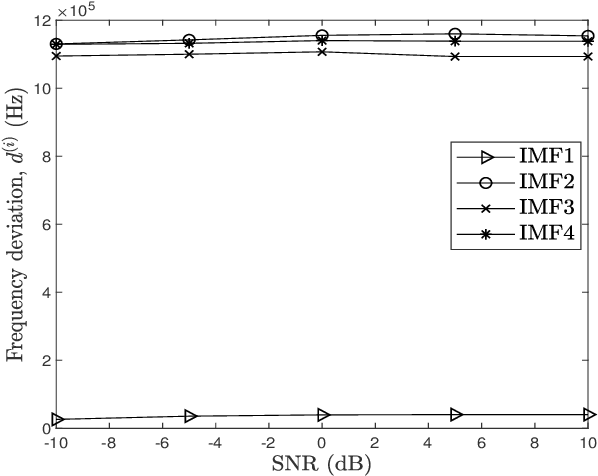
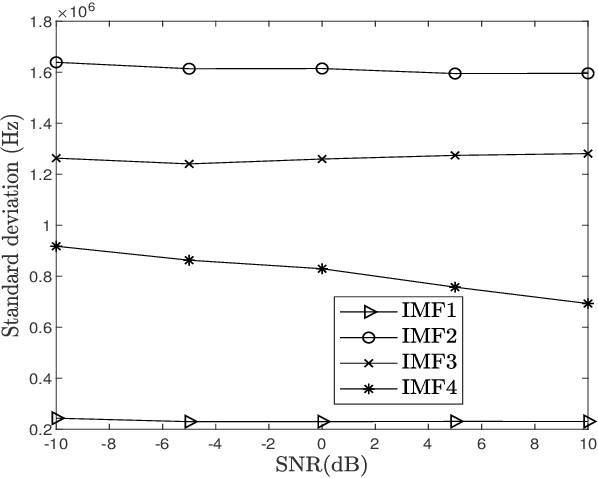
Micro-Doppler signature is a potent feature that has been used for target identification and micro-motion parameter estimation. The extraction of high frequency micro-Doppler signature from frequency modulated continuous wave (FMCW) radar along with the target range and velocity is the problem considered in this article. The severe aliasing of the high micro-Doppler frequency spread is circumvented by the fast time processing in the proposed method. The use of range-Doppler (RD) filtering and empirical mode decomposition (EMD) enables effective out-of-band and in-band noise suppression. Simulation studies and experimental results present the effectiveness of the proposed approach.
Target-aware Abstractive Related Work Generation with Contrastive Learning
May 26, 2022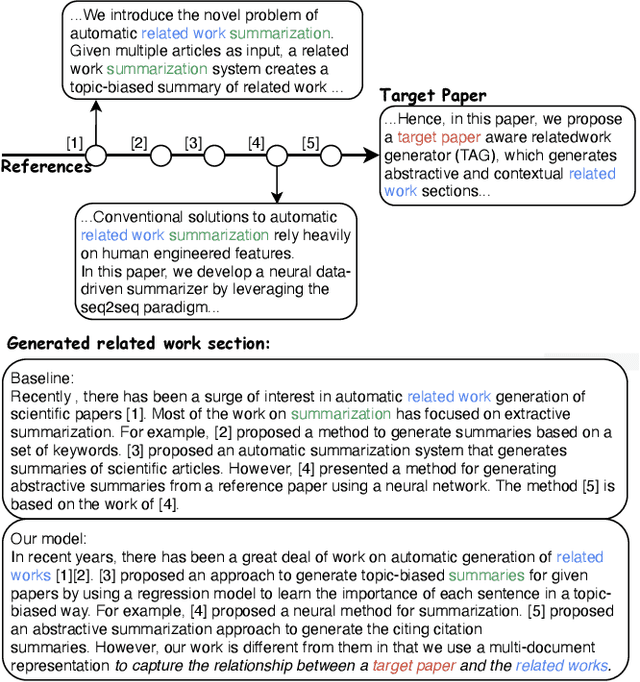
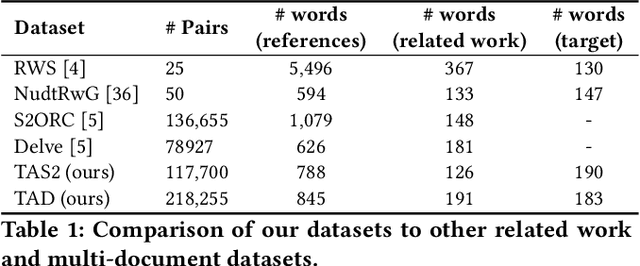
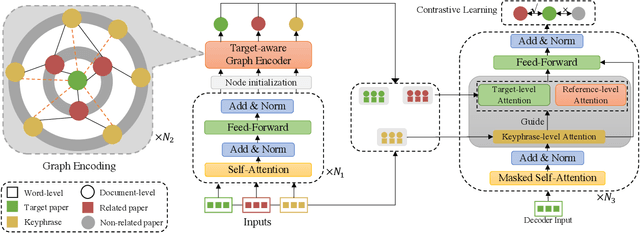
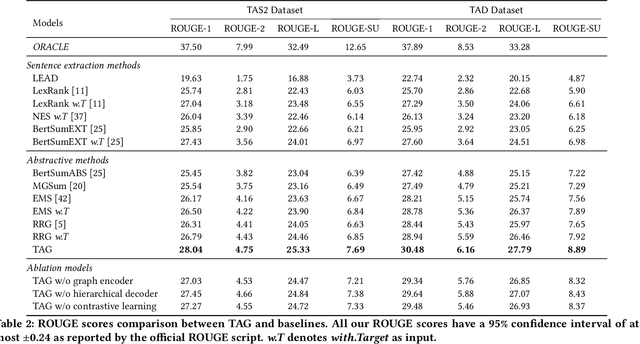
The related work section is an important component of a scientific paper, which highlights the contribution of the target paper in the context of the reference papers. Authors can save their time and effort by using the automatically generated related work section as a draft to complete the final related work. Most of the existing related work section generation methods rely on extracting off-the-shelf sentences to make a comparative discussion about the target work and the reference papers. However, such sentences need to be written in advance and are hard to obtain in practice. Hence, in this paper, we propose an abstractive target-aware related work generator (TAG), which can generate related work sections consisting of new sentences. Concretely, we first propose a target-aware graph encoder, which models the relationships between reference papers and the target paper with target-centered attention mechanisms. In the decoding process, we propose a hierarchical decoder that attends to the nodes of different levels in the graph with keyphrases as semantic indicators. Finally, to generate a more informative related work, we propose multi-level contrastive optimization objectives, which aim to maximize the mutual information between the generated related work with the references and minimize that with non-references. Extensive experiments on two public scholar datasets show that the proposed model brings substantial improvements over several strong baselines in terms of automatic and tailored human evaluations.